

개요
SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation 논문의 얕은 리뷰. 해당 논문은 2022년에 ECCV에 발표되었다.
가장 중요한 것은 일반적인 2D HPE의 헤더 부분에는 가우시안 형태의 히트맵을 출력으로 하고 이를 통해 관절이 위치를 알아왔다. 이 과정에서 압축된 피쳐맵을 업샘플링 하는 과정이 필요했었는데 해당 SimCC 방법은 이러한 회귀 문제를 2개의 선형적인 분류 문제로 치환하였고, 이는 연산량을 많이 늘리는 디컨볼루션 모듈 등을 제거할 수 있어 추론 속도 및 연산량을 줄이는데 많은 기여를 한다. 그리고 이러한 방식은 CNN 기반의 모델이나 Transformer 기반의 방식에 쉽게 적용하도록 기여한다.
SimCC
핵심 아이디어는 백본 네트워크를 지나 두개의 분류 헤드를 구성하여 관절의 위치를 추정한다.
- 백본의 경우 CNN, Transformer 기반 모델을 모두 사용할 수 있다.
- 좌표의 추정을 위한 분류 헤드는 CNN을 예시로 들면 (n,W,H)의 shape을 (n, W*H)으로 변형한다. 이는 연산량을 효율적으로 줄인다.
- 분류 헤드를 거쳐 나오는 연속적인 좌표값을 이산화하여 서브 픽셀 수준의 정밀도를 구현한다. i 번째 관절을 수평 헤드의 값이 제일 높은 예측 지점과 수직 헤드의 값이 제일 높은 예측 지점을 통해 알 수 있다.
- 기존에 사용하던 균등 라벨 스무딩 기법은 틀린 라벨에 대한 무차별적 처벌(손실 적용)로 공간적 관련성을 무시하기에 효율이 떨어진다. 라플라스 또는 가우시안 형태의 라벨 스무딩을 적용하여 모델의 성능을 향상 시킨다.
그림 3을 통해 SimCC 방식이 히트맵 기반 방식에 비해 가지는 우수성을 볼 수 있다.
- SimCC 방식은 2차원 히트맵 방식에 비해 양자화 에러를 줄인다.
- 기존 2차원 히트맵 방식은 성능을 추가적인 후처리에 크게 의존하는데 SimCC는 이러한 후처리 없이도 HPE에 대한 더 간단하면서도 높은 성능을 달성한다.
