

개요
CVPR에 2015년에 발표된 Efficient Object Localization Using Convolutional Networks 논문의 얕은 리뷰
기존에 DPM, SVM 등 신체의 관절을 추정하기 위한 여러 방법들이 제안되었고 컨볼루션 네트워크를 활용한 자세 추정 테스크의 발전에 중점을 두어 새로운 아키텍쳐를 제안한다. 풀링이 가지는 과적합을 방지 및 계산 복잡성의 감소와 위치 정확도의 트레이드 오프를 잘 조절하고 활용하여 높은 자세 추정 정확도를 유지하면서도 계산 효율성을 제공하는 방법을 제안한다. 해당 논문이 주장하는 모델 아키텍쳐의 근간은 앞서 리뷰했던 Joint training of a convolutional network and a graphical model for human pose estimation 논문에 있다고 말한다.
Coarse Heat-Map Regression Model
- 기존 [21]논문(Joint training…) 에 소개된 아키텍쳐를 기본으로 보완한다.
- 기존 아키텍쳐에 드롭아웃 레이어를 추가함으로써 모델을 개선하는데 일반적으로 추가하는 것은 공간적 상관성을 보이는 특징에 따라 과적합 개선에 도움이 안된다고 한다.
- 그래서 새로운 방법론인 Spatial Dropout을 제안한다. 너비와 높이 * N개의 채널이 있는 컨볼루션 피쳐맵에 대해 아예 특정 채널을 통채로 드롭아웃 시킨다.
- 이러한 방법이 Train set 크기가 작은 FLIC 데이터 셋에서의 성능 향상을 발견했다.
- 해당 아키텍쳐의 학습과 관련하여 히트맵 간의 MSE를 최소화 하는데 히트맵은 실제 관절 위치 (x, y)에 분산 1.5px로 설정한 2D 가우시안이다.
- 학습을 위해 랜덤 로테이션, 랜덤 스케일, 좌우 반전 등을 사용하며 이는 [21] 논문의 방식과 동일하다.
Fine Heat-Map Regression Model
- 풀링으로 인해 손실된 정확도를 회복하기 위한 연구: 기존의 컨볼루션 피쳐의 재사용
- 기본적인 구조는 히트맵 모델이 대략적인 관절의 (x,y)를 추출하고 이를 통해 세부모델에 넣기 위한 입력 자르기 등 샘플링 진행. 이를 세부 히트맵 모델을 통해 출력으로 오프셋 ($\Delta{x}, \Delta{y}$)를 생성하여 해당 값을 대략적인 관절 위치에 보정하여 최종 관절 위치를 생성하는 구조.
- 기본적으로 세부 히트맵 모델의 모듈의 가중치와 바이어스는 공유된다. 기존에는 각 관절에 대한 샘플 위치가 다르니까 분리되어야 하지만 여기서는 파라미터 공유를 하여 연산량을 줄이고 과적합을 방지한다.
- 해당 모델의 손실 함수는 각 관절(MPII경우 14개)의 개수만큼의 예측 히트맵과 정답 히트맵의 차이를 통해 손실함수를 설계하고 이를 앞선 전체 히트맵 모델의 손실과 비율을 조정하여 더함으로써 전체 손실함수를 설계한다.
- 이상적인 것은 히트맵을 통해 argmax 함수로 (x,y)를 추출하여 좌표간의 차이를 줄이는 것이지만 argmax 함수는 미분이 불가능하여 활용하기에 어렵다.
Expreiments
- FLIC 데이터는 PCK 메트릭을 통해, MPII 데이터는 PCKh 메트릭을 통해 성능을 측정한다.
- 네트워크 내에서 풀링을 많이 사용할 수록 관절 위치에 대한 예측 정확도가 떨어지는 것을 볼 수 있다.
- 실제 ground truth가 애매한 경우에는 해당 모델 네트워크가 좋은 성능을 낼 것이라고 기대하지 않는다. 실제로 여러 명을 대상으로 테스트 결과 각자가 라벨링한 위치의 결과가 다 달랐고 이 결과를 보면 애매한 이미지에선 성능이 좋지 않음을 시사한다.
- 해당 논문의 SpatialDropout은 적용 여부에 따라 정규화 효과와 강력한 히트맵에 대한 이상값 감소 효과를 가져와 성능 향상에 기여한다는 점을 알 수 있다.
- 그림15, 그림16을 통해 FLIC, MPII 데이터 셋에 대해서 해당 논문의 제안 모델이 기존의 방법들을 능가함을 보여준다.
결론
해당 논문은 Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation 논문이 제안한 네트워크 아키텍쳐를 개선하여 CNN 기반의 풀링에서 발생하는 공간적 정확도 감소 문제를 해결하여 성능을 향상시킨다. 기존 대비 개선된 coarse 모델과 fine 모델을 제시 및 두 아키텍쳐의 연결된 학습을 구현한다. 또한 Spatial Dropout의 제안으로 과적합을 방지하는 방법을 제시한다.
번역
Abstract
최근 인간 신체 자세 추정 분야에서 최첨단 성능이 깊은 합성곱 신경망(ConvNets)을 통해 달성되었습니다. 전통적인 ConvNet 구조는 풀링과 하위 샘플링 층을 포함하여 계산 요구 사항을 줄이고 불변성을 도입하며 과적합을 방지합니다. 풀링의 이러한 이점들은 위치 추정 정확도 감소라는 대가를 수반합니다. 우리는 이미지의 작은 영역 내에서 관절 오프셋 위치를 추정하기 위해 학습된 효율적인 ‘위치 보정’ 모델을 포함하는 새로운 구조를 도입합니다. 이 보정 모델은 최신 ConvNet 모델과 함께 계단식으로 공동 학습되어 인간 관절 위치 추정에서 향상된 정확도를 달성합니다. 우리는 우리의 검출기의 분산이 FLIC 데이터셋에서의 인간 주석 분산에 근접하며, MPII-human-pose 데이터셋에서 모든 기존 방법들을 능가함을 보여줍니다.
1. Introduction

인간 신체 부위 위치 추정 작업에서 최첨단 성능은 최근 몇 년 동안 크게 발전했습니다. 이는 부분적으로는 심층 학습 구조, 특히 합성곱 신경망(ConvNets)의 성공 덕분이며, 점점 더 크고 포괄적인 데이터셋의 이용 가능성 덕분이기도 합니다 ([1]의 어려운 예제에 대한 우리 모델의 예측은 그림 1에 표시되어 있습니다).
현재까지 인간 신체 자세 감지에 사용된 모든 ConvNet 구조의 공통된 특성은 내부적으로 스트라이드 풀링 층을 사용한다는 점입니다. 이러한 층은 지역적 공간 영역에 대한 요약 통계를 계산함으로써 공간 해상도를 줄입니다 (일반적으로 사용되는 Max-Pooling 층의 경우, 이는 최대 연산을 수행합니다). 이러한 층의 사용 동기는 지역적 입력 변환에 대한 불변성을 촉진하는 것이며, 특히 변환(translation)에서 불변성을 갖도록 합니다. 이는 특히 지역 이미지 변환이 객체 식별을 혼동시키는 이미지 분류에서 중요합니다. 따라서 풀링은 과적합을 방지하고 분류 작업의 계산 복잡성을 줄이는 데 중요한 역할을 합니다.
