

개요
해당 포스팅은 OpenPose 논문의 2019년 PAMI 저널 버전의 논문이다. 며칠 전 해당 OpenPose 논문의 2017 CVPR 버전도 한번 읽어보았으며, 전체적으로 다시 읽어보며 차이점도 보고 중요한 점에 대해 다시 한번 집고 넘어가면 좋을 것으로 생각된다.
여러 사람이 있는 이미지에서 각 사람의 자세를 추정하는 작업은 다음과 같은 어려운 점 등이 있다.
- 사람이 몇 명이나 있을지 알기 힘들다.
- 사람들 간의 상호작용으로 인한 복잡한 간섭으로 인해 정확한 자세를 알기 어렵다.
- 실행 시간이 이미지 내 사람의 수에 따라 증가하는 경향이 있다.
17년에 나온 논문 내용이 있지만 여기서 사람의 신체 관절 부위 + 발에 대한 관절을 추가하였다고 한다. 그리고 관절 위치 추정보다 PAF의 성능을 향상시키는데에 집중하였다. 해당 논문이 제시한 기여는 다음과 같다.
- PAF를 정제하는 것이 신체 부위 예측 성능 정제보다 중요하다는 것을 입증한다.
- 몸과 발의 키포인트를 결합한 신체 자세를 이용하면서 모델의 속도를 유지 및 정확도를 유지한다.
- 아예 다른 도메인인 차량 키포인트 추정작업에 적용하여 방법의 일반성을 입증한다.
방법론
- 네트워크 구조는 PAF를 에측하는 부분과 각 관절의 신뢰도 맵을 예측하는 부분으로 나뉜다.
- 기존 2017년 버전 방식에서는 7x7 컨볼루션을 사용했었는데, 이를 3개의 3x3 컨볼루션으로 대체한다.
- 각 PAF와 신뢰도 맵은 반복적인 예측으로 그 결과를 더욱 견고히 한다.
- L2 손실을 사용하며 실제 이미지 상에서 유효하지 않은 부분은 마스킹을 사용하여 손실에 반영하지 않는다.
- PAF는 한글로는 부위 연관 필드라고 번역하면 될듯하며, 기존의 관절 모델들이 각 팔다리 등의 신체 부위의 위치만 인코딩하고 연결 방향을 인코딩하지 않는 문제, 팔다리 등의 신체 부위의 영역을 단일 지점으로 축소하는 문제를 해결한다. 신체의 영역 전체에서 위치 및 방향 정보를 인코딩한다.
- 여러명이 있을 때의 각 관절에 대한 온전한 신체 매칭은 NP-Hard 문제이지만 해당 논문은 탐욕적 완화 알고리즘을 제시하여 이러한 문제를 해결한다. 아이디어는 PAF의 수용 영역으로 각 쌍-별 연결점수가 전역적인 신체의 컨텍스트를 암묵적으로 인코딩한다고 전제하며, 연결 간선들의 최대 가중치를 갖는 매칭을 헝가리안 알고리즘을 통해 찾는다.
- PAF와 CNN 아키텍처 자체의 조합은 명시적인 모델링과 픽셀 데이터로 인한 암묵적 모델링을 모두 포함한다고 보는 것이다.
Openpose
- 해당 논문은 오픈소스 프레임워크
OpenPose를 소개한다. 해당 프레임워크는 인간의 신체 자세에 대해서 전신(신체), 발, 손, 얼굴을 포함하여 총 135개의 키포인트 구성을 제공한다. - 실시간(Realtime) + 다인(Multi-Person)에 대한 키포인트 감지 및 자세 추정을 제공한다.
- 운영체제 종속, 임베디드 하드웨어(Nvidia Tegra TX2) 등에서도 작동하며, CPU, GPU, OpenCL GPU 등의 다양한 장치, 이미지, 비디오, 스트리밍 등의 다양한 입력을 지원한다.
- 핵심은 신체+발 키포인트 탐지를 추구한다.
- 1080TI 기준 22FPS를 달성하여 실시간에도 높은 정확도를 제공한다.
실험
- MPII와 COCO 키포인트 데이터 셋, COCO에서 신체의 발 부분을 주석을 단 데이터 셋을 가지고 해당 논문의 방법론을 검증한다.
- MPII 데이터 셋에 대해 DeeperCut 방법보다 높은 mAP를 기록하며, 자리수가 6자리나 차이나는 추론 시간을 보인다.
- 스켈레톤을 만드는 매칭 알고리즘에서 그림 6에 표시된 방법의 검증 결과 최종 모델의 탐욕 알고리즘이 제일 속도면에서 빠르고, 높은 정확도를 보인다.
- COCO 데이터 셋 비교 시 최고 수준의 모델들에 비해 떨어지지만, 사람 객체의 스케일이 큰 부분에서 유독 떨어진다는 점을 주목할 만하다.
- Top-Down 방식은 객체감지기의 성능에 전체 자세 추정 성능이 크게 의존하는 것을 확인하며, SSD, CPM 등의 비교군 조합에서 우수한 성능을 달성함을 확인한다.
- Mask R-CNN, Alpha-Pose 등에 비해 런타임 성능이 제일 합리적임을 확인한다.
- 발에 대한 키포인트를 접목함으로써 기존 발목에 대한 감지 성능까지 향상되어 전체 적인 성능 지표가 오름을 확인한다.
- 일반화 성능을 위해 차량에 대한 키포인트 모델에도 적용될 수 있음을 확인한다.
결론
해당 논문의 OpenPose는 Bottom-Up 방식에서 신체 뿐 아니라 발에 대한 키포인트를 결합하여 전체적인 인간 신체 자세 추정 작업의 성능을 향상 시키고 실시간 처리를 위한 오픈 소스를 제공한다. PAF에 대한 정제와 Greedy 알고리즘을 통한 인간 스켈레톤 매칭으로 이미지 속에 여러명의 사람이 있더라도 안정적인 인간 포즈 스켈레톤을 구축한다. 또한 오픈 소스 제공을 통한 생태계에 기여한 점을 인상 깊게 볼 수 있다.
번역
Abstract
실시간 다인 2D 자세 추정은 기계가 이미지와 비디오에서 사람을 이해할 수 있게 하는 중요한 구성 요소입니다. 이 연구에서는 이미지에서 여러 사람의 2D 자세를 감지하는 실시간 방법을 제시합니다. 제안된 방법은 비모수적 표현을 사용하며, 이를 PAFs(Part Affinity Fields)라고 부르며, 이미지 내에서 신체 부위를 각 개인과 연결하는 방법을 학습합니다. 이 하향식 시스템은 이미지 내 사람 수와 관계없이 높은 정확도와 실시간 성능을 달성합니다. 이전 연구에서는 PAFs와 신체 부위 위치 추정이 학습 단계에서 동시에 개선되었습니다. 우리는 PAF와 신체 부위 위치 정제를 모두 사용하는 대신, PAF만을 정제하는 것이 실행 성능과 정확도에서 상당한 향상을 가져온다는 것을 입증합니다. 우리는 공개적으로 배포한 내부 주석이 달린 발 데이터셋을 기반으로, 최초의 몸과 발 키포인트 결합 검출기를 제시합니다. 우리는 결합된 검출기가 순차적으로 실행하는 것보다 추론 시간을 줄일 뿐만 아니라 각 구성 요소의 정확도도 개별적으로 유지한다는 것을 보여줍니다. 이 연구는 몸, 발, 손, 얼굴의 키포인트를 포함한 다인 2D 자세 추출을 위한 첫 번째 오픈소스 실시간 시스템인 OpenPose의 출시로 결실을 맺었습니다.
색인 용어 — 2D 인간 자세 추정, 2D 발 키포인트 추정, 실시간, 다인, Part Affinity Fields.
1 Introduction
이 논문에서는 이미지와 비디오에서 사람을 세밀하게 이해하는 핵심 요소인 인간 2D 자세 추정, 즉 해부학적 키포인트나 ‘부위’를 찾는 문제를 다룹니다. 인간 추정은 주로 개별 사람의 신체 부위를 찾는 데 중점을 두어 왔습니다. 이미지에서 여러 사람의 자세를 추정하는 것은 독특한 도전 과제를 제시합니다. 첫째, 각 이미지는 위치나 크기에 관계없이 나타날 수 있는 알 수 없는 수의 사람을 포함할 수 있습니다. 둘째, 사람들 간의 상호작용은 접촉, 가림, 또는 사지 관절의 움직임으로 인해 복잡한 공간적 간섭을 유발하며, 부위를 연결하는 것을 어렵게 만듭니다. 셋째, 실행 시간의 복잡성은 이미지 내 사람의 수에 따라 증가하는 경향이 있어 실시간 성능이 어려운 과제가 됩니다.
일반적인 접근 방식은 사람 탐지기를 사용하여 각 탐지에 대해 단일 사람의 자세 추정을 수행하는 것입니다. 이러한 상향식 접근 방식은 단일 사람 자세 추정을 위한 기존 기술을 직접 활용하지만, 조기 확정으로 인해 문제가 발생합니다. 즉, 사람이 가까이 있을 때 탐지기가 실패하면 복구할 방법이 없습니다. 게다가 실행 시간은 이미지 내 사람 수에 비례하며, 각 사람 탐지에 대해 단일 사람 자세 추정기가 실행됩니다. 반면, 하향식 접근 방식은 조기 확정에 대한 견고성을 제공하며, 실행 시간의 복잡성을 이미지 내 사람 수와 분리할 가능성을 제공합니다. 그러나 하향식 접근 방식은 다른 신체 부위나 다른 사람들로부터 전역적인 맥락적 단서를 직접 사용하지는 않습니다. 초기 하향식 방법([1], [2])은 마지막 분석에서 비용이 많이 드는 전역 추론이 필요하여 이미지당 몇 분씩 걸렸기 때문에 효율성의 이점을 유지하지 못했습니다.
이 논문에서는 여러 공개 벤치마크에서 경쟁력 있는 성능을 가진 다인 자세 추정을 위한 효율적인 방법을 제시합니다. 우리는 이미지 영역에서 사지의 위치와 방향을 인코딩하는 2D 벡터 필드 집합인 PAFs(Part Affinity Fields)를 통해 연관 점수의 최초 하향식 표현을 제시합니다. 우리는 이러한 하향식 탐지 및 연관 표현을 동시에 추론하는 것이 적은 계산 비용으로 높은 품질의 결과를 얻기 위한 충분한 전역 문맥을 인코딩한다는 것을 입증합니다.
이 원고의 초기 버전이 [3]에 등장했습니다. 이 버전은 몇 가지 새로운 기여를 합니다. 첫째, 우리는 PAF 정제가 정확도를 극대화하는 데 중요하지만, 신체 부위 예측 정제는 그리 중요하지 않다는 것을 입증합니다. 우리는 네트워크 깊이를 증가시키지만 신체 부위 정제 단계를 제거합니다(섹션 3.1 및 3.2). 이 정제된 네트워크는 속도와 정확도를 각각 약 200%와 7% 증가시킵니다(섹션 5.2 및 5.3). 둘째, 우리는 공개적으로 배포된 1만 5천 개의 인간 발 사례가 포함된 주석이 달린 발 데이터셋을 제시하며, 몸과 발 키포인트를 결합한 모델이 신체만을 사용하는 모델의 속도를 유지하면서 정확도를 유지할 수 있음을 보여줍니다(섹션 5.5). 셋째, 우리는 이 방법을 차량 키포인트 추정 작업에 적용하여 방법의 일반성을 입증합니다(섹션 5.6). 마지막으로, 이 작업은 OpenPose의 출시를 문서화합니다 [4]. 이 오픈소스 라이브러리는 몸, 발, 손, 얼굴의 키포인트를 포함한 다인 2D 자세 탐지를 위한 최초의 실시간 시스템입니다(섹션 4). 우리는 또한 Mask R-CNN [5] 및 AlphaPose [6]와의 실행 시간 비교를 포함하여, 우리의 하향식 접근 방식의 계산적 이점을 보여줍니다(섹션 5.3).
2 RELATED WORK
Single Person Pose Estimation
전통적인 인간 자세 추정 접근 방식은 신체 부위에 대한 지역적 관찰과 이들 간의 공간적 종속성을 결합하여 추론을 수행하는 것입니다. 자세에 대한 공간 모델은 인접 부위 간의 공간적 관계를 운동 사슬을 따라 파라미터화한 트리 구조 그래픽 모델 [7], [8], [9], [10], [11], [12], [13]을 기반으로 하거나, 트리 구조에 가림, 대칭, 장거리 관계를 포착하는 추가적인 엣지를 추가한 비트리 모델 [14], [15], [16], [17], [18]을 기반으로 합니다. 신체 부위의 신뢰할 수 있는 지역 관찰을 얻기 위해 CNN(Convolutional Neural Networks)이 널리 사용되었으며, 신체 자세 추정의 정확도를 크게 향상시켰습니다 [19], [20], [21], [22], [23], [24], [25], [26], [27], [28], [29], [30], [31], [32]. Tompson 등 [23]은 네트워크와 함께 매개 변수를 공동으로 학습하는 그래픽 모델과 함께 심층 아키텍처를 사용했습니다. Pfister 등 [33]은 큰 수용 영역을 갖춘 네트워크를 설계하여 CNN을 통해 전역 공간 종속성을 암묵적으로 포착하는 방식을 추가로 사용했습니다. Wei 등 [20]이 제안한 컨볼루션 포즈 머신 아키텍처는 순차적 예측 프레임워크 [34]를 기반으로 하는 다단계 아키텍처를 사용하며, 반복적으로 전역 문맥을 통합하여 부위 신뢰도 지도를 정제하고 이전 반복에서 다중 모달 불확실성을 유지했습니다. 학습 중 사라지는 그래디언트 문제를 해결하기 위해 각 단계의 끝에서 중간 감독이 적용됩니다 [35], [36], [37]. Newell 등 [19]은 중간 감독이 스택드 아워글라스 아키텍처에서 유익하다는 것도 보여주었습니다. 그러나 이러한 방법들은 모두 관심 대상의 위치와 크기가 주어지는 단일 사람을 가정합니다.
Multi-Person Pose Estimation
다인 자세 추정을 위해 대부분의 접근 방식 [5], [6], [38], [39], [40], [41], [42], [43], [44]은 우선 사람을 감지한 후 각 감지된 영역에서 개별적으로 자세를 추정하는 상향식 전략을 사용했습니다. 이 전략은 단일 사람 사례를 위해 개발된 기술을 직접 적용할 수 있게 하지만, 사람 탐지에 대한 조기 확정의 문제를 겪을 뿐만 아니라, 전역적인 추론이 필요한 서로 다른 사람들 간의 공간적 종속성을 포착하지 못합니다. 일부 접근 방식은 사람 간의 종속성을 고려하기 시작했습니다. Eichner 등 [45]은 상호 작용하는 사람 집합과 깊이 순서를 고려하여 그림 구조를 확장했지만, 여전히 탐지 가설을 초기화하기 위해 사람 탐지기가 필요했습니다. Pishchulin 등 [1]은 부위 탐지 후보를 공동으로 라벨링하고 이를 개별 사람과 연결하는 하향식 접근 방식을 제안했으며, 탐지된 부위의 공간 오프셋으로부터 회귀된 쌍별 점수를 사용했습니다. 이 접근 방식은 사람 탐지에 의존하지 않지만, 완전 연결된 그래프에서 제안된 정수 선형 프로그래밍을 해결하는 것은 NP-난해 문제이며, 따라서 단일 이미지의 평균 처리 시간은 몇 시간 단위로 걸립니다. Insafutdinov 등 [2]은 [1]을 기반으로 ResNet [46]과 이미지 의존적인 쌍별 점수를 사용한 더 강력한 부위 탐지기를 구축하고, 점진적 최적화 접근 방식을 통해 실행 시간을 크게 개선했지만, 여전히 이미지당 몇 분씩 걸리며 최대 150개의 부위 제안을 처리할 수 있습니다. [2]에서 사용된 쌍별 표현은 각 신체 부위 쌍 간의 오프셋 벡터로, 이를 정확하게 회귀하기 어렵기 때문에 쌍별 특징을 확률 점수로 변환하기 위한 별도의 로지스틱 회귀가 필요합니다.
이전 연구 [3]에서는 다양한 수의 사람 신체 부위 간의 구조화되지 않은 쌍별 관계를 인코딩하는 흐름 필드 집합으로 구성된 PAFs(Part Affinity Fields) 표현을 제시했습니다. [1] 및 [2]와 달리 우리는 추가적인 학습 단계 없이 PAF에서 효율적으로 쌍별 점수를 얻을 수 있습니다. 이러한 점수는 실시간 성능을 갖춘 다인 추정을 위한 고품질 결과를 얻기 위한 탐욕적 분석에 충분합니다. 이 연구와 동시에, Insafutdinov 등 [47]은 단일 프레임 모델에서 더 빠른 추론을 위해 신체 부위 관계 그래프를 더욱 단순화하고, 부위 제안의 시공간 그룹화로 인간 트래킹을 공식화했습니다. 최근 Newell 등 [48]은 각 키포인트 그룹을 나타내는 태그로 생각할 수 있는 연관 임베딩을 제안했습니다. 그들은 비슷한 태그를 가진 키포인트를 개별 사람으로 그룹화합니다. Papandreou 등 [49]은 개별 키포인트를 감지하고 그들의 상대적 이동을 예측하는 방식을 제안하여 탐욕적 디코딩 과정을 통해 키포인트를 사람 인스턴스로 그룹화할 수 있게 했습니다. Kocabas 등 [50]은 키포인트와 사람 탐지를 받아서, 키포인트를 감지된 사람의 경계 상자에 할당하는 Pose Residual Network를 제안했습니다. Nie 등 [51]은 이미지 내 사람의 중심으로부터 키포인트 후보까지의 밀집 회귀를 사용하여 모든 키포인트 탐지를 분할하는 방법을 제안했습니다.
이 연구에서는 이전 연구 [3]에 여러 확장을 추가했습니다. 우리는 PAF 정제가 높은 정확도를 위해 매우 중요하고 충분하다는 것을 입증했으며, 신체 부위 신뢰도 지도 정제를 제거하면서 네트워크 깊이를 증가시켰습니다. 이는 더 빠르고 더 정확한 모델로 이어집니다. 우리는 또한 주석이 달린 발 데이터셋에서 생성된 최초의 몸과 발 키포인트 결합 검출기를 제시하며, 이 데이터셋은 공개될 예정입니다. 우리는 두 가지 탐지 접근 방식을 결합하면 독립적으로 실행하는 것에 비해 추론 시간이 줄어들 뿐만 아니라 각각의 정확도도 유지된다는 것을 입증했습니다. 마지막으로, 우리는 실시간 몸, 발, 손, 얼굴 키포인트 탐지를 위한 최초의 오픈소스 라이브러리인 OpenPose를 제시합니다.
3 METHOD

그림 2는 우리의 방법의 전체 파이프라인을 보여줍니다. 시스템은 $w × h$ (그림 2a) 크기의 컬러 이미지를 입력으로 받아들여, 이미지 내 각 사람의 해부학적 키포인트의 2D 위치를 생성합니다(그림 2e). 먼저, 피드포워드 네트워크가 신체 부위 위치의 2D 신뢰도 지도 집합 $\mathbf{S}$ (그림 2b)와 부위 연관 필드(PAF)의 2D 벡터 필드 집합 $\mathbf{L}$ (그림 2c)를 예측하며, 이는 부위 간 연관 정도를 인코딩합니다. 집합 $\mathbf{S} = (\mathbf{S}₁, \mathbf{S}₂, …, \mathbf{S}ⱼ)$ 는 각 부위에 하나씩, 총 $J$ 개의 신뢰도 지도를 가지고 있으며, $\mathbf{S}_j ∈ ℝ^{w \times h}, j ∈ {1 … J}$ 입니다. 집합 $\mathbf{L} = (\mathbf{L}₁, \mathbf{L}₂, …, \mathbf{L}c)$ 는 각 팔다리에 하나씩, 총 $C$ 개의 벡터 필드를 가지고 있으며, $\mathbf{L}_c ∈ ℝ^{w\times h\times 2}, c ∈ {1 … C}$ 입니다. 명확히 하기 위해 부위 쌍을 팔다리라고 부르지만, 일부 쌍은 인간의 팔다리가 아닙니다(예: 얼굴). $\mathbf{L}_c$ 의 각 이미지 위치는 2D 벡터를 인코딩합니다(그림 1). 마지막으로, 신뢰도 지도와 PAF는 탐욕적 추론을 통해 해석되어 이미지 내 모든 사람의 2D 키포인트를 출력합니다(그림 2d).

3.1 Network Architecture
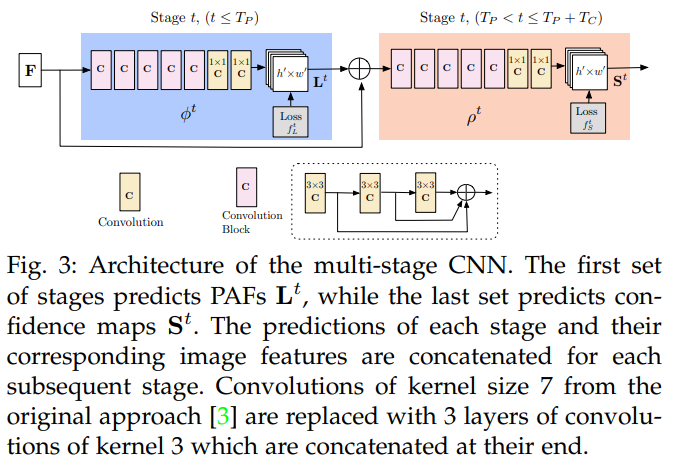
그림 3에서 보여지는 우리의 구조는 파란색으로 표시된 부위 간 연관을 인코딩하는 친화 필드와 베이지색으로 표시된 탐지 신뢰도 지도를 반복적으로 예측합니다. [20]을 따라 반복 예측 구조는 각 단계에서 중간 감독과 함께 연속적인 단계, $t ∈ {1, …, T},$ 에서 예측을 정제합니다.
네트워크 깊이는 [3]에 비해 증가합니다. 원래 접근 방식에서, 네트워크 구조는 여러 개의 7x7 컨볼루션 층을 포함했습니다. 현재 모델에서는 각 7x7 컨볼루션 커널을 연속적인 3개의 3x3 커널로 대체함으로써 계산은 줄이면서 수용 필드는 유지됩니다. 전자의 연산 횟수는 $2 × 7^2 - 1 = 97$ 인 반면, 후자는 $51$ 에 불과합니다. 또한, 3개의 컨볼루션 커널 각각의 출력은 DenseNet [52]과 유사한 방식으로 연결됩니다. 비선형 층의 수가 세 배로 늘어나고, 네트워크는 하위 레벨과 상위 레벨의 특징을 모두 유지할 수 있습니다. 5.2절과 5.3절에서는 각각 정확도와 실행 속도 개선을 분석합니다.
3.2 Simultaneous Detection and Association
이미지는 VGG-19 [53]의 처음 10개의 층으로 초기화된 CNN에 의해 분석되고, 첫 번째 단계에 입력되는 특징 맵 집합 $\mathcal{F}$ 를 생성합니다. 이 단계에서 네트워크는 부위 연관 필드(PAF) 집합 $\mathbf{L}^1 = \phi^1(\mathbf{F})$ 를 생성하며, 여기서 $\phi^1$ 은 1단계에서의 추론을 위한 CNN을 의미합니다. 각 이후 단계에서, 이후 각 단계에서 이전 단계의 예측과 원본 이미지 특징 $\mathbf{F}$ 가 연결되어 정제된 예측을 생성하는 데 사용됩니다.
\[\begin{equation} \mathbf{L}^1 = \phi^t(\mathbf{F}, \mathbf{L}^{t-1}, \forall2 \leq t\leq T_P) \end{equation}\]여기서 $\phi^t$ 는 $t$ 단계 추론을 위한 CNN을 나타내며, $T_P$ 는 총 PAF 단계의 수를 의미합니다. $T_P$ 번의 반복 후, 최신 PAF 예측에서 시작하여 신뢰도 지도 탐지를 위한 과정이 반복됩니다.
\[\begin{equation} \mathbf{S}^{T_P} = \rho^t(\mathbf{F},\mathbf{L}^{T_P}), \forall{t}=T_P \end{equation}\] \[\begin{equation} \mathbf{S}^{T} = \rho^t(\mathbf{F},\mathbf{L}^{T_P},\mathbf{S}^{t-1}), \forall{T_P} < t \leq T_P+T_C, \end{equation}\]여기서 $\rho^t$는 $t$ 단계 추론을 위한 CNN을 나타내며, $T_C$ 는 총 신뢰도 지도 단계의 수를 의미합니다.
이 접근 방식은 [3]과 다르며, [3]에서는 PAF와 신뢰도 지도 가지가 각 단계에서 정제되었습니다. 따라서 각 단계에서의 계산량이 절반으로 줄어듭니다. 우리는 5.2절에서 정제된 연관 필드 예측이 신뢰도 지도 결과를 개선하지만, 반대의 경우는 성립하지 않는다는 것을 경험적으로 관찰합니다. 직관적으로, PAF 채널 출력을 보면 신체 부위의 위치를 추정할 수 있습니다. 그러나 다른 정보 없이 신체 부위만 모여 있는 것을 보면, 이를 다른 사람들로 해석할 수 없습니다.

그림 4는 각 단계에서 친화 필드의 정제를 보여줍니다. 신뢰도 지도 결과는 최신 및 가장 정제된 PAF 예측을 기반으로 하며, 신뢰도 지도 단계 간 차이는 거의 눈에 띄지 않습니다. 네트워크가 첫 번째 분기에서 신체 부위의 PAF를 반복적으로 예측하고 두 번째 분기에서 신뢰도 지도를 예측하도록 유도하기 위해, 우리는 각 단계 끝에 손실 함수를 적용합니다. 우리는 추정된 예측과 실제 지도의 $L_2$ 손실을 사용합니다. 여기서 우리는 일부 데이터셋이 모든 사람을 완벽하게 라벨링하지 않는 실제 문제를 해결하기 위해 손실 함수를 공간적으로 가중합니다. 구체적으로, $t_i$ 단계에서 PAF 분기의 손실 함수와 $t_k$ 단계에서 신뢰도 지도 분기의 손실 함수는 다음과 같습니다:
\[\begin{equation} f_\mathbf{L}^{t_i} = \sum_{c=1}^C\sum_\mathbf{p}{\mathbf{W}(\mathbf{p})\cdot\Vert\mathbf{L}_c^{t_i}(\mathbf{p})-\mathbf{L}_c^{\ast}(\mathbf{p})\Vert_2^2}, \end{equation}\] \[\begin{equation} f_\mathbf{S}^{t_k} = \sum_{j=1}^J\sum_\mathbf{p}{\mathbf{W}(\mathbf{p})\cdot\Vert\mathbf{S}_j^{t_k}(\mathbf{p})-\mathbf{S}_j^{\ast}(\mathbf{p})\Vert_2^2}, \end{equation}\]여기서 $\mathbf{L}_c^{\ast}$ 는 실제 PAF 이고, $\mathbf{S}_j$ 는 실제 부위 신뢰도 지도이며, $\mathbf{W}$ 는 픽셀 $\mathbf{p}$ 에서 주석이 없을 때 $\mathbf{W}(\mathbf{p}) = 0$ 인 이진 마스크입니다. 이 마스크는 학습 중 참 양성 예측에 대한 페널티를 방지하는 데 사용됩니다. 각 단계의 중간 감독은 [20]에서 설명된 대로 그래디언트를 주기적으로 보충하여 사라지는 그래디언트 문제를 해결합니다. 전체 목표는 다음과 같습니다.
\[\begin{equation} f = \sum_{t=1}^{T_P}{f_{\mathbf{L}}^t}+\sum_{t=T_P+1}^{T_P+T_C}{f_\mathbf{S}^t} \end{equation}\]3.3 Confidence Maps for Part Detection
학습 중 식 (6)에서 $f_\mathbf{S}$ 를 평가하기 위해, 우리는 주석이 달린 2D 키포인트에서 실제 신뢰도 지도 $\mathbf{S}\ast$ 를 생성합니다. 각 신뢰도 지도는 특정 신체 부위가 주어진 픽셀에 위치할 수 있다는 믿음을 나타내는 2D 표현입니다. 이상적으로, 이미지에 한 명의 사람만 나타나면, 해당 부위가 보이는 경우 각 신뢰도 지도에 하나의 봉우리가 있어야 합니다. 여러 사람이 있는 경우, 각 사람 $k$ 의 보이는 부위 $j$ 에 해당하는 봉우리가 있어야 합니다.
우리는 먼저 각 사람 $k$ 에 대해 개별 신뢰도 지도 $\mathbf{S}_{j,k}^\ast$ 를 생성합니다. $\mathbf{x}_{j,k} ∈ ℝ^2$ 는 이미지에서 사람 $k$ 의 신체 부위 $j$ 의 실제 위치입니다. $\mathbf{S}_{j,k}^{\ast}$ 의 $\mathbf{p} ∈ ℝ^2$ 위치에서의 값은 다음과 같이 정의됩니다.
여기서 $σ$ 는 봉우리의 퍼짐을 제어합니다. 네트워크가 예측하는 실제 신뢰도 지도는 최대 연산자를 통해 개별 신뢰도 지도의 집합입니다.
\[\begin{equation} \mathbf{S}^{\ast}_{j}(\mathbf{p}) = \max_k\mathbf{S}_{j,k}^{\ast}(\mathbf{p}). \end{equation}\]
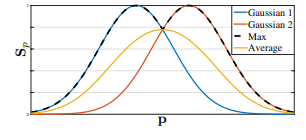
우리는 평균 대신 신뢰도 지도의 최대값을 취하여, 인접한 봉우리의 정밀도가 뚜렷하게 유지되도록 합니다. 이는 오른쪽 그림에 나와 있습니다. 테스트 시점에 우리는 신뢰도 지도를 예측하고, 비최대 억제를 통해 신체 부위 후보를 얻습니다.
3.4 Part Affinity Fields for Part Association

탐지된 신체 부위 집합(그림 5a에서 빨간색과 파란색 점으로 표시됨)을 바탕으로, 우리는 어떻게 이들을 조합하여 알 수 없는 수의 사람들에 대한 전체 신체 자세를 구성할 수 있을까요? 우리는 각 신체 부위 탐지 쌍에 대해 연결 신뢰도를 측정할 필요가 있습니다. 즉, 그것들이 동일한 사람에게 속하는지 여부입니다. 연결을 측정하는 한 가지 방법은 각 팔다리의 부위 쌍 사이에 추가적인 중간점을 감지하고, 후보 신체 부위 탐지 간의 발생을 확인하는 것입니다(그림 5b 참조). 그러나 사람들이 가까이 모이면(자주 일어나는 일처럼), 이러한 중간점은 잘못된 연결을 지지할 가능성이 큽니다(그림 5b에서 녹색 선으로 표시됨). 이러한 잘못된 연결은 두 가지 한계로 인해 발생합니다: (1) 각 팔다리의 위치만 인코딩되고 방향은 인코딩되지 않습니다; (2) 팔다리 지지 영역이 단일 지점으로 축소됩니다.
부위 연관 필드(PAF)는 이러한 한계를 해결합니다. 그것들은 팔다리 지지 영역 전체에서 위치 및 방향 정보를 유지합니다(그림 5c 참조). 각 PAF는 각 팔다리에 대한 2D 벡터 필드이며, 그림 1d에서도 보여집니다. 특정 팔다리 영역에 속하는 각 픽셀에 대해 2D 벡터는 팔다리의 한 부분에서 다른 부분으로 향하는 방향을 인코딩합니다. 각 유형의 팔다리는 두 관련 신체 부위를 연결하는 PAF를 가지고 있습니다.
아래 그림에 표시된 단일 팔다리를 고려하십시오.
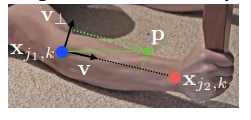
$\mathbf{x}_{j_1,k}$ 및 $\mathbf{x}_{j_2,k}$ 는 이미지에서 사람 $k$ 의 팔다리 $c$ 에 있는 신체 부위 $j_1$ 및 $j_2$ 의 실제 위치입니다. 만약 지점 $\mathbf{p}$ 가 팔다리에 있으면, $\mathbf{L}_{c,k}^{\ast}(\mathbf{p})$ 에서의 값은 $j_1$ 에서 $j_2$ 로 향하는 단위 벡터입니다. 나머지 모든 지점에 대해서는 벡터 값이 0입니다.
학습 중 식 (6)에서 $f_\mathbf{L}$ 을 평가하기 위해, 우리는 이미지 지점 $\mathbf{p}$ 에서의 실제 PAF, $L^{\ast}_{c,k}$ 를 다음과 같이 정의합니다.
\[\begin{equation} \mathbf{L}^{\ast}_{c,k}(\mathbf{p})= \begin{cases} \mathbf{v} & \text{if } \mathbf{p} \text{ on limb } c,k \\ 0 & \text{otherwise. } \end{cases} \end{equation}\]여기서, $\mathbf{v} = (\mathbf{x}_{j_2,k} - \mathbf{x}_{j_1,k})/\Vert \mathbf{x}_{j_2,k} - \mathbf{x}_{j_1,k}\Vert_2$ 는 팔다리 방향으로의 단위 벡터입니다. 팔다리 위의 점 집합은 선분의 거리 임계값 내에 있는 점으로 정의됩니다. 즉, $\mathbf{p}$ 가 해당하는 점은
\[0 \leq \mathbf{v}\cdot(\mathbf{p}-\mathbf{x}\_{j_1,k}) \leq l\_{c,k} \text{ and }|\mathbf{v}_⊥·(\mathbf{p}-\mathbf{x}_{j_1,k})|\leq σ_l,\]여기서 팔다리 폭 $σ_l$ 는 픽셀 단위의 거리이며, 팔다리 길이는 $l_{c,k} = \Vert\mathbf{x}_{j_2,k} - \mathbf{x}_{j_1,k}\Vert_2$ 이고, $\mathbf{v}_⊥$ 는 $\mathbf{v}$ 에 수직인 벡터입니다.
실제 신체 부위 연관 필드는 이미지에 있는 모든 사람의 연관 필드를 평균화합니다.
여기서 $n_c(\mathbf{p})$ 는 $\mathbf{p}$ 지점에서 모든 사람에 대한 0이 아닌 벡터의 수입니다.
테스트 중 우리는 후보 신체 부위 탐지 간의 연결을, 후보 신체 부위 위치를 연결하는 선분을 따라 해당 PAF에 대한 선적분을 계산하여 측정합니다. 즉, 탐지된 신체 부위를 연결하여 형성되는 후보 팔다리와 예측된 PAF의 정렬을 측정합니다. 구체적으로, 두 후보 신체 부위 위치 $\mathbf{d}_{j_1}$ 과 $\mathbf{d}_{j_2}$ 에 대해, 우리는 선분을 따라 예측된 신체 부위 연관 필드 $\mathbf{L}_c$ 를 샘플링하여 연결에 대한 신뢰도를 측정합니다:
여기서 $\mathbf{p}(u)$ 는 두 신체 부위 $d_{j_1}$ 과 $d_{j_2}$ 의 위치를 보간합니다.
\[\begin{equation} \mathbf{p}(u)=(1-u)\mathbf{d}_{j_1}+u\mathbf{d}_{j_2}. \end{equation}\]실제로 우리는 $u$ 의 균등하게 간격을 둔 값을 샘플링하고 합산하여 적분을 근사화합니다.
3.5 Multi-Person Parsing using PAFs
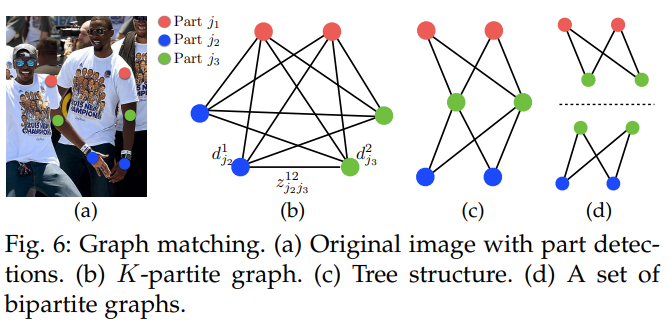
우리는 탐지 신뢰도 지도에 대해 비최대 억제를 수행하여 신체 부위 후보 위치의 이산 집합을 얻습니다. 각 신체 부위에 대해 여러 후보가 있을 수 있으며, 이는 이미지 내 여러 사람 또는 잘못된 탐지(그림 6b)로 인한 것입니다. 이러한 신체 부위 후보는 가능한 팔다리의 큰 집합을 정의합니다. 우리는 식 11에서 정의된 PAF의 선적분 계산을 사용하여 각 후보 팔다리에 점수를 부여합니다. 최적의 파싱을 찾는 문제는 NP-Hard 한 것으로 알려진 $K$ 차원 매칭 문제에 해당합니다 [54] (그림 6c). 이 논문에서는 지속적으로 높은 품질의 매칭을 생성하는 탐욕적인 완화 방식을 제시합니다. 우리는 PAF 네트워크의 큰 수용 영역으로 인해 쌍별 연결 점수가 전역적인 문맥을 암묵적으로 인코딩한다고 추측합니다.
공식적으로, 우리는 먼저 여러 사람에 대해 신체 부위 탐지 후보 집합 $\mathcal{D}_\mathcal{J}$ 를 얻으며, 여기서 $\mathcal{D}_\mathcal{J} = {\mathbf{d}^m_j: j ∈ {1…J}, m ∈ {1…N_j}}$ 이고, $N_j$ 는 신체 부위 $j$ 의 후보 수이며, $\mathbf{d}^m_j ∈ ℝ^2$ 는 신체 부위 $j$ 의 $m$ 번째 탐지 후보의 위치입니다. 이러한 신체 부위 탐지 후보는 여전히 동일한 사람의 다른 부위와 연결되어야 합니다. 즉, 실제로 연결된 팔다리인 신체 부위 탐지 쌍을 찾아야 합니다. 우리는 $z_{j_1j_2}^{mn} ∈ {0,1}$ 변수를 정의하여 두 탐지 후보 $d_{j_1}^m$ 과 $d_{j_2}^n$ 이 연결되어 있는지 나타내며, 목표는 가능한 모든 연결 집합에 대한 최적의 할당을 찾는 것입니다, $\mathcal{Z} = {z_{j_1j_2}^{mn}}$.
신체 부위 $j_1$ 과 $j_2$ 의 단일 쌍(예: 목과 오른쪽 엉덩이)을 $c$ 번째 팔다리로 고려하면, 최적의 연결 찾기는 최대 가중치 이분 그래프 매칭 문제로 줄어듭니다 [54]. 이 경우는 그림 5b에 나와 있습니다. 이 그래프 매칭 문제에서, 그래프의 노드는 신체 부위 탐지 후보 $\mathcal{D}_{j_1}$ 및 $\mathcal{D}_{j_2}$ 이며, 간선은 탐지 후보 쌍 간의 가능한 모든 연결입니다. 또한, 각 간선은 신체 부위 연관 집합인 식 11로 가중됩니다. 이분 그래프의 매칭은 두 간선이 노드를 공유하지 않도록 선택된 간선들의 부분 집합입니다. 우리의 목표는 선택된 간선들에 대해 최대 가중치를 갖는 매칭을 찾는 것입니다.
여기서 $E_c$ 는 팔다리 유형 $c$ 에서의 매칭에 대한 전체 가중치이며, $\mathcal{Z}_c$ 는 팔다리 유형 $c$ 에 대한 $\mathcal{Z}$ 의 부분 집합이고, $E_{mn}$ 은 식 11에서 정의된 신체 부위 $d_{j_1}^m$ 과 $d_{j_2}^n$ 간의 부위 친화성입니다. 식 14와 15는 두 개의 간선이 노드를 공유하지 않도록 보장하며, 즉 동일한 유형의 두 팔다리(예: 왼팔)는 신체 부위를 공유하지 않습니다. 헝가리안 알고리즘 [55]을 사용하여 최적의 매칭을 얻을 수 있습니다.
여러 사람의 전체 신체 자세를 찾는 문제에서는, $\mathcal{Z}$ 를 결정하는 것이 $K$차원 매칭 문제입니다. 이 문제는 NP-Hard 문제 [54]이며, 많은 완화 방법이 존재합니다. 이 논문에서는 우리 도메인에 특화된 두 가지 완화 방식을 최적화에 추가합니다. 첫째, 우리는 그림 6c에 표시된 것처럼 완전한 그래프 대신 최소 간선 수로 사람의 신체 자세에 대한 스패닝 트리 골격을 선택합니다. 둘째, 우리는 매칭 문제를 이분 매칭 하위 문제 집합으로 더 세분화하고, 인접한 트리 노드에서의 매칭을 독립적으로 결정합니다(그림 6d 참조). 우리는 5.1절에서 상세한 비교 결과를 보여주며, 최소한의 탐욕적 추론이 전역 해법을 계산 비용의 일부로 잘 근사화함을 증명합니다. 그 이유는 인접한 트리 노드 간의 관계는 PAF에 의해 명시적으로 모델링되지만, 내부적으로는 CNN에 의해 비인접 트리 노드 간의 관계가 암묵적으로 모델링되기 때문입니다. 이 특성은 CNN이 큰 수용 영역으로 훈련되었기 때문에 발생하며, 비인접 트리 노드에서의 PAF도 예측된 PAF에 영향을 미칩니다.
이러한 두 가지 완화 방식으로 최적화는 단순하게 분해됩니다:
따라서 우리는 식 13–15를 사용하여 각 팔다리 유형에 대한 팔다리 연결 후보를 독립적으로 얻습니다. 모든 팔다리 연결 후보를 통해, 우리는 동일한 신체 부위 탐지 후보를 공유하는 연결을 조합하여 여러 사람의 전체 신체 자세를 구성할 수 있습니다. 트리 구조를 통한 우리의 최적화 방식은 완전 연결된 그래프에 대한 최적화보다 훨씬 빠릅니다 [1], [2].

현재 모델은 귀와 어깨, 손목과 어깨 간의 중복 PAF 연결 등을 포함합니다. 이 중복성은 그림 7에서 보이는 것처럼 사람이 많은 이미지에서 정확도를 특히 향상시킵니다. 이러한 중복 연결을 처리하기 위해 우리는 다인 파싱 알고리즘을 약간 수정했습니다. 원래 방식은 루트 구성 요소에서 시작했지만, 우리의 알고리즘은 모든 쌍별 가능한 연결을 PAF 점수에 따라 정렬합니다. 만약 연결이 이미 다른 사람에게 할당된 두 신체 부위를 연결하려고 시도하면, 알고리즘은 이것이 더 높은 신뢰도의 PAF 연결과 모순된다는 것을 인식하고, 현재 연결은 무시됩니다.
4 OPENPOSE

점점 더 많은 컴퓨터 비전 및 머신러닝 애플리케이션이 시스템 입력으로 2D 인간 자세 추정을 필요로 합니다 [56], [57], [58], [59], [60], [61], [62]. 연구 커뮤니티가 그들의 작업을 향상시킬 수 있도록, 우리는 OpenPose [4]를 공개적으로 출시했습니다. 이는 단일 이미지에서 인체, 발, 손, 얼굴 키포인트(총 135개의 키포인트)를 공동으로 감지하는 최초의 실시간 다인 시스템입니다. 시스템 전체의 예는 그림 8을 참조하십시오.
4.1 System
Mask R-CNN [5] 또는 Alpha-Pose [6]와 같은 기존의 2D 신체 자세 추정 라이브러리는 사용자에게 파이프라인의 대부분을 구현하고, 자체 프레임 리더(예: 비디오, 이미지 또는 카메라 스트리밍), 결과 시각화를 위한 디스플레이, JSON 또는 XML 파일과 같은 결과 파일 생성을 요구합니다. 또한, 기존의 얼굴 및 신체 키포인트 감지기는 결합되어 있지 않아 각 용도마다 다른 라이브러리를 필요로 합니다. OpenPose는 이러한 모든 문제를 해결합니다. Ubuntu, Windows, Mac OSX, Nvidia Tegra TX2와 같은 임베디드 시스템을 포함한 다양한 플랫폼에서 실행할 수 있습니다. 또한, CUDA GPU, OpenCL GPU 및 CPU 전용 장치와 같은 다양한 하드웨어를 지원합니다. 사용자는 이미지, 비디오, 웹캠 및 IP 카메라 스트리밍 중 입력을 선택할 수 있습니다. 사용자는 결과를 화면에 표시할지 또는 디스크에 저장할지 선택할 수 있으며, 신체, 발, 얼굴, 손 탐지기 각각을 활성화 또는 비활성화할 수 있습니다. 또한 픽셀 좌표 정규화 활성화, GPU 사용 개수 제어, 빠른 처리를 위한 프레임 건너뛰기 등을 할 수 있습니다.
OpenPose는 세 가지 다른 블록으로 구성됩니다: (a) 신체+발 탐지, (b) 손 탐지 [63], (c) 얼굴 탐지. 핵심 블록은 신체+발 키포인트 탐지기입니다(4.2절 참조). COCO 및 MPII 데이터셋에서 훈련된 원래의 신체 전용 모델 [3]을 사용할 수도 있습니다. 신체 탐지기의 출력에 따라, 얼굴의 경계 상자 제안은 주로 귀, 눈, 코, 목과 같은 신체 부위 위치에서 대략적으로 추정될 수 있습니다. 유사하게, 손 경계 상자 제안은 팔의 키포인트로 생성됩니다. 이 방법론은 1장에서 논의된 탑다운 접근 방식의 문제를 계승합니다. 손 키포인트 탐지기 알고리즘은 [63]에서 자세히 설명되어 있으며, 얼굴 키포인트 탐지기는 손 키포인트 탐지기와 동일한 방식으로 훈련되었습니다. 라이브러리에는 여러 동기화된 카메라 뷰의 결과를 기반으로 비선형 Levenberg-Marquardt 보정을 사용한 3D 삼각 측량을 수행하여 3D 키포인트 자세 탐지가 포함됩니다 [64].
OpenPose의 추론 시간은 최첨단 방법을 능가하면서도 고품질 결과를 유지합니다. Nvidia GTX 1080 Ti가 장착된 기계에서 초당 약 22프레임(FPS)으로 높은 정확도를 유지하며 실행할 수 있습니다 (5.3절 참조). OpenPose는 이미 연구 커뮤니티에서 사람 재식별 [56], GAN 기반 얼굴 [57] 및 신체 [58] 비디오 리타겟팅, 인간-컴퓨터 상호작용 [59], 3D 자세 추정 [60], 3D 인간 메시 모델 생성 [61] 등의 여러 비전 및 로봇 공학 주제에 사용되고 있습니다. 또한, OpenCV 라이브러리 [65]는 OpenPose와 우리의 PAF 기반 네트워크 아키텍처를 심층 신경망(DNN) 모듈에 포함시켰습니다.
4.2 Extended Foot Keypoint Detection
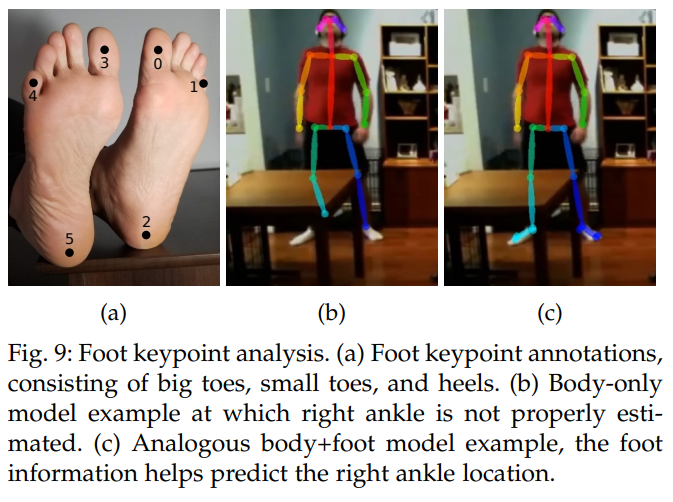
기존 인간 자세 데이터셋([66], [67])에는 제한된 신체 부위 유형이 포함되어 있습니다. MPII 데이터셋 [66]은 발목, 무릎, 엉덩이, 어깨, 팔꿈치, 손목, 목, 몸통, 머리 위쪽을 주석으로 달고 있으며, COCO [67]는 일부 얼굴 키포인트도 포함합니다. 이 두 데이터셋 모두 발 주석은 발목 위치에만 제한됩니다. 그러나 아바타 리타겟팅 또는 3D 인간 형상 재구성([61], [68])과 같은 그래픽 애플리케이션에서는 큰 발가락과 발뒤꿈치 같은 발 키포인트가 필요합니다. 발 정보가 없으면 이러한 접근 방식은 캔디 래퍼 효과, 바닥 관통, 발 스케이트와 같은 문제에 직면합니다. 이러한 문제를 해결하기 위해 COCO 데이터셋의 작은 발 인스턴스 하위 집합이 Clickworker 플랫폼 [69]을 사용하여 주석 처리되었습니다. COCO 훈련 세트에서 14,000개의 주석과 검증 세트에서 545개의 주석으로 분할되었습니다. 총 6개의 발 키포인트가 레이블링되었습니다 (그림 9a 참조). 우리는 표면 위치보다는 발 키포인트의 3D 좌표를 고려합니다. 예를 들어, 정확한 발가락 위치의 경우, 우리는 발톱과 피부의 연결 부위 사이를 레이블링하고, 표면이 아닌 발가락의 중심을 레이블링하여 깊이도 고려합니다.
우리의 데이터셋을 사용하여 발 키포인트 탐지 알고리즘을 훈련합니다. 단순한 발 키포인트 탐지기는 신체 키포인트 탐지기를 사용하여 발 경계 상자 제안을 생성하고, 그 위에 발 탐지기를 훈련함으로써 구축될 수 있었을 것입니다. 그러나 이 방법은 1장에서 설명한 탑다운 문제를 겪습니다. 대신, 신체 추정을 위해 이전에 설명된 동일한 아키텍처가 신체와 발 위치 모두를 예측하도록 훈련됩니다. 그림 10은 세 가지 데이터셋(COCO, MPII, COCO+foot)의 키포인트 분포를 보여줍니다. 신체+발 모델은 엉덩이 사이에 보간된 점을 포함하여 상체가 가려지거나 이미지 밖에 있을 때도 두 다리를 연결할 수 있도록 합니다. 우리는 발 키포인트 탐지가 특히 발목 위치와 같은 다리 키포인트를 더 정확하게 예측하는 데 네트워크를 암묵적으로 돕는다는 증거를 발견했습니다. 그림 9b는 신체 전용 네트워크가 발목 위치를 예측하지 못한 예시를 보여줍니다. 훈련 중 발 키포인트를 포함하면서 동일한 신체 주석을 유지함으로써, 알고리즘은 그림 9c에서 발목 위치를 적절하게 예측할 수 있습니다. 우리는 5.5장에서 정확도 차이를 정량적으로 분석합니다.

5 DATASETS AND EVALUATIONS
우리는 다인 자세 추정을 위한 세 가지 벤치마크에서 우리의 방법을 평가합니다: (1) MPII 인간 다인 데이터셋 [66], 이 데이터셋은 14개의 신체 부위를 가진 여러 상호 작용하는 개인의 자세를 포함하는 3844개의 훈련 그룹과 1758개의 테스트 그룹으로 구성됩니다. (2) COCO 키포인트 챌린지 데이터셋 [67], 이 데이터셋은 사람을 동시에 감지하고 각 사람의 17개의 키포인트(12개의 신체 부위와 5개의 얼굴 키포인트 포함)를 위치화해야 합니다. (3) COCO 키포인트 데이터셋에서 15,000개의 주석으로 구성된 발 데이터셋입니다. 이 데이터셋은 군중, 크기 변화, 가림, 접촉과 같은 현실적인 많은 도전 과제를 포함하는 다양한 시나리오에서 이미지를 수집합니다. 우리의 접근 방식은 첫 번째 COCO 2016 키포인트 챌린지 [70]에서 1위를 차지했으며, MPII 다인 벤치마크에서 이전 최첨단 결과를 크게 초과했습니다. 우리는 또한 시스템의 효율성을 정량화하고 주요 실패 사례를 분석하기 위해 Mask R-CNN 및 Alpha-Pose와의 실행 시간 분석 비교를 제공합니다.
5.1 Results on the MPII Multi-Person Dataset
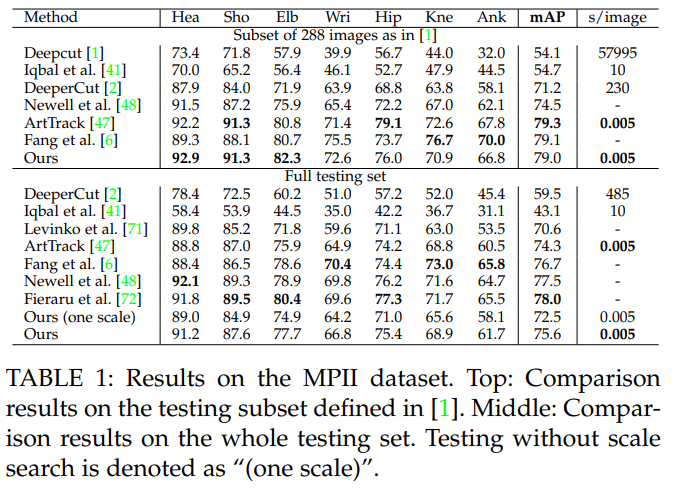
MPII 데이터셋과의 비교를 위해, 우리는 [66]에서 정의된 “PCKh” 메트릭을 사용하여 모든 신체 부위의 평균 정밀도(mAP)를 측정하기 위해 툴킷 [1]을 사용합니다. 표 1은 공식 MPII 테스트 세트에서 우리 방법과 다른 접근법 간의 mAP 성능을 비교합니다. 우리는 또한 이미지당 평균 추론/최적화 시간을 초 단위로 비교합니다. 288개의 이미지 하위 집합에서 우리의 방법은 이전 최첨단 바텀업 방법 [2]보다 8.5% 높은 mAP를 기록합니다. 놀랍게도, 우리의 추론 시간은 6자리 적습니다. 우리는 5.3장에서 더 자세한 실행 시간 분석을 보고합니다. 전체 MPII 테스트 세트에 대해, 스케일 검색 없이도 우리의 방법은 이전 최첨단 방법보다 큰 차이로 뛰어나며, mAP가 13% 절대적으로 증가합니다. 3단계 스케일 검색(×0.7, ×1 및 ×1.3)을 사용하면 성능이 75.6% mAP로 더욱 향상됩니다. 이전 바텀업 접근법과의 mAP 비교는 신체 부위를 연결하는 데 있어 우리의 새로운 특징 표현인 PAF의 효율성을 나타냅니다. 트리 구조를 기반으로, 우리의 그리디 파싱 방법은 완전히 연결된 그래프 구조를 기반으로 한 그래프컷 최적화 공식 [1], [2]보다 더 나은 정확도를 달성합니다.
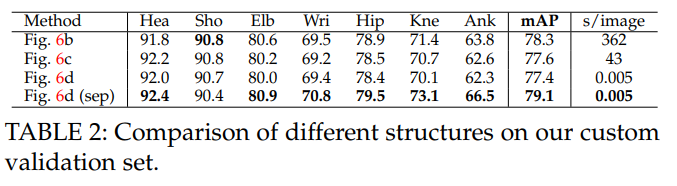
표 2에서는 그림 6에 표시된 서로 다른 스켈레톤 구조의 비교 결과를 보여줍니다. 우리는 원래 MPII 훈련 세트에서 343개의 이미지로 구성된 맞춤형 검증 세트를 만들었습니다. 우리는 완전히 연결된 그래프를 기반으로 모델을 훈련하고, 모든 엣지를 선택하여 결과를 비교합니다(그림 6b, 정수 선형 프로그래밍으로 대략 해결), 최소 트리 엣지(그림 6c, 정수 선형 프로그래밍으로 대략 해결), 그리고 그림 6d는 이 논문에서 제시된 그리디 알고리즘으로 해결되었습니다. 두 방법 모두 유사한 결과를 도출하며, 최소 엣지 사용으로 충분하다는 것을 입증합니다. 우리는 최종 모델을 최소 엣지만 학습하도록 훈련하여 네트워크 용량을 최대한 활용했습니다(그림 6d (sep)로 표시). 이 접근법은 효율성을 유지하면서도 그림 6c와 그림 6b보다 성능이 뛰어납니다. 필요한 부분 연결 채널 수가 적을수록(트리의 13개 엣지 대 그래프의 91개 엣지) 훈련 수렴이 촉진됩니다.
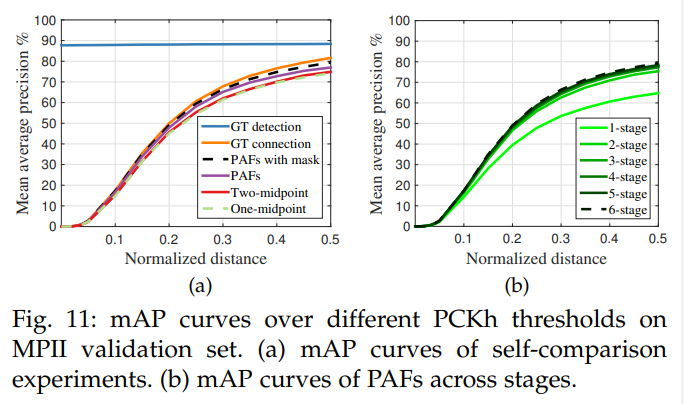
그림 11a는 검증 세트에서의 소거 분석을 보여줍니다. PCKh-0.5 [66] 임계값에서, 우리의 PAF 방법의 정확도는 한 중간점보다 2.9%, 두 중간점보다 2.3% 높으며, 일반적으로 중간점 표현 방법보다 더 뛰어납니다. 인체 사지의 위치와 방향 정보를 인코딩하는 PAF는 중첩된 팔과 같은 일반적인 교차 사례를 더 잘 구별할 수 있습니다. 라벨이 없는 사람의 마스크로 훈련하면 훈련 중 손실에서 진성 긍정 예측에 대한 페널티를 피하기 때문에 성능이 2.3% 더 향상됩니다. 우리의 파싱 알고리즘과 함께 실제 키포인트 위치를 사용하면 88.3%의 mAP를 얻을 수 있습니다. 그림 11a에서, GT 감지와 함께 파싱을 사용하여 얻은 mAP는 위치 오류가 없기 때문에 다양한 PCKh 임계값에 걸쳐 일정하게 유지됩니다. 우리의 키포인트 감지에 GT 연결을 사용하면 81.6%의 mAP를 달성합니다. 우리의 PAF 기반 파싱 알고리즘이 GT 연결을 기반으로 했을 때와 유사한 mAP(79.4% 대 81.6%)를 달성했다는 점은 주목할 만합니다. 이는 PAF 기반의 파싱이 올바른 부위 감지 연결에 있어 매우 강력함을 나타냅니다. 그림 11b는 단계별 성능 비교를 보여줍니다. mAP는 반복적인 개선 프레임워크와 함께 단조롭게 증가합니다. 그림 4는 단계별 예측의 질적 향상을 보여줍니다.
5.2 Results on the COCO Keypoints Challenge
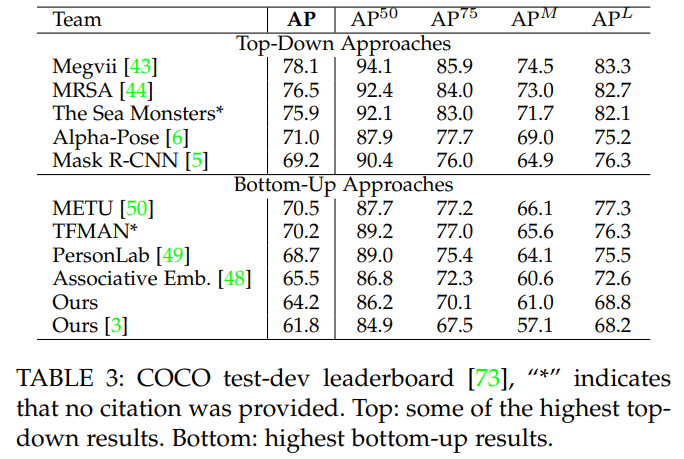
COCO 훈련 세트는 100K 이상의 사람 인스턴스가 100만 개 이상의 키포인트로 레이블링된 데이터를 포함합니다. 테스트 세트는 “test-challenge” 및 “test-dev” 하위 세트로 나뉘며, 각각 약 20K 이미지가 포함됩니다. COCO 평가는 객체 키포인트 유사성(OKS)을 정의하고, 주된 경쟁 지표로서 10개의 OKS 임계값에 대한 평균 정밀도(AP)를 사용합니다 [70]. OKS는 객체 감지에서 IoU와 동일한 역할을 합니다. 이는 사람의 크기와 예측된 키포인트와 실제 키포인트(GT) 사이의 거리를 기준으로 계산됩니다. 표 3은 챌린지에서 상위 팀의 결과를 보여줍니다. 특히 우리 방법은 높은 스케일($AP^L$)을 가진 사람들만을 고려할 때 정확도가 더 크게 떨어진다는 점이 주목할 만합니다.
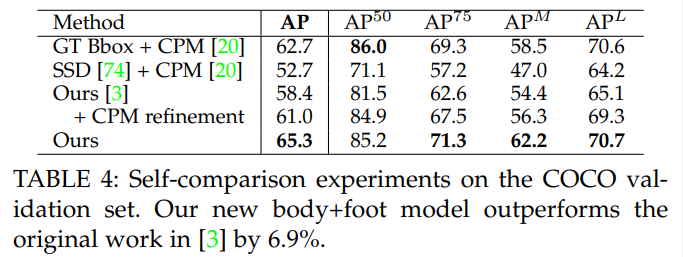
표 4에서, 우리는 COCO 검증 세트에서의 자기비교 결과를 보고합니다. GT 경계 상자와 단일 인물 CPM [20]을 사용하면, CPM을 사용하는 top-down 접근 방식의 상한을 62.7% AP로 달성할 수 있습니다. 최첨단 객체 탐지기인 Single Shot MultiBox Detector (SSD) [74]를 사용하면 성능이 10% 하락합니다. 이 비교는 top-down 접근 방식의 성능이 인물 탐지기에 크게 의존한다는 것을 보여줍니다. 반면에, 우리의 원래 bottom-up 방식은 58.4% AP를 달성합니다. 예상된 인물의 재조정된 각 영역에 단일 인물 CPM을 적용하여 결과를 세분화하면, 전체 AP가 2.6% 증가합니다. 우리는 두 방식이 대체로 일치하는 예측에 대해서만 추정값을 업데이트하여, 정밀도와 재현율을 개선합니다. CPM 세분화를 적용하지 않은 새로운 구조는 원래 방식보다 약 7% 더 정확하면서도 속도는 2배로 증가합니다.
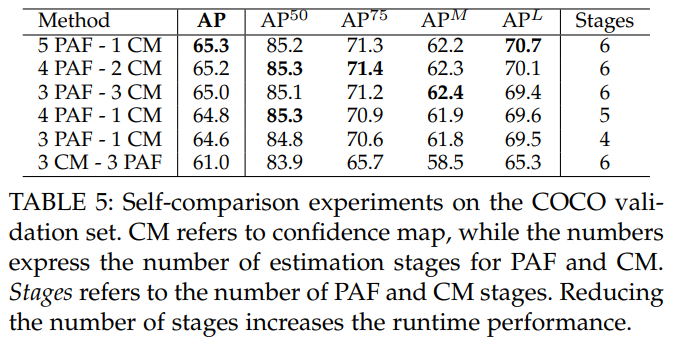
PAF 정제가 confidence map 추정에 미치는 영향을 표 5에서 분석합니다. 우리는 계산을 최대 6단계로 고정하고, PAF와 confidence map 분기에서 다르게 분배합니다. 이 실험에서 세 가지 결론을 도출할 수 있습니다. 첫째, PAF는 수렴하기 위해 더 많은 단계를 필요로 하며, 정제 단계에서 더 많은 이점을 얻습니다. 둘째, PAF 채널 수를 증가시키면 참 양성의 수가 주로 향상되지만, 이들이 항상 정확하지는 않습니다 (더 높은 $AP^{50}$). 반면에, confidence map 채널 수를 늘리면 위치 정확도가 더욱 향상됩니다 (더 높은 $AP^{75}$). 셋째, PAF를 사전 정보로 사용할 때 부위 confidence map의 정확도가 크게 향상된다는 것을 증명했으며, 반대로 사용하면 절대 정확도가 4% 감소합니다. 심지어 4단계만 있는 모델 (3 PAF - 1 CM)이 처음으로 confidence map을 예측하는 6단계 모델 (3 CM - 3 PAF)보다 더 정확합니다. 원래 모델 대비 새로운 모델의 정확도를 더욱 높인 추가 사항으로는 ReLU 대신 PReLU 레이어, 그리고 모멘텀을 사용하는 SGD 대신 Adam 최적화를 사용한 점이 있습니다. [3]과 달리, 우리는 속도 저하를 방지하기 위해 CPM [20]을 사용한 현재 접근 방식을 정제하지 않았습니다.
5.3 Inference Runtime Analysis
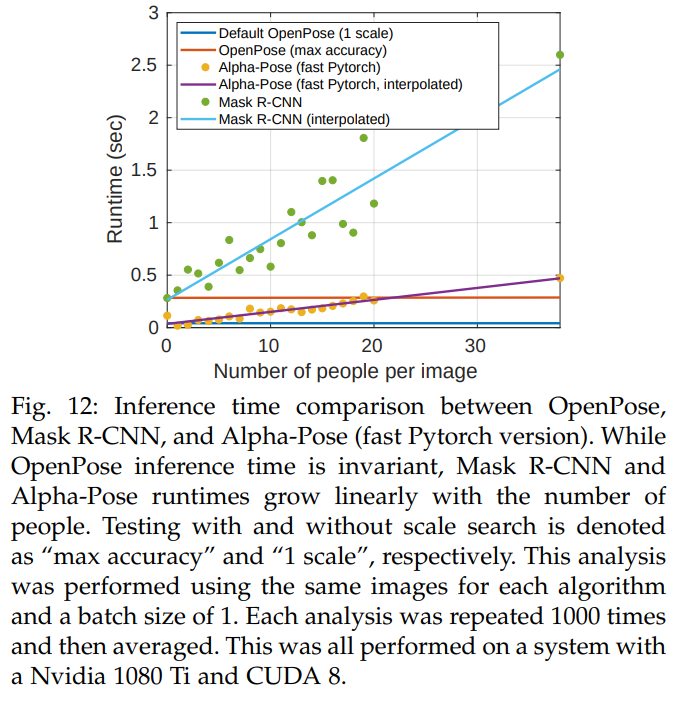
우리는 이 논문을 기반으로 한 OpenPose [4], Mask R-CNN [5], Alpha-Pose [6] 등 3가지 최신 멀티-사람 포즈 추정 라이브러리를 비교했습니다. 그림 12에서 이러한 방법들의 추론 런타임 성능을 분석했습니다. Megvii (Face++) [43]와 MSRA [44] GitHub 저장소는 그들이 사용하는 사람 감지기를 포함하지 않고, 잘린 사람에 대한 포즈 추정 결과만을 제공합니다. 따라서 우리는 이들의 정확한 런타임 성능을 알 수 없으므로 이 분석에서 제외되었습니다. Mask R-CNN은 Nvidia 그래픽 카드에서만 호환되므로, 우리는 NVIDIA 1080 Ti에서 분석을 수행했습니다. Mask R-CNN, Alpha-Pose, Megvii, MSRA 같은 상향식 접근 방식의 경우, 추론 시간은 이미지에 있는 사람 수에 비례합니다. 정확히는, 사람 감지기가 추출하는 후보 개수에 비례합니다. 반면, 우리의 하향식 접근법에서는 이미지 내 사람 수에 관계없이 추론 시간이 일정합니다. OpenPose의 런타임은 두 가지 주요 부분으로 구성됩니다: (1) 복잡도가 O(1)인 CNN 처리 시간, 즉 사람 수가 증가해도 일정한 처리 시간, (2) 복잡도가 O(n^2)인 멀티-사람 파싱 시간, 여기서 n은 사람 수를 나타냅니다. 하지만 파싱 시간은 CNN 처리 시간보다 두 자릿수 정도 짧습니다. 예를 들어, 9명에 대한 파싱 시간은 0.58ms인 반면, CNN 처리 시간은 36ms가 소요됩니다.
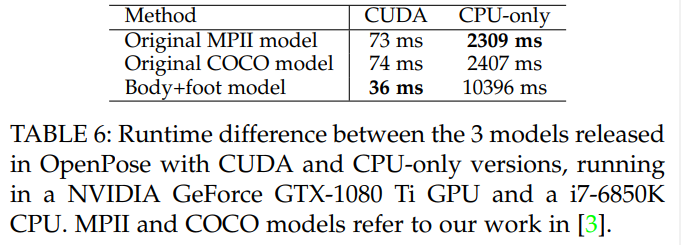
Table 6에서는 OpenPose에서 릴리스된 모델들 간의 추론 시간 차이를 분석한다. 즉, [3]에서의 MPII 및 COCO 모델과 새로운 신체+발 모델 간의 차이를 분석한다. 새롭게 결합된 모델은 더 정확할 뿐만 아니라 GPU 버전을 사용할 때 원래 모델보다 2배 더 빠르다. 흥미롭게도, CPU 버전의 실행 시간은 원래 모델보다 5배 느리다. 새로운 아키텍처는 더 많은 레이어로 구성되어 있어 더 많은 메모리를 필요로 하지만, 연산 횟수는 상당히 적다. 그래픽 카드는 연산 횟수 감소로 인해 더 큰 이점을 얻는 반면, CPU 버전은 더 많은 메모리 요구 사항 때문에 상당히 느리다. OpenCL과 CUDA의 성능은 직접 비교할 수 없다. 이는 각기 다른 하드웨어, 특히 서로 다른 GPU 브랜드가 필요하기 때문이다.
5.4 Trade-off between Speed and Accuracy
객체 탐지 분야에서 Huang 등 [75]은 지역 제안 방법(예: Faster-rcnn [76])이 더 높은 정확도를 달성하는 반면, 단일 샷 방식(예: YOLO [77], SSD [74])은 더 빠른 실행 성능을 제공한다는 것을 보여줍니다. 유사하게, 인간 포즈 추정에서도 top-down 방식이 bottom-up 방식에 비해 더 높은 정확도를 보이지만, 특히 여러 사람이 포함된 이미지에서는 속도가 떨어지는 경향이 있습니다. bottom-up 방식의 낮은 정확도의 주된 이유는 제한된 해상도 때문입니다. top-down 방식은 각각의 감지된 사람을 개별적으로 잘라내어 네트워크에 넣는 반면, bottom-up 방식은 한 번에 전체 이미지를 입력해야 하기 때문에 각 사람에 대한 해상도가 더 작아집니다. 예를 들어, Moon 등 [78]은 원본 연구 [3]에서 더 큰 이미지 패치를 적용하여 개선을 하면 다른 top-down 방식보다 더 큰 정확도 향상을 이끌어낸다는 것을 보여줍니다. 하드웨어가 더 빨라지고 메모리가 증가함에 따라, 더 높은 해상도를 사용하는 bottom-up 방식이 top-down 방식과의 정확도 차이를 줄일 수 있을 것입니다.
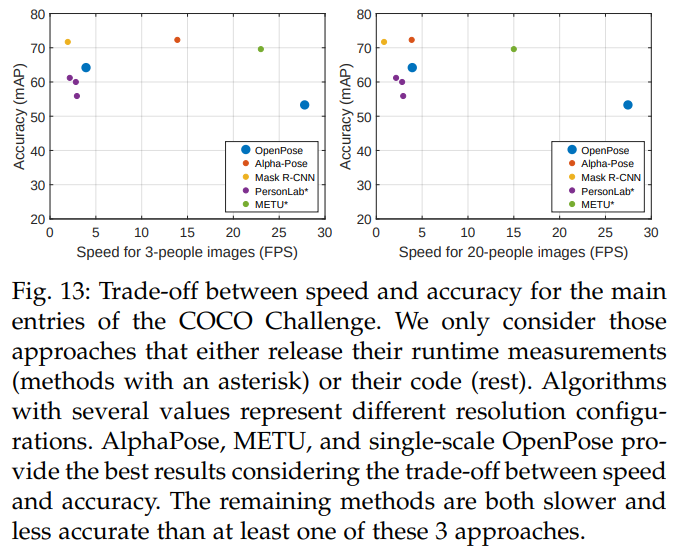
추가적으로, 현재의 인간 포즈 성능 측정치는 순수하게 키포인트 정확성에만 기반하며 속도는 무시됩니다. 보다 완전한 비교를 제공하기 위해, 우리는 그림 13에서 COCO 챌린지의 상위 항목들에 대한 속도와 정확성을 모두 표시합니다. 이 결과를 고려할 때, 최대 속도를 위해서는 단일 스케일 OpenPose를 선택해야 하고, 최대 정확성을 위해서는 AlphaPose를, 그리고 둘 사이의 균형을 위해서는 METU를 선택해야 합니다. 나머지 방법들은 이 세 가지 방법 중 적어도 하나보다 느리고 덜 정확합니다. 전반적으로, 상향식 접근법(예: AlphaPose)은 사람 수가 적은 이미지에서 더 나은 결과를 제공하지만, 사람 수가 많은 이미지에서는 속도가 상당히 떨어집니다. 또한, 정확도 측정치가 오해를 불러일으킬 수 있다는 점을 확인했습니다. 섹션 5.2에서 PersonLab [49]가 우리의 방법보다 더 높은 정확성을 달성했음을 확인할 수 있습니다. 그러나 우리의 다중 스케일 접근법은 그들이 런타임 결과를 보고한 버전들보다 더 높은 속도와 정확성을 동시에 제공합니다. 그들의 가장 정확하지만 더 느린 모델에 대해 [49]에서는 런타임 결과가 제공되지 않았음을 유의해야 합니다.
5.5 Results on the Foot Keypoint Dataset
발 키포인트 데이터셋에서 얻은 발 키포인트 검출 결과를 평가하기 위해, COCO 평가 지표에서 사용된 것처럼 10개의 OKS에서의 평균 정밀도와 재현율을 계산합니다. 결합된 방식과 바디 전용 방식 간에는 사소한 차이만 존재합니다. 결합된 학습 방식에서는 두 개의 분리되고 완전히 독립적인 데이터셋이 존재합니다. 두 데이터셋 중 더 큰 데이터셋은 바디 주석으로만 구성되어 있으며, 더 작은 데이터셋은 바디와 발 주석을 모두 포함하고 있습니다. 바디 전용 학습에 사용된 것과 동일한 배치 크기가 결합된 학습에도 사용됩니다. 그럼에도 불구하고, 한 번에 하나의 데이터셋에서만 주석을 포함합니다. 각 배치에서 어느 데이터셋을 선택할지 결정하는 확률 비율이 정의되어 있습니다. 주석 수와 다양성이 훨씬 더 높은 큰 데이터셋에서 배치를 선택할 확률이 더 높게 할당됩니다. 발 키포인트는 라벨이 없는 데이터로 인해 네트워크에 손상을 주지 않도록, 바디 전용 데이터셋의 역전파 단계에서 마스킹됩니다. 추가로, 발 데이터셋에서도 바디 주석이 마스킹됩니다. 이러한 주석들을 유지하면 정확도가 약간 하락할 수 있으며, 이는 동일한 샘플이 두 데이터셋에서 반복되기 때문에 발생할 가능성이 있습니다.

표 7은 우리 검증 세트에서의 발 키포인트 정확도를 보여줍니다. 이 검증 세트는 COCO 검증 세트의 부분 집합으로부터 생성되었으며, 특히 모든 사람의 발목이 보이고 주석이 달린 이미지로 구성됩니다. 이로 인해 COCO보다 더 단순한 검증 세트가 만들어졌으며, 신체 검출(표 4)과 비교했을 때 더 높은 정확도와 재현율을 보입니다. 질적으로 보면, 우리는 신체 키포인트 예측에 비해 더 많은 지터와 검출 오류를 발견합니다. 14,000개의 훈련 주석은 신체 키포인트 데이터셋에서 100,000개 이상의 인스턴스를 사용하는 것을 고려했을 때 견고한 발 검출기를 훈련시키기에는 충분한 숫자가 아니라고 생각합니다. 발 또는 신체 주석만 있는 전체 배치를 사용하는 대신, 두 데이터셋(COCO 또는 COCO+발)의 샘플이 같은 배치에 입력될 수 있는 혼합 배치를 사용해 보았습니다. 동일한 확률 비율을 유지하면서 말입니다. 그러나 네트워크 정확도는 약간 감소했습니다. 데이터셋을 불균형 비율로 혼합함으로써, 우리는 실질적으로 발에 대해 매우 작은 배치 크기를 할당했으며, 이는 발 수렴을 방해했습니다.
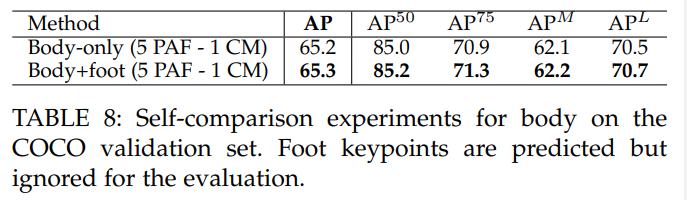
표 8에서 우리는 COCO 테스트-개발 세트에서 몸체 주석으로만 훈련된 동일한 네트워크 아키텍처와 비교했을 때 거의 정확도 차이가 없음을 보여줍니다. 우리는 5개의 PAF와 1개의 신뢰도 맵 단계를 포함하는 모델을 비교했으며, COCO 몸체 전용 데이터셋에서 배치를 선택할 확률이 95%, body+foot 데이터셋에서 선택할 확률이 5%였습니다. 발 CM과 PAFs를 포함하기 위한 출력 수 증가를 제외하고는 몸체 전용 모델과 비교했을 때 아키텍처 차이가 없습니다.
5.6 Vehicle Pose Estimation

우리의 접근 방식은 인간의 몸이나 발 키포인트에만 국한되지 않으며, 모든 키포인트 주석 작업에 일반화될 수 있습니다. 이를 입증하기 위해, 우리는 동일한 네트워크 구조를 차량 키포인트 감지 작업에 적용했습니다 [79]. 다시 한번, 우리는 평균 정밀도(mAP)를 10 OKS(객체 키포인트 유사성)를 통해 평가했습니다. 결과는 표 9에 나타나 있습니다. 평균 정밀도(AP)와 재현율(AR)은 몸 키포인트 작업보다 더 높게 나타나는데, 이는 우리가 더 작고 간단한 데이터셋을 사용했기 때문입니다. 이 초기 데이터셋은 19개의 서로 다른 카메라에서 얻은 이미지 주석으로 구성되어 있습니다. 첫 18개의 카메라 프레임은 훈련 세트로 사용되었으며, 마지막 카메라의 프레임은 검증 세트로 사용되었습니다. 모델 아키텍처나 훈련 파라미터에는 변화가 없었습니다. 우리는 그림 14에서 정성적 결과를 보여줍니다.

5.7 Failure Case Analysis

우리는 현재 접근 방식이 MPII, COCO, 그리고 COCO+발 검증 세트에서 실패하는 주요 사례를 분석했습니다. 그림 15에서는 주요 신체 실패 사례의 개요를 보여주고, 그림 16에서는 주요 발 실패 사례를 보여줍니다. 그림 15a는 비전형적인 자세와 거꾸로 된 예시를 나타내며, 이는 예측이 보통 실패하는 경우입니다. 회전 증강을 증가시키면 이러한 문제를 시각적으로 부분적으로 해결할 수 있지만, COCO 검증 세트에서의 전체 정확도는 약 5% 감소합니다. 또 다른 대안은 다양한 회전을 사용하여 네트워크를 실행하고 자신감이 높은 자세를 유지하는 것입니다. 신체 가림(occlusion)도 때때로 거짓 음성 및 높은 위치 오류를 초래할 수 있습니다. 이 문제는 데이터 세트 주석에서 상속된 문제로, 가려진 키포인트가 포함되지 않습니다. 사람들이 많이 겹치는 이미지에서는 서로 다른 사람들의 주석이 합쳐지는 경향이 있으며, 다른 주석은 탐욕적인 다중 인물 파싱을 실패하게 만드는 겹치는 PAF 때문에 누락됩니다. 동물과 동상도 자주 잘못된 긍정 오류를 초래합니다. 이 문제는 훈련 중에 더 많은 부정적인 예시를 추가하여 네트워크가 인간과 기타 인간형 피사체를 구별하는 데 도움이 되도록 완화할 수 있습니다.
6 CONCLUSION
실시간 다중 인물 2D 포즈 추정은 기계가 시각적으로 인간과 그 상호작용을 이해하고 해석할 수 있게 하는 중요한 요소입니다. 이 논문에서 우리는 인간 사지의 위치와 방향을 모두 인코딩하는 키포인트 연결의 명시적인 비모수 표현을 제시합니다. 두 번째로, 우리는 부품 감지와 연결을 동시에 학습하는 아키텍처를 설계했습니다. 세 번째로, 탐욕적 분석 알고리즘이 신체 포즈의 고품질 해석을 생성하는 데 충분하며, 사람 수와 관계없이 효율성을 유지한다는 것을 입증합니다. 네 번째로, 우리는 PAF(Pose Affinity Field) 정제가 PAF와 신체 부위 위치 정제를 결합하는 것보다 훨씬 더 중요하다는 것을 입증했으며, 이는 실행 시간 성능과 정확도 모두에서 상당한 향상을 가져옵니다. 다섯 번째로, 우리는 신체와 발 추정을 단일 모델로 결합함으로써 각 구성 요소의 정확도를 개별적으로 향상시키고, 이를 순차적으로 실행하는 대신 추론 시간을 줄일 수 있음을 보여줍니다. 우리는 15K 발 키포인트 인스턴스로 구성된 발 키포인트 데이터셋을 생성했으며, 이를 공개할 예정입니다. 마지막으로, 우리는 신체, 발, 손, 얼굴 키포인트 감지를 위한 최초의 실시간 다중 인물 시스템인 OpenPose [4]를 오픈 소스로 공개했습니다. 이 라이브러리는 오늘날 인간 재식별, 리타겟팅, 인간-컴퓨터 상호작용과 같은 여러 연구 주제에 널리 사용되고 있습니다. 또한 OpenPose는 OpenCV 라이브러리 [65]에 포함되었습니다.
ACKNOWLEDGMENTS
우리는 MPII 및 COCO 인간 포즈 데이터셋의 저자들의 노고에 감사를 표합니다. 이 데이터셋은 자연 환경에서의 2D 인간 포즈 추정을 가능하게 합니다. 이 연구는 정보고급연구계획국(IARPA)과 DOI/IBC의 계약 번호 D17PC00340에 의해 지원되었습니다.
Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, Yaser Sheikh OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields

댓글남기기