

개요
CVPRW 2020에 발표된 논문. 객체감지 관련 YOLO 논문들을 읽다보면 백본 네트워크의 이름 앞에 CSP-가 붙은 것을 보게된다. CSP 화 되었다는 말이 무슨 말인지 몰라 해당 논문을 읽어보기로 생각하였다.
Introduction을 참고하면 CSPNet을 기존의 백본인 ResNet, ResNext, DenseNet에 적용하여 계산량을 감소하면서 정확도를 올리는 것을 보인다. 이 처럼 여러 백본 네트워크에 적용하여 기존 연산의 병목현상을 감소시키고, 메모리 비용을 줄이는 등의 여러 성능 향상을 볼 수 있다.
방법론
- CSP(Cross Stage Partial) 구조는 기본적으로 많은 네트워크의 아키텍쳐 스타일을 해당 스타일로 변경 적용하여 구현할 수 있다.
- 간단하게 이해해보자면 CNN을 전제로 하는 네트워크 에서 입력 피쳐를 2부분으로 나누어 한 부분은 기존의 처리를 따르고 한 부분은 전이(Transition)을 통해 기존 부분의 출력에 통합한다.
- 기존 네트워크의 특징들을 이용하면서 과도한 그래디언트 중복 정보를 방지하며 연산량을 줄이는 효과가 있다.
- 전이(trainsitio)과 연결(concatenation)의 순서에 따라 다양한 전략을 가질 수 있고 이에 따른 성능 향상 및 연산량 감소효과가 다르다.
- 또한, EFM(Exact Fusion Model)이라는 객체감지에 적용할 수 있는 기법을 제안하며, 피라미드 구조의 특징에서 정보를 더욱 잘 집계하여 성능을 끌어올린다.
실험
- CSP 모듈의 partial $\gamma$에 따라 연산량 감소의 차이를 확인하였는데, $\gamma$ 가 낮은 부분에서 오히려 성능이 증가하는 모델을 확인
- 이미지 분류를 수행하는 여러 모델에서 대부분의 경우 CSP를 적용하였을 때 성능이 적더라도 증가하는 부분을 볼 수 있고, 확실한 연산량 감소를 발견할 수 있다.
- 객체감지 모델 비교군에서는 프레임 처리 속도에 따른 모델별로 비교를 진행한다. 규모 별로 최고 모델성능은 PANet + CSPResNeXt50, EFM + CSPPeleeNet, 400FPS 이상의 모델에서도 PRN + CSPDenseNet 조합을 사용하여 제일 빠른 모델을 달성한다.
결론
본 논문에서 제시하는 CSPNet은 기존 네트워크들과 결합하여 CNN 기반의 모델들을 경량화 시킴과 동시에 성능을 끌어올리는 방법론을 제시한다.
중복되는 그래디언트 정보 문제를 해결하여 최적화를 달성하고 다양한 특징을 결합시키는 크로스 스테이지 전략 및 Maxout 연산을 활용한 EFM 전략을 통해 메모리 대역폭을 줄여 경량 네트워크 구조를 달성한다.
이를 통해 엣지 컴퓨팅 장치와의 호환성 및 정확도, 추론 속도를 향상 시켜 경량 모델에서도 일정 성능을 달성할 수 있음을 증명했다.
번역
Abstract
신경망은 객체 감지와 같은 컴퓨터 비전 작업에서 놀라운 결과를 얻을 수 있는 최첨단 접근 방식을 가능하게 했습니다. 그러나 이러한 성공은 많은 비용이 드는 계산 자원에 크게 의존하며, 이는 저렴한 장치를 사용하는 사람들이 고급 기술을 활용하는 것을 방해합니다. 본 논문에서는 이전 작업들이 네트워크 아키텍처 관점에서 무거운 추론 계산을 요구하는 문제를 완화하기 위해 Cross Stage Partial Network (CSPNet)을 제안합니다. 우리는 이 문제의 원인을 네트워크 최적화 과정에서 발생하는 중복된 그래디언트 정보로 돌립니다. 제안된 네트워크는 네트워크 단계의 시작과 끝에서 특징 맵(feature map)을 통합하여 그래디언트의 변동성을 고려하며, 우리의 실험에서 ImageNet 데이터셋에서 동등하거나 더 우수한 정확도를 유지하면서 계산량을 20% 줄였고, MS COCO 객체 감지 데이터셋에서 AP50 기준으로 최첨단 접근 방식보다 뛰어난 성능을 보였습니다. CSPNet은 구현이 용이하며, ResNet, ResNeXt, DenseNet 기반의 아키텍처와도 충분히 대응할 수 있을 만큼 일반적입니다.
1. Introduction
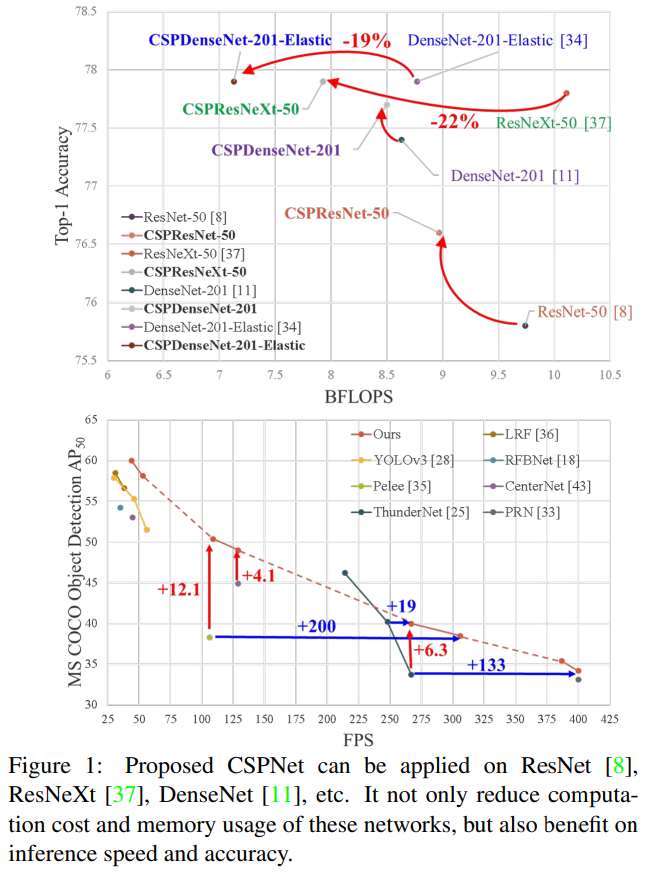
신경망은 더 깊어지거나 [8, 37, 11] 넓어질수록 [38] 특히 강력한 성능을 발휘하는 것으로 나타났습니다. 그러나 신경망 아키텍처를 확장하면 더 많은 계산을 필요로 하게 되며, 이는 대부분의 사람들에게는 객체 감지와 같은 계산 집약적인 작업을 감당하기 어렵게 만듭니다. 경량 컴퓨팅은 실제 응용 프로그램들이 일반적으로 소형 장치에서 짧은 추론 시간을 요구하기 때문에 점점 더 많은 주목을 받고 있으며, 이는 컴퓨터 비전 알고리즘에 심각한 도전 과제를 제시합니다. 일부 접근법은 모바일 CPU [10, 30, 9, 32, 41, 23] 전용으로 설계되었으나, 그들이 채택한 depth-wise convolution(깊이별 합성곱)은 산업용 IC 설계, 예를 들어 엣지 컴퓨팅 시스템을 위한 응용별 집적 회로(ASIC)와는 일반적으로 호환되지 않습니다. 이 연구에서 우리는 ResNet, ResNeXt, DenseNet과 같은 최첨단 접근법에서의 계산 부담을 조사합니다. 우리는 이러한 네트워크들이 성능을 희생하지 않고도 CPU와 모바일 GPU 모두에서 배포될 수 있도록 계산적으로 효율적인 구성 요소를 추가로 개발했습니다.
