

개요
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking 논문의 얕은 리뷰.
다중 객체 추적(MOT) 작업은 일반적으로 두 단계로 나뉘어왔다. 탐지 모델이 각 프레임에서 객체를 바운딩 박스 형태로 탐지하고, 연결 모델이 탐지된 객체의 이미지 영역에서 Re-ID를 위한 피쳐를 추출하여 기존 추적 궤적과 연결하거나 새로운 추적을 생성했다. 이러한 방식은 실시간 추론과 같은 문제를 겪는다. 피쳐맵을 두 모델이 공유하지 않기 때문이다.
최근에는 객체 감지와 re-ID를 단일 네트워크에서 처리하는 원샷 트래커에 주목한다. 아직 기존 원샷 추적기는 성능이 떨어지는 문제가 있으며, 탐지 정확도가 높지만 추적 성능이 떨어져 ID 스위치 횟수가 크게 증가하는 단점이 있다.
본 논문은 이를 해결 하기 위한 간단한 구조의 FairMOT를 제안한다.
원-샷 추적기의 불공정함
- 기존 원샷 추적기는 앵커 기반의 객체감지와 추적기를 결합한 모델을 사용
- 기존 원샷 추적기는 객체감지 성능이 좋지 않으면 re-ID의 특징의 효용이 전혀 쓸모없는 문제를 가지고 있다. 이는 네트워크 설계를 공정하게 하지 못한다.
- 또한 앵커 기반 방법은 해당 영역에 다른 겹치는 객체나 배경을 포함하고 있어 성능을 저하시키는 요소가 있다.
- 객체의 인접으로 인해 애매한 앵커가 사용될 수 있으며, 객체 감지를 위한 네트워크의 다운 샘플링 요소는 re-ID를 위해선 쓸모가 없을 수 있다.
- 객체 감지를 위한 피쳐맵과 re-ID 작업을 위한 피쳐맵이 공유되지 실제 객체 감지는 깊은 피쳐맵을 필요로 하고 re-ID는 낮은 수준의 외형 피쳐맵을 필요로 한다. 이러한 두 필요성은 서로 상충된다.
- 기존 re-ID 연구는 높은 차원의 피쳐맵을 학습하는데 우리는 낮은 차원을 학습하는 것이 테스크에 적합하다고 주장한다. 높은 차원의 피쳐맵은 객체 감지 정확도를 저해하며, 추적 정확도에도 부정적이다. 또한 MOT를 위해선 re-ID랑 달리 높은 차원의 피쳐맵을 필요로 하지 않는 다는 것을 주장한다.
FairMOT
- 백본은 ResNet-34를 기반으로한 향상된 DLA를 적용하여 DAL-34로 이름짓는다. 출력은 각각 높이와 너비를 4분의 1로 줄인다.
- 감지 브랜치는 CenterNet을 기반으로 하며, 히트맵(중심 좌표용), 중심 오프셋(오차 수정용), 바운딩 박스 크기 헤드를 포함한다.
- Re-ID 브랜치는 객체를 구별하는 외형적인 피쳐맵을 생성하며, 중심 좌표를 기준으로 128개의 피쳐맵을 추출한다.
- 이게 기존 DeepSORT 방식과 다른 점이라 볼 수 있는데, 기존 방식은 바운딩 박스 영역을 N개의 임베딩으로 만든다하면, FairMOT는 센터 좌표의 한 점에서 128차원의 특징맵이 추출되는 방식이다.
- 객체감지 브랜치와 Re-ID 브랜치에 대해 각각 손실함수를 설계하고 공동 학습한다. COCO 혹은 CrwodHuman과 같은 데이터 셋에서 단일 이미지 학습 방법을 사용한다.
- 네트워크는 $1088\times608$의 입력을 받아 추론하며 히트맵에 대해 NMS를 수행한다.
- 첫 프레임의 결과로 트랙렛(추적단위)를 초기화하고 다음 프레임부터 2단계 매칭 전략을 통해 추적을 수행한다.
- 첫 단계는 칼만필터와 마할라노비스 거리를 계산(DeepSORT와 동일한)하여 코사인 거리와 융합한다. 이를 통해 매칭 임계값으로 필터링 하여, 헝가리안 알고리즘을 통해 추적에 대해 첫 단계 매칭을 수행한다.
- 두번째 단계는 매칭되지 않은 탐지와 기존 트랙렛을 처리하기위해, 박스간의 겹침 정도를 기반으로 2차 매칭을 시도한다. 최종적으로 매칭되지 않은 탐지는 새로운 트랙렛으로 초기화한다. 트랙렛은 마지막 등장 기준으로 30프레임 동안 저장한다.
실험
- 학습에 사용된 데이터 셋
- 디텍션: ETH, CityPerson
- Re-ID 및 디텍션: CalTech, MOT17, CUHK-SYSU, PRW
- Self-Supervised: CrowdHuman(사전학습)
- 평가 메트릭: AP(디텍션), TPR(Re-ID), CLEAR metric(MOT)
- 소거 연구에서 앵커 기반 Re-ID 특징을 사용하는 연구들과의 비교를 진행하였고 Center 에서 추출한 샘플링의 성능이 우수함을 확인
- Multi-task 손실의 균형에서 Uncertainty, GradNorm, MGDA-UB 등의 방식을 평가하고, 균형을 위해 Uncertainty Method 를 채택
- MLFF(Multi Layer feature fusion)가 적용되지 않은 백본들과 비교하여 해당 방법론의 성능 입증. 더욱이 백본의 능력이 강하다고해서 MOT 측면에서 더 성능이 좋은 것만은 아니라는 것을 확인
- 512와 64의 파라미터 값을 통해 Re-ID 특징 차원 수에 따른 성능 및 효율성 확인
- 데이터 연관(매칭) 측면에서 박스의 IoU, Re-ID 특징맵 활용, Kalman 필터 적용을 모두 결합하는 것이 성능이 제일 좋음을 확인
- 테스트 결과 원-샷 SOTA 모델 JDE, TRACK RCNN 대비 압도적인 성능향상을 보임
- 투-샷 SOTA 모델과 비교하여 MOT15, MOT16, MOT17, MOT20 데이터셋에 대해 테스트 한 결과, MOTA 메트릭 및 여타 메트릭 기준 최고성능 기록, 높은 FPS로 실시간 성능 입증
- 더 많은 데이터 셋을 결합하여 학습할 수록 성능이 향상되는 것을 확인
결론
본 논문은 MOT 및 Re-ID 작업에서 Two-shot 방법 대비 One-shot 방법의 한계를 분석하여 해결책을 제안한다. 객체 감지 부분에서 앵커도 제거하고, 멀티 레이어의 특징을 융합하며, 낮은 차원 수의 Re-ID 특징을 사용하는 등의 방법을 제시하여 압도적으로 높은 성능을 달성한다. 또한 추론 정확도 뿐 아니라 추론 속도까지도 향상을 보인다. 심지어 혼잡한 환경, 객체 간 가림, 스케일의 변화에도 강하게 대처할 수 있는 추적기의 우수한 성능을 입증한다.
사람 객체에 대한 다양한 관제 시스템 환경에 활용이 가능할 것으로 보인다.
번역
Abstract
다중 객체 추적(MOT)은 컴퓨터 비전에서 중요한 문제로, 다양한 응용 분야를 가지고 있습니다. 객체 탐지와 재식별(re-ID)을 단일 네트워크에서 다중 과제 학습으로 공식화하는 것은 두 작업을 공동 최적화할 수 있게 하고 높은 계산 효율을 누릴 수 있기 때문에 매력적입니다. 그러나 우리는 이 두 작업이 서로 경쟁하는 경향이 있음을 발견했으며, 이를 신중히 다뤄야 합니다. 특히, 이전 연구들은 일반적으로 re-ID를 부차적인 과제로 간주하며, 이는 주된 탐지 작업에 의해 re-ID의 정확도가 크게 영향을 받습니다. 결과적으로 네트워크는 주된 탐지 작업에 편향되며, 이는 re-ID 작업에 공정하지 않습니다. 이 문제를 해결하기 위해, 우리는 앵커 없는 객체 탐지 아키텍처인 CenterNet을 기반으로 하는 간단하면서도 효과적인 접근법인 FairMOT를 제안합니다. 이는 단순히 CenterNet과 re-ID를 결합한 것이 아니라, 철저한 실증적 연구를 통해 좋은 추적 결과를 달성하기 위해 중요한 세부 설계를 제시합니다. 이 결과로 도출된 방법은 탐지와 추적 모두에서 높은 정확도를 달성합니다. 이 접근법은 여러 공공 데이터셋에서 최신 방법들을 큰 차이로 능가합니다. 소스 코드와 사전 학습된 모델은 https://github.com/ifzhang/FairMOT 에서 공개되었습니다.
Keywords
FairMOT · 다중 객체 추적 · 원샷 · 앵커 없음 · 실시간 추론
1 Introduction
다중 객체 추적(MOT)은 컴퓨터 비전에서 오랜 기간 동안 주요 목표로 여겨져 왔습니다 (Bewley et al., 2016; Wojke et al., 2017; Chen et al., 2018a; Yu et al., 2016). MOT의 목표는 영상에 등장하는 관심 객체의 궤적을 추정하는 것입니다. 이 문제를 성공적으로 해결하면 지능형 비디오 분석, 인간-컴퓨터 상호작용, 인간 활동 인식(Wang et al., 2013; Luo et al., 2017), 그리고 심지어 사회 컴퓨팅과 같은 많은 응용 분야에서 즉각적으로 이점을 얻을 수 있습니다.
기존의 대부분의 방법(Mahmoudi et al., 2019; Zhou et al., 2018; Fang et al., 2018; Bewley et al., 2016; Wojke et al., 2017; Chen et al., 2018a; Yu et al., 2016)은 문제를 두 개의 분리된 모델로 해결하려고 시도합니다. 탐지 모델은 각 프레임에서 관심 객체를 바운딩 박스 형태로 먼저 탐지한 뒤, 연결 모델이 각 바운딩 박스에 해당하는 이미지 영역에서 재식별(re-ID) 특성을 추출하여 이를 기존 궤적 중 하나와 연결하거나 정의된 특정 기준에 따라 새로운 궤적을 생성합니다.
최근 객체 탐지(Ren et al., 2015; He et al., 2017; Zhou et al., 2019a; Redmon and Farhadi, 2018; Fu et al., 2020; Sun et al., 2021b,a)와 재식별(Zheng et al., 2017a; Chen et al., 2018a)에서 주목할 만한 진전이 이루어졌으며, 이는 전반적인 추적 정확도를 향상시키는 데 기여했습니다. 그러나 이러한 2단계 방법들은 확장성 문제를 겪고 있습니다. 이들은 환경에 많은 객체가 있을 경우 실시간 추론 속도를 달성하지 못하며, 이는 두 모델이 특성을 공유하지 않으며, 영상 내에서 각 바운딩 박스마다 별도로 재식별 모델을 적용해야 하기 때문입니다.
다중 과제 학습이 성숙함에 따라(Kokkinos, 2017; Chen et al., 2018b), 하나의 네트워크에서 객체를 추정하고 재식별 특성을 학습하는 원샷 추적기가 더 많은 주목을 받고 있습니다(Wang et al., 2020b; Voigtlaender et al., 2019). 예를 들어, Voigtlaender et al. (Voigtlaender et al., 2019)은 Mask R-CNN에 재식별 분기를 추가하여 각 제안(proposal)에 대해 재식별 특성을 추출합니다(He et al., 2017). 이는 재식별 네트워크에 백본 특성을 재사용함으로써 추론 시간을 줄입니다. 그러나 성능은 2단계 모델에 비해 상당히 떨어집니다. 사실 탐지 정확도는 여전히 우수하지만 추적 성능은 크게 저하됩니다. 예를 들어, ID 전환 횟수가 대폭 증가합니다. 이 결과는 두 작업을 결합하는 것이 단순하지 않은 작업이며 신중히 다뤄야 함을 시사합니다.
