

개요
CNN 기반의 2D Pose Estimation 논문에서 제일 유명한 HRNet-Pose 의 논문인 ‘Deep High-Resolution Representation Learning for Human Pose Estimation’ 번역 및 얕은 리뷰이다. 해당 논문은 2019년 CVPR에서 발표되었다.
해당 논문의 방법론은 Top-Down으로 불리는 단일 인물 자세 추정에 집중한다. HRNet은 병렬적인 고해상도에서 저해상도로의 연결 방식을 통해 고해상도 표현을 유지하고 다중 스케일 융합을 반복적으로 수행하여 정확한 키포인트 예측을 가능하게 한다.
접근
- 기본적으로 CPN, Stacked Hourglass Network, Simple baseline 등의 아키텍쳐의 파이프라인을 따른다. 그림 1참조
- 멀티 스케일에 따른 서브네트워크를 일렬로 배치하지 않고 병렬로 배치한다(식 2 참조). 서브네트워크는 다음 단계에서 새로운 서브네트워크 단계를 만들면서 해상도를 줄여간다.
- 병렬 네트워크 간에 교환 유닛을 도입하여 각 서브네트워크가 하단의 병렬 네트워크로부터 정보를 받도록 한다. 이는 해상도 간의 특징을 융합하는 것으로 보인다.
- 마지막 교환 유닛에서 히트맵 회귀를 사용한다.
- 이러한 방식을 사용해 작은 규모, 큰 규모의 아키텍쳐를 설계하였으며 각각 HRNet-W32, HRNet-W48로 명명한다.
실험
- COCO 데이터 셋에 대해서 OKS 메트릭을 통한 AP 계산, MPII 데이터 셋에 대해서 PCKh@0.5 메트릭을 통한 성능계산 방법을 이용하여 비교 실험한다.
- COCO 데이터 기준으로 백본, ImageNet 사전학습, 입력 해상도, 등의 차이를 제어하였고 HRNet-W48이 가장 성능이 좋았음을 확인한다.
- MPII 데이터 기준으로 HRNet-W32 모델 만으로 지금까지의 모델 중에서 최고 성능을 달성한다.
- PoseTrack 데이터 셋에 대해서 기존 SimpleBaseline 기반의 FlowTrack 모델을 제치고 최고 성능을 달성한다.
- 병렬 네트워크 간의 정보 교환 유닛, 해상도의 스케일 등의 소거 연구를 진행하여 각 모듈의 유효성을 입증한다.
결론
해당 HRNet Pose 논문은 고해상도 정보를 유지하는 HRNet을 제안하며 자세 추정 분야에서 높은 성능을 달성한다. 고해상도 정보의 유지 뿐 아니라 여러 스케일의 정보 융합 방법을 제안한다. 이를 통해 높지 않은 연산량에서도 2019년 당시 SOTA를 달성했다.
번역
Abstract
본 논문에서는 신뢰성 있는 고해상도 표현을 학습하는 데 중점을 두고 인간 자세 추정 문제에 관심을 두고 있습니다. 대부분의 기존 방법은 저해상도 네트워크에 의해 생성된 저해상도 표현으로부터 고해상도 표현을 복원합니다. 반면에, 본 논문에서 제안하는 네트워크는 전체 과정에서 고해상도 표현을 유지합니다.
우리는 첫 번째 단계로 고해상도 서브네트워크에서 시작하여, 점진적으로 고해상도에서 저해상도로 변환되는 서브네트워크를 추가하여 더 많은 단계를 형성하고, 다중 해상도 서브네트워크를 병렬로 연결합니다. 반복적인 다중 스케일 융합을 수행하여 각 고해상도에서 저해상도로 변환되는 표현이 다른 병렬 표현으로부터 반복적으로 정보를 받아 풍부한 고해상도 표현을 얻습니다. 결과적으로, 예측된 키포인트 히트맵은 더욱 정확하고 공간적으로 더 정밀해집니다. 우리는 COCO 키포인트 검출 데이터셋과 MPII 인간 자세 데이터셋이라는 두 개의 벤치마크 데이터셋에서 우수한 자세 추정 결과를 통해 우리의 네트워크의 효율성을 실험적으로 입증합니다. 추가로, 우리는 PoseTrack 데이터셋에서의 자세 추적에서 우리의 네트워크가 우수하다는 것을 보여줍니다. 코드와 모델은 https://github.com/leoxiaobin/deep-high-resolution-net.pytorch에서 공개적으로 이용할 수 있습니다.
1. Introduction
2D 인간 자세 추정은 컴퓨터 비전에서 기본적이지만 어려운 문제로 여겨져 왔습니다. 이 문제의 목표는 인간의 해부학적 키포인트(예: 팔꿈치, 손목 등)나 부위를 위치시켜 파악하는 것입니다. 이는 인간 행동 인식, 인간-컴퓨터 상호작용, 애니메이션 등과 같은 많은 응용 분야를 가지고 있습니다. 본 논문에서는 단일 인물 자세 추정에 초점을 맞추고 있으며, 이는 다중 인물 자세 추정[6, 26, 32, 38, 46, 55, 40, 45, 17, 69], 비디오 자세 추정 및 추적[48, 70] 과 같은 다른 관련 문제들의 기초가 됩니다.
최근의 발전은 딥 컨볼루션 신경망이 최첨단 성능을 달성했음을 보여줍니다. 대부분의 기존 방법은 입력을 일련으로 연결된 고해상도에서 저해상도로 변환되는 서브 네트워크로 구성된 네트워크를 통과시킨 다음 해상도를 향상시킵니다. 예를 들어, Hourglass[39]는 대칭적인 저해상도에서 고해상도로의 과정을 통해 고해상도를 복원합니다. SimpleBaseline[70]은 고해상도 표현을 생성하기 위해 몇 가지 전치된 컨볼루션 레이어를 채택합니다. 추가로, 딜레이션 컨볼루션은 고해상도에서 저해상도로 변환되는 네트워크의 후반 레이어(예: VGGNet 또는 ResNet)[26, 74]를 확대하는 데 사용됩니다.
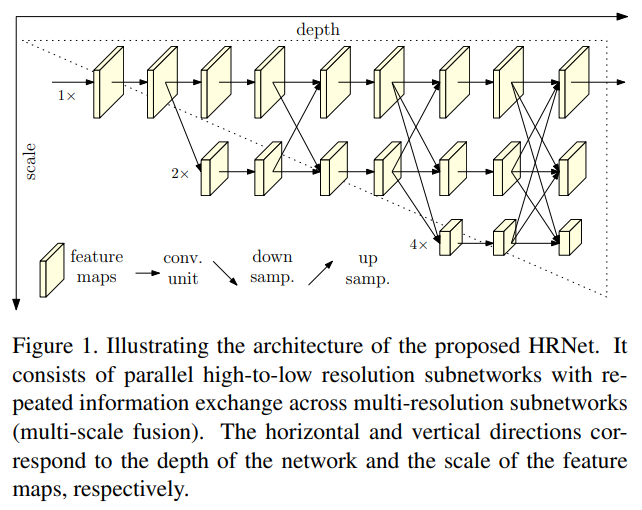
우리는 HRNet(High-Resolution Net)이라고 불리는 새로운 구조를 제시하며, 이 구조는 전체 과정에서 고해상도 표현을 유지할 수 있습니다. 우리는 첫 단계로 고해상도 서브네트워크에서 시작하고, 점차적으로 고해상도에서 저해상도로 변환되는 서브네트워크를 하나씩 추가하여 더 많은 단계를 형성하며, 다중 해상도 서브네트워크를 병렬로 연결합니다. 우리는 전체 과정에서 병렬 다중 해상도 서브네트워크 간의 정보 교환을 통해 반복적인 다중 스케일 융합을 수행합니다. 우리는 네트워크에서 출력된 고해상도 표현을 통해 키포인트를 추정합니다. 이 결과적인 네트워크는 그림 1에 나와 있습니다.