이 연구에서 우리는 Cross Stage Partial Network(CSPNet)를 소개합니다. CSPNet의 주요 설계 목적은 계산량을 줄이면서 더 풍부한 그래디언트 조합을 달성할 수 있도록 하는 것입니다. 이 목표는 기본 계층의 특징 맵을 두 부분으로 나눈 후 제안된 크로스 스테이지 계층을 통해 이를 병합함으로써 달성됩니다. 우리의 주요 개념은 그래디언트 흐름을 분할하여 서로 다른 네트워크 경로를 통해 그래디언트 흐름을 전달하는 것입니다. 이를 통해 우리는 연결 및 전이 단계를 전환함으로써 전달된 그래디언트 정보가 큰 상관관계 차이를 가질 수 있음을 확인했습니다. 또한 CSPNet은 계산량을 크게 줄이고, 그림 1에서 설명한 바와 같이 추론 속도와 정확성도 향상시킬 수 있습니다.
(1) Strengthening learning ability of a CNN
기존 CNN의 정확도는 경량화 이후 크게 저하되므로, 우리는 CNN의 학습 능력을 강화하여 경량화된 상태에서도 충분한 정확도를 유지할 수 있기를 바랍니다. 제안된 CSPNet은 ResNet, ResNeXt, DenseNet에 쉽게 적용될 수 있습니다. CSPNet을 적용한 후, 계산량은 10%에서 20%까지 감소하지만, ImageNet에서 이미지 분류 작업을 수행하는 데 있어 ResNet [8], ResNeXt [37], DenseNet [11], HarDNet [2], Elastic [34], Res2Net [5]보다 높은 정확도를 보입니다.
(2) Removing computational bottlenecks
과도한 계산 병목 현상은 추론 과정을 완료하는 데 더 많은 사이클이 필요하게 하거나, 일부 연산 유닛이 자주 유휴 상태가 될 수 있습니다. 따라서 우리는 CNN의 각 계층에서 계산량을 균등하게 분배하여 각 연산 유닛의 활용률을 효과적으로 향상시키고 불필요한 에너지 소비를 줄이기를 바랍니다. 제안된 CSPNet은 PeleeNet [35]의 계산 병목을 절반으로 줄였음을 알 수 있습니다. 또한 MS COCO [17] 데이터셋 기반 객체 감지 실험에서 제안된 모델은 YOLOv3 기반 모델에서 80%의 계산 병목을 효과적으로 줄일 수 있었습니다.
(3) Reducing memory costs
동적 랜덤 액세스 메모리(DRAM)의 웨이퍼 제조 비용은 매우 비싸며, 공간도 많이 차지합니다. 메모리 비용을 효과적으로 줄일 수 있다면, 이는 ASIC 비용을 크게 절감할 수 있습니다. 또한 작은 면적의 웨이퍼는 다양한 엣지 컴퓨팅 장치에 사용할 수 있습니다. 우리는 특징 피라미드 생성 과정에서 특징 맵을 압축하기 위해 크로스 채널 풀링 [6]을 채택했습니다. 이 방법을 통해 제안된 CSPNet과 감지기를 사용하여 PeleeNet에서 특징 피라미드를 생성할 때 메모리 사용량을 75% 절감할 수 있습니다.
CSPNet이 CNN의 학습 능력을 향상시킬 수 있기 때문에, 우리는 GTX 1080ti에서 109 fps로 50% COCO AP50을 달성하기 위해 더 작은 모델을 사용합니다. CSPNet이 상당한 양의 메모리 트래픽을 효과적으로 줄일 수 있기 때문에, 제안된 방법은 Intel Core i9-9900K에서 52 fps로 40% COCO AP50을 달성할 수 있습니다. 또한 CSPNet은 계산 병목 현상을 크게 줄일 수 있고, EFM(Exact Fusion Model)은 필요한 메모리 대역폭을 효과적으로 줄일 수 있기 때문에 제안된 방법은 Nvidia Jetson TX2에서 49 fps로 42% COCO AP50을 달성할 수 있습니다.
2. Related work
CNN architectures design.
ResNeXt [37]에서 Xie et al. 은 카디널리티(cardinality)가 너비와 깊이의 차원보다 더 효과적일 수 있음을 처음으로 입증했습니다. DenseNet [11]은 재사용 특징을 대량으로 사용하는 전략 덕분에 매개변수와 계산량을 크게 줄일 수 있습니다. 또한, 모든 이전 계층의 출력 특징을 다음 입력으로 연결하여 카디널리티를 최대화하는 방법으로 간주할 수 있습니다. SparseNet [44]은 조밀한 연결을 지수적으로 간격을 둔 연결로 조정하여 매개변수 활용을 효과적으로 개선하고 더 나은 결과를 얻을 수 있습니다. Wang et al. 은 높은 카디널리티와 희소 연결이 그래디언트 결합 개념을 통해 네트워크의 학습 능력을 개선할 수 있음을 설명하고, 부분 ResNet(PRN) [33]을 개발했습니다. CNN의 추론 속도를 향상시키기 위해, Ma et al. [23]는 따를 네 가지 지침을 소개하고 ShuffleNet-v2를 설계했습니다. Chao et al. [2]은 저메모리 트래픽 CNN인 Harmonic DenseNet (HarDNet)과 실 DRAM 트래픽을 측정한 DRAM 트래픽의 비율에 따른 근사치인 CIO(Convolutional Input/Output) 메트릭을 제안했습니다.
Real-time object detector.
가장 유명한 두 가지 실시간 객체 탐지기는 YOLOv3 [28]와 SSD [20]입니다. SSD를 기반으로 LRF [36]와 RFBNet [18]은 GPU에서 최첨단 실시간 객체 탐지 성능을 달성할 수 있습니다. 최근에는 앵커프리(anchor-free) 기반 객체 탐지기 [4, 43, 13, 14, 40]가 주류 객체 탐지 시스템이 되었습니다. 이러한 종류의 두 가지 객체 탐지기는 CenterNet [43]과 CornerNet-Lite [14]이며, 이 둘은 효율성과 효과성 면에서 매우 뛰어난 성능을 발휘합니다. CPU 또는 모바일 GPU에서 실시간 객체 탐지를 위해, SSD 기반 Pelee [35], YOLOv3 기반 PRN [33], 그리고 Light-Head RCNN [16] 기반 ThunderNet [25] 모두 객체 탐지에서 뛰어난 성능을 보였습니다.