풀링 층을 통해 달성된 공간 불변성은 공간 위치 정확도를 제한하는 대가를 수반합니다. 따라서 네트워크 내의 풀링 양을 조정함으로써, 위치 추정 작업에서는 일반화 성능, 모델 크기, 그리고 공간 정확도 간의 절충이 이루어집니다.
이 논문에서 우리는 단안 RGB 이미지에서 인간 골격 관절을 효율적으로 위치 추정하기 위한 ConvNet 구조를 제시합니다. 이 구조는 높은 공간 정확도를 유지하면서도 상당한 계산 오버헤드를 유발하지 않습니다. 이 모델은 계산 효율성을 위해 풀링의 양을 늘리면서도 높은 공간 정밀도를 유지할 수 있도록 합니다.
우리는 먼저 대략적인 신체 부위 위치 추정을 수행하기 위한 ConvNet 구조를 제시합니다. 이 네트워크는 각 공간 위치에서 관절이 발생할 가능성을 설명하는 저해상도 픽셀별 히트맵을 출력합니다. 우리는 이 구조를 플랫폼으로 사용하여 차원 축소 및 노이즈 및 지역 이미지 변환에 대한 불변성을 개선하는 데 있어 합성곱 구조에서 Max-pooling 층의 역할을 논의하고 실증적으로 평가합니다. 그런 다음 우리는 대략적인 히트맵 회귀 모델에서 은닉층 합성곱 피처를 재사용하여 위치 추정 정확도를 개선하는 새로운 네트워크 구조를 제시합니다. 이러한 모델을 공동으로 학습함으로써, 우리는 우리의 모델이 표준 인간 신체 자세 데이터셋에서 최근의 최첨단 성능을 능가함을 보여줍니다.
2. Related Work
Felzenszwalb 등의 [10] 인간 신체 자세 추정을 위한 ‘변형 가능한 부품 모델’(DPM)에 대한 중요한 연구 이후, DPM 구조를 개선하기 위한 많은 알고리즘이 제안되었습니다 [2, 9, 23, 7]. Yang과 Ramanan [23]은 SVM을 사용하여 모델링된 템플릿 혼합 모델을 제안하였으며, Johnson과 Everingham [15]은 신체 부위 감지기의 계단식을 사용하여 더 구별력 있는 템플릿을 제안하였습니다.
최근 고차원 DPM 기반 신체 부위 의존성 모델들이 제안되었습니다 [18, 19, 11, 20]. Pishchulin [18, 19]은 Poselet 사전 정보와 DPM 모델 [3]을 사용하여 신체 부위의 공간적 관계를 포착하였으며, Gkioxari 등 [11]은 반-글로벌 부품 구성 분류기를 사용하는 Armlets 접근 방식을 제안하였습니다. 이 방법은 실제 데이터에서 좋은 성능을 보였지만, 팔에 대해서만 입증되었습니다. Sapp과 Taskar [20]은 대략적인 모드 선택과 자세 추정을 위해 전체적 신호와 지역 신호를 모두 포함하는 다중 모드 모델을 제안하였습니다. 이러한 접근법들의 공통된 특성은 수작업으로 제작된 특징(에지, 윤곽선, HoG 특징 및 색상 히스토그램)을 사용한다는 점인데, 이는 학습된 특징(이 연구에서와 같이)과 비교했을 때 일반화 성능과 구별력이 떨어진다는 것이 입증되었습니다.
오늘날 많은 시각적 작업에서 가장 성능이 좋은 알고리즘은 합성곱 신경망(ConvNets)에 기반을 두고 있습니다. 현재 ‘실제 환경’에서의 인간 자세 추정 작업을 위한 최첨단 방법들도 ConvNets [22, 13, 21, 14, 5]을 사용하여 구축되었습니다. Toshev 등의 [22] 모델은 어려운 ‘FLIC’ [20] 데이터셋에서 최첨단 방법들을 크게 능가하였으며, ‘LSP’ [16] 데이터셋에서도 경쟁력이 있었습니다. 우리의 연구와는 달리, 그들은 문제를 이산적인 히트맵 출력 대신 관절 위치로의 직접적인(연속적인) 회귀로 공식화했습니다. 그러나 그들의 방법은 고정밀 영역에서 성능이 좋지 않으며, 이는 입력 RGB 이미지에서 XY 위치로의 매핑이 불필요한 학습 복잡성을 추가하여 일반화를 약화시키기 때문이라고 우리는 믿습니다.
예를 들어, 직접적인 회귀는 다중 모드 출력(유효한 관절이 두 공간 위치에 존재하는 경우)을 우아하게 처리하지 못합니다. 네트워크는 주어진 회귀 입력에 대해 단일 출력을 생성하도록 강제되기 때문에 출력 표현에서 작은 오류를 수용할 수 있는 충분한 자유도를 가지지 못하며, 이는 과적합으로 이어진다고 믿습니다 (예: 유효한 신체 부위의 존재로 인해 작은 이상치가 XY에서 큰 오류에 기여할 수 있음).
Chen 등 [5]은 ConvNet을 사용하여 입력 이미지의 저차원 표현을 학습하고 이미지 의존적 공간 모델을 사용하여 [22]보다 향상된 성능을 보였습니다. Tompson 등 [21]은 다중 해상도 ConvNet 구조를 사용하여 히트맵 가능성 회귀를 수행하였으며, 이를 그래픽 모델 네트워크와 공동으로 학습하여 관절 일관성을 더욱 촉진하였습니다. 비슷한 연구에서 Jain 등 [14]은 또한 다중 해상도 ConvNet 구조를 사용했지만, 추가로 정확도를 높이기 위해 네트워크 입력에 모션 특징을 추가하였습니다. 우리의 히트맵 회귀 모델은 이러한 연구들에서 영감을 받아 더 나은 위치 정확도를 위한 개선이 이루어졌습니다. 이 연구의 기여는 [21]의 구조를 확장한 것으로 볼 수 있으며, 우리는 풀링의 한계를 극복하여 공간 지역성의 정밀도를 향상시키려 하고 있습니다.
관련 없는 응용 프로그램에서 Eigen 등 [8]은 대략적인 모델에서 세밀한 ConvNet 모델로 이어지는 계단식 구조를 사용하여 깊이를 예측했습니다. 그들의 연구에서는 대략적인 모델을 미리 학습시키고 세밀한 모델을 학습할 때 모델 매개 변수를 고정합니다. 반면에, 이 연구에서는 두 모델을 공동 학습하여 일반화 성능을 향상시키고 실행 시간 성능을 개선하기 위해 입력 특징의 일부를 샘플링하는 새로운 공유 특징 구조를 제안합니다.
