

개요
A simple yet effective baseline for 3d human pose estimation 논문의 번역 및 얕은 리뷰. 3차원 사람 자세 추정 Task를 다룰 예정으로 주요 논문부터 읽어볼 예정.
본 논문은 단일 이미지에서 3차원 사람 자세 추정 문제를 다루고 있다. 그러나 이미지를 입력으로 하지는 않으며, 2차원 자세 정보를 입력으로 하여 3차원 자세 정보를 출력을 하는 방법론을 제안한다.
이를 해결하기 위한 딥 뉴럴 넷 아키텍쳐는 매우 빠른 추론 및 학습 성능을 보이며, 기존의 방법론을 능가하는 성능을 보인다.
방법론
- $\mathbf{x} \in \mathbb{R}^{2n}$ 인 입력을 받아 $\mathbf{y} \in \mathbb{R}^{3n}$ 의 출력을 낸다. 즉, 2차원 좌표를 입력으로 하고 3차원 좌표를 출력으로 하는 딥뉴럴 넷 방법론을 제안한다.
- BN, Dropout, ReLU 를 곁들인, 6개의 선형 신경망을 통해 3차원 좌표로 2차원 좌표를 승강 시킨다. 대략적으로 학습되는 모델 파라미터는 400-500만
- 입출력의 정규화를 수행하며, 3차원 좌표를 엉덩이 관절을 중심으로 영점 정렬 한다.
- 카메라 파라미터를 통해 3차원 정답 데이터를 회전시켜서 훈련 데이터를 늘린다.
- 2차원 포인트 감지는 Stacked Hourglass 네트워크를 통해 수행한다. 객체를 중심으로 440 x 440 으로 크롭 후 256 x 256으로 리사이즈 하여 사용.
- 2차원 감지기의 파인튜닝을 통해 Human3.6M 데이터 셋을 사용한 정밀한 예측이 가능.
실험 및 검증
- 주요 데이터 셋은 HumanEva 와 Human3.6M 데이터셋을 사용하였다.
- 3D 좌표에 대해 평균 오차 37.1mm의 최고성능을 달성하였다.(Human3.6M 데이터에 대해)
- 프로토콜 #1, 프로토콜 #2 로 테스트 케이스를 나누어 테스트
- SH 감지기로 훈련한 경우 오류가 일부 증가했으나, 대부분의 동작에서 기존 연구보다 나은 성능을 달성
- MPII 데이터에 대해 정성적인 결과 확인 시, 신체 일부가 가려지거나 잘린 경우에 대해 제한이 일부 있었음.
결론
본 논문은 2D 관절을 입력으로 하여 3D 관절을 출력으로 하는 가벼운 심층 신경망을 제안한다. 3차원 사람 자세 데이터 셋인 Human3.6M 과 HumanEva 데이터 셋을 사용하여 그 효과를 입증한다. 제안된 방법론은 매우 빠른 실시간 성능을 달성하며, 기존의 2차원 감지기와의 결합 관점에서 매우 효율적으로 쓰일 수 있을 것으로 보인다.
번역
Abstract
딥 컨볼루션 네트워크의 성공 이후, 3D 인간 자세 추정을 위한 최첨단 방법들은 원시 이미지 픽셀을 입력으로 받아 3D 관절 위치를 예측하는 딥 엔드-투-엔드 시스템에 집중해 왔습니다. 이들의 뛰어난 성능에도 불구하고, 남아 있는 오류가 제한된 2D 자세(시각적) 이해에서 기인한 것인지, 아니면 2D 자세를 3차원 위치로 매핑하는 데 실패한 것인지 이해하기가 종종 어렵습니다.
이러한 오류의 원인을 이해하기 위해, 우리는 2D 관절 위치를 입력으로 받아 3D 위치를 예측하는 시스템을 구축하려 했습니다. 놀랍게도, 현재의 기술로 “정확한 2D 관절 위치 데이터를 3D 공간으로 변환”하는 작업이 매우 낮은 오류율로 해결될 수 있음을 발견했습니다. 상대적으로 간단한 딥 피드포워드 네트워크가 Human3.6M 데이터셋(가장 큰 공개 3D 자세 추정 벤치마크)에서 기존 최고 성능 결과를 약 30% 초과했습니다. 또한, 최신 2D 감지기(즉, 이미지를 입력으로 사용하는) 출력 데이터를 기반으로 시스템을 학습시킨 결과 최첨단 성능을 달성했습니다. 이는 이 작업을 위해 엔드-투-엔드로 학습된 다양한 시스템을 포함합니다. 우리의 결과는 현대의 딥 3D 자세 추정 시스템의 오류 중 많은 부분이 시각적 분석에서 기인하며, 3D 인간 자세 추정 분야를 더 발전시키기 위한 방향성을 제시합니다.
1. Introduction
현재 존재하는 인간 표현의 대부분은 2차원적입니다. 예를 들어 비디오 영상, 이미지 또는 그림 등이 있습니다. 이러한 표현들은 전통적으로 사실, 아이디어 및 감정을 다른 사람들에게 전달하는 데 중요한 역할을 해왔으며, 이러한 정보 전달 방식은 깊이의 모호성이 존재하는 상황에서도 복잡한 공간적 배열을 이해할 수 있는 인간의 능력 덕분에 가능했습니다. 가상 및 증강 현실, 의류 크기 추정 또는 자율 주행과 같은 많은 응용 프로그램에서 이 공간적 추론 능력을 기계에 부여하는 것이 중요합니다. 이 논문에서는 이러한 공간적 추론 문제의 특정 사례, 즉 단일 이미지에서의 3D 인간 자세 추정을 다룹니다.
보다 공식적으로, 인간을 2차원적으로 표현한 이미지를 주어진다고 할 때, 3D 자세 추정은 묘사된 사람의 공간적 위치에 맞는 3차원 형상을 생성하는 작업입니다. 이미지를 3D 자세로 변환하려면, 알고리즘은 배경 장면, 조명, 의복의 모양과 질감, 피부 색상 및 이미지의 결함 등을 포함한 여러 요인들에 대해 불변성을 가져야 합니다. 초기 방법들은 실루엣 [1], 형태 컨텍스트 [28], SIFT 디스크립터 [6], 또는 에지 방향 히스토그램 [40]과 같은 특징을 통해 이러한 불변성을 달성했습니다. 데이터가 많이 필요한 딥 러닝 시스템들은 현재 이러한 불변성을 필요로 하는 2D 자세 추정과 같은 작업에서 인간이 설계한 특징 기반 접근 방식을 능가하지만, 자연 이미지에서 3D 자세의 정확한 데이터 부족은 컬러 이미지에서 직접적으로 3D 자세를 추정하는 작업을 어렵게 만듭니다.