3. Method
3.1. Cross Stage Partial Network
Cross Stage Partial Network.
주요 CNN 아키텍처인 ResNet [8], ResNeXt [37], DenseNet [11]은 출력이 보통 중간 계층의 출력의 선형 또는 비선형 조합으로 나타납니다. 따라서 k-계층 CNN의 출력을 다음과 같이 표현할 수 있습니다:
\[\begin{align*} y & = F(x_0) = x_k \\ & = H_k(x_{k-1}, H_{k-1}(x_{k-2}), H_{k-2}(x_{k-3},...,,H_1(x_0), x_0)) \end{align*}\]여기서 F는 입력 $x_0$ 에서 목표 y로의 매핑 함수이며, 전체 CNN의 모델이기도 합니다. $H_k$ 는 CNN의 k번째 계층의 연산 함수입니다. 보통 $H_k$ 는 일련의 합성곱 계층과 비선형 활성화 함수로 구성됩니다. ResNet과 DenseNet을 예로 들면, 각각 식 (2)와 식 (3)으로 표현할 수 있습니다:
\[\begin{align*} x_k & = R_k(x_{k-1}) + x_{k-1} \\ & = R_k(x_{k-1}) + R_{k-1}(x_{k-2}) +...+...R_1(x_0)+x_0 \end{align*}\] \[\begin{align*} x_k & = [D_k(x_{k-1}), x_{k-1}] \\ & = [D_k(x_{k-1}), D_{k-1}(x_{k-2}),...,D_1(x_0),x_0] \end{align*}\]위의 두 식에서 R과 D는 각각 잔차 계층과 밀집 계층의 연산자를 나타내며, 이 연산자들은 종종 2~3개의 합성곱 계층으로 구성됩니다.
위의 두 식에서 잔차 계층이든 밀집 계층이든 상관없이, 각 합성곱 계층의 입력은 이전 모든 계층의 출력을 받습니다. 이러한 상황에서는 그래디언트 경로의 길이가 최소화되어 역전파 과정에서 그래디언트 흐름 전파가 더 효율적으로 이루어집니다. 하지만 이러한 아키텍처 설계는 $k$번째 계층이 그래디언트를 $k−1,k−2,…,1$ 계층에 모두 전달하고 이를 사용하여 가중치를 업데이트하게 되는데, 이는 중복된 학습 정보를 초래할 수 있습니다.
최근 몇몇 연구에서는 학습 능력과 매개변수 활용을 개선하기 위해 선별된 $H_k(.)$ 의 입력을 사용하는 방법을 시도했습니다. 예를 들어, SparseNet [44]은 지수 간격 연결을 사용하여 $H_k$가 $H_{k−1},H_{k−2},H_{k−4},…,H_{k−2^i}$ 에만 직접적으로 연결되도록 했습니다. ShuffleNetV2 [23]은 분할 채널을 사용하여 $H_k$ 가 $H_{k−1}$ 채널의 절반에만 직접적으로 연결되도록 하며, 그 식은 다음과 같이 표현될 수 있습니다: $S([H_k(x_{k−1}[1:c/2]),x_{k−1}[(c/2+1):c]])$. 여기서 S는 셔플 연산을 나타내며, $x_{k−1}[1:c/2]$ 는 $x_{k−1}$ 의 처음부터 $c/2$ 까지의 채널을 나타냅니다. PyramidNet [7]과 PRN [33]의 경우, 불균일한 수의 채널로 특징 맵을 사용하여 ResNet을 구축하고 그래디언트 션팅 효과를 얻습니다.
최첨단 방법들은 각 계층에서 $H_i$ 함수를 최적화하는 데 중점을 두고 있으며, 우리는 CSPNet이 $F$ 함수를 다음과 같이 직접 최적화한다고 제안합니다:
여기서 $x_0$ 는 채널을 따라 두 부분으로 분할되며, $x_0 =[x_{0’},x_{0’’}]$로 표현할 수 있습니다. $T$는 $H_1,H_2,…,H_k$ 의 그래디언트 흐름을 절단하는 데 사용되는 전이 함수이며, $M$ 은 두 분할된 부분을 혼합하는 데 사용되는 전이 함수입니다. 다음으로, CSPNet을 DenseNet에 통합하는 예를 보여주고 CNN에서 중복된 학습 정보 문제를 해결하는 방법을 설명하겠습니다.
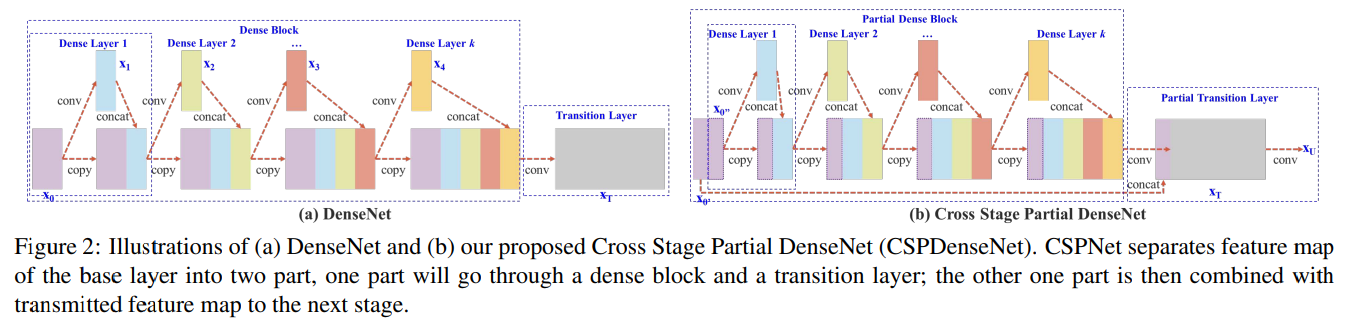
DenseNet.
그림 2(a)는 Huang et al. [11]에 의해 제안된 DenseNet의 한 단계의 세부 구조를 보여줍니다. DenseNet의 각 단계는 밀집 블록과 전이 계층을 포함하며, 각 밀집 블록은 $k$개의 밀집 계층으로 구성됩니다. $i$번째 밀집 계층의 출력은 $i$번째 밀집 계층의 입력과 연결되며, 연결된 결과는 $(i+1)$번째 밀집 계층의 입력이 됩니다. 위에서 설명한 메커니즘을 나타내는 방정식은 다음과 같이 표현됩니다:
\[\begin{align*} x_1 = w_1 &* x_0 \\ x_2 = w_2 &* [x_0, x_1] \\ \vdots \\ x_k = w_k &* [x_0,x_1,...,x_{k-1}] \end{align*}\]여기서 $*$ 은 합성곱 연산자를 나타내며, $[x_0, x_1, …]$ 은 $x_0, x_1,…$ 을 연결하는 것을 의미합니다. $w_i$ 와 $x_i$ 는 각각 $i$번째 밀집 계층의 가중치와 출력을 나타냅니다. 가중치를 업데이트하기 위해 역전파를 사용할 경우, 가중치 업데이트의 방정식은 다음과 같이 작성될 수 있습니다:
\[\begin{align*} w'_1=f_1(w_1, &\{g_0\}) \\ w'_2=f_2(w_2, &\{g_0,g_1\}) \\ \vdots \\ w'_k=f_k(w_k, &\{g_0,g_1,...,g_{k-1}\}) \end{align*}\]여기서 $f_i$ 는 i번째 밀집 계층의 가중치 업데이트 함수이고, $g_i$ 는 $i$번째 밀집 계층으로 전달된 그래디언트를 나타냅니다. 우리는 다양한 밀집 계층의 가중치를 업데이트하는 데 많은 양의 그래디언트 정보가 재사용된다는 것을 알 수 있습니다. 이는 다양한 밀집 계층이 반복적으로 복사된 그래디언트 정보를 학습하게 됩니다.
