

개요
RTMW: Real-Time Multi-Person 2D and 3D Whole-body Pose Estimation 논문의 번역 및 얕은 리뷰. 본 논문은 2D Human Pose Estimation 뿐 아니라 3D Pose에 대한 추정도 제공한다. 실시간 처리가 가능한 3차원 자세 추정에 대한 논문으로 읽어보려한다.
본 논문은 여러 산업 분야에서 적용할 수 있는 실시간 어플리케이션에 도움이 되는 모델 방법을 제안한다. 제안하는 RTMW 모델은 얼굴, 손, 발 부위의 포즈를 포함한 Wholebody 자세 추정 테스크를 다룬다. 데이터 셋의 한계를 어떻게 처리하였고, 기존 방식 대비 효율성을 어떻게 달성하는지 보면 좋다.
방법론
- RTMW
- 기본적으로 RTMPose의 아키텍쳐를 따른다.
- PAFPN 모듈을 통해 다양한 해상도를 가진(얼굴, 손, 발은 해상도가 작을 수 있으므로) 부위의 특징을 잘 추출하려 결합한다.
- VQVAE-2 논문에서 언급된 HEM(Hierarchical Encoding Module) 모듈을 도입하여 계층적인 인코딩 방식을 통해 해상도가 낮은 부위의 키포인트 예측 정확도를 높인다.
- DWPose에서 도입된 2단계 지식 증류 기법을 통해 모델 성능을 추가로 끌어올린다.
- RTMW3D
- 단일 이미지에서 절대적인 Z축 좌표값을 추정하는 것은 어렵기에 루트 지점을 기준으로 한 오프셋 방식으로 Z 좌표를 재정의 한다.
- SimCC 방법론에서 Z축에 대한 브랜치를 추가한다.
- 부족한 3D 데이터 셋 문제를 해결하기 위해 2D 와 3D 데이터 셋을 함께 활용한다.
실험
- COCO-Wholebody와 H3WB(Human3.6M-Wholebody) 데이터 셋에 대해 테스트를 진행한다.
- 두 데이터 셋에 대해 2D 는 제안된 모델이 AP, AR을 기존 오픈소스 모델 대비 상회하며 계산복잡도와 성능의 효율 균형을 유지하였다.
- 3D 테스트에 대해 H3WB 기준 높은 MPJPE 메트릭 성능을 달성한다.
- 실시간 연산에 초점을 맞추었으므로, CPU에서 연산 성능 결과를 제시한다. ONNXRuntime의 CPU 기준으로 20FPS 이상의 연산 성능을 보여준다.
결론
본 논문은 Wholebody 자세 추정에 대해 RTMW/RTMW3D 모델 방법론을 제안한다. 이는 성능이 뛰어나면서도 실시간 연산의 효율성을 달성한다. 사람의 자세를 다루는 다양한 도메인의 실시간 어플리케이션에서 활용될 것으로 생각된다.