3. Coarse Heat-Map Regression Model
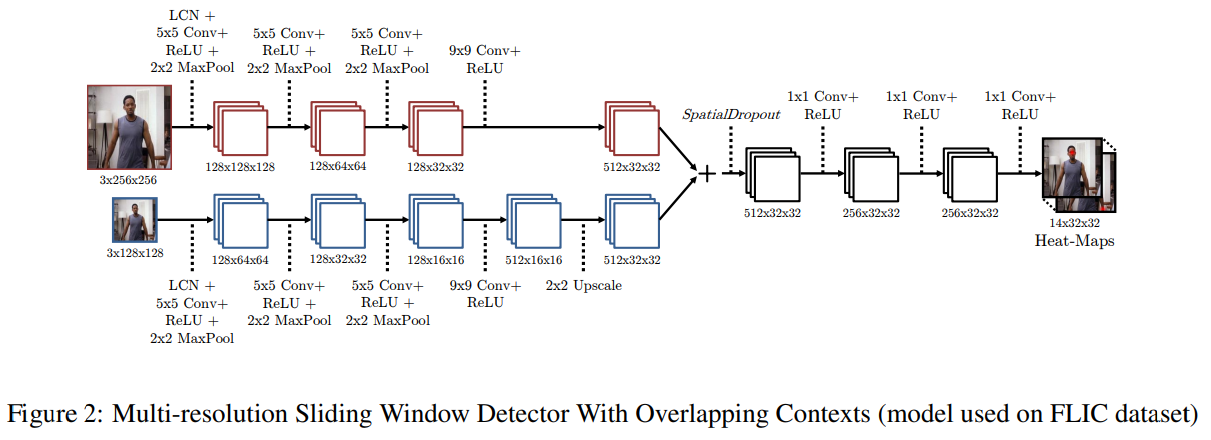
Tompson 등 [21]의 연구에서 영감을 받아, 우리는 다중 해상도 ConvNet 구조(Figure 2)를 사용하여 겹치는 컨텍스트가 있는 슬라이딩 윈도우 감지기를 구현하고 대략적인 히트맵 출력을 생성합니다. 우리의 연구는 그들의 모델을 확장한 것이므로, 우리는 구조의 간단한 개요만을 제시하고 우리 모델의 확장된 부분을 설명할 것입니다.
3.1. Model Architecture
대략적인 히트맵 회귀 모델은 3단계의 RGB 가우시안 피라미드를 입력으로 사용하며(그림 2에서는 간략화를 위해 2단계만 표시됨), 각 관절의 히트맵을 출력하여 해당 관절이 각 출력 공간 위치에서 발생할 가능성을 픽셀 단위로 설명합니다. 우리는 FLIC [20]과 MPII [1] 데이터셋에 대해 각각 320x240 및 256x256 픽셀의 입력 해상도를 사용합니다. 네트워크의 첫 번째 층은 각 해상도 뱅크에서 동일한 필터 커널을 사용하는 국부 대조 보정(LCN) 층입니다.
각 LCN 이미지는 7단계 다중 해상도 합성곱 신경망에 입력되며(MPII 데이터셋 모델의 경우 11단계), 풀링이 존재하기 때문에 히트맵 출력은 입력 이미지보다 낮은 해상도에서 발생합니다. 마지막 4단계(MPII 데이터셋 모델의 경우 3단계)는 효과적으로 대상 입력 패치 크기(일반적으로 입력 이미지보다 훨씬 작은 컨텍스트)를 위한 완전 연결 네트워크를 시뮬레이션합니다. 자세한 내용은 [21]을 참조하십시오.
3.2. SpatialDropout
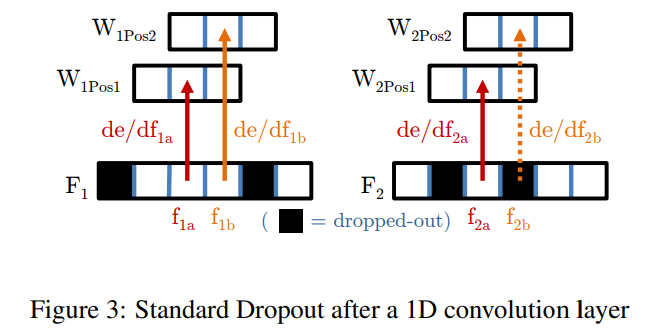
우리는 그림 2에서 첫 번째 1x1 합성곱 층 앞에 추가적인 드롭아웃 층을 추가함으로써 [21]의 모델을 개선합니다. 드롭아웃의 역할은 활성화가 강하게 상관되지 않도록 하여 일반화 성능을 향상시키는 것입니다 [12]. 이는 과적합을 방지하는 데 기여합니다. 표준 드롭아웃 구현에서는 훈련 중에 독립적인 확률 $p_{drop}$ 로 뉴런의 활성화를 0으로 설정하여 “드롭아웃”합니다. 테스트 시에는 모든 활성화가 사용되지만, 기대된 편향의 증가를 보정하기 위해 뉴런 활성화에 $1−p_{drop}$ 가 곱해집니다.
초기 실험에서, 우리는 각 합성곱 특징 맵의 활성화가 독립적으로 “드롭아웃”되는 표준 드롭아웃을 1x1 합성곱 층 전에 적용하면 훈련 시간이 전반적으로 증가하지만 과적합을 방지하지 못한다는 것을 발견했습니다. 우리의 네트워크는 완전 합성곱 신경망이며 자연 이미지들은 강한 공간적 상관성을 보이기 때문에, 특징 맵 활성화도 강하게 상관되어 있고, 이러한 상황에서는 표준 드롭아웃이 실패합니다.
1D 합성곱 출력에서의 표준 드롭아웃은 그림 3에 나와 있습니다. 위쪽 두 줄의 픽셀은 특징 맵 1과 2에 대한 합성곱 커널을 나타내고, 아래쪽 줄은 이전 층의 출력 특징을 나타냅니다. 역전파 동안, $W_2$ 커널의 중심 픽셀은 입력 특징 $F_2$ 를 따라 합성곱 커널 $W_2$ 가 이동할 때 $f_{2a}$ 와 $f_{2b}$ 모두로부터 그래디언트 기여를 받습니다. 이 예에서 $f_{2b}$ 는 랜덤하게 드롭아웃되었고(따라서 활성화는 0으로 설정됨), $f_{2a}$ 는 드롭아웃되지 않았습니다. $F_2$ 와 $F_1$ 은 합성곱 층의 출력이므로, $f_{2a}$ 와 $f_{2b}$ 는 강하게 상관될 것으로 예상됩니다: 즉, $f_{2a} ≈ f_{2b}$ 이고, $de/df_{2a} ≈ de/df_{2b}$ 입니다(여기서 $e$는 최소화할 오류 함수입니다). $f_{2b}$ 의 그래디언트 기여는 0이지만, 강하게 상관된 $f_{2a}$ 의 그래디언트는 남아 있습니다. 본질적으로 학습률은 드롭아웃 확률 $p$ 에 의해 조정되지만, 독립성은 강화되지 않습니다.