Cross Stage Partial DenseNet.
제안된 CSPDenseNet의 한 단계의 아키텍처는 그림 2(b)에 나타나 있습니다. CSPDenseNet의 한 단계는 부분 밀집 블록과 부분 전이 계층으로 구성됩니다. 부분 밀집 블록에서는, 기본 계층의 특징 맵이 두 부분으로 분리되며, 채널을 통해 $x_0=[x_{0’},x_{0’’}]$ 로 나뉩니다. $x_{0’}$ 과 $x_{0’’}$ 사이에서 전자는 단계의 끝에 직접 연결되며, 후자는 밀집 블록을 거치게 됩니다. 부분 전이 계층에 포함된 모든 단계는 다음과 같습니다: 첫째, 밀집 계층의 출력인 $[x_{0’’},x_1,…,x_k]$ 는 전이 계층을 거칩니다. 둘째, 이 전이 계층의 출력인 $x_T$ 는 $x_{0’}$ 과 연결되어 또 다른 전이 계층을 거쳐 최종 출력 $x_U$ 를 생성합니다. CSPDenseNet의 피드 포워드 단계와 가중치 업데이트 방정식은 각각 식 7과 8에 나타나 있습니다.
\[\begin{align*} x_k=w_k&*[x_{0''},x_1,...,x_k{k-1}] \\ x_T=w_T&*[x_{0''},x_1,...,x_k] \\ x_U=w_U&*[x_{0'},x_T] \end{align*}\] \[\begin{align*} w'_k=f_k(w_k,&\{g_{0''},g_1,...,g_{k-1}\}) \\ w'_T=f_T(w_T,&\{g_{0''},g_1,...,g_k\}) \\ w'_U=f_U(w_U,&\{g_{0'},g_T\}) \end{align*}\]우리는 밀집 계층에서 오는 그래디언트들이 별도로 통합된다는 것을 볼 수 있습니다. 반면, 밀집 계층을 거치지 않은 특징 맵 $x’_0$ 도 별도로 통합됩니다. 가중치 업데이트에 사용되는 그래디언트는 두 측 모두 밀집 계층에 속하는 중복된 그래디언트 정보를 포함하지 않습니다.
전체적으로 제안된 CSPDenseNet은 DenseNet의 특징 재사용 특성을 유지하면서도, 그래디언트 흐름을 단절하여 과도한 중복 그래디언트 정보를 방지합니다. 이 아이디어는 계층적 특징 융합 전략을 설계하고 부분 전이 계층에 적용하여 실현되었습니다.
Partial Dense Block.
부분 밀집 블록을 설계하는 장점은 다음과 같습니다: 1.) 그래디언트 경로 증가: 분할 및 병합 전략을 통해 그래디언트 경로의 수를 두 배로 늘릴 수 있습니다. 크로스 스테이지 전략 덕분에 명시적인 특징 맵 복사로 인한 단점을 완화할 수 있습니다; 2.) 각 계층의 계산 균형: 일반적으로 DenseNet의 기본 계층의 채널 수는 성장률보다 훨씬 큽니다. 부분 밀집 블록의 밀집 계층에서 기본 계층 채널이 원래 수의 절반만 차지하기 때문에, 이는 거의 절반의 계산 병목 문제를 효과적으로 해결할 수 있습니다; 3.) 메모리 트래픽 감소: DenseNet의 밀집 블록에서 기본 특징 맵 크기가 $w×h×c$, 성장률이 $d$, 그리고 밀집 계층이 총 $m$개라고 가정합니다. 이때 해당 밀집 블록의 CIO(Convolutional Input/Output)는 $(c×m)+((m^2+m)×d)/2$ 이며, 부분 밀집 블록의 CIO는 $((c×m)+(m^2+m)×d)/2$ 입니다. $m$과 $d$는 일반적으로 $c$ 보다 훨씬 작기 때문에, 부분 밀집 블록은 네트워크의 메모리 트래픽의 최대 절반을 절약할 수 있습니다.
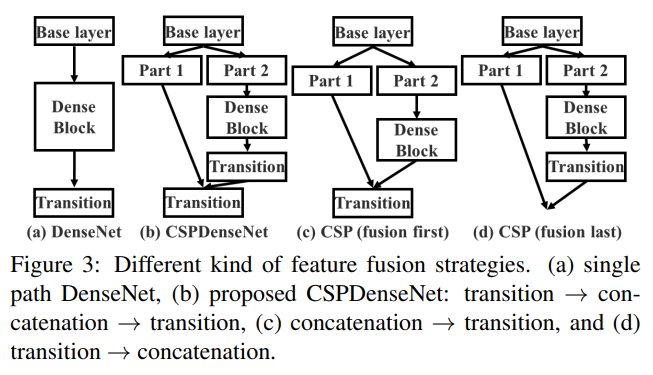
Partial Transition Layer
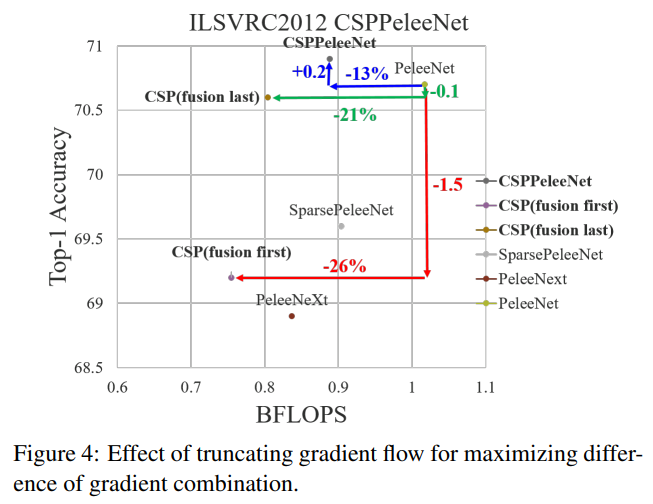
부분 전이 계층을 설계하는 목적은 그래디언트 결합의 차이를 극대화하는 것입니다. 부분 전이 계층은 계층적 특징 융합 메커니즘으로, 그래디언트 흐름을 절단하여 서로 다른 계층이 중복된 그래디언트 정보를 학습하는 것을 방지하는 전략을 사용합니다. 여기서 우리는 CSPDenseNet의 두 가지 변형을 설계하여 이러한 그래디언트 흐름 절단이 네트워크의 학습 능력에 어떻게 영향을 미치는지 보여줍니다. 그림 3(c)와 그림 3(d)는 두 가지 다른 융합 전략을 보여줍니다. CSP (fusion first)는 두 부분에서 생성된 특징 맵을 연결한 후 전이 작업을 수행하는 것을 의미합니다. 이 전략이 채택되면 많은 양의 그래디언트 정보가 재사용됩니다. 반면에 CSP (fusion last) 전략에서는 밀집 블록의 출력이 전이 계층을 거친 후 1번 부분에서 나온 특징 맵과 연결됩니다. CSP (fusion last) 전략을 선택하면 그래디언트 흐름이 절단되어 그래디언트 정보가 재사용되지 않습니다. 그림 3에 나와 있는 네 가지 아키텍처를 사용하여 이미지 분류를 수행하면, 그에 따른 결과가 그림 4에 나타납니다. CSP (fusion last) 전략을 사용하면 계산 비용이 크게 감소하지만, Top-1 Accuracy는 단지 0.1%만 감소합니다. 반면 CSP (fusion first) 전략은 계산 비용을 크게 줄이는 데 도움이 되지만 Top-1 Accuracy는 1.5%나 크게 떨어집니다. 우리는 각 단계에서 분할 및 병합 전략을 사용하여 정보 통합 과정에서 중복 가능성을 효과적으로 줄일 수 있습니다. 그림 4에서 볼 수 있듯이, 중복된 그래디언트 정보를 효과적으로 줄이면 네트워크의 학습 능력이 크게 향상될 수 있습니다.