- 또한 여러 다양한 해상도에 대해서도 히트맵 방식 대비 높은 성능을 달성하며 저해상도에서의 성능향상이 눈에 띈다.
- SimCC 방식은 업샘플링을 위한 디컨볼루션이 없으므로 추론 속도를 높일 수 있다.
실험
- 실험은 크게 COCO 데이터셋에 대한 주 실험과, CrowdPose, MPII 에 대한 실험으로 구성된다.
- COCO
- COCO 데이터 셋에 대해선 TokenPose, SimpleBaseline, HRNet-W48 아키텍쳐에 대해 테스트 진행하였고 여기서 입력해상도에 대한 성능 평가, 후처리 여부에 대한 성능 평가를 진행한다.
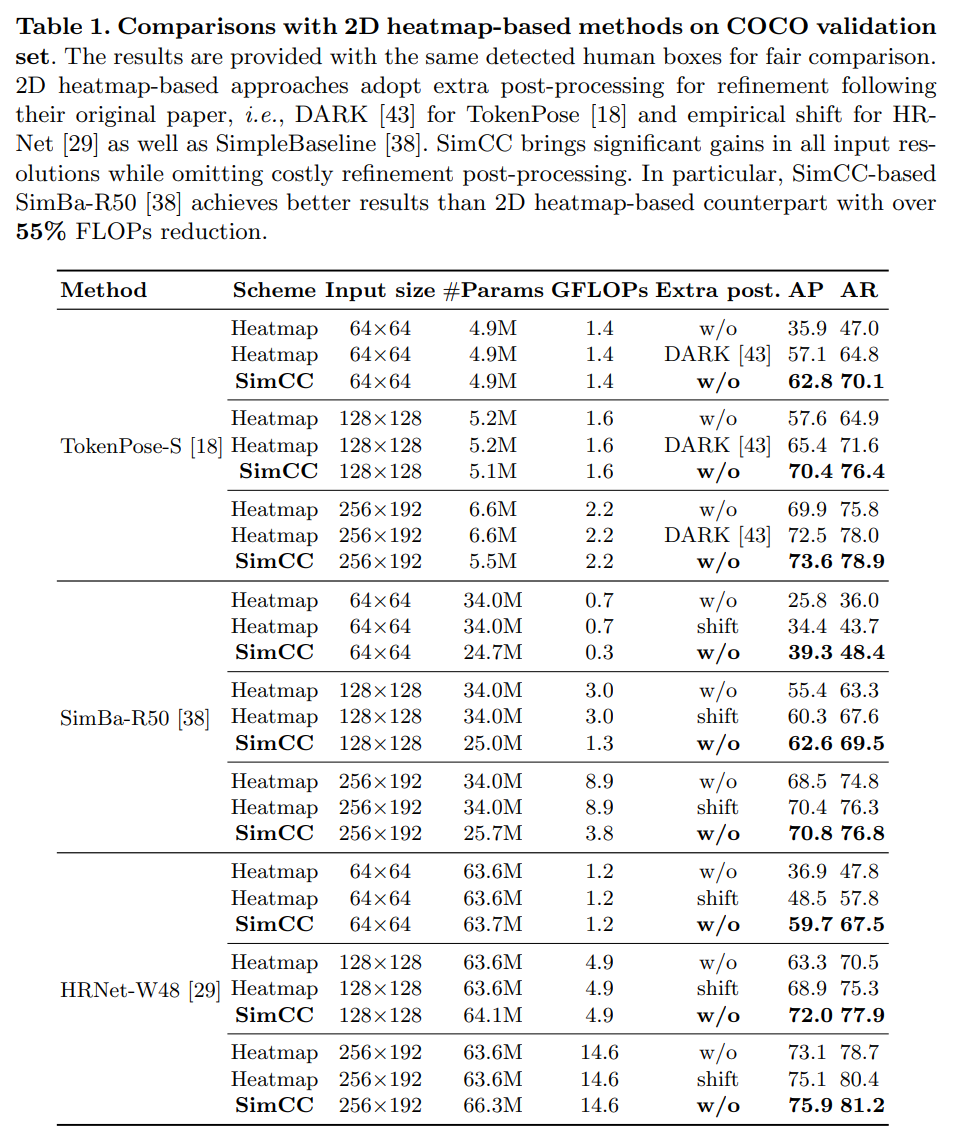
- 제안된 SimCC는 64x64의 저해상도에서도 성능향상이 두드러지며, DARK나 Empirical Shift 같은 후처리 없이도 높은 성능을 달성한다.
- 2D 히트맵 기반, 회귀 기반 모델들 과의 비교군들 중에서 제일 높은 성능을 달성함을 볼 수 있다.
- 헤드에 붙는 분할 계수(bin을 위한) k에 대한 최적화 실험을 진행했으며 아키텍쳐 별로 다르지만 2 혹은 3의 적정값을 확인한다.
- 업샘플링과 SimCC 헤드를 둘다 사용하는 것이 성능이 제일 좋지만, 업샘플링 헤드를 없애는 것이 50% 이상으로 연산량을 감소시키므로 계산 비용 감소 측면에서 높은 효과를 볼 수 있다.
- 라벨 스무딩의 효과를 4가지 케이스(없음, 균등, 가우시안, 라플라스)로 확인하였다. 효과는 있었지만 해당 논문에서 이에 대한 추가 논의는 향후 연구로 미뤘다고 한다.
- CrowdPose
- 히트맵 기반의 HRNet-W32 오리지널 모델과 SimCC를 적용한 HRNet-W32 모델을 비교하여 일관된 성능 향상을 확인하였다.
- MPII
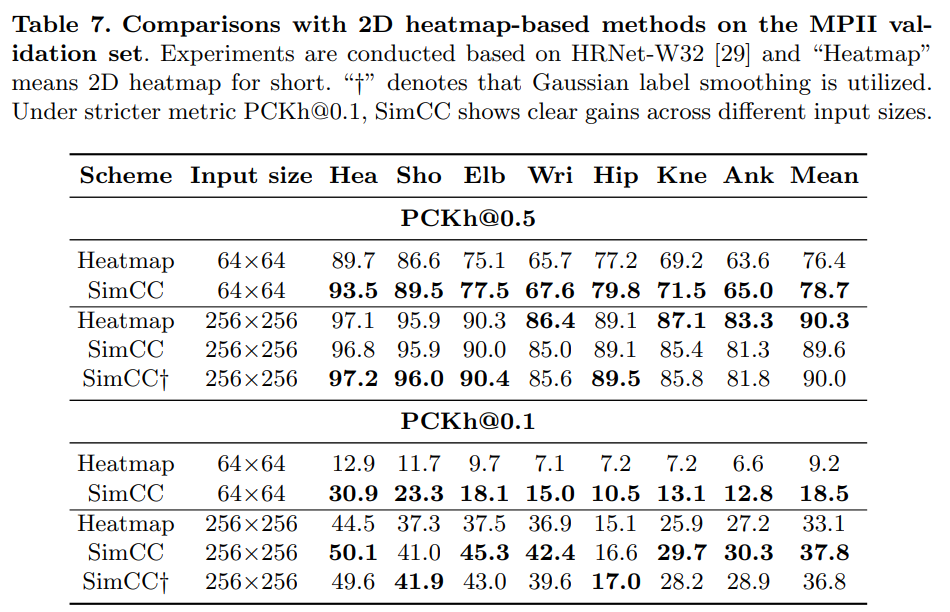
- PCKh@0.5와 PCKh@0.1이라는 더 엄격한 성능 지표를 사용하였을 때 SimCC 방식에서 일관적인 성능향상을 확인한다.