번역
Abstract
전신(Whole-body) 포즈 추정은 신체, 손, 얼굴, 발에 대한 키포인트를 동시에 예측해야 하는 어려운 과제입니다. 전신 포즈 추정은 얼굴, 상체, 손, 발 등을 포함하는 사람의 세부적인 포즈 정보를 예측하는 것을 목표로 하며, 이는 인간 중심의 지각과 생성 연구 및 다양한 응용 분야에서 중요한 역할을 합니다. 본 연구에서는 2D/3D 전신 포즈 추정을 위한 고성능 모델 시리즈인 RTMW(Real-Time Multi-person Whole-body Pose Estimation models)를 제안합니다. 우리는 RTMPose 모델 아키텍처를 FPN 및 HEM(Hierarchical Encoding Module)과 결합하여, 다양한 스케일을 지닌 여러 신체 부위에서의 포즈 정보를 더욱 효과적으로 포착하도록 하였습니다. 이 모델은 오픈 소스 인체 키포인트 데이터셋의 방대한 컬렉션과 수작업으로 정렬된 주석(annotations)을 통해 학습되었으며, 2단계 지식 증류(distillation) 전략을 통해 추가로 성능이 향상되었습니다. RTMW는 여러 전신 포즈 추정 벤치마크에서 우수한 성능을 보이는 동시에 높은 추론 효율성과 배포 편의성을 유지합니다. 우리는 m/l/x의 세 가지 크기를 공개했으며, 이 중 RTMW-l 모델은 COCO-Wholebody 벤치마크에서 70.2 mAP를 달성하여, 이 벤치마크에서 70 mAP를 넘어선 최초의 오픈 소스 모델이 되었습니다. 한편, 우리는 3D 전신 포즈 추정 작업에서도 RTMW의 성능을 탐색하여, 좌표 분류 방식으로 단안(單眼) 영상 기반 3D 전신 포즈 추정을 수행했습니다. 우리는 본 연구가 학계 연구와 산업적 활용 모두에 도움이 되기를 바랍니다. 코드와 모델은 다음 링크에서 공개되어 있습니다: https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose
1. Introduction
전신(Whole-body) 포즈 추정은 인간 중심 인공지능 시스템의 역량을 확장하는 데 필수적인 요소입니다. 이는 인간-컴퓨터 상호작용, 가상 아바타 애니메이션, 영화 산업 등에서 활용될 수 있습니다. AIGC(AI Generated Content) 분야에서도 전신 포즈 추정 결과가 캐릭터 생성 제어에 활용됩니다. 전신 포즈 추정을 통해 가능해진 후속 작업과 산업적 활용이 늘어나는 상황에서, 높은 정확도와 저지연, 그리고 손쉬운 배포가 가능한 모델을 설계하는 것은 매우 가치가 있습니다.
인체 포즈 추정에 관한 초기 연구에서는, 작업의 복잡성과 제한된 계산 자원 및 데이터 때문에 연구자들이 신체를 여러 부위로 나누어 각각 독립적인 포즈 추정 연구를 수행했습니다. 선행 연구자들의 꾸준한 노력 덕분에, 이러한 단일 부위별 2D 포즈 추정 과업에서 눈에 띄는 성과들이 이루어졌습니다.
이전 연구인 OpenPose [3] 등은 분리된 부위별 결과를 결합함으로써 전신 포즈 추정 결과를 얻을 수 있었습니다. 하지만 이러한 단순 조합 방식은 높은 계산 비용과 성능 상의 한계에 부딪혔습니다. MediaPipe [22]와 같은 경량형 도구들은 실시간 성능과 배포의 용이성 측면에서 이점을 제공하지만, 정확도 면에서는 완전히 만족스럽지 않은 편입니다.
우리 MMPose [5] 팀은 지난해 RTMPose [10] 모델을 공개하였으며, 이 모델은 정확도와 실시간 성능 간에 뛰어난 균형을 달성했습니다. 이후 이를 기반으로, DWPose [40]는 2단계 지식 증류(two-stage distillation) 기법을 적용하고 UBody [17]라는 새로운 데이터셋을 통합함으로써 전신 포즈 추정 작업에서 RTMPose의 성능을 더욱 향상시켰습니다.
RTMPose [10]의 구조적 설계는 초기에는 신체 포즈만을 고려했습니다. 그러나 전신 포즈 추정 작업에서 얼굴, 손, 발의 포즈 정확도를 높이기 위해서는 특징(feature) 해상도가 매우 중요합니다. 이에 우리는 특징 해상도를 강화하기 위해 PAFPN(Part-Aggregation Feature Pyramid Network)과 HEM(High-Efficiency Multi-Scale Feature Fusion) 두 가지 기법을 도입했습니다. 실험 결과, 이 두 모듈은 세분화된 신체 부위의 위치 추정 정확도를 크게 향상시키는 것으로 확인되었습니다.
