

개요
ByteTrack: Multi-Object Tracking by Associating Every Detection Box 논문의 얕은 리뷰.
본 논문은 기존까지의 객체 추적 방법론에서 압도적인 성능을 끌어올리는 BYTE라는 연관 방법론을 제시한다. 사실 내용을 뜯어보면 상당히 간단한데, 디텍션의 결과로 나온 바운딩 박스 중 스코어가 낮은 박스들을 버리지 않고 활용하는 것이다. 간단한 이 아이디어 만으로 MOT17, MOT20 뿐 아니라 자율주행 관련 데이터셋 벤치마크에서도 우수한 성능을 달성한다.
방법론
BYTE
- 단순하면서도 효과적인 데이터 연결(association) 방법으로, 낮은 스코어의 디텍션 박스까지 활성하여 트랙렛(tracklet)을 형성 및 보완하는 기법
- 기존에는 일정 기준(예: 0.5) 이상인 바운딩 박스만 연결에 사용했으나, occlusion이나 모션 블러 등으로 점수가 낮게 나온 실제 객체가 버려지는 일이 발생. 그래서 이러한 낮은 스코어의 박스를 고려하면서도, 진짜 객체인지 배경인지를 구분함으로써 추적의 성능을 높임.
- 이러한 방법론은 다른 객체 추적기(에: FairMOT, CenterTrack 등)의 연결 단계에도 적용 가능한 방법론으로, 낮은 점수 박스에서 실제 객체를 찾아 성능을 높이도록 적용할 수 있다.
- 즉, ‘BYTE‘는 연결(association)만 담당하는 모듈로 볼 수 있다.
ByteTrack
- BYTE 기법을 적용한 전체 추적기(Tracker) 구조
- 본 논문에서는 YOLOX 라는 고성능 디텍터를 사용했는데, 해당 포스팅을 작성하는 현 시점에서는 더 높은 실시간 객체 감지 모델로 대체가 가능할 것으로 보인다.
- 너무 간단한게 핵심. 객체감지기의 추론 결과인 바운딩 박스 검출(Detection)과 연결(Association)을 통해 트랙렛을 형성하고 유지하여 객체 추적을 달성한다.
Details
본 논문이 제시하는 방법론은 고성능 객체감지기의 정확한 디텍션 박스를 활용하여 일부 가림(occlusion)이나 모션 블러가 존재해도 객체 감지 자체는 어느정도 낮은 스코어더라도 성공함을 전제로 한다.
이어진 두 단계의 연결 전략인 BYTE 를 통해 우선 높은 점수의 디텍션 박스와 트랙렛을 모션 정보 기반(칼만필터 + IoU)로 매칭하고, 두 번째 연결 단계에서는 낮은 점수 박스를 활용하여 매칭되지 않은 트랙렛과 재매칭한다. 해당 방법론에서는 외형정보에 의존하지 않기 때문에, 가림이나 모션블러로 인해 이러한 외형 특징(Feature)이 불안정한 상황에서도 안정적으로 객체를 복원할 수 있다.
칼만 필터를 통해 트랙렛의 위치를 예측함으로써, 디텍션의 점수가 낮아진 경우에도 이전 프레임의 모션 정보를 이용해 객체의 위치를 효과적으로 추정가능하고, 이로 인해 가림이나 모션블러의 상황에서도 연결 단게를 견고하게 유지할 수 있다.
단, 완전히 사라졌다가 나중에 재등장하는 경우에는 별도의 외형정보 등을 활용하는 특징 추출기(Feature Extractor)가 있는 객체 추적기가 더 성능이 좋은 것 아닌가 하는 의문이 들 수 있으나, 이런 극단적인 상황에서는 대부분의 추적 시스템이 완전히 사라진 경우를 별도의 트랙 재생(Track Rebirth) 메커니즘을 통해 처리한다. 본 논문에서는 매칭되지 않은(사라진) 트랙에 대해서 바로 삭제하지 않고 임시로 보관하다가, 다시 감지된 디텍션과 충분한 유사도를 보인다면, 이러한 임시 트랙과 매칭하여 트랙렛을 부활 시는 것이다.
결론
본 논문은 기존의 “높은 점수 디텍션 박스만 연결”하는 방식의 한계를 극복하기 위해 낮은 점수 박스까지 포함하여 모든 디텍션 박스를 활용하는 간단하고 효과적인 연결(association) 방법인 BYTE를 제안한다. 해당 방법은 칼만 필터와 IoU와 같은 모션 예측 기법만으로, 가림이나 모션 블러와 같은 어려운 상황에서도 낮은 스코어의 박스를 활용해 효과적인 성능 향상을 달성할 수 있음을 보인다. 복잡한 외형(Re-ID) 네트워크 없이도, 효과적인 성능을 달성했으며, 필요하다면 기존의 특징 추출 네트워크를 사용하는 추적기에도 BYTE를 결합해 사용할 수 있음에 확장성도 챙겼다. 심지어 객체감지기의 성능 향상은 추적 성능 향상을 가져옴을 암시하며 우수한 성능을 입증한다.
번역
Abstract
멀티 객체 추적(MOT)은 영상에서 객체의 경계 상자와 아이덴티티를 추정하는 것을 목표로 한다. 대부분의 기법은 점수(score)가 임계값보다 높은 디텍션 박스들을 서로 연결(association)하여 아이덴티티를 얻는다. 하지만 점수가 낮은 디텍션 박스들(예: 가려진 객체)은 단순히 버려지는데, 이는 무시할 수 없는 수준의 실제 객체 누락과 단절된 궤적을 야기한다. 이 문제를 해결하기 위해 우리는 간단하면서도 효과적이고 범용적인 연결 방식(association) 방법을 제안한다. 이는 높은 점수 박스만 쓰는 대신, 거의 모든 디텍션 박스를 활용하여 추적을 수행한다. 점수가 낮은 디텍션 박스에 대해서는 트랙렛(tracklet)과의 유사도를 활용해 실제 객체를 복원하고 배경 디텍션을 걸러낸다. 우리 방법을 9가지 최첨단 추적기에 적용한 결과, IDF1 점수가 1점에서 최대 10점까지 꾸준히 향상되는 것을 확인하였다. 또한 MOT의 최신 성능을 달성하기 위해 ByteTrack이라 명명한 단순하면서도 강력한 추적기를 설계하였다. 처음으로 단일 V100 GPU에서 초당 30프레임(FPS)으로 동작하면서 MOT17 테스트 세트에서 80.3의 MOTA, 77.3의 IDF1, 63.1의 HOTA를 달성하였다. ByteTrack은 또한 MOT20, HiEve, BDD100K 추적 벤치마크에서도 최첨단 성능을 보여준다. 소스 코드와 배포 버전의 사전 학습 모델, 그리고 다른 추적기에 적용하는 방법에 대한 튜토리얼은 다음 주소에서 공개되어 있다: https://github.com/ifzhang/ByteTrack.