최근 몇몇 시스템들은 엔드-투-엔드 딥 아키텍처 [33, 45]를 통해 이미지로부터 직접 3D 자세를 추론하는 가능성을 탐구해왔으며, 다른 시스템들은 컬러 이미지에서 3D 추론이 합성 데이터를 사용한 학습으로 달성될 수 있다고 주장합니다 [38, 48]. 본 논문에서는 3D 자세 추정을 2D 자세 추정 [30, 50]과 2D 관절 검출로부터의 3D 자세 추정이라는 잘 연구된 두 문제로 분리하는 접근법을 탐구하며, 후자에 초점을 맞춥니다. 자세 추정을 이 두 문제로 분리하면, 이전에 언급된 요인들에 대해 이미 불변성을 제공하는 기존의 2D 자세 추정 시스템을 활용할 수 있는 가능성을 열어줍니다. 또한, 제어된 환경에서 수집된 대량의 3D 모션 캡처 데이터를 활용하여, 데이터 소모가 많은 2D-3D 문제를 위한 알고리즘을 훈련시킬 수 있으며, 이는 대량 데이터에 대해 잘 확장 가능한 저차원 표현으로 작업을 수행합니다.
본 논문의 주요 기여는 최신 시스템들보다 약간 더 나은 성능을 보이는 (감지 결과를 미세 조정하거나 실제 데이터를 사용할 경우 그 차이가 커짐) 신경망 설계와 분석이며, 빠르게 처리할 수 있다는 점입니다(64 크기의 배치에서 하나의 전방 패스가 약 3ms 소요되며, 배치 모드에서 초당 최대 300fps까지 처리 가능). 이와 동시에 이해하고 재현하기 쉬운 구조를 제공합니다. 이 정확도와 성능의 도약의 주요 이유는 카메라 좌표계에서 3D 관절을 추정하고, 잔차 연결(residual connections)을 추가하며, 배치 정규화(batch normalization)를 사용하는 것과 같은 몇 가지 간단한 아이디어들에 있습니다. 네트워크의 단순성 덕분에 이러한 아이디어들은 실패한 다른 시도들(예: 관절 각도 추정)과 함께 빠르게 테스트될 수 있었습니다.
실험 결과, 정확한 2D 투영 데이터로부터 3D 관절을 추론하는 작업이 기존 최첨단 성능보다 30% 낮은 오류율로, 현재 존재하는 가장 큰 3D 자세 데이터셋에서 해결될 수 있음을 보여줍니다. 또한, 최신 2D 키포인트 감지기의 노이즈가 포함된 출력으로 시스템을 학습시켰을 때, 원시 픽셀로부터 엔드-투-엔드로 학습된 시스템의 3D 인간 자세 추정 최첨단 성능을 약간 능가하는 결과를 얻었습니다.
우리의 연구는 Human3.6M에서 노이즈가 없는 2D 감지를 사용하여 이전의 최고 2D-3D 자세 추정 결과를 크게 개선하였으며, 더 간단한 아키텍처를 사용했습니다. 이는 2D 자세를 3D로 변환하는 작업이 여전히 완벽하게 해결되지 않았지만, 이전에 생각했던 것보다 더 쉬운 작업임을 보여줍니다. 또한, 우리의 연구가 상용 2D 감지기의 출력으로부터 시작하여 최첨단 성능을 달성했으므로, 현재 시스템들이 2D 이미지에서 인간 신체의 시각적 구문 분석에 집중함으로써 추가적으로 개선될 수 있음을 시사합니다. 또한, 우리는 높은 성능을 제공하면서도 가볍고 재현하기 쉬운 기준선을 제공하고 이를 공개함으로써 이 작업에 대한 미래 연구의 새로운 기준을 설정합니다. 우리의 코드는 https://github.com/una-dinosauria/3d-pose-baseline에서 공개적으로 이용할 수 있습니다.
2. Previous work
Depth from images
순전히 2차원 자극에서 깊이를 인지하는 문제는 르네상스 시대로 거슬러 올라가며, 당시 브루넬레스키는 피렌체 건축물 그림에서 공간감을 전달하기 위해 수학적 원근법 개념을 사용했습니다. 이는 과학자들과 예술가들의 관심을 끌어온 고전적인 문제입니다.
수세기 후, 컴퓨터 비전에서는 임의의 장면에서 길이, 면적 및 거리 비율을 추론하기 위해 유사한 원근법 단서를 활용했습니다 [57]. 원근 정보 외에도, 고전적인 컴퓨터 비전 시스템은 음영 [53]이나 텍스처 [25]와 같은 다른 단서를 사용하여 단일 이미지에서 깊이를 복원하려고 시도했습니다. 현대 시스템들 [12, 26, 34, 39]은 주로 감독 학습 관점에서 이 문제를 접근하며, 어떤 이미지 특징이 깊이 추정을 위해 가장 판별적인지 시스템이 학습하게 합니다.
Top-down 3d reasoning
깊이 추정을 위한 초기 알고리즘 중 하나는 장면에 있는 객체의 알려진 3D 구조를 활용하는 다른 접근법을 사용했습니다 [37]. 이러한 상향식(top-down) 정보는 인간의 움직임이 희소 점 투영 집합으로 추상화될 때 인간이 이를 인지하는 데에도 사용된다는 것이 밝혀졌습니다 [8]. 희소한 2D 투영과 같은 최소 표현에서 3D 인간 자세를 추론하는 아이디어는, 잠재적으로 더 풍부한 이미지 단서를 추상화하여 2D 관절로부터 3D 자세를 추정하는 문제를 다루는 본 연구의 영감을 제공했습니다.