결론
해당 논문은 2D Human Pose Estimation 작업에서 2D 히트맵 기반 방식에서 발생하는 양자화 오류 문제를 해결하고자 새로운 분류 기반 접근 법인 SimCC를 제안한다. 2차원 히트맵 출력을 2개의 1차원 분류 헤드로 변경하여 더 단순화 된 방법을 제시한다. 해당 방법론은 2D 히트맵 기반 HPE 보다 간단하고 효과적으로 연산량을 줄이며, 실험의 결과를 보면 AP 등의 메트릭 면에서 더 성능을 높일 수 있음을 시사한다. 단, Bottom-Up에선 사람에 대한 식별 모호성 문제가 발생할 수 있음을 말한다.
번역
Abstract
2D 히트맵 기반 접근 방식은 높은 성능으로 인해 오랫동안 인간 포즈 추정(HPE)을 지배해 왔습니다. 그러나 2D 히트맵 기반 방법의 장기간에 걸친 양자화 오류 문제는 여러가지 잘 알려진 단점을 초래합니다.: 1) 저해상도 입력에 대한 성능이 제한됨; 2) 더 높은 위치 정밀도를 위한 피처 맵 해상도를 향상시키기 위해 다수의 비용이 많이 드는 업샘플링 레이어가 필요함; 3) 양자화 오류를 줄이기 위해 추가적인 후처리가 채택됨. 이러한 문제를 해결하기 위해, 우리는 SimCC라는 새로운 방식을 탐구하고자 합니다. 이 방식은 HPE를 수평 및 수직 좌표에 대한 두 가지 분류 작업으로 재구성합니다.제안된 SimCC는 각 픽셀을 여러 구간(bin)으로 균등하게 나누어 서브 픽셀 수준의 위치 정밀도와 낮은 양자화 오류를 달성합니다. 이점 덕분에, SimCC는 추가적인 정제 후처리와 특정 설정 하에서 업샘플링 계층을 생략할 수 있어 HPE에 더 단순하고 효과적인 파이프라인을 제공합니다. COCO, CrowdPose, 및 MPII 데이터셋에 걸친 광범위한 실험 결과, SimCC는 특히 저해상도 설정에서 히트맵 기반 방법을 크게 능가하는 성능을 보여줍니다.
1 Introduction
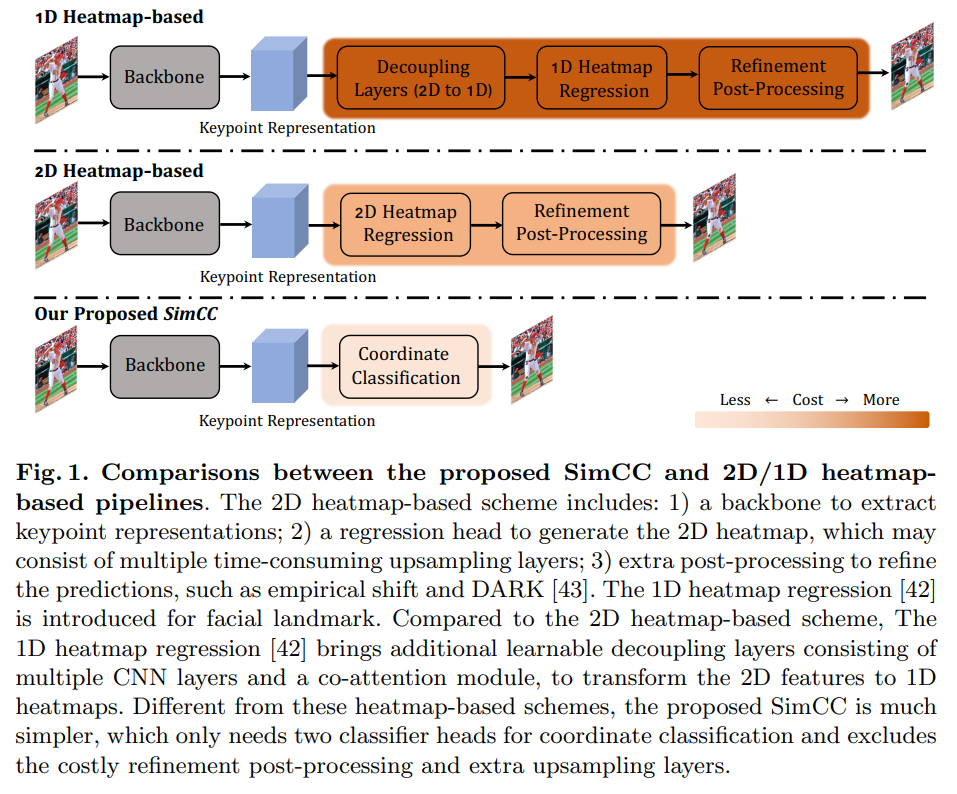
2D 인간 자세 추정(Human Pose Estimation, HPE)은 단일 이미지에서 신체 관절을 위치시키는 것을 목표로 하며, 2D 히트맵 기반 방법 [2,3,6,7,43,17,18,20,23,29,38,40]이 최근 몇 년간 사실상의 표준이 되었습니다. 2D 히트맵은 실제 관절 위치를 중심으로 하는 2차원 가우시안 분포로 생성되며, 각 위치에 확률 값을 할당하여 훈련 과정을 부드럽게 하고 오탐을 억제합니다.