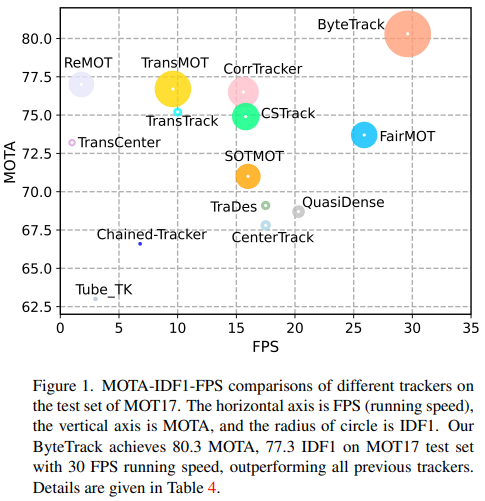
1. Introduction
합리적인 것은 현실적이며, 현실적인 것은 합리적이다. —— G. W. F. 헤겔
트래킹-바이-디텍션(tracking-by-detection)은 현재 멀티 객체 추적(MOT)에서 가장 효과적인 패러다임이다. 영상이 복잡한 상황을 담고 있기 때문에, 디텍터는 불완전한 예측을 하기 쉽다. 최신 MOT 기법들 [1–3, 6, 12, 18, 45, 59, 70, 72, 85]은 낮은 신뢰도의 디텍션 박스를 제거하기 위해, 디텍션 박스 내에서 진양성(true positive)과 오검출(false positive)을 조정하는 문제 [4, 40]를 다루어야 한다. 그렇다면 모든 낮은 신뢰도 디텍션 박스를 제거하는 방식이 옳은가? 우리의 대답은 “아니다.”이다. 헤겔이 말했듯이, “합리적인 것은 현실적이고, 현실적인 것은 합리적이다.” 낮은 신뢰도의 디텍션 박스는 때때로 객체(예: 가려진 객체)의 존재를 나타낸다. 이런 객체들을 걸러내면 멀티 객체 추적에서 되돌릴 수 없는 오류가 발생하고, 실제 객체가 누락되거나 궤적이 단절되는 문제를 무시할 수 없게 된다.

그림 2 (a)와 (b)는 이 문제를 보여준다. 프레임 t1에서, 우리는 점수가 모두 0.5를 초과하는 세 개의 트랙렛(tracklet)을 초기화한다. 그러나 프레임 t2와 t3에서 가림(occlusion)이 발생하자, 빨간색 트랙렛에 해당하는 디텍션 점수가 0.8에서 0.4로, 그리고 0.4에서 0.1로 낮아진다. 이러한 디텍션 박스들은 임계값 기법에 의해 제거되고, 그 결과 빨간색 트랙렛도 사라진다. 반면에 모든 디텍션 박스를 고려한다면, 예컨대 그림 2 (a)의 프레임 t3에 있는 가장 오른쪽 박스처럼 추가적인 오검출(false positive)이 바로 유입될 것이다. 우리가 아는 한, MOT에서 이와 같은 디텍션 딜레마를 해결할 수 있는 방법은 [30, 63]처럼 극히 드물다.
본 논문에서 우리는 트랙렛과의 유사도가 낮은 점수의 디텍션 박스에서 객체와 배경을 구분하는 강력한 단서를 제공한다는 사실을 확인한다. 그림 2 (c)에서 보이듯이, 두 개의 낮은 점수 디텍션 박스는 모션 모델이 예측한 박스를 통해 트랙렛과 매칭되어 정확히 객체를 복원한다. 동시에 매칭되는 트랙렛이 없는 배경 박스는 제거된다.
매칭 과정에서 점수가 높은 디텍션 박스부터 낮은 디텍션 박스까지 최대한 활용하기 위해, 우리는 BYTE라는 간단하면서도 효과적인 연결(association) 방법을 제안한다. 여기서 각 디텍션 박스는 컴퓨터 프로그램의 ‘바이트(byte)’처럼 트랙렛(tracklet)의 기본 단위가 되며, 우리의 추적 기법은 모든 디텍션 박스를 세밀하게 중요시한다. 먼저 높은 점수의 디텍션 박스들은 모션 유사도 혹은 외형(appearance) 유사도를 기반으로 트랙렛에 매칭된다. [6]과 유사하게, 우리는 칼만 필터(Kalman filter) [29]를 사용해 새로운 프레임에서 트랙렛의 위치를 예측한다. 유사도는 예측된 박스와 디텍션 박스 사이의 IoU 또는 Re-ID 특징 거리로 계산할 수 있다. 그림 2 (b)는 첫 번째 매칭 후의 결과를 정확히 보여준다. 이후 우리는 매칭되지 않은 트랙렛(빨간 박스에 해당하는 트랙렛)과 낮은 점수 디텍션 박스 간에 동일한 모션 유사도를 사용해 두 번째 매칭을 수행한다. 그림 2 (c)는 두 번째 매칭 이후의 결과를 나타낸다. 낮은 점수 디텍션을 가진 가려진 사람(occluded person)이 이전 트랙렛과 올바르게 매칭되고, 영상 오른쪽에 위치한 배경은 제거된다.