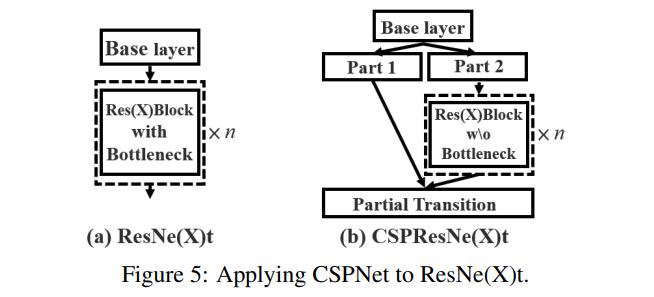
Apply CSPNet to Other Architectures.
CSPNet은 ResNet과 ResNeXt에도 적용할 수 있으며, 해당 아키텍처는 그림 5에 나와 있습니다. 특징 채널의 절반만 Res(X) 블록을 거치기 때문에 더 이상 병목 계층을 도입할 필요가 없습니다. 이것은 FLOPs(부동 소수점 연산)가 고정된 상태에서 메모리 접근 비용(MAC)의 이론적인 하한을 만듭니다.
3.2. Exact Fusion Model
Looking Exactly to predict perfectly
우리는 각 앵커에 적합한 수용 필드를 포착하는 EFM을 제안하며, 이는 단일 단계 객체 탐지기의 정확성을 향상시킵니다. 분할 작업의 경우, 픽셀 수준의 라벨은 일반적으로 전역 정보를 포함하지 않으므로, 더 나은 정보 검색을 위해 더 큰 패치를 고려하는 것이 바람직합니다 [21]. 그러나 이미지 분류 및 객체 탐지와 같은 작업의 경우, 이미지 수준 및 경계 상자 수준의 라벨에서 중요한 정보가 흐릿해질 수 있습니다. Li et al. [15]은 CNN이 이미지 수준의 라벨에서 학습할 때 종종 산만해질 수 있음을 발견했으며, 이로 인해 2단계 객체 탐지기가 단일 단계 객체 탐지기보다 성능이 우수한 주요 이유 중 하나라고 결론지었습니다.
Aggregate Feature Pyramid.
제안된 EFM은 초기 특징 피라미드를 더 잘 집합할 수 있습니다. EFM은 YOLOv3 [28]에 기반을 두며, 각 실제 객체마다 정확히 하나의 경계 상자를 할당합니다. 각 실제 경계 상자는 임계값 IoU를 초과하는 하나의 앵커 상자에 해당합니다. 앵커 상자의 크기가 그리드 셀의 수용 필드와 동일하다면, s번째 스케일의 그리드 셀에 대한 해당 경계 상자는 $(s-1)$번째 스케일에 의해 하한으로, $(s+1)$번째 스케일에 의해 상한으로 제한됩니다. 따라서 EFM은 세 가지 스케일에서 특징을 집합합니다.
Balance Computation.
특징 피라미드에서 결합된 특징 맵은 방대하므로 많은 양의 메모리와 계산 비용을 초래합니다. 이 문제를 완화하기 위해 우리는 Maxout 기술을 사용하여 특징 맵을 압축합니다.
4. Experiments
우리는 제안된 CSPNet을 검증하기 위해 ImageNet 이미지 분류 데이터셋 [3]을 사용합니다. 또한, 제안된 CSPNet과 EFM을 검증하기 위해 MS COCO 객체 탐지 데이터셋 [17]을 사용합니다.
4.1. Implementation Details
ImageNet.
ImageNet 이미지 분류 실험에서 훈련 단계, 학습률 스케줄, 옵티마이저, 데이터 증강 등 모든 하이퍼 파라미터는 Redmon et al. [28]의 설정을 따릅니다. ResNet 기반 모델과 ResNeXt 기반 모델에 대해 우리는 8,000,000번의 훈련 단계를 설정했습니다. DenseNet 기반 모델의 경우 1,600,000번의 훈련 단계를 설정했습니다. 초기 학습률을 0.1로 설정하고 다항식 감소 학습률 스케줄링 전략을 채택했습니다. 모멘텀과 가중치 감쇠는 각각 0.9와 0.005로 설정되었습니다. 모든 아키텍처는 단일 GPU를 사용하여 배치 크기 128로 보편적으로 훈련됩니다. 마지막으로, 우리는 ILSVRC 2012의 검증 세트를 사용하여 우리의 방법을 검증했습니다.
MS COCO.
MS COCO 객체 탐지 실험에서 모든 하이퍼 파라미터는 Redmon et al. [28]의 설정을 따릅니다. 우리는 총 500,000번의 훈련 단계를 진행했습니다. 우리는 계단식 감소 학습률 스케줄링 전략을 채택하고, 400,000단계와 450,000단계에서 각각 0.1의 계수로 곱했습니다. 모멘텀과 가중치 감쇠는 각각 0.9와 0.0005로 설정되었습니다. 모든 아키텍처는 단일 GPU를 사용하여 배치 크기 64로 다중 스케일 훈련을 수행합니다. 마지막으로, COCO test-dev 세트를 사용하여 우리의 방법을 검증했습니다.
4.2. Ablation Experiments
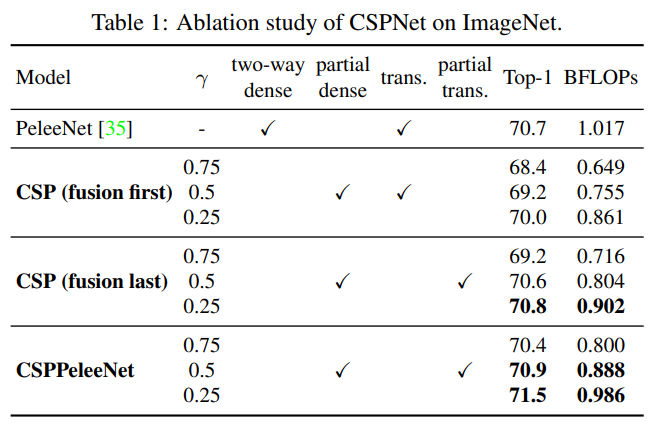
Ablation study of CSPNet on ImageNet.