이런 성공에도 불구하고, 히트맵 기반 방법은 연속적인 좌표 값을 이산화된 2D 다운스케일 히트맵으로 매핑함으로써 발생하는 오랜 양자화 오류 문제로 심각한 어려움을 겪습니다. 이러한 큰 양자화 오류는 추가적으로 여러 잘 알려진 단점을 초래합니다: 1) 양자화 오류를 완화하기 위해 피처 맵 해상도를 증가시키는 비용이 많이 드는 업샘플링 계층(예: 디컨볼루션 계층 [38])이 사용됩니다; 2)예측을 정제하기 위해 추가 후처리(예: 경험적 시프트, DARK [43])가 도입됩니다; 3) 심각한 양자화 오류로 인해 저해상도 입력에 대한 성능이 만족스럽지 못합니다. 고해상도 2D 히트맵을 얻는 것은 높은 연산 비용을 초래하기 때문에, 양자화 오류를 줄이는 자연스러운 방법은 2D 히트맵을 1D 히트맵으로 먼저 분리한 후 해상도를 높이는 것입니다. 이는 Yin 등 [42]에 의해 얼굴 랜드마크 영역에 대해 탐구되었습니다. 그러나, 이 목표를 달성하기 위해 Yin 등 [42]은 추가적인 분리 계층(예: 협업 주의 모듈 및 다중 컨볼루션 계층)과 비용이 많이 드는 디컨볼루션 모듈을 도입하여, 그림 1에서 보여진 바와 같이 2D 히트맵 기반 방법보다 더 복잡한 파이프라인을 야기합니다.
따라서, 본 연구에서는 HPE를 위한 히트맵 기반 방법에 대한 새로운 방안을 탐구하고자 합니다. 구체적으로, 우리는 SimCC라는 간단하면서도 효과적인 좌표 분류 파이프라인을 제안합니다. 이 방식은 HPE를 수평 및 수직 좌표에 대한 두 가지 분류 작업으로 간주합니다. SimCC는 먼저 주요 지점 표현을 추출하기 위해 CNN 또는 Transformer 기반 백본을 사용합니다. 획득한 주요 지점 표현을 바탕으로, SimCC는 최종 예측을 도출하기 위해 수직 및 수평 좌표에 대한 좌표 분류를 독립적으로 수행합니다. 양자화 오류를 줄이기 위해, SimCC는 각 픽셀을 여러 구간으로 균일하게 나누어 서브 픽셀 수준의 위치 정밀도를 달성합니다. 히트맵 기반 접근법이 여러 디컨볼루션 계층을 도입할 수 있는 것과는 달리, SimCC는 가벼운 두 개의 분류기 헤드(즉, 각 헤드에 하나의 선형 계층만 필요)를 사용합니다.
그림 1은 제안된 SimCC와 1D/2D 히트맵 기반 접근법 간의 비교를 보여줍니다. 지배적인 2D 히트맵 기반 방식과 비교하여, SimCC는 다음 세 가지 장점을 가지고 있습니다: 1) 각 픽셀을 여러 구간으로 균일하게 나누어 양자화 오류를 줄입니다; 2) 특정 설정에서 업샘플링 계층을 생략하고 [38] 비용이 많이 드는 정제 후처리를 배제하여 실제 응용에 더 적합합니다; 3) SimCC는 낮은 입력 크기에서도 인상적인 성능을 보여줍니다. 우리의 기여는 다음과 같이 요약됩니다:
- 우리는 SimCC라는 인간 자세 추정을 위한 좌표 분류 파이프라인을 제안하여, 문제를 수평 및 수직 좌표에 대한 두 가지 분류 작업으로 재구성했습니다. SimCC는 일반적인 방식으로, 기존 CNN 기반 또는 Transformer 기반 HPE 모델에 쉽게 적용될 수 있습니다.