객체 검출과 연결(association)이 결합된 주제로서, 바람직한 MOT 솔루션은 결코 디텍터와 이후 연결 과정을 따로 떼어놓을 수 없으며, 두 과정이 맞닿는 접점 영역을 잘 설계하는 것도 중요하다. BYTE의 혁신은 바로 이 디텍션과 연결이 만나는 지점에 있으며, 여기서 낮은 점수의 디텍션 박스가 두 과정을 모두 강화해 주는 ‘교량’ 역할을 한다. 이러한 통합적 발상의 이점을 통해 BYTE를 Re-ID 기반 추적기 [33,47,69,85], 모션 기반 추적기 [71, 89], 체인 구조를 사용하는 추적기 [48], 그리고 어텐션 기반 추적기 [59, 80] 등 9가지 최신 기법에 적용했을 때, MOTA, IDF1 점수, ID 전환(ID switches) 등 거의 모든 지표에서 의미 있는 성능 향상을 얻었다. 예를 들어, CenterTrack [89]의 경우 MOT17 절반 검증 세트에서 MOTA를 66.1에서 67.4로, IDF1을 64.2에서 74.0으로 끌어올렸으며, ID 전환 횟수는 528에서 144로 줄였다.
MOT 분야에서 최신 성능을 한 단계 끌어올리기 위해, 우리는 ByteTrack이라 불리는 간단하고도 강력한 추적기를 제안한다. 우리는 최근 높은 성능을 보이는 디텍터 YOLOX [24]를 사용해 디텍션 박스를 얻은 뒤, 제안 기법 BYTE로 이를 연결한다. MOT 챌린지에서 ByteTrack은 MOT17 [44]과 MOT20 [17] 두 벤치마크 모두에서 1위를 기록했으며, MOT17에서는 V100 GPU 단일 장치에서 초당 30프레임으로 동작하면서 80.3 MOTA, 77.3 IDF1, 63.1 HOTA를 달성했고, 더욱 혼잡한 MOT20에서는 77.8 MOTA, 75.2 IDF1, 61.3 HOTA를 얻었다. 또한 ByteTrack은 HiEve [37], BDD100K [79] 추적 벤치마크에서도 최첨단 성능을 달성했다. 우리는 ByteTrack의 효율성과 단순성이 사회적 컴퓨팅과 같은 실제 활용 분야에서도 매력적인 해법이 되기를 기대한다.
2. Related Work
2.1. Object Detection in MOT
객체 검출은 컴퓨터 비전에서 가장 활발히 연구되는 주제 중 하나이며, 이는 멀티 객체 추적의 기반이 된다. MOT17 데이터셋 [44]은 DPM [22], Faster R-CNN [50], SDP [77] 같은 유명 디텍터로부터 얻은 디텍션 결과를 제공한다. 많은 기법들 [3, 9, 12, 14, 28, 74, 91]은 이러한 주어진 디텍션 결과를 활용하여 추적 성능을 개선하는 데 초점을 맞추고 있다.
Tracking by detection.
객체 검출 [10, 23, 26, 35, 49, 50, 58, 60] 기술이 빠르게 발전함에 따라, 더 높은 추적 성능을 얻기 위해 보다 강력한 디텍터를 활용하는 방법이 늘어나고 있다. 단일 단계(one-stage) 객체 검출기인 RetinaNet [35]은 [39, 48] 등의 여러 기법에서 채택되기 시작했다. CenterNet [63, 65, 67, 71, 85, 87, 89]은 간단하고 효율적이라는 점에서 가장 많이 사용되는 디텍터이다. YOLO 시리즈 디텍터 [8, 49] 역시 정확도와 속도의 우수한 균형 덕분에 [15, 33, 34, 69] 등 많은 기법에서 채택된다. 대부분의 이러한 방법들은 단일 이미지에서 얻은 디텍션 박스를 바로 추적에 사용한다.
하지만 영상 시퀀스에서 가림(occlusion)이나 모션 블러가 발생하면 누락된 디텍션이나 매우 낮은 점수를 가진 디텍션이 늘어나기 시작하는데, 이는 비디오 객체 검출 기법 [41, 62]에서도 지적된 바 있다. 따라서 이전 프레임의 정보를 활용해 비디오 디텍션 성능을 향상하는 경우가 많다.
Detection by tracking.
추적을 활용하여 더 정확한 디텍션 박스를 얻을 수도 있다. 몇몇 기법들 [12–15, 53, 91]은 단일 객체 추적(SOT) [5] 또는 칼만 필터(Kalman filter) [29]를 사용해 다음 프레임에서 트랙렛(tracklet)의 위치를 예측하고, 예측된 박스를 디텍션 박스와 결합해 디텍션 결과를 향상시킨다. 다른 방법들 [34, 86]은 이전 프레임에서 추적된 박스를 활용하여 다음 프레임의 특징 표현(feature representation)을 강화한다. 최근에는 트랜스포머(Transformer) 기반 [20, 38, 64, 66] 디텍터 [11, 92]가 프레임 간 박스를 전달(propagate)하는 강력한 능력 덕분에 여러 기법 [42, 59, 80]에서 채택되고 있다. 본 논문 역시 트랙렛과의 유사도를 활용해 디텍션 박스의 신뢰도를 높인다.
여러 디텍터를 통해 디텍션 박스를 얻은 뒤, 대부분의 MOT 기법 [33, 39, 47, 59, 69, 71, 85]은 일정 임계값(예: 0.5) 이상 점수를 가진 박스만 남기고 이를 데이터 연결(data association)의 입력으로 사용한다. 이는 낮은 점수의 디텍션 박스가 추적 성능을 저해하는 배경(background)일 가능성이 높기 때문이다. 하지만 우리가 관찰한 바에 따르면, 가려진 객체 중에서도 낮은 점수를 가지면서도 실제로는 올바르게 검출된 경우가 많다. 따라서 누락된 디텍션을 줄이고 궤적을 일관되게 유지하기 위해, 우리는 모든 디텍션 박스를 남긴 뒤 이를 전부 연결한다.
2.2. Data Association
데이터 연결(data association)은 멀티 객체 추적의 핵심으로, 먼저 트랙렛과 디텍션 박스 간의 유사도를 계산한 뒤 해당 유사도에 따라 매칭 전략을 달리 적용한다.