동시에, 오픈 소스 전신 포즈 추정 데이터셋의 부족은 오픈 소스 모델의 성능을 크게 제한합니다. 다양한 신체 부위에 초점을 맞춘 데이터셋을 충분히 활용하기 위해, 우리는 14개 오픈 소스 데이터셋(전신 키포인트용 3개, 신체 키포인트용 6개, 얼굴 키포인트용 4개, 손 키포인트용 1개)에 대한 키 포인트 정의를 수작업으로 정렬하였으며, 이를 결합하여 RTMW를 학습시켰습니다.
3D 전신 포즈 추정 분야에서 학계는 주로 Lifting [26, 29, 42] 접근법과 회귀(regression) [28, 32] 접근법, 두 가지 방법론을 채택해 왔습니다. SimCC [16] 기법을 기반으로 하는 방법에 대한 학술적 탐구는 거의 이루어지지 않았습니다. 우리 연구는 RTMW 아키텍처를 3D 전신 포즈 추정 작업에 적용함으로써 새로운 영역에 도전했습니다. 실험 결과, SimCC [16] 기법이 해당 분야에서 자체적인 경쟁력을 보이며 우수한 성능을 보여준다는 사실을 확인했습니다.
2. Related Work
Top-down Approaches.
톱다운 알고리즘은 기존에 사용 가능한 디텍터를 활용하여 바운딩 박스를 제공하고, 이를 통해 사람 영역을 균일한 크기로 잘라낸 뒤 포즈를 추정합니다. 톱다운 방식의 알고리즘 [2, 18, 31, 37, 39]은 여러 공개 벤치마크에서 지배적인 위치를 차지해왔습니다. 2단계 추론(two-stage inference) 패러다임을 사용하면 사람 검출기와 포즈 추정기가 모두 상대적으로 작은 해상도의 입력 영상을 사용할 수 있어, 사람 수가 6명 이하인 일반적인 상황에서 속도와 정확도 면에서 보텀업(bottom-up) 알고리즘보다 우수한 성능을 발휘할 수 있습니다. 또한 대부분의 기존 연구는 공개 데이터셋에서 최고 성능(state-of-the-art)을 달성하는 데 주력해 왔습니다. 이에 반해 본 연구는 산업적 수요를 충족할 수 있는, 더 나은 속도-정확도 균형을 가진 모델을 설계하는 것을 목표로 합니다.
Coordinate Classification.
기존의 포즈 추정 접근법은 키포인트 위치 추정을 주로 좌표 회귀(regression) 방식([14, 25, 33])이나 히트맵 회귀 방식([8, 37, 39, 41])으로 간주해 왔습니다. SimCC [16]는 가로 좌표와 세로 좌표 각각을 서브픽셀 단위의 구간(bin)으로 분류(classification)하는 새로운 개념을 제안하며, 이를 통해 여러 가지 이점을 얻을 수 있습니다. 첫째, SimCC는 고해상도 히트맵에 대한 의존성을 없앰으로써, 고해상도 중간 표현([31])이나 비용이 큰 업스케일링(upscaling) 레이어([37])가 필요 없는 매우 간결한 아키텍처 구현이 가능합니다. 둘째, SimCC는 최종 특징 맵을 분류를 위해 펼쳐서(flattens) 사용하며, 전역 풀링(global pooling, [33]) 과정을 거치지 않으므로 공간적 정보 손실을 방지합니다. 셋째, 서브픽셀(sub-pixel) 단위의 좌표 분류를 통해 정량화 오차(quantization error)를 크게 줄일 수 있으며, 추가적인 정교화 후처리(refinement post-processing, [41])가 필요하지 않습니다. 이러한 특성으로 인해 SimCC는 경량형 포즈 추정 모델을 구성하는 데 매력적인 방법론으로 주목받고 있습니다. RTMO [21]는 좌표 분류 기법을 원스테이지(한 단계) 포즈 추정 방식에 도입하여 상당한 성능 향상을 달성했으며, 이를 통해 SimCC 기법이 포즈 추정 작업에서 큰 잠재력을 지니고 있음을 재확인했습니다. 본 연구에서는 모델 아키텍처와 학습 전략 최적화를 통해 좌표 분류 기법을 더욱 발전시키고자 합니다.