CSPNet에 대해 수행한 소거 실험에서 우리는 PeleeNet [35]을 기준으로 사용하였으며, ImageNet을 사용하여 CSPNet의 성능을 검증했습니다. 우리는 절단 실험을 위해 서로 다른 부분 비율 $γ$와 특징 융합 전략을 사용했습니다. 표 1은 CSPNet에 대한 절단 실험 결과를 보여줍니다. CSP (fusion first)와 CSP (fusion last)에 대해서는 부분 전환의 이점을 검증하기 위해 제안되었습니다.
CSP (fusion last)의 실험 결과에서, 중복된 정보 학습을 줄이기 위해 설계된 부분 전이 계층은 매우 우수한 성능을 달성할 수 있었습니다. 예를 들어, 계산량이 21% 줄어들 때, 정확도는 단 0.1%만 감소했습니다. 주목할 점은 $γ=0.25$ 일 때, 계산량은 11% 감소하지만, 정확도는 0.1% 증가했습니다. 기준 PeleeNet과 비교했을 때, 제안된 CSPPeleeNet은 최고의 성능을 달성했으며, 13%의 계산량을 줄이면서도 정확도를 0.2% 향상시킬 수 있었습니다. 부분 비율을 $γ=0.25$로 조정하면 정확도를 0.8% 향상시키고 계산량을 3% 줄일 수 있습니다.
Ablation study of EFM on MS COCO.
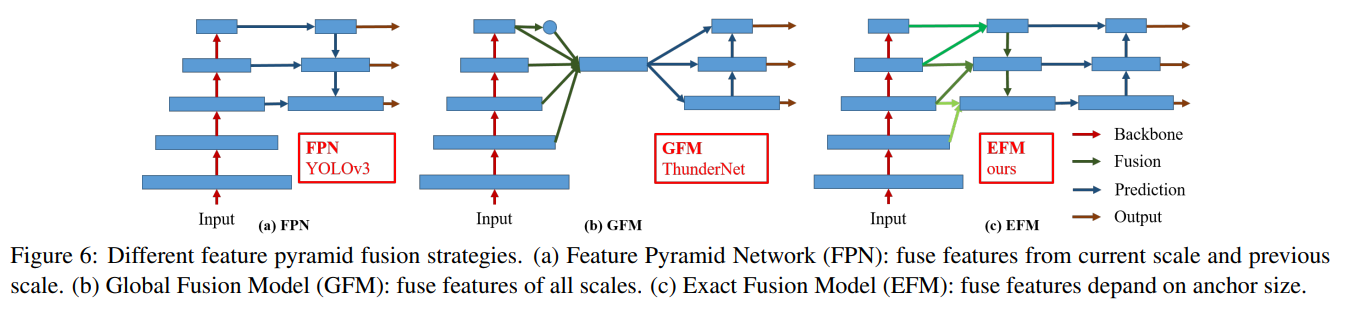
다음으로, 우리는 EFM의 절단 실험을 수행하고 그림 6에 나타난 세 가지 다른 특징 융합 전략을 비교합니다. 우리는 PRN [33]과 ThunderNet [25]을 선택하여 비교합니다. PRN과 ThunderNet은 각각 FPN과 GFM 아키텍처인 Context Enhancement Module(CEM) 및 Spatial Attention Module(SAM)을 사용합니다. 또한 우리는 제안된 EFM과 비교하기 위해 GFM을 설계합니다. 또한, GIoU [29], SPP 및 SAM도 EFM에 적용됩니다. 표 2에 나열된 모든 실험 결과는 CSPPeleeNet을 백본으로 사용합니다.
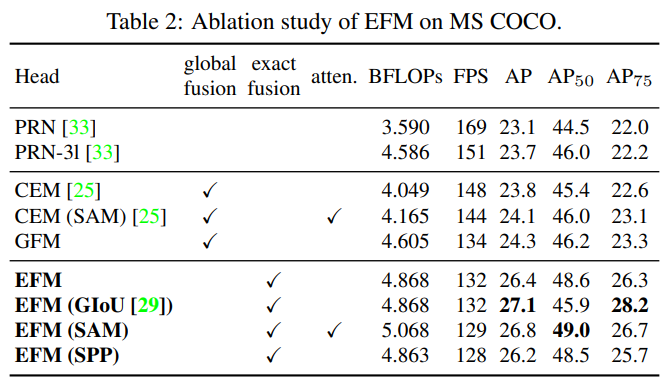
실험 결과에 따르면, 제안된 EFM은 GFM보다 2 fps 느리지만 $AP_{50}$ 는 2.4% 향상되었습니다. GIoU는 AP를 0.7% 향상시킬 수 있지만, $AP_{50}$ 는 2.7% 감소합니다. 엣지 컴퓨팅의 경우, 중요한 것은 객체의 수와 위치입니다. 따라서 우리는 이후 모델에서 GIoU 학습을 사용하지 않을 것입니다. SAM은 SPP보다 더 나은 프레임 속도와 AP를 제공할 수 있으므로 최종 아키텍처로 EFM(SAM)을 사용합니다.
4.3. ImageNet Image Classification
우리는 CSPNet을 ResNet-10 [8], ResNeXt-50 [37], DenseNet-201 [11], PeleeNet [35], 및 DenseNet-201-Elastic [34]에 적용하고 최신 기법들과 비교합니다. 실험 결과는 표 3에 나와 있습니다.
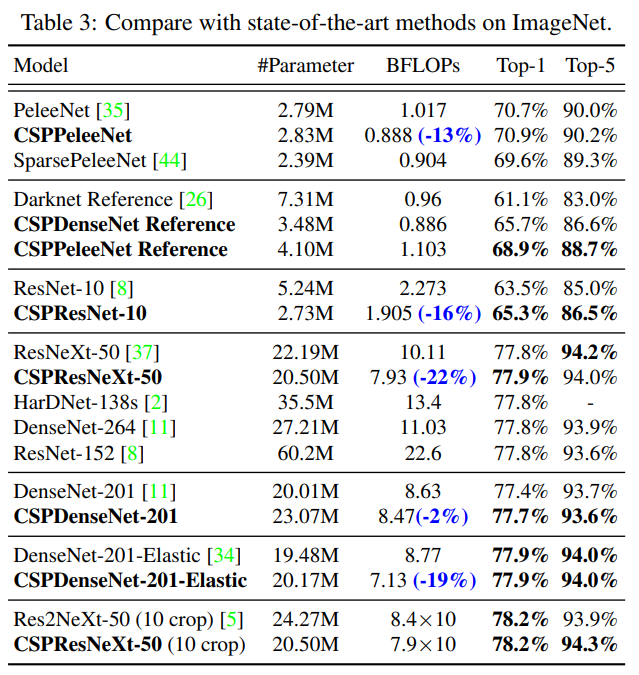
실험 결과에 따르면, CSPNet 개념이 도입되면 어떤 아키텍처에서도 계산 부하가 줄어들고 정확도는 유지되거나 향상되며, 특히 경량 모델의 성능 향상에 유용하다는 것이 확인되었습니다. 예를 들어, ResNet-10과 비교했을 때, CSPResNet-10은 정확도를 1.8% 향상시킬 수 있습니다. PeleeNet과 DenseNet-201-Elastic의 경우, CSPPeleeNet 및 CSPDenseNet-201-Elastic은 각각 13% 및 19%의 계산량을 줄이고, 정확도를 약간 향상시키거나 유지할 수 있습니다. ResNeXt-50의 경우, CSPResNeXt-50은 22%의 계산량을 줄이고 top-1 정확도를 77.9%로 향상시킬 수 있습니다.