이 논문에서는 실패의 원인을 조사하고 간단하면서도 효과적인 해결책을 제시합니다. 세 가지 요인이 실패를 설명하기 위해 식별되었습니다. 첫 번째 문제는 앵커(anchor)에서 발생합니다. 앵커는 원래 객체 탐지를 위해 설계된 것입니다(Ren et al., 2015). 그러나 우리는 앵커가 두 가지 이유로 re-ID 특성 추출에 적합하지 않음을 보여줍니다. 첫째, Track R-CNN(Voigtlaender et al., 2019)과 같은 앵커 기반 원샷 추적기는 RPN(Ren et al., 2015)을 사용해 객체를 먼저 탐지하고, 탐지 결과를 기반으로 re-ID 특성을 추출해야 하기 때문에 re-ID 작업을 간과합니다(re-ID 특성은 탐지 결과가 정확하지 않으면 쓸모없습니다). 따라서 두 작업 간 경쟁이 발생하면 탐지 작업에 유리하게 작용합니다. 또한, 앵커는 학습 과정에서 많은 모호성을 초래합니다. 특히 혼잡한 장면에서는 하나의 앵커가 여러 신원을 나타내거나 여러 앵커가 하나의 신원을 나타낼 수 있습니다.
두 번째 문제는 두 작업 간의 특성 공유에서 발생합니다. 탐지 작업과 re-ID 작업은 완전히 다른 작업이며, 서로 다른 특성을 필요로 합니다. 일반적으로 re-ID 특성은 동일 클래스의 다른 인스턴스를 구별하기 위해 더 낮은 수준의 특성을 필요로 하는 반면, 탐지 특성은 서로 다른 인스턴스 간 유사성을 필요로 합니다. 원샷 추적기에서의 공유 특성은 특성 충돌로 이어지며 각 작업의 성능을 저하시킵니다.
세 번째 문제는 특성 차원에서 발생합니다. re-ID 특성의 차원은 일반적으로 512(Wang et al., 2020b) 또는 1024(Zheng et al., 2017a)로, 객체 탐지보다 훨씬 높습니다. 우리는 이러한 차원 간 큰 차이가 두 작업의 성능을 해칠 것임을 발견했습니다. 더 중요한 점은, 우리의 실험은 “공동 탐지 및 re-ID” 네트워크를 위한 저차원 re-ID 특성을 학습하는 것이 더 높은 추적 정확도와 효율성을 달성하는 일반적인 규칙임을 제안합니다. 이는 또한 MOT 작업과 re-ID 작업 간의 차이를 드러내며, 이는 MOT 분야에서 간과된 문제입니다.
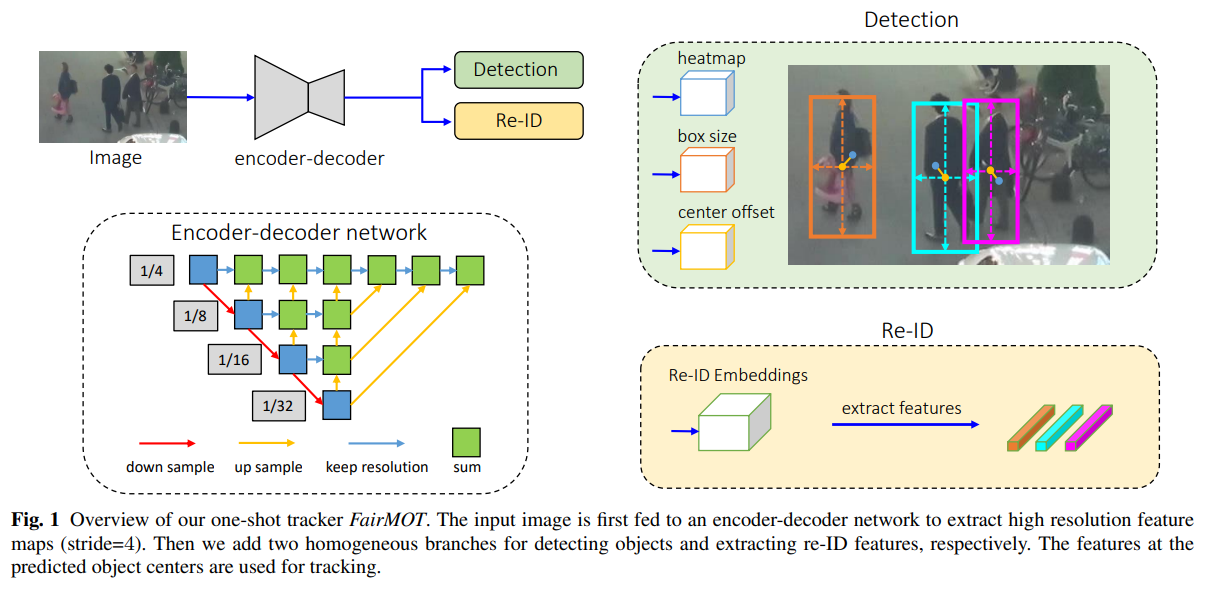
이 연구에서는 그림 1에 설명된 세 가지 문제를 우아하게 해결하는 FairMOT라는 간단한 접근 방식을 제시합니다. FairMOT는 CenterNet(Zhou et al., 2019a)을 기반으로 구축되었습니다. 특히, FairMOT에서는 탐지 작업과 re-ID 작업이 동등하게 다루어지며, 이는 이전의 “탐지 우선, re-ID 후속” 프레임워크와 본질적으로 다릅니다. 주목할 점은 이것이 단순히 CenterNet과 re-ID의 단순 결합이 아니라는 것입니다. 대신, 철저한 실증 연구를 통해 좋은 추적 결과를 달성하기 위해 중요한 세부 설계를 다수 제시합니다.
그림 1은 FairMOT의 개요를 보여줍니다. 이 네트워크는 객체 탐지와 re-ID 특성 추출을 각각 담당하는 두 개의 동일한 분기로 구성된 간단한 구조를 가지고 있습니다. (Zhou et al., 2019a; Law and Deng, 2018; Zhou et al., 2019b; Duan et al., 2019)에서 영감을 받아, 탐지 분기는 앵커 없는(anchor-free) 스타일로 구현되었으며, 객체 중심과 크기를 위치 인식 측정 맵으로 추정합니다. 유사하게, re-ID 분기는 각 픽셀에 대한 re-ID 특성을 추정하여 해당 픽셀의 중심 객체를 특성화합니다. 두 분기는 완전히 동질적이며, 이는 탐지와 re-ID를 두 단계로 수행하는 이전 방법과 본질적으로 다릅니다. 따라서 FairMOT는 표 1에서 나타난 탐지 분기의 불공정한 단점을 제거하고, 고품질 re-ID 특성을 효과적으로 학습하며 탐지와 re-ID 간에 적절한 균형을 이룹니다.
우리는 평가 서버를 통해 MOT Challenge 벤치마크에서 FairMOT를 평가했습니다. FairMOT는 2DMOT15(Leal-Taixé et al., 2015), MOT16(Milan et al., 2016), MOT17(Milan et al., 2016), MOT20(Dendorfer et al., 2020) 데이터셋에서 모든 추적기 중 1위를 차지했습니다. 제안된 단일 이미지 학습 방법을 사용하여 모델을 사전 학습했을 때, 모든 데이터셋에서 추가적인 성능 향상을 달성했습니다. 강력한 결과에도 불구하고 이 접근법은 매우 간단하며, 단일 RTX 2080Ti GPU에서 초당 30 프레임으로 실행됩니다. 이 방법은 MOT에서 탐지와 re-ID 간의 관계를 밝히고, 원샷 비디오 추적 네트워크 설계에 대한 지침을 제공합니다.
- 기존 앵커 기반 원샷 MOT 아키텍처가 효과적인 re-ID 특성 학습 측면에서 제한이 있음을 실증적으로 보여주었습니다. 이러한 문제는 해당 방법들의 추적 성능을 심각하게 제한합니다.
- 우리는 공정성 문제를 해결하기 위해 FairMOT를 제시했습니다. FairMOT는 CenterNet을 기반으로 구축되었습니다. 채택된 기술들이 자체적으로는 대부분 새롭지 않지만, MOT에서 중요한 새로운 발견을 포함하고 있으며, 이는 새롭고 가치 있습니다.
- 우리가 달성한 공정성은 FairMOT가 높은 수준의 탐지 및 추적 정확도를 달성하고 2DMOT15, MOT16, MOT17, MOT20과 같은 여러 데이터셋에서 이전 최신 방법들을 큰 차이로 능가할 수 있도록 합니다.
2 Related Work
가장 성능이 뛰어난 MOT 방법들(Bergmann et al., 2019; Brasó and Leal-Taixé, 2020; Hornakova et al., 2020; Yu et al., 2016; Mahmoudi et al., 2019; Zhou et al., 2018; Wojke et al., 2017; Chen et al., 2018a; Wang et al., 2020b; Voigtlaender et al., 2019; Zhang et al., 2021a)은 일반적으로 tracking-by-detection 패러다임을 따릅니다. 이는 각 프레임에서 객체를 먼저 탐지한 뒤, 시간에 따라 이를 연관시키는 방식입니다. 우리는 기존 연구를 객체 탐지와 연관 특성을 추출하는 데 단일 모델을 사용하는지, 또는 분리된 모델을 사용하는지에 따라 두 가지 범주로 분류합니다. 또한 이러한 방법들의 장단점을 논의하고, 이를 우리 접근법과 비교합니다.
2.1 Detection and Tracking by Separate Models
2.1.1 Detection Methods
MOT17(Milan et al., 2016)과 같은 대부분의 벤치마크 데이터셋은 DPM(Felzenszwalb et al., 2008), Faster R-CNN(Ren et al., 2015), SDP(Yang et al., 2016)과 같은 인기 있는 방법으로 얻어진 탐지 결과를 제공합니다. 이를 통해 추적 부분에 중점을 둔 연구들이 동일한 객체 탐지 결과를 기준으로 공정하게 비교될 수 있습니다. (Yu et al., 2016; Wojke et al., 2017; Zhou et al., 2018; Mahmoudi et al., 2019)과 같은 연구들은 VGG-16(Simonyan and Zisserman, 2014)을 백본으로 사용하는 Faster R-CNN 탐지기를 훈련하기 위해 대규모의 비공개 보행자 탐지 데이터셋을 활용하여 더 나은 탐지 성능을 달성합니다. (Han et al., 2020)과 같은 소수의 연구들은 Cascade R-CNN(Cai and Vasconcelos, 2018)과 같이 최근 개발된 더 강력한 탐지기를 사용하여 탐지 성능을 향상시킵니다.
2.1.2 Tracking Methods
기존 연구의 대부분은 문제의 추적 부분에 초점을 맞춥니다. 우리는 연관에 사용된 단서의 유형에 따라 이를 두 가지 범주로 분류합니다.
Location and Motion Cues based Methods
SORT(Bewley et al., 2016)는 먼저 칼만 필터(Kalman, 1960)를 사용해 트랙렛의 미래 위치를 예측하고, 탐지 결과와의 겹침을 계산한 다음 헝가리안 알고리즘(Kuhn, 1955)을 사용해 탐지를 트랙렛에 할당합니다. IOU-Tracker(Bochinski et al., 2017)는 미래 위치를 예측하기 위해 칼만 필터를 사용하지 않고 이전 프레임의 트랙렛과 탐지 결과 간의 겹침을 직접 계산합니다. 이 접근법은 100K fps 추론 속도를 달성하며(탐지 시간은 제외), 객체의 움직임이 적을 때 잘 작동합니다. SORT와 IOU-Tracker는 단순성 때문에 실제로 널리 사용됩니다.
