
얼마 전 포스팅 한 ViTPose 포스팅 작성 후 실제로 ViTPose를 돌려보고 싶어서 진행해보며 남기는 포스팅.
가상환경 설정
아나콘다 혹은 미니콘다의 conda 도구 사용하여 python 기반 가상환경 설정하여 세팅을 해보려한다. https://github.com/ViTAE-Transformer/ViTPose 페이지의 Readme.md 는 작성된지 좀 되어, 요구하는 pytorch, mmcv 등의 버전이 상당히 낮아 일단 언급한 버전대로 진행해보려한다. 하지만 본인의 취향은 현재 버전에서 과거의 라이브러리가 돌아가도록 주기적인 최신화를 하는 것이다.
- conda setting
# create conda env $ conda create -n vitpose python==3.8.19 $ conda activate vitpose - install python package
$ pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html $ MMCV_WITH_OPS=1 pip install mmcv-full==1.3.9 $ git clone https://github.com/ViTAE-Transformer/ViTPose.git $ cd ViTPose $ pip install -v -e .
추론 준비
-
Install optinal python package 나는 해당 ViTPose 디렉토리의
demo/top_down_pose_tracking_demo_with_mmdet.py파일을 돌려보려한다. 그래서 해당 파일에 있는 파이썬 패키지들을 추가로 설치해줘야 할 소요가 있다.$ pip install mmdet==2.14.0 $ pip install timm==0.4.9그 후 해당 파일의
ArgumentParser부분을 보고 적절한 파라미터와 함께 실행 시키면 정상작동을 확인할 수 있다.$ python demo/top_down_pose_tracking_demo_with_mmdet.py \ ./demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ ./weights/faster_rcnn_r50_fpn_mstrain_3x_coco_20210524_110822-e10bd31c.pth \ ./configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py \ ./weights/vitpose-b-multi-coco.pth \ --video-path=/home/dongle94/Videos/dance/dance3.mp4 \ --show \ --out-video-root ./runs/- 앞선 4개의 파라미터는 각각
det_config,det_checkpoint,pose_config,pose_checkpoint의 포지션 아규먼트이다. 디텍션 관련한 건 이어서 설명 --video-path로 분석할 동영상 파일을 지정한다.--show옵션을 활성화하면 스크립트 실행 시 실시간으로 영상에 대한 자세추정 시각화가 실행된다.--out-video-root지정 시 해당 경로에 자세 추정 시각화 영상이 저장된다.
- 앞선 4개의 파라미터는 각각
mmdet 관련 부분
위의 스크립트에서 det_config, det_checkpoint 부분에 해당 하는 내용. 우선적으로 det_config에 해당하는 부분은 ViTPose/demo/mmdetection_cfg 경로에 파이썬 파일의 형태로 존재한다. cascade_rcnn..., faster_rcnn.. 등 여러 객체 감지 모델이 존재하나 본인은 faster_rcnn_r50_fpn_coco.py 파일을 선택하였다.
이어서 해당 설정의 체크포인트 파일을 준비해야한다. 해당 파일은 mmdetection 리포지토리에서 확인할 수 있으며 하단의 Model Zoo에서 필요한 모델을 찾을 수 있다.