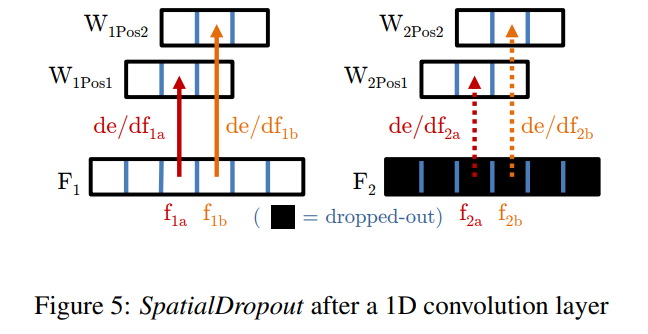
대신 우리는 새로운 드롭아웃 방법을 제안하며, 이를 SpatialDropout라고 부릅니다. 주어진 크기 $n_{feats}×height×width$ 의 합성곱 특징 텐서에 대해 우리는 $n_{feats}$ 드롭아웃 시도만 수행하고, 드롭아웃 값을 전체 특징 맵에 확장합니다. 따라서, 드롭아웃된 특징 맵에서 인접한 픽셀들은 모두 0(드롭아웃됨) 또는 모두 활성화 상태가 됩니다(그림 5에 표시된 대로). 우리는 이 수정된 드롭아웃 구현이 특히 훈련 셋 크기가 작은 FLIC 데이터셋에서 성능을 향상시킨다는 것을 발견했습니다.
3.3. Training and Data Augmentation
우리는 그림 2의 모델을 예측된 히트맵과 목표 히트맵 간의 평균 제곱 오차(MSE) 거리를 최소화함으로써 훈련시킵니다. 목표 히트맵은 지상 진실 $(x, y)$ 관절 위치에 중심을 둔 일정한 분산($σ ≈ 1.5$ 픽셀)을 가진 2D 가우시안입니다. 목적 함수는 다음과 같습니다:
\[\begin{equation} E_1 = \frac{1}{N} \sum_{j=1}^{N}\sum_{xy} \Vert H'_j(x,y) - H_j(x,y) \Vert^2 \end{equation}\]여기서 $H’_j$ 와 $H_j$ 는 각각 $j^{th}$ 관절에 대한 예측된 히트맵과 지상 진실 히트맵을 나타냅니다.
훈련 중 각 입력 이미지는 검증 셋에서의 일반화 성능을 향상시키기 위해 무작위로 회전 ($r∈[−20°,+20°]$), 크기 조정 ($s∈[0.5,1.5]$), 그리고 좌우 반전(확률 0.5)을 거칩니다. 이는 [21]에서 사용된 동일한 훈련 프로토콜을 따릅니다.
많은 이미지에는 여러 사람이 포함되어 있지만, 오직 한 사람만 주석 처리됩니다. 테스트 시점에서 목표 인물의 주석을 추론할 수 있도록 FLIC와 MPII 데이터셋은 대략적인 몸통 위치를 포함합니다. 우리의 슬라이딩 윈도우 감지기는 단일 프레임에서 모든 관절 인스턴스를 구별 없이 감지하므로, 우리는 Tompson 등 [21]의 MRF 기반 공간 모델을 구현하여 이 몸통 정보를 통합합니다. 가장 가능성 있는 관절 위치는 ConvNet에서 나오는 노이즈가 있는 입력 분포를 바탕으로 메시지 패싱을 사용하여 추론됩니다. 지상 진실 몸통 위치는 ConvNet 출력에서 예측된 14개의 관절과 연결되며, 이 15개의 관절 위치는 MRF에 입력됩니다. 이 설정에서, MRF 추론 단계는 지상 진실 몸통이 해부학적으로 유효하지 않은 사람의 관절 활성화를 약화시키는 것을 학습하고, 따라서 올바른 사람을 레이블링하기 위해 “선택”합니다. 더 자세한 내용은 [20]을 참조하십시오.
4. Fine Heat-Map Regression Model
본 연구의 목표는 3.1절에서 모델의 풀링으로 인해 손실된 공간 정확도를 회복하기 위해 추가적인 ConvNet을 사용하여 대략적인 히트맵의 위치 결과를 정제하는 것입니다. 그러나 Toshev 등의 연구 [22]에서 사용된 표준 모델 계단식 구조와 달리, 우리는 기존의 합성곱 특징을 재사용합니다. 이는 계단식 구조에서 학습 가능한 파라미터 수를 줄일 뿐만 아니라 대략적인 히트맵 모델에 대한 정규화 역할도 합니다. 왜냐하면 대략적인 모델과 세부 모델이 공동으로 학습되기 때문입니다.
4.1. Model Architecture
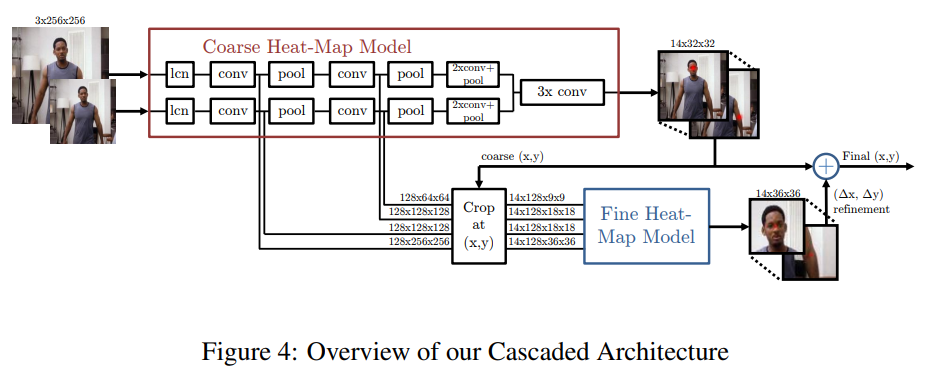
전체 시스템 아키텍처는 그림 4에 나와 있습니다. 이 구조는 3.1절에서 제시된 대략적인 위치 추정을 위한 히트맵 기반 부품 모델과 각 관절에 대해 지정된 (x, y) 위치에서 합성곱 특징을 샘플링하고 자르는 모듈, 그리고 세부 조정을 위한 추가적인 합성곱 모델로 구성됩니다.
입력 이미지에서 관절 추론은 다음과 같이 진행됩니다: 우리는 대략적인 히트맵 모델을 통해 전파(FPROP)를 수행한 후, 각 관절 히트맵에서 최대값을 사용하여 모든 관절의 (x, y) 위치를 추론합니다. 그런 다음 이 대략적인 (x, y) 위치를 사용하여 각 관절 위치에서 첫 번째 2개의 합성곱 층(모든 해상도 뱅크)을 샘플링하고 자릅니다. 이 특징들을 세부 히트맵 모델을 통해 다시 전파(FPROP)하여 자른 하위 창 내에서 (Δx, Δy) 오프셋을 생성합니다. 마지막으로, 이 위치 보정을 대략적인 위치에 더하여 각 관절에 대한 최종 (x, y) 위치를 생성합니다.