그러나 이 방법들은 복잡한 군중 장면과 빠른 움직임 같은 도전적인 경우에는 실패할 수 있습니다. (Xiang et al., 2015; Zhu et al., 2018; Chu and Ling, 2019; Chu et al., 2019)과 같은 연구는 정확한 객체 위치를 얻고 오탐(False Negatives)을 줄이기 위해 정교한 단일 객체 추적 방법을 활용합니다.
그러나 이러한 방법들은 특히 장면에 많은 사람들이 있을 때 매우 느립니다. 궤적 단편화 문제를 해결하기 위해 Zhang et al.(Zhang et al., 2020)은 트랙렛의 장거리 특성을 학습하기 위한 동작 평가 네트워크를 제안합니다. MAT(Han et al., 2020)은 향상된 SORT로, 카메라 동작을 추가로 모델링하고 장거리 재연결을 위한 동적 창(dynamic window)을 사용합니다.
Appearance Cues based Methods
(Yu et al., 2016; Mahmoudi et al., 2019; Zhou et al., 2018; Wojke et al., 2017)과 같은 최근 연구는 탐지된 이미지 영역을 잘라내고 이를 re-ID 네트워크(Zheng et al., 2017b; Hermans et al., 2017; Luo et al., 2019a)에 입력하여 이미지 특성을 추출하는 방법을 제안합니다. 그런 다음 re-ID 특성을 기반으로 트랙렛과 탐지 결과 간 유사성을 계산하고 헝가리안 알고리즘(Kuhn, 1955)을 사용해 할당을 수행합니다. 이 방법은 빠른 움직임과 가림(occlusion)에 강합니다. 특히, 외형 특성이 시간이 지남에 따라 비교적 안정적이기 때문에 분실된 궤적을 재초기화할 수 있습니다.
(Bae and Yoon, 2014; Tang et al., 2017; Sadeghian et al., 2017; Chen et al., 2018a; Xu et al., 2019)과 같은 연구는 외형 특성을 강화하는 데 중점을 둡니다. 예를 들어, Bae et al.(Bae and Yoon, 2014)은 외형 변화를 처리하기 위한 온라인 외형 학습 방법을 제안합니다. Tang et al.(Tang et al., 2017)은 외형 특성을 강화하기 위해 신체 자세 특성을 활용합니다. (Sadeghian et al., 2017; Xu et al., 2019; Shan et al., 2020)과 같은 몇몇 방법들은 더 신뢰할 수 있는 유사성을 얻기 위해 움직임, 외형 및 위치와 같은 다중 단서를 융합하는 방법을 제안합니다. MOTDT(Chen et al., 2018a)는 외형 특성이 신뢰할 수 없을 때 객체를 연관시키기 위해 IoU를 사용하는 계층적 데이터 연관 전략을 제안합니다. (Mahmoudi et al., 2019; Zhou et al., 2018; Fang et al., 2018)과 같은 일부 연구는 그룹 모델 및 RNN과 같은 더 복잡한 연관 전략을 사용하는 것을 제안합니다.
Offline Methods
오프라인 방법(또는 배치 방법)(Zhang et al., 2008; Wen et al., 2014; Berclaz et al., 2011; Zamir et al., 2012; Milan et al., 2013; Choi, 2015; Brasó and Leal-Taixé, 2020; Hornakova et al., 2020)은 전체 시퀀스에서 전역 최적화를 수행함으로써 더 나은 결과를 달성하는 경우가 많습니다. 예를 들어, Zhang et al.(Zhang et al., 2008)은 모든 프레임에서 탐지를 나타내는 노드를 가진 그래프 모델을 구축합니다. 최적 할당은 그래프의 특정 구조를 활용해 선형 계획법보다 더 빠르게 최적점에 도달하는 최소 비용 흐름(min-cost flow) 알고리즘을 사용해 검색됩니다. Berclaz et al.(Berclaz et al., 2011)은 데이터 연관을 흐름 최적화 작업으로 간주하고 K-최단 경로 알고리즘을 사용해 이를 해결하며, 이는 계산 속도를 크게 높이고 조정해야 할 매개변수를 줄입니다. Milan et al.(Milan et al., 2013)은 다중 객체 추적을 연속 에너지 최소화로 공식화하고 에너지 함수 설계에 중점을 둡니다. 에너지는 모든 프레임에서의 모든 대상의 위치와 움직임 및 물리적 제약에 따라 달라집니다. MPNTrack(Brasó and Leal-Taixé, 2020)은 탐지 세트 전체를 전역적으로 연관시키기 위해 학습 가능한 그래프 신경망을 제안하며, 이를 통해 MOT를 완전히 미분 가능하게 만듭니다. Lif.T(Hornakova et al., 2020)은 MOT를 리프트된 비분리 경로 문제로 공식화하고 장기적 시간 상호작용을 위한 리프트된 엣지를 도입하며, 이를 통해 ID 전환과 재식별 손실을 크게 줄입니다.
Advantages and Limitations
탐지와 추적을 별도 모델로 수행하는 방법의 주요 장점은 각 작업에 가장 적합한 모델을 타협 없이 개별적으로 개발할 수 있다는 점입니다. 또한, 탐지된 바운딩 박스에 따라 이미지 패치를 잘라내고 이를 동일한 크기로 조정한 후 re-ID 특성을 추정할 수 있습니다. 이는 객체의 크기 변화를 처리하는 데 도움이 됩니다. 결과적으로 이러한 접근법(Yu et al., 2016; Henschel et al., 2019)은 공공 데이터셋에서 최고의 성능을 달성했습니다. 그러나 두 작업이 공유 없이 별도로 수행되어야 하기 때문에 일반적으로 매우 느립니다. 따라서 많은 응용 프로그램에서 요구되는 비디오 속도 추론을 달성하기는 어렵습니다.
2.2 Detection and Tracking by a Single Model
딥러닝에서 다중 과제 학습(Kokkinos, 2017; Ranjan et al., 2017; Sener and Koltun, 2018)의 빠른 성숙과 함께, 단일 네트워크를 사용한 탐지와 추적 통합이 더 많은 연구 관심을 끌기 시작했습니다. 우리는 이를 다음에 논의된 두 가지 범주로 분류합니다.
Joint Detection and Re-ID
첫 번째 방법군(Voigtlaender et al., 2019; Wang et al., 2020b; Liang et al., 2020; Pang et al., 2021; Lu et al., 2020)은 객체 탐지와 re-ID 특성 추출을 단일 네트워크에서 수행하여 추론 시간을 줄입니다. 예를 들어, Track-RCNN(Voigtlaender et al., 2019)은 Mask R-CNN(He et al., 2017)에 re-ID 헤드를 추가하여 각 제안에 대해 바운딩 박스와 re-ID 특성을 회귀(regression)합니다. 유사하게, JDE(Wang et al., 2020b)는 YOLOv3(Redmon and Farhadi, 2018)를 기반으로 구축되어 거의 비디오 속도 수준의 추론을 달성합니다. 그러나 이러한 원샷 추적기의 정확도는 일반적으로 2단계 방법보다 낮습니다.
Joint Detection and Motion Prediction
두 번째 방법군(Feichtenhofer et al., 2017; Zhou et al., 2020; Pang et al., 2020; Peng et al., 2020; Sun et al., 2020)은 단일 네트워크에서 탐지 및 동작 특성을 학습합니다. D&T(Feichtenhofer et al., 2017)는 인접 프레임의 입력을 받아 바운딩 박스 간의 프레임 간 변위를 예측하는 시아미즈 네트워크를 제안합니다. Tracktor(Bergmann et al., 2019)는 바운딩 박스 회귀 헤드를 직접 활용하여 영역 제안의 신원을 전달하며, 이에 따라 박스 연관을 제거합니다. Chained-Tracker(Peng et al., 2020)는 인접 프레임 쌍을 입력으로 사용하여 동일한 대상을 나타내는 박스 쌍을 생성하는 엔드투엔드 모델을 제안합니다. 이러한 박스 기반 방법은 저프레임 비디오에서 사실이 아닌 큰 프레임 간 겹침을 가정합니다. 이러한 방법들과 달리, CenterTrack(Zhou et al., 2020)은 객체 중심 변위를 예측하고 쌍별 입력을 사용하여 해당 점 거리를 통해 연관합니다. 또한 트랙렛을 네트워크의 추가적인 점 기반 히트맵 입력으로 제공하여 바운딩 박스가 전혀 겹치지 않아도 객체를 어디에서든 매칭할 수 있습니다. 그러나 이러한 방법은 인접 프레임의 객체만 연관시키며 분실된 트랙을 재초기화하지 않아 가림(occlusion) 문제를 처리하는 데 어려움을 겪습니다.
우리 연구는 첫 번째 방법군에 속합니다. 우리는 원샷 추적기의 연관 성능 저하 원인을 조사하고, 문제를 해결하기 위한 간단한 접근 방식을 제안합니다. 우리는 복잡한 공학적 노력 없이도 추적 정확도가 크게 향상됨을 보여줍니다. 동시 연구인 CSTrack(Liang et al., 2020) 또한 특성 관점에서 두 작업 간의 충돌을 완화하려고 하며, 모델이 작업 종속 표현을 학습할 수 있도록 크로스 상관 네트워크 모듈을 제안합니다. CSTrack과 달리, 우리의 방법은 문제를 세 가지 관점에서 체계적으로 해결하려고 하며 CSTrack보다 현저히 우수한 성능을 얻습니다. CenterTrack(Zhou et al., 2020) 또한 센터 기반 객체 탐지 프레임워크를 사용하기 때문에 우리의 연구와 관련이 있습니다. 그러나 CenterTrack은 외형 특성을 추출하지 않고 인접 프레임의 객체만 연관시킵니다. 반면, FairMOT는 외형 특성을 사용하여 장거리 연관을 수행하고 가림 문제를 처리할 수 있습니다.
Multi-task Learning
다중 과제 학습에 대한 풍부한 문헌이 있으며(Liu et al., 2019; Kendall et al., 2018; Chen et al., 2018b; Guo et al., 2018; Sener and Koltun, 2018), 이는 객체 탐지와 re-ID 특성 추출 작업을 균형 있게 조정하는 데 사용될 수 있습니다. Uncertainty(Kendall et al., 2018)는 작업 종속적인 불확실성을 사용해 단일 작업 손실을 자동으로 균형 조정합니다. MGDA는(Sener and Koltun, 2018) 작업별 그래디언트 간의 공통 방향을 찾아 공유 네트워크 가중치를 업데이트하는 방법을 제안합니다. GradNorm(Chen et al., 2018b)은 작업별 그래디언트의 크기를 유사하게 시뮬레이션하여 다중 작업 네트워크의 학습을 제어합니다. 우리는 실험 섹션에서 이러한 방법들을 평가합니다.
2.3 Video Object Detection
비디오 객체 탐지(VOD)(Feichtenhofer et al., 2017; Luo et al., 2019b)는 추적을 활용해 도전적인 프레임에서 객체 탐지 성능을 향상시키는 점에서 MOT와 관련이 있습니다. 이러한 방법들이 MOT 데이터셋에서 평가되지는 않았지만, 몇 가지 아이디어는 이 분야에 유용할 수 있습니다. 따라서 이 섹션에서 간략히 검토합니다. Tang et al.(Tang et al., 2019)은 비디오에서 객체 튜브를 탐지하여 이웃 프레임을 기반으로 어려운 프레임에서의 분류 점수를 향상시키는 것을 목표로 합니다. 작은 객체의 탐지율은 벤치마크 데이터셋에서 큰 폭으로 증가합니다. 유사한 아이디어는 (Han et al., 2016; Kang et al., 2016, 2017; Tang et al., 2019; Pang et al., 2020)에서도 탐구되었습니다. 튜브 기반 방법의 주요 한계는 비디오에 많은 객체가 있을 경우 특히 매우 느리다는 점입니다.