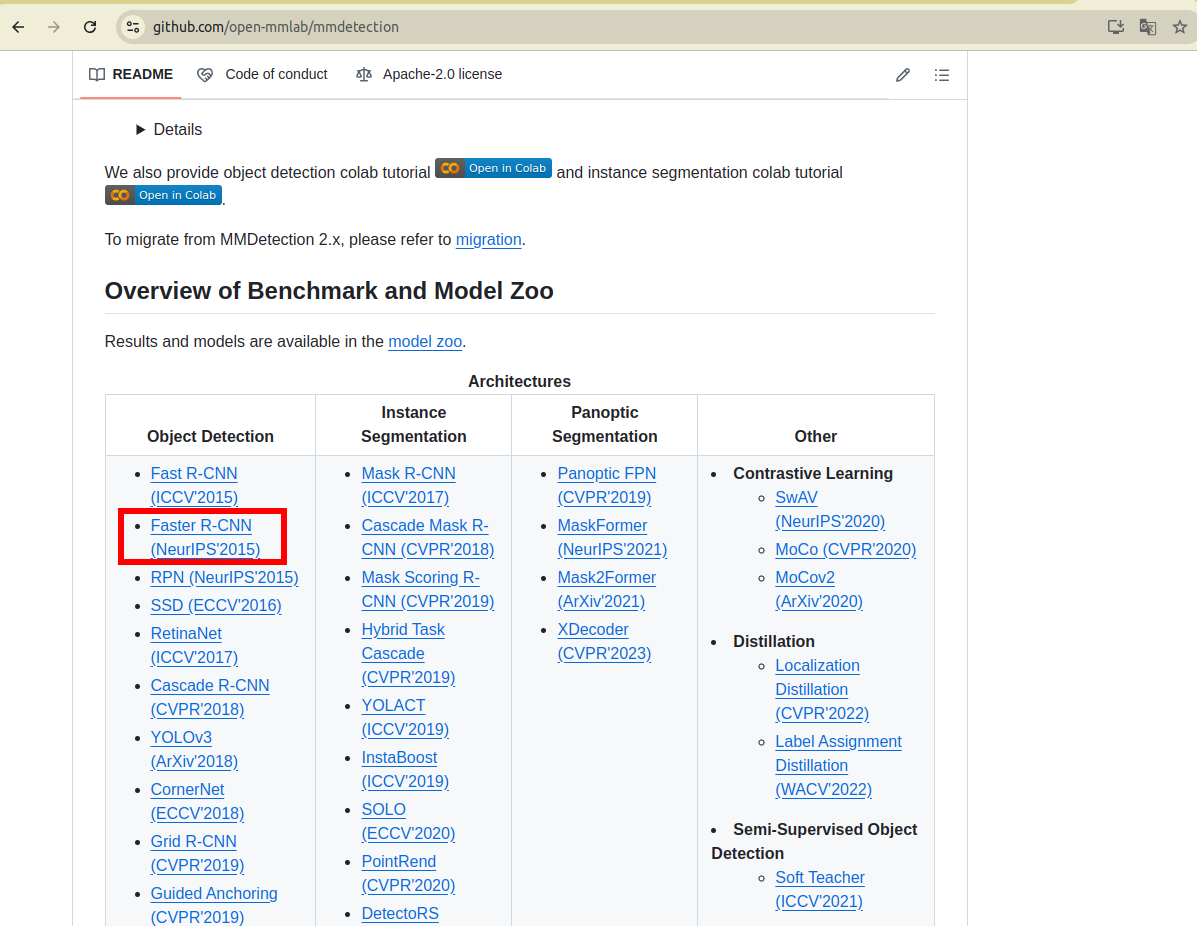
원하는 모델을 클릭하여 링크로 들어간 후 아래에 제공되는 모델들 목록에서 적절한 weight 파일을 다운로드 하자. 본인은 pytorch 프레임워크와 대략적인 box AP 등의 성능을 확인 후 아래의 빨간색으로 표시한 항목의 weight를 다운로드 받았다.