2d to 3d joints
2D 투영에서 3D 관절을 추론하는 문제는 Lee와 Chen의 고전적인 연구로 거슬러 올라갑니다 [23]. 그들은 뼈 길이가 주어질 경우, 이 문제가 이진 의사 결정 트리로 환원되며, 여기서 각 분할은 부모 관절에 대한 관절의 두 가지 가능한 상태에 해당함을 보여주었습니다. 이 이진 트리는 관절 제약을 기반으로 가지치기할 수 있지만, 단일 해결책에 도달하는 경우는 드뭅니다. Jiang [20]는 최근접 이웃 쿼리를 기반으로 모호성을 해결하기 위해 대규모 자세 데이터베이스를 사용했습니다. 흥미롭게도, 자세 추론 결과를 개선하기 위해 최근접 이웃을 활용하는 아이디어는 Gupta 등 [14]에 의해 재검토되었으며, 이들은 검색 과정에서 시간적 제약을 통합했습니다. 또한 Chen과 Ramanan [9]에 의해도 다뤄졌습니다. 데이터셋에서 3D 인간 자세에 대한 지식을 수집하는 또 다른 방법은, 희소 결합으로 인간 자세를 표현하기에 적합한 과잉완비 기저(overcomplete bases)를 생성하는 것 [2, 7, 36, 49, 55, 56], 자세를 재현 가능한 커널 힐베르트 공간(RHKS)으로 올리는 것 [18], 또는 극단적인 인간 자세에 대한 특수 데이터셋에서 새로운 사전 확률(priors)을 생성하는 것 [2]입니다.
Deep-net-based 2d to 3d joints
우리의 시스템은 2D와 3D 간의 매핑을 학습하는 딥 뉴럴 네트워크와 관련된 최근 연구와 가장 밀접하게 연관됩니다. Pavlakos 등 [33]은 스택형 아워글래스(stacked hourglass) 아키텍처 [30]를 기반으로 하는 딥 컨볼루션 뉴럴 네트워크를 도입했으며, 이는 2D 관절 확률 히트맵을 회귀하는 대신 3D 공간에서 확률 분포로 매핑합니다. Moreno-Noguer [27]는 2D에서 3D로의 공간에서 쌍별 거리 행렬(DM)을 예측하는 방법을 학습했습니다. 거리 행렬은 회전, 변환 및 반사에 대해 불변성이 있으므로, 다차원 스케일링은 인간 자세의 사전 정보 [2]를 추가하여 가능성이 낮은 예측을 배제합니다.
Moreno-Noguer의 DM 회귀 접근법과 Pavlakos 등의 부피 기반 접근법의 주요 동기는 2D 감지로부터 3D 키포인트를 예측하는 것이 본질적으로 어렵다는 아이디어입니다. 예를 들어, Pavlakos 등 [33]은 직접적인 3D 관절 표현(우리 시스템과 유사한)을 사용하는 기준선을 제시했으나([33]의 표 1 참조), 부피 기반 회귀를 사용하는 것보다 훨씬 낮은 정확도를 보였습니다. 우리의 연구는 2D 관절 감지로부터 3D 키포인트를 직접 회귀하는 것을 피해야 한다는 아이디어와 반대되며, 잘 설계된 단순한 네트워크가 2D-3D 키포인트 회귀 작업에서 충분히 경쟁력 있는 성능을 낼 수 있음을 보여줍니다.
2d to 3d angular pose
이미지에서 3D 자세를 추론하는 두 번째 알고리즘 분기는 관절의 3D 위치를 직접 추정하는 대신, 각도(그리고 때로는 신체 형태)의 관점에서 신체 구성을 추정하는 방식입니다 [4, 7, 31, 54]. 이러한 방법의 주요 장점은 인간 관절의 제한된 이동성으로 인해 문제의 차원이 더 낮아지고, 결과적으로 추정된 값이 인간과 유사한 구조를 가지도록 강제된다는 점입니다. 또한, 이 표현 방식을 통해 뼈 길이나 관절 각도 범위와 같은 인간 속성을 제한하는 것이 비교적 간단합니다 [51]. 우리는 이러한 접근 방식을 실험해 보았지만, 관절과 2D 점 간의 매우 비선형적인 매핑은 학습과 추론을 어렵게 하고 계산 비용을 증가시킨다는 것을 경험했습니다. 따라서, 우리는 3D 관절을 직접 추정하는 방식을 선택했습니다.
3. Solution methodology
우리의 목표는 2차원 입력이 주어졌을 때 3차원 공간에서 신체 관절 위치를 추정하는 것입니다. 공식적으로, 입력은 2D 점들의 집합 $\mathbf{x}∈\mathbb{R}^{2n}$ 이고, 출력은 3D 공간에서 점들의 집합 $\mathbf{y}∈\mathbb{R}^{3n}$ 입니다. 우리는 다음과 같은 데이터셋 $N$ 자세에 대해 예측 오류를 최소화하는 함수 $f^\ast: \mathbf{R}^{2n}→\mathbf{R}^{3n}$ 을 학습하려 합니다:
\[f^\ast =\min_f \frac{1}{N}\sum_{i=1}^N\mathcal{L}(f(\mathbb{x}_i)-\mathbb{y}_i). \tag{1}\]실제로, $\mathbf{x}_i$ 는 알려진 카메라 매개변수 하에서 정확한 2D 관절 위치로부터 얻어지거나, 2D 관절 감지기를 사용하여 획득될 수 있습니다. 또한, 루트 관절에 대해 고정된 전역 공간을 기준으로 3D 위치를 예측하는 것이 일반적이며, 이는 약간 더 낮은 차원의 출력을 제공합니다.
3.1. Our approach – network design
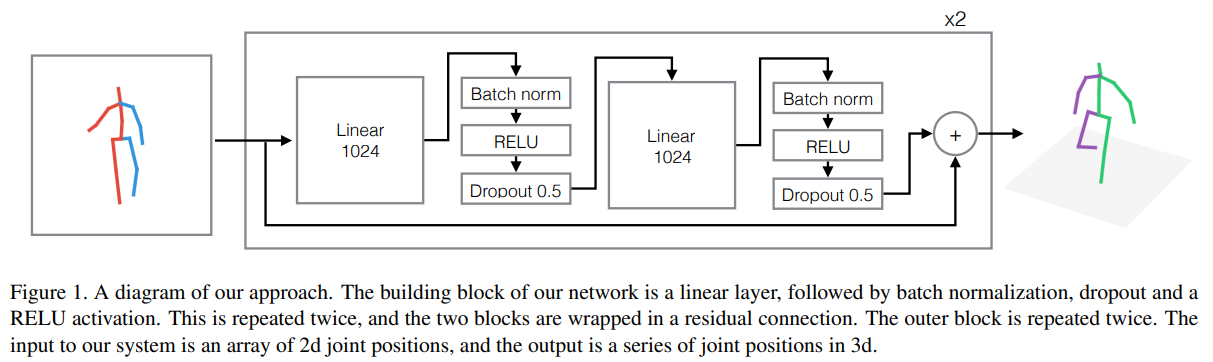
그림 1은 우리의 아키텍처의 기본 구성 요소를 보여주는 다이어그램입니다. 우리의 접근 방식은 배치 정규화 [17], 드롭아웃 [44], 정류 선형 유닛(ReLU) [29], 그리고 잔차 연결(residual connections) [16]을 포함한 단순하고 깊은 다층 신경망을 기반으로 합니다. 도식화되지 않은 두 개의 추가 선형 계층이 있습니다. 하나는 입력에 직접 적용되어 차원을 1024로 증가시키며, 다른 하나는 최종 예측 전에 적용되어 크기 $3n$ 의 출력을 생성합니다. 대부분의 실험에서 우리는 2개의 잔차 블록을 사용했으며, 이는 총 6개의 선형 계층을 갖는 것을 의미하며, 모델은 400만에서 500만 개의 학습 가능한 매개변수를 포함합니다.