3 Unfairness Issues in One-shot Trackers
이 섹션에서는 기존 원샷 추적기에서 발생하는 세 가지 불공정성 문제를 논의합니다. 이러한 문제는 일반적으로 추적 성능 저하로 이어집니다.
3.1 Unfairness Caused by Anchors
Track R-CNN(Voigtlaender et al., 2019)과 JDE(Wang et al., 2020b)와 같은 기존 원샷 추적기는 대부분 앵커 기반이며, 이는 YOLO(Redmon and Farhadi, 2018) 및 Mask R-CNN(He et al., 2017)과 같은 앵커 기반 객체 탐지기를 직접 수정하여 만들어졌습니다. 그러나 우리는 앵커 기반 설계가 re-ID 특성 학습에 적합하지 않으며, 이는 우수한 탐지 결과에도 불구하고 많은 ID 전환을 초래한다는 것을 발견했습니다. 우리는 이 문제를 세 가지 관점에서 설명합니다.
Overlooked re-ID task
Track R-CNN(Voigtlaender et al., 2019)은 계단식 스타일로 작동하며, 먼저 객체 제안(박스)을 추정한 후, 해당하는 re-ID 특성을 추정하기 위해 이들로부터 특성을 풀링합니다. re-ID 특성의 품질은 학습 중 제안의 품질에 크게 의존합니다(제안이 정확하지 않으면 re-ID 특성은 쓸모가 없습니다). 결과적으로, 학습 단계에서 모델은 고품질 re-ID 특성보다는 정확한 객체 제안을 추정하는 데 편향됩니다. 따라서 기존 원샷 추적기의 “탐지 우선, re-ID 후속” 설계는 re-ID 네트워크를 공정하게 학습하지 못하게 만듭니다.
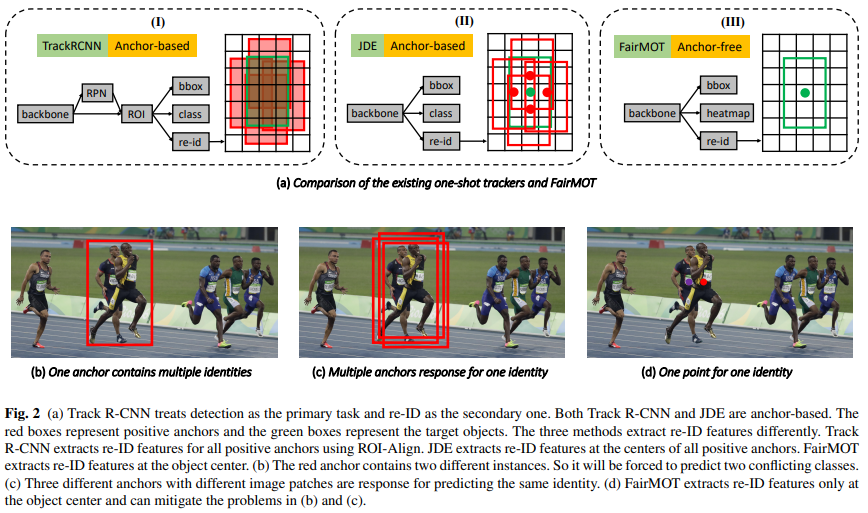
One anchor corresponds to multiple identities
앵커 기반 방법은 일반적으로 ROI-Align을 사용하여 제안에서 특성을 추출합니다. ROI-Align에서 대부분의 샘플링 위치는 그림 2에 표시된 것처럼 다른 방해 객체 또는 배경에 속할 수 있습니다. 결과적으로, 추출된 특성은 대상 객체를 정확하고 차별적으로 표현하는 데 최적이 아닙니다. 대신, 이 연구에서는 추정된 객체 중심이라는 단일 지점에서만 특성을 추출하는 것이 훨씬 더 효과적임을 발견했습니다.
Multiple anchors correspond to one identity
(Voigtlaender et al., 2019) 및 (Wang et al., 2020b) 모두에서 여러 인접한 앵커가 다른 이미지 패치에 해당하지만, IOU가 충분히 큰 경우 동일한 신원을 추정하도록 강요될 수 있습니다. 이는 학습에 심각한 모호성을 초래합니다. 자세한 내용은 그림 2를 참조하십시오. 한편, 데이터 증강과 같은 작은 이미지 변동이 발생할 경우 동일한 앵커가 서로 다른 신원을 추정하도록 강요될 수 있습니다. 더욱이, 객체 탐지에서 특성 맵은 정확도와 속도의 균형을 맞추기 위해 일반적으로 8/16/32배 다운샘플링됩니다. 이는 객체 탐지에는 허용 가능하지만, re-ID 특성을 학습하기에는 너무 조잡합니다. 이는 조잡한 앵커에서 추출된 특성이 객체 중심과 정렬되지 않을 수 있기 때문입니다.
3.2 Unfairness Caused by Features
원샷 추적기에서 대부분의 특성은 객체 탐지와 re-ID 작업 간에 공유됩니다. 하지만 최상의 결과를 얻기 위해서는 실제로 서로 다른 계층의 특성을 필요로 한다는 것이 잘 알려져 있습니다. 특히, 객체 탐지는 객체의 클래스와 위치를 추정하기 위해 깊은 특성을 필요로 하지만, re-ID는 동일 클래스의 다른 인스턴스를 구별하기 위해 낮은 수준의 외형 특성을 필요로 합니다. 다중 작업 손실 최적화 관점에서 보면, 탐지와 re-ID의 최적화 목표는 상충됩니다. 따라서 두 작업의 손실 최적화 전략을 균형 있게 조정하는 것이 중요합니다.
3.3 Unfairness Caused by Feature Dimension
기존 re-ID 연구들은 일반적으로 매우 높은 차원의 특성을 학습하며, 해당 분야의 벤치마크에서 유망한 결과를 달성했습니다. 그러나 우리는 낮은 차원의 특성을 학습하는 것이 원샷 MOT에 실제로 더 적합하다는 것을 세 가지 이유에서 발견했습니다: (1)높은 차원의 re-ID 특성은 두 작업 간의 경쟁으로 인해 객체 탐지 정확도를 현저히 저해하며, 이는 최종 추적 정확도에도 부정적인 영향을 미칩니다. 객체 탐지에서의 특성 차원은 일반적으로 매우 낮습니다(클래스 수 + 박스 위치). 따라서 두 작업을 균형 있게 하기 위해 낮은 차원의 re-ID 특성을 학습할 것을 제안합니다. (2)MOT 작업은 re-ID 작업과 다릅니다. MOT 작업은 두 연속된 프레임 간의 소수의 1대1 매칭만 수행합니다. 반면, re-ID 작업은 많은 후보들 중에서 쿼리를 매칭해야 하며, 이로 인해 더 차별적이고 고차원의 re-ID 특성이 필요합니다. 따라서 MOT에서는 그렇게 높은 차원의 특성을 필요로 하지 않습니다. (3)낮은 차원의 re-ID 특성을 학습하면 추론 속도가 개선되며, 이는 실험에서 보여질 것입니다.
4 FairMOT
이 섹션에서는 FairMOT의 백본 네트워크, 객체 탐지 분기, re-ID 분기 및 학습 세부 정보를 소개합니다.
4.1 Backbone Network
FairMOT는 정확도와 속도의 균형을 맞추기 위해 ResNet-34를 백본으로 채택합니다. Deep Layer Aggregation (DLA)(Zhou et al., 2019a)의 향상된 버전이 백본에 적용되어 그림 1과 같이 다중 계층 특성을 융합합니다. 기존 DLA(Yu et al., 2018)와 달리, 낮은 수준과 높은 수준의 특성 간에 더 많은 스킵 연결을 가지며, 이는 Feature Pyramid Network (FPN)(Lin et al., 2017a)와 유사합니다. 또한, 모든 업샘플링 모듈의 합성곱 계층이 변형 가능한 합성곱으로 대체되어 객체 크기와 자세에 따라 동적으로 수용 필드를 조정할 수 있습니다. 이러한 수정은 정렬 문제를 완화하는 데에도 유용합니다. 결과 모델은 DLA-34로 명명됩니다. 입력 이미지 크기를 $H_{\text{image}} \times W_{\text{image}}$로 나타내면, 출력 특성 맵은 $C×H×W$ 형식을 가지며, 여기서 $H=H_{\text{image}}/4, W=W_{\text{image}} /4$ 입니다. DLA 외에도, Higher HRNet(Cheng et al., 2020)과 같이 다중 스케일 합성곱 특성을 제공하는 다른 심층 네트워크를 프레임워크에 사용하여 탐지와 re-ID 모두에 공정한 특성을 제공할 수 있습니다.
4.2 Detection Branch
우리의 탐지 분기는 CenterNet(Zhou et al., 2019a)을 기반으로 구축되었으며, (Duan et al., 2019; Law and Deng, 2018; Dong et al., 2020; Yang et al., 2019)과 같은 다른 앵커 없는(anchor-free) 방법도 사용할 수 있습니다. 이 작업을 독립적으로 이해할 수 있도록 접근 방식을 간략히 설명합니다. 특히, DLA-34에 세 개의 병렬 헤드를 추가하여 각각 히트맵, 객체 중심 오프셋 및 바운딩 박스 크기를 추정합니다. 각 헤드는 DLA-34의 출력 특성에 대해 $3×3$ 합성곱(256 채널)을 적용한 후, $1×1$ 합성곱 계층을 통해 최종 목표를 생성합니다.
4.2.1 Heatmap Head
이 헤드는 객체 중심의 위치를 추정하는 역할을 합니다. 랜드마크 포인트 추정 작업의 사실상 표준인 히트맵 기반 표현을 여기서 채택했습니다. 특히, 히트맵의 차원은 $1×H×W$ 입니다. 히트맵의 특정 위치에서 응답 값은 해당 위치가 실제 객체 중심과 일치하면 1로 예상됩니다. 히트맵 위치와 객체 중심 간 거리가 멀어질수록 응답 값은 지수적으로 감소합니다.
이미지의 각 GT 박스 $\mathbb{b}^i=(x_1^i,y_1^i,x_2^i,y_2^i)$ 에 대해 객체 중심 $(c_x^i,c_y^i)$ 를 $c_x^i= \frac{x_1^i+x_2^i}{2}$, $c_y^i=\frac{y_1^i+y_2^i}{2}$ 로 계산합니다. 그런 다음, 피처 맵에서의 위치는 스트라이드로 나눠 계산되며 $(\tilde{c}_x^i, \tilde{c}_y^i)=(\lfloor\frac{c_x^i}{4}\rfloor, \lfloor\frac{c_y^i}{4}\rfloor)$ 입니다. 히트맵의 위치 $(x,y)$ 에서의 응답은 $M_{xy}=\sum_{i=1}^N \exp^{(-\frac{(x-\tilde{c}_x^i)^2+(y-\tilde{c}_y^i)^2}{2\sigma_c^2})}$ 로 계산되며, 여기서 $N$은 이미지 내 객체의 수를, $\sigma_c$ 는 표준 편차를 나타냅니다. 손실 함수는 초점 손실(focal loss)을 사용한 픽셀 단위 로지스틱 회귀로 정의됩니다:
여기서 $\hat{M}$ 은 추정된 히트맵이고, $α,β$ 는 초점 손실의 사전 설정된 매개변수입니다.