실행 결과
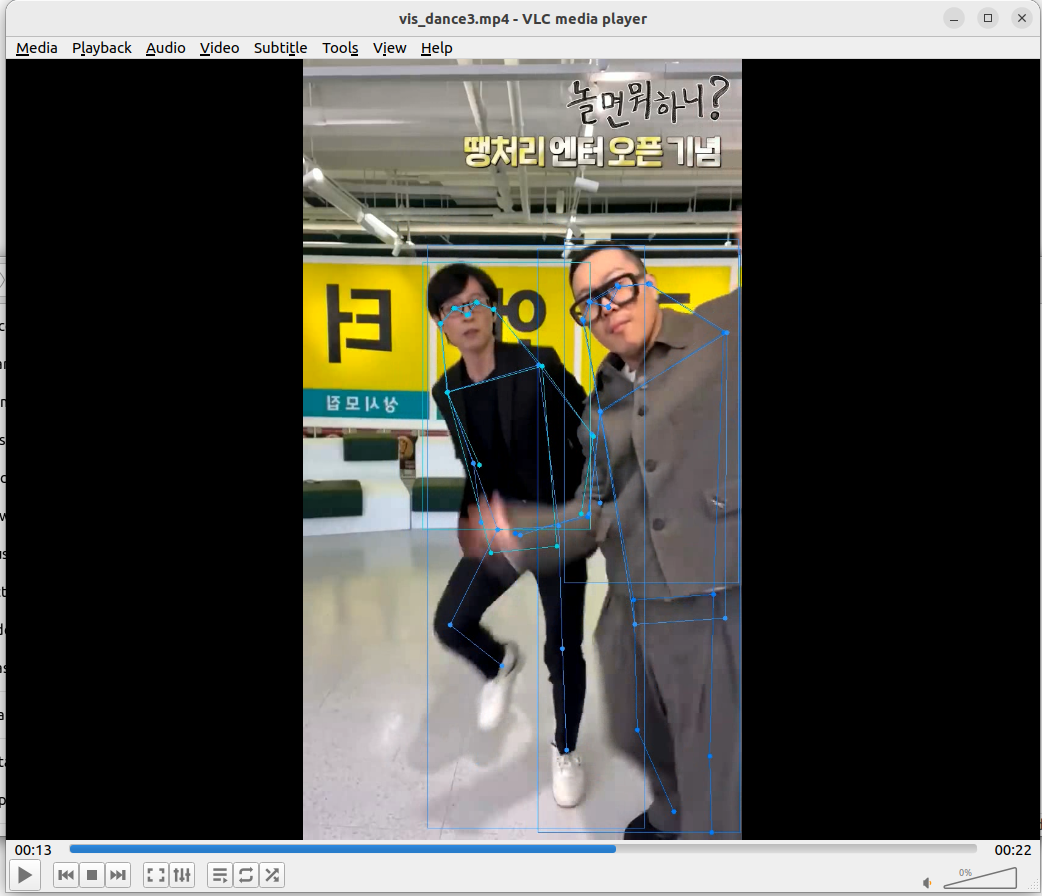
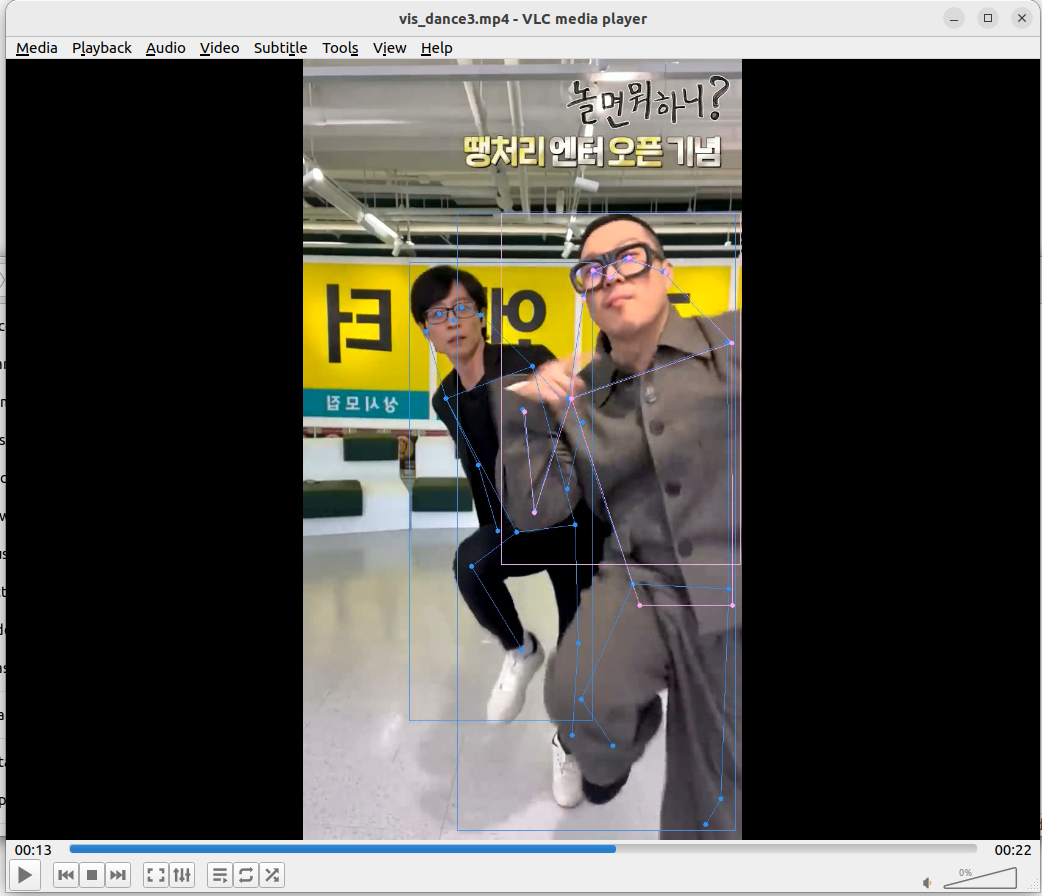
테스트 용으로 가지고 있던 댄스 챌린지 영상들이 있다. 해당 영상을 대상으로 테스트를 진행해보았고, Top-Down 모델의 맞게 객체 감지 모델 결과에 따라 출력을 보여주었다. 정리하자면 다음과 같다.