Similarity metrics.
위치(location), 모션(motion), 외형(appearance)은 연결 과정에서 유용한 단서가 된다. SORT [6]는 위치와 모션 정보를 매우 간단하게 결합한다. 우선 칼만 필터(Kalman filter) [29]로 새 프레임에서 트랙렛의 위치를 예측한 뒤, 예측된 박스와 디텍션 박스 간의 IoU를 유사도로 계산한다. 최근 일부 기법들 [59, 71, 89]은 객체 모션을 학습하는 네트워크를 설계하여 큰 카메라 움직임이나 낮은 프레임레이트 상황에서도 더욱 견고한 결과를 얻는다. 위치와 모션 유사도는 근거리 매칭에서 정확도가 높으며, 외형 유사도는 장거리 매칭에 유리하다. 예컨대 객체가 오랫동안 가려진 뒤에도 외형 유사도를 통해 재식별(re-identification)할 수 있다. 외형 유사도는 Re-ID 특징의 코사인 유사도로 측정할 수 있다. DeepSORT [70]는 독립적인 Re-ID 모델을 사용해 디텍션 박스에서 외형 특징을 추출한다. 최근에는 검출과 Re-ID를 결합한 모델 [33, 39, 47, 69, 84, 85]이 단순성과 효율성 덕분에 더욱 주목받고 있다.
Matching strategy.
유사도 계산 후에는 매칭 전략을 통해 객체에 아이덴티티를 할당한다. 이는 헝가리안 알고리즘(Hungarian Algorithm) [31] 또는 탐욕적 할당(greedy assignment) [89]으로 수행할 수 있다. SORT [6]는 단 한 번의 매칭으로 디텍션 박스와 트랙렛을 연결한다. DeepSORT [70]는 계단식(cascaded) 매칭 전략을 제안하여, 먼저 디텍션 박스를 가장 최근 트랙렛에 매칭한 후 남은 트랙렛(잃어버린 트랙렛)에 매칭한다. MOTDT [12]는 먼저 외형 유사도를 사용해 매칭을 수행하고, 이후 남은 트랙렛을 IoU 유사도로 매칭한다. QDTrack [47]은 외형 유사도를 양방향 소프트맥스 연산을 통해 확률로 변환하고, 최근접 이웃(nearest neighbor) 탐색을 통해 매칭을 완성한다. 어텐션(attention) 메커니즘 [64]은 프레임 간 박스를 직접 전달하여 암묵적으로 연결 과정을 수행한다. 최근 기법들 [42, 80]은 트랙 쿼리(track queries)를 사용해 다음 프레임에서 추적 중인 객체의 위치를 찾으며, 매칭은 어텐션 상호작용 과정에서 헝가리안 알고리즘 없이 암묵적으로 이뤄진다.
이러한 방법들은 모두 더 나은 연결 방안을 고안하는 데 초점을 맞춘다. 그러나 우리는 디텍션 박스를 어떤 식으로 활용하느냐가 데이터 연결의 상한선을 결정한다고 주장하며, 점수가 높은 디텍션 박스부터 낮은 디텍션 박스까지 모두 효율적으로 활용하는 방안에 주목한다.
3. BYTE

우리는 간단하면서도 효과적이고 범용적인 데이터 연결(association) 방식인 BYTE를 제안한다. [33, 47, 69, 85] 등의 기존 기법이 높은 점수를 가진 디텍션 박스만 사용했던 것과 달리, 우리는 거의 모든 디텍션 박스를 유지하고 이를 높은 점수 박스와 낮은 점수 박스로 나눈다. 먼저 높은 점수의 디텍션 박스들을 트랙렛에 연결한다. 가려짐(occlusion), 모션 블러, 객체 크기 변화 등이 발생하면 적절한 높은 점수 디텍션 박스와 매칭되지 못한 트랙렛이 생길 수 있다. 이후에는 낮은 점수 디텍션 박스와 이 매칭되지 않은 트랙렛들을 연결하여 낮은 점수 디텍션 박스 내 객체를 복원하고, 동시에 배경을 걸러낸다. BYTE의 의사코드(pseudo-code)는 알고리즘 1에 제시되어 있다.
BYTE의 입력은 영상 시퀀스 V 와 객체 검출기 Det이며, 추가로 디텍션 점수 임계값 $τ$를 설정한다. BYTE의 출력은 영상 내 트랙들의 집합 $\mathcal{T}$이며, 각 트랙은 매 프레임에서 객체의 경계 상자와 아이덴티티를 포함한다.
영상의 각 프레임마다, 우리는 Det를 사용해 디텍션 박스와 점수를 예측한다. 예측된 디텍션 박스는 점수 임계값 $τ$에 따라 $\mathcal{D}_high$ 와 $\mathcal{D}_low$ 두 부분으로 나뉜다. 점수가 $τ$보다 높은 디텍션 박스는 $\mathcal{D}_high$ 에, 점수가 $τ$ 이하인 디텍션 박스는 $\mathcal{D}_low$ 에 각각 저장한다(알고리즘 1의 3~13번째 줄).
낮은 점수 디텍션 박스와 높은 점수 디텍션 박스를 구분한 뒤, 우리는 칼만 필터를 사용하여 현재 프레임에서 트랙 $\mathcal{T}$ 각각의 새로운 위치를 예측한다(알고리즘 1의 14~16번째 줄).
첫 번째 연결 과정은 높은 점수 디텍션 박스 $\mathcal{D}_high$ 와 모든 트랙 $\mathcal{T}$ (잃어버린 트랙 $\mathcal{T}_lost$ 포함) 간에 수행된다. Similarity#1 은 $\mathcal{D}_high$ 와 트랙 $\mathcal{T}$ 가 예측한 박스 사이의 IoU 혹은 Re-ID 특징 거리를 통해 계산할 수 있다. 이후 헝가리안 알고리즘 [31]을 사용해 이 유사도에 기반한 매칭을 완료한다. 매칭에서 남은 디텍션 박스는 $\mathcal{D}_remain$ 에, 매칭에서 남은 트랙은 $\mathcal{T}_remain$ 에 저장한다(알고리즘 1의 17~19번째 줄).