3D pose estimation
3D 포즈 추정은 산업 전반에 폭넓게 활용되는 활발한 연구 분야입니다. 현재 주류로 자리 잡은 기법들은 크게 두 가지로, 2D 키포인트를 활용하는 Lifting 방식([26, 29, 42])과 영상 분석에 기반한 회귀(regression) 방식([28, 32])입니다. Lifting 방식은 2D 좌표를 신경망에 입력해 해당 좌표의 3차원 공간 위치를 직접 예측하기 때문에 계산 속도가 빠르다는 장점이 있습니다. 하지만 이러한 효율성은 장면(scene) 정보의 부재라는 대가를 치르게 하며, 이로 인해 예측 가능한 범위에 대한 학습 데이터의 주석(annotaion)에 의존해야 합니다.
한편, 이미지 기반의 회귀 방식([28, 32])은 풍부한 시각 정보를 사용할 수 있지만, 추론 속도가 느리고 과제 복잡도가 높아지는 문제가 있습니다. 이는 모델 학습과 높은 정확도 달성에도 어려움을 초래합니다. 본 논문에서 제안하는 RTMW3D는 이러한 전통적 방식들과 달리, SimCC 기법([16])을 활용한 분류 전략을 통해 최종 3차원 좌표를 후처리 단계에서 정교화하여 새로운 접근법을 제시합니다. 우리의 실험 결과에 따르면, 이와 같은 혁신적인 방법이 높은 효율성을 보인다는 사실을 확인할 수 있었습니다.
3. Model Architecture and Training
이전에 제안했던 RTMPose는 전신 키포인트 추정을 위한 특별한 설계를 갖추고 있지는 않았지만, 실험을 통해 확인한 결과 현재 최신 기법인 ZoomNas [38]와 견줄 만한 성능을 보였습니다. 그러나 실험 과정에서, RTMPose가 전신 포즈 추정 작업에서 특정 성능 병목현상을 지닌다는 사실을 발견했습니다. 매개변수의 규모가 커질수록 모델 성능이 그에 비례하여 향상되지 않는 문제가 나타난 것입니다. 한편, DWPose 팀 등 다른 연구팀이 RTMPose 학습 과정에서 새로운 데이터셋을 추가하고 더 효율적인 2단계 지식 증류(two-stage distillation) 학습 기술을 적용하여 RTMPose의 정확도를 효과적으로 향상시켰지만, 여전히 매개변수 수가 늘어날 때 나타나는 RTMPose 고유의 성능 병목 문제를 피할 수는 없었습니다.