우리의 아키텍처는 딥 뉴럴 네트워크 최적화에 대한 최근 개선 사항들의 이점을 얻습니다. 이러한 개선 사항들은 주로 매우 깊은 컨볼루션 뉴럴 네트워크의 맥락에서 등장했으며, ILSVRC(Imagenet [10]) 벤치마크에 제출된 최신 시스템들의 핵심 요소였습니다.
2d/3d positions
우리의 첫 번째 설계 선택은 2D 및 3D 점을 입력과 출력으로 사용하는 것입니다. 이는 원시 이미지 [11, 13, 24, 32, 33, 45, 46, 54, 56]나 2D 확률 분포 [33, 56]을 입력으로 사용하고, 3D 확률 [33], 3D 동작 매개변수 [54], 또는 기본 자세 계수와 카메라 매개변수 추정 [2, 7, 36, 55, 56]을 출력으로 사용하는 최근 연구들과 대조됩니다. 2D 감지는 적은 정보를 포함하지만, 낮은 차원성 덕분에 작업하기 매우 매력적입니다. 예를 들어, 네트워크를 학습시키는 동안 Human3.6M 데이터셋 전체를 GPU에 쉽게 저장할 수 있으며, 이는 전체 학습 시간을 단축하고 네트워크 설계 및 학습 하이퍼파라미터 탐색을 크게 가속화할 수 있게 했습니다.
Linear-RELU layers
3D 인간 자세 추정을 위한 대부분의 딥 러닝 접근법은 컨볼루션 뉴럴 네트워크에 기반을 두고 있으며, 이는 전체 이미지 [13, 24, 32, 33, 45]나 2차원 관절 위치 히트맵 [33, 56]에 적용 가능한 이동 불변 필터를 학습합니다. 하지만, 입력과 출력이 저차원 점이므로, 더 단순하고 계산 비용이 적은 선형 계층을 사용할 수 있습니다. ReLU [29]는 딥 뉴럴 네트워크에서 비선형성을 추가하기 위한 표준 선택입니다.
Residual connections
우리는 잔차 연결(residual connections)이 최근 매우 깊은 컨볼루션 뉴럴 네트워크의 학습을 용이하게 하기 위한 기술로 제안되었으며 [16], 일반화 성능을 개선하고 학습 시간을 단축한다는 것을 발견했습니다. 우리의 경우, 이는 오류를 약 10% 감소시키는 데 도움이 되었습니다.
Batch normalization and dropout
위에서 설명한 세 가지 구성 요소를 포함한 단순한 네트워크는 정확한 2D 위치로 학습했을 때 2D-3D 자세 추정에서 좋은 성능을 발휘하지만, 2D 감지기의 출력으로 학습하거나 2D 실제 데이터로 학습하고 노이즈가 있는 2D 관측값으로 테스트할 경우 성능이 떨어진다는 것을 발견했습니다. 배치 정규화 [17]와 드롭아웃 [44]은 이러한 두 가지 경우에서 시스템 성능을 향상시키며, 학습 및 테스트 시간에는 약간의 증가를 가져옵니다.
Max-norm constraint
우리는 각 계층의 가중치가 최대 노름이 1 이하가 되도록 제약을 추가했습니다. 배치 정규화와 결합하여, 이는 학습과 테스트 예제 간의 분포가 다를 때 학습을 안정화하고 일반화를 개선한다는 것을 발견했습니다.
3.2. Data preprocessing
우리는 2D 입력과 3D 출력을 표준화하기 위해 평균을 빼고 표준편차로 나누는 방식의 정규화를 적용합니다. 3D 예측의 전역 위치를 예측하지 않기 때문에, 우리는 3D 자세를 엉덩이 관절을 중심으로 영점 정렬(zero-centre)합니다. 이는 이전 연구 및 Human3.6M의 표준 프로토콜과 일치합니다.
Camera coordinates
우리의 견해로는, 임의의 좌표 공간에서 3D 관절 위치를 추론하는 알고리즘을 기대하는 것은 비현실적입니다. 해당 공간의 변환이나 회전이 입력 데이터에 변화를 초래하지 않기 때문입니다. 전역 좌표 프레임의 자연스러운 선택은 카메라 프레임 [11, 24, 33, 46, 54, 56]이며, 이는 다양한 카메라에서 2D-3D 문제를 유사하게 만들어 카메라당 더 많은 훈련 데이터를 암묵적으로 가능하게 하고, 특정 전역 좌표 프레임에 과적합되는 것을 방지합니다. 우리는 카메라의 역변환을 기준으로 3D 정답 데이터를 회전 및 변환하여 이를 수행합니다. 임의의 전역 좌표 프레임에서 3D 자세를 추론하는 직접적인 결과는 사람의 전역 방향을 회귀하지 못하는 것이며, 이는 모든 관절에서 큰 오류를 초래합니다. 이 좌표 프레임의 정의는 임의적이며, 우리가 테스트에서 자세의 실제 데이터를 이용하고 있음을 의미하지는 않습니다.