4.2.2 Box Offset and Size Heads
박스 오프셋 헤드는 객체를 더 정밀하게 로컬라이즈하는 것을 목표로 합니다. 최종 피처 맵의 스트라이드가 4이기 때문에 최대 4픽셀까지의 양자화 오류가 발생할 수 있습니다. 이 분기는 다운샘플링의 영향을 완화하기 위해 각 픽셀에 대해 객체 중심에 상대적인 연속적인 오프셋을 추정합니다. 박스 크기 헤드는 각 위치에서 대상 박스의 높이와 너비를 추정하는 역할을 합니다. 크기 및 오프셋 헤드의 출력을 각각 $\hat{S}∈\mathbb{R}^{2×H×W}$ 및 $\hat{O}∈\mathbb{R}^{2×H×W}$ 로 나타냅니다. 이미지에서 각 GT 박스 $\mathbf{b}^i=(x_1^i,y_1^i,x_2^i,y_2^i)$ 에 대해 크기는 %s_i=(x_2^i−x_1^i,y_2^i−y_1^i)$ 로 계산합니다. 유사하게, GT 오프셋은 $o^i=(\frac{c_x^i}{4}, \frac{c_y^i}{4})-(\lfloor\frac{c_x^i}{4}\rfloor, \lfloor\frac{c_y^i}{4}\rfloor)$ 로 계산합니다. 해당 위치에서 추정된 크기와 오프셋을 각각 $\hat{s}^i$ 및 $\hat{o}^i$ 로 나타냅니다. 그런 다음 두 헤드에 대해 %l_1$ 손실을 적용합니다:
\[L_{\text{box}}=\sum_{i=1}^N\Vert \mathbf{o}^i-\hat{\mathbf{o}}^i\Vert_1 + \lambda_s \Vert \mathbf{s}^i-\hat{\mathbf{s}}^i\Vert_1. \tag{2}\]여기서 $λ_s$ 는 가중 매개변수이며, CenterNet(Zhou et al., 2019a)에서 설정한 값인 0.1로 설정됩니다.
4.3 Re-ID Branch
Re-ID 분기는 객체를 구별할 수 있는 특성을 생성하는 것을 목표로 합니다. 이상적으로는 서로 다른 객체 간의 유사성은 동일한 객체 간의 유사성보다 작아야 합니다. 이 목표를 달성하기 위해, 백본 특성 위에 128개의 커널을 가진 합성곱 계층을 적용하여 각 위치에서 re-ID 특성을 추출합니다. 결과 특성 맵을 $\mathbf{E}∈\mathbb{R}^{128×H×W}$ 로 나타냅니다. 중심이 $(x,y)$ 인 객체의 re-ID 특성 $\mathbf{E}_{x,y}∈\mathbb{R}^{128}$ 는 특성 맵에서 추출될 수 있습니다.
4.3.1 Re-ID Loss
우리는 분류 작업을 통해 re-ID 특성을 학습합니다. 학습 세트에서 동일한 신원을 가진 모든 객체 인스턴스는 동일한 클래스로 간주됩니다. 이미지에서 각 GT 박스 $\mathbf{b}^i=(x_1^i,y_1^i,x_2^i,y_2^i)$ 에 대해 히트맵에서 객체 중심 $(\tilde{c}^i_x, \tilde{c}^i_y)$ 을 얻습니다. 우리는 re-ID 특성 벡터 $\mathbf{E}_{\tilde{c^i_x}, \tilde{c}^i_y}$ 를 추출하고, 이를 완전 연결 계층과 소프트맥스 연산을 사용하여 클래스 분포 벡터 $\mathbf{P}=\lbrace\mathbf{p}(k),k∈[1,K]\rbrace$ 로 매핑합니다. GT 클래스 레이블의 원-핫 표현을 $\mathbf{L}^i(k)$ 로 나타냅니다. 그런 다음, re-ID 손실은 다음과 같이 계산됩니다:
\[L_{\text{identity}} = -\sum_{i=1}^N \sum_{k=1}^K \mathbf{L}^i(k)\log(\mathbf{p}(k)), \tag{3}\]여기서 $K$ 는 학습 데이터에서 모든 신원의 수를 나타냅니다. 네트워크의 학습 과정에서는 객체 중심에 위치한 신원 임베딩 벡터만 학습에 사용됩니다. 이는 테스트에서 객체 히트맵을 통해 객체 중심을 얻을 수 있기 때문입니다.
4.4 Training FairMOT
우리는 탐지 및 re-ID 분기를 Eq. (1), Eq. (2) 및 Eq. (3)의 손실을 더하여 공동으로 학습합니다. 특히, 탐지와 re-ID 작업을 자동으로 균형 잡기 위해 (Kendall et al., 2018)에서 제안된 불확실성 손실을 사용합니다:
\[L_{\text{detection}} = L{\text{heat}} + L_{\text{box}}, \tag{4}\] \[L_{\text{total}} = \frac{1}{2}(\frac{1}{e^{w1}}L_{\text{detection}}+\frac{1}{e^{w2}}L_{\text{identity}}+w_1+w_2), \tag{5}\]여기서 $w_1$ 과 $w_2$ 는 두 작업의 균형을 맞추는 학습 가능한 매개변수입니다. 구체적으로, 몇 개의 객체와 해당 ID가 포함된 이미지가 주어지면, 우리는 히트맵, 박스 오프셋 및 크기 맵, 객체의 원-핫 클래스 표현을 생성합니다. 이것들은 추정된 측정값과 비교되어 전체 네트워크를 학습하는 데 필요한 손실을 얻습니다.
위에서 설명한 표준 학습 전략 외에도, 우리는 COCO(Lin et al., 2014)와 CrowdHuman(Shao et al., 2018)과 같은 이미지 수준 객체 탐지 데이터셋에서 FairMOT를 학습하기 위해 단일 이미지 학습 방법을 제안합니다. CenterTrack(Zhou et al., 2020)이 두 개의 시뮬레이션된 연속 프레임을 입력으로 사용하는 것과 달리, 우리는 단일 이미지만 입력으로 사용합니다. 각 바운딩 박스에 고유한 신원을 할당하고 데이터셋의 각 객체 인스턴스를 별도의 클래스로 간주합니다. 우리는 HSV 증강, 회전, 스케일링, 이동, 전단(shearing)을 포함한 다양한 변환을 전체 이미지에 적용합니다. 단일 이미지 학습 방법은 중요한 실험적 가치를 지닙니다. 첫째, CrowdHuman 데이터셋에서 사전 학습된 모델은 추적기로 직접 사용될 수 있으며, MOT17(Milan et al., 2016)과 같은 MOT 데이터셋에서 허용 가능한 결과를 얻을 수 있습니다. 이는 CrowdHuman 데이터셋이 사람 탐지 성능을 향상시키고 강력한 도메인 일반화 능력을 가지기 때문입니다. 우리의 re-ID 특성 학습은 추적기의 연관 능력을 더욱 강화합니다. 둘째, 이를 다른 MOT 데이터셋에서 미세 조정(fine-tune)하여 최종 성능을 더욱 향상시킬 수 있습니다.
4.5 Online Inference
이 섹션에서는 온라인 추론을 수행하는 방법, 특히 탐지 및 re-ID 특성을 사용한 연관 방법을 설명합니다.
4.5.1 Network Inference
네트워크는 $1088×608$ 크기의 프레임을 입력으로 받으며, 이는 이전 작업 JDE(Wang et al., 2020b)와 동일합니다. 예측된 히트맵 위에서, 우리는 히트맵 점수를 기반으로 비최대 억제(NMS)를 수행하여 피크 키포인트를 추출합니다. NMS는 (Zhou et al., 2019a)에서처럼 간단한 $3×3$ 최대 풀링 연산으로 구현됩니다. 히트맵 점수가 임계값보다 큰 키포인트 위치를 유지한 다음, 추정된 오프셋 및 박스 크기를 기반으로 해당 바운딩 박스를 계산합니다. 또한, 추정된 객체 중심에서 신원 임베딩을 추출합니다. 다음 섹션에서는 re-ID 특성을 사용하여 탐지된 박스를 시간적으로 연관시키는 방법을 논의합니다.
4.5.2 Online Association
우리는 MOTDT(Chen et al., 2018a)를 따르며 계층적 온라인 데이터 연관 방법을 사용합니다. 먼저, 첫 번째 프레임에서 탐지된 박스를 기반으로 여러 트랙렛을 초기화합니다. 그런 다음 후속 프레임에서는 두 단계 매칭 전략을 사용하여 탐지된 박스를 기존 트랙렛과 연결합니다. 첫 번째 단계에서는 Kalman 필터(Kalman, 1960)와 re-ID 특성을 사용하여 초기 추적 결과를 얻습니다. 특히, Kalman 필터를 사용하여 다음 프레임에서 트랙렛 위치를 예측하고, DeepSORT(Wojke et al., 2017)을 따라 예측된 박스와 탐지된 박스 간의 마할라노비스 거리 $D_m$ 를 계산합니다. 그런 다음, 마할라노비스 거리를 re-ID 특성에서 계산된 코사인 거리와 융합합니다: $D=\lambda D_r + (1-\lambda)D_m$ 여기서 $λ$ 는 가중 매개변수이며, 우리의 실험에서는 0.98로 설정됩니다. JDE(Wang et al., 2020b)를 따라, 마할라노비스 거리가 임계값을 초과하면 이를 무한대로 설정하여 큰 움직임을 가진 궤적을 피합니다. 매칭 임계값 $τ_1=0.4$를 사용하여 Hungarian 알고리즘(Kuhn, 1955)으로 첫 번째 단계 매칭을 완료합니다.
두 번째 단계에서는 매칭되지 않은 탐지와 트랙렛을 처리하기 위해 박스 간의 겹침을 기반으로 매칭을 시도합니다. 특히, 매칭 임계값 $τ_2=0.5$ 로 설정합니다. 이 단계에서 (Bolme et al., 2010; Henriques et al., 2014)에서와 같이 외형 변화를 처리하기 위해 트랙렛의 외형 특성을 업데이트합니다. 마지막으로, 매칭되지 않은 탐지를 새로운 트랙으로 초기화하고, 매칭되지 않은 트랙렛을 30 프레임 동안 저장하여 나중에 다시 나타날 가능성에 대비합니다.
5 Experiments
5.1 Datasets and Metrics
다음과 같이 6개의 학습 데이터셋이 간략히 소개됩니다: ETH(Ess et al., 2008) 및 CityPerson(Zhang et al., 2017) 데이터셋은 박스 주석만 제공되므로 탐지 분기만 학습에 사용됩니다. CalTech(Dollár et al., 2009), MOT17(Milan et al., 2016), CUHK-SYSU(Xiao et al., 2017), PRW(Zheng et al., 2017a) 데이터셋은 박스 및 신원 주석을 모두 제공하여 두 분기 모두 학습할 수 있습니다. ETH의 일부 비디오는 MOT17 테스트 세트에 포함되어 있어 공정한 비교를 위해 학습 데이터셋에서 제거되었습니다. 전체 학습 전략은 Section 4.4에 설명되어 있으며 (Wang et al., 2020b)와 동일합니다. 우리의 방법에서 자기 지도 학습을 위해 CrowdHuman 데이터셋(Shao et al., 2018)을 사용하며, 이 데이터셋은 객체 바운딩 박스 주석만 포함합니다.
우리의 접근법은 4개의 벤치마크 테스트 세트(2DMOT15, MOT16, MOT17, MOT20)에서 평가됩니다: 탐지 결과는 평균 정밀도(AP)로 평가합니다. (Wang et al., 2020b)를 따라 re-ID 특성은 거짓 수락률 0.1에서의 진양성률(TPR@FAR=0.1)을 사용하여 평가합니다. 특히, re-ID 특성은 실제 박스에 해당하는 특성을 추출하고 각 특성을 사용하여 $N$개의 가장 유사한 후보를 검색합니다. 우리는 거짓 수락률 0.1에서 진양성률을 보고합니다(TPR@FAR=0.1). TPR은 탐지 결과의 영향을 받지 않으며 re-ID 특성의 품질을 충실히 반영합니다. 우리는 CLEAR 메트릭(Bernardin and Stiefelhagen, 2008)(즉, MOTA, IDs)과 IDF1(Ristani et al., 2016)을 사용하여 전체 추적 정확도를 평가합니다.