3.1. RTMW
3.1.1 Task Limitation
우리는 먼저 전신 포즈 추정 과제에서 아직 해결되지 않은 문제들을 분석하였으며, RTMW는 이러한 문제들을 해결하기 위해 고안되었습니다. 첫 번째 문제는 국소 영역(local areas) 해상도의 한계입니다. 이미지에서 얼굴, 손, 발과 같은 신체 부위는 인체 전체와 이미지 전체에서 차지하는 비중이 매우 작습니다. 모델 입장에서는 이 부위들의 입력 해상도가 해당 부위 키포인트 예측 정확도에 직접적인 영향을 미치게 됩니다. 두 번째 문제는 서로 다른 신체 부위의 키포인트를 학습하는 난이도가 각각 다르다는 점입니다. 예를 들어, 얼굴 키포인트는 얼굴이라는 비교적 단단한(rigid) 구조체에 붙어 있는 점들로 볼 수 있으며, 얼굴 변형은 매우 작기 때문에 모델이 얼굴 키포인트를 예측하기 상대적으로 수월합니다. 반면, 손 키포인트는 손가락과 손목의 회전과 움직임으로 자유도가 매우 높아 예측이 훨씬 까다롭습니다. 세 번째 문제는 손실 함수(loss function)에 있습니다. 흔히 사용되는 KL 발산(KL divergence)이나 회귀 오차(regression error) 등은 점 단위로 계산되므로, 상체나 얼굴같이 키포인트 수가 많고 공간적 비중이 큰 부위에 의해 지배되는 경향을 보입니다. 이로 인해 손이나 발과 같은 작은지만 복잡한 부위에는 충분한 주의를 기울이지 못하게 됩니다. 이는 종종 불균형한 수렴(imbalanced convergence)으로 이어져, 모델이 전체적인 평균 오차는 낮게 달성하지만 복잡한 신체 부위에서의 정확도는 떨어지는 결과를 낳게 됩니다. 마지막 문제로, 오픈 소스 전신 포즈 추정 데이터셋 자체가 매우 제한적이어서 모델 역량에 대한 연구에 큰 제약이 있습니다. 위와 같은 한계에 대응하기 위해, 우리는 RTMPose에 대한 목표 지향적 최적화 솔루션을 마련하고 RTMW 모델을 제안하였습니다.
3.1.2 Model Architecture
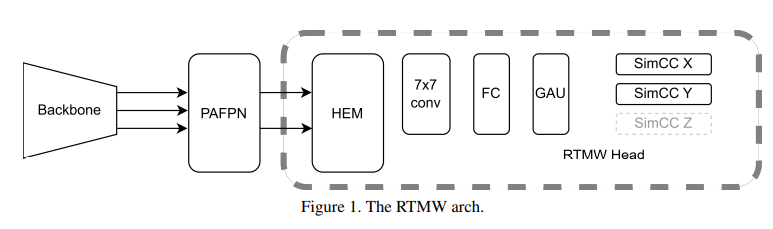
RTMW 모델 구조는 그림 1에 제시되어 있으며, RTMPose를 기반으로 설계되었고, 특징 해상도를 향상시키기 위해 PAFPN [19]과 HEM 모듈을 통합하였습니다. 이 중 FPN(Feature Pyramid Network)은 특징 해상도를 개선하기 위한 효과적인 기법으로, 밀집 예측(dense prediction) 작업을 위한 모델 구조에서 널리 활용됩니다. 또한 VQVAE-2 [30] 논문에서 제안된 계층적 인코딩(hierarchical encoding) 개념에 착안하여 HEM(Hierarchical Encoding Module) 모듈을 도입했습니다. 실험 결과, 이 두 모듈을 동시에 적용하면 전신 포즈 추정 작업에서 RTMPose의 성능을 크게 향상시킬 수 있음을 확인했습니다.
PAFPN
이전 분석에서 다양한 신체 부위의 입력 해상도가 모델 예측 정확도에 미치는 영향에 주목했기 때문에, 우리는 자연스럽게 FPN 모듈을 도입했습니다. 이 기법은 객체 검출 등 다른 비전(vision) 작업에서도 매우 흔히 사용됩니다. 모듈에 대한 자세한 내용은 원 논문 [19]와 RTMDet [24]에서 사용된 개선 버전을 참고할 수 있습니다.
HEM (Hierarchical Encoding Module)
이 모듈은 원래의 인코더-디코더(Encoder-Decoder) 구조 위에 계층적 개념을 도입한 VQVAEv2 작업에서 영감을 받았습니다. 기존 VQVAE 연구에서는 생성된 이미지가 선명하고 풍부한 세부 정보를 충분히 담지 못했는데, 이를 개선하기 위해 두 번째 버전에서는 서로 다른 해상도의 특징을 계층적으로 인코딩하고, 디코딩 과정에서 이 계층적 특징들을 별도로 디코딩함으로써 생성 이미지의 세부 정보를 풍부하게 했습니다. 우리는 이 아이디어를 RTMW 설계에 반영하여, PAFPN에서 출력된 특징에 대해 SimCC 인코딩을 계층적으로 수행한 뒤, 계층적 인코딩을 마친 특징들을 병합한 후 디코더에서 최종 디코딩하는 HEM(Hierarchical Encoding Module)을 구현했습니다. 실험 결과, 이러한 설계를 통해 낮은 해상도의 신체 부위에 대한 포즈 예측 정확도를 향상할 수 있음을 확인했습니다.
