

개요
TPAMI’2019 에 발표된 HRNetv2로 불리는 Deep High-Resolution Representation Learning for Visual Recognition 논문의 얕은 리뷰
본 논문에서 제시한 HRNet 백본 구조는 고해상도에서 저해상도로 줄이는 다운샘플링에 이은 업샘플링을 사용하지 않고 다운샘플링 구조를 병렬적으로 배치하며 각 해상도 파이프라인간의 정보 교환을 통해 고해상도 정보와 다운샘플링 된 저해상도 정보의 지속적인 정보의 교환 및 반영으로 다중 해상도가 통합하여 사용할 수 있는 아키텍쳐를 구현한다. 또한 해당 구조에서 v1, v2, 추가로 V2p라는 버저닝을 사용하며 이는 각각, 고해상도 출력만을 사용하여 사람 자세 추정(히트맵 방식)에 사용하고 v2는 모든 스케일의 출력을 활용하여 시맨틱 세그멘테이션에 활용한다. 또한 V2p는 객체 감지 및 인스턴스 세그멘테이션에 활용한다. 여기서 V2p는 v2를 기반으로 한 고해상도 표현만을 사용하는 것이다.
네트워크
- 기본적으로 고해상도(원본 해상도) 스트림으로 시작하여 저해상도의 스트림을 하나씩 추가하는 식으로 구성된다.
- 이 때, 고해상도와 저해상도는 뒤로 연결되는 것이 아니라 병렬적으로 연결된다.
- 각 단계와 단계 사이에 다중 해상도 표현을 교환하는 연산이 있다. 해상도를 내릴 때는 strided 3*3 컨볼루션을 사용하여 해상도를 낮추며, 업샘플링 시에는 1*1 컨볼루션을 이용하여 업샘플링을 수행한다.
- 3종류의 헤드가 있다. HRNet
v1,v2,v2p로 이름 지었으며,v1은 병렬 스트림에서 제일 고해상도 출력만을 사용하는 것.v2는 저해상도 출력들을 전부 선형 업샘플링하여 고해상도로 조정 후 연결(concat)하여 사용한다.v2p는v2에서 생성된 고해상도 표현을 다운 샘플링하여 여러 레벨(스케일)의 표현을 구성한다. - 각 메인 해상도부터 원본 대비 1/4, 1/8, 1/16, 1/32 해상도를 가진다. 원본에서 2개의 3*3 컨볼루션으로 해상도를 줄이고 시작한다.
실험
실험은 매우 방대하게 진행되었으며, 사람 자세추정, 객체 감지, 의미론적 분할의 3가지 분야로 크게 나뉘어 진행되었다.
자세 추정
- 학습 이미지 크기 대비 W/4 * H/4 크기의 출력으로 관절의 히트맵 추정 방식을 이용한다.
- COCO 데이터 셋을 학습에 사용하였다. val2017 및 test-dev2017 세트를 평가한다.
- OKS 메트릭을 기반으로 각종 AP 및 AR을 평가한다.
- 학습은 기존 HRNet Pose 논문에 나와있는 것처럼 256*192, 384*288 해상도를 평가한다.
- 사람 객체 감지기는 SimpleBaseline의 그것과 동일한 것을 사용한다.
- val2017 데이터에 대해 Hourglass, CPN, SimpleBaseline의 메트릭 보다 좋은 성능을 확인한다.
- test-dev2017 데이터에 대해 bottom-up 보다 훨씬 우수한 결과를 보이며, 다른 여전히 CPN, SimpleBaseline 등의 Top-down 방법 모델들 보다 우수한 성능을 보인다.
의미론적 분할
- 각 픽셀의 클래스 레이블을 할당하는 문제로 PASCAL-Context, Cityscapes, LIP 데이터셋에서 테스트 한다.
- Cityscapes: 5,000장의 이미지, 30개의 클래스, 중 19개의 클래스가 평가에 사용되며 mIoU로 평가된다.
- PASCAL-Context: 약 10,000장의 이미지 데이터, 배경을 포함한 60개의 클래스
- LIP: 총 50,462장의 사람 이미지, 배경을 포함한 20개의 신체 카테고리
- 성능 지표는 mIoU 를 활용하여 평가된다.
- Cityscapes val 데이터 셋에 대해 DeepLabv3+, PSPNet, UNet++ 모델 대비 높은 성능을 보인다.
- Cityscapes test 데이터 셋에 대해 최신의 수많은 모델들과 비교하였고 HRNetV2-W48 모델이 가장 우수한 성능을 달성함을 확인한다.
- PASCAL-Context 데이터 셋에 대해 APCN, CFNet 등의 모델들과 비교하였고 HRNetV2를 기반으로 최신성능을 달성하지만, 이땐 OCR 방법론을 결합하여 최고 성능을 달성하였다.
- LIP 데이터 셋에 대해 CE2P, JPPNet 등의 모델과 비교하여, 더 적은 파라미터와 낮은 연산 비용으로 최고 성능을 달성한다.
COCO 객체 감지
- MS COCO 2017 객체 감지 데이터 셋에서 평가를 수행한다. 학습, val, test-dev로 나뉘어 있다.
- HRNetV2p 모델을 적용하여 추론을 수행한다.
- ResNet, ResNeXt 같은 표준 모델과 비교하며, Faster R-CNN, Cascade R-CNN, FCOS, CenterNet의 프레임워크와 비교한다.
- 일부 결과에서 HRNetV2p-W18의 비교군인 ResNet-50-FPN 보다 낮은 성능을 보이는데, 이는 학습의 이터레이션이 낮은 것으로 분석한다.
- Hybrid Task Cascaed 프레임워크의 테스트 결과를 바탕으로 더 긴 학습으로부터 많은 이점을 얻을 수 있음을 시사한다.
- 그 외에도 COCO test-dev 데이터 셋을 기반으로 최신의 객체 검출 모델들과의 비교를 진행하였으며, ResNet 및 ResNeXt 백본 기반의 프레임워크 보다 더 나은 성능을 보임을 확인한다.
소거 연구
- 자세 추정에서 고해상도 뿐 아니라 중간 및 최저 해상도 맵을 사용한 결과 도출 결과 성능이 많이 낮아졌다. 이는 출력의 해상도가 키포인트 예측 성능에 영향을 미친다는 것을 시사한다.
- 다중 해상도간 정보 교환의 효과를 실험적으로 테스트 하며, 최종 1번만 융합, 스테이지 간 3회 융합, 제안된 모델과 같이 8회 융합의 경우로 테스트 하며 결과를 통해 다중 해상도 융합이 더 나은 성능으로 이어짐을 확인한다.
- 자세 추정에서 변형 모델이 v1 모델보다 성능이 안좋음을 확인하고 저해상도의 저수준 특징이 자세추정 테스크에는 덜 유용함을 밝힌다.
- V1과 V2의 차이 연구를 통해 테스크 별 여러 해상도 특징 맵을 사용하는 것이 성능 향상에 도움이 됨을 확인한다.
결론
본 논문은 HRNet 백본을 기반으로 여러 헤드의 경우를 제시하며 다양한 비전 테스크에서 활용될 수 있는 방법을 제안한다. 가장 큰 특징으로 다중 해상도에 대한 병렬 처리 및 고해상도를 유지하는 파이프라인과 여러 멀티 스케일의 해상도를 네트워크 중간에서 서로 융합하며 정보를 교환하는 방법을 제안한다.
이를 사람 자세 추정, 의미론적 분할, 객체 검출 등의 여러 컴퓨터 비전 작업에 적용하며 성능을 테스트하였고 높은 성능을 달성함을 보여주었다.
해당 논문이 제시하는 HRNet 아키텍쳐는 메모리 소모와 연산 시간 및 연산 비용이 기존 기법과 유사하거나 더 적음을 확인하였고 정확도가 높으므로 각종 다양한 작업의 강력한 백본 네트워크로 사용될 수 있음을 확인하였다.
번역
Abstract
고해상도 표현은 인간 자세 추정, 의미론적 분할, 객체 검출과 같은 위치 민감 비전 문제에서 필수적입니다. 기존 최첨단 프레임워크는 고해상도에서 저해상도로 연속적인 컨볼루션을 연결한 서브네트워크(e.g., ResNet, VGGNet)를 통해 입력 이미지를 저해상도 표현으로 인코딩한 후, 이를 기반으로 고해상도 표현을 복원합니다. 반면, 우리가 제안하는 네트워크인 HRNet(High-Resolution Network)은 전체 과정에서 고해상도 표현을 유지합니다. 이 네트워크는 두 가지 주요 특징을 가집니다: (i) 고해상도에서 저해상도까지의 컨볼루션 스트림을 병렬로 연결합니다. (ii) 다양한 해상도 간 정보를 반복적으로 교환합니다. 이를 통해 결과로 얻어지는 표현은 의미적으로 더 풍부하고 공간적으로 더 정밀합니다. HRNet은 인간 자세 추정, 의미론적 분할, 객체 검출을 포함한 다양한 응용에서 뛰어난 성능을 보여주며, 컴퓨터 비전 문제를 위한 강력한 백본(backbone)이 될 수 있음을 시사합니다. 모든 코드는 https://github.com/HRNet 에서 확인할 수 있습니다.
Index Terms
HRNet, 고해상도 표현, 저해상도 표현, 인간 자세 추정, 의미론적 분할, 객체 검출.
1 INTRODUCTION
딥 컨볼루션 신경망(DCNN)은 이미지 분류, 객체 검출, 의미론적 분할, 인간 자세 추정 등 여러 컴퓨터 비전 과제에서 최첨단 결과를 달성했습니다. DCNN의 강점은 기존의 수작업 특징 표현보다 더 풍부한 표현을 학습할 수 있다는 점에 있습니다.
최근 개발된 대부분의 분류 네트워크(AlexNet [77], VGGNet [126], GoogleNet [133], ResNet [54] 등)는 LeNet-5 [81]의 설계 규칙을 따릅니다. 이 규칙은 그림 1(a)와 같이 설명됩니다: 특징 맵의 공간적 크기를 점차적으로 줄이고, 고해상도에서 저해상도로 컨볼루션을 순차적으로 연결하여 저해상도 표현을 생성한 뒤, 이를 분류를 위해 추가적으로 처리합니다.