우리 네트워크는 기존에 널리 사용되는 자세 추정 네트워크【39, 26, 74, 70】와 비교했을 때 두 가지 장점을 가집니다. (i) 우리의 접근 방식은 대부분의 기존 솔루션이 직렬로 연결하는 것과 달리, 고해상도에서 저해상도로 변환되는 서브네트워크를 병렬로 연결합니다. 따라서 우리의 접근 방식은 저해상도에서 고해상도로 복원하는 대신 고해상도를 유지할 수 있으며, 이에 따라 예측된 히트맵이 공간적으로 더욱 정밀해집니다. (ii) 대부분의 기존 융합 방식은 저레벨과 고레벨 표현을 집계합니다. 반면에 우리는 동일한 깊이와 유사한 레벨의 저해상도 표현의 도움으로 고해상도 표현을 강화하기 위해 반복적인 다중 스케일 융합을 수행하며, 그 반대도 마찬가지입니다. 결과적으로 고해상도 표현은 자세 추정에도 풍부한 정보를 제공합니다. 따라서 우리의 예측 히트맵은 잠재적으로 더 정확해집니다.
우리는 COCO 키포인트 검출 데이터셋[35]과 MPII 인간 자세 데이터셋[2]이라는 두 벤치마크 데이터셋에서의 우수한 키포인트 검출 성능을 실험적으로 입증합니다. 추가로, 우리는 PoseTrack 데이터셋[1]에서의 비디오 자세 추적에서 네트워크의 우수성을 보여줍니다.
2. Related Work
단일 인물 자세 추정에 대한 대부분의 전통적인 해결책은 확률 그래프 모델 또는 화상 구조 모델을 채택하며[76, 49], 이는 최근에 단일 및 쌍별 에너지를 더 잘 모델링하기 위해 딥러닝을 활용하거나[9, 63, 44]반복적인 추론 과정을 모방함으로써 개선되었습니다[13]. 현재는 딥 컨볼루션 신경망이 우세한 해결책을 제공합니다[20, 34, 60, 41, 42, 47, 56, 16]. 주요한 두 가지 방법은 키포인트의 위치를 회귀하는 것과[64, 7] 키포인트 히트맵을 추정하고 히트맵에서 가장 높은 값을 가지는 위치를 키포인트로 선택하는 것입니다[13, 14, 75].
키포인트 히트맵 추정을 위한 대부분의 컨볼루션 신경망은 분류 네트워크와 유사한 스템 서브네트워크로 구성되어 해상도를 감소시키며, 입력과 동일한 해상도의 표현을 생성하는 메인 바디와 키포인트 위치를 추정하는 히트맵을 추정한 후 전체 해상도로 변환하는 회귀자가 뒤따릅니다. 메인 바디는 주로 고해상도에서 저해상도, 저해상도에서 고해상도로 변환되는 프레임워크를 채택하며, 경우에 따라 다중 스케일 융합 및 중간(딥) 감독을 통해 강화될 수 있습니다.
High-to-low and low-to-high.
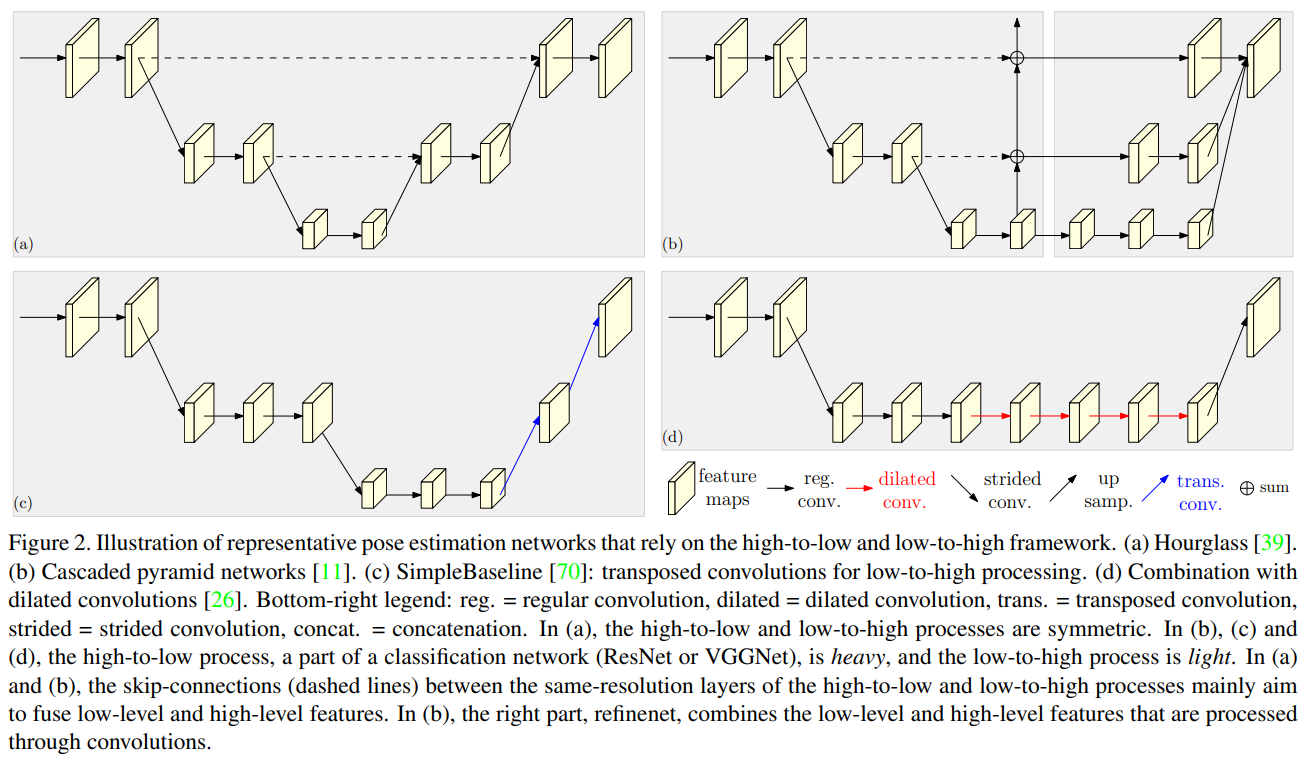
고해상도에서 저해상도로의 변환 과정은 저해상도 및 고레벨의 표현을 생성하는 것을 목표로 하며, 저해상도에서 고해상도로의 변환 과정은 고해상도 표현을 생성하는 것을 목표로 합니다[4, 11, 22, 70, 39, 60]. 이 두 과정은 성능을 향상시키기 위해 여러 번 반복될 수 있습니다[74, 39, 14].