5.2 Implementation Details
우리는 (Zhou et al., 2019a)에서 제안된 DLA-34 변형을 기본 백본으로 사용합니다. 모델 매개변수는 COCO 데이터셋(Lin et al., 2014)에서 사전 학습된 값을 사용하여 초기화합니다. Adam 최적화 알고리즘(Kingma and Ba, 2014)을 사용해 초기 학습률 $10^{−4}$ 로 30 에포크 동안 학습합니다. 학습률은 20 에포크에서 $10^{−5}$ 로 감소합니다. 배치 크기는 12로 설정됩니다. 회전, 스케일링, 색상 조정을 포함한 표준 데이터 증강 기법을 사용합니다. 입력 이미지는 $1088×608$ 로 리사이즈되며, 피처 맵 해상도는 $272×152$ 입니다. 학습에는 RTX 2080 Ti GPU 두 대에서 약 30시간이 소요됩니다.
5.3 Ablative Studies
이 섹션에서는 FairMOT에서 앵커 없는 re-ID 특성 추출, 특성 융합, 특성 차원을 포함한 세 가지 주요 요소를 엄격히 연구하며, 여러 기준 방법을 신중히 설계하여 실험합니다.
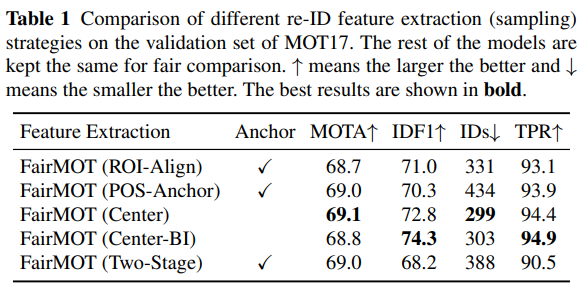
5.3.1 Anchors
우리는 탐지된 박스에서 re-ID 특성을 샘플링하는 네 가지 전략을 평가합니다. 이는 이전 연구(Wang et al., 2020b; Voigtlaender et al., 2019)에서 자주 사용된 방식입니다. 첫 번째 전략은 Track R-CNN(Voigtlaender et al., 2019)에서 사용된 ROI-Align입니다. 이는 ROI-Align을 사용하여 탐지된 제안(proposal)에서 특성을 샘플링합니다. 이전에 논의된 바와 같이, 많은 샘플링 위치가 객체 중심에서 벗어납니다. 두 번째 전략은 JDE(Wang et al., 2020b)에서 사용된 POS-Anchor입니다. 이는 양성(positive) 앵커에서 특성을 샘플링하며, 이는 또한 객체 중심에서 벗어날 수 있습니다. 세 번째 전략은 FairMOT에서 사용된 “Center”입니다. 이는 객체 중심에서만 특성을 샘플링합니다. 우리의 접근법에서 re-ID 특성은 이산화된 저해상도 맵에서 추출된다는 점을 상기하십시오. 정확한 객체 위치에서 특성을 샘플링하기 위해, 우리는 Bi-linear Interpolation(Center-BI)을 적용하여 더 정확한 특성을 추출하려고 시도합니다.
우리는 또한 먼저 객체 바운딩 박스를 탐지한 다음 re-ID 특성을 추출하는 2단계 접근법을 평가합니다. 첫 번째 단계에서 탐지 부분은 FairMOT와 동일합니다. 두 번째 단계에서는 탐지된 바운딩 박스를 기반으로 백본 특성을 추출하기 위해 ROI-Align(He et al., 2017)을 사용하고, 그다음에 re-ID 헤드(완전 연결 계층)를 사용하여 re-ID 특성을 얻습니다. 2단계 접근법과 1단계 “ROI-Align” 접근법의 주요 차이점은 2단계 접근법에서 re-ID 특성이 탐지 결과에 의존하는 반면, 1단계 접근법에서는 학습 중 탐지 결과에 의존하지 않는다는 점입니다.
결과는 표 1에 나타나 있습니다. 다섯 가지 접근법은 모두 FairMOT을 기반으로 구축됩니다. 차이점은 탐지된 박스에서 re-ID 특성을 샘플링하는 방식에 있습니다. 첫째, 우리의 접근법(Center)은 ROI-Align, POS-Anchor 및 2단계 접근법보다 IDF1 점수와 진양성률(TPR)이 상당히 높습니다. 이 메트릭은 객체 탐지 결과에 독립적이며 re-ID 특성의 품질을 충실히 반영합니다. 또한, 우리의 접근법에서 ID 전환(ID switch)의 수는 두 기준보다도 현저히 적습니다. 결과는 객체 중심에서 특성을 샘플링하는 것이 이전 연구에서 사용된 전략보다 더 효과적임을 입증합니다. Bi-linear Interpolation(Center-BI)은 더 정확한 위치에서 특성을 샘플링하므로 Center보다 더 높은 TPR을 달성합니다. 2단계 접근법은 re-ID 특성의 품질을 저하시킵니다.
5.3.2 Balancing Multi-task Losses
우리는 다양한 작업의 손실 균형을 평가하기 위해 Uncertainty(Kendall et al., 2018), GradNorm(Chen et al., 2018b), MGDA-UB(Sener and Koltun, 2018)을 포함한 여러 방법을 평가합니다. 또한, 그리드 탐색을 통해 얻은 고정 가중치를 사용한 기준선을 평가합니다. 우리는 불확실성 기반 방법에 대해 두 가지 버전을 구현했습니다. 첫 번째는 “Uncertainty-task”로, 탐지 손실과 re-ID 손실 각각에 대해 두 개의 매개변수를 학습합니다. 두 번째는 “Uncertainty-branch”로, 히트맵 손실, 박스 크기 손실, 오프셋 손실 및 re-ID 손실 각각에 대해 네 개의 매개변수를 학습합니다.
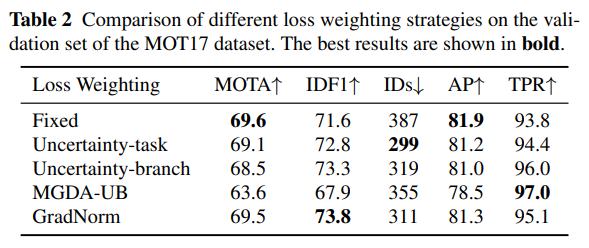
결과는 표 2에 나타나 있습니다. “Fixed” 방법은 MOTA와 AP에서 가장 높은 값을 얻었지만 IDs와 TPR에서 최악의 값을 보입니다. 이는 모델이 탐지 작업에 편향되어 있음을 의미합니다. MGDA-UB는 TPR에서 가장 높은 값을 기록했지만 MOTA와 AP에서는 가장 낮은 값을 보였으며, 이는 모델이 re-ID 작업에 편향되어 있음을 나타냅니다. 유사한 결과는 (Wang et al., 2020b; Vandenhende et al., 2021)에서도 발견됩니다. GradNorm은 전체적인 추적 정확도에서 가장 높은 IDF1과 두 번째로 높은 MOTA를 기록하며, 이는 다양한 작업이 유사한 그래디언트 크기를 갖도록 보장하는 것이 특성 충돌을 해결하는 데 도움이 됨을 의미합니다. 그러나 GradNorm은 더 긴 학습 시간이 필요합니다. 따라서 나머지 실험에서는 GradNorm보다 약간 성능이 떨어지지만 더 간단한 Uncertainty 방법을 사용했습니다.
5.3.3 Multi-layer Feature Fusion
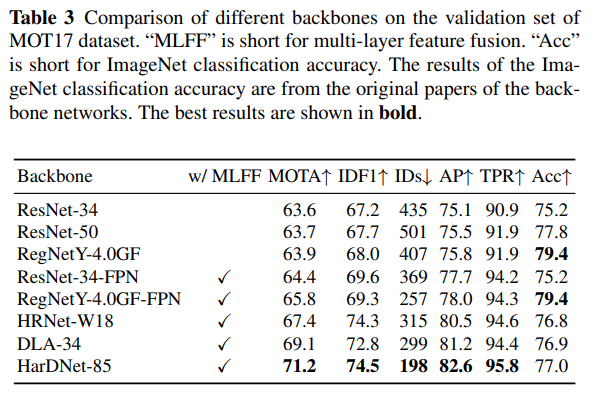
우리는 Vanilla ResNet (He et al., 2016), Feature Pyramid Network(FPN) (Lin et al., 2017a), High-Resolution Network (HRNet) (Wang et al., 2020a), DLA (Zhou et al., 2019a), HarDNet (Chao et al., 2019), RegNet (Radosavovic et al., 2020)와 같은 다양한 백본을 비교합니다. 이 접근법들의 나머지 요소, 예를 들어 학습 데이터셋, 모두 공정한 비교를 위해 동일하게 설정되었습니다. 특히, 최종 피처 맵의 스트라이드는 모든 방법에서 4로 설정되어 있습니다. 우리는 Vanilla ResNet 및 RegNet에 대해 3개의 업샘플링 연산을 추가하여 스트라이드 4의 피처 맵을 얻습니다. 이 백본들을 두 가지 카테고리로 나눕니다. 하나는 다층 융합(multi-layer fusion)이 없는 경우(예: ResNet, RegNet)이고, 다른 하나는 다층 융합이 있는 경우(예: FPN, HRNet, DLA, HarDNet)입니다.
결과는 표 3에 나와 있습니다. 우리는 ImageNet (Russakovsky et al., 2015) 분류 정확도(Acc)도 나열하여 한 작업에서 강력한 백본이 있다고 해서 반드시 MOT에서도 좋은 결과를 낼 수 있는 것은 아니라는 것을 보여줍니다. 따라서 MOT에 대한 세부적인 연구가 필요하고 유용합니다.
ResNet-34와 ResNet-50의 결과를 비교해보면, 더 큰 네트워크를 맹목적으로 사용하는 것이 MOTA로 측정한 전체 추적 결과를 크게 향상시키지 못한다는 것을 알 수 있습니다. 특히, re-ID 특성의 품질은 더 큰 네트워크에서도 거의 이점을 얻지 못합니다. 예를 들어, IDF1은 67.2%에서 67.7%로, TPR은 90.9%에서 91.9%로 각각 소폭 증가하지만, ID 전환 횟수는 435에서 501로 증가합니다. ResNet-50과 RegNetY-4.0GF를 비교해보면, 더 강력한 백본을 사용하는 것도 매우 제한된 성과를 낸다는 것을 알 수 있습니다. RegNetY-4.0GF의 re-ID 메트릭 TPR은 ResNet-50(91.9)과 동일하지만, ImageNet 분류 정확도는 크게 개선됩니다(79.4 vs 77.8). 이러한 모든 결과는 더 크거나 더 강력한 네트워크를 직접 사용하는 것이 항상 최종 추적 정확도를 향상시키지는 않는다는 것을 시사합니다.
반면, ResNet-34-FPN은 ResNet-50보다 매개변수가 적음에도 불구하고 ResNet-50보다 높은 MOTA 점수를 기록했습니다. 더 중요한 것은, TPR이 90.9%에서 94.2%로 상당히 향상되었다는 점입니다. RegNetY-4.0GF-FPN과 RegNetY-4.0GF를 비교하면, RegNet에 다층 특성 융합 구조(Lin et al., 2017a)를 추가하는 것이 상당한 이점을 가져온다는 것을 알 수 있습니다(+1.9 MOTA, +1.3 IDF1, -36.9% IDs, +2.2 AP, +2.3 TPR). 이는 다층 특성 융합이 단순히 더 크거나 더 강력한 네트워크를 사용하는 것보다 명확한 장점을 가지고 있음을 시사합니다.