고해상도 표현은 의미론적 분할, 인간 자세 추정, 객체 검출과 같은 위치 민감 과제에서 필요합니다. 이전의 최첨단 방법들은 그림 1(b)와 같이 분류 또는 분류 유사 네트워크에서 출력된 저해상도 표현을 고해상도로 복원하는 과정을 채택했습니다. 이 과정은 Hourglass [105], SegNet [3], DeconvNet [107], U-Net [119], SimpleBaseline [152], encoder-decoder [112] 등과 같은 네트워크에서 구현되었습니다. 추가적으로, 일부 다운샘플 레이어를 제거하고 중간 해상도 표현을 생성하기 위해 팽창 컨볼루션(dilated convolution)이 사용됩니다 [19], [181].
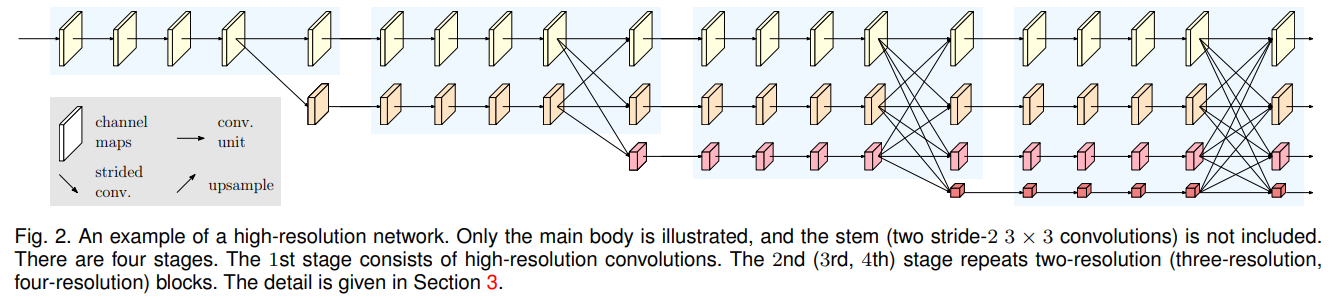
우리는 새로운 아키텍처인 High-Resolution Net (HRNet)을 제안합니다. HRNet은 전체 과정에서 고해상도 표현을 유지할 수 있습니다. 이 네트워크는 고해상도 컨볼루션 스트림으로 시작하여 고해상도에서 저해상도로의 컨볼루션 스트림을 하나씩 추가하며, 다중 해상도 스트림을 병렬로 연결합니다. 결과 네트워크는 그림 2와 같이 여러 단계(본 논문에서는 4단계)로 구성되며, n번째 단계는 n개의 해상도에 해당하는 n개의 스트림을 포함합니다. 우리는 병렬 스트림 간의 정보를 반복적으로 교환하여 다중 해상도 통합(multi-resolution fusion)을 수행합니다.
HRNet에서 학습된 고해상도 표현은 의미적으로 강력할 뿐만 아니라 공간적으로도 정밀합니다. 이는 두 가지 측면에서 비롯됩니다. (i) 우리의 접근 방식은 고해상도에서 저해상도로의 컨볼루션 스트림을 직렬이 아닌 병렬로 연결합니다. 따라서 저해상도로부터 고해상도를 복원하는 대신 고해상도를 유지할 수 있으며, 그 결과 학습된 표현은 공간적으로 더 정밀할 가능성이 있습니다. (ii) 대부분의 기존 통합 방식은 저해상도 표현을 업샘플링하여 얻은 고해상도 저수준 및 고수준 표현을 결합합니다. 반면에, 우리는 저해상도 표현을 활용하여 고해상도 표현을 강화하고 그 반대의 작업을 수행하기 위해 다중 해상도 통합을 반복적으로 수행합니다. 그 결과, 모든 고해상도에서 저해상도 표현이 의미적으로 강력합니다.
우리는 HRNet의 두 가지 버전을 제시합니다. 첫 번째 버전은 HRNetV1으로, 고해상도 컨볼루션 스트림에서 계산된 고해상도 표현만을 출력합니다. 우리는 이를 히트맵 추정 프레임워크를 따라 인간 자세 추정에 적용합니다. COCO 키포인트 검출 데이터셋 [94]에서 HRNetV1의 뛰어난 자세 추정 성능을 실험적으로 입증했습니다.
다른 하나는 HRNetV2로, 고해상도에서 저해상도로 병렬 스트림을 연결하여 모든 표현을 결합합니다. 우리는 이를 결합된 고해상도 표현으로부터 세그먼트 맵을 추정하여 의미론적 분할에 적용합니다. 제안된 방법은 유사한 모델 크기와 낮은 계산 복잡도로 PASCAL-Context, Cityscapes, LIP 데이터셋에서 최첨단 결과를 달성했습니다. COCO 자세 추정에서는 HRNetV1과 HRNetV2가 유사한 성능을 보였으며, 의미론적 분할에서는 HRNetV2가 HRNetV1보다 우수함을 관찰했습니다.
추가적으로, 우리는 HRNetV2에서 출력된 고해상도 표현을 기반으로 HRNetV2p라는 다중 레벨 표현을 구축하여 Faster R-CNN, Cascade R-CNN [12], FCOS [136], CenterNet [36] 등의 최첨단 검출 프레임워크와 Mask R-CNN [53], Cascade Mask R-CNN, Hybrid Task Cascade [16] 등의 최첨단 객체 검출 및 인스턴스 분할 프레임워크에 적용했습니다. 결과적으로, 우리의 방법은 검출 성능의 향상을 보여주었으며, 특히 작은 객체에 대해 극적인 성능 향상을 나타냈습니다.
2 RELATED WORK
우리는 인간 자세 추정 [57], 의미론적 분할, 객체 검출을 위해 주로 개발된 관련 표현 학습 기술을 세 가지 측면에서 검토합니다: 저해상도 표현 학습, 고해상도 표현 복원, 고해상도 표현 유지. 또한, 다중 해상도 통합과 관련된 몇 가지 연구도 언급합니다.
Learning low-resolution representations.
완전 컨볼루션 네트워크 접근법 [99], [124]은 분류 네트워크에서 완전 연결 계층을 제거하여 저해상도 표현을 계산하고, 거친(segmentation map) 세분화 맵을 추정합니다. 추정된 세분화 맵은 중간 저수준 중간 해상도 표현에서 추정된 세밀한 세분화 점수 맵을 결합하거나 [99], 과정을 반복함으로써 [76] 개선됩니다. 유사한 기술은 에지 검출(e.g., 전체론적 에지 검출 [157])에도 적용되었습니다.
완전 컨볼루션 네트워크는 몇 가지(보통 두 가지) 스트라이드 컨볼루션과 관련된 컨볼루션을 팽창 컨볼루션으로 대체하여 팽창 버전으로 확장되며, 이를 통해 중간 해상도 표현을 생성합니다 [18], [19], [86], [168], [181]. 이러한 표현은 여러 스케일에서 객체를 분할하기 위해 특징 피라미드를 통해 다중 스케일 맥락 표현으로 추가 강화됩니다 [19], [21], [181].
Recovering high-resolution representations.
업샘플 과정을 통해 저해상도 표현에서 고해상도 표현을 점진적으로 복원할 수 있습니다. 업샘플 서브네트워크는 다운샘플 과정(e.g., VGGNet)의 대칭 버전이 될 수 있으며, 풀링 인덱스를 변환하기 위해 일부 미러 레이어를 건너뛰는 연결을 사용합니다(e.g., SegNet [3], DeconvNet [107]). 또는 특징 맵을 복사하는 방식(e.g., U-Net [119], Hourglass [8], [9], [27], [31], [68], [105], [134], [163], [165], encoder-decoder [112])도 사용됩니다. U-Net의 확장 버전인 전해상도 잔여 네트워크(full-resolution residual network) [114]는 풀 이미지 해상도에서 정보를 전달하는 추가적인 전해상도 스트림을 도입하여 스킵 연결을 대체하며, 다운샘플 및 업샘플 서브네트워크의 각 유닛은 전해상도 스트림으로부터 정보를 받고 이를 전달합니다.
비대칭 업샘플 과정 또한 널리 연구되었습니다. RefineNet [90]은 업샘플된 표현과 다운샘플 과정에서 복사된 동일 해상도 표현의 결합을 개선합니다. 다른 연구로는 경량 업샘플 과정 [7], [24], [92], [152] (백본에 팽창 컨볼루션이 사용될 가능성 포함 [63], [89], [113]), 경량 다운샘플 및 무거운 업샘플 과정 [141], 재조합 네트워크 [55], 복잡하거나 더 많은 컨볼루션 유닛을 사용하여 스킵 연결 개선 [64], [111], [180], 저해상도 스킵 연결 정보를 고해상도 스킵 연결로 전달하거나 [189], 두 스킵 연결 간에 정보를 교환하는 방식 [49], 업샘플 과정의 세부 사항 연구 [147], 다중 스케일 피라미드 표현 결합 [22], [154], 조밀한 연결을 갖춘 다수의 DeconvNet/U-Net/Hourglass 스택 구성 [44], [149], [135] 등이 포함됩니다.
Maintaining high-resolution representations.
우리의 연구는 고해상도 표현을 생성할 수 있는 여러 연구들과 밀접하게 관련이 있습니다(e.g., convolutional neural fabrics [123], interlinked CNNs [188], GridNet [42], multi-scale DenseNet [58]).
초기 연구 두 가지인 convolutional neural fabrics [123]와 interlinked CNNs [188]은 저해상도 병렬 스트림을 언제 시작할지, 병렬 스트림 간의 정보를 어디에서 어떻게 교환할지에 대한 설계가 부족하며, 배치 정규화 및 잔여 연결을 사용하지 않아 만족스러운 성능을 보여주지 못합니다. GridNet [42]은 여러 U-Net을 결합한 형태와 유사하며, 두 개의 대칭 정보 교환 단계를 포함합니다: 첫 번째 단계는 고해상도에서 저해상도로만 정보를 전달하며, 두 번째 단계는 저해상도에서 고해상도로만 정보를 전달합니다. 이러한 제한은 분할 품질을 저하시킵니다. Multi-scale DenseNet [58]은 저해상도 표현으로부터 정보를 받지 않기 때문에 강력한 고해상도 표현을 학습할 수 없습니다.