대표적인 네트워크 디자인 패턴은 다음을 포함합니다. (i) 대칭적인 고해상도에서 저해상도 및 저해상도에서 고해상도로의 변환 과정. Hourglass와 그 후속 연구들은[39, 14, 74, 30] 저해상도에서 고해상도로의 과정을 고해상도에서 저해상도로의 변환의 거울로 디자인합니다. (ii) 무거운 고해상도에서 저해상도로의 변환과 가벼운 저해상도에서 고해상도로의 변환. 고해상도에서 저해상도로의 변환은 ImageNet 분류 네트워크에 기반하며, 예를 들어 ResNet은[11, 70] 저해상도에서 고해상도로의 변환은 몇 개의 선형 업샘플링이나[11] 전치된 컨볼루션 레이어[70]를 사용합니다. (iii) 팽창 컨볼루션과의 조합. [26, 50, 34]에서는 ResNet이나 VGGNet의 마지막 두 단계에서 공간 해상도 손실을 제거하기 위해 팽창 컨볼루션을 적용하며, 이는 가벼운 저해상도에서 고해상도로의 변환 과정을 통해 해상도를 더 높이게 되어 팽창 컨볼루션만을 사용했을 때 발생하는 고비용 연산을 피할 수 있습니다[11, 26, 50]. 그림 2는 네 가지 대표적인 자세 추정 네트워크를 보여줍니다.
Multi-scale fusion.
가장 간단한 방법은 다중 해상도 이미지를 여러 네트워크에 개별적으로 입력하고 출력 응답 맵을 집계하는 것입니다[62]. Hourglass[39]와 그 확장 모델들은[74, 30] 스킵 연결을 통해 고해상도에서 저해상도 과정의 저레벨 특징을 동일 해상도의 고레벨 특징에 점진적으로 결합합니다. Cascaded Pyramid Network[11]에서는 글로벌넷이 저해상도에서 고해상도 과정을 통해 저레벨과 고레벨 특징을 점진적으로 결합하고, 이후 refinenet이 컨볼루션을 통해 처리된 저해상도에서 고해상도의 특징을 결합합니다. 우리의 접근 방식은 다중 스케일 융합을 반복하며, 이는 딥 융합과 그 확장 모델들[65, 71, 57, 77, 79]에서 부분적으로 영감을 받았습니다.
Intermediate supervision.
중간 감독 또는 딥 감독은 초기에는 이미지 분류를 위해 개발되었으며[33, 59], 딥 네트워크의 학습을 돕고 히트맵 추정 품질을 향상시키는 데에도 사용됩니다[67, 39, 62, 3, 11]. Hourglass 접근법[39]과 컨볼루션 포즈 머신 접근법[67]은 중간 히트맵을 남은 서브네트워크의 입력 또는 입력의 일부로 처리합니다.
Our approach.
우리의 네트워크는 고해상도에서 저해상도 서브네트워크를 병렬로 연결합니다. 전체 과정에서 공간적으로 정확한 히트맵 추정을 위해 고해상도 표현을 유지합니다. 고해상도에서 저해상도 서브네트워크가 생성한 표현을 반복적으로 융합하여 신뢰성 있는 고해상도 표현을 생성합니다. 우리의 접근 방식은 대부분의 기존 작업과 다르며, 별도의 저해상도에서 고해상도로의 업샘플링 과정 및 저레벨과 고레벨 표현을 집계할 필요가 없습니다. 우리의 접근 방식은 중간 히트맵 감독을 사용하지 않고도 키포인트 검출 정확도에서 우수하며, 연산 복잡도와 파라미터 면에서 효율적입니다.
분류 및 세그멘테이션을 위한 관련 다중 스케일 네트워크가 있습니다[5, 8, 72, 78, 29, 73, 53, 54, 23, 80, 53, 51, 18]. 우리의 연구는 이들 중 일부에서 영감을 받았지만[54, 23, 80, 53], 이들과 명확한 차이점이 있어 우리의 문제에 적용될 수 없습니다. 컨볼루션 신경 패브릭[54]과 인터링크드 CNN[80]은 각 서브네트워크의 적절한 설계(깊이, 배치 정규화)와 다중 스케일 융합의 부족으로 인해 고품질의 세그멘테이션 결과를 생성하지 못합니다. 그리드 네트워크[18]는 가중치가 공유된 여러 U-Net의 조합으로, 다중 해상도 표현에 대한 두 개의 개별 융합 과정을 포함합니다: 첫 번째 단계에서는 정보가 고해상도에서 저해상도로만 전송되고, 두 번째 단계에서는 저해상도에서 고해상도로만 전송되므로 경쟁력이 떨어집니다. 다중 스케일 덴스넷[23]은 신뢰성 있는 고해상도 표현을 생성하지 못하고 이를 목표로 하지도 않습니다.
3. Approach
인간 자세 추정, 즉 키포인트 검출은 이미지 $I$ (크기: $W×H×3$)에서 $K$ 개의 키포인트 또는 부위(예: 팔꿈치, 손목 등)의 위치를 검출하는 것을 목표로 합니다. 최신 방법들은 이 문제를 $W’×H’$ 크기의 $K$ 개의 히트맵 ${H_1,H_2,…,H_K}$ 을 추정하는 문제로 변환하며, 각 히트맵 $H_k$ 는 $k$ 번째 키포인트의 위치 신뢰도를 나타냅니다.
우리는 컨볼루션 네트워크를 사용하여 인간 키포인트를 예측하기 위해 널리 사용되는 파이프라인[39, 70, 11]을 따릅니다. 이 네트워크는 해상도를 줄이는 두 개의 스트라이드 컨볼루션으로 구성된 스템, 입력 특징 맵과 동일한 해상도의 특징 맵을 출력하는 메인 바디, 키포인트 위치를 선택하고 전체 해상도로 변환하는 히트맵을 추정하는 회귀자로 구성됩니다. 우리는 메인 바디의 설계에 집중하며 그림 1에 나타난 HRNet(High-Resolution Net)을 소개합니다.
Sequential multi-resolution subnetworks.
기존의 자세 추정 네트워크는 고해상도에서 저해상도로 변환되는 서브네트워크를 일렬로 연결하여 구축됩니다. 각 서브네트워크는 컨볼루션의 시퀀스로 구성되어 있으며 인접한 서브네트워크 사이에는 해상도를 절반으로 줄이는 다운샘플 레이어가 있습니다.