3.1.3 Training Techniques
오픈 소스 전신 포즈 추정 데이터셋이 부족하기 때문에, 우리는 전신, 상체, 손, 얼굴 키포인트를 포함하는 14개의 오픈 소스 데이터셋을 직접 정렬하여 통합했습니다. 이 14개 데이터셋을 함께 사용해 모델을 학습하였으며, 동시에 모델 성능을 극대화하기 위해 모델 학습 과정에서 DWPose가 사용한 2단계 지식 증류(two-stage distillation) 기법을 채택하여 모델 성능을 추가로 향상시켰습니다.
3.2. RTMW3D
우리는 RTMW 아키텍처를 3D 전신 포즈 추정으로 확장하는 가능성을 추가로 탐색하였습니다. 이는 부정정(ill-posed) 문제의 특성 때문에 매우 까다로운 과제입니다. 구체적으로, 단일 RGB 이미지로부터 키포인트의 x와 y 좌표를 추정하는 것은 비교적 간단하지만, z축의 모호성은 모델 학습 과정에 복잡성을 더합니다. 게다가 오픈 소스 3D 인체 포즈 데이터셋(특히 키포인트 주석이 있는 데이터셋)의 부족과 제한적인 장면 다양성은 모델의 성능과 일반화 능력을 크게 저해합니다. 이러한 문제를 해결하기 위해, RTMW3D는 3D 데이터셋의 개선, z축 재정의, 그리고 z축 좌표 예측 난이도 완화를 통해 단안(單眼) 3D 포즈 추정에 최적화되도록 설계되었습니다. 구조적으로 RTMW3D는 RTMW와 유사하나, 디코더 헤드에 z축 예측 분기(branch)가 추가된 점이 특징입니다.
Task definition

RTMW3D는 2D 포즈 추정의 원칙을 따르며, SimCC 좌표 공간에서 키포인트의 x와 y 좌표를 직접 예측합니다. 그림 2에 나타난 바와 같이, SimCC [16] 기법의 설계를 참고하여 z축에 대해 데이터셋에서 주석이 달린 z축 좌표의 직접적인 사용을 피합니다. 대신, 우리는 인간 골격의 루트 포인트를 설정하고 이 루트 포인트에 대한 키 포인트의 z축 오프셋을 계산합니다. 이 혁신적인 접근법은 여러 데이터셋 간에 z축을 표준화하고, 모델 학습의 난이도를 줄여줍니다.
Data process
키포인트 중심의 3D 인체 포즈 데이터셋이 부족하다는 점을 감안하여, 우리는 2D 및 3D 데이터셋을 통합하는 시너지 학습 전략을 도입했습니다. 이 방법은 다양한 장면으로 구성된 데이터를 확보함으로써 2D 포즈 추정 작업에서 모델의 성능을 강화합니다. 또한 2D 키포인트 데이터셋에 z축 주석이 없다는 문제를 해결하기 위해, 2D 키포인트 데이터에 z축 마스크를 포함시켰습니다. 이러한 수정사항은 두 종류의 데이터에 대해 통합 학습 프로토콜을 구성할 수 있도록 해 주며, 모델이 키포인트의 x와 y 좌표를 보다 정확히 예측함과 동시에 2D 포즈 추정 역량을 향상시킬 수 있게 합니다.