제안된 CSPResNeXt-50은 ResNet-152 [8], DenseNet-264 [11], HarDNet-138s [2]와 비교하여 #파라미터, BFLOPs, top-1 정확도에 관계없이 최고의 결과를 달성했습니다. 10-crop 테스트에서 CSPResNeXt-50은 Res2NeXt-50 [5]보다 우수한 성능을 보여주었습니다.
4.4. MS COCO Object Detection
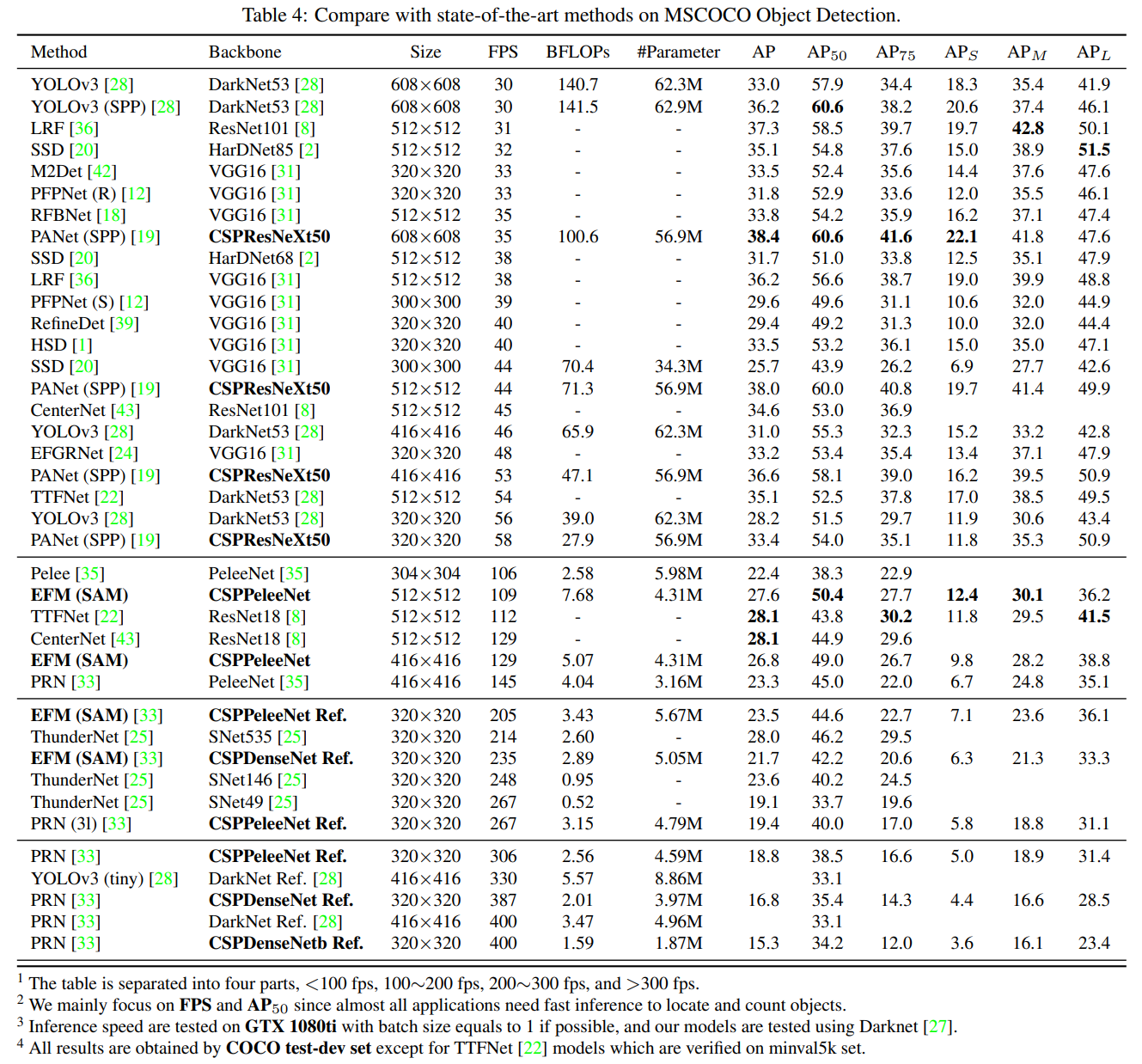
객체 탐지 작업에서 우리는 세 가지 목표 시나리오를 설정했습니다: (1) GPU에서 실시간 성능: CSPResNeXt50과 PANet (SPP) [19]를 사용, (2) 모바일 GPU에서 실시간 성능: 제안된 EFM(SAM)을 사용하는 CSPDenseNet 기반 모델을 사용, (3) CPU에서 실시간 성능: PRN [33]과 CSPDenseNet 기반 모델을 사용합니다. 위 모델들과 최신 기법들 간의 비교는 표 4에 나와 있습니다. CPU와 모바일 GPU의 추론 속도에 대한 분석은 다음 절에서 자세히 다룹니다.
30~100 fps 속도로 실행되는 객체 탐지기와 비교했을 때, CSPResNeXt50과 PANet(SPP)은 $AP, AP_{50}, AP_{75}$ 에서 최고의 성능을 달성합니다. 각각 38.4%, 60.6%, 41.6%의 탐지율을 기록했습니다. 입력 이미지 크기 512×512에서 LRF [36]과 비교했을 때, CSPResNeXt50과 PANet(SPP)은 LRF를 사용하는 ResNet101보다 $AP$는 0.7%, AP50 은 1.5%, AP75 는 1.1% 더 우수합니다. 100~200 fps 속도로 실행되는 객체 탐지기와 비교했을 때, CSPPeleeNet과 EFM(SAM)은 Pelee [35] 및 CenterNet [43]과 동일한 속도에서 AP50을 각각 12.1%와 4.1% 향상시켰습니다.
ThunderNet [25], YOLOv3-tiny [28], YOLOv3-tiny-PRN [33]과 같은 매우 빠른 객체 탐지기와 비교했을 때, 제안된 CSPDenseNet Reference는 PRN을 사용하여 가장 빠릅니다. 프레임 속도는 400 fps에 도달하며, SNet49을 사용하는 ThunderNet보다 133 fps 더 빠릅니다. 게다가 AP50은 0.5% 더 높습니다. ThunderNet146과 비교했을 때, CSPPeleeNet Reference는 PRN(31)을 사용하여 프레임 속도를 19 fps 향상시키면서도 AP50 수준을 동일하게 유지합니다.