$\mathcal{N}_{sr}$ 을 $s$ 번째 단계의 서브네트워크로, $r$ 을 해상도 인덱스로 두면(그 해상도는 첫 번째 서브네트워크의 해상도의 $\frac{1}{2^{r-1}}$ 입니다.), $S$ (예: 4) 단계로 구성된 고해상도에서 저해상도로 변환되는 네트워크는 다음과 같이 표현될 수 있습니다:
Parallel multi-resolution subnetworks.
우리는 첫 번째 단계로 고해상도 서브네트워크에서 시작하여, 점차적으로 고해상도에서 저해상도로 변환되는 서브네트워크를 하나씩 추가하여 새로운 단계를 형성하고, 다중 해상도 서브네트워크를 병렬로 연결합니다. 그 결과, 이후 단계의 병렬 서브네트워크의 해상도는 이전 단계의 해상도와 추가로 낮은 해상도로 구성됩니다.
\[\begin{align} \mathcal{N}_{11} \rightarrow \mathcal{N}_{21} \rightarrow \mathcal{N}_{31} \rightarrow & \mathcal{N}_{41} \\ \searrow \mathcal{N}_{22} \rightarrow \mathcal{N}_{32} \rightarrow & \mathcal{N}_{42} \\ \searrow \mathcal{N}_{33} \rightarrow & \mathcal{N}_{43} \\ \searrow & \mathcal{N}_{44}. \\ \end{align}\]Repeated multi-scale fusion.
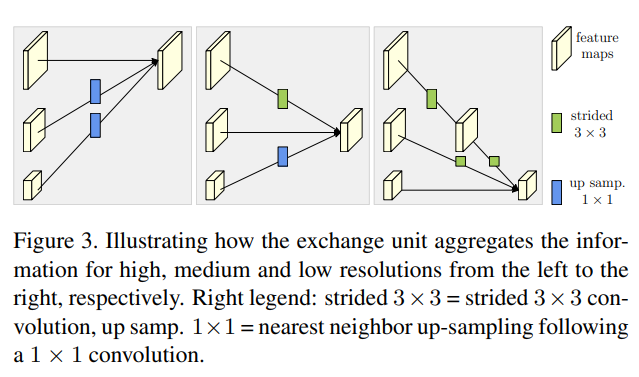
우리는 병렬 서브네트워크 사이에 교환 유닛을 도입하여 각 서브네트워크가 반복적으로 다른 병렬 서브네트워크로부터 정보를 받도록 합니다. 다음은 정보 교환의 구조를 보여주는 예시입니다. 우리는 세 번째 단계를 여러 교환 블록(예: 3개)으로 나누었으며, 각 블록은 병렬 유닛 간의 교환 유닛을 포함한 3개의 병렬 컨볼루션 유닛으로 구성됩니다. 이는 다음과 같습니다.
\[\begin{align} & \mathcal{C}_{31}^1 \searrow \qquad \nearrow \mathcal{C}_{31}^2 \searrow \qquad \nearrow \mathcal{C}_{31}^3 \searrow \\ & \mathcal{C}_{32}^1 \rightarrow \mathcal{E}_3^1 \;\, \rightarrow \mathcal{C}_{32}^2 \rightarrow \mathcal{E}_3^2 \;\, \rightarrow \mathcal{C}_{32}^3 \rightarrow \mathcal{E}^3_3 \\ & \mathcal{C}_{33}^1 \nearrow \qquad \searrow \mathcal{C}_{33}^2 \nearrow \qquad \searrow \mathcal{C}_{31}^3 \nearrow \\ \end{align}\]여기서 $C_{sr}^b$ 은 $s$ 번째 단계의 $b$ 번째 블록의 $r$ 번째 해상도의 컨볼루션 유닛을 나타내며, $\mathcal{E}_s^b$ 는 해당 교환 유닛을 나타냅니다.
우리는 그림 3에서 교환 유닛을 설명하고, 그 수식을 아래에 제시합니다. 논의의 편의를 위해 첨자 $s$ 와 첨자 $b$를 생략합니다. 입력은 $s$ 개의 응답 맵입니다: ${X_1, X_2,…,X_s}$. 출력은 $s$ 개의 응답 맵이며, 그 해상도와 너비는 입력과 동일합니다: ${Y_1,Y_2,…,Y_s}$. 각 출력은 입력 맵의 집계로 이루어지며, $Y_k=\sum_{i=1}^s{a(X_i,k)}$ 로 나타냅니다. 단계 간 교환 유닛은 추가적인 출력 맵을 가집니다: $Y_{s+1}=a(Y_s,s+1)$.
함수 $a(X_i,k)$ 는 해상도 $i$ 에서 해상도 $k$ 로의 업샘플링 또는 다운샘플링을 구성합니다. 우리는 다운샘플링을 위해 스트라이드 $3×3$ 컨볼루션을 사용합니다. 예를 들어, 스트라이드가 2인 하나의 $3×3$ 컨볼루션은 $2×$ 다운샘플링을 하고, 스트라이드가 2인 두 개의 연속적인 $3×3$ 컨볼루션은 $4×$ 다운샘플링을 합니다. 업샘플링을 위해서는 채널 수를 정렬하기 위해 $1×1$ 컨볼루션 후 최근접 이웃 샘플링을 사용합니다. 만약 $i=k$ 라면, $a(⋅,⋅)$ 는 단순한 아이덴티티 연결입니다: $a(X_i,k)=X_i$.
Heatmap estimation.
우리는 마지막 교환 유닛에서 출력된 고해상도 표현을 사용하여 히트맵을 단순히 회귀합니다. 이는 실험적으로 잘 작동합니다. 손실 함수는 예측된 히트맵과 실제 히트맵을 비교하기 위해 평균 제곱 오차로 정의됩니다. 실제 히트맵은 각 키포인트의 실제 위치를 중심으로 표준 편차가 1 픽셀인 2D 가우시안을 적용하여 생성됩니다.
Network instantiation.
우리는 각 단계에 깊이를 분배하고 각 해상도에 채널 수를 할당하기 위해 ResNet의 설계 규칙을 따라 키포인트 히트맵 추정을 위한 네트워크를 인스턴스화합니다.
HRNet의 메인 바디는 4개의 병렬 서브네트워크로 구성된 4개의 단계로 이루어져 있으며, 각 단계에서 해상도는 절반으로 점진적으로 감소하고 그에 따라 너비(채널 수)는 두 배로 증가합니다. 첫 번째 단계에는 4개의 잔차 유닛이 있으며, 각 유닛은 ResNet-50과 동일하게 너비 64의 병목으로 형성되고, 이후 특징 맵의 너비를 $C$ 로 줄이는 하나의 $3×3$ 컨볼루션이 이어집니다. 두 번째, 세 번째, 네 번째 단계는 각각 1, 4, 3개의 교환 블록을 포함합니다. 하나의 교환 블록은 4개의 잔차 유닛을 포함하며, 각 유닛은 각 해상도에서 두 개의 $3×3$ 컨볼루션과 해상도 간 교환 유닛을 포함합니다. 요약하면, 총 8개의 교환 유닛이 있으며, 이는 8개의 다중 스케일 융합이 수행된다는 것을 의미합니다.