Multi-scale fusion.
다중 스케일 통합은 널리 연구되었습니다 [11], [19], [24], [42], [58], [66], [122], [123], [157], [161], [181], [188]. 가장 단순한 방법은 다중 해상도 이미지를 개별 네트워크에 입력한 뒤 출력된 응답 맵을 결합하는 것입니다 [137]. Hourglass [105], U-Net [119], SegNet [3]은 스킵 연결을 통해 다운샘플 과정에서 생성된 저수준 특징을 업샘플 과정의 동일 해상도 고수준 특징으로 점진적으로 결합합니다. PSPNet [181]과 DeepLabV2/3 [19]은 피라미드 풀링 모듈과 팽창 공간 피라미드 풀링으로 얻은 피라미드 특징을 통합합니다. 우리의 다중 스케일(해상도) 통합 모듈은 이 두 풀링 모듈과 유사합니다. 차이점은 다음과 같습니다: (1) 우리의 통합 모듈은 단일 해상도 표현만 출력하는 대신 4개의 해상도 표현을 출력합니다. (2) 우리의 통합 모듈은 여러 번 반복되며 이는 딥 통합(deep fusion) [129], [143], [155], [178], [184]에서 영감을 받았습니다.
Our approach.
우리의 네트워크는 고해상도에서 저해상도로의 컨볼루션 스트림을 병렬로 연결합니다. 이를 통해 전체 과정에서 고해상도 표현을 유지하며, 다중 해상도 스트림에서 표현을 반복적으로 통합함으로써 강력한 위치 민감도를 가진 신뢰할 수 있는 고해상도 표현을 생성합니다.
이 논문은 우리의 이전 학회 논문 [130]을 상당히 확장한 것으로, 미발표 기술 보고서 [131]에서 추가된 자료와 최근 개발된 최첨단 객체 검출 및 인스턴스 분할 프레임워크에서의 더 많은 객체 검출 결과를 포함합니다. [130]과 비교했을 때 주요 기술적 혁신은 세 가지로 요약됩니다. (1) 우리는 [130]에서 제안한 네트워크(HRNetV1)를 두 가지 버전, 즉 HRNetV2와 HRNetV2p로 확장하였으며, 이는 네 가지 해상도 표현을 모두 탐구합니다. (2) 우리는 다중 해상도 통합과 일반 컨볼루션 사이의 연결을 구축하여 HRNetV2와 HRNetV2p에서 모든 네 가지 해상도 표현을 탐구할 필요성을 입증합니다. (3) 우리는 HRNetV1 대비 HRNetV2와 HRNetV2p의 우수성을 보여주며, HRNetV2와 HRNetV2p를 의미론적 분할 및 객체 검출을 포함한 다양한 비전 문제에 적용한 결과를 제시합니다.
3 HIGH-RESOLUTION NETWORKS
이미지는 스템(stem)으로 입력되며, 이 스템은 두 개의 stride-2 3×3 컨볼루션으로 구성되어 해상도를 $\frac{1}{4}$ 로 줄입니다. 이후 메인 본체가 같은 해상도($\frac{1}{4}$)로 표현을 출력합니다. 그림 2에 나타난 메인 본체는 아래에 상세히 설명된 여러 구성 요소로 이루어져 있습니다: 병렬 다중 해상도 컨볼루션, 반복적인 다중 해상도 통합, 그리고 그림 4에 표시된 표현 헤드입니다.
3.1 Parallel Multi-Resolution Convolutions
우리는 첫 번째 단계에서 고해상도 컨볼루션 스트림으로 시작하여, 고해상도에서 저해상도로의 스트림을 하나씩 추가하며 새로운 단계를 형성하고, 다중 해상도 스트림을 병렬로 연결합니다. 결과적으로, 이후 단계의 병렬 스트림은 이전 단계의 해상도와 추가된 더 낮은 해상도로 구성됩니다.
그림 2에 나타난 네트워크 구조의 예는 4개의 병렬 스트림으로 구성되며, 논리적으로 다음과 같습니다:
여기서 $\mathcal{N}_{sr}$ 은 $s$-번째 단계에서의 하위 스트림이며, $r$은 해상도 인덱스입니다. 첫 번째 스트림의 해상도 인덱스는 $r=1$ 입니다. 인덱스 $r$ 의 해상도는 첫 번째 스트림 해상도의 $\frac{1}{2^{r-1}}$ 에 해당합니다.
3.2 Repeated Multi-Resolution Fusions

통합 모듈의 목표는 다중 해상도 표현 간의 정보를 교환하는 것입니다. 이 과정은 여러 번 반복됩니다(예: 4개의 잔여 유닛마다 한 번씩).
그림 3에 나타난 3개의 해상도 표현을 통합하는 예를 살펴봅시다. 2개의 표현 또는 4개의 표현 통합은 쉽게 유도할 수 있습니다. 입력은 ${\mathbf{R}_r^i,r=1,2,3 }$ 으로 구성되며, 여기서 $r$ 은 해상도 인덱스이고, 관련된 출력 표현은 ${\mathbf{R}_r^o,r=1,2,3}$ 입니다. 각 출력 표현은 세 입력의 변환된 표현의 합입니다: $\mathbf{R}_r^o=f_{1r}(\mathbf{R}_1^i)+f_{2r}(\mathbf{R}_2^i)+f_{3r}(\mathbf{R}_3^i)$. 단계 간 통합(3단계에서 4단계로)은 추가 출력 값을 가집니다: $\mathbf{R}_4^o=f_{14}(\mathbf{R}_1^i)+f_{24}(\mathbf{R}_2^i)+f_{34}(\mathbf{R}_3^i)$.
변환 함수 $f_{rx}(⋅)$ 의 선택은 입력 해상도 인덱스 $x$ 와 출력 해상도 인덱스 $r$에 따라 결정됩니다. $x=r$ 인 경우, $f_{rx}(\mathbf{R})=\mathbf{R}$ 입니다. $x<r$ 인 경우, $f_{rx}(\mathbf{R})$ 은 입력 표현 $\mathbf{R}$ 을 $(r−x)$ 번의 stride-2 $3×3$ 컨볼루션을 통해 다운샘플링합니다. 예를 들어, 2× 다운샘플링에는 한 번의 stride-2 3×3 컨볼루션을, 4× 다운샘플링에는 두 번의 연속적인 stride-2 3×3 컨볼루션을 사용합니다. $x>r$ 인 경우, $f_{rx}(\mathbf{R})$ 은 선형 업샘플링 후 1×1 컨볼루션을 사용하여 채널 수를 정렬하며 입력 표현 $\mathbf{R}$ 을 업샘플링합니다. 이러한 함수는 그림 3에 나타나 있습니다.
3.3 Representation Head
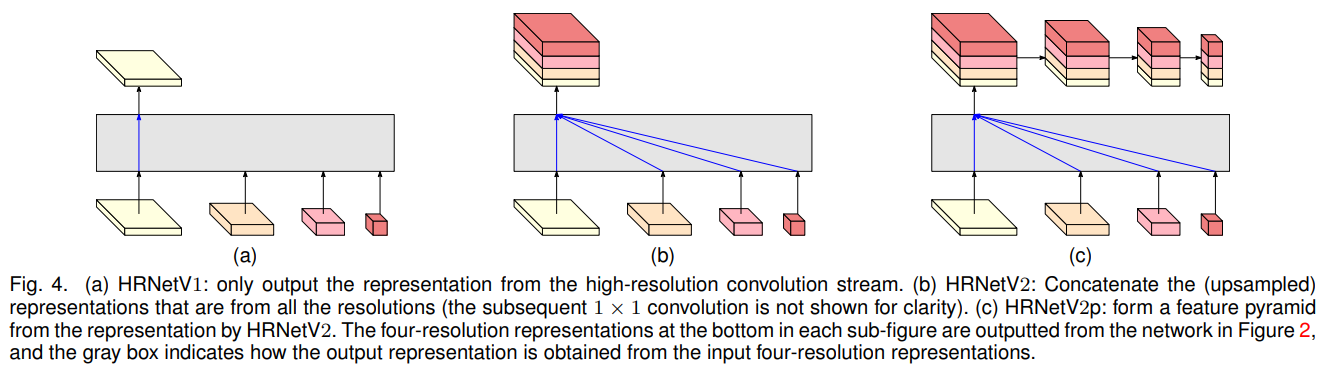
우리는 그림 4에 나타난 세 가지 표현 헤드를 가지고 있으며, 각각 HRNetV1, HRNetV2, HRNetV2p라고 부릅니다.
HRNetV1. 출력은 고해상도 스트림에서만 생성된 표현입니다. 다른 세 표현은 무시됩니다. 이는 그림 4(a)에 나타나 있습니다.
HRNetV2. 저해상도 표현을 선형 업샘플링하여 채널 수를 변경하지 않고 고해상도로 조정한 후, 네 가지 표현을 연결하고, 1×1 컨볼루션을 추가로 수행하여 네 표현을 혼합합니다. 이는 그림 4(b)에 나타나 있습니다.
HRNetV2p. HRNetV2에서 출력된 고해상도 표현을 다운샘플링하여 여러 레벨의 표현을 구성합니다. 이는 그림 4(c)에 나타나 있습니다.
본 논문에서는 HRNetV1의 인간 자세 추정 결과, HRNetV2의 의미론적 분할 결과, HRNetV2p의 객체 검출 및 인스턴스 분할 결과를 제시하며, HRNetV1에 대한 HRNetV2와 HRNetV2p의 우수성을 입증합니다.