- SimCC는 히트맵 기반 방법에서 추가적인 시간 소모적인 업샘플링과 후처리를 생략함으로써 높은 효율성을 달성합니다. 특히, SimCC를 적용하면 SimBa-Res50 [38]의 GFLOPs를 55% 이상 줄이면서 히트맵 기반 방법보다 더 높은 모델 성능을 달성합니다.
- COCO, CrowdPose, 및 MPII 데이터셋에 걸친 포괄적인 실험이 수행되어, 서로 다른 백본과 다양한 입력 크기로 제안된 SimCC의 효과가 검증되었습니다.
우리는 높은 계산 비용, 복잡한 후처리, 저해상도 입력에서의 낮은 성능 때문에 기존 2D 히트맵 기반 방법이 HPE의 최종 솔루션이 아닐 수 있다고 믿습니다. 우리는 SimCC에 대한 탐구가 HPE의 잠재적인 연구 작업과 실질적인 배치를 위한 새로운 관점을 제공할 수 있기를 바랍니다.
2 Related Work
Regression-based HPE
회귀 기반 방법 [35,4,33,31,30,24]은 2D 인간 자세 추정의 초기 단계에서 더 자주 탐구되었습니다. 2D 그리드 형태의 히트맵에 의존하는 것과 달리, 이 접근법은 계산 친화적인 프레임워크에서 주요 지점 좌표를 직접 회귀합니다. 그러나 성능이 만족스럽지 않아 기존 방법 중 일부만 이 방식을 채택합니다. 최근에, Li 등 [14]은 잔차 로그 가능도(RLE)를 도입하여 정규화 흐름(normalizing flows) [27]을 활용하여 기본 출력 분포를 포착하고 회귀 기반 방법이 최신 히트맵 기반 방법의 정확도와 일치하도록 만들었습니다. RLE의 핵심 아이디어는 정규화 흐름을 기반으로 적응형 손실을 구성하여 우리 연구에 상보적 역할을 합니다.
2D heatmap-based HPE.
또 다른 연구 분야 [2,3,6,7,17,18,20,23,29,38,40,43,11]에서는 관절 좌표를 나타내기 위해 2차원 가우시안 분포(즉, 히트맵)를 채택합니다. 히트맵의 각 위치에는 실제 지점일 확률이 할당됩니다. 히트맵의 초기 사용 예 중 하나로, Tompson 등 [34]은 깊은 컨볼루션 네트워크와 마르코프 랜덤 필드로 구성된 하이브리드 아키텍처를 제안했습니다. Newell 등 [23]은 HPE에 샌드타이머(hallglass) 스타일의 아키텍처를 도입했습니다. Papandreou 등 [25]은 위치 정밀도를 향상시키기 위해 히트맵과 오프셋 예측을 결합할 것을 제안했습니다. Xiao 등 [38]은 백본 네트워크 뒤에 세 개의 디컨볼루션 계층을 활용하는 간단한 기준을 제안하여 최종 예측 히트맵을 얻습니다. Sun 등 [29]은 전체 과정에서 고해상도 표현을 유지하여 성능을 크게 개선하는 새로운 네트워크를 제안했습니다. 공간적 불확실성이 포함됨으로 인해, 이러한 학습 체계는 지터 오류에 대한 내성이 있습니다. 그 결과, 히트맵 기반 방법은 여러 해 동안 안정적인 최첨단 성능을 유지해왔습니다. 그러나 양자화 오류는 특히 낮은 입력 해상도에서 히트맵 기반 방법의 주요 문제로 남아 있습니다.
quantization error.
이산 된 2D 축소 히트맵에 의해 발생하는 큰 양자화 오류를 해결하기 위해, Zhang 등 [43]은 테일러 전개 기반 분포 근사화를 후처리로 채택하여 히트맵 활성화의 분포 정보를 종합적으로 고려할 것을 제안했습니다. 양자화 오류를 줄이기 위한 또 다른 시도로, Yin 등 [42]은 얼굴 랜드마크 검출을 위해 학습 가능한 분리 계층을 사용하여 2D 히트맵을 1D 히트맵으로 변환하고 추가 디컨볼루션 계층을 사용하여 1D 히트맵 해상도를 높이는 방법을 탐구했습니다.
1D heatmap regression in facial landmark.
인간 자세 추정 영역 외에도, 1D 히트맵 기반 방법 [42,39]이 얼굴 랜드마크 검출을 위해 탐구되었습니다. 그 중에서 Yin 등 [42]은 분리된 1D 히트맵의 해상도를 높이기 위해 디컨볼루션 계층을 사용하여 양자화 오류를 완화하려는 주의 깊은 1D 히트맵 회귀 방법을 제안했습니다. 분리된 1D 히트맵 간의 결합된 분포 정보를 포착하기 위해 1D 히트맵 회귀에 협업 주의 모듈이 도입되었습니다 [42].