우리의 실험에서 우리는 하나의 작은 네트워크와 하나의 큰 네트워크를 연구합니다: HRNet-W32와 HRNet-W48이며, 여기서 32와 48은 각각 마지막 세 단계에서 고해상도 서브네트워크의 너비($C$)를 나타냅니다. 다른 세 개의 병렬 서브네트워크의 너비는 HRNet-W32의 경우 64, 128, 256이고, HRNet-W48의 경우 96, 192, 384입니다.
4. Experiments
4.1. COCO Keypoint Detection
Dataset.
COCO 데이터셋[35]은 20만 장 이상의 이미지와 25만 개의 사람 인스턴스를 포함하며, 각 인스턴스는 17개의 키포인트로 레이블링되어 있습니다. 우리는 COCO train2017 데이터셋(57K 이미지 및 150K 사람 인스턴스 포함)에서 모델을 학습합니다. 제안된 접근 방법은 val2017 세트(5000 이미지) 및 test-dev2017 세트(20K 이미지)에서 평가합니다.
Evaluation metric.
표준 평가 지표는 객체 키포인트 유사성(OKS)을 기반으로 합니다: $OKS=\frac{\sum_i{\exp(-\frac{d_i^2}{2s^2k_i^2})\delta(v_i>0)}}{\sum_i{\delta(v_i>0)}}$. 여기서 $d_i$ 는 검출된 키포인트와 해당하는 실제 값 사이의 유클리드 거리, $v_i$ 는 실제 값의 가시성 플래그, $s$ 는 객체의 크기, $k_i$ 는 키포인트별로 설정된 감소 상수입니다. 우리는 표준 평균 정밀도(AP)와 재현율(AR) 점수를 보고합니다: $AP^{50}$ (OKS = 0.50에서의 AP), $AP^{75}$, AP (OKS = 0.50, 0.55, …, 0.90, 0.95의 10개 위치에서의 AP 평균값); $AP^M$ 은 중간 크기의 객체에 대해, $AP^L$ 은 큰 크기의 객체에 대해, OKS = 0.50, 0.55, …, 0.90, 0.95에서의 AR.
Training.
우리는 인간 검출 박스를 높이 또는 너비로 확장하여 고정된 종횡비를 가지도록 합니다: 높이:너비 = 4:3, 이후 이미지를 잘라내고 고정된 크기(256 × 192 또는 384 × 288)로 리사이즈합니다. 데이터 증강에는 무작위 회전($[−45^\circ, 45^\circ]$), 무작위 크기 조절([0.65, 1.35]), 그리고 뒤집기가 포함됩니다. [66]의 방법을 따라 반신 데이터 증강도 포함됩니다.
우리는 Adam 옵티마이저[31]를 사용합니다. 학습 스케줄은 설정[70]을 따릅니다. 기본 학습률은 1e-3으로 설정되며, 170번째와 200번째 에포크에서 각각 1e-4와 1e-5로 감소합니다. 훈련 과정은 210 에포크 내에 종료됩니다.
Testing.
[46, 11, 70]와 유사한 2단계 상향식 패러다임을 사용합니다. 먼저 사람 감지기를 사용하여 사람 인스턴스를 검출하고, 그 다음에 검출된 키포인트를 예측합니다.
검증 세트와 테스트 개발 세트 모두에 대해 SimpleBaseline[2]에서 제공된 동일한 사람 감지기를 사용합니다. [70, 39, 11]을 따라, 원본 이미지와 뒤집힌 이미지의 히트맵을 평균하여 최종 히트맵을 계산합니다. 각 키포인트의 위치는 최고 응답값의 위치를 기준으로 두 번째로 높은 응답값의 방향으로 1/4의 오프셋을 조정하여 예측됩니다.
Results on the validation set.
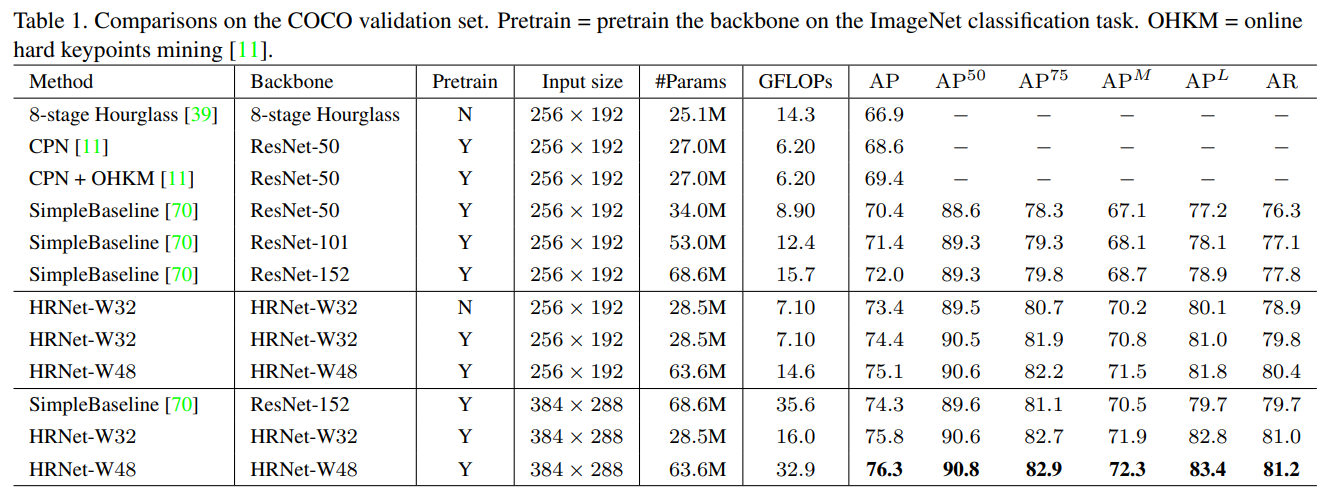
우리는 표 1에서 제시한 방법과 다른 최신 기법들의 결과를 보고합니다. 입력 크기 256 × 192로 처음부터 학습된 소형 네트워크 HRNet-W32는 73.4 AP 점수를 달성하며, 동일한 입력 크기를 가진 다른 방법보다 뛰어난 성능을 보입니다. (i) Hourglass[39]와 비교했을 때, 우리의 소형 네트워크는 AP를 6.5포인트 개선하였고, 네트워크의 GFLOPs는 훨씬 낮아 절반 이하이며, 파라미터 수는 유사하지만 우리의 것이 약간 더 큽니다. (ii) CPN[11] (OHKM 적용 전후)과 비교했을 때, 우리의 네트워크는 약간 더 큰 모델 크기와 복잡성을 가지며, 각각 4.8 및 4.0포인트의 개선을 이뤄냈습니다. (iii) 이전에 가장 성능이 좋았던 SimpleBaseline[70]과 비교했을 때, 우리의 HRNet-W32는 큰 개선을 달성했습니다: 비슷한 모델 크기와 GFLOPs를 가진 백본 ResNet-50에서는 3.0포인트, 모델 크기와 GFLOPs가 우리 모델의 두 배인 백본 ResNet-152에서는 1.4포인트의 개선이 있었습니다.