4. Experiments
4.1. Datasets
학습 단계에서 우리는 RTMPose에 사용된 모든 학습 기법을 계속 활용하였으며, DWPose에서 제안된 2단계 지식 증류(two-stage distillation) 기술을 도입했습니다. 오픈 소스 전신 포즈 추정 데이터셋이 충분하지 않기 때문에, 서로 다른 부위를 다루는 14개 데이터셋을 통합하고, 이들의 키포인트 정의를 수작업으로 정렬한 뒤 COCO-Wholebody의 133개 키포인트 정의에 일관되게 매핑하였습니다. 단안(單眼) 3D 전신 포즈 추정 작업에서는 오픈 소스 3D 데이터셋이 부족하기 때문에, 기존 2D 데이터셋 14개와 오픈 소스 3D 데이터셋 3개를 합쳐 총 17개 데이터셋을 사용해 공동 학습을 수행했습니다. 사용한 데이터셋은 다음과 같습니다.
- 전신(whole-body) 데이터셋 3종: COCO-Wholebody [11, 38], UBody [17], Halpe [6]
- 신체(human body) 데이터셋 6종: AIC [7], CrowdPose [15], MPII [1], sub-JHMDB [9], PoseTrack18 [37], Human-Art [13]
- 얼굴(face) 데이터셋 4종: WFLW [36], 300W, COFW, LaPa [20]
- 손(hand) 데이터셋 1종: InterHand [27]
- 3D 전신 포인트(whole-body point) 데이터셋 3종: H3WB [43], UBody [17], DNA-rendering [4]
자세한 매핑 관계에 대해서는 부록을 참고하시기 바랍니다. 우리는 DWPose [40]에서 제안한 과정에 따라 RTMW의 2단계 지식 증류(two-stage distillation)를 수행했으며, 관련 하이퍼파라미터 또한 DWPose [40]에서 설정된 값을 따랐습니다.
4.2. Results
COCO-Wholebody
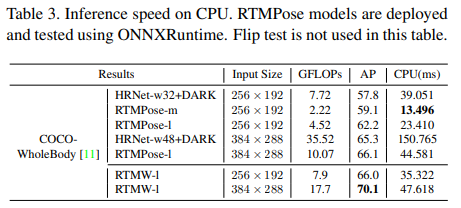
우리는 COCO-WholeBody [12, 38] V1.0 데이터셋을 이용하여 전신 포즈 추정 과제에서 제안된 RTMW 모델을 검증했습니다. 표 1에서 볼 수 있듯이, RTMW는 탁월한 성능을 달성함과 동시에 정확도와 복잡도 간의 균형을 잘 유지합니다. 또한 우리가 제안한 RTMW3D 모델 역시 COCO-WholeBody에서 양호한 성능을 보였습니다.
H3WB
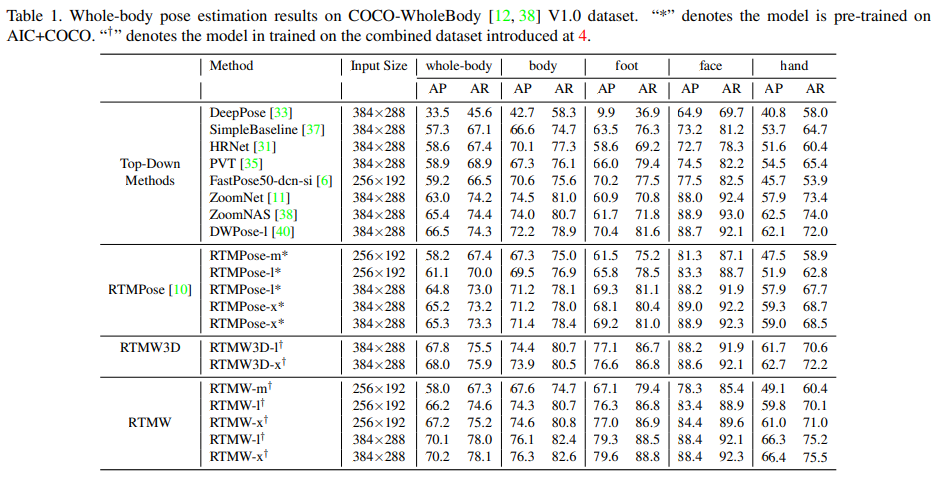
H3WB [43]는 현재 테스트 세트를 제공하는 유일한 오픈 소스 3D 전신 포즈 추정 데이터셋입니다. 우리는 H3WB 테스트 세트에서 RTMW3D의 성능을 평가했으며, 그 결과는 표 2에 제시되어 있습니다. 이와 마찬가지로, RTMW3D는 H3WB 데이터셋에서도 우수한 성능을 보였습니다.