4.5. Analysis
Computational Bottleneck.
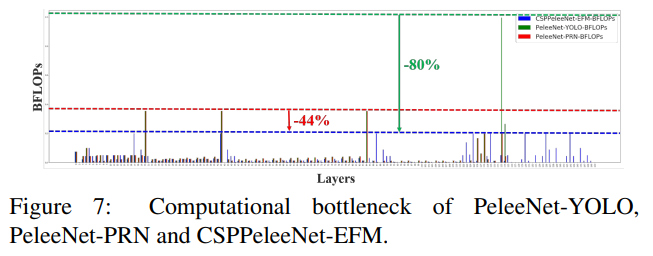
그림 7은 PeleeNet-YOLO, PeleeNet-PRN, 및 제안된 CSPPeleeNet-EFM의 각 레이어의 BLOPs를 보여줍니다. PeleeNet-YOLO의 계산 병목 현상은 헤드가 특징 피라미드를 통합할 때 발생하고, PeleeNet-PRN의 계산 병목 현상은 PeleeNet 백본의 전이 계층에서 발생합니다. 제안된 CSPPeleeNet-EFM은 전체 계산 병목 현상을 균형 있게 조절하여, PeleeNet 백본의 계산 병목 현상을 44% 줄이고 PeleeNet-YOLO의 계산 병목을 80% 줄일 수 있습니다. 따라서, 제안된 CSPNet은 하드웨어의 활용률을 높일 수 있음을 알 수 있습니다.
Memory Traffic.
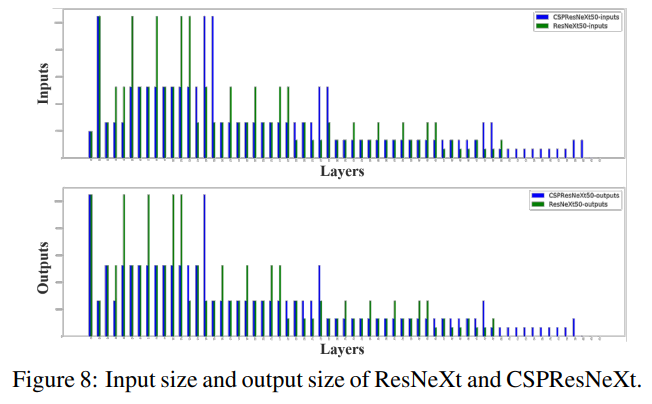
그림 8은 ResNeXt50과 제안된 CSPResNeXt50의 각 레이어 크기를 보여줍니다. 제안된 CSPResNeXt의 CIO(32.6M)는 기존 ResNeXt50(34.4M)보다 작습니다. 또한, CSPResNeXt50은 ResXBlock에서 병목 계층을 제거하고 입력 채널과 출력 채널의 수를 동일하게 유지합니다. Ma 등 [23]의 연구에 따르면, 이 방식은 FLOPs가 고정될 때 가장 낮은 MAC과 가장 효율적인 계산을 제공합니다. 낮은 CIO와 FLOPs 덕분에 CSPResNeXt50은 계산 측면에서 기존 ResNeXt50보다 22% 더 우수한 성능을 발휘할 수 있습니다.
Inference Rate.
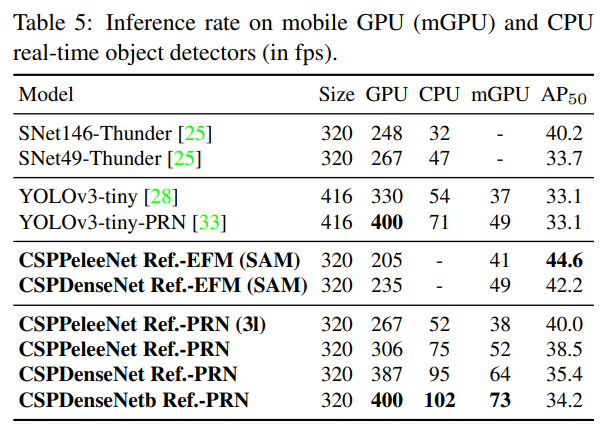
우리는 제안된 방법들이 모바일 GPU나 CPU에서 실시간 탐지기로 배포될 수 있는지를 추가로 평가했습니다. 실험은 NVIDIA Jetson TX2와 Intel Core i9-9900K를 기반으로 하였습니다. CPU에서의 추론 속도는 OpenCV DNN 모듈로 평가되었습니다. 공정한 비교를 위해 모델 압축이나 양자화를 채택하지 않았습니다. 결과는 표 5에 나와 있습니다.
CPU에서 실행된 추론 속도를 비교하면, CSPDenseNetb Ref.-PRN은 SNet49-ThunderNet보다 AP50이 더 높으며, 프레임 속도 측면에서 SNet49-ThunderNet보다 55 fps 더 우수합니다. 반면에, CSPPeleeNet Ref.-PRN(3l)은 SNet146-ThunderNet과 동일한 정확도 수준에 도달하지만 CPU에서 프레임 속도를 20 fps 크게 향상시켰습니다.
모바일 GPU에서 실행된 추론 속도를 비교하면, 제안된 EFM은 특징 피라미드를 생성할 때 메모리 요구 사항을 크게 줄일 수 있으며, 메모리 대역폭이 제한된 모바일 환경에서 작동하는 데 매우 유익합니다. 예를 들어, CSPPeleeNet Ref.-EFM(SAM)은 YOLOv3-tiny보다 더 높은 프레임 속도를 가질 수 있으며, AP50은 YOLOv3-tiny보다 11.5% 더 높습니다. 같은 CSPPeleeNet Ref. 백본에서 EFM(SAM)은 GTX 1080ti에서 PRN(3l)보다 62 fps 느리지만, Jetson TX2에서 41 fps를 기록하며 PRN(3l)보다 3 fps 빠르고 AP50은 4.6% 증가합니다.
5. Conclusion
우리는 ResNet, ResNeXT, DenseNet과 같은 최신 기법을 모바일 GPU나 CPU에서도 경량화할 수 있게 하는 CSPNet을 제안했습니다. 주요 기여 중 하나는 비효율적인 최적화와 높은 추론 계산 비용을 초래하는 중복된 그래디언트 정보 문제를 인식한 것입니다. 우리는 학습된 특징의 다양성을 향상시키기 위해 크로스 스테이지 특징 결합 전략과 그래디언트 흐름 절단을 제안했습니다. 또한, 우리는 Maxout 연산을 사용하여 특징 피라미드에서 생성된 특징 맵을 압축하는 EFM을 제안했으며, 이를 통해 요구되는 메모리 대역폭을 크게 줄이고 엣지 컴퓨팅 장치와 호환될 수 있을 만큼 효율적인 추론을 가능하게 했습니다. 실험적으로, 우리는 제안된 CSPNet이 EFM과 함께 모바일 GPU와 CPU에서 실시간 객체 탐지 작업에 있어 정확도와 추론 속도 면에서 경쟁자들을 크게 능가한다는 것을 보여주었습니다.
Chien-Yao Wang, Hong-Yuan Mark Liao, I-Hau Yeh, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh CSPNet: A New Backbone that can Enhance Learning Capability of CNN

댓글남기기