3.4 Instantiation
메인 본체는 네 개의 병렬 컨볼루션 스트림으로 이루어진 네 단계를 포함합니다. 해상도는 1/4, 1/8, 1/16, 1/32 입니다. 첫 번째 단계는 폭이 64인 병목으로 구성된 4개의 잔여 유닛(residual unit)을 포함하며, 그 뒤에 특징 맵의 폭을 $C$ 로 변경하는 3×3 컨볼루션이 따릅니다. 두 번째, 세 번째, 네 번째 단계는 각각 1, 4, 3개의 모듈화된 블록을 포함합니다. 모듈화된 블록의 다중 해상도 병렬 컨볼루션의 각 분기는 4개의 잔여 유닛을 포함합니다. 각 유닛은 각 해상도에 대해 두 개의 3×3 컨볼루션으로 구성되며, 각 컨볼루션 뒤에는 배치 정규화와 비선형 활성화 함수(ReLU)가 따릅니다. 네 가지 해상도에서의 컨볼루션 폭(채널 수)은 각각 $C$, $2C$, $4C$, $8C$ 입니다. 예시는 그림 2에 나타나 있습니다.
3.5 Analysis
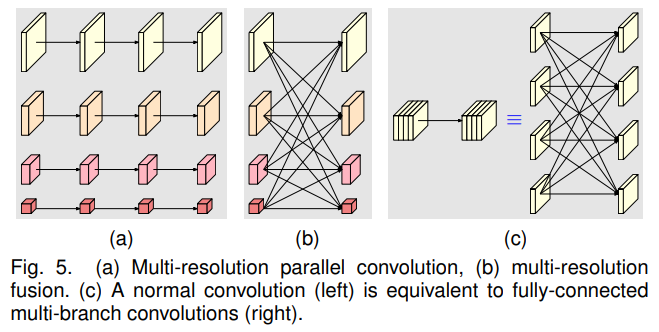
우리는 두 가지 구성 요소로 나뉜 모듈화된 블록을 분석합니다: 다중 해상도 병렬 컨볼루션(그림 5 (a))과 다중 해상도 통합(그림 5 (b)). 다중 해상도 병렬 컨볼루션은 그룹 컨볼루션과 유사합니다. 입력 채널을 여러 서브셋으로 나누고, 각 서브셋에 대해 서로 다른 공간 해상도에서 별도로 일반 컨볼루션을 수행합니다. 반면 그룹 컨볼루션에서는 해상도가 동일합니다. 이 연결은 다중 해상도 병렬 컨볼루션이 그룹 컨볼루션의 일부 이점을 활용함을 시사합니다.
다중 해상도 통합 유닛은 그림 5 (c)에 나타난 것처럼 일반 컨볼루션의 다중 분기 완전 연결 형태와 유사합니다. 일반 컨볼루션은 [178]에서 설명된 대로 여러 작은 컨볼루션으로 나눌 수 있습니다. 입력 채널은 여러 서브셋으로 나뉘며, 출력 채널 또한 여러 서브셋으로 나뉩니다. 입력과 출력 서브셋은 완전 연결 방식으로 연결되며, 각 연결은 일반 컨볼루션입니다. 출력 채널의 각 서브셋은 입력 채널의 각 서브셋에 대해 수행된 컨볼루션의 출력 합계입니다. 차이점은 다중 해상도 통합이 해상도 변화를 처리해야 한다는 점입니다. 다중 해상도 통합과 일반 컨볼루션 간의 연결은 HRNetV2와 HRNetV2p에서 수행된 네 가지 해상도 표현 탐구의 필요성을 뒷받침하는 증거를 제공합니다.
4 HUMAN POSE ESTIMATION

사람 자세 추정(키포인트 검출)은 이미지 $I$ (크기 $W×H×3$)로부터 $K$ 개의 키포인트 또는 신체 부위(예: 팔꿈치, 손목 등)의 위치를 검출하는 것을 목표로 합니다. 우리는 최첨단 프레임워크를 따르며 이 문제를 $K$ 개의 히트맵 {$H_1,H_2,…,H_K$}을 추정하는 문제로 변환합니다. 각 히트맵 $H_k$ 는 $k$-번째 키포인트의 위치 신뢰도를 나타내며, 크기는 $\frac{W}{4}× \frac{H}{4}$ 입니다.
우리는 HRNetV1이 출력한 고해상도 표현에 대해 히트맵을 회귀(regress)합니다. 실험적으로 HRNetV1과 HRNetV2의 성능이 거의 동일하다는 것을 관찰했으며, HRNetV1이 계산 복잡도가 조금 더 낮기 때문에 이를 선택했습니다. 손실 함수는 예측된 히트맵과 정답 히트맵을 비교하는 평균 제곱 오차(mean squared error)로 정의됩니다. 정답 히트맵은 키포인트의 정답 위치를 중심으로 표준 편차 2 픽셀의 2D 가우시안을 적용하여 생성됩니다. 몇 가지 예제 결과는 그림 6에 제시됩니다.
Dataset.
COCO 데이터셋 [94]은 17개의 키포인트로 라벨링된 200,000개 이상의 이미지와 250,000개의 사람 인스턴스를 포함합니다. 우리는 train2017 세트(57K 이미지 및 150K 사람 인스턴스)를 사용하여 모델을 학습하고, val2017 및 test-dev2017 세트(각각 5,000개 및 20K 이미지)를 사용하여 접근법을 평가합니다.
Evaluation metric.
표준 평가 지표는 객체 키포인트 유사도(Object Keypoint Similarity, OKS)를 기반으로 합니다: $OKS=\frac{\sum_i{\exp{(-d_i^2/2s^2k_i^2)\delta(v_i>0)}}}{\sum{_i}{\delta(v_i>0)}}$. 여기서 $d_i$ 는 예측된 키포인트와 정답 키포인트 간의 유클리드 거리이고, $v_i$ 는 정답의 가시성 플래그입니다. $s$ 는 객체의 스케일이며, $k_i$ 는 키포인트마다 고유하게 정의된 감소율 제어 상수입니다. 우리는 표준 평균 정밀도(AP)와 리콜 점수를 보고합니다: AP50 (OKS = 0.50에서의 AP), AP75, AP (10개의 OKS 위치에서의 평균 AP), 중간 크기 객체를 위한 APM, 큰 크기 객체를 위한 APL, 그리고 AR (10개의 OKS 위치에서의 평균 AR).
Training.
우리는 사람 감지 박스를 높이 또는 너비로 확장하여 고정된 종횡비(높이 : 너비 = 4 : 3)를 맞춘 후, 이미지를 해당 박스로 크롭하고 $256 × 192$ 또는 $384 × 288$ 크기로 리사이즈합니다. 데이터 증강 기법은 랜덤 회전([-45°, 45°]), 랜덤 스케일링([0.65, 1.35]), 그리고 플리핑을 포함합니다. [146]에 따라 하프 바디 데이터 증강도 적용됩니다.
최적화에는 Adam 옵티마이저 [71]를 사용합니다. 학습 스케줄은 [152]를 따릅니다. 초기 학습률은 $1e−3$ 로 설정되며, 170번째와 200번째 에폭에서 각각 $1e-4$ 및 $1e−5$ 로 감소합니다. 학습은 210 에폭 내에 종료됩니다. 모델 학습은 4개의 V100 GPU에서 이루어지며 HRNet-W32는 약 60시간, HRNet-W48은 약 80시간 소요됩니다.
Testing.
우리는 [24], [109], [152]와 유사한 2단계 탑다운 패러다임을 사용합니다: 사람 감지기를 사용해 객체 인스턴스를 검출한 후, 키포인트를 예측합니다.
val 및 test-dev 세트 모두 SimpleBaseline에서 제공된 사람 감지기를 사용합니다. [24], [105], [152]를 따라, 히트맵은 원본 이미지와 플리핑된 이미지의 히트맵을 평균 내어 계산합니다. 각 키포인트 위치는 히트맵의 최대값 위치를 기반으로 하여, 가장 높은 응답에서 두 번째로 높은 응답 방향으로 1/4 픽셀 오프셋을 조정해 예측됩니다.
Results on the val set.
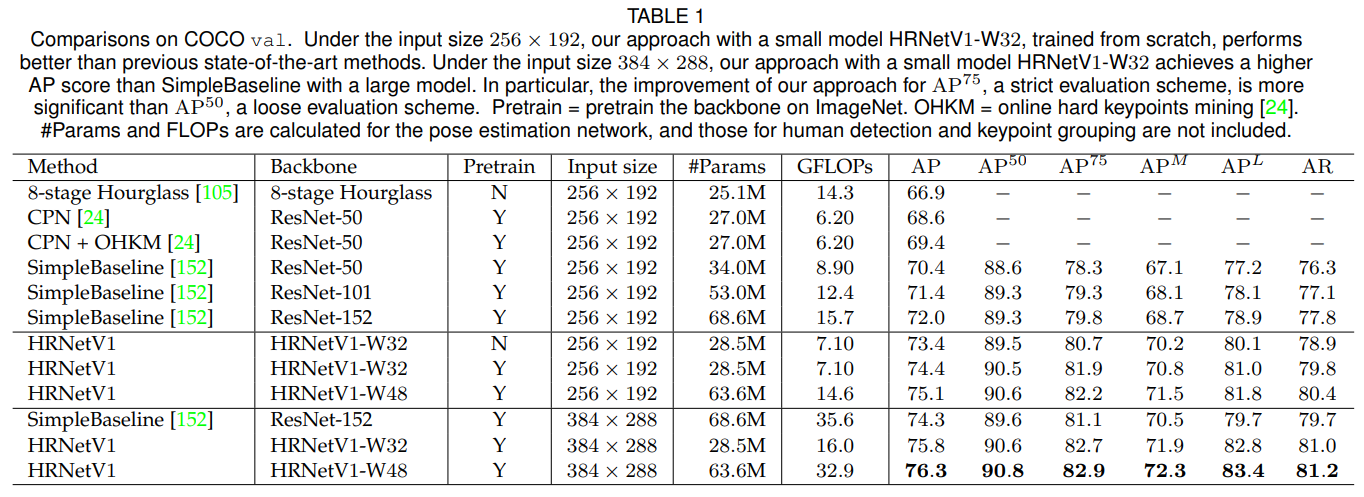
우리는 Table 1에서 제안된 방법과 다른 최신 기법의 결과를 보고합니다. HRNetV1-W32 네트워크는 $256 × 192$ 의 입력 크기로 처음부터 학습되었으며, AP 점수 73.4를 기록하며 동일한 입력 크기의 다른 방법들을 능가합니다. (i) Hourglass [105]와 비교하여, 우리 네트워크는 AP를 6.5점 개선했으며, GFLOP은 훨씬 낮고 절반 이하입니다. 매개변수 수는 비슷하지만 약간 더 많습니다. (ii) CPN [24] w/o 및 w/ OHKM과 비교하여, 우리 네트워크는 약간 더 큰 모델 크기와 약간 더 높은 복잡성으로 각각 4.8점과 4.0점의 이득을 얻습니다. (iii) 이전 최고의 방법인 SimpleBaseline [152]와 비교하여, HRNetV1-W32는 다음과 같은 상당한 개선을 얻었습니다: ResNet-50 백본의 경우 비슷한 모델 크기와 GFLOPs로 AP가 3.0점 증가했으며, ResNet-152 백본의 경우 모델 크기(#Params)와 GFLOPs가 두 배인 상황에서도 AP가 1.4점 증가했습니다.