2d detections
우리는 Newell 등 [30]의 최신 스택형 아워글래스 네트워크를 사용하여 2D 감지를 수행하며, 이는 MPII 데이터셋 [3]에서 사전 학습된 모델입니다. 이전 연구 [19, 24, 27, 32, 46]와 유사하게, 우리는 H3.6M과 함께 제공된 경계 상자를 사용하여 이미지에서 사람의 중심을 추정합니다. 우리는 감지기에 대해 계산된 중심 주위에서 크기 440 × 440 픽셀의 정사각형을 잘라냅니다(이후 스택형 아워글래스를 통해 256 × 256으로 크기 조정됨). 이 감지와 실제 2D 랜드마크 사이의 평균 오류는 15픽셀로, 동일한 데이터셋에서 CPM [50]을 사용한 Moreno-Noguer [27]가 보고한 10픽셀보다 약간 높습니다. 우리는 CPM보다 스택형 아워글래스를 선호하는데, 그 이유는 (a) MPII 데이터셋에서 약간 더 나은 결과를 보였으며, (b) 평가 속도가 약 10배 더 빠르기 때문에 H3.6M 데이터셋 전체에 대한 감지를 계산할 수 있었기 때문입니다.
우리는 또한 Human3.6M 데이터셋에서 스택형 아워글래스 모델을 미세 조정했으며(원래는 MPII에서 사전 학습됨), 이는 대상 데이터셋에서 더 정확한 2D 관절 감지를 수행하고 3D 자세 추정 오류를 더욱 줄였습니다. 우리는 스택형 아워글래스의 모든 기본 매개변수를 사용했으며, GPU의 메모리 제한으로 인해 미니배치 크기만 6에서 3으로 줄였습니다. 학습률은 $2.5×10^{−4}$ 로 설정하였고, 40,000번의 반복 동안 학습을 진행했습니다.
Training details
우리는 Adam [21] 최적화 알고리즘과 초기 학습률 0.001, 지수적 감소를 사용하여 네트워크를 200 에포크 동안 학습하며, 미니 배치 크기는 64입니다. 초기에는 선형 계층의 가중치를 Kaiming 초기화 [15]를 사용하여 설정합니다. 우리는 Tensorflow를 사용하여 코드를 구현했으며, Titan Xp GPU에서 한 번의 전방+후방 패스에 약 5ms가 소요되며, 전방 패스만 수행할 경우 약 2ms가 소요됩니다. 이는 최신 실시간 2D 감지기(예: [50])와 결합하여, 우리의 네트워크가 실시간으로 실행되는 완전한 픽셀-3D 시스템의 일부가 될 수 있음을 의미합니다.
Human3.6M 데이터셋 전체에서 하나의 에포크를 학습하는 데 약 2분이 소요되며, 이를 통해 우리는 아키텍처와 학습 하이퍼파라미터의 다양한 변형을 폭넓게 실험할 수 있었습니다.
4. Experimental evaluation
Datasets and protocols
우리는 3D 인간 자세 추정을 위한 두 개의 표준 데이터셋, HumanEva [42]와 Human3.6M [19]을 중심으로 수치 평가를 수행합니다. 또한, 3D 정답 데이터가 제공되지 않는 MPII 데이터셋 [3]에 대한 정성적 결과도 제시합니다.
Human3.6M은, 우리가 아는 한, 현재 3D 인간 자세 추정을 위한 가장 큰 공개 데이터셋입니다. 이 데이터셋은 걷기, 먹기, 앉기, 전화 통화하기 및 대화 참여와 같은 15가지 일상 활동을 수행하는 7명의 전문 배우가 포함된 360만 개의 이미지로 구성되어 있습니다. 2D 관절 위치와 3D 정답 위치뿐만 아니라 모든 배우에 대한 투영(카메라) 매개변수와 신체 비율도 포함되어 있습니다. 반면에 HumanEva는 지난 10년 동안 이전 연구를 벤치마크하는 데 주로 사용된 더 작은 데이터셋입니다. MPII는 수천 개의 짧은 유튜브 비디오를 기반으로 2D 인간 자세 추정을 위한 표준 데이터셋입니다.
Human3.6M에서 우리는 표준 프로토콜을 따르며, 주제 1, 5, 6, 7, 8을 학습에 사용하고, 주제 9와 11을 평가에 사용합니다. 모든 관절과 카메라에 대해, 루트(중앙 엉덩이) 관절을 정렬한 후, 정답과 예측 간의 평균 오류를 밀리미터 단위로 보고합니다. 일반적으로, 각 동작에서 학습과 테스트는 독립적으로 수행됩니다. 우리는 이것을 프로토콜 #1로 참조합니다. 그러나 일부 기준선에서는 예측이 강체 변환(예: [7, 27])을 통해 정답과 추가로 정렬되었습니다. 우리는 이를 후처리 프로토콜 #2라고 부릅니다. 이와 유사하게, 일부 최신 방법들은 특정 동작별 모델을 구축하는 대신, 모든 동작에 대해 하나의 모델을 학습시켰습니다. 우리는 이러한 방식이 일관되게 결과를 향상시키는 것을 발견했으며, 따라서 이 두 가지 변형 하에서 우리 방법의 결과를 보고합니다. HumanEva에서는 모든 주제와 각 동작에 대해 학습과 테스트가 별도로 수행되며, 오류는 항상 강체 변환 후에 계산됩니다.
4.1. Quantitative results
An upper bound on 2d-to-3d regression
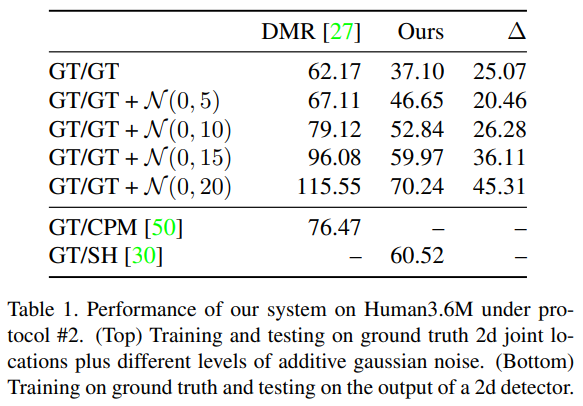
우리의 방법은 2D 관절 위치로부터 직접 회귀를 기반으로 하며, 2D 자세 감지기의 출력 품질에 자연스럽게 의존하며, 실제 2D 관절 위치를 사용할 때 최고의 성능을 달성합니다.