우리의 네트워크는 다음과 같은 이점을 얻을 수 있습니다. (i) ImageNet에서 사전 학습된 모델로부터의 학습: HRNet-W32의 경우 1.0포인트의 개선이 있습니다. (ii) 너비를 늘려 용량을 증가시키는 경우: HRNet-W48은 입력 크기가 256 × 192일 때 0.7포인트, 384 × 288일 때 0.5포인트의 개선이 있습니다.
입력 크기 384 × 288을 고려할 때, 우리의 HRNet-W32와 HRNet-W48은 각각 75.8과 76.3의 AP를 달성하며, 이는 입력 크기 256 × 192와 비교하여 각각 1.4 및 1.2의 개선을 보입니다. 백본으로 ResNet-152를 사용하는 SimpleBaseline【70】과 비교했을 때, 우리의 HRNet-W32와 HRNet-W48은 AP 측면에서 각각 1.5 및 2.0포인트의 개선을 이루며, 연산 비용은 각각 45% 및 92.4%입니다.
Results on the test-dev set.
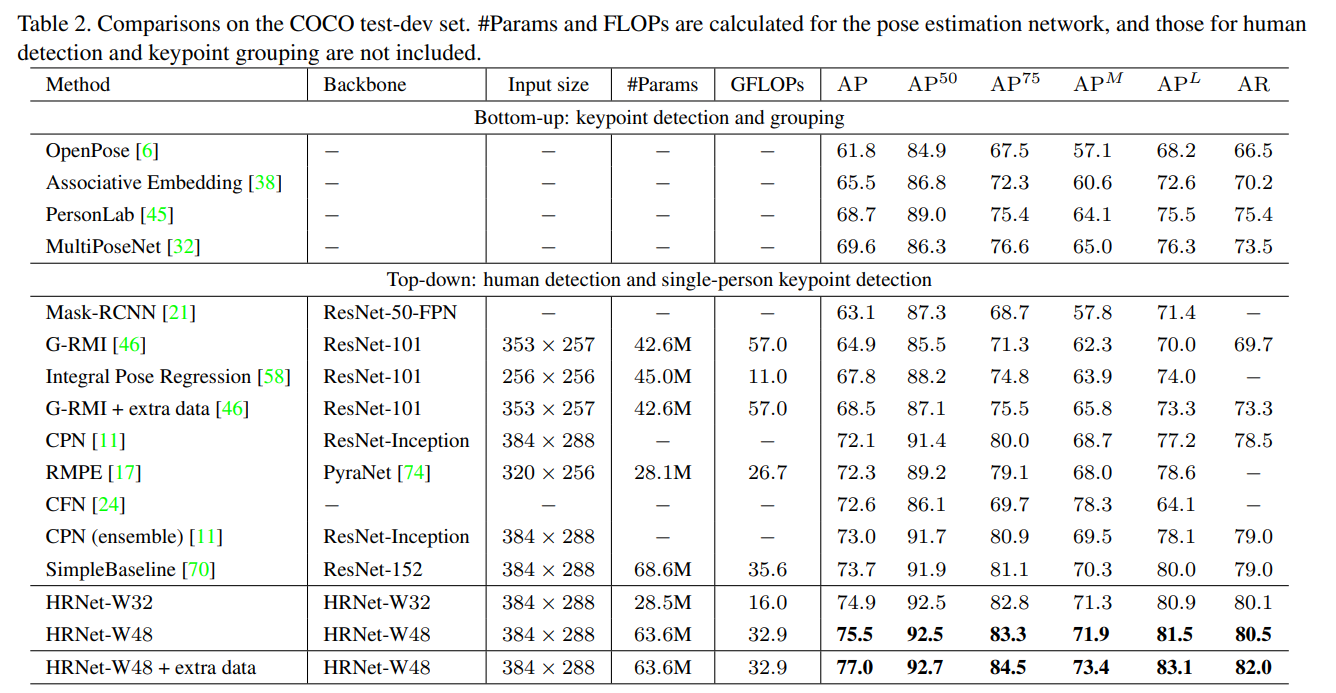
표 2는 우리의 접근법과 기존 최첨단 방법들의 자세 추정 성능을 보여줍니다. 우리의 접근법은 상향식 방법보다 훨씬 뛰어납니다. 반면에 우리의 소형 네트워크인 HRNet-W32는 74.9의 AP를 달성하였으며, 다른 모든 하향식 접근법보다 뛰어나고, 모델 크기(#Params) 및 연산 복잡도(GFLOPs) 측면에서도 더 효율적입니다. 대형 모델인 HRNet-W48은 최고 AP 75.5를 달성하였습니다. 동일한 입력 크기를 가진 SimpleBaseline[70]과 비교했을 때, 우리의 소형과 대형 네트워크는 각각 1.2와 1.8의 개선을 얻었습니다. AI 챌린저[68]데이터를 추가적으로 학습에 사용하면, 우리의 대형 네트워크는 AP 77.0을 달성할 수 있습니다.
4.2. MPII Human Pose Estimation
Dataset.
MPII Human Pose 데이터셋[2]은 다양한 실제 활동에서 촬영된 이미지를 포함하며, 전체 자세에 대한 주석이 제공됩니다. 약 25K의 이미지에 40K의 인물이 있으며, 이 중 12K 인물이 테스트에 사용되고 나머지 인물은 학습 세트에 사용됩니다. 데이터 증강 및 학습 전략은 MS COCO와 동일하지만, 다른 방법들과의 공정한 비교를 위해 입력 크기가 256 × 256으로 잘려 사용됩니다.
Testing.
테스트 절차는 COCO와 거의 동일하지만, 검출된 사람 박스 대신 제공된 사람 박스를 사용하는 표준 테스트 전략을 채택한다는 점이 다릅니다. [14, 74, 60]을 따라 6-스케일 피라미드 테스트 절차를 수행합니다.
Evaluation metric.
표준 평가 지표로는 PCKh(정확한 키포인트의 머리 기준 확률) 점수가 사용됩니다[2]. 관절이 실제 위치로부터 $\alpha l$ 픽셀 내에 있으면 올바르다고 간주되며, 여기서 $α$는 상수이고 $l$ 은 실제 머리 경계 상자의 대각선 길이의 60%에 해당하는 머리 크기입니다. PCKh@0.5 (α=0.5) 점수를 보고합니다.
Results on the test set.