BYTE는 매우 유연하며, 다른 여러 연결 기법과도 호환 가능하다. 예를 들어 FairMOT [85]과 결합할 때는 알고리즘 1의 * first association * 단계에 Re-ID 특징을 추가하고 나머지는 동일하게 유지한다. 실험에서 우리는 BYTE를 9가지 최신 추적기에 적용해 거의 모든 지표에서 의미 있는 성능 향상을 달성했다.
두 번째 연결(association)은 첫 번째 연결 후 남은 트랙 $\mathcal{T}_remain$ 과 낮은 점수 디텍션 박스 $\mathcal{D}_low$ 간에 수행된다. 매칭되지 않은 트랙은 $\mathcal{T}_re\text{-}remain$ 에 남겨두고, 매칭되지 않은 낮은 점수 디텍션 박스는 모두 배경으로 간주하여 삭제한다(알고리즘 1의 20~21번째 줄). 우리는 두 번째 연결에서 Similarity#2로 오직 IoU만 사용하는 것을 중요하게 본다. 이는 낮은 점수 디텍션 박스가 보통 심한 가림(occlusion)이나 모션 블러를 포함하고 있어 외형(appearance) 특징이 신뢰하기 어렵기 때문이다. 따라서 BYTE를 다른 Re-ID 기반 추적기 [47, 69, 85]에 적용할 때는 두 번째 연결에서 외형 유사도를 사용하지 않는다.
연결 과정 이후에도 매칭되지 않은 트랙은 트랙렛에서 제거된다. 단순화를 위해 알고리즘 1에서는 트랙 재생(track rebirth) [12, 70, 89] 과정을 생략했지만, 실제로는 트랙의 아이덴티티를 장기적으로 유지하기 위해 필수적이다. 두 번째 연결 후 매칭되지 않은 트랙 $\mathcal{T}_re\text{-}remain$ 은 $\mathcal{T}_lost$ 에 넣는다. $\mathcal{T}_lost$ 에 있는 각 트랙은 30프레임 등 특정 개수 이상의 프레임 동안 유지된 경우에만 트랙 $\mathcal{T}$ 에서 제거하고, 그렇지 않다면 계속 $\mathcal{T}$ 내에 $\mathcal{T}_lost$ 형태로 둔다(알고리즘 1의 22번째 줄). 마지막으로, 첫 번째 연결 후 매칭되지 않은 높은 점수 디텍션 박스 $\mathcal{D}_remain$ 에서 새로운 트랙을 초기화한다(알고리즘 1의 23~27번째 줄). 각 프레임에서 최종적으로 출력되는 것은 현재 프레임에 존재하는 트랙 $T$의 경계 상자와 아이덴티티이며, $\mathcal{T}_lost$ 에 속한 박스와 아이덴티티는 출력하지 않는다.
4. Experiments
4.1. Setting
Datasets.
우리는 MOT17 [44]과 MOT20 [17] 데이터셋에서 “private detection” 프로토콜을 적용해 BYTE와 ByteTrack을 평가한다. 두 데이터셋 모두 학습 세트와 테스트 세트만 있으며, 검증 세트는 없다. 에블레이션 연구를 위해, [89]를 따라 MOT17 학습 세트의 각 비디오 전반부를 학습용으로, 후반부를 검증용으로 사용한다. [59, 71, 80, 89]를 참고하여 CrowdHuman 데이터셋 [55]과 MOT17 절반 학습 세트를 조합해 학습하며, MOT17 테스트 세트를 평가할 때는 [33, 69, 85]를 따라 Cityperson [82]과 ETHZ [21]도 추가로 학습에 활용한다. 또한 ByteTrack을 HiEve [37]와 BDD100K [79] 데이터셋에도 적용해본다. HiEve는 혼잡하고 복잡한 이벤트를 다루는 대규모 휴먼 중심 데이터셋이고, BDD100K는 가장 큰 주행 영상 데이터셋으로, MOT 작업에 대해 1400개 비디오를 학습용, 200개를 검증용, 400개를 테스트용으로 분할한다. 여기서는 8개 클래스의 객체를 추적해야 하며, 큰 카메라 움직임이 포함된 경우도 있다.
Metrics.
우리는 CLEAR 지표 [4], 즉 MOTA, FP, FN, IDs 등을 사용하고, 추가로 IDF1 [51], HOTA [40]를 활용하여 추적 성능의 여러 측면을 평가한다. MOTA는 FP, FN, ID 전환(IDs)에 기반해 계산되는데, FP와 FN의 절대량이 IDs보다 많으므로 MOTA는 검출 성능에 더 큰 비중을 둔다. IDF1은 아이덴티티 보존 능력을 평가하며, 연결(association) 성능에 초점을 맞춘다. HOTA는 최근 제안된 지표로, 정확한 검출·연결·위치 추정이 얼마나 균형을 이루는지를 명시적으로 평가한다. BDD100K 데이터셋의 경우, mMOTA나 mIDF1 같은 멀티 클래스 지표도 있는데, 이는 모든 클래스에 대해 계산된 MOTA, IDF1을 평균 낸 값이다.
Implementation details.
BYTE의 기본 디텍션 점수 임계값 $τ$는 별도의 언급이 없으면 0.6을 사용한다. MOT17, MOT20, HiEve 벤치마크 평가에서는 유사도 척도로 IoU만을 사용한다. 선형 할당(linear assignment) 단계에서, 디텍션 박스와 트랙렛 박스 간 IoU가 0.2보다 작으면 매칭이 거부된다. 잃어버린 트랙렛(lost tracklet)은 30프레임까지 유지하며, 그 안에 재등장하지 않으면 제거한다. BDD100K에서는 UniTrack [68]을 Re-ID 모델로 활용한다. 에블레이션 연구에서는 MOT17에 대해 FastReID [27]를 사용해 Re-ID 특징을 추출한다.