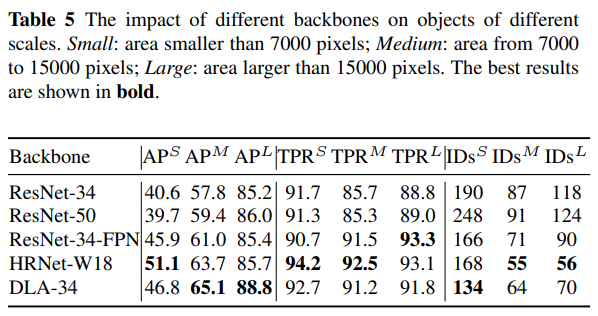
또한, ResNet-34를 기반으로 구축되었지만 더 많은 수준의 특성 융합을 포함하는 DLA-34는 더 높은 MOTA 점수를 기록합니다. 특히, TPR은 90.9%에서 94.4%로 상당히 증가하며, 이에 따라 ID 전환(ID switches) 수는 435에서 299로 감소합니다. HRNet-W18의 결과에서도 유사한 결론을 얻을 수 있습니다. 이 결과는 특성 융합(FPN, DLA, HRNet)이 re-ID 특성의 변별력을 효과적으로 향상시킨다는 것을 검증합니다. 한편, ResNet-34-FPN은 DLA-34와 동일한 수준의 re-ID 특성(TPR)을 얻었음에도 불구하고, 탐지 결과(AP)는 DLA-34보다 크게 떨어집니다. 우리는 DLA-34에서 변형 가능한 컨볼루션(deformable convolution)을 사용하는 것이 주요 이유라고 생각합니다. 이는 다양한 크기의 객체에 대해 더 유연한 수용 필드를 가능하게 하기 때문입니다. 이는 FairMOT이 영역 특성을 사용하지 않고 객체 중심에서만 특성을 추출하기 때문에 매우 중요합니다. DLA-34의 모든 변형 가능한 컨볼루션을 일반 컨볼루션으로 대체하면 65.0 MOTA와 78.1 AP만 얻을 수 있습니다. 표 5에 나타난 바와 같이, DLA-34는 주로 중간 및 대형 객체에서 HRNet-W18을 능가합니다. 더 강력한 백본 HarDNet-85와 더 많은 다층 특성 융합 구조를 사용할 경우, 우리는 DLA-34보다 더 나은 결과를 얻습니다(+2.1 MOTA, +1.7 IDF1, -33.8% IDs, +1.4 AP, +1.4 TPR). HRNet-W18, DLA-34, HarDNet-85는 ResNet-50 및 RegNetY-4.0GF보다 ImageNet 분류 정확도는 낮지만, 추적 정확도는 훨씬 높습니다. 위 실험 결과를 기반으로, 우리는 다층 특성 융합이 “특성” 문제를 해결하는 열쇠라고 믿습니다.
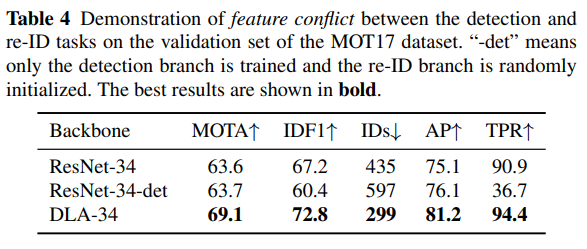
탐지와 re-ID 작업 간의 feature conflict(특성 충돌)의 존재를 확인하기 위해, 우리는 탐지 분기만 학습하고 re-ID 분기는 임의로 초기화된 ResNet-34-det라는 기준선을 도입합니다. 표 4에서 볼 수 있듯이, re-ID 분기를 학습하지 않으면 AP로 측정된 탐지 결과가 1 포인트 개선되며, 이는 두 작업 간의 충돌을 보여줍니다. 특히, ResNet-34-det는 ResNet-34보다 더 높은 MOTA 점수를 얻는데, 이는 이 지표가 추적 결과보다 탐지 결과를 더 선호하기 때문입니다. 반면, ResNet-34 위에 다층 특성 융합을 추가한 DLA-34는 탐지 결과와 추적 결과 모두에서 더 나은 성능을 달성합니다. 이는 다층 특성 융합이 각 작업이 융합된 특성에서 자신만의 작업에 필요한 것을 추출할 수 있도록 하여 feature conflict 문제를 완화하는 데 도움이 된다는 것을 의미합니다.
5.3.4 Feature Dimension
이전의 원샷 트래커들(JDE 등, Wang et al., 2020b)은 일반적으로 별도의 실험 없이 512차원의 re-ID 특성을 학습했습니다. 하지만 우리의 실험 결과, 특성의 차원이 실제로 탐지와 추적 정확도 간의 균형을 유지하는 데 중요한 역할을 한다는 것을 발견했습니다. 더 낮은 차원의 re-ID 특성을 학습하면 탐지 정확도에 미치는 해가 줄어들고 추론 속도가 향상됩니다. 우리는 다양한 원샷 트래커에 대한 실험을 수행한 결과, 저차원(즉, 64) 재식별 기능이 고차원(즉, 512) 재식별 기능보다 더 나은 성능을 달성하는 것이 일반적인 규칙임을 발견했습니다.
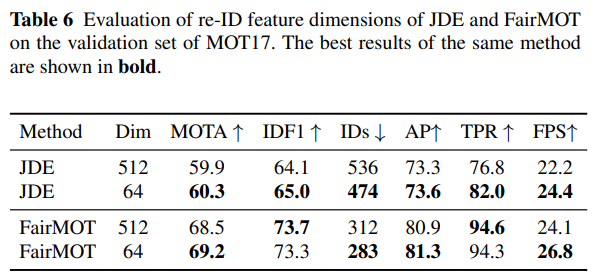
우리는 JDE와 FairMOT의 re-ID 특성 차원에 대한 다양한 선택지를 Table 6에서 평가했습니다. JDE의 경우, 64차원이 모든 지표에서 512차원보다 더 나은 성능을 보임을 알 수 있습니다. FairMOT의 경우, 512차원이 더 높은 IDF1 및 TPR 점수를 달성하며 이는 더 높은 차원의 re-ID 특성이 강력한 판별력을 제공함을 나타냅니다. 그러나 MOTA 점수는 512차원에서 64차원으로 차원을 줄이면 개선됩니다. 이는 주로 탐지 작업과 re-ID 작업 간의 충돌로 인한 것입니다. 특히 re-ID 특성의 차원을 줄이면 탐지 결과(AP)가 개선됨을 확인할 수 있습니다. re-ID 작업과는 달리, 낮은 차원의 re-ID 특성이 MOT 작업에서 더 나은 성능과 효율성을 달성합니다.
5.3.5 Data Association Methods

이 섹션은 데이터 연관 단계에서 바운딩 박스 IoU, re-ID 특성 및 칼만 필터(Kalman, 1960)를 포함한 세 가지 요소를 평가합니다. 이들은 감지된 상자 쌍 간의 유사성을 계산하는 데 사용됩니다. 그런 다음 헝가리 알고리즘(Kuhn, 1955)을 사용하여 할당 문제를 해결합니다. Table 7은 결과를 보여줍니다. Box IoU만 사용하면 많은 ID 전환이 발생함을 알 수 있습니다. 이는 특히 붐비는 장면과 빠른 카메라 움직임에서 두드러집니다. re-ID 특성만을 사용하는 것은 IDF1을 눈에 띄게 증가시키고 ID 전환의 수를 감소시킵니다. 또한 칼만 필터를 추가하면 더 매끄러운(합리적인) 트랙렛을 얻을 수 있으며 ID 전환의 수가 더욱 감소합니다. 객체가 부분적으로 가려진 경우, re-ID 특성이 신뢰할 수 없게 됩니다. 이러한 경우에는 Box IoU, re-ID 특성 및 칼만 필터를 활용하여 우수한 추적 성능을 얻는 것이 중요합니다.

우리는 탐지, 재식별(re-ID) 매칭, 칼만 필터(Kalman Filter), IoU 매칭 등 다양한 구성 요소의 실행 시간 세부 내역을 제공합니다. 프레임당 평균 보행자 수를 기준으로 한 밀도가 다른 시퀀스에서 실행 시간을 테스트합니다. 결과는 그림 4에 표시되어 있습니다. 공동 탐지 및 재식별(re-ID)에 소요되는 시간은 밀도의 영향을 거의 받지 않습니다. 칼만 필터 및 IoU 매칭에 소요되는 시간은 약 $1ms$ 또는 $2ms$로 무시할 수 있습니다. 재식별(re-ID) 매칭에 소요되는 시간은 밀도가 증가함에 따라 선형적으로 증가합니다. 이는 각 트랙렛의 재식별(re-ID) 특성을 업데이트하는 데 많은 시간이 소요되기 때문입니다.
5.3.6 Visualization of Re-ID Similarity

우리는 그림 3에서 재식별(re-ID) 유사도 맵을 사용하여 재식별(re-ID) 특성의 판별 능력을 보여줍니다. 검증 세트에서 임의로 두 개의 프레임을 선택합니다. 첫 번째 프레임은 질의 인스턴스를 포함하고, 두 번째 프레임은 동일한 ID를 가진 타겟 인스턴스를 포함합니다. 재식별(re-ID) 유사도 맵은 섹션 5.3.1 및 5.3.3에 설명된 대로, 질의 인스턴스의 재식별(re-ID) 특성과 타겟 프레임의 전체 재식별(re-ID) 특성 맵 간 코사인 유사도를 계산하여 얻습니다. ResNet-34와 ResNet-34-det의 유사도 맵을 비교하면, 재식별(re-ID) 분기를 훈련하는 것이 중요함을 알 수 있습니다. DLA-34와 ResNet-34를 비교하면, 다층 특성 집계가 더 판별력 있는 재식별(re-ID) 특성을 얻을 수 있음을 알 수 있습니다. DLA-34와 ResNet-34를 비교하면, 다층 특성 집계가 더 판별력 있는 재식별(re-ID) 특성을 얻을 수 있음을 알 수 있습니다. 제안된 Center와 Center-BI 샘플링 전략은 혼잡한 장면에서 주변 객체와 타겟 객체를 더 잘 구별할 수 있습니다.
5.4 Single Image Training
우리는 먼저 CrowdHuman 데이터 세트 (Shao et al., 2018)에서 FairMOT를 사전 학습합니다. 특히, 각 바운딩 박스에 고유한 신원 레이블을 할당하고 4.4절에서 설명된 방법을 사용하여 FairMOT를 학습합니다. 그런 다음 사전 학습된 모델을 대상 데이터 세트 MOT17에서 세부 조정합니다.
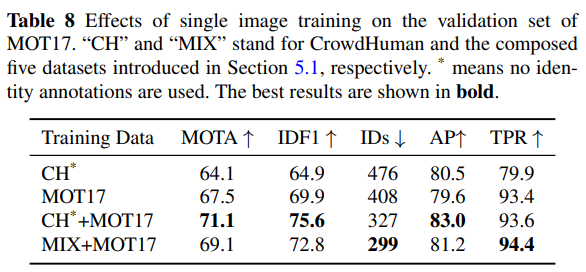
표 8은 결과를 보여줍니다. 첫째, 사전 학습된 모델은 직접 추적기로 사용될 수 있으며 MOT17과 같은 MOT 데이터 세트에서 수용 가능한 결과를 얻을 수 있습니다. 이는 CrowdHuman 데이터 세트가 인간 탐지 성능을 향상시키고 강력한 도메인 일반화 능력을 가지고 있기 때문입니다. 다시 말해, FairMOT의 재식별 학습은 추적기의 연결 능력을 추가로 강화합니다. 둘째, CrowdHuman에서의 사전 학습은 MOT17 데이터 세트를 직접 학습하는 것보다 큰 차이로 성능이 우수합니다. 셋째, 단일 이미지 학습 모델은 신원 주석이 있는 “MIX”와 MOT17 데이터 세트에서 학습된 모델을 능가합니다. 이러한 결과는 제안된 단일 이미지 사전 학습의 효과를 검증하며, 이는 많은 주석 노력을 절약하고 FairMOT를 실제 응용에서 더욱 매력적으로 만듭니다.