우리는 Moreno-Noguer [27]의 방법을 따랐으며, 원래 2D 정답으로 학습된 시스템에 대해 다양한 수준의 가우시안 노이즈 하에서 테스트를 진행했습니다. 결과는 표 1에서 확인할 수 있습니다. 우리의 방법은 모든 노이즈 수준에서 Distance-Matrix 방법 [27]을 크게 능가하며, 2D 정답 투영으로 학습되었을 때 37.10mm의 오류로 최고 성능을 달성했습니다. 이는 우리가 알고 있는 2D 관절 정답 데이터를 사용하여 보고된 최고 결과 [27]보다 약 43% 더 나은 결과입니다. 또한, 이 결과는 Pavlakos 등 [33]이 보고한 51.9mm보다 약 30% 더 나은 결과이며, 이는 Human3.6M에서 우리가 알고 있는 최고의 결과입니다. 그러나 그들의 결과는 2D 정답 위치를 사용하지 않으므로, 이 비교는 공정하지 않습니다.
모든 프레임이 독립적으로 평가되고 시간 정보를 사용하지 않지만, 우리의 네트워크가 생성한 예측이 상당히 부드럽다는 점을 주목할 만합니다. 이러한 결과와 더 많은 정성적 결과를 포함한 비디오는 https://youtu.be/Hmi3Pd9x1BE에서 확인할 수 있습니다.
Robustness to detector noise
우리의 접근법의 강건성을 추가로 분석하기 위해, 우리는 (항상 2D 정답 위치로 학습된) 시스템을 이미지에서 추출한 (노이즈가 포함된) 2D 감지 데이터를 사용하여 테스트했습니다. 이러한 결과는 표 1 하단에도 보고되었습니다. 이 경우에도 우리는 이전 연구를 능가했으며, 정답으로 학습하고 2D 감지기의 출력으로 테스트할 때 우리의 네트워크가 합리적으로 잘 작동할 수 있음을 입증했습니다.
Training on 2d detections
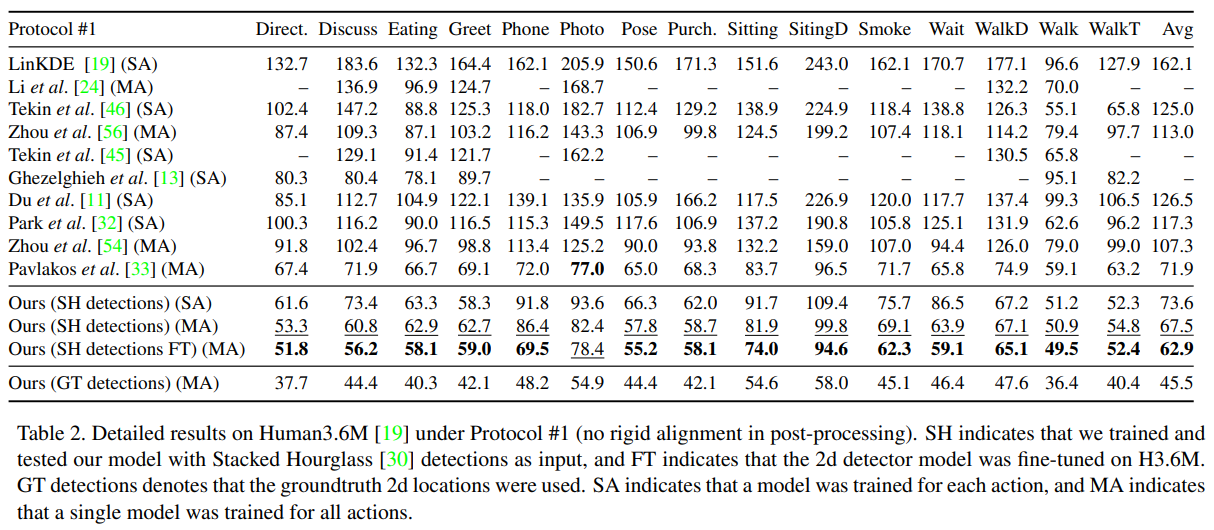
학습 및 테스트 시간에 2D 정답 데이터를 사용하는 것은 우리의 네트워크 성능을 특성화하는 데 흥미롭지만, 실제 응용에서 우리의 시스템은 2D 감지기의 출력을 다뤄야 합니다. 우리는 표 2에서 Human3.6M의 프로토콜 #1에 대한 결과를 보고합니다. 여기서 우리의 가장 가까운 경쟁자는 Pavlakos 등 [33]의 최신 부피 기반 예측 방법이며, 이는 Stacked Hourglass 아키텍처를 사용하고 Human3.6M에서 종단 간 학습이 이루어지며, 모든 동작에 대해 단일 모델을 사용합니다. 우리의 방법은 기본 상태의 Stacked Hourglass 감지를 사용할 때에도 최첨단 결과를 4.4mm 초과하며, 2D 감지기를 H3.6M에서 미세 조정했을 때 간극을 9.0mm 이상으로 두 배 넘게 벌립니다. 또한 우리의 방법은 H3.6M의 15개 동작 중 하나를 제외하고 모두 이전 연구를 꾸준히 능가합니다.
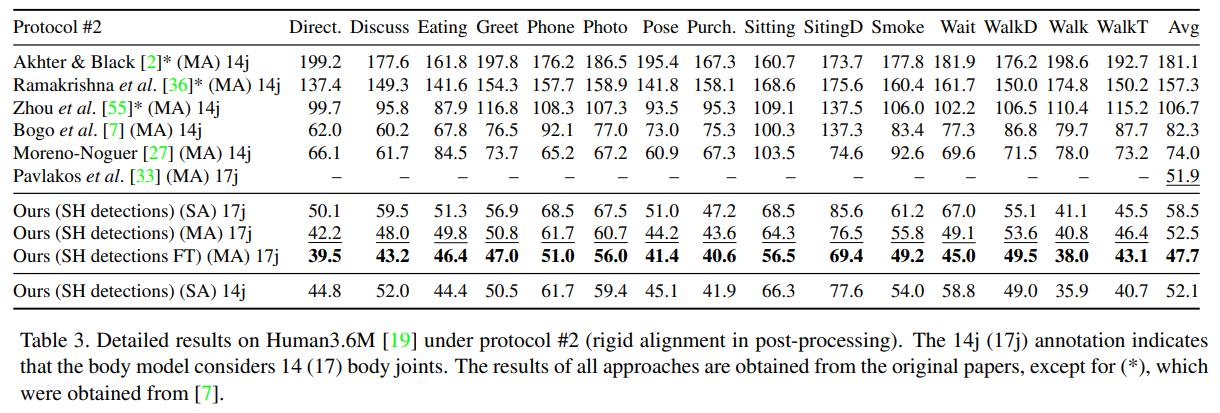
프로토콜 #2(정답 데이터와의 강체 정렬 사용) 하에서 Human3.6M에 대한 우리의 결과는 표 3에 나와 있습니다. 기본 상태 감지기를 사용할 때 우리의 방법은 이전 연구보다 약간 열등하지만, 미세 조정된 감지기를 사용할 때는 최고 성능을 보입니다.