Coordinate classification.
우리 연구와 동시에, Chen 등 [5]은 Pix2Seq를 통해 객체 검출을 언어 모델링 작업으로 변환하여 객체를 다섯 개의 이산 토큰 시퀀스로 설명하고 추가 분류를 수행할 것을 제안했습니다. Pix2Seq에서는 Transformer 디코더 아키텍처가 각 객체를 “읽어내기”(예측을 도출) 위해 필수적입니다. 반면, 우리가 제안하는 SimCC는 인간 자세 추정을 위한 히트맵 기반 방법에 대항하는 새로운 경로를 탐구하며, CNN 또는 Transformer 기반 HPE 방법과 쉽게 결합될 수 있으며 추가 Transformer 디코더에 의존하지 않고 예측을 생성합니다.
3 SimCC: Reformulating HPE from Classification Perspective
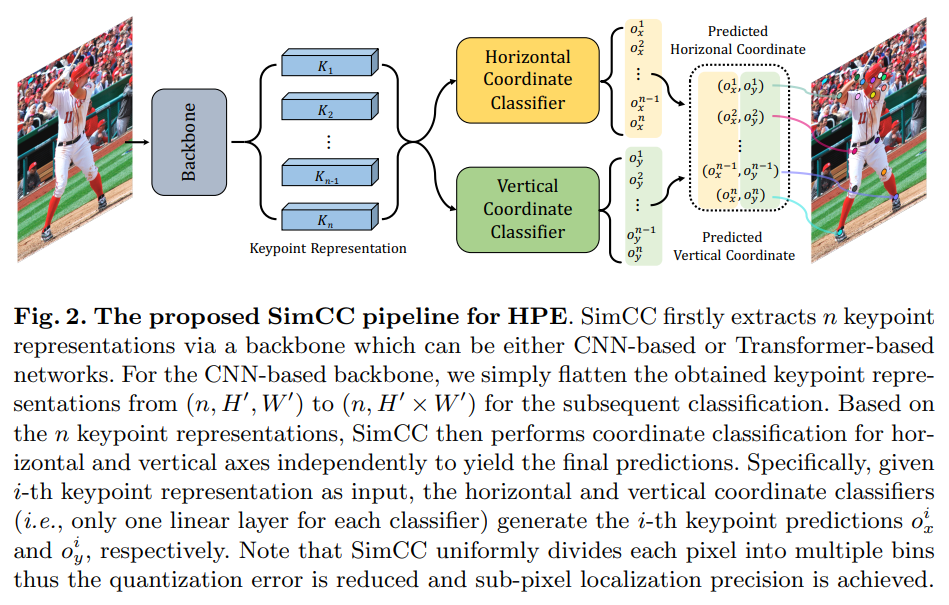
SimCC의 핵심 아이디어는 인간 자세 추정을 수직 및 수평 좌표에 대한 두 가지 분류 작업으로 간주하고 각 픽셀을 여러 구간으로 나누어 양자화 오류를 줄이는 것입니다. 그림 2는 백본 네트워크와 두 개의 분류기 헤드로 구성된 SimCC의 개략도를 보여줍니다. 이 절에서는 각 구성 요소를 자세히 설명하겠습니다.
Backbone
크기 $H×W×3$ 의 입력 이미지가 주어지면, SimCC는 백본으로 CNN 기반 또는 Transformer 기반 네트워크(예: HRNet [29], TokenPose [18])를 사용하여 $n$ 개의 해당 주요 지점에 대한 $n$ 개의 주요 지점 표현을 추출합니다.
Head
그림 2에 표시된 바와 같이, 수평 및 수직 분류기(즉, 각 분류기에 하나의 선형 계층만 있음)가 백본 뒤에 추가되어 각각 좌표 분류를 수행합니다. CNN 기반 백본의 경우, 분류를 위해 출력된 주요 지점 표현을 $(n,H′,W′)$ 에서 $(n,H′×W′)$ 로 단순 평탄화합니다. 여러 비용이 많이 드는 디컨볼루션 계층을 헤드로 사용하는 히트맵 기반 접근법 [38]과 비교할 때, SimCC 헤드는 훨씬 가볍고 간단합니다.
Coordinate classification.