우리 네트워크는 다음의 이점을 얻을 수 있습니다: (i) ImageNet에서 사전 학습된 모델을 사용한 학습: HRNetV1-W32는 1.0점의 이득을 얻습니다. (ii) 폭을 늘려 용량을 증가시킴: HRNetV1-W48은 입력 크기 $256 × 192$ 와 $384 × 288$에 대해 각각 0.7점과 0.5점의 이득을 얻습니다.
입력 크기가 384 × 288인 경우, HRNetV1-W32와 HRNetV1-W48은 각각 75.8과 76.3의 AP 점수를 기록하며, 입력 크기 256 × 192와 비교하여 각각 1.4점과 1.2점의 개선을 보여줍니다. SimpleBaseline [152]에서 ResNet-152 백본을 사용하는 경우와 비교했을 때, HRNetV1-W32와 HRNetV1-W48은 각각 AP 기준으로 1.5점과 2.0점의 개선을 얻었으며, 이는 각각 45%와 92.4%의 계산 비용에서 이루어진 것입니다.
Results on the test-dev set.
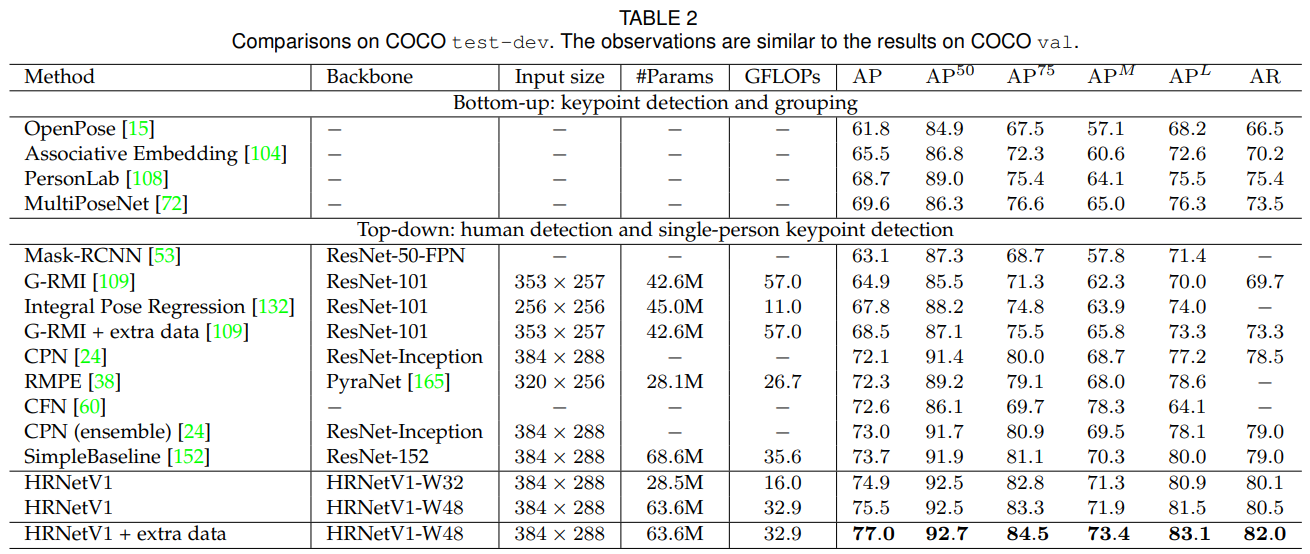
Table 2는 제안된 방법과 기존 최신 기법들의 자세 추정 성능을 보여줍니다. 제안된 방법은 하향식 방법(bottom-up approaches)보다 훨씬 우수합니다. 반면, 작은 네트워크인 HRNetV1-W32는 AP 점수 74.9를 기록하며, 다른 모든 상향식(top-down) 접근법을 능가하며 모델 크기(#Params)와 계산 복잡성(GFLOPs) 측면에서 더 효율적입니다. 대형 모델인 HRNetV1-W48은 최고 AP 점수인 75.5를 달성합니다. 동일한 입력 크기에서 SimpleBaseline [152]와 비교했을 때, 우리의 소형 네트워크와 대형 네트워크는 각각 1.2와 1.8점의 개선을 보였습니다. AI Challenger [148]의 추가 데이터를 사용해 학습하면, 우리의 단일 대형 네트워크는 AP 점수 77.0을 달성할 수 있습니다.
5 SEMANTIC SEGMENTATION

의미론적 분할은 각 픽셀에 클래스 레이블을 할당하는 문제입니다. 우리의 접근법을 통해 얻은 일부 예제 결과는 그림 7에 제시되어 있습니다. 입력 이미지는 HRNetV2(그림 4(b))에 입력되고, 각 위치에서 15C 차원의 표현을 선형 분류기에 전달하여 소프트맥스 손실로 세분화 맵을 예측합니다. 세분화 맵은 학습과 테스트 모두에서 선형 업샘플링을 통해 입력 크기의 4배로 업샘플링됩니다. 우리는 두 가지 장면 파싱 데이터셋 PASCAL-Context [103]와 Cityscapes [28], 그리고 사람 파싱 데이터셋인 LIP [47]에 대한 결과를 보고합니다. 클래스별 교차-연합 평균(mIoU)이 평가 지표로 채택되었습니다.
Cityscapes.
Cityscapes 데이터셋 [28]은 고품질 픽셀 레벨로 정교하게 주석된 장면 이미지 5,000장을 포함합니다. 이 정교하게 주석된 이미지는 학습, 검증 및 테스트를 위해 각각 2,975/500/1,525장으로 나뉘어 있습니다. 총 30개의 클래스가 있으며, 그 중 19개의 클래스가 평가에 사용됩니다. 클래스별 교차-연합 평균(mIoU) 외에도 테스트 세트에서 IoU 카테고리(cat.), iIoU 클래스(cla.), iIoU 카테고리(cat.)의 세 가지 점수를 보고합니다.
우리는 동일한 학습 프로토콜 [181], [182]을 따릅니다. 데이터는 랜덤 크롭(1024 × 2048에서 512 × 1024), [0.5, 2] 범위의 랜덤 스케일링, 그리고 랜덤 수평 플리핑을 통해 증강됩니다. 기본 학습률 0.01, 모멘텀 0.9, 가중치 감쇠 0.0005를 사용하여 SGD 옵티마이저를 적용합니다. 폴리 학습률 정책은 0.9의 power로 학습률을 감소시키는 데 사용됩니다. 모든 모델은 4개의 GPU와 동기화 배치 정규화(syncBN)를 사용하여 배치 크기 12로 120K 반복 학습됩니다.
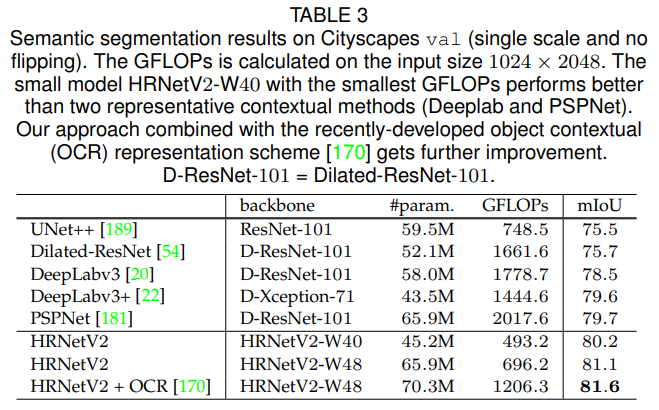
Table 3은 Cityscapes val 세트에서 파라미터 및 계산 복잡도와 mIoU 클래스 측면에서 여러 대표적인 방법과의 비교를 제공합니다. (i) HRNetV2-W40(40은 고해상도 컨볼루션의 폭을 나타냄)는 DeepLabv3+와 유사한 모델 크기를 가지면서도 훨씬 낮은 계산 복잡도를 가지고 더 나은 성능을 보입니다: UNet++ 대비 4.7점, DeepLabv3 대비 1.7점, 그리고 PSPNet 및 DeepLabv3+ 대비 약 0.5점의 향상을 달성합니다. (ii) HRNetV2-W48은 PSPNet과 유사한 모델 크기를 가지면서도 계산 복잡도가 훨씬 낮아 더욱 의미 있는 개선을 달성합니다: UNet++ 대비 5.6점, DeepLabv3 대비 2.6점, 그리고 PSPNet 및 DeepLabv3+ 대비 약 1.4점의 향상을 달성합니다. 이후의 비교에서는, ImageNet에서 사전 학습된 HRNetV2-W48을 사용하며, 이는 대부분의 Dilated-ResNet-101 기반 방법들과 유사한 모델 크기를 가집니다.
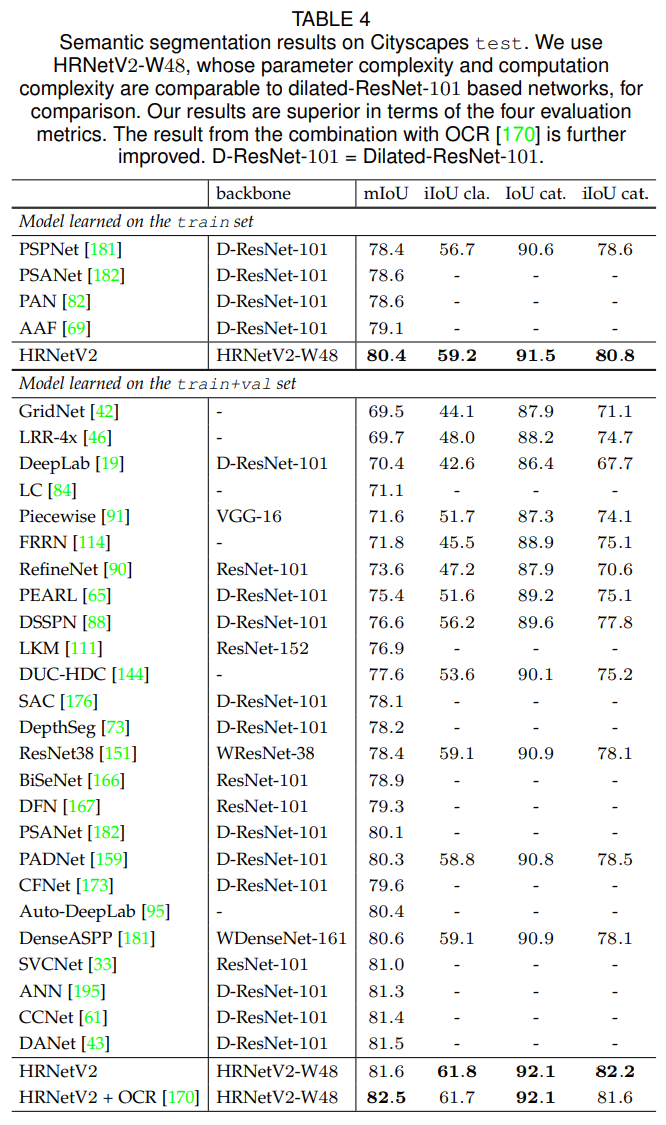
Table 4는 Cityscapes test 세트에서 우리의 방법과 최신 기법들 간의 비교를 제공합니다. 모든 결과는 6개의 스케일과 플리핑을 사용했습니다. 두 가지 경우가 평가됩니다: 하나는 train 세트에서 학습된 모델이며, 다른 하나는 train+val 세트에서 학습된 모델입니다. 두 경우 모두 HRNetV2-W48이 우수한 성능을 달성합니다.
PASCAL-Context.
PASCAL-Context 데이터셋 [103]은 학습용 4,998장의 장면 이미지와 테스트용 5,105장의 이미지를 포함하며, 59개의 의미론적 라벨과 1개의 배경 라벨이 제공됩니다.
데이터 증강과 학습률 정책은 Cityscapes와 동일합니다. 널리 사용되는 학습 전략 [32], [172]에 따라 이미지를 $480×480$ 크기로 리사이즈하고, 초기 학습률을 0.004로 설정하며, 가중치 감쇠는 0.0001로 설정합니다. 배치 크기는 16이고 학습 반복 수는 $60K$ 입니다.
우리는 표준 테스트 절차 [32], [172]를 따릅니다. 이미지는 $480×480$ 으로 리사이즈된 후 네트워크에 입력됩니다. 결과로 얻어진 $480×480$ 라벨 맵은 원본 이미지 크기로 다시 리사이즈됩니다. 우리는 6개의 스케일과 플리핑을 사용하여 우리의 접근법과 다른 접근법의 성능을 평가합니다.
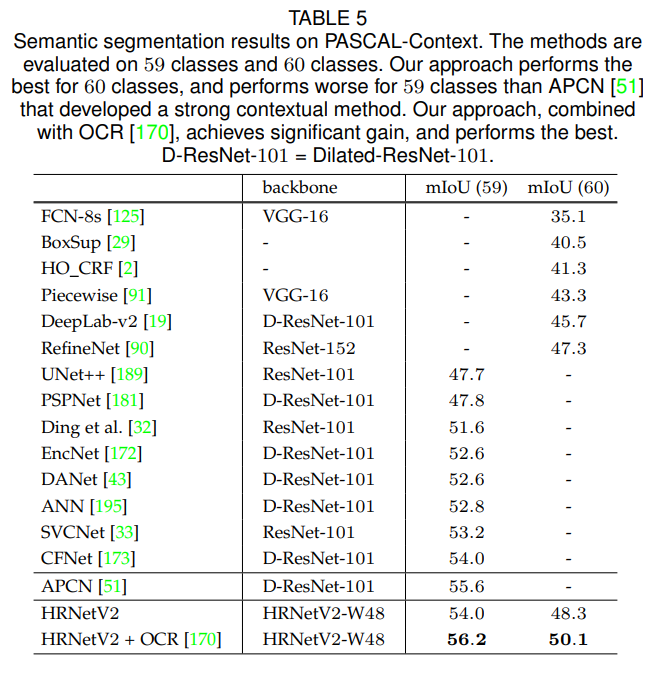
Table 5는 우리의 방법과 최신 기법들을 비교한 결과를 보여줍니다. 평가 방식은 두 가지로, 59개 클래스와 60개 클래스(59개 클래스 + 배경)에 대한 mIoU입니다. 두 경우 모두 HRNetV2-W48이 최신 성능을 달성하지만, OCR 스키마 [170]를 사용하지 않은 경우 [51]의 결과가 우리보다 높았습니다.
LIP.
LIP 데이터셋 [47]은 정교하게 주석된 50,462개의 사람 이미지로 구성되며, 학습용 30,462장과 검증용 10,000장으로 나뉘어 있습니다. 방법들은 20개의 범주(19개의 신체 부위 라벨과 1개의 배경 라벨)에 대해 평가됩니다. 표준 학습 및 테스트 설정 [98]을 따르며, 이미지는 $473×473$ 크기로 리사이즈되고 성능은 원본 이미지와 플리핑된 이미지의 세분화 맵 평균을 기반으로 평가됩니다.
데이터 증강과 학습률 정책은 Cityscapes와 동일합니다. 학습 전략은 최근 설정 [98]을 따르며, 초기 학습률은 0.007로 설정하고 모멘텀은 0.9, 가중치 감쇠는 0.0005로 설정합니다. 배치 크기는 40이며, 반복 횟수는 $110K$ 입니다.
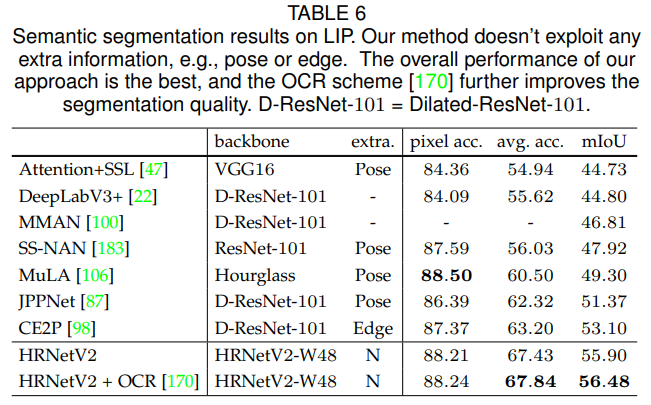
Table 6은 우리의 방법과 최신 기법을 비교한 결과를 보여줍니다. HRNetV2-W48의 전체 성능은 더 적은 파라미터와 낮은 계산 비용으로 최고 성능을 달성합니다. 또한 우리의 네트워크는 포즈나 에지와 같은 추가 정보를 사용하지 않았다는 점을 강조하고자 합니다.
6 COCO OBJECT DETECTION

우리는 MS COCO 2017 검출 데이터셋에서 평가를 수행합니다. 이 데이터셋은 학습용 약 118k 이미지, 검증용 (val) 5k 이미지, 그리고 주어진 주석이 없는 테스트용 (test-dev) 약 20k 이미지를 포함합니다. 표준 COCO 평가 방식을 적용합니다. 우리의 접근법을 통해 얻은 일부 예제 결과는 그림 8에 제시됩니다.
우리는 객체 검출을 위해 다중 레벨 표현(HRNetV2p)을 적용하며, 이는 그림 4 (c)에 나타나 있습니다. 데이터는 표준 수평 플리핑을 통해 증강됩니다. 입력 이미지는 짧은 변의 길이가 800 픽셀이 되도록 리사이즈됩니다 [92]. 추론은 단일 이미지 스케일에서 수행됩니다.
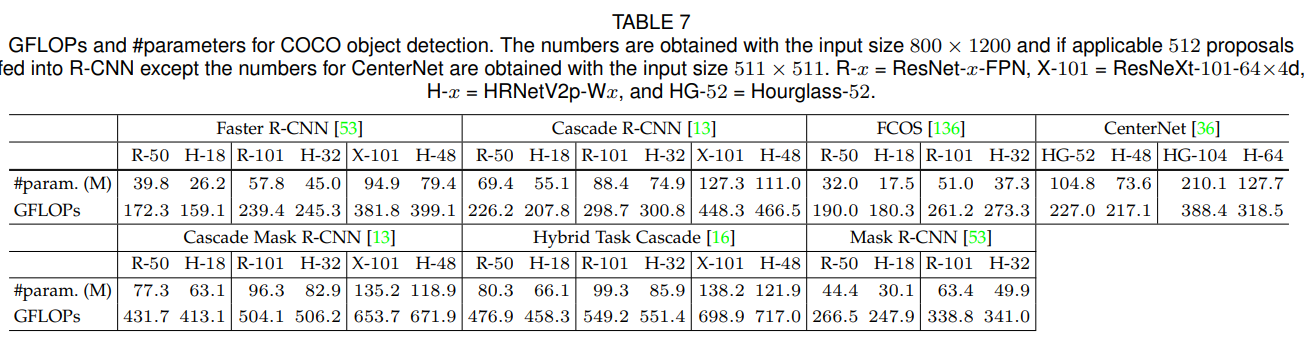
우리는 HRNet을 ResNet [54]과 ResNeXt [156] 같은 표준 모델과 비교합니다. COCO val에서 검출 성능을 두 가지 앵커 기반 프레임워크(Faster R-CNN [118], Cascade R-CNN [12])와 두 가지 최신 앵커-프리 프레임워크(FCOS [136], CenterNet [36])에서 평가합니다. Faster R-CNN 및 Cascade R-CNN 모델은 HRNetV2p와 ResNet 모두에 대해 공공 MMDetection 플랫폼 [17]에서 제공된 학습 설정을 사용하여 학습되지만, 학습률 스케줄은 [52]에서 제안한 $2×$ 설정을 따릅니다. FCOS [136] 및 CenterNet [36]은 저자들이 제공한 구현을 사용합니다. Table 7은 #파라미터와 GFLOPs를 요약합니다. Table 8과 Table 9는 검출 점수를 보고합니다.
또한 Mask R-CNN [53], Cascade Mask R-CNN [13], 그리고 Hybrid Task Cascade [16]의 세 가지 프레임워크를 사용하여 객체 검출 및 인스턴스 세분화 성능을 평가합니다. 결과는 공공 MMDetection 플랫폼 [17]에서 얻어졌으며 Table 10에 나타나 있습니다.
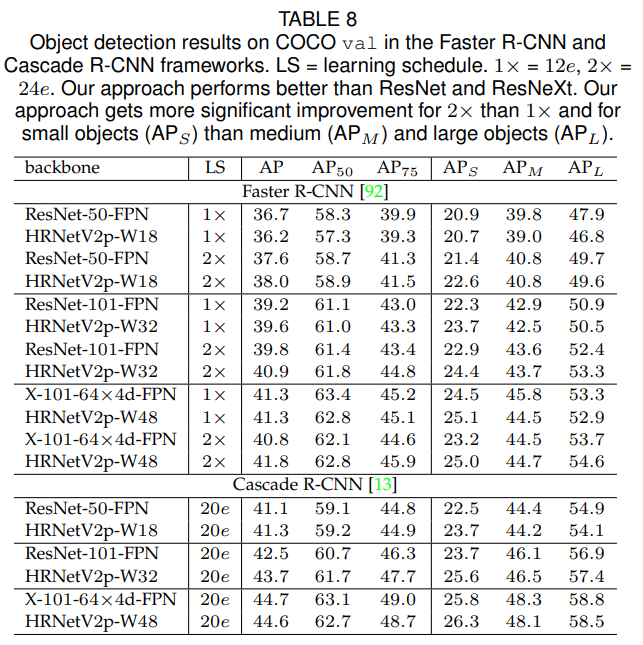
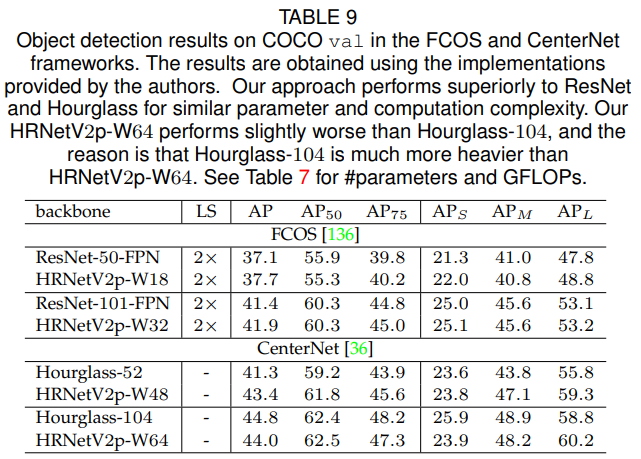
몇 가지 관찰이 있습니다. 한편, Tables 8과 9에 나타난 것처럼 HRNetV2의 전체 객체 검출 성능은 유사한 모델 크기와 계산 복잡도를 가진 ResNet보다 더 우수합니다. 일부 경우, $1×$ 학습에서는 HRNetV2p-W18이 ResNet-50-FPN보다 낮은 성능을 보이는데, 이는 최적화 반복 횟수가 부족하기 때문일 수 있습니다. 다른 한편, Table 10에 나타난 것처럼 전체 객체 검출 및 인스턴스 세분화 성능은 ResNet과 ResNeXt보다 더 뛰어납니다. 특히 Hybrid Task Cascade 프레임워크에서 HRNet은 $20e$ 학습에서는 ResNeXt-101-64×4d-FPN보다 약간 낮은 성능을 보이지만, $28e$ 학습에서는 더 나은 성능을 보입니다. 이는 HRNet이 더 긴 학습으로부터 더 많은 혜택을 얻는다는 것을 시사합니다.

Table 11은 COCO test-dev에서 우리의 네트워크를 최신 단일 모델 객체 검출기와 비교한 결과를 보여줍니다. 이 비교는 [85], [97], [110], [115], [127], [128]에서 수행된 멀티 스케일 학습 및 테스트 없이 수행되었습니다. Faster R-CNN 프레임워크에서 우리의 네트워크는 유사한 파라미터 및 계산 복잡도를 가진 ResNet보다 더 나은 성능을 보입니다: HRNetV2p-W32 vs. ResNet-101-FPN, HRNetV2p-W40 vs. ResNet-152-FPN, HRNetV2p-W48 vs. X-101-64×4d-FPN. Cascade R-CNN과 CenterNet 프레임워크에서도 HRNetV2는 더 나은 성능을 보이며, Cascade Mask R-CNN 및 Hybrid Task Cascade 프레임워크에서도 HRNet은 전체적으로 더 나은 성능을 달성합니다.

7 ABLATION STUDY
우리는 HRNet의 구성 요소에 대한 ablation 연구를 두 가지 작업에서 수행합니다: COCO 검증 데이터셋에서 인간 자세 추정과 Cityscapes 검증 데이터셋에서 의미론적 분할입니다. 우리는 주로 HRNetV1-W32를 인간 자세 추정에, HRNetV2-W48을 의미론적 분할에 사용합니다. 모든 자세 추정 결과는 입력 크기 $256×192$에서 얻어졌습니다. 또한 HRNetV1과 HRNetV2를 비교한 결과도 제시합니다.
Representations of different resolutions.
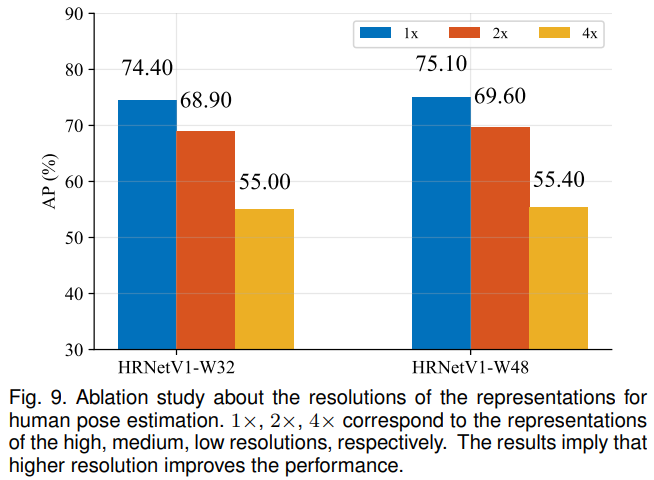
우리는 표현 해상도가 자세 추정 성능에 어떤 영향을 미치는지를 확인하기 위해 각 해상도의 특징 맵에서 추정된 히트맵의 품질을 검토합니다. 우리는 ImageNet 분류용으로 사전 학습된 모델을 사용하여 초기화된 두 개의 HRNetV1 네트워크를 훈련시켰습니다. 네트워크는 고해상도에서 저해상도까지 네 개의 응답 맵을 출력합니다. 가장 낮은 해상도 응답 맵에서의 히트맵 예측 품질은 매우 낮으며 AP 점수는 10점 미만입니다. 나머지 세 가지 맵의 AP 점수는 그림 9에 보고되어 있습니다. 이 비교는 해상도가 키포인트 예측 품질에 영향을 미친다는 것을 시사합니다.
Repeated multi-resolution fusion.
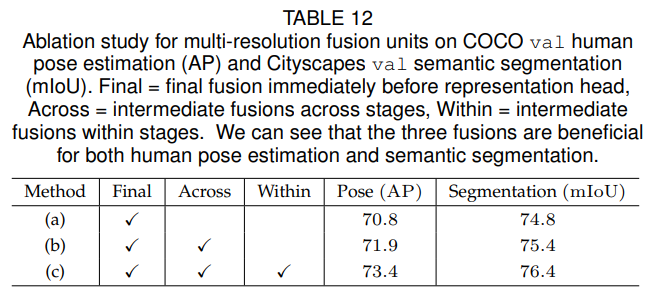
우리는 반복된 다중 해상도 융합의 효과를 실험적으로 분석합니다. 우리의 네트워크에 대해 세 가지 변형을 연구합니다. (a) 중간 융합 유닛 없음 (1회 융합): 최종 융합 유닛을 제외하고 다중 해상도 스트림 간 융합이 없습니다. (b) 스테이지 간 융합 유닛 사용 (3회 융합): 각 스테이지 내 병렬 스트림 간 융합이 없습니다. (c) 스테이지 간 및 스테이지 내 융합 유닛 사용 (총 8회 융합): 이것이 우리가 제안하는 방법입니다. 모든 네트워크는 처음부터 훈련됩니다. COCO 인간 자세 추정과 Cityscapes 의미론적 분할(검증)의 결과는 표 12에 제시되어 있으며, 다중 해상도 융합 유닛이 도움이 되며 더 많은 융합이 더 나은 성능으로 이어짐을 보여줍니다.
우리는 융합 설계의 다른 가능한 선택지도 연구합니다:
(i) 스트라이드 컨볼루션을 선형 다운샘플링으로 대체하는 방법,
(ii) 합 연산을 곱 연산으로 대체하는 방법입니다.
첫 번째 경우, COCO 자세 추정 AP 점수와 Cityscapes 분할 mIoU 점수는 72.6과 74.2로 감소합니다. 그 이유는 다운샘플링이 표현 맵의 볼륨 크기(너비 × 높이 × 채널 수)를 줄이며, 스트라이드 컨볼루션이 선형 다운샘플링보다 더 나은 볼륨 크기 축소를 학습하기 때문입니다.
두 번째 경우 결과는 훨씬 더 나빠지며 각각 54.7과 66.0을 기록합니다. 그 원인은 곱 연산이 훈련의 어려움을 증가시키기 때문일 수 있으며, 이는 [145]에서 언급되었습니다.
Resolution maintenance.
우리는 HRNet의 변형 모델의 성능을 연구합니다. 이 모델은 네 개의 고해상도에서 저해상도까지의 스트림이 처음에 추가되며, 네 스트림의 깊이는 동일하고 융합 스키마는 기존 모델과 같습니다. HRNet과 변형 모델(유사한 파라미터 수와 GFLOPs)은 처음부터 훈련됩니다.
COCO val에서 변형 모델의 인간 자세 추정 성능(AP)은 72.5로, HRNetV1-W32의 73.4보다 낮습니다. Cityscapes val에서 변형 모델의 세분화 성능(mIoU)은 75.7로, HRNetV2-W48의 76.4보다 낮습니다. 그 이유는 초기 단계에서 저해상도 스트림을 통해 추출된 저수준 특징이 덜 유용하기 때문이라고 생각됩니다. 추가적으로, 단순히 고해상도 스트림만을 사용하고 저해상도 병렬 스트림이 없는 또 다른 변형 모델은 유사한 파라미터 수와 GFLOPs를 가지지만 COCO와 Cityscapes에서 훨씬 낮은 성능을 보입니다.
V1 vs. V2.
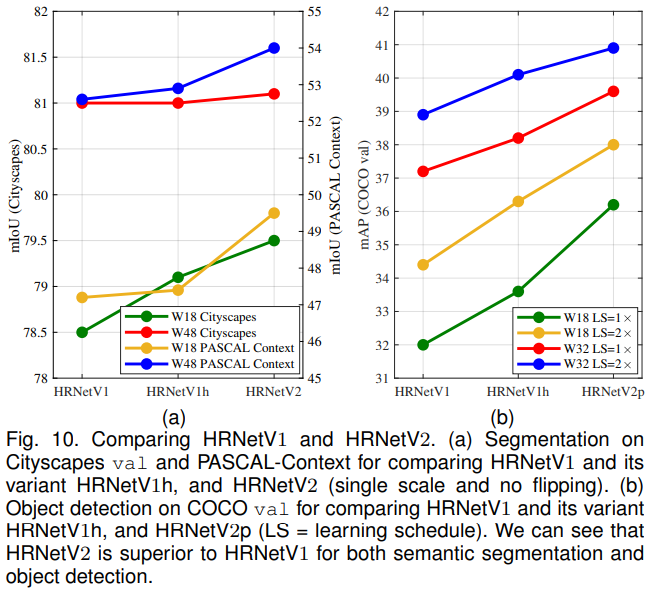
우리는 HRNetV2 및 HRNetV2p를 HRNetV1과 자세 추정, 의미론적 분할 및 COCO 객체 검출에서 비교합니다. 인간 자세 추정 성능은 유사합니다. 예를 들어, HRNetV2-W32(Imagenet 사전 학습 없이)는 AP 점수 73.6을 달성하며, 이는 HRNetV1-W32의 73.4보다 약간 높습니다.
Figure 10 (a)와 Figure 10 (b)에 나타난 세분화 및 객체 검출 결과는 HRNetV2가 HRNetV1보다 크게 우수함을 보여줍니다. 하지만 Cityscapes에서 큰 모델($1×$)의 경우 성능 향상은 미미합니다. 우리는 또한 HRNetV1h라는 변형 모델을 테스트했습니다. 이 모델은 $1×1$ 컨볼루션을 추가하여 출력 고해상도 표현의 차원을 HRNetV2와 일치시키도록 설계되었습니다. Figure 10 (a)와 Figure 10 (b)의 결과는 이 변형 모델이 HRNetV1에 약간의 개선을 달성함을 보여주며, HRNetV2에서 저해상도 병렬 컨볼루션으로부터의 표현 결합이 성능 향상에 필수적임을 시사합니다.
8 CONCLUSIONS
본 논문에서는 시각 인식 문제를 위한 고해상도 네트워크를 제시합니다. 기존 저해상도 분류 네트워크 및 고해상도 표현 학습 네트워크와의 세 가지 근본적인 차이점은 다음과 같습니다: (i) 고해상도와 저해상도 컨볼루션을 직렬이 아닌 병렬로 연결합니다. (ii) 저해상도에서 고해상도를 복원하는 대신 전체 과정에서 고해상도를 유지합니다. (iii) 다중 해상도 표현을 반복적으로 융합하여 위치 민감도가 높은 풍부한 고해상도 표현을 생성합니다.
시각 인식 문제 전반에 걸친 우수한 결과는 제안된 HRNet이 컴퓨터 비전 문제를 위한 강력한 백본임을 시사합니다. 우리의 연구는 또한 저해상도 네트워크(예: ResNet 또는 VGGNet)로부터 학습된 표현을 확장, 개선, 수정하는 대신 특정 비전 문제를 위해 네트워크 아키텍처를 직접 설계하는 연구를 장려합니다.
Discussions.
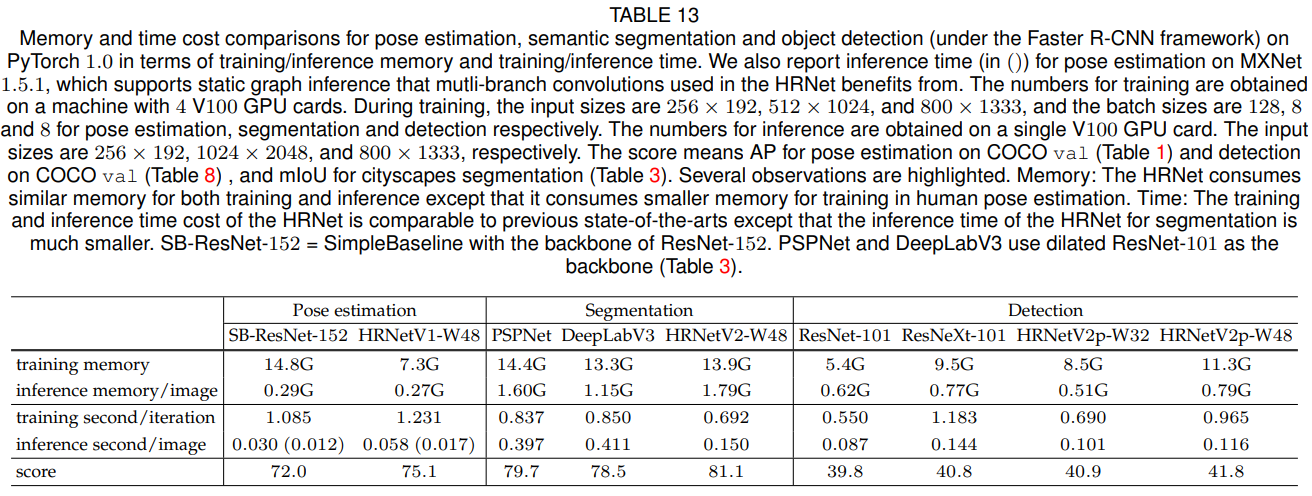
HRNet의 해상도가 높을수록 메모리 비용이 더 커진다는 오해가 있을 수 있습니다. 그러나 HRNet의 메모리 비용은 인간 자세 추정, 의미론적 세분화 및 객체 검출의 세 가지 애플리케이션 모두에서 기존 최신 기법들과 비교할 때 유사하며, 객체 검출의 경우 훈련 메모리 비용만 약간 더 큽니다.
또한, 우리는 PyTorch 1.0 플랫폼에서 실행 시간 비용을 요약합니다. HRNet의 학습 및 추론 시간 비용은 기존 최신 기법들과 비교하여 유사하지만 (1) HRNet의 세분화를 위한 추론 시간이 훨씬 작으며, (2) 자세 추정을 위한 HRNet의 학습 시간 비용은 약간 더 큽니다. 그러나 정적 그래프 추론을 지원하는 MXNet 1.5.1 플랫폼에서는 비용이 SimpleBaseline과 유사합니다. 우리는 의미론적 세분화의 경우 PSPNet 및 DeepLabv3보다 추론 비용이 훨씬 작다는 점을 강조하고 싶습니다. 표 13은 메모리 및 시간 비용 비교를 요약합니다.
Future and followup works.
우리는 HRNet을 의미론적 세분화 및 인스턴스 세분화를 위한 다른 기술들과 결합하는 연구를 수행할 것입니다. 현재, 우리는 HRNet과 객체-맥락적 표현(OCR) 스키마 [170], 객체 맥락의 변형 [59], [171]을 결합한 결과(mIoU)를 표 3, 4, 5, 6에서 보여주고 있습니다. 우리는 표현의 해상도를 더 높이는 연구를 진행할 계획이며, 예를 들어 $\frac{1}{2}$ 또는 전체 해상도까지 확장할 것입니다.
HRNet의 적용은 우리가 수행한 연구에 국한되지 않으며, 얼굴 랜드마크 검출, 초해상도, 광학 흐름 추정, 깊이 추정 등과 같은 다른 위치 민감 시각 애플리케이션에도 적합합니다. 이미 후속 연구들이 진행되고 있으며, 예를 들어 이미지 스타일화 [83], 인페인팅 [50], 이미지 향상 [62], 이미지 디헤이징 [1], 시간적 자세 추정 [6], 드론 객체 검출 [190] 등이 있습니다.
[26]에 따르면, 약간 수정된 HRNet이 ASPP와 결합되어 단일 모델 케이스에서 Mapillary 파노라마 세분화에서 최고의 성능을 달성했습니다. ICCV 2019에서 열린 COCO + Mapillary Joint Recognition Challenge 워크숍에서 COCO DensePose 챌린지의 우승자와 거의 모든 COCO 키포인트 검출 챌린지 참가자들이 HRNet을 채택했습니다. OpenImage 인스턴스 세분화 챌린지의 우승자(ICCV 2019) 또한 HRNet을 사용했습니다.
Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, Bin Xiao Deep High-Resolution Representation Learning for Visual Recognition

댓글남기기