ByteTrack의 경우, 디텍터로 YOLOX [24]를 사용하고, YOLOX-X를 백본으로 삼으며 COCO 사전 학습 모델 [36]을 초기 가중치로 적용한다. MOT17에 대해서는 MOT17, CrowdHuman, Cityperson, ETHZ를 결합해 총 80에폭(epoch) 동안 학습한다. MOT20, HiEve에 대해서는 CrowdHuman만 추가 학습 데이터로 사용한다. BDD100K의 경우 추가 학습 데이터를 사용하지 않고 50에폭만 학습한다. 입력 이미지 크기는 1440 × 800이며, 멀티 스케일 학습 시 가장 짧은 변은 576부터 1024까지 변화한다. 데이터 증강으로는 Mosaic [8]과 Mixup [81]을 적용한다. 모델은 NVIDIA Tesla V100 GPU 8장에 배치 크기(batch size) 48로 학습하며, 옵티마이저로는 $5\times 10^{-4}$ 의 weight decay와 0.9의 모멘텀을 가진 SGD를 사용한다. 초기 학습률은 $10^{-3}$ 이고, 1에폭의 워밍업(warmup)ju 후 코사인 에닐링(cosine annealing) 스케줄을 적용한다. 전체 학습 시간은 약 12시간 정도이며, [24]를 따라 단일 GPU에서 FP16 정밀도 [43]와 배치 크기 1로 FPS를 측정한다.
4.2. Ablation Studies on BYTE
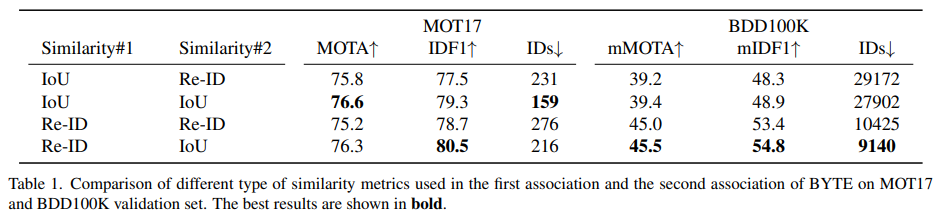
Similarity analysis.
우리는 BYTE의 첫 번째 연결(association)과 두 번째 연결에서 각각 다른 유형의 유사도를 적용해 보았다. MOT17에서는 IoU나 Re-ID 둘 다 Similarity#1으로 사용하기에 적합하다는 것을 확인할 수 있는데, IoU를 쓰면 MOTA와 ID 항목에서 더 좋은 결과를 얻고, Re-ID를 쓰면 IDF1이 더 높아진다. 반면 BDD100K에서는 첫 번째 연결에서 Re-ID가 IoU보다 훨씬 우수한 결과를 보이는데, 이는 BDD100K가 큰 카메라 움직임을 포함하고 주석이 저프레임(low frame rate) 형태라서 모션 정보를 활용하기 어렵기 때문이다. 두 번째 연결에서는 두 데이터셋 모두 낮은 점수 디텍션 박스가 심한 가림(occlusion)이나 모션 블러를 포함하는 경우가 많아 외형(Re-ID) 특징이 신뢰하기 어렵기 때문에, Similarity#2로 IoU만 사용하는 것이 중요하다. 표 1에서 확인할 수 있듯이, Similarity#2에 IoU를 적용했을 때 Re-ID를 적용한 경우 대비 약 1.0 정도 MOTA가 향상되었는데, 이는 낮은 점수 디텍션 박스의 Re-ID 특징이 신뢰하기 어렵다는 사실을 보여준다.
Comparisons with other association methods.
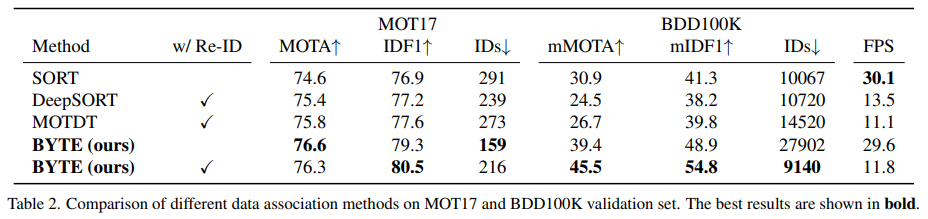
다른 연결 기법과의 비교. 우리는 BYTE를 SORT [6], DeepSORT [70], MOTDT [12] 같은 널리 쓰이는 연결 기법들과 비교하기 위해, MOT17 및 BDD100K의 검증 세트에서 평가를 수행하였다(결과는 표 2에 제시).
SORT는 Kalman 필터만 사용해 객체의 움직임을 예측한다는 점에서 우리 방식과 가장 기본적인 구조가 유사하므로, 우리의 베이스라인으로 볼 수 있다. BYTE를 적용했을 때, SORT의 MOTA는 74.6에서 76.6으로, IDF1은 76.9에서 79.3으로 향상되고, ID 전환 횟수(IDs)는 291에서 159로 줄었다. 이는 낮은 점수 디텍션 박스의 중요성을 보여주는 동시에, BYTE가 낮은 점수 박스에서도 객체를 성공적으로 복원할 수 있음을 입증한다.
DeepSORT는 장거리 연결을 강화하기 위해 추가적인 Re-ID 모델을 사용한다. 그러나 BYTE 역시 DeepSORT에 비해 추가적인 성능 향상을 보여주었다는 점이 인상적이다. 이는 간단한 Kalman 필터만으로도 디텍션 박스가 충분히 정확한 경우 장거리 연결을 수행하여 더 나은 IDF1 및 ID 전환 수를 달성할 수 있음을 시사한다. 특히 가림이 심한 상황에서는 Re-ID 특징이 취약하여 아이덴티티가 바뀔 위험이 있지만, 모션 모델은 더 안정적인 결과를 제공한다는 점도 주목할 만하다.
MOTDT는 모션 정보를 활용해 박스를 전이(propagate)한 결과와 디텍션 결과를 함께 사용해 신뢰도 낮은 디텍션을 트랙렛과 연결한다. 그러나 같은 동기(낮은 신뢰도 디텍션을 활용)에도 불구하고, MOTDT는 BYTE와 큰 격차가 있다. 그 이유로, MOTDT는 전이된 박스를 트랙렛 박스로 사용하기 때문에 추적 과정에서 위치가 조금씩 드리프트될 가능성이 있고, 반면 BYTE는 낮은 점수 디텍션 박스를 재활용하여 매칭되지 않은 트랙렛을 다시 연결하므로 트랙렛 박스의 정확도가 더 높아진다.