분류를 달성하기 위해, 우리는 각 연속 좌표 값을 정수로 균일하게 이산화하여 모델 훈련의 클래스 레이블로 사용할 것을 제안합니다: $c_x ∈[1,N_x],c_y∈[1,N_y]$, 여기서 $N_x=W⋅k$ 및 $N_y=H⋅k$ 는 각각 수평 및 수직 축에 대한 구간(bin)의 수를 나타냅니다. k는 분할 계수로 설정되어 $k≥1$ 로 설정하여 양자화 오류를 줄이며 서브 픽셀 수준의 위치 정밀도를 제공합니다. 최종 예측을 위해, SimCC는 백본에 의해 학습된 $n$ 개의 주요 지점 표현을 기반으로 수직 및 수평 좌표 분류를 독립적으로 수행합니다. 구체적으로, $i$ 번째 주요 지점 표현을 입력으로 주었을 때, 수평 및 수직 좌표 분류기에 의해 각각 $i$ 번째 주요 지점 예측 $o_x^i$ 와 $o_y^i$ 가 생성됩니다. 추가적으로, Kullback–Leibler 발산이 훈련을 위한 손실 함수로 사용됩니다.
Label smoothing
전통적인 분류 작업에서 레이블 스무딩 [32]은 모델 성능을 향상시키기 위해 널리 사용됩니다. 따라서 우리는 SimCC에 이를 채택하였으며, 이 논문에서는 이를 균등 레이블 스무딩이라 부릅니다. 그러나 균등 레이블 스무딩은 잘못된 레이블을 무차별적으로 처벌하여 인간 자세 추정 작업에서 인접한 레이블 간의 공간적 관련성을 무시합니다. 보다 합리적인 해결책은 출력 카테고리가 실제 값에 가까울수록 더 좋게 모델이 작동하도록 유도하는 것입니다. 이 문제를 해결하기 위해, 우리는 라플라스 또는 가우시안 레이블 스무딩을 사용하여 해당 분포를 따르는 부드러운 레이블을 탐구합니다. 별도의 언급이 없는 한, SimCC는 균등 레이블 스무딩을 적용한 변형을 나타내는 약어로 사용됩니다.
3.1 Comparisons to 2D heatmap-based approaches
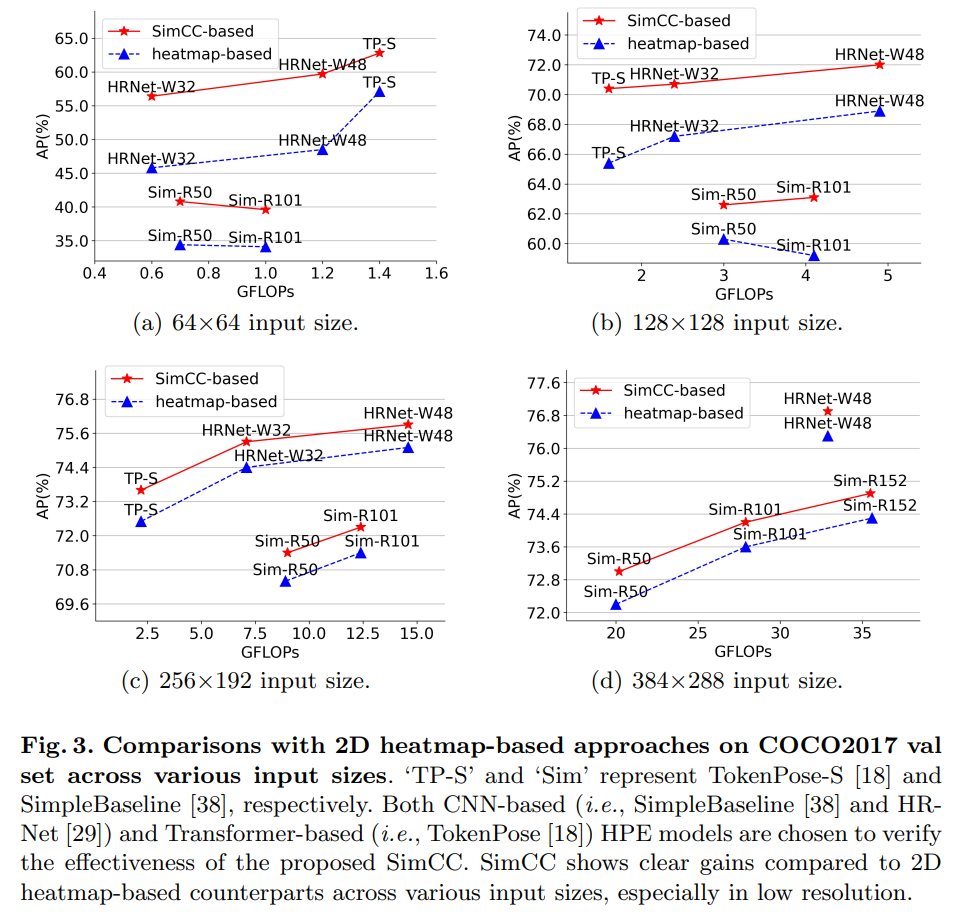
이 부분에서는 SimCC 방식을 2D 히트맵 기반 접근법과 비교하여 우수성을 포괄적으로 조사합니다.
Quantization error.