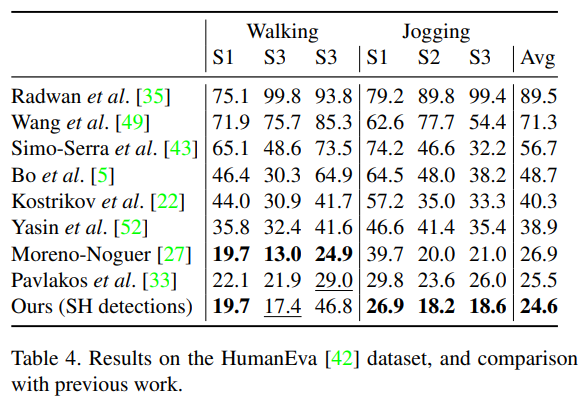
마지막으로, HumanEva 데이터셋에 대한 결과를 표 4에 보고합니다. 이 경우, 6개의 사례 중 3개에서 현재까지의 최고의 결과를 얻었으며, 조깅(Jogging) 및 걷기(Walking) 동작에서 전체적으로 가장 낮은 평균 오류를 기록했습니다. 이 데이터셋은 비교적 작으며 동일한 피험자가 학습 및 테스트 세트에 나타나기 때문에, 이 결과는 Human3.6M에서 우리의 방법으로 얻은 결과만큼 중요하지 않다고 봅니다.
Ablative and hyperparameter analysis
우리는 네트워크 설계 선택의 영향을 더 잘 이해하기 위해 제거 실험을 수행했습니다. 미세 조정되지 않은 MA 모델을 기반으로 표 5에 해당 결과를 제시합니다. 드롭아웃 또는 배치 정규화를 제거하면 오류가 3~8mm 증가하며, 잔차 연결(residual connections)은 약 8mm의 성능 향상에 기여합니다. 그러나 데이터를 카메라 좌표로 네트워크에 전처리하지 않으면 오류가 100mm 이상으로 증가하며, 이는 최첨단 성능보다 훨씬 열악한 결과를 초래합니다.
마지막으로, 우리는 네트워크의 깊이와 너비에 대한 민감도를 분석했습니다. 단일 잔차 블록을 사용하는 경우 오류가 6mm 증가하며, 2개 블록 이후에는 성능이 포화 상태에 도달합니다. 실험적으로, 층을 512 차원으로 줄이면 성능이 저하되었고, 2,048 유닛의 층은 훨씬 느렸으며 정확도를 증가시키지 않는 것으로 보였습니다.
4.2. Qualitative results
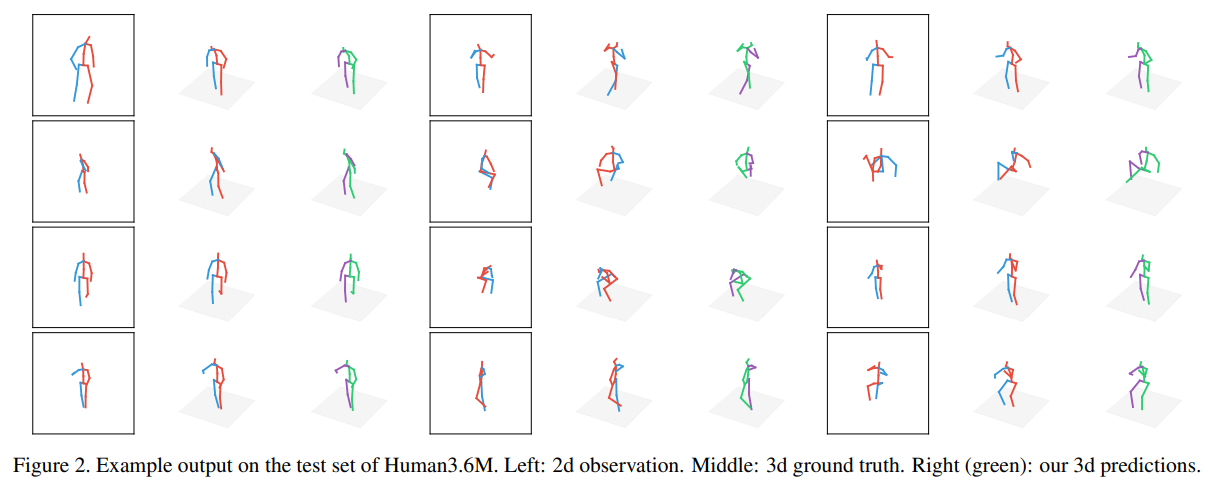
마지막으로, 그림 2에서는 Human3.6M에서의 정성적 결과를, 그림 3에서는 MPII 테스트 세트의 “실제 환경” 이미지에서의 결과를 보여줍니다. MPII에 대한 우리의 결과는 접근 방식의 일부 한계를 드러냅니다. 예를 들어, 우리의 시스템은 감지기의 실패한 출력에서 복구할 수 없으며, H3.6M의 어떤 예제와도 유사하지 않은 자세(예: 거꾸로 선 사람)를 처리하는 데 어려움을 겪습니다. 또한, 실제 환경에서 대부분의 사람 이미지에는 전체 몸이 표시되지 않고 일부가 잘려 있습니다. 전체 몸 자세에 대해 학습된 우리의 시스템은 현재 이러한 사례를 처리할 수 없습니다.

5. Discussion
표 2를 보면, 모든 동작에 대해 SH 감지를 사용하여 학습할 경우, 2D 정답 데이터로 학습한 경우에 비해 오류가 전반적으로 증가하는 것을 알 수 있습니다. 하지만 특히 사진 찍기, 전화 통화, 앉기, 앉아 있는 자세와 같은 클래스에서 오류가 크게 증가합니다. 우리는 이것이 이러한 동작에서 심각한 자기 가림(self-occlusion) 때문이라고 가정합니다. 예를 들어, 일부 전화 통화 시퀀스에서는 배우의 한 손을 볼 수 없는 경우가 있습니다. 마찬가지로, 앉거나 앉아 있는 자세에서는 다리가 종종 카메라 시점과 일치하여 단축 효과(foreshortening)가 크게 발생합니다.