표 2에는 BDD100K 데이터셋에서의 결과도 함께 제시된다. BYTE는 이 데이터셋에서도 다른 연결 기법보다 훨씬 좋은 성능을 보인다. Kalman 필터는 자율주행 영상과 같이 카메라 움직임이 큰 장면에서 성능이 떨어지기 때문에, SORT, DeepSORT, MOTDT가 낮은 점수를 기록하는 주요 원인이 된다. 따라서 BDD100K에서는 Kalman 필터를 사용하지 않으며, 추가적인 Re-ID 모델을 통해 BYTE 성능을 크게 향상할 수 있었다.
Robustness to detection score threshold.
검출 점수 임계값에 대한 강인성. 디텍션 점수 임계값 $τ_{high}$ 은 멀티 객체 추적에서 매우 중요한 하이퍼파라미터이며, 신중하게 조정해야 한다. 우리는 이를 0.2부터 0.8까지 바꿔가며 BYTE와 SORT의 MOTA 및 IDF1을 비교했으며, 결과는 그림 3에 제시되어 있다. 이 실험에서 BYTE가 SORT보다 임계값 변화에 훨씬 강인함을 확인할 수 있는데, 이는 BYTE의 두 번째 연결 과정이 $τ_{high}$ 이하의 점수를 가진 객체들도 복원하여, $τ_{high}$ 값의 변화와 무관하게 거의 모든 디텍션 박스를 고려하기 때문이다.
Analysis on low score detection boxes.
낮은 점수 디텍션 박스 분석. BYTE의 효과를 입증하기 위해, 우리는 BYTE가 활용한 낮은 점수 디텍션 박스에서의 참검출(TP) 및 오검출(FP) 개수를 수집하였다. 이를 위해 MOT17 절반 학습 세트와 CrowdHuman을 학습에 사용한 뒤, MOT17 절반 검증 세트에서 평가를 진행한다. 먼저 $τ_{low}$ 부터 $τ_{high}$ 사이 점수를 가진 모든 낮은 점수 디텍션 박스를 유지하고, 이를 정답(ground truth)과 비교하여 TP와 FP를 분류한다. 이후 낮은 점수 디텍션 박스 중에서 BYTE가 실제로 추적에 사용한 결과를 확인하였다. 각 시퀀스별 결과는 그림 4에 나타나 있으며, 예를 들어 MOT17-02처럼 전체 디텍션 박스에서 FP가 매우 많은 경우에도 BYTE가 활용한 낮은 점수 박스에서는 TP가 FP보다 훨씬 많음을 볼 수 있다. 이렇게 얻어진 TP들로 인해, 표 2에서 볼 수 있듯이 MOTA가 74.6에서 76.6으로 크게 상승한다.
Applications on other trackers.

다른 추적기에의 적용. 우리는 BYTE를 9가지 최신 추적기에 적용해 보았는데, 여기에는 JDE [69], CSTrack [33], FairMOT [85], TraDes [71], QDTrack [47], CenterTrack [89], Chained-Tracker [48], TransTrack [59], MOTR [80] 등이 포함된다. 이 중 JDE, CSTrack, FairMOT, TraDes는 모션과 Re-ID 유사도를 결합하여 사용하며, QDTrack은 Re-ID만 사용한다. CenterTrack과 TraDes는 학습된 네트워크로 모션 유사도를 예측하고, Chained-Tracker는 체인(chain) 구조를 이용해 두 연속 프레임의 결과를 동시에 출력한 뒤 IoU로 같은 프레임에서 연결을 수행한다. TransTrack과 MOTR는 어텐션 메커니즘을 활용하여 프레임 간 박스를 전달(propagate)한다. 이들의 원래 결과는 표 3 각 추적기의 첫 번째 줄에 나타나며, BYTE의 효과를 평가하기 위해 우리는 두 가지 다른 방식을 설계해 각 추적기에 BYTE를 적용해 보았다.
- 첫 번째 모드는 표 3에서 각 추적기의 결과 두 번째 줄에 나타나듯, 기존 추적기들의 연결(association) 방식에 BYTE를 삽입하는 것이다. 예를 들어 FairMOT [85]의 경우, 원래 연결 과정을 끝낸 뒤에 매칭되지 않은 모든 트랙렛을 찾아, 알고리즘 1에 제시된 두 번째 연결을 통해 낮은 점수 디텍션 박스와 연결한다. 점수가 낮은 객체들의 경우 Re-ID 특징이 신뢰하기 어려우므로, 모션 예측으로 얻은 트랙렛 박스와 디텍션 박스 사이의 IoU만 유사도로 사용한다. 또한 체인 구조를 사용하는 Chained-Tracker에는 첫 번째 모드를 적용하지 않았는데, 체인 구조 특성상 구현이 어렵기 때문이다.
- 두 번째 모드는 각 추적기가 제공하는 디텍션 박스를 그대로 받아, 알고리즘 1 전체 절차를 통해 연결하는 방식이며, 이는 표 3에서 각 추적기의 결과 세 번째 줄에 나타나 있다.
두 가지 방식 모두에서 BYTE는 MOTA, IDF1, ID 전환(IDs) 등 대부분의 지표에서 안정적인 성능 향상을 가져온다. 예를 들어, CenterTrack에서는 MOTA를 1.3, IDF1을 9.8 향상시키고, Chained-Tracker는 MOTA를 1.9, IDF1을 5.8, TransTrack은 MOTA를 1.2, IDF1을 4.1 각각 끌어올렸다. 표 3의 결과들은 BYTE가 높은 범용성을 지니며, 기존 추적기에 쉽게 적용되어 성능을 개선할 수 있음을 보여준다.