- 적절한 사람 객체 감지를 했을 때 자세 추정의 성능은 정성적으로 매우 좋아보인다.
- 단, 객체감지 결과의 바운딩 박스에 따라 성능이 안좋게 나올 수 있는 것처럼 보인다.
- 그런데 프레임 별로 확인해보니 신체의 일부가 잘린 바운딩 박스에도 해당 신체 영역 만큼의 인체 관절을 적절히 추출한 것으로 보인다.
- 바운딩 박스가 애매하게 하반신+상반신 일부만 잘린다거나 그러면 애매한 관절들이 보일 수 있지만 바운딩 박스가 상반신만 깔끔히 예측했다면 허리 관절부터 그 위로 존재하는 관절들이 전신 바운딩 박스에 대한 관절 추정 결과와 거의 유사하게 나온다.
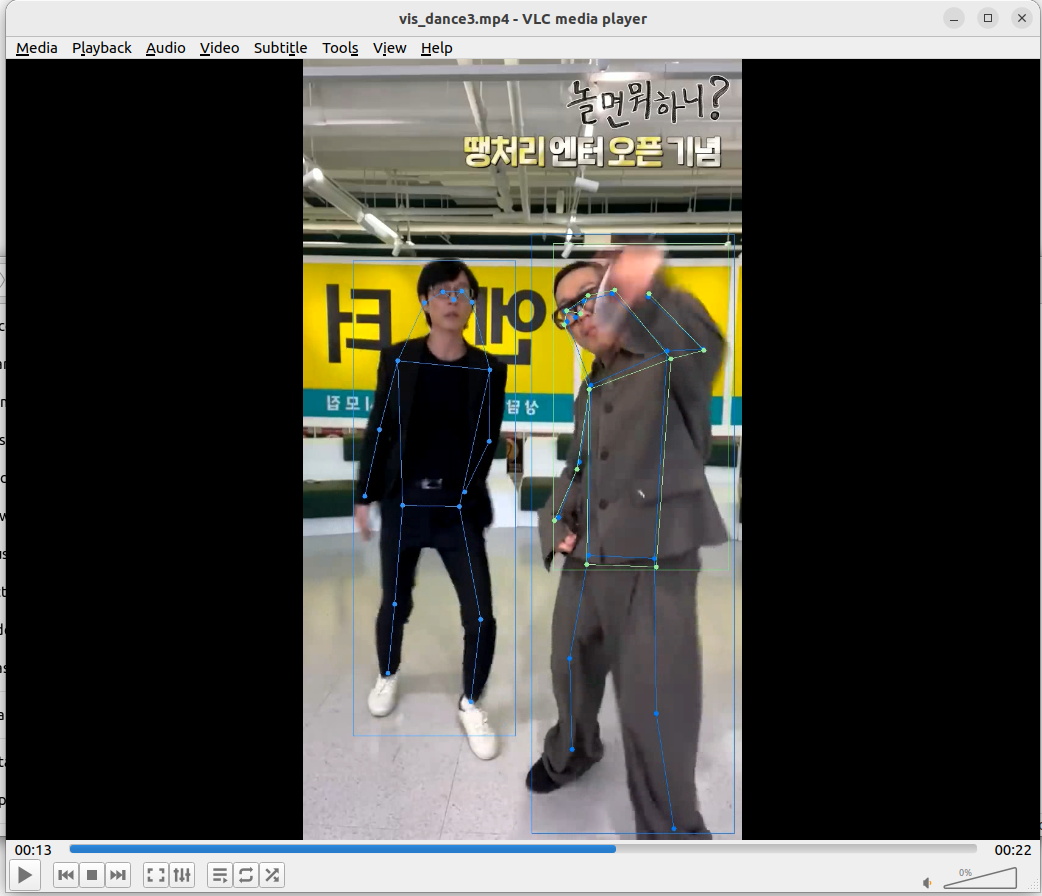
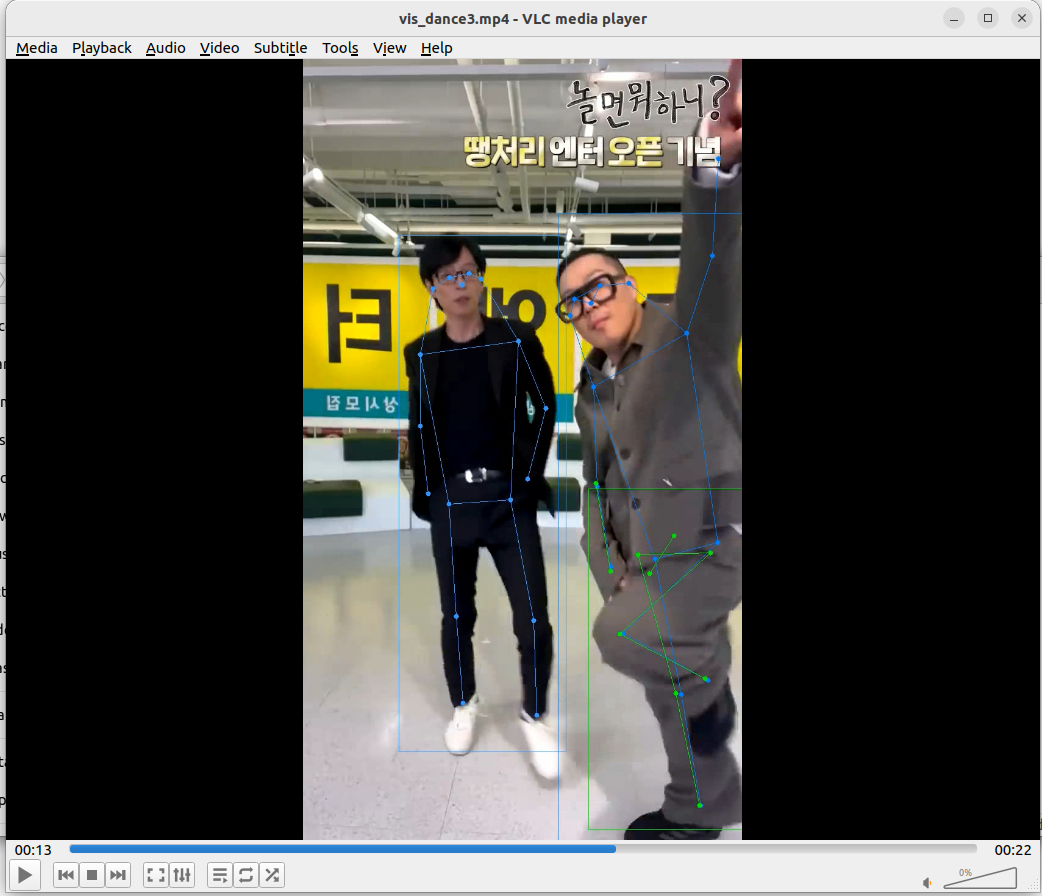

댓글남기기