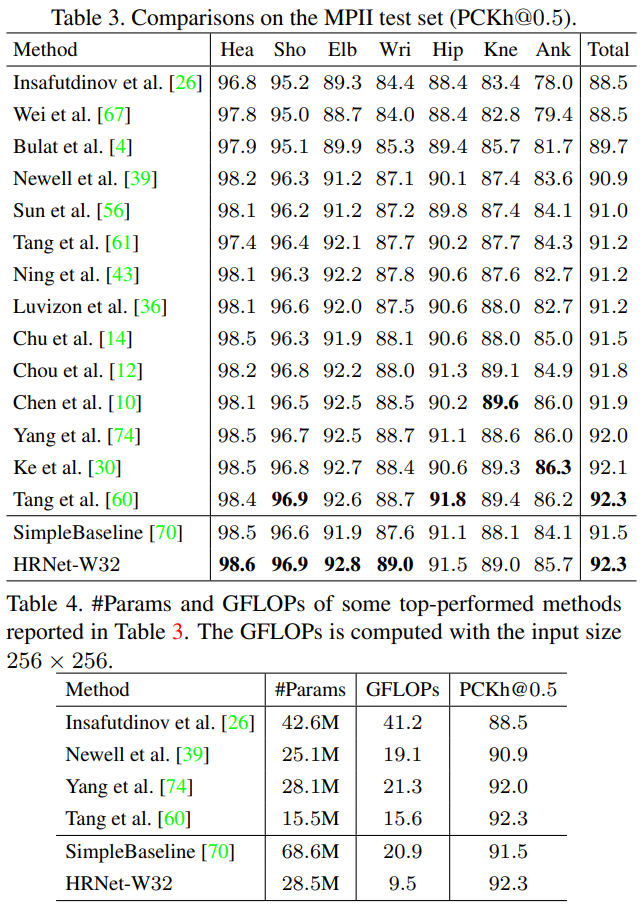
표 3과 4는 최고 성능을 보인 방법들의 PCKh@0.5 결과, 모델 크기, 그리고 GFLOPs를 보여줍니다. 우리는 SimpleBaseline[70]을 ResNet-152를 백본으로 사용하여 입력 크기 256 × 256으로 재구현했습니다. 우리의 HRNet-W32는 92.3의 PCKh@0.5 점수를 달성하며, 스택된 Hourglass 접근법[39]과 그 확장 모델들[56, 14, 74, 30, 60]보다 뛰어납니다. 우리의 결과는 2018년 11월 16일 리더보드에 이전에 발표된 결과 중 최고 점수와 동일합니다[60]. 우리는 [60]의 접근법이 우리의 접근법을 보완하고 있으며, 인체의 구성을 학습하기 위해 구성 모델을 활용하고 다중 수준의 중간 감독을 채택한다는 점을 지적하고자 합니다. 이는 우리의 접근법에도 도움이 될 수 있습니다. 우리는 대형 네트워크 HRNet-W48도 테스트했으며, 동일한 결과인 92.3을 얻었습니다. 이는 이 데이터셋의 성능이 포화되는 경향이 있기 때문일 수 있습니다.
4.3. Application to Pose Tracking
Dataset.
PoseTrack[27]은 비디오에서 인간의 자세 추정 및 관절 추적을 위한 대규모 벤치마크입니다. 이 데이터셋은 유명한 MPII Human Pose 데이터셋에서 제공되는 원시 비디오를 기반으로 하며, 550개의 비디오 시퀀스와 66,374개의 프레임을 포함합니다. 비디오 시퀀스는 학습, 검증, 테스트를 위해 각각 292, 50, 208개의 비디오로 나뉩니다. 학습 비디오의 길이는 41 – 151 프레임 사이이며, 비디오의 중앙에서 30개의 프레임이 밀집 주석처리되어 있습니다. 검증/테스트 비디오의 프레임 수는 65 – 298 프레임 사이입니다. MPII Pose 데이터셋의 키프레임 주변의 30개 프레임이 밀집 주석처리되고, 이후 매 4번째 프레임이 주석처리됩니다. 총 약 23,000개의 라벨링된 프레임과 153,615개의 포즈 주석이 포함됩니다.
Evaluation metric.
우리는 결과를 두 가지 측면에서 평가합니다: 프레임 단위의 다중 인물 자세 추정 및 다중 인물 자세 추적. 자세 추정은 [50, 27]과 동일하게 평균 정확도(mAP)로 평가됩니다. 다중 인물 자세 추적은 다중 객체 추적 정확도(MOTA)[37, 27]로 평가됩니다. 자세한 내용은 [27]에 나와 있습니다.
Training.
우리는 HRNet-W48을 PoseTrack2017 학습 세트에서 단일 인물 자세 추정을 위해 학습하며, 네트워크는 COCO 데이터셋에서 사전 학습된 모델로 초기화됩니다. 우리는 학습 프레임의 주석처리된 키포인트에서 사람 박스를 추출하며, 모든 키포인트(단일 인물)의 경계 상자의 길이를 15% 확장하여 추출합니다. 데이터 증강을 포함한 학습 설정은 COCO와 거의 동일하지만, 학습 스케줄이 다릅니다(현재는 파인튜닝을 위해). 학습률은 1e-4에서 시작하여 10번째 에포크에서 1e-5로, 15번째 에포크에서 1e-6으로 감소하며, 총 20 에포크 내에 학습이 완료됩니다.
Testing.
우리는 프레임 간 자세를 추적하기 위해 [70]을 따릅니다. 이 과정은 세 단계로 구성됩니다: 사람 박스 감지 및 전파, 인간 자세 추정, 인접 프레임 간 자세 연관. 우리는 SimpleBaseline[70]에서 사용된 것과 동일한 사람 박스 감지기를 사용하며, FlowNet 2.0[25]으로 계산된 광학 흐름에 따라 예측된 키포인트를 전파하여 인접 프레임으로 검출된 박스를 전파합니다. 이후 박스 제거를 위해 비최대 억제(NMS)를 적용합니다. 자세 연관 방식은 한 프레임의 키포인트와 인접 프레임에서 전파된 키포인트 간의 객체 키포인트 유사성을 기반으로 합니다. 탐욕적 매칭 알고리즘은 인접 프레임의 키포인트 간의 대응을 계산하는 데 사용됩니다. 자세한 내용은 [70]에 나와 있습니다.
Results on the PoseTrack2017 test set.
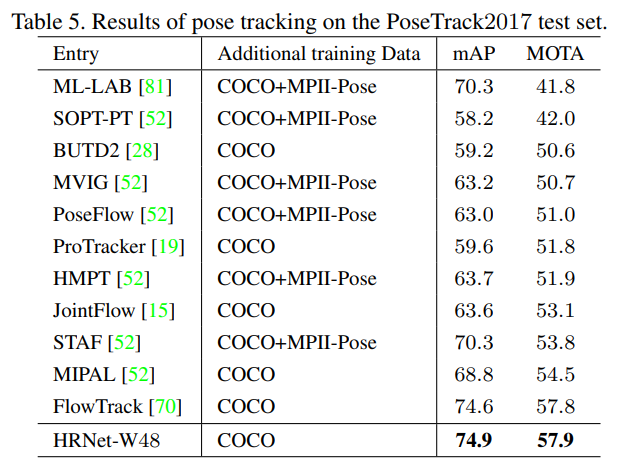
표 5는 결과를 보여줍니다. ResNet-152를 백본으로 사용한 SimpleBaseline의 FlowTrack[70]과 비교했을 때, 우리의 접근법은 mAP와 MOTA에서 각각 0.3과 0.1 포인트의 향상을 이뤘습니다. FlowTrack[70]에 대한 우수성은 COCO 키포인트 검출 및 MPII 인간 자세 추정 데이터셋에서도 일관되게 나타납니다. 이는 우리의 자세 추정 네트워크의 효과를 더욱 시사합니다.