4.3. Benchmark Evaluation
우리는 MOT17, MOT20, HiEve의 테스트 세트에서 private detection 프로토콜을 적용해 ByteTrack을 최신 추적기들과 비교하며, 그 결과를 표 4, 표 5, 표 6에 각각 제시한다. 모든 결과는 공식 MOT Challenge 평가 서버와 Human in Events 서버에서 직접 얻은 것이다.
MOT17.
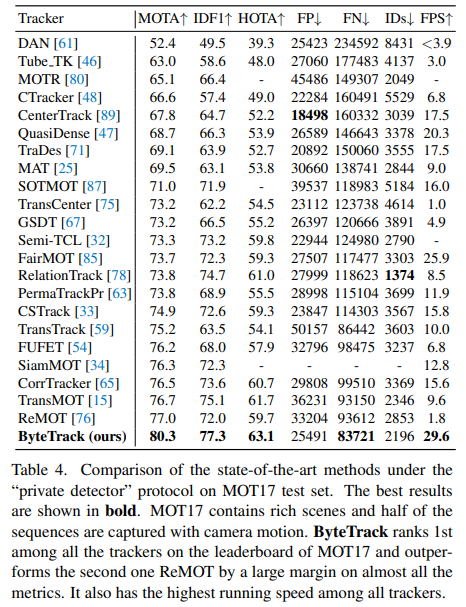
ByteTrack은 MOT17 리더보드에서 1위를 차지한다. 80.3 MOTA, 77.3 IDF1, 63.1 HOTA라는 최고 정확도뿐 아니라, 초당 30프레임(30 FPS)의 가장 빠른 실행 속도도 달성한다. 또한 2위 성능의 추적기를 크게 앞서는데(MOTA +3.3, IDF1 +5.3, HOTA +3.4), [33, 34, 65, 85] 등 다른 고성능 기법들이 훨씬 많은 학습 데이터를 사용하는 것(29K 이미지 vs. 73K 이미지)과 달리, 우리는 상대적으로 적은 데이터로도 이 성능을 얻었다. 특히 [33, 47, 59, 67, 80, 85]처럼 Re-ID 유사도나 어텐션 메커니즘을 추가로 사용하는 대신, 연결 과정에서 칼만 필터라는 가장 간단한 유사도 계산만을 적용한다는 점도 주목할 만하다. 이 모든 사실은 ByteTrack이 단순하면서도 강력한 추적기임을 보여준다.
MOT20.

MOT17에 비해 MOT20은 훨씬 더 혼잡한 상황과 가림(occlusion)이 많다. 실제로 MOT20 테스트 세트의 이미지 한 장당 보행자 수는 평균 170명에 달한다. ByteTrack은 MOT20 리더보드에서도 1위를 차지하며, 거의 모든 지표에서 다른 추적기를 큰 차이로 앞선다. 예를 들어 MOTA는 68.6에서 77.8로, IDF1은 71.4에서 75.2로 끌어올리고, ID 전환 횟수(IDs)는 4209에서 1223으로 71% 감소시켰다. 특히 아이덴티티 전환이 매우 적다는 점은, 가림이 심한 상황에서도 모든 디텍션 박스를 연결하는 전략이 매우 효과적임을 다시 한번 보여준다.
Human in Events.
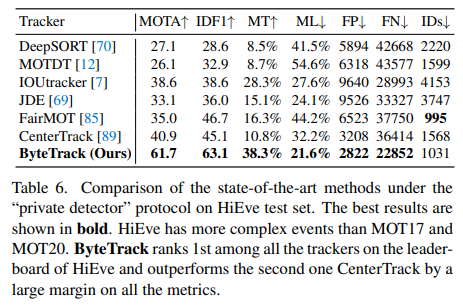
MOT17 및 MOT20과 비교해 보면, HiEve는 훨씬 더 복잡한 이벤트와 다양한 카메라 뷰를 포함한다. 우리는 CrowdHuman 데이터셋과 HiEve 학습 세트를 활용해 ByteTrack을 학습했으며, 그 결과 HiEve 리더보드에서도 1위를 차지하며 다른 최신 기법을 크게 앞선다. 예를 들어 MOTA는 40.9에서 61.3으로, IDF1은 45.1에서 62.9로 상승했다. 이러한 뛰어난 결과는 ByteTrack이 복잡한 장면에서도 강인함을 지닌다는 사실을 보여준다.
BDD100K.
BDD100K는 자율주행 환경에서 다중 카테고리 객체를 추적해야 하는 데이터셋으로, 낮은 프레임레이트와 큰 카메라 움직임 같은 난관이 있다. 우리는 UniTrack [68]에서 제공하는 간단한 ResNet-50 ImageNet 분류 모델로 Re-ID 특징을 추출하고 외형 유사도를 계산했다. 그 결과 ByteTrack은 BDD100K 리더보드에서도 1위를 기록하며, 검증 세트에서는 mMOTA를 36.6에서 45.5로, 테스트 세트에서는 35.5에서 40.1로 향상시켰다. 이는 자율주행 장면에서의 어려움도 ByteTrack이 충분히 극복할 수 있음을 보여준다.
5. Conclusion
우리는 멀티 객체 추적을 위한 간단하면서도 효과적인 데이터 연결(association) 기법인 BYTE를 제안한다. BYTE는 기존 추적기에 쉽게 적용 가능하며, 일관된 성능 향상을 달성할 수 있다. 또한 우리는 강력한 추적기인 ByteTrack을 제안하는데, 이는 MOT17 테스트 세트에서 초당 30프레임(30 FPS)으로 동작하면서 80.3 MOTA, 77.3 IDF1, 63.1 HOTA를 기록해 리더보드 전체 추적기 중 1위를 차지한다. ByteTrack은 정확한 디텍션 성능과 낮은 점수 디텍션 박스를 연결하는 전략을 통해 가림(occlusion)에 매우 강인하다. 또한 멀티 객체 추적을 개선하기 위해 디텍션 결과를 최대한 활용하는 방안을 제시한다. 우리는 ByteTrack의 높은 정확도와 빠른 속도, 그리고 단순함이 실제 응용 분야에서도 매력적인 해법이 될 것으로 기대한다.
Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, Xinggang Wang ByteTrack: Multi-Object Tracking by Associating Every Detection Box

댓글남기기