5.5 Results on MOTChallenge
우리는 제안한 접근법을 최신 기법(SOTA)과 비교했으며, 여기에는 단일 단계 방법과 2단계 방법이 모두 포함됩니다.
5.5.1 Comparing with One-Shot SOTA MOT Methods
JDE(Wang et al., 2020b)와 TrackRCNN(Voigtlaender et al., 2019)의 두 가지 발표된 연구는 객체 감지와 ID 특성 내재화를 동시에 수행합니다. 우리는 두 방법과 FairMOT의 접근 방식을 비교합니다. 이전 연구(Wang et al., 2020b)에 따라, 테스트 데이터셋은 2DMOT15에서 6개의 비디오로 구성됩니다. FairMOT은 논문에서 설명된 두 가지 방법과 동일한 훈련 데이터를 사용합니다. 특히, JDE와 비교할 때, FairMOT과 JDE는 모두 섹션 5.1에서 설명된 대규모 데이터셋을 사용합니다. Track R-CNN은 네트워크 훈련을 위해 분할 레이블이 필요하므로 MOT17 데이터셋에서 4개의 비디오만 훈련 데이터로 사용합니다. 이 경우, 우리의 모델도 동일한 4개의 비디오를 사용하여 훈련합니다. CLEAR 지표(Bernardin and Stiefelhagen, 2008)와 IDF1(Ristani et al., 2016)은 성능을 측정하는 데 사용됩니다.
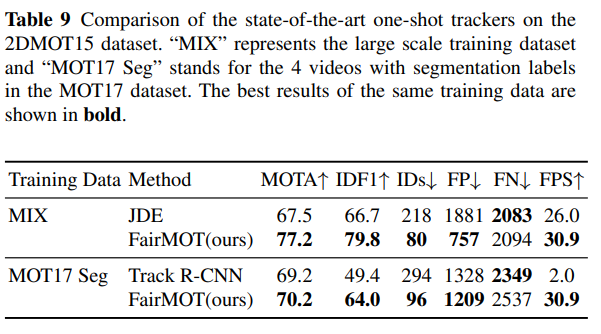
결과는 표 9에 나와 있습니다. 우리의 접근 방식이 JDE(Wang et al., 2020b)보다 현저히 우수하다는 것을 알 수 있습니다. 특히, ID 전환 수가 218에서 80으로 감소하여 사용자 경험 측면에서 큰 개선을 보여줍니다. 이 결과는 이전 앵커 기반 접근 방식보다 앵커 없는 접근 방식의 효과를 입증합니다. 추론 속도는 두 방법 모두 거의 비디오 속도에 가깝고, 우리의 방법이 더 빠릅니다. Track R-CNN(Voigtlaender et al., 2019)과 비교했을 때, 감지 결과는 약간 더 우수하지만(FN이 더 낮음), FairMOT은 훨씬 더 높은 IDF1 점수(64.0 대 49.4)와 더 적은 ID 전환 수(96 대 294)를 달성합니다. 이는 주로 Track R-CNN이 “먼저 감지하고, 다음으로 re-ID 수행” 프레임워크를 따르며, re-ID 작업에 모호성을 초래하는 앵커를 사용하기 때문입니다.
5.5.2 Comparing with Other SOTA MOT Methods
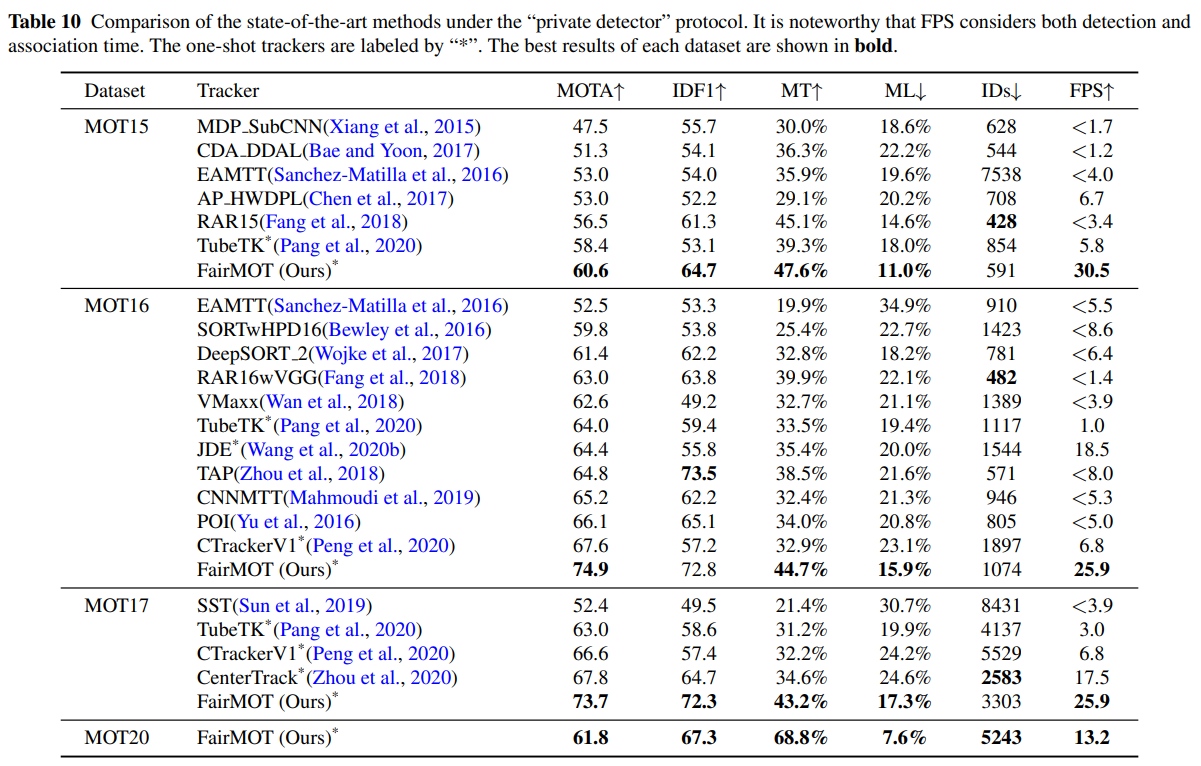
우리는 Table 10에서 언급된 두 단계 방법을 포함한 최신 SOTA 추적기들과 우리의 접근 방식을 비교하였습니다. 우리는 공공 탐지 결과를 사용하지 않으므로, “프라이빗 디텍터(private detector)” 프로토콜을 채택하였습니다. 2DMOT15, MOT16, MOT17, MOT20 데이터셋의 테스트 세트에 대한 결과를 보고하며, 모든 결과는 공식 MOT 챌린지 평가 서버에서 직접 확인한 것입니다.
우리의 접근 방식은 네 개 데이터셋에서 모든 온라인 및 오프라인 추적기 중 1위를 차지했습니다. 특히, 단순한 접근 방식임에도 불구하고 다른 방법들을 큰 차이로 능가하였습니다. 또한, 우리 방법은 비디오 속도 추론(video rate inference)을 달성하였습니다. 반면, (Fang et al., 2018; Yu et al., 2016)과 같은 대부분의 고성능 추적기는 우리의 방식보다 느립니다. 또한, 우리의 방법은 최근 소개된 지역 MOT 메트릭 ALTA (Valmadre et al., 2021)에서 2위를 기록하였으며, 이는 우리의 접근 방식이 매우 높은 추적 성능을 달성했음을 추가로 입증합니다(Table 10).
5.5.3 Training Data Ablation Study
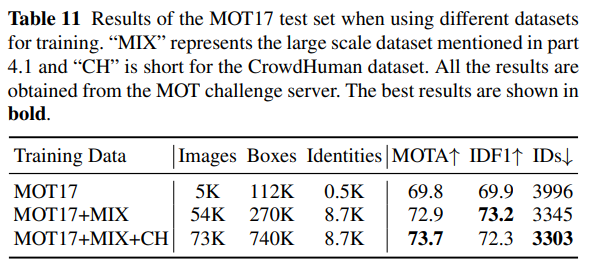
우리는 표 11에서 FairMOT의 성능을 서로 다른 훈련 데이터 양으로 평가합니다. MOT17 데이터 세트만을 사용하여 훈련할 경우 69.8 MOTA를 달성할 수 있으며, 이는 더 많은 훈련 데이터를 사용하는 다른 방법들을 이미 능가합니다. JDE(Wang et al., 2020b)와 동일한 훈련 데이터를 사용할 경우, 72.9 MOTA를 달성하며 JDE를 크게 능가합니다. 추가적으로 CrowdHuman 데이터 세트에서 단일 이미지 훈련을 수행했을 때 MOTA 점수는 73.7로 향상됩니다. 이 결과는 우리의 접근 방식이 데이터 의존성이 낮다는 것을 시사하며, 이는 실용적인 응용에서 큰 장점입니다.
5.6 Qualitative Results

Figure 5는 MOT17 테스트 세트에서 FairMOT의 여러 추적 결과를 시각화한 것입니다(Milan et al., 2016). MOT17-01의 결과에서, 두 보행자가 서로 교차할 때 고품질 re-ID 기능의 도움으로 올바른 ID를 할당할 수 있음을 확인할 수 있습니다. 경계 박스 IoUs(Bewley et al., 2016; Bochinski et al., 2017)를 사용하는 트래커는 이러한 상황에서 ID 전환이 발생하는 경우가 많습니다. MOT17-03의 결과에서, 우리 방법이 혼잡한 장면에서도 잘 작동함을 확인할 수 있습니다. MOT17-08의 결과에서, 보행자가 심하게 가려진 경우에도 올바른 ID와 경계 박스를 유지할 수 있음을 확인할 수 있습니다. MOT17-06과 MOT17-12의 결과는 우리 방법이 큰 규모 변화에 대처할 수 있음을 보여줍니다. 이는 주로 다층 기능 집계 사용 덕분입니다. 우리 방법은 MOT17-07 및 MOT17-14의 결과에서 볼 수 있듯이 작은 객체도 정확하게 감지할 수 있습니다.
6 Summary and Future Work
이전의 one-shot 방법(Wang et al., 2020b)이 왜 two-step 방법과 비교하여 유사한 결과를 달성하지 못했는지 연구를 시작으로, 우리는 객체 감지 및 ID 임베딩에서 앵커 사용이 열화된 결과의 주요 원인임을 발견했습니다. 특히, 객체의 다른 부분에 해당하는 여러 인접 앵커가 동일한 ID를 추정하는 데 관여하여 네트워크 훈련에 모호성을 유발할 수 있습니다. 또한, 이전 MOT 프레임워크에서 감지 및 re-ID 작업 간의 특징 불공정성 문제와 특징 차원 문제를 발견했습니다. 이러한 문제를 앵커 없는(single-shot) 심층 네트워크에서 해결하여, 우리는 FairMOT를 제안합니다. FairMOT는 추적 정확도와 추론 속도 측면에서 여러 벤치마크 데이터 세트에서 이전 최첨단 방법을 큰 차이로 능가합니다. 또한, FairMOT는 본질적으로 훈련 데이터 효율적이며, 경계 박스 주석 이미지만 사용하여 다중 객체 추적기를 단일 이미지로 훈련하는 방법을 제안합니다. 이는 실제 응용에서 우리 방법을 더 매력적으로 만듭니다(Zhang et al., 2021b).
Acknowledgements
이 연구는 부분적으로 NSFC(No. 61733007 및 No. 61876212) 및 MSRA 공동 연구 기금의 지원을 받았습니다. 귀중한 제안을 제공해 주신 익명의 심사위원들께 감사드립니다.
Yifu Zhang, Chunyu Wang, Xinggang Wang, Wenjun Zeng, Wenyu Liu FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking

댓글남기기