4.4. Ablation Study
우리는 COCO 키포인트 검출 데이터셋에서 접근법의 각 구성 요소의 효과를 연구합니다. 모든 결과는 입력 크기가 256 × 192일 때 얻어졌으며, 입력 크기의 효과를 연구한 경우는 제외합니다.
Repeated multi-scale fusion.

우리는 반복되는 다중 스케일 융합의 효과를 실증적으로 분석합니다. 우리는 세 가지 변형 네트워크를 연구합니다. (a) 중간 교환 유닛 없이 (1개 융합): 마지막 교환 유닛을 제외하고 다중 해상도 서브네트워크 간 교환이 없습니다. (b) 단계 간 교환 유닛 사용 (3개 융합): 각 단계 내 병렬 서브네트워크 간 교환이 없습니다. (c) 단계 간 및 단계 내 교환 유닛 모두 사용 (총 8개 융합): 이것이 우리의 제안된 방법입니다. 모든 네트워크는 처음부터 학습되었습니다. 표 6에 주어진 COCO 검증 세트의 결과는 다중 스케일 융합이 효과적이며, 더 많은 융합이 더 나은 성능을 가져온다는 것을 보여줍니다.
Resolution maintenance.
우리는 HRNet의 변형의 성능을 연구합니다: 모든 4개의 고해상도에서 저해상도로 이어지는 서브네트워크가 시작 지점에서 추가되며, 깊이는 동일합니다. 융합 방식은 우리의 방법과 동일합니다. HRNet-W32와 그 변형(유사한 #Params와 GFLOPs를 가짐) 모두 처음부터 학습되었으며, COCO 검증 세트에서 테스트되었습니다. 변형은 72.5 AP를 달성했지만, 이는 HRNet-W32의 73.4 AP보다 낮습니다. 그 이유는 저해상도 서브네트워크의 초기 단계에서 추출된 저수준 특징이 덜 도움이 되기 때문이라고 생각됩니다. 또한, 저해상도 병렬 서브네트워크 없이 유사한 파라미터와 GFLOPs를 가진 단순 고해상도 네트워크는 훨씬 낮은 성능을 보입니다.
Representation resolution.
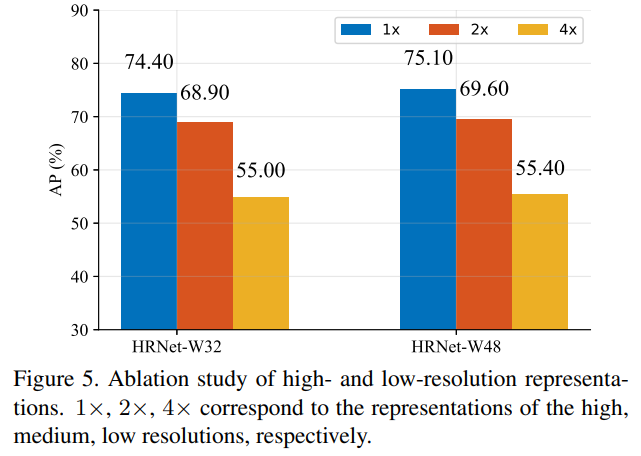
우리는 표현 해상도가 자세 추정 성능에 미치는 영향을 두 가지 측면에서 연구합니다: 각 해상도에서 특징 맵으로부터 추정된 히트맵의 품질을 확인하고, 입력 크기가 품질에 어떻게 영향을 미치는지 연구합니다.
우리는 ImageNet 분류를 위해 사전 학습된 모델로 초기화된 소형과 대형 네트워크를 학습합니다. 우리의 네트워크는 고해상도부터 저해상도까지 네 개의 응답 맵을 출력합니다. 가장 낮은 해상도 응답 맵의 히트맵 예측 품질은 너무 낮으며 AP 점수는 10점가 낮습니다. 다른 세 맵의 AP 점수는 그림 5에 보고되어 있습니다. 이 비교는 해상도가 키포인트 예측 품질에 영향을 미친다는 것을 시사합니다.
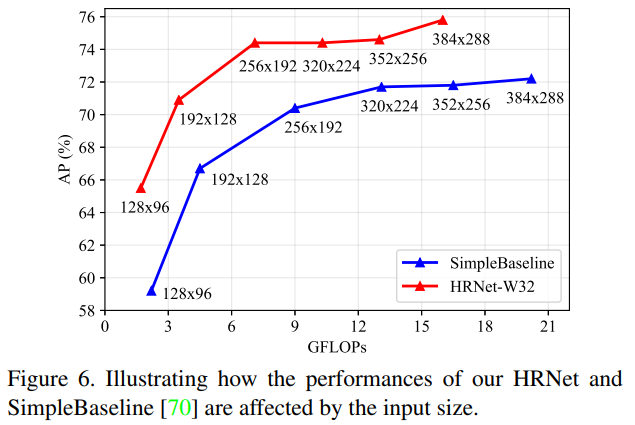
그림 6은 SimpleBaseline(ResNet-50)과 비교하여 입력 크기가 성능에 미치는 영향을 보여줍니다. 전체 과정에서 고해상도를 유지한 덕분에, 작은 입력 크기에서의 개선이 더 큰 입력 크기보다 더 크게 나타나며, 예를 들어 $256×192$ 에서는 4.0점, $128×96$ 에서는 6.3점의 개선이 있습니다. 이는 계산 비용이 중요한 요소인 실제 응용에서 우리의 접근법이 더 유리하다는 것을 의미합니다. 반면에, 우리의 접근법은 입력 크기 $256×192$ 일 때, 더 큰 입력 크기 $384×288$ 의 SimpleBaseline을 능가합니다.
5. Conclusion and Future Works
본 논문에서는 인간 자세 추정을 위한 고해상도 네트워크를 제시하며, 이는 정확하고 공간적으로 정밀한 키포인트 히트맵을 제공합니다. 이러한 성공은 두 가지 측면에서 비롯됩니다: (i) 고해상도를 회복할 필요 없이 전체 과정에서 유지하는 것; (ii) 다중 해상도 표현을 반복적으로 융합하여 신뢰성 있는 고해상도 표현을 생성하는 것.
향후 연구에서는 얼굴 정렬, 객체 검출, 의미론적 분할과 같은 다른 고밀도 예측 작업에 대한 적용과, 더 간단한 방식으로 다중 해상도 표현을 집계하는 방법에 대한 연구를 포함합니다.
Acknowledgements.
저자들은 유익한 토론을 제공해 준 Dianqi Li와 Lei Zhang에게 감사를 표합니다. Dr. Liu는 중국 과학 아카데미의 전략적 우선 연구 프로그램(Grant XDB06040900)의 부분 지원을 받았습니다.
Ke Sun, Bin Xiao, Dong Liu, Jingdong Wang Deep High-Resolution Representation Learning for Human Pose Estimation

댓글남기기