

개요
Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification Box 논문의 얕은 리뷰.
본 논문은 2018 ICME에서 발표되었으며 MOTDT라 불리는 방법론을 제안한다. 해당 방법론은 탐지(Detection)와 추적(Track)의 결과에서 후보를 수집하고 신뢰할 수 없는 탐지를 처리하기 위한 방법을 제안한다.
탐지 결과는 장기적으로 추적이 표류하는 것을 방지하고, 예측된 추적은 가림(occlusion) 으로 인한 노이즈가 포함된 탐지를 처리하도록 서로 상호작용하는 방법을 제안한다.
방법론
- 기존 접근 방식은 탐지 기반 추적(tracking-by-detection) 방식을 확장하여 탐지 결과와 추적 결과 모두에서 후보를 수집한다.
- 제안하는 프레임워크는 두 가지 순차적 작업을 진행한다.
- 우선 후보군 선택(Candidate Selection) 작업인데, 통합 점수 함수를 통해 모든 후보들을 평가하며, 객체 분류기와 tracklet에 대한 신뢰도를 결합한 점수로 구성된다.
- 추정된 결과에 대해 NMS가 수행된다.
- 데이터 연결(Data Association) 작업은 외형 표현과 공간적 정보를 통해 중복을 제거하고, 기존 추적 결과와 계층적으로 연결한다.
- 입력 이미지에 대해 계산을 공유하는 R-FCN(Region-based Fully Convolution Network)를 사용하여, 인코더-디코더 네트워크를 활용한다.
- 인코더를 통해 백본에 대해 피드포워드가 수행되고, 다시 디코더를 통해 업샘플링이 수행된다.
- 배경은 RoI의 Negative 데이터, 실제 객체 주변의 바운딩 박스 RoI를 Positive 데이터로 활용하며, 객체의 특정 위치에 반응하도록 분류 task를 학습한다.
- 이를 position-sensitive-RoI 풀링 레이어를 사용한다고 하며, $k^2$개의 스코어 맵으로 객체가 있는지에 대한 분류 확률을 추정해 낸다고 보면 된다.
- 간단하게는 객체가 있다/없다에 대한 네트워크 모델을 사용하는 셈.
- 칼만 필터를 통한 추적(track)은 잠시 동안 가려진(occlusion) 상황이나 이로인해 탐지가 잘 안되는 상황에서 유용하나 장기간 미갱신(놓친) 상황에는 부적절하다.
- Tracklet은 연속된 프레임에서 후보들을 시간적으로 연결한 것이며, 하나의 Track에는 여러 Tracklet으로 분할될 수 있다. 이 때의 tracklet의 신뢰도는 식(2)를 참조한다.
- 그래서 위에서 얻은 객체 분류 확률과 tracklet 신뢰도를 통해 통합 점수를 계산할 수 있다. 수식은 식(3)을 참조한다. 이를 기반으로 NMS를 적용한다.
- 이때 사용되는 파라미터는 NMS의 IoU 임계값과, 통합 점수의 스코어 임계값이다.
- 위의 과정을 통해 Candidate Selection 과정을 진행했다면, 이어서 Data Association 과정을 진행한다.
- 데이터 연결 과정에서는 앞선 과정을 통해 추출 된 후보들 간의 유사도를 통해 연결하는데, 객체의 외형 정보 벡터를 추출하는 네트워크를 사용한다.
- 이 때, 네트워크는 GoogLeNet 기반의 백본을 사용하며, 외형 특징을 반영하는 임베딩을 도출해준다.
- 3가지로 구성된 데이터로 앵커, 양성, 음성의 트리플렛 기반으로 학습된다.
- 외형 정보를 사용하는 딥-뉴럴넷은 DeepSORT를 읽었다면 익숙할 것이라 생각된다.
- 이런 일련의 과정을 거쳐서 전체적인 일련의 계층적 데이터 연결 과정을 정리하면 다음과 같다.
- 통합 점수 함수를 통해 탐지를 통해 나온 후보들에 대해 거리 임계값을 적용하여 필터링하고, 외형 표현(appearance representations)을 통해 데이터를 연결한다.
- 임계값을 넘지 못해 남아있는 후보군에 대해 IoU 기반 매칭을 수행하여 미연결된 추적들과 연결한다.
- 탐지와 연결 된 track에만 외형 표현을 갱신하여 저장한다. 그리고 새로운 탐지들에 대해서 새로운 추적(track)을 초기화하고 다음 프레임으로 넘어간다.
실험
- MOT16 데이터 셋을 사용하였다.
- SqueezeNet을 R-FCN의 백본으로 사용하여 빠른 연산으로 실시간 성능을 달성
- 분류확률+Tracklet 신뢰도와 Re-ID 특징을 기반으로한 접근 방식에서 모든 지표에 대해 우수한 성능을 보임
- 이는 기존의 수작업 기반 특징을 활용한 방법보다 높은 성능을 보였다.
- 제안하는 방법이 기존 패치를 기반으로 연산하는 것보다 전체 이미지를 대상으로 하여 해당 특징 및 연산을 공유할 수 있으므로 높은 시간 효율을 보인다.
결론
본 논문은 온라인 다중 인물 추적을 달성하기 위해 탐지 결과와 트랙의 예측을 모두 활용하는 방법론을 제시하고, 이를 통합하여 하나의 점수화 하는 방법론을 제안한다. 또한 외형 정보를 사용하여 앞서 통합 점수로 필터링 된 후보군과 매칭하는 방식으로 추적 성능을 끌어올렸다. 단일 GTX 1080Ti GPU로도 실시간 성능을 달성했다는 의의를 가지며, 분류와 외형 추출과정 등을 더 통합해 효율성을 극대화하는 방향으로 연구가 확장될 수 있음을 보인다.
번역
Abstract
온라인 다중 객체 추적은 시간에 민감한 비디오 분석 응용 프로그램에서의 근본적인 문제이다. 일반적으로 사용되는 탐지 기반 추적(tracking-by-detection) 프레임워크에서 주요한 과제는 신뢰할 수 없는 탐지 결과들을 기존의 추적과 어떻게 연결시킬 것인가이다. 이 논문에서는 탐지와 추적 양쪽 모두의 결과에서 후보를 수집함으로써 신뢰할 수 없는 탐지를 처리할 것을 제안한다. 중복된 후보를 생성하는 배경 아이디어는 탐지와 추적 결과가 서로 다른 상황에서 상호 보완이 가능하다는 것이다. 높은 신뢰도를 가진 탐지 결과는 장기적으로 추적이 표류하는 것을 방지하며, 추적 예측은 가림(occlusion)으로 인해 발생한 노이즈가 포함된 탐지를 처리할 수 있다. 실시간으로 방대한 수의 후보군 중에서 최적의 선택을 적용하기 위해, 전체 이미지에서 대부분의 계산을 공유하는 완전 합성곱 신경망(fully convolutional neural network, FCN) 기반의 새로운 점수화(scoring) 함수를 제안한다. 또한, 추적기의 식별 능력을 향상시키기 위해 대규모의 인물 재식별(person re-identification) 데이터셋으로 훈련된 심층적으로 학습된 외형 표현(appearance representation)을 채택하였다. 폭넓은 실험 결과, 제안한 추적기가 널리 사용되는 인물 추적 벤치마크에서 실시간으로 최신(state-of-the-art)의 성능을 달성했음을 보여준다.
Index Terms - 다중 객체 추적, 합성곱 신경망, 인물 재식별
1. INTRODUCTION
복잡한 장면에서 여러 객체를 추적하는 것은 비주얼 감시, 스포츠 분석, 자율 주행 등 많은 비디오 분석 및 멀티미디어 응용 분야에서의 어려운 문제이다. 다중 객체 추적의 목적은 특정 카테고리에 속한 객체들의 궤적을 추정하는 것이다. 본 논문에서는 인물 재식별(person re-identification)을 활용하여 사람 추적 문제를 다룬다.
지난 10년간 객체 탐지의 발전은 다중 객체 추적에 큰 도움을 주었다. 일반적으로 사용되는 탐지 기반 추적(tracking-by-detection) 방법은 각 프레임에 탐지기를 적용한 후, 여러 프레임에 걸쳐 탐지 결과를 연결하여 객체의 궤적을 생성한다. 이 프레임워크에서는 카테고리 내부의 가림(intra-category occlusion)과 신뢰할 수 없는 탐지가 모두 큰 도전 과제이다[1, 2]. 카테고리 내부의 가림과 객체들의 유사한 외형은 데이터 연결(data association) 과정에서 모호성을 야기할 수 있다. 움직임(motion), 형태(shape), 객체의 외형(appearance)과 같은 여러 단서들을 결합하여 이 문제를 완화시킬 수 있다[3, 4]. 반면, 탐지 결과는 항상 신뢰할 수 있는 것은 아니다. 붐비는 장면에서의 자세(pose) 변화나 가림은 종종 오탐지(false positives), 탐지 누락(missing detection), 부정확한 경계(non-accurate bounding)와 같은 탐지 실패를 유발한다. 일부 연구에서는 배치(batch) 방식으로 신뢰할 수 없는 탐지를 다루는 방법을 제안하였다[2, 5, 6]. 이 방법들은 이후의 프레임으로부터의 정보를 도입하여 탐지 잡음을 해결한다. 전체 비디오 프레임이나 시간적 윈도우에서의 탐지 결과를 사용하여 전역 최적화(global optimization) 문제를 해결함으로써 궤적을 연결한다. 그러나 배치 방식의 추적은 비인과적(non-causal)이기 때문에 시간에 민감한 응용 분야에는 적합하지 않다. 이와 대조적으로, 본 연구는 현재 및 과거 프레임만을 이용하는 온라인 방식의 다중 인물 추적 문제에 중점을 둔다.
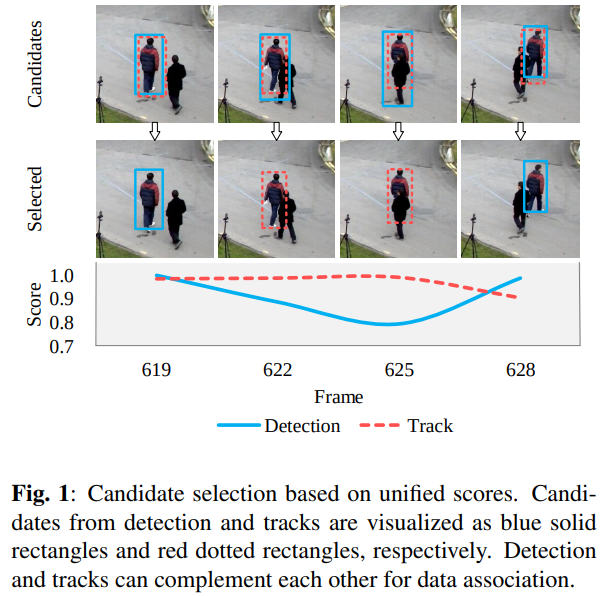
온라인 환경에서 신뢰할 수 없는 탐지를 처리하기 위해, 본 논문의 추적 프레임워크는 각 프레임에서 탐지 결과와 기존 추적 결과 양쪽에서 후보들을 최적으로 선택한다(그림 1 참조). 기존의 대부분 탐지 기반 추적 방법에서는 데이터 연결 시 기존 추적과 연결할 후보가 탐지 결과로만 구성된다. Yan 등[4]은 추적기와 객체 탐지기를 두 개의 독립된 요소로 취급하여 각자의 결과를 후보로 유지할 것을 제안하였다. 이들은 색상 히스토그램, 광학 흐름(optical flow), 움직임 특징(motion features)과 같은 수작업 특징을 사용하여 후보를 선택하였다. 중복된 후보를 생성하는 이유는 탐지와 추적 결과가 서로 다른 상황에서 상호 보완될 수 있기 때문이다. 즉, 한편으로는 추적기의 신뢰성 높은 예측이 탐지 누락이나 부정확한 경계의 경우 단기 연결에 사용될 수 있으며, 다른 한편으로는 신뢰할 수 있는 탐지 결과가 장기적으로 추적 대상이 배경으로 표류하는 것을 방지하는 데 필수적이다. 그러나 탐지 결과와 추적 결과를 통합하여 점수화하는 방법은 여전히 해결되지 않은 문제이다. 최근 심층 신경망, 특히 합성곱 신경망(CNN)은 컴퓨터 비전과 멀티미디어 분야에서 큰 발전을 이루었다. 본 논문에서는 심층 신경망을 최대한 활용하여 신뢰할 수 없는 탐지와 카테고리 내부의 가림 문제를 해결한다. 우리의 기여는 세 가지로 정리할 수 있다. 첫째, 탐지 결과와 추적 결과 모두를 후보로 조합하고 심층 신경망 기반으로 최적의 후보를 선택함으로써 온라인 추적에서 신뢰할 수 없는 탐지를 처리한다. 둘째, 공간적 정보와 심층 학습된 인물 재식별(ReID) 특징을 활용하는 계층적 데이터 연결(hierarchical data association) 전략을 제안한다. 셋째, 널리 사용되는 인물 추적 벤치마크에서 본 연구가 제안한 추적기의 실시간 및 최첨단 성능을 입증한다.
2. RELATED WORK
탐지 기반 추적(tracking-by-detection)은 다중 객체 추적에서 가장 널리 사용되는 전략이 되어가고 있다. Bae 등[1]은 탐지의 신뢰도(confidence)에 따라 서로 다른 방식으로 트랙릿(tracklets)을 탐지 결과와 연결하였다. Sanchez-Matilla 등[7]은 다중 탐지기를 활용하여 추적 성능을 개선하였다. 이들은 이른바 과탐지(overdetection) 과정에서 여러 탐지기의 결과를 수집하였다. 다중 탐지기의 결과를 결합하면 추적 성능이 향상될 수 있지만, 실시간 응용 분야에 효율적이지는 않다. 반면 본 연구의 프레임워크는 단 하나의 탐지기만 필요로 하며 기존 추적 결과에서 후보를 생성한다. Chu 등[8]은 온라인 다중 객체 추적을 위해 이진 분류기(binary classifier)와 단일 객체 추적기를 사용하였다. 이들은 분류를 위한 특징 맵을 공유하였으나 여전히 계산 복잡성이 높았다.
‘배치(batch) 방식은 추적을 전역 최적화(global optimization) 문제로 공식화한다[4, 5, 6, 9]. 이 방법들은 이후 프레임의 정보를 활용하여 잡음이 많은 탐지를 처리하고 데이터 연결의 모호성을 줄인다. Liu 등[10]은 이후 프레임 정보를 이용한 역방향 트랙릿(backward tracklets)을 생성하여, 더 안정적인 유사도 측정을 얻는 “되감기 추적(rewind to track)” 전략을 제안하였다. 인물 재식별 또한 전역 최적화를 위해 [6, 9, 11]에서 다뤄진 바 있다. 본 논문의 프레임워크는 온라인 환경에서 심층적으로 학습된 ReID 특징을 활용하여 카테고리 내부의 가림 문제를 처리할 때 식별 능력을 개선한다.
3. PROPOSED METHOD
3.1. Framework Overview
본 연구에서는 기존의 탐지 기반 추적(tracking-by-detection)을 확장하여 탐지 결과와 추적 결과 모두에서 후보들을 수집한다. 제안하는 프레임워크는 후보 선택(candidate selection)과 데이터 연결(data association)의 두 가지 순차적 작업으로 구성된다. 먼저 통합 점수 함수를 사용하여 모든 후보들을 평가한다. 점수 함수는 판별적으로 학습된 객체 분류기와 잘 설계된 트랙릿(tracklet) 신뢰도를 융합하여 구성되며, 이는 3.2절과 3.3절에서 설명한다. 이후 추정된 점수를 바탕으로 비최대 억제(NMS)를 수행한다. 중복 없는 후보군을 얻은 후, 외형 표현(appearance representations)과 공간적 정보를 사용하여 선택된 후보들을 기존 추적 결과와 계층적으로 연결한다. 외형 표현은 3.4절에서 설명하는 인물 재식별(ReID) 특징을 통해 심층적으로 학습된다. 계층적 데이터 연결에 관한 세부 내용은 3.5절에서 다룬다.
3.2. Real-Time Object Classification
탐지와 추적의 결과를 결합하면 매우 많은 수의 후보들이 생성된다. 본 연구의 분류기는 영역 기반 완전 합성곱 신경망(R-FCN)[12]을 사용하여 전체 이미지에 대한 계산을 대부분 공유한다. 따라서 중복되는 후보 영역에서 잘라낸 이미지 패치(patch)를 사용하는 분류 방식보다 훨씬 효율적이다. 이 두 가지 방식의 시간 소모 비교는 그림 3에서 확인할 수 있다.
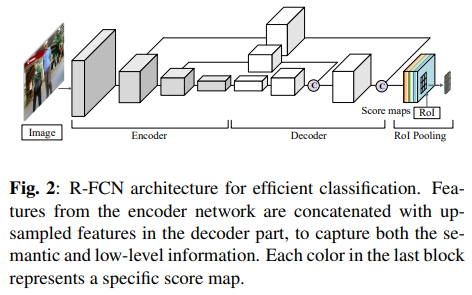
제안한 효율적인 분류기는 그림 2에서 볼 수 있다. 입력된 이미지 프레임에 대해 전체 이미지의 점수 맵(score maps)은 인코더-디코더 구조를 가진 완전 합성곱 신경망으로 예측된다. 인코더 부분은 실시간 성능을 위한 경량의 합성곱 기반 백본(backbone)이며, 이후 분류를 위한 공간적 해상도를 높이기 위해 디코더 부분에서 업샘플링(up-sampling)을 수행한다. 분류할 각 후보는 관심 영역(RoI, Region of Interest)으로 정의되며, $\mathbf{x}=(x_0, y_0, w, h)$ 로 나타낸다. 여기서 $(x_0, y_0)$는 왼쪽 상단 좌표이며, $w, h$는 영역의 너비와 높이를 나타낸다. 계산 효율성을 위해 각 RoI의 분류 확률은 공유된 점수 맵으로부터 직접 투표(voting)되도록 설계된다. 단순한 방법은 모든 픽셀의 전경(foreground) 확률을 계산한 뒤, RoI 내부 픽셀의 평균 확률을 구하는 것이다. 하지만 이 단순한 전략은 객체의 공간 정보를 잃게 된다. 예를 들어 RoI가 객체의 일부만 덮고 있더라도 높은 신뢰 점수가 나올 수 있다.
점수 맵에 공간 정보를 명시적으로 부호화하기 위해, 우리는 position-sensitive RoI 풀링 레이어 [12]를 사용하여, $k^2$ 개의 position-sensitive 점수 맵 $\mathbf{z}$ 로부터 분류 확률을 추정한다. 각 셀(bin)은 $\lfloor\frac{w}{k}\times\frac{h}{k}\rfloor$ 크기를 가지며, 객체의 특정 공간적 위치를 나타낸다. 우리는 $k^2$ 의 점수 맵에서 $k×k$ 개의 셀에 대한 응답값을 추출한다. 각 점수 맵은 오직 한 개의 셀에만 대응한다. RoI $\mathbf{x}$ 에 대한 최종 분류 확률은 다음과 같이 공식화된다:
여기서 $\sigma(x)=\frac{1}{1+e^{-x}}$ 는 시그모이드 함수이며, $z^i$ 는 i번째 점수 맵을 의미한다.
훈련 과정에서는, 정답 바운딩 박스(ground truth) 주변에서 RoI를 임의로 샘플링하여 양성 예제로 사용하고, 동일한 수의 RoI를 배경에서 가져와 음성 예제로 사용한다. 네트워크를 end-to-end로 학습함으로써, 디코더의 최상단(출력부)인 $k^2$ 점수 맵은 객체의 특정 공간 위치에 반응하도록 학습된다. 예를 들어 $k=3$ 인 경우, 9개의 점수 맵이 각각 객체의 왼쪽 위, 위쪽 중앙, 오른쪽 위, …, 오른쪽 아래 영역에 대응하여 반응한다. 이처럼, RoI 풀링 레이어는 공간적 위치에 민감하므로, 추가 학습 파라미터 없이도 객체 분류에서 높은 판별 능력을 갖춘다. 또한 본 논문에서 제안된 신경망은 후보 분류만을 위해 학습되며, 바운딩 박스 회귀(regression) 목적의 학습은 수행하지 않는다.
3.3. Tracklet Confidence and Scoring Function
새로운 프레임이 주어지면, 각 기존 트랙의 새로운 위치를 칼만 필터(Kalman filter)를 통해 추정한다. 이러한 예측은 객체의 다양한 시각적 특성과 복잡한 장면에서의 가림(occlusion)으로 인해 발생하는 탐지 실패를 처리하기 위해 사용되지만, 장기 추적에는 적합하지 않다. 오랜 기간 탐지로 갱신되지 않을 경우 칼만 필터의 정확도는 저하될 수 있다. 트랙릿(tracklet) 신뢰도는 시간 정보를 사용해 필터의 정확도를 평가하도록 설계되었다.
트랙릿은 연속된 프레임에서 얻은 후보들을 시간적으로 연결해 생성된다. 트랙은 생애 주기에 여러 번 중단되었다가 다시 이어질 수 있으므로, 하나의 트랙을 여러 트랙릿으로 나눌 수 있다. 트랙이 분실(lost) 상태에서 복원될 때마다 칼만 필터가 재초기화되므로, 트랙 신뢰도를 결정할 때는 마지막 트랙릿 정보만 활용한다. 여기서 $L_{det}$ 은 해당 트랙릿과 연결된 탐지 결과 수이며, $L_{trk}$ 은 마지막 탐지 이후에 발생한 트랙 예측 횟수를 나타낸다. 트랙릿 신뢰도는 다음과 같이 정의된다.
여기서 $\mathbb{1}(⋅)$ 는 입력이 참이면 1, 그렇지 않으면 0을 반환하는 지시자 함수이다. 우리는 트랙을 후보로 사용하기 전에, 관측된 탐지 결과를 이용해 합리적인 운동 모델을 구성하기 위해 $L_{det}≥2$ 를 만족하도록 설정했다.
후보 $\mathbf{x}$ 에 대한 통합 점수 함수는 분류 확률과 트랙릿 신뢰도를 융합하여 다음과 같이 정의된다.
여기서 $C_{det}$ 는 탐지 결과에서 온 후보, $C_{trk}$ 는 트랙에서 온 후보를 각각 의미하고, $s_{trk}∈[0,1]$ 는 불확실한 트랙에서 온 후보에 패널티를 부여하기 위한 값이다. 데이터 연결에 사용될 최종 후보들은 이 통합 점수를 바탕으로 비최대 억제(non-maximal suppression)를 거쳐 선별된다. 우리는 최대 IoU(교집합 대비 합집합)를 $τ_{nms}$ 로 정의하며, 최소 점수에 대한 임계값 $τ_s$ 도 함께 설정한다.
3.4. Appearance Representation with ReID Features
후보들 간 유사도 함수는 데이터 연결에서 핵심적인 요소이다. 본 논문에서는 데이터 기반 접근법으로 심층 학습된 객체 외형이, 유사도 측정에서 기존의 수작업 특징보다 더 우수하다고 주장한다. 객체 외형과 유사도 함수를 학습하기 위해, 우리는 심층 신경망을 통해 RGB 이미지에서 특징 벡터를 추출하고, 추출된 특징들 간의 거리를 활용하여 유사도를 정의한다.
우리는 [13]에서 제안된 네트워크 구조를 사용하고, 여러 대규모 인물 재식별(person re-identification) 데이터셋을 결합하여 네트워크를 학습한다. 네트워크 $H_{reid}$ 는 GoogLeNet [14]의 합성곱 백본 위에, 부분 정렬(part-aligned)된 K개의 완전연결(FC) 레이어 분기를 추가한 구조이다. 자세한 구조는 [13]을 참고한다. 사람의 RGB 이미지 $\mathbf{I}$ 가 주어졌을 때, 외형 표현은 $f=H_{reid}$(\mathbf{I})$ 로 정의된다. 특징 벡터 간 유클리드 거리를 사용하여 두 이미지 $\mathbf{I}_i$ 와 $\mathbf{I}_j$ 사이의 거리 $d_{ij}$ 를 측정한다. 학습 과정에서, 훈련용 데이터셋의 개별 정체성(identity) 이미지는 $T=\lbrace⟨\mathbf{I}_i,\mathbf{I}_j,\mathbf{I}_k⟩\rbrace$ 형태의 트리플릿 집합으로 구성된다. 여기서 $⟨\mathbf{I}_i,\mathbf{I}_j⟩$ 는 같은 사람의 양성 쌍, $⟨\mathbf{I}_i,\mathbf{I}_k⟩$ 는 다른 사람의 음성 쌍이다. $N$ 개의 트리플릿이 있을 때, 최소화해야 할 손실 함수는
와 같이 정의된다. 여기서 $m>0$ 는 사전에 정의된 마진이다. 학습된 특징 표현의 판별 능력을 높이기 위해, $d_{ik}−d_{ij}>m$ 과 같이 쉽게 구분되는 트리플릿은 무시한다.
3.5. Hierarchical Data Association
복잡한 장면에서 발생하는 탐지 누락을 처리하기 위해, 우리는 트랙 예측을 활용한다. 그러나 카테고리 내부의 가림으로 인해 이 예측이 다른 객체와 겹칠 가능성이 있다. 불필요한 객체나 배경 정보가 외형 표현에 포함되지 않도록, 우리는 서로 다른 특징을 사용하여 트랙과 여러 후보들을 계층적으로 연결(hierarchically associate)한다.
구체적으로, 먼저 탐지에서 온 후보들에 대해 최대 거리 임계값 $τ_d$ 를 적용하고, 외형 표현을 이용한 데이터 연결을 수행한다. 이후 남은 후보들은 후보와 트랙 간의 IoU(교집합/합집합)을 기준으로, 임계값 $τ_{iou}$ 를 사용하여 아직 연결되지 않은 트랙과 매칭한다. 트랙은 탐지와 연결될 때에만 외형 표현을 업데이트하는데, 연결된 탐지 결과로부터 ReID 특징을 저장함으로써 갱신 과정을 수행한다. 마지막으로, 남은 탐지 결과들을 바탕으로 새로운 트랙을 초기화한다. 제안하는 온라인 추적 알고리즘의 세부 내용은 알고리즘 1에 제시되어 있다. 계층적 데이터 연결을 통해, 각 프레임마다 탐지된 후보에 대해서만 ReID 특징을 한 번 추출하면 되므로, 이전 섹션에서 소개한 효율적인 점수 함수와 트랙릿 신뢰도와 결합하여 본 프레임워크는 실시간으로 동작할 수 있다.

4. EXPERIMENTS
4.1. Experiment Setup
제안하는 온라인 추적 방식의 성능을 평가하기 위해, 우리는 다중 인물 추적 분야에서 널리 사용되는 MOT16 데이터셋 [15]을 대상으로 광범위한 실험을 수행했다. 이 데이터셋은 훈련 세트와 테스트 세트로 구성되며, 각각 제약 없는 환경에서 촬영된 7개의 까다로운 비디오 시퀀스를 포함한다. 우리는 프레임워크 내 각 구성 요소의 기여도를 분석하기 위해, 훈련 세트에서 5개 비디오 시퀀스를 골라 검증 세트를 구성하였다. 이후, 테스트 세트에 대한 추적 결과를 공식 벤치마크 사이트에 제출하여, 최첨단 기법들과 성능을 비교하였다.
Implementation details.
우리는 실시간 성능을 위해 R-FCN의 백본(backbone)으로 SqueezeNet [16]을 사용한다. SqueezeNet과 디코더 부분으로 이루어진 완전 합성곱 네트워크는 GTX1080Ti GPU에서 1152×640 크기의 입력 이미지를 처리할 때, 점수 맵을 추정하는 데 약 8ms만 소요된다. 위치 민감형 점수 맵(position-sensitive score maps)을 위해 k=7로 설정하고, RMSprop 옵티마이저를 사용하여 학습률 1e-4, 배치 크기 32로 총 2만 번 반복하여 네트워크를 학습한다. 인물 분류에 사용할 학습 데이터는 MS COCO [17]와 나머지 두 개의 훈련 비디오 시퀀스에서 수집하였다. 후보 선택을 위해 $τ_{nms}=0.3$, $τ_s=0.4$로 설정하였다. ReID 네트워크는 Market1501 [18], CUHK01, CUHK03 [19] 등 세 가지 대규모 인물 재식별(person re-identification) 데이터셋을 결합하여 학습함으로써 추적에 필요한 일반화 능력을 높였다. 계층적 데이터 연결을 위해서는 $τ_d=0.4$, $τ_{iou}=0.3$ 을 사용하며, 이후의 모든 실험은 동일한 하이퍼파라미터를 기반으로 진행된다.
Evaluation metrics.
바운딩 박스 정확도와 식별 정확도를 동시에 측정하기 위해, 본 연구에서는 벤치마크에서 사용하는 여러 지표를 채택하여 제안된 방법을 평가한다. 이는 다중 객체 추적 정확도(MOTA) [20], 프레임당 오탐(false alarm) 수(FAF), 주로 추적된 대상 수(MT, 80% 이상 추적 성공), 주로 놓친 대상 수(ML, 20% 미만 추적 성공) [21], 오검출(FP), 미검출(FN), ID 스위치(IDS), 식별 재현율(IDR), 식별 F1 점수(IDF1) [22], 그리고 처리 속도(FPS)를 포함한다.
4.2. Analysis on Validation Set
Contribution of each component.
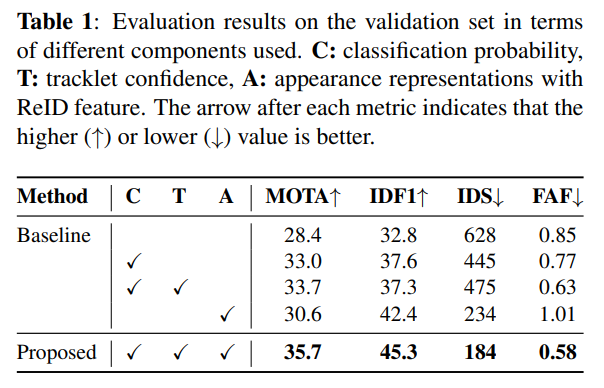
각 구성 요소의 기여도: 제안 기법의 효과를 입증하기 위해, 표 1에서 프레임워크 내 여러 구성 요소들의 기여도를 분석하였다. 베이스라인 방법은 칼만 필터를 사용해 각 트랙의 위치를 예측한 뒤, IoU를 기준으로 탐지 결과와 트랙을 연결한다. 탐지와 트랙 양쪽에서 후보를 고르는 데 분류 확률을 활용했을 때, 베이스라인 대비 MOTA가 4.6% 향상된다. 3.3절에서 설명한 대로, 불확실한 트랙에서 온 후보를 패널티 처리하기 위해 트랙릿 신뢰도와 분류 확률을 결합하면 MOTA가 추가로 개선되고 오검출도 줄어든다. 한편, ReID 특징 기반의 외형 표현을 도입함으로써, 식별 성능(IDF1, IDS 기준)에서 크게 개선된 결과를 얻을 수 있었다. 통합 점수 함수와 ReID 특징을 결합한 우리의 방법은 모든 지표에서 가장 우수한 성능을 보였다.
Comparison with different appearance features.
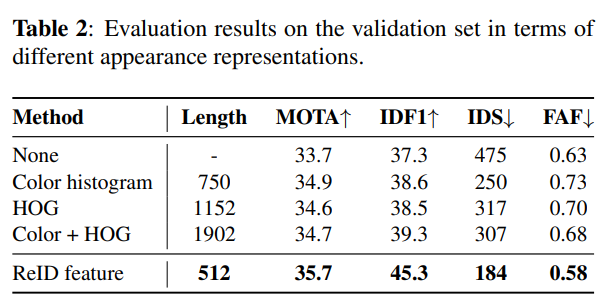
표 2에서 보이듯이, 본 논문의 3.4절에서 제시한 데이터 기반 접근법으로 학습된 외형 표현을 대표적인 수작업 특징 두 가지(색상 히스토그램, HOG)와 비교하였다. 외형 기술자(appearance descriptor)로 널리 쓰이는 고정 파트 모델 [23]에 따라, 사람 이미지를 가로 방향으로 6개 스트립(stripe)으로 나누어 색상 히스토그램을 계산한다. 각 스트립의 색상 히스토그램은 HSV 색공간에서 125개 구간(bin)으로 구성된다. 색상 히스토그램과 HOG 특징 모두 L2 정규화를 적용하고, 코사인 유사도(cosine similarity) 함수를 이용해 유사도를 정의했다. 표에서 확인할 수 있듯이, 제안한 외형 표현은 다른 방법들보다 짧은 길이의 특징 벡터임에도 불구하고, IDF1과 IDS 지표 면에서 기존 수작업 특징보다 큰 폭으로 우수한 성능을 보였다. 검증 세트에서의 평가 결과는 제안된 데이터 기반 접근법이 다중 인물 추적에 효과적임을 입증한다. 또한 제안된 추적 프레임워크는 차량 재식별(vehicle re-identification) [24]과 같은 다른 데이터셋으로부터 외형 표현을 학습함으로써 쉽게 다른 범주에도 확장 가능하다.
4.3. Evaluation on Test Set
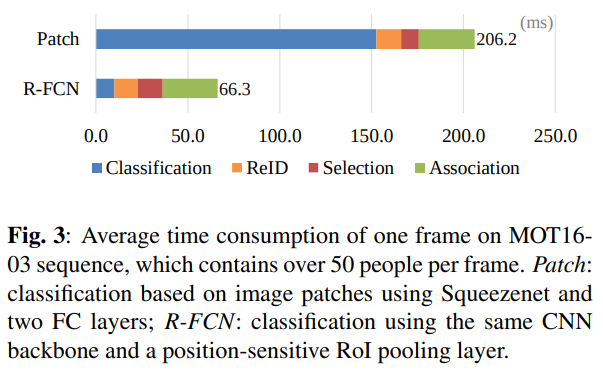
먼저, MOT16-03 시퀀스에 대해 제안한 추적 프레임워크가 소요하는 시간을 분석하였다. 그림 3에서 보이듯이, 제안 기법은 전체 이미지를 대상으로 연산을 공유함으로써 훨씬 더 높은 시간 효율을 보인다.
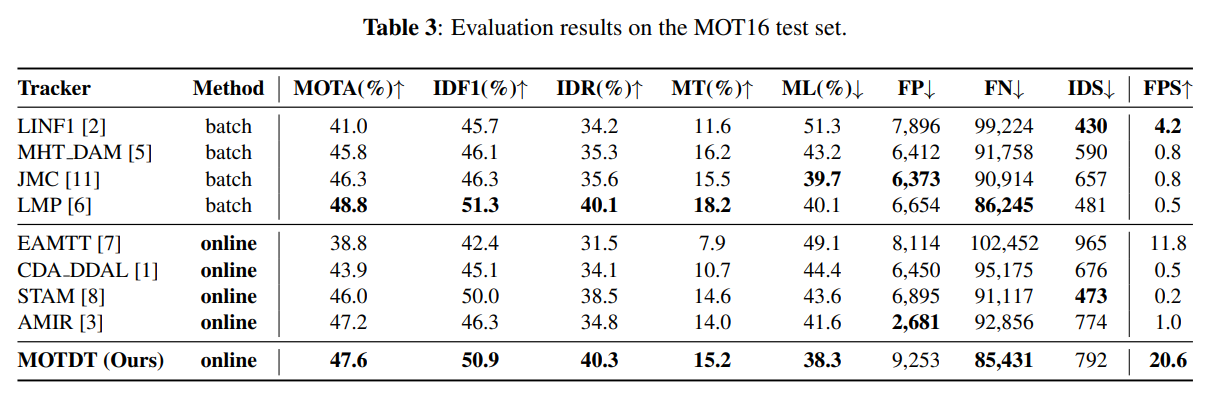
MOT16 테스트 세트에 대한 평가 결과를 표 3에 정리하였으며, 여기서 우리 추적기를 다른 오프라인·온라인 추적기들과 비교하였다. 추적 성능은 탐지 품질에 크게 좌우되므로, 공정한 비교를 위해 표에 제시된 모든 추적기는 벤치마크에서 제공하는 동일한 탐지 결과를 사용했다. 표에서 볼 수 있듯이, 본 추적기는 실시간 속도로 동작하며, 특히 IDF1, IDR, MT, ML 지표에서 기존 온라인 추적기들을 상회한다. 이는 심층적으로 학습된 외형 표현이 식별 능력을 높인 결과이며, MT와 ML의 개선은 통합 점수 함수를 통한 후보 선택이 효과적임을 보여준다. 실제로 탐지와 트랙 양쪽에서 후보를 추려 사용하면 누락된 탐지로 인해 발생하는 추적 실패가 감소한다. 또한 제안하는 온라인 추적기는 계산 복잡도가 훨씬 낮고, 대부분의 기존 방법보다 약 5~20배가량 빠르다.
5. CONCLUSION
본 논문에서는 최신 심층 신경망을 적극 활용하는 온라인 다중 인물 추적 프레임워크를 제안하였다. 우리는 탐지 결과와 추적 결과 모두에서 후보를 선택함으로써 신뢰할 수 없는 탐지 문제를 해결한다. 후보 선택을 위한 점수 함수는 전체 이미지에 대한 연산을 공유하는 효율적인 R-FCN 기반으로 정식화된다. 또한, 인물 재식별(ReID) 특징을 데이터 연결에 도입하여 카테고리 내부 가림 상황에서 식별 능력을 향상시켰다. 데이터 기반 접근 방식으로 학습된 ReID 특징은 전통적인 수작업 특징 대비 큰 폭의 성능 향상을 보인다. 제안된 추적기는 MOT16 벤치마크에서 실시간으로 동작하면서 최신 성능을 달성하였고, 향후 연구로는 분류 및 외형 추출 과정을 모두 공유할 수 있는 합성곱 레이어 설계 등을 통해 효율성을 더욱 높일 계획이다.
Long Chen, Haizhou Ai, Zijie Zhuang, Chong Shang Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification

댓글남기기