Further improvements
우리의 시스템이 단순하다는 점은 미래 연구에서 여러 개선 방향을 시사합니다. 예를 들어, Stacked Hourglass가 $64×64$ 크기의 최종 관절 감지 히트맵을 생성하므로, 더 큰 출력 해상도는 더 세밀한 감지를 가능하게 하여 정답 데이터로 학습했을 때의 성능에 더 가까워질 수 있습니다. 또 다른 흥미로운 방향은 2D Stacked Hourglass 히트맵에서 여러 샘플을 사용하여 기대되는 그래디언트를 추정하는 것으로, 이는 강화 학습에서 일반적으로 사용되는 정책 그래디언트(policy gradients) 방식에 따라 네트워크를 종단 간 학습하는 것입니다. 또 다른 아이디어는 3차원 동작 캡처(mocap) 데이터베이스와 “가짜” 카메라 매개변수를 사용하여 2D 감지기의 출력을 모방하여 데이터 증강을 수행하는 것입니다. 이는 Shrivastava 등 [41]의 적대적 접근법을 따를 수 있습니다. 장면 내 각 사람의 깊이를 일관성 있게 추정하는 방법을 학습하는 것은 흥미로운 연구 방향이며, 이는 우리의 시스템이 다수 사람의 3D 자세 추정 작업을 수행할 수 있도록 할 것입니다. 마지막으로, 우리의 아키텍처는 단순하며, 네트워크 설계에 대한 추가 연구가 2D-3D 시스템에서 더 나은 결과로 이어질 가능성이 있습니다.
5.1. Implications of our results
우리는 비교적 간단한 심층 피드포워드 신경망이 3D 인간 자세 추정에서 놀라울 정도로 낮은 오류율을 달성할 수 있음을 입증했습니다. 최첨단 2D 감지기와 결합하여, 우리의 시스템은 현재까지 3D 자세 추정에서 최고의 결과를 얻었습니다.
우리의 결과는 픽셀에서 3D 위치로 학습된 심층 종단 간 시스템에 초점을 맞춘 최근 연구와 대조되며, 최신 최첨단 3D 인간 자세 추정 접근 방식의 복잡성을 정당화하는 근본적인 가정을 반박합니다. 예를 들어, [33] 등의 부피 기반 회귀 접근 방식은 3D 점을 직접 회귀하는 것이 본질적으로 어렵고, 부피 공간에서의 회귀가 네트워크에 더 쉬운 그래디언트를 제공할 것이라는 가정에 기반합니다([33]의 표 1 참조). 이미지 콘텐츠가 어려운 모호한 사례를 해결하는 데 도움이 되어야 한다는 데 동의하지만(예: 회전하는 발레리나 착시 현상), 단순하면서도 높은 용량의 시스템으로도 2D 점에서 경쟁력 있는 3D 자세 추정이 가능합니다. 이는 2D 관절 자극에 존재하는 미묘한 신체 및 움직임 특성(예: 성별)에 대한 잠재 정보와 관련이 있을 수 있으며, 이는 사람들이 인지할 수 있습니다[47]. 마찬가지로, [27]에서 거리 행렬을 신체 표현으로 사용하는 것은 불변의 인간 설계 기능이 시스템의 정확도를 높여야 한다는 주장에 의해 정당화됩니다. 그러나 우리의 결과는 잘 학습된 시스템이 이러한 특정 기능을 단순한 방식으로 능가할 수 있음을 보여줍니다. 관절 거리와 관절 위치의 조합이 성능을 더욱 향상시킬 수 있는지 확인하는 것은 흥미로울 것입니다. 이는 향후 연구로 남겨두겠습니다.
6. Conclusions and future work
우리는 간단하고 빠르며 가벼운 심층 신경망이 2D-3D 인간 자세 추정 작업에서 놀라울 정도로 정확한 결과를 달성할 수 있음을 보여주었습니다. 최첨단 2D 감지기와 결합하여, 우리의 연구는 재현하기 쉬우면서도 성능이 뛰어난 기준선을 제공하며, 3D 인간 자세 추정에서 최신 기술을 능가하는 결과를 가져옵니다.
2D 정답 데이터를 기반으로 한 우리의 3D 자세 추정 정확도는 2D 자세 추정이 거의 해결된 문제로 간주되더라도, 여전히 3D 인간 자세 추정 작업에서 주요 오류 원인 중 하나로 남아 있음을 시사합니다. 게다가, 우리의 연구는 간단한 2D 및 3D 좌표로 자세를 표현하며, 이는 최근 연구의 초점이었던 불변의(그리고 더 복잡한) 신체 표현을 찾는 것이 필수적이지 않을 수도 있고, 아직 완전히 활용되지 않았을 수도 있음을 시사합니다.
마지막으로, 우리의 연구는 그 단순성과 분야의 빠른 발전을 감안할 때, 3D 자세 추정을 위한 완전한 시스템이라기보다는 향후 기준선으로 간주하고자 합니다. 이는 향후 연구에 대한 여러 방향을 제시합니다. 첫째, 우리의 네트워크는 현재 시각적 증거에 접근하지 못하고 있습니다. 우리는 2D 감지의 미세 조정을 통해 또는 멀티 센서 융합을 통해 이 정보를 파이프라인에 추가하면 성능이 더욱 향상될 것이라고 믿습니다. 반면, 우리의 아키텍처는 다층 퍼셉트론과 유사하며, 이는 아마도 생각할 수 있는 가장 단순한 아키텍처일 것입니다. 네트워크 아키텍처에 대한 추가 탐구가 성능 향상을 가져올 것이라고 믿습니다. 이는 모두 미래 연구의 흥미로운 영역입니다.
Acknowledgments
저자들은 이 연구에 사용된 GPU를 기부해 준 NVIDIA에 감사를 표합니다. Julieta는 Max Planck Institute for Intelligent Systems의 Perceiving Systems 그룹의 일부 지원을 받았습니다. 이 연구는 캐나다 자연과학 및 공학 연구위원회(NSERC)의 지원을 일부 받았습니다.
Julieta Martinez, Rayat Hossain, Javier Romero, James J. Little A Simple yet Effective Baseline for 3D Human Pose Estimation

댓글남기기