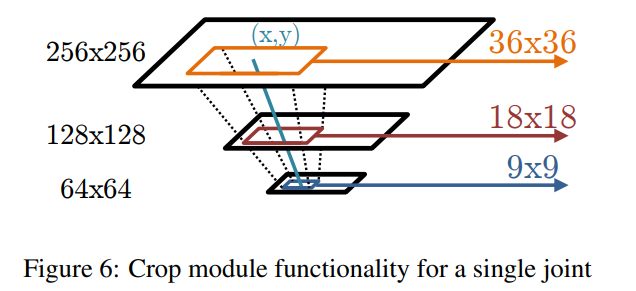
그림 6은 단일 관절에 대한 크롭 모듈 기능을 보여줍니다. 우리는 각 해상도 특징 맵에서 대략적인 관절 (x, y) 위치를 중심으로 창을 자릅니다. 그러나 창의 맥락적 크기를 유지하면서 더 높은 해상도 수준에서 크롭된 영역을 확장합니다. 이 모듈을 통한 출력 특징에서 입력 특징으로의 역전파(BPROP)는 간단합니다. 크롭된 이미지에서의 출력 그래디언트는 샘플링된 픽셀 위치에서 대략적인 히트맵 모델의 합성곱 단계에 있는 출력 그래디언트에 단순히 추가됩니다.
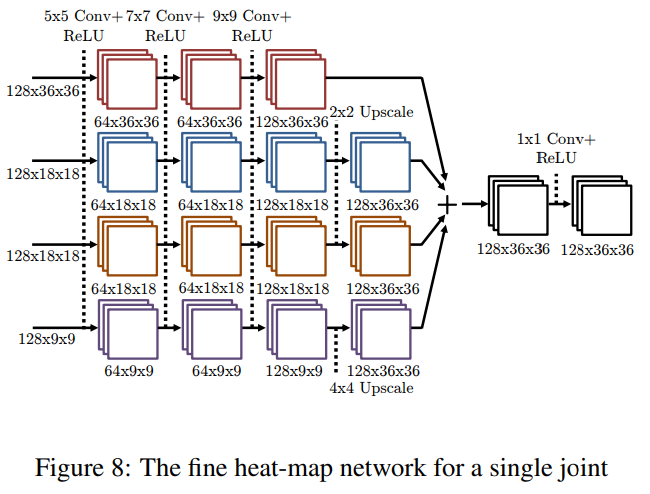
세부 히트맵 모델은 7개의 인스턴스(14는 MPII 데이터셋)의 시암 네트워크 [4]로 구성되며, 각 모듈의 가중치와 바이어스는 공유됩니다(즉, 모든 인스턴스에 걸쳐 복제되고 BPROP 동안 함께 업데이트됨). 각 관절에 대한 샘플 위치가 다르기 때문에 합성곱 특징은 동일한 공간적 맥락을 공유하지 않으며, 따라서 합성곱 서브 네트워크는 각 관절에 독립적으로 적용되어야 합니다. 그러나 우리는 7개의 인스턴스 간의 파라미터 공유를 사용하여 공유되는 파라미터 수를 크게 줄이고 과적합을 방지합니다. 각 서브 네트워크의 출력에서 우리는 각 관절에 대한 세부 해상도의 히트맵을 출력하기 위해 가중치 공유 없이 1x1 합성곱을 수행합니다. 이 마지막 층의 목적은 각 관절에 대한 최종 감지를 수행하는 것입니다.
시암 네트워크에서 중복된 연산이 발생할 가능성이 있습니다. 두 개의 크롭된 서브 윈도우가 겹치고, 합성곱 가중치가 공유되기 때문에 동일한 합성곱이 동일한 공간 위치에 여러 번 적용될 수 있습니다. 그러나 실제로는 이런 일이 드물게 발생함을 확인했습니다. 관절이 함께 위치하는 경우가 드물고, 크롭된 서브 영역 간의 중첩이 거의 없도록 공간적 맥락 크기가 선택되었습니다 (그림 4와 8에서 표시된 크롭된 이미지의 맥락은 명확성을 위해 과장되었습니다).
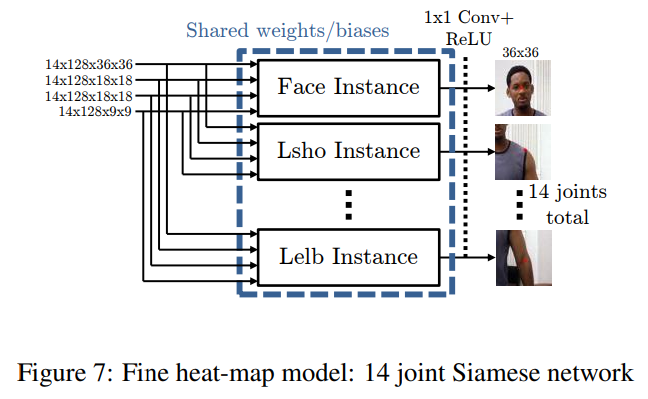
그림 7의 서브 네트워크 각 인스턴스는 그림 8에서처럼 4개의 층으로 이루어진 ConvNet입니다. 입력 이미지는 서로 다른 해상도와 대략적인 히트맵 모델의 깊이에서 기인하기 때문에, 우리는 입력 특징을 별도의 해상도 뱅크로 처리하고 3.1절에서 사용된 유사한 아키텍처 전략을 적용합니다. 즉, 각 뱅크에 동일한 크기의 합성곱을 적용하고, 저해상도 특징을 업스케일하여 표준 해상도로 맞춘 뒤, 특징 맵을 통해 활성화를 더한 다음 출력 특징에 1x1 합성곱을 적용합니다.
이 계단식 아키텍처는 더 적은 풀링을 가진 여러 계단식 레벨로 확장될 수 있음을 주목해야 합니다. 그러나 실제로 우리는 단일 층이 충분한 정확도를 제공하며, 특히 FLIC 데이터셋에서 레이블 노이즈 수준 내에서 충분함을 발견했습니다 (섹션 5에서 설명된 대로).
4.2. Joint Training
합동 학습을 하기 전에, 우리는 먼저 3.1절에서 설명된 대략적인 히트맵 모델을 Eq 1을 최소화하여 사전 훈련합니다. 그런 다음 대략적인 모델의 파라미터를 고정하고, 4.1절의 세부 히트맵 모델을 다음을 최소화하여 훈련합니다:
\[\begin{equation} E_2 = \frac{1}{N}\sum_{j=1}^N\sum_{x,y} \Vert G'_j(X,Y)-G_j(x,y)\Vert^2 \end{equation}\]여기서 $G’_j$ 와 $G_j$ 는 각각 세부 히트맵 모델에 대한 예측된 히트맵과 지상 진실 히트맵을 나타냅니다. 마지막으로, 우리는 $E_3=E_1+λE_2$ 를 최소화하여 두 모델을 공동으로 학습합니다. 여기서 $λ$ 는 두 하위 작업의 상대적인 중요도를 조정하는 상수입니다. 우리는 $λ$ 를 또 다른 네트워크 하이퍼파라미터로 취급하며, 검증 셋에서 성능을 최적화하도록 선택됩니다(우리는 $λ=0.1$ 을 사용합니다). 이상적으로, 더 직접적인 최적화 함수는 두 히트맵의 $argmax$ 를 측정하고, 따라서 최종 (x, y) 예측을 직접 최소화하려고 할 것입니다. 그러나 $argmax$ 함수는 미분할 수 없기 때문에, 우리는 문제를 목표 히트맵 집합으로의 회귀로 다시 구성하고, 해당 히트맵들과의 거리를 최소화하는 방식으로 문제를 해결합니다.