고해상도의 2차원 구조를 얻거나 유지하는 계산 비용으로 인해, 2D 히트맵 기반 방법은 입력 해상도를 $λ×$ 축소한 피처 맵을 출력하는 경향이 있어 양자화 오류가 크게 확대됩니다. 반면, SimCC는 이산화 과정에서 각 픽셀을 $k (≥1)$ 구간으로 균일하게 나누어 양자화 오류를 줄이고 서브 픽셀 수준의 위치 정밀도를 얻습니다.
Refinement post-processing.
히트맵 기반 접근법은 양자화 오류를 줄이기 위해 추가 후처리(예: 경험적 시프트 및 DARK [43])에 크게 의존합니다. 표 1에 표시된 바와 같이, 히트맵 기반 방법의 성능은 정제를 위한 후처리를 사용하지 않을 경우 크게 감소합니다. 그러나 이러한 후처리 전략은 일반적으로 계산 비용이 많이 들기 때문에 실제 응용에는 적합하지 않습니다. 예를 들어, DARK [43]은 얻어진 2D 히트맵을 기반으로 테일러 전개 및 고차 도함수를 계산해야 합니다. 이에 반해, 제안된 SimCC는 서브 픽셀 수준의 위치 정밀도 덕분에 정제 후처리를 생략하여 HPE에 대한 더 간단한 방식을 제공합니다.
Low/high resolution robustness.
그림 3은 비교 결과를 시각화한 것입니다. 낮은 양자화 오류의 이점을 통해, SimCC 기반 방법은 다양한 입력 크기(예: 64×64, 128×128, 256×192, 384×288)에서 히트맵 기반 방법을 쉽게 능가할 수 있으며, 특히 저해상도 입력에서 명확한 성능 향상을 보여줍니다. 더 구체적인 정량적 결과는 4장에서 논의됩니다.
Speed.
SimCC는 [38]과 같은 방법이 시간 소모적인 디컨볼루션 모듈을 제거할 수 있게 하여 추론 속도를 높입니다. 업샘플링 계층을 제거한 후, SimCC를 적용한 SimpleBaseline-Res50 [38]은 GFLOPs를 57.3% 줄이고, 속도를 23.5% 향상시키며, 히트맵 기반 방법보다 +0.4 AP의 성능을 향상시킵니다. 추가 비교는 4장에서 제시됩니다.
4 Experiments
다음 절에서는 제안된 SimCC의 2D 인간 자세 추정에 대한 효과를 실증적으로 조사합니다. 우리는 COCO [19], CrowdPose [15], MPII [1]의 세 가지 벤치마크 데이터셋에서 실험을 수행합니다.
4.1 COCO Keypoint Detection
HPE를 위한 가장 크고 도전적인 데이터셋 중 하나인 COCO 데이터셋 [19]은 20만 장 이상의 이미지와 25만 개의 사람 인스턴스를 17개의 키포인트(예: 코, 왼쪽 귀 등)로 라벨링하고 있습니다. COCO 데이터셋은 세 부분으로 나뉘며, 학습 세트에는 57k 이미지, 검증 세트에는 5k 이미지, 테스트-개발 세트에는 20k 이미지가 포함됩니다. 본 논문에서는 [29]의 데이터 증강 방식을 따릅니다.
Evaluation metric.
COCO 데이터셋에서 표준 평균 정밀도(AP)를 평가 지표로 사용하며, 이는 객체 키포인트 유사도(OKS)를 기반으로 계산됩니다:
\[\begin{equation} OKS = \frac{\sum_i\exp{(-d_i^2/2s^2j_i^2)\sigma(v_i>0)}}{\sum_i \sigma(v_i>0)}, \end{equation}\]여기서 $d_i$ 는 $i$ 번째 예측된 키포인트 좌표와 해당 좌표의 실제 값 간의 유클리드 거리, $j_i$ 는 상수, $v_i$ 는 가시성 플래그, $σ$ 는 지시 함수, $s$ 는 객체의 크기를 나타냅니다.
Baselines.
HPE를 위한 CNN 기반 및 최근 Transformer 기반 방법이 많이 있습니다. 제안된 SimCC의 우수성을 보여주기 위해, 우리는 CNN 기반에서 두 가지 최신 방법(SimpleBaseline [38] 및 HRNet [29])과 Transformer 기반에서 하나(TokenPose [18])를 기준선으로 선택했습니다.
Implementation details.
선택된 기준선에 대해, 우리는 그들의 논문에서 제시된 원래 설정을 따릅니다. 구체적으로, SimpleBaseline [38]의 경우, 기본 학습률은 $1×10^{-3}$ 로 설정되며, 90번째와 120번째 에포크에서 각각 $1×10^{−4}$ 및 $1×10^{-5}$ 로 감소합니다. HRNet [29]의 경우, 기본