Inference speed
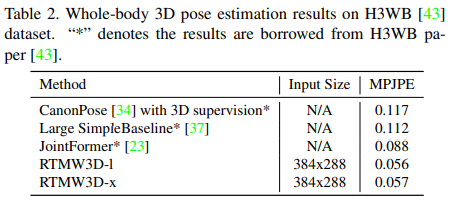
우리는 실시간 모델 개발을 주된 목표로 삼고 있으므로, 추론 속도는 중요한 성능 지표로 부각됩니다. RTMW 모델들의 추론 속도 평가는 표 3에 상세히 제시되어 있습니다. RTMPose 대비 추가 모듈을 포함한 RTMW는 추론 속도가 조금 감소하지만, 정확도가 크게 향상되므로, 우리의 목적을 고려할 때 이러한 트레이드오프는 정당화될 수 있습니다.
4.3. Ablation study
4.3.1 Ablation on RTMW
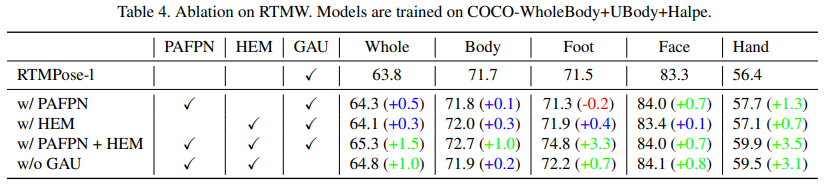
우리는 RTMW의 각 모듈이 성능에 미치는 영향을 평가했으며, 그 결과는 표 4에 제시되어 있습니다. 모델은 COCO-Wholebody [12, 38], UBody [17], Halpe [6] 데이터셋으로 학습되었고, 입력 크기는 256 × 192입니다. 실험 결과, PAFPN과 HEM 모듈이 특히 해상도가 낮은 입력에서 손과 발과 같은 신체 부위의 예측 정확도를 크게 향상시키는 것으로 확인되었습니다.
4.4. Visualization Results

그림 3과 그림 4는 RTMW 및 RTMW3D 모델의 추론 결과를 시각적으로 나타낸 것입니다. 이를 통해 RTMW와 RTMW3D 모델 모두에서 매우 우수한 성능이 확인되며, 이는 정량적 평가 결과와도 일치함을 보여줍니다.

5. Conclusion
본 논문은 전신 포즈 추정에 내재된 복잡성과 난제를 비판적으로 고찰함으로써 기존 학계 연구를 확장합니다. RTMPose 모델을 기반으로, 우리는 실시간 전신 포즈 추정을 위한 고성능 모델인 RTMW/RTMW3D를 소개합니다. 제안된 모델은 기존의 모든 오픈 소스 대안들 중에서도 탁월한 성능을 입증했을 뿐 아니라, 단안(單眼) 3D 포즈 추정 기능에서도 차별화된 역량을 보여줍니다. 우리는 제안된 알고리즘과 이의 오픈 소스 공개가, 견고한 포즈 추정 솔루션에 대한 업계의 여러 실용적 요구 사항을 해결할 수 있을 것으로 기대합니다.
Tao Jiang, Xinchen Xie, Yining Li RTMW: Real-Time Multi-Person 2D and 3D Whole-body Pose Estimation

댓글남기기