5. Results
우리의 ConvNet 아키텍처는 Torch7 [6] 프레임워크 내에서 구현되었고, FLIC [20]과 MPII-Human-Pose [1] 데이터셋에서 평가되었습니다. FLIC 데이터셋은 할리우드 영화에서 상반신 관절 레이블이 주석된 3,987개의 학습 예시와 1,016개의 테스트 예시로 구성되어 있습니다. FLIC는 주로 정면을 향하고 똑바른 자세가 많기 때문에, 최근 데이터셋보다 덜 도전적이라고 간주됩니다. 그러나 학습 예시의 수가 적다는 점이 데이터셋을 일반화 성능의 좋은 지표로 만듭니다. 반면, MPII 데이터셋은 매우 도전적이며 28,821개의 학습 예시와 11,701개의 테스트 예시에서 전신 자세 주석이 포함된 다양한 자세를 포함합니다. FLIC 데이터셋에서 우리의 모델을 평가하기 위해 우리는 [20]에서 제안된 표준 PCK 측정을 사용하고, MPII 데이터셋에서는 [1]의 PCKh 측정을 사용하여 평가합니다.
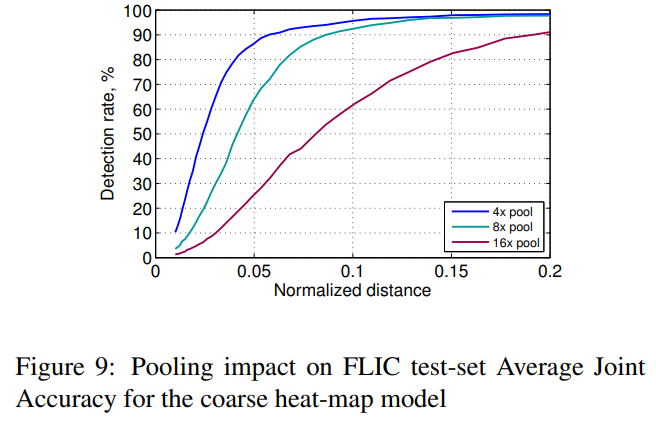
그림 9는 네트워크 내에서 다양한 풀링 양을 사용할 때 대략적인 히트맵 모델(3.1절)의 PCK 테스트 셋 성능을 보여줍니다(합성곱 특징의 수는 일정하게 유지). 그림 9의 결과는 (x, y)에서 대략적인 양자화의 예상 효과를 명확하게 보여주며, 따라서 풀링이 공간적 정밀도에 미치는 영향을 보여줍니다. 더 많은 풀링이 사용될수록 작은 거리 임계값 내에서 탐지 성능이 감소합니다.
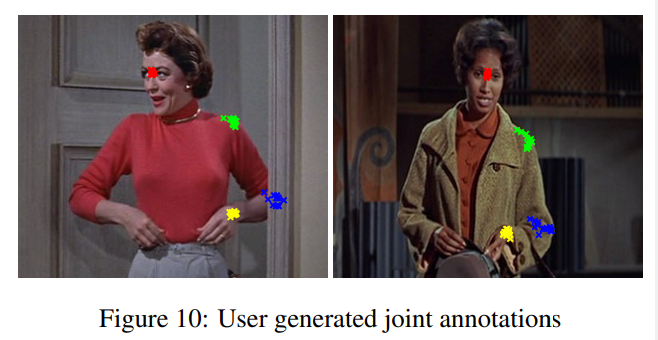
지상 진실 레이블이 모호하고 기계적인 작업자들이 레이블을 지정하기 어려운 관절에 대해서는, 우리의 계단식 네트워크가 사용자 생성 레이블의 예상 분산보다 나은 성능을 낼 것이라고 기대하지 않습니다. 이 분산을 측정하고(따라서 성능의 상한을 추정하기 위해) 우리는 다음과 같은 비공식적인 실험을 수행했습니다:
우리는 13명의 사용자에게 주석된 지상 진실 레이블이 포함된 FLIC 학습 셋의 10개의 무작위 이미지를 보여주어 각 관절의 원하는 해부학적 위치에 익숙해지도록 했습니다. 그런 다음, 사용자들은 FLIC 테스트 셋에서 얼굴, 왼손목, 왼쪽 어깨, 왼쪽 팔꿈치 관절에 대해 일관된 10개의 무작위 이미지 세트를 주석 처리했습니다. 그림 10은 그 결과로 생성된 2개의 이미지에 대한 관절 주석을 보여줍니다.
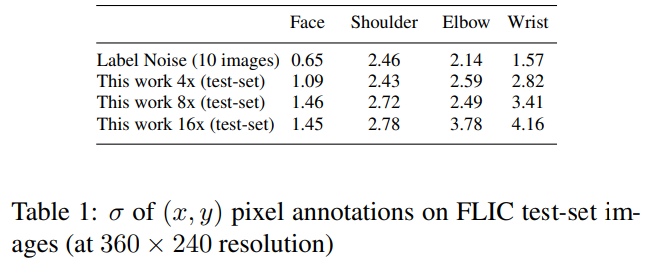
관절 주석 노이즈를 추정하기 위해 우리는 각 이미지에 대한 x 좌표의 사용자 주석 표준편차($σ$)를 계산하고, 10개의 샘플 이미지에 대한 $σ$의 평균을 내어 각 관절에 대한 총 $σ$를 얻습니다. FLIC 이미지를 모델에서 사용하기 위해 2배로 다운샘플링하므로, 우리는 동일한 다운샘플 비율로 $σ$ 값을 나눕니다. 결과는 표 1에 나와 있습니다.
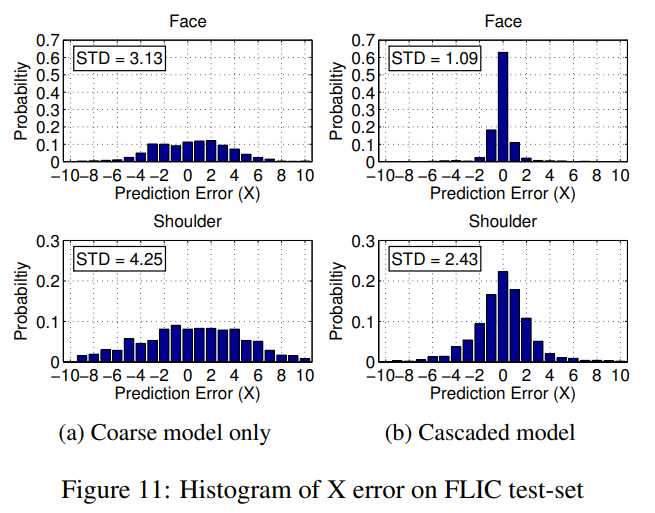
8x 내부 풀링을 사용했을 때 FLIC 테스트 셋에서 대략적인 히트맵 모델의 X 차원의 픽셀 오차 히스토그램이 그림 11a에 나와 있습니다 (얼굴과 어깨 관절에 대한). 설명을 위해 우리는 네트워크로 입력된 이미지의 픽셀 좌표에서의 오차를 인용하며 (FLIC의 경우 360 x 240), 원래 해상도는 아닙니다. 예상대로 이러한 좌표에서는 히트맵 양자화로 인해 -4에서 +4 픽셀 범위 내에서 대략적인 불확실성이 존재합니다. 이에 반해, 계단식 네트워크의 히스토그램은 그림 11b에 나와 있으며 측정된 레이블 노이즈와 가깝습니다.
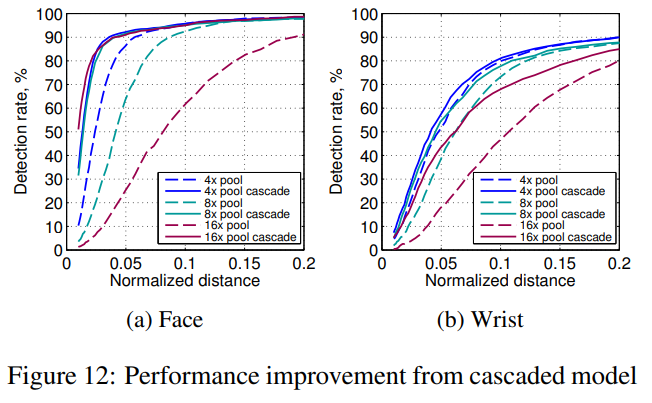
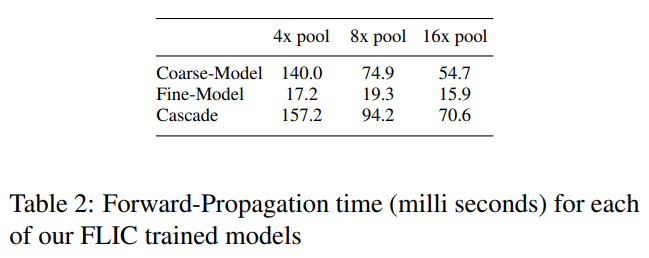
얼굴과 손목에 대한 FLIC의 PCK 성능이 각각 그림 12a와 12b에 나와 있습니다. 얼굴의 경우, 8x와 16x 풀링 모델에서 성능 향상이 특히 두드러집니다. Nvidia-K40 GPU를 사용하여 각 모델의 단일 이미지에 대한 전파 시간이 표 2에 나와 있습니다. 8x 풀링 계단식 네트워크를 사용하면 4x 네트워크에 비해 계산 시간이 크게 개선되면서 레이블 노이즈 수준에 가까운 성능을 발휘할 수 있었습니다.
손목에 대한 성능 향상도 8x와 16x 풀링 모델에서만 두드러졌습니다. 우리의 실험 결과는 손목 탐지(탐지하기 가장 어려운 관절 중 하나)가 많은 공간적 맥락을 가진 특징 학습이 필요하다는 것을 시사합니다. 이는 손목 관절이 어깨나 얼굴보다 더 큰 골격 변형을 겪고, 일반적으로 의류 및 손목 액세서리로 인해 입력 변동성이 높기 때문입니다. 따라서 세부 히트맵 회귀 네트워크에서 제한된 합성곱 크기와 샘플링 맥락으로 인해 계단식 네트워크는 대략적인 모델 이상의 손목 정확도를 향상시키지 못합니다.
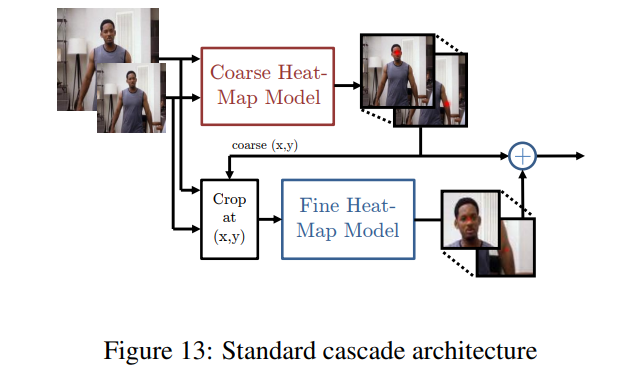
공유된 특징을 사용하는 계단식 네트워크의 효과를 평가하기 위해, 우리는 입력 이미지의 잘린 버전을 입력으로 받아들이는 세부 히트맵 모델을 훈련했습니다 (그림 13 참조). 이 비교 모델은 독립적으로 학습된 계단식 모델입니다. 추가적으로, 그림 4의 네트워크가 비교 모델보다 더 큰 용량을 가지므로, 학습 가능한 파라미터 수를 동일하게 유지하기 위해 추가적인 합성곱 층을 추가했습니다. 그림 14a는 4x 풀링 네트워크가 손목 관절에서 비교 모델을 능가한다는 것을 보여줍니다 (다른 관절에서도 비슷한 성능 향상이 나타났습니다). 우리는 이를 합동 학습의 정규화 효과 덕분으로 봅니다. 목표 함수 내의 세부 히트맵 모델 항목이 대략적인 모델의 과도한 학습을 방지하고 그 반대의 경우도 마찬가지입니다.
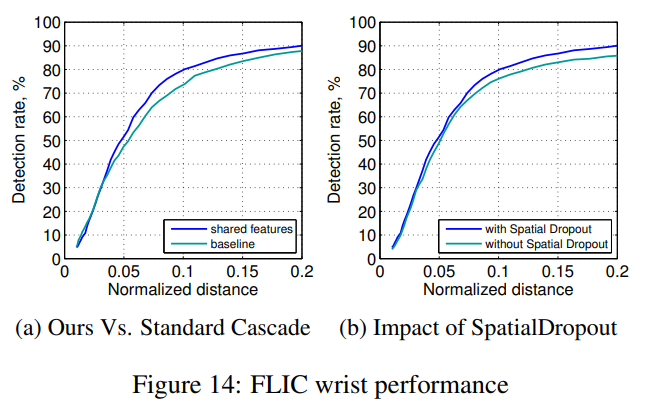
우리는 또한 그림 14b에서 손목 관절에 대한 SpatialDropout을 적용한 경우와 적용하지 않은 경우의 모델 성능을 보여줍니다. 예상대로, 드롭아웃 구현의 정규화 효과와 강력한 히트맵 이상값 감소로 인해 정규화된 높은 거리 영역에서 상당한 성능 향상을 볼 수 있습니다.
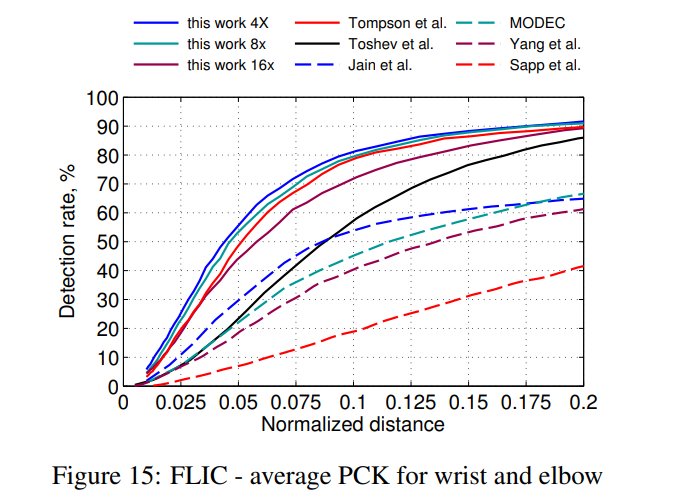
그림 15는 손목과 팔꿈치 관절에 대한 PCK 성능을 기존 연구와 비교한 것입니다. 우리 모델은 SpatialDropout을 사용한 덕분에 Tompson 등 [21]의 기존 최첨단 결과를 큰 거리에서 능가했습니다. 높은 정밀도 구간에서는 계단식 네트워크가 모든 기존 최첨단 결과를 상당한 차이로 능가합니다. 각 관절에 대한 0.05의 정상화된 거리에서의 PCK 성능은 표 3에 나와 있습니다.
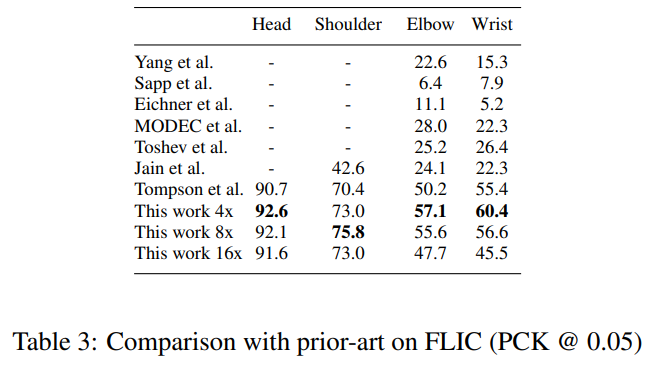
마지막으로, 그림 16은 MPII 인간 포즈 데이터셋에서의 모델의 PCKh 성능을 보여줍니다. 마찬가지로, 표 4는 0.5의 정규화된 거리에서 현재 연구의 PCKh 성능과 기존 최첨단 연구의 성능을 비교한 것입니다. 우리 모델은 기존의 모든 방법들을 상당한 차이로 능가합니다.
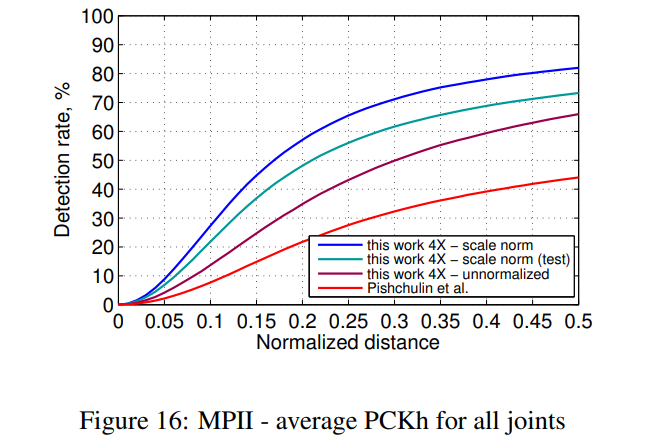
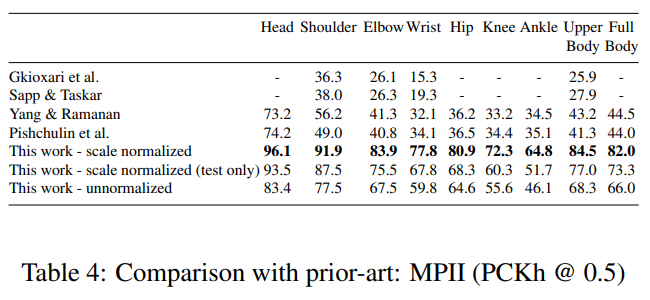
MPII 데이터셋은 테스트 시 피사체의 스케일을 제공하므로, 표준 평가 관행에서는 쿼리 이미지를 스케일 정규화하여 평균적인 사람의 키가 일정하게 유지되도록 합니다. 이렇게 하면 탐지 작업이 더 쉬워집니다. 실제 애플리케이션에서는 쿼리 이미지를 여러 스케일에서 감지기에 통과시키고, 일반적으로 결과 히트맵 전반에 걸쳐 활성화를 집계하기 위해 비최대 억제(non-maximum suppression)가 사용됩니다. 대안으로는, 테스트 및 훈련 세트 전반에서 원래 쿼리 이미지 스케일(크기가 매우 다양함)에서 ConvNet을 훈련시켜 탐지 단계에서 스케일 불변성을 학습할 수 있습니다. 이를 통해 단일 스케일에서 테스트 시간에 탐지기를 실행할 수 있어 실시간 애플리케이션에 더 적합하게 만들 수 있습니다. 그림 16과 표 4에서는 원래 데이터셋 스케일(비정규화)에서 훈련된 모델의 성능을 보여줍니다. 이 모델은 정규화된 테스트 세트와 비정규화된 테스트 세트에서 모두 성능을 보여줍니다. 예상대로, 탐지 문제가 더 어려워지면서 성능이 저하됩니다. 그러나 놀랍게도 이 모델은 기존 최첨단 방법들을 능가하여 ConvNet이 어느 정도 스케일 불변성을 학습할 수 있음을 보여줍니다.
6. Conclusion
원래 분류 작업을 위해 개발된 심층 합성곱 신경망(Deep Convolutional Networks)은 다양한 다른 문제에도 성공적으로 적용되었습니다. 분류 작업에서는 객체의 정체성을 제외한 모든 변동성이 억제됩니다. 반면, 인간의 신체 자세 추정과 같은 위치 지정 작업은 종종 높은 수준의 공간적 정밀도를 요구합니다. 이번 연구에서는 전통적인 ConvNet 아키텍처에서 풀링으로 인해 손실된 정밀도를 계산 효율성을 유지하면서도 효과적으로 회복할 수 있음을 보여주었습니다. 우리는 세밀한 스케일과 거친 스케일의 합성곱 네트워크를 결합한 새로운 계단식 아키텍처를 제시하였으며, FLIC 및 MPII 인간 자세 데이터셋에서 새로운 최첨단 결과를 달성했습니다.
7. Acknowledgements
이 연구는 Google과 해군 연구소(Office of Naval Research)의 ONR Award N000141210327의 부분적 지원을 받았습니다. 우리는 또한 Torch7의 모든 기여자들, 특히 Soumith Chintala에게 그들의 노고에 대해 감사드립니다.
Jonathan Tompson, Ross Goroshin, Arjun Jain, Yann LeCun, Christopher Bregler Efficient Object Localization Using Convolutional Networks

댓글남기기