

개요
RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose 논문의 얕은 리뷰. 해당 논문은 2023년에 arXiv에 올라왔으며, ICLR 2024에 제출되었으나 reject 된 것으로 확인된다.
본 논문은 CSPNeXt 를 백본으로 사용하는 RTMPose 아키텍쳐를 제안한다. SimCC 기반의 개량된 헤드를 붙여 연산 효율성을 챙기며 추가적인 학습 테크닉을 통해 고사양이 아닌 하드웨어에서도 높은 정확도와 빠른 연산 속도를 제공한다.
방법론
- SimCC 헤드를 더 가볍게 개량 시킨 헤드를 사용한다. 또한 가우시안 분포의 라벨 스무딩을 적용한 소프트 레이블오 대체하여 성능향상을 가져옴을 확인한다.
- 백본에 대한 사전학습을 위해 히트맵 기반의 UDP 방법을 채택한 상황에서 백본을 우선 학습 시킨다.
- EMA을 사용한 최적화 전략을 채택 및 플랫 코사인 애닐링 전략은 과적합을 줄이고 정확도를 향상 시킨다.
- 데이터 증강을 학습 에폭에 따라 다르게 선택하여 학습의 강도를 강함에서 후에 약해지도록 조절한다. 이는 과적합을 방지하고 전체적인 포즈의 구조 정보를 학습하는 효과를 가져온다.
- GAU(Gated Attention Unit)은 전역 및 지역적 공간 정보를 잘 활용하며 연산량을 줄이면서도 더 높은 성능을 제공한다.
- COCO와 AIC 데이터 셋을 결합하여 학습을 하여 더 높은 성능을 달성한다.
실험
- COCO 데이터 셋을 벤치마크로 활용하기 위해 YOLOv3, Faster-RCNN, RTMDet 등의 디텍터를 앞 단에 활용하며 PaddleDetection, AlphaPose 등의 비교군을 압도적으로 능가한다.
- 또한 경량 상황에서 활용되는 MediaPipe, MoveNet, PaddleDetection를 비교군으로 할 때에도 RTMPose 가 뛰어난 성능과 효율성을 달성함을 보여준다.
- COCO-WholeBody, MPII, AP-10K, CrowdPose 데이터 셋에 대해서도 비교군(DeepPose, SimpleBaseline, HRNet, TokenPose, SimCC 등)ㅇ에 비해 높은 성능을 달성함을 알 수 있다.
- 모바일 환경 및 CPU 환경에서 비교군인 TinyPose, LiteHRNet에 비해 압도적인 빠른 연산 속도를 보여줌을 알 수 있다.
결론
본 논문은 RTMPose 라는 아키텍쳐를 제안하며 이는 정확도와 효율성을 동시에 충족하여 산업 환경에서의 실시간 자세 추정 테스크를 다루기에 좋은 방안을 제시한다. 기존 SimCC 헤드를 좀 더 경량화하면서 여러 학습 테크닉들을 붙여 점진적으로 베이스 모델로 부터 성능이 올라가는 과정을 상세히 보여준다.
번역
Abstract
최근 2D 포즈 추정 연구는 공개 벤치마크에서 뛰어난 성능을 달성했지만, 산업계에서의 적용은 여전히 무거운 모델 파라미터와 높은 지연으로 인해 어려움을 겪고 있다. 이 격차를 해소하기 위해 우리는 파라다임, 모델 아키텍처, 학습 전략, 배포를 포함한 포즈 추정의 주요 요소를 실험적으로 탐구하고, MMPose에 기반한 고성능 실시간 다중 인물 포즈 추정 프레임워크인 RTMPose를 제시한다. 우리의 RTMPose-m은 Intel i7-11700 CPU에서 90 FPS 이상, NVIDIA GTX 1660 Ti GPU에서 430 FPS 이상의 속도로 COCO에서 75.8%의 AP를 달성하고, RTMPose-x는 COCO-WholeBody에서 65.3%의 AP를 달성한다. RTMPose의 중요한 실시간 애플리케이션에서의 성능을 평가하기 위해, 모바일 장치에 배포한 후의 성능도 보고한다. 우리의 RTMPose-s 모델은 Snapdragon 865 칩에서 70 FPS 이상의 속도로 COCO에서 72.2%의 AP를 달성하며 기존 오픈소스 라이브러리를 능가한다. 우리의 코드와 모델은 https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose 에서 확인할 수 있다.
1 Introduction
실시간 인간 포즈 추정은 인간-컴퓨터 상호작용, 행동 인식, 스포츠 분석, 그리고 VTuber 기술과 같은 다양한 애플리케이션에 매력적이다. 학문적 벤치마크 [52, 61]에서 놀라운 진전을 이루었음에도 불구하고, 제한된 컴퓨팅 성능을 가진 장치에서 견고하고 실시간으로 다중 인물 포즈 추정을 수행하는 것은 여전히 도전적인 과제이다. 최근의 시도는 효율적인 네트워크 아키텍처 [3, 56, 63]와 비탐지형 패러다임 [19, 29, 51]을 통해 격차를 줄이고 있지만, 여전히 산업 애플리케이션에서 만족스러운 성능에 도달하기에는 부족하다.
본 연구에서는 2D 다중 인물 포즈 추정 프레임워크의 성능과 지연에 영향을 미치는 주요 요소를 패러다임, 백본 네트워크, 위치 결정 방법, 학습 전략, 배포의 다섯 가지 측면에서 실험적으로 연구한다. 최적화 집합을 통해 우리는 포즈 추정을 위한 새로운 실시간 모델 시리즈인 RTMPose를 소개한다.
먼저, RTMPose는 기성 탐지기를 사용하여 바운딩 박스를 얻고 각 개인의 포즈를 개별적으로 추정하는 상향식 접근 방식을 채택한다. 상향식 알고리즘은 추가적인 탐지 과정과 군중 장면에서의 증가하는 작업량 때문에 정확하지만 느리다는 고정관념이 있다. 그러나 실시간 탐지기의 뛰어난 효율성 [42, 46] 덕분에 탐지 부분은 더 이상 상향식 방법의 추론 속도의 병목이 아니다. 대부분의 시나리오(이미지당 6명 이하)에서 제안된 경량 포즈 추정 네트워크는 모든 인스턴스에 대해 실시간으로 다중 순방향 패스를 수행할 수 있다.
두 번째로, RTMPose는 CSPNeXt [42]를 백본으로 채택했으며, 이는 처음에 객체 탐지를 위해 설계되었다. 이미지 분류를 위해 설계된 백본 [20, 49]은 객체 탐지, 포즈 추정 및 의미적 분할과 같은 밀집 예측 작업에 최적화되어 있지 않다. 고해상도 피처 맵을 활용한 일부 백본 [52, 63]이나 고급 트랜스포머 아키텍처 [15]는 공개 포즈 추정 벤치마크에서 높은 정확도를 달성하지만, 높은 계산 비용, 높은 추론 지연 또는 배포의 어려움을 겪는다. CSPNeXt는 속도와 정확도의 균형이 잘 잡혀 있고 배포 친화적이다.
세 번째로, RTMPose는 키포인트 위치 결정을 분류 작업으로 취급하는 SimCC 기반 [35] 알고리즘을 사용하여 키포인트를 예측한다. 히트맵 기반 알고리즘 [24, 59, 61, 65]과 비교하여, SimCC 기반 알고리즘은 더 낮은 계산 노력으로 경쟁력 있는 정확도를 달성한다. 또한, SimCC는 예측을 위한 두 개의 완전 연결 층으로 구성된 매우 간단한 아키텍처를 사용하여 다양한 백엔드에 쉽게 배포할 수 있다.
네 번째로, 우리는 이전 연구 [3, 30, 42]의 학습 설정을 재검토하고, 포즈 추정 작업에 적용할 수 있는 학습 전략 모음을 실험적으로 소개한다. 우리의 실험 결과, 이러한 전략 모음이 제안된 RTMPose 및 다른 포즈 추정 모델에 상당한 성능 향상을 가져온다는 것을 보여준다.
마지막으로, 우리는 포즈 추정 프레임워크의 추론 파이프라인을 공동으로 최적화한다. 우리는 지연 시간을 줄이고 포즈 비최대 억제(NMS)와 매끄러운 필터링을 통해 포즈 처리를 개선하기 위해 [3]에서 제안된 프레임 건너뛰기 탐지 전략을 사용한다. 또한, 우리는 최적의 성능-속도 절충으로 다양한 애플리케이션 시나리오를 다룰 수 있는 t/s/m/l/x 크기의 RTMPose 모델 시리즈를 제공한다.
우리는 RTMPose를 다양한 추론 프레임워크(PyTorch, ONNX Runtime, TensorRT, ncnn)와 하드웨어(i7-11700, GTX1660Ti, Snapdragon865)에서 배포하여 효율성을 테스트한다.

그림 1에 표시된 바와 같이, 우리는 다양한 추론 프레임워크(PyTorch, ONNX Runtime, TensorRT, ncnn)와 하드웨어(Intel i7-11700, GTX 1660 Ti, Snapdragon 865)를 사용하여 RTMPose의 효율성을 평가한다. 우리의 RTMPose-m은 COCO 검증 세트에서 Intel i7-11700 CPU에서 90+ FPS, NVIDIA GeForce GTX 1660 Ti GPU에서 430+ FPS, Snapdragon 865 칩에서 35+ FPS로 75.8% AP(플리핑 포함)를 달성한다. 우리의 포즈 추정 파이프라인에서 고성능 실시간 객체 탐지 모델인 RTMDet-nano를 사용하여 RTMPose-m은 73.2% AP를 달성할 수 있다. MMDeploy [12]의 도움으로, RTMPose는 RKNN, OpenVINO, PPLNN 등 다양한 백엔드에 쉽게 배포될 수 있다.
2. Related Work
Bottom-up Approaches.
상향식 알고리즘 [7, 10, 19, 27, 29, 41, 44, 45]은 이미지에서 인스턴스에 구애받지 않는 키포인트를 감지하고 이러한 키포인트를 분할하여 인간의 포즈를 얻는다. 상향식 패러다임은 사람 수가 증가하더라도 안정적인 계산 비용 덕분에 군중 상황에 적합한 것으로 간주된다. 그러나 이러한 알고리즘은 종종 다양한 사람 크기를 처리하기 위해 큰 입력 해상도를 요구하여 정확성과 추론 속도를 조화시키는 것이 어렵다.
Top-down Approaches.
하향식 알고리즘은 기성 탐지기를 사용하여 바운딩 박스를 제공하고, 포즈 추정을 위해 사람을 일정한 비율로 자른다. 하향식 패러다임의 알고리즘 [5, 38, 52, 59, 61]은 공공 벤치마크를 지배해왔다. 2단계 추론 패러다임은 사람 탐지기와 포즈 추정기가 상대적으로 작은 입력 해상도를 사용할 수 있게 하여 비극단적인 시나리오(즉, 이미지의 사람 수가 6명 이하인 경우)에서 상향식 알고리즘보다 속도와 정확도 면에서 우수하도록 한다. 또한, 대부분의 이전 연구는 공공 데이터셋에서 최첨단 성능을 달성하는 데 초점을 맞췄지만, 우리의 연구는 산업 애플리케이션의 요구를 충족하기 위해 더 나은 속도-정확도 균형을 갖춘 모델을 설계하는 것을 목표로 한다.
Coordinate Classification.
이전 포즈 추정 접근법은 일반적으로 키포인트 위치 결정을 좌표 회귀(예: [30, 43, 54]) 또는 히트맵 회귀(예: [25, 59, 61, 65])로 간주한다. SimCC [35]는 각각 수평 및 수직 좌표의 서브 픽셀 빈에서 키포인트 예측을 분류로 구성하는 새로운 체계를 도입하여 여러 가지 장점을 제공한다. 첫째, SimCC는 고해상도 히트맵에 대한 의존성을 벗어나므로 고해상도 중간 표현 [52]이나 비용이 많이 드는 업스케일링 계층 [59]이 필요 없는 매우 컴팩트한 아키텍처를 허용한다. 둘째, SimCC는 전역 풀링 [54]을 포함하는 대신 분류를 위해 최종 특징 맵을 평탄화하여 공간 정보 손실을 피한다. 셋째, 추가적인 정제 후처리가 필요 없이 서브 픽셀 수준에서 좌표 분류를 통해 양자화 오류를 효과적으로 완화할 수 있다 [65]. 이러한 특성은 SimCC를 경량 포즈 추정 모델을 구축하는 데 매력적으로 만든다. 본 연구에서는 모델 아키텍처와 학습 전략의 최적화를 통해 좌표 분류 체계를 더욱 활용한다.
Vision Transformers.
현대 자연어 처리(NLP)에서 이식된 트랜스포머 기반 아키텍처 [55]는 표현 학습 [15, 39], 객체 탐지 [8, 34, 67], 의미적 분할 [66], 비디오 이해 [4, 17, 40], 그리고 포즈 추정 [36, 43, 51, 61, 62] 등 다양한 비전 작업에서 큰 성공을 거두었다. ViTPose [61]는 최첨단 트랜스포머 백본을 활용하여 포즈 추정 정확도를 높이며, TransPose [62]는 트랜스포머 인코더를 CNN과 통합하여 장거리 공간적 관계를 효율적으로 캡처한다. 토큰 기반 키포인트 임베딩은 시각적 단서 쿼리 및 해부학적 제약 학습을 통합하여 히트맵 기반 [36] 및 회귀 기반 [43] 접근 방식 모두에서 효과적으로 작용한다. PRTR [33]과 PETR [51]은 탐지 분야의 선구자 [8]에서 영감을 받아 트랜스포머를 이용한 엔드투엔드 다중 인물 포즈 추정 프레임워크를 제안한다. 이전 트랜스포머 기반 포즈 추정 접근법은 히트맵 기반 표현을 사용하거나 픽셀 토큰과 키포인트 토큰을 모두 유지하여 높은 계산 비용을 초래하고 실시간 추론이 어려웠다. 반면, 우리는 컴팩트한 SimCC 기반 표현과 자기 어텐션 메커니즘을 통합하여 키포인트 의존성을 포착하며, 이를 통해 계산 부담을 크게 줄이고 고급 정확도와 효율성으로 실시간 추론을 가능하게 한다.
3. Methodology

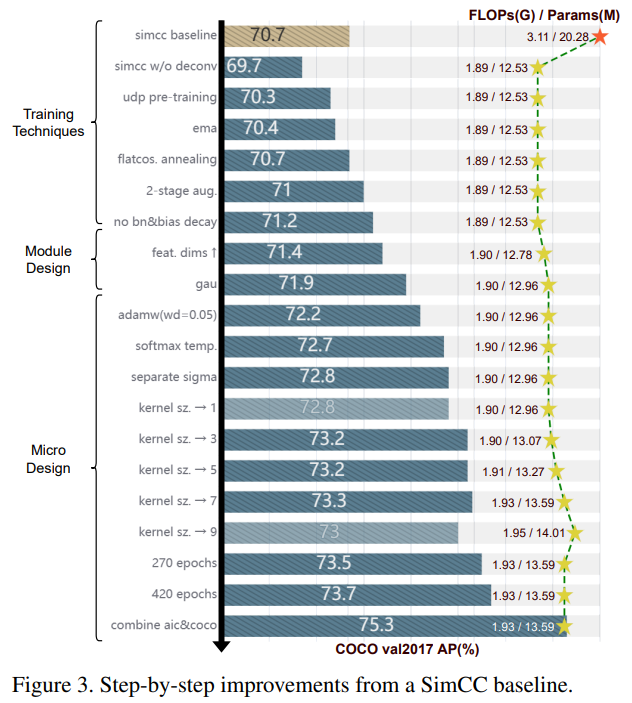
본 절에서는 좌표 분류 패러다임을 따르며 RTMPose를 구축하는 로드맵을 설명한다. 우리는 더 효율적인 백본 아키텍처로 SimCC [35]를 리핏하여 가벼우면서도 강력한 베이스라인을 설정한다 (3.1). 우리는 포즈 추정 작업에서 더 효과적으로 만들기 위해 [42]에서 제안된 학습 전략을 약간 수정하여 채택한다. 모델 성능은 일련의 정교한 모듈(3.3)과 미세한 디자인(3.4)을 통해 더욱 향상된다. 마지막으로, 더 높은 속도와 안정성을 위해 전체 하향식(top-down) 추론 파이프라인을 공동으로 최적화한다. 최종 모델 아키텍처는 그림 2에, 그림 3은 로드맵의 단계별 개선 사항을 보여준다.
3.1. SimCC: A lightweight yet strong baseline
Preliminary
SimCC [35]는 키포인트 위치 결정을 분류 문제로 공식화한다. 핵심 아이디어는 수평 및 수직 축을 동일한 너비의 번호가 매겨진 빈으로 나누고, 연속적인 좌표를 정수형 빈 레이블로 이산화하는 것이다. 그런 다음 모델은 키포인트가 위치한 빈을 예측하도록 학습된다. 많은 빈을 사용하여 양자화 오류를 서브픽셀 수준으로 줄일 수 있다.
이 새로운 공식화 덕분에 SimCC는 백본에서 추출된 특징을 벡터화된 키포인트 표현으로 변환하는 1 × 1 컨볼루션 층과 각각 분류를 수행하는 두 개의 완전 연결 층을 사용하는 매우 간단한 구조를 가지고 있다.
전통적인 분류 작업의 레이블 스무딩 [53]에 영감을 받아, SimCC는 가우시안 레이블 스무딩 전략을 제안하여 원핫 레이블을 실제 빈을 중심으로 하는 가우시안 분포 소프트 레이블로 대체하며, 이는 모델 학습에 귀납적 편향을 통합하고 성능 향상을 가져온다. 우리는 이 기법이 순서 회귀 작업의 SORD [16] 개념과도 일치함을 발견한다. 소프트 레이블은 레이블 분포에 의해 정의된 클래스 간 패널티 거리에 따라 키포인트 위치의 순위 가능성을 자연스럽게 포함한다.
Baseline
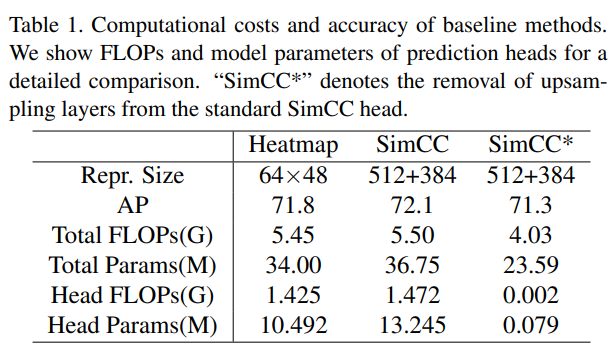
우리는 먼저 표준 SimCC에서 비용이 많이 드는 업샘플링 층을 제거한다. 표 1의 결과는 간소화된 SimCC가 SimCC 및 히트맵 기반 베이스라인 [59]에 비해 상당히 낮은 복잡성을 가지며, 여전히 유망한 정확도를 달성함을 보여준다. 이는 위치 결정 작업에서 전역 공간 정보를 1차원 표현으로 분리하여 효율적으로 인코딩하는 것을 나타낸다. ResNet-50 [21] 백본을 더 컴팩트한 CSPNext-m [42]로 대체하여 모델 크기를 줄이고 가벼우면서도 강력한 베이스라인인 69.7% AP를 얻는다.
3.2. Training Techniques
Pre-training
이전 연구 [3, 30]는 히트맵 기반 방법을 사용하여 백본을 사전 학습하면 모델 정확도가 향상될 수 있음을 보여준다. 우리는 백본 사전 학습을 위해 UDP [24] 방법을 채택한다. 이를 통해 모델이 69.7% AP에서 70.3% AP로 향상된다. 우리는 이 기법을 다음 섹션의 기본 설정으로 사용한다.
Optimization Strategy
우리는 [42]의 최적화 전략을 채택한다. 지수 이동 평균(EMA)을 사용하여 과적합을 완화(70.3%에서 70.4%로)하고, 평탄한 코사인 애닐링 전략을 통해 정확도를 70.7% AP로 향상시킨다. 우리는 또한 정규화 층과 바이어스에 대한 가중치 감소를 억제한다.
Two-stage training augmentations
[42]의 학습 전략을 따르며, 우리는 강한-약한 2단계 증강을 사용한다. 먼저 강한 데이터 증강을 사용하여 180 에포크 동안 학습하고, 이후 30 에포크 동안 약한 전략을 사용한다. 강한 단계에서는 0.6에서 1.4의 큰 무작위 스케일링 범위와 80의 큰 무작위 회전 인자를 사용하고, Cutout [14] 확률을 1로 설정한다. AID [26]에 따르면, Cutout은 모델이 이미지 텍스처에 과적합되는 것을 방지하고 포즈 구조 정보를 학습하도록 촉진한다. 약한 전략 단계에서는 무작위 이동을 끄고, 작은 무작위 회전 범위를 사용하며, Cutout 확률을 0.5로 설정하여 모델이 실제 이미지 분포에 더 가깝게 맞춰 세밀하게 조정할 수 있게 한다.
3.3. Module Design
Feature dimension
우리는 모델 성능이 높은 특징 해상도와 함께 증가하는 것을 관찰한다. 따라서 우리는 1D 키포인트 표현을 하이퍼파라미터에 의해 제어되는 원하는 차원으로 확장하기 위해 완전 연결 층을 사용한다. 본 연구에서는 256 차원을 사용하여 정확도가 71.2% AP에서 71.4% AP로 향상되었다.
Self-attention module
전역 및 지역 공간 정보를 더 잘 활용하기 위해 우리는 [36, 62]에서 영감을 받아 자기 어텐션 모듈을 사용하여 키포인트 표현을 정제한다. 우리는 기본 트랜스포머 [55]보다 더 빠른 속도, 낮은 메모리 비용, 더 나은 성능을 제공하는 트랜스포머 변형인 게이트드 어텐션 유닛(GAU) [23]을 채택한다. 구체적으로, GAU는 트랜스포머 층의 피드포워드 네트워크(FFN)를 게이트드 선형 유닛(GLU) [50]로 개선하고, 우아한 형태로 어텐션 메커니즘을 통합한다:
\[\begin{equation}\begin{aligned} U &= \phi_u(XW_u) \\ V &= \phi_u(XW_u) \\ O &= (U \odot AV)W_o \end{aligned}\end{equation}\]여기서 $⊙$ 는 쌍별 곱셈(Hadamard 곱)이고, $ϕ$ 는 활성화 함수이다. 본 연구에서는 다음과 같이 자기 어텐션을 구현한다:
\[\begin{equation} A=\frac{1}{n}relu^2(\frac{Q(X)K(Z)^T}{\sqrt{s}}), Z=\phi_z(XW_z) \end{equation}\]여기서 $s=128$, $Q$ 및 $K$ 는 단순한 선형 변환이며, $relu^2(⋅)$ 는 ReLU에 제곱한 것이다. 이 자기 어텐션 모듈은 모델 성능을 0.5% AP(71.9%) 향상시킨다.
3.4. Micro Design
Loss function
우리는 좌표 분류를 순서 회귀 작업으로 처리하고, SORD [16]에서 제안한 소프트 레이블 인코딩을 따른다:
\[\begin{equation} y_i = \frac{e^{\phi(r_t,r_i)}}{\sum_{k=1}^K{e^{\phi(r_t,r_k)}}} \end{equation}\]여기서 $ϕ(r_t,r_i)$ 는 $r_t$ 의 실제 측정값이 순위 $r_i∈Y$에서 얼마나 먼지를 패널티하는 측정 손실 함수이다. 본 연구에서는 클래스 간 거리 측정으로 비정규화된 가우시안 분포를 채택한다:
\[\begin{equation} \phi(r_t, r_i)=e^{\frac{-(r_t-r_i)^2}{2\sigma^2}} \end{equation}\]식 3은 모든 $ϕ(r_t,r_i)$ 에 대해 소프트맥스를 계산하는 것으로 볼 수 있다. 우리는 모델 출력과 소프트 레이블 모두에 소프트맥스 연산에서 온도를 추가하여 정규화된 분포 모양을 더욱 조정한다:
\[\begin{equation} y_i = \frac{e^{\phi(r_t,r_i)/\tau}}{\sum_{k=1}^K{e^{\phi(r_t,r_i)/\tau}}} \end{equation}\]실험 결과에 따르면, $τ=0.1$ 을 사용하면 성능이 71.9%에서 72.7%로 향상된다.
Separate $\sigma$
SimCC에서는 수평 및 수직 레이블이 동일한 $σ$ 를 사용하여 인코딩된다. 우리는 이에 대한 별도의 $σ$ 를 설정하는 간단한 전략을 실험적으로 탐구한다:
\[\begin{equation} \sigma = \sqrt{\frac{W_S}{16}} \end{equation}\]여기서 $W_S$ 는 각각 수평 및 수직 방향의 빈 수이다. 이 단계는 정확도를 72.7%에서 72.8%로 향상시킨다.
Larger convolution kernel
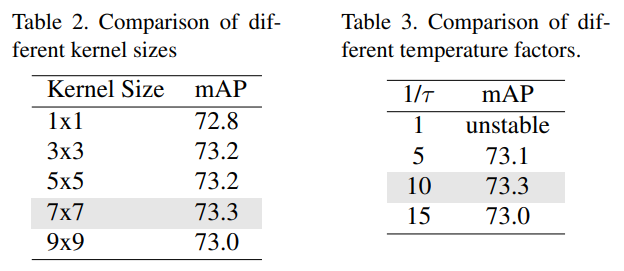
우리는 마지막 컨볼루션 층의 다양한 커널 크기를 실험한 결과, $1 × 1$ 커널을 사용하는 것보다 더 큰 커널 크기를 사용할 때 성능이 향상됨을 발견했다. 최종적으로 $7 × 7$ 컨볼루션 층을 선택했으며, 73.3% AP를 달성했다. 표 2에서 서로 다른 커널 크기를 사용한 모델 성능을 비교한다. 또한, 표 3에서는 최종 모델 아키텍처를 사용하여 서로 다른 온도 요인의 효과를 비교한다.
More epochs and multi-dataset training
학습 에포크를 늘리면 모델 성능에 추가적인 향상이 생긴다. 구체적으로, 270 및 420 에포크 학습은 각각 73.5% AP와 73.7% AP를 달성한다. 모델의 잠재력을 더 활용하기 위해, COCO [37]와 AI 챌린저 [58] 데이터셋을 결합하여 균형 잡힌 샘플링 비율로 사전 학습과 미세 조정을 수행한다. 최종 성능은 75.3% AP에 도달한다.
3.5. Inference pipeline

포즈 추정 모델을 넘어서, 우리는 더 낮은 지연 시간과 더 나은 견고성을 위해 전체 상향식 추론 파이프라인을 최적화한다. 우리는 BlazePose [3]에서와 같이 프레임 건너뛰기 탐지 메커니즘을 사용하여 K 프레임마다 사람 탐지를 수행하고, 간격 프레임에서는 이전 포즈 추정 결과에서 바운딩 박스를 생성한다. 추가적으로, 프레임 간 매끄러운 예측을 달성하기 위해 후처리 단계에서 OKS 기반 포즈 NMS 및 OneEuro [9] 필터를 사용한다.
4. Experiments
4.1. Settings
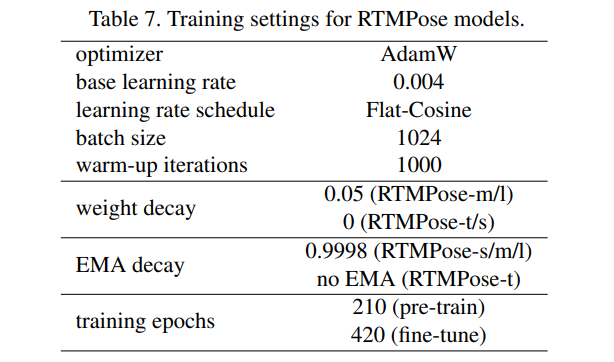
본 실험에서의 학습 설정은 표 7에 나와 있다. 섹션 3.2에서 설명한 바와 같이, 우리는 동일한 학습 전략을 따르는 히트맵 기반의 사전 학습 [24]을 수행하되, 에포크 수는 더 짧게 설정한다. 모든 모델은 8개의 NVIDIA A100 GPU에서 학습되며, 모델 성능은 평균 정밀도(AP)로 평가한다.
4.2. Benchmark Results
COCO

COCO [37]는 2D 신체 포즈 추정을 위한 가장 인기 있는 벤치마크이다. 우리는 train2017과 val2017의 표준 분할을 따르며, 각각 118K와 5K의 이미지를 학습과 검증에 사용한다. 우리는 YOLOv3 [47], Faster-RCNN [48], RTMDet [42]을 포함한 다양한 기성 탐지기를 사용하여 포즈 추정 성능을 광범위하게 연구한다. 추가 학습 데이터를 사용하지 않는 AlphaPose [18]와 공정한 비교를 위해, COCO로만 학습한 RTMPose의 성능도 보고한다. 표 4에 나타난 바와 같이, RTMPose는 훨씬 낮은 복잡도로 경쟁자를 큰 차이로 능가하며, 탐지에서 강력한 견고성을 보여준다.
COCO-SinglePerson
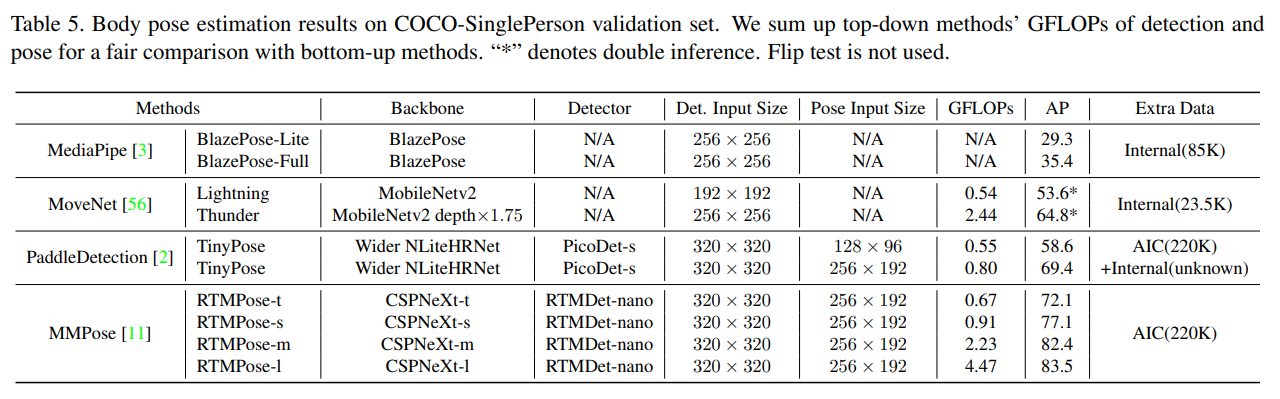
BlazePose [3], MoveNet [56], PaddleDetection [2]과 같은 인기 있는 포즈 추정 오픈 소스 알고리즘은 주로 단일 인물 또는 희소한 시나리오를 위해 설계되어 있으며, 이는 모바일 애플리케이션과 인간-기계 상호작용에 실용적이다. 공정한 비교를 위해 우리는 COCO val2017 세트에서 1045개의 단일 인물 이미지를 포함하는 COCO-SinglePerson 데이터셋을 구축하여 RTMPose와 다른 접근 방식을 평가한다. MoveNet의 경우, 첫 번째 추론의 대략적인 포즈 예측을 사용하여 입력 이미지를 자르고, 더 나은 포즈 추정 결과를 위해 두 번째 추론을 수행하는 크롭 알고리즘을 적용하는 공식 추론 파이프라인을 따른다. 표 5의 평가 결과는 RTMPose가 단일 인물 시나리오에 맞춰진 이전 솔루션보다도 뛰어난 성능과 효율성을 달성했음을 보여준다.
COCO-WholeBody
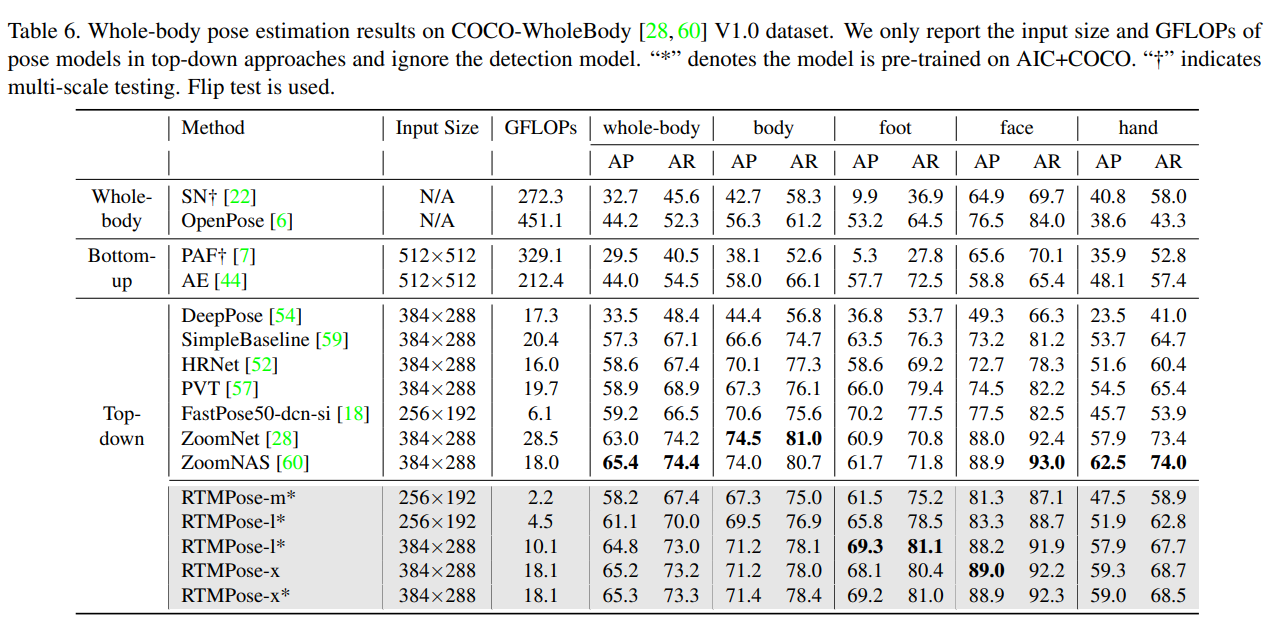
COCO-WholeBody 우리는 또한 COCO-WholeBody [28, 60] V1.0 데이터셋을 사용하여 전체 신체 포즈 추정 작업에서 제안된 RTMPose 모델을 검증한다. 표 6에 나타난 바와 같이, RTMPose는 우수한 성능을 달성하며 정확성과 복잡성을 잘 균형 잡는다. 구체적으로, RTMPose-m 모델은 이전 오픈 소스 라이브러리 [6, 18, 63]보다 훨씬 낮은 GFLOP으로 성능을 능가한다. 입력 해상도와 학습 데이터를 증가시킴으로써 최첨단(SOTA) 접근 방식 [28, 60]과 경쟁력 있는 정확도를 달성한다.
Other Datasets


다른 데이터셋 표 8과 표 9에 나타난 바와 같이, 우리는 AP-10K [64], CrowdPose [32], 그리고 MPII [1] 데이터셋에서 RTMPose를 추가로 평가한다. 공정한 비교를 위해 ImageNet [13] 사전 학습을 사용하여 모델 성능을 보고한다. 또한, COCO [37]와 AI 챌린저(AIC) [58]를 결합하여 사전 학습된 모델의 성능도 보고하며, 이 모델은 더 높은 정확도를 달성하고 제공된 사전 학습 가중치를 통해 사용자들이 쉽게 재현할 수 있다.
4.3. Inference Speed

우리는 CPU 및 GPU에서의 추론 속도를 테스트하기 위해 MMDeploy [112]를 사용하여 모델을 내보내고, 배포하고, 추론 및 테스트를 수행한다. 표 10은 모바일 기기에서의 추론 속도 비교를 보여준다. 우리는 Snapdragon 865 칩에 ncnn을 사용하여 RTMPose를 배포하고 4개의 스레드로 추론을 수행한다. TensorRT 추론 지연 시간은 NVIDIA GeForce GTX 1660 Ti GPU에서 반정밀 부동 소수점 형식(FP16)으로 테스트되며, ONNX 지연 시간은 Intel I7-11700 CPU에서 ONNXRuntime과 1개의 스레드로 테스트된다. 추론 배치 크기는 1이다. 모든 모델은 동일한 장치에서 50회 워밍업과 200회 추론으로 공정하게 비교된다. TinyPose [2]의 경우 MMDeploy 및 FastDeploy로 테스트되었으며, MMDeploy에서의 ONNXRuntime 속도가 약간 더 빠르다는 점(10.58 ms 대 12.84 ms)을 주목할 수 있다. 결과는 표 11과 표 12에 나와 있다.


5. Conclusion

이 논문은 패러다임, 모델 아키텍처, 학습 전략 및 배포와 같은 포즈 추정의 핵심 요소들을 실증적으로 탐구한다. 연구 결과를 바탕으로 우리는 RTMPose라는 고성능 실시간 다중 인물 포즈 추정 프레임워크를 제안하며, 이는 모델 성능과 복잡성을 균형 있게 유지하고, 다양한 장치(CPU, GPU 및 모바일 장치)에서 실시간 추론으로 배포될 수 있다. 우리는 제안된 알고리즘이 오픈 소스 구현과 함께 산업에서 활용 가능한 포즈 추정 수요를 충족시키고, 인간 포즈 추정 작업에 대한 향후 탐구에 기여할 수 있기를 바란다.
Tao Jiang, Peng Lu, Li Zhang, Ningsheng Ma, Rui Han, Chengqi Lyu, Yining Li, Kai Chen RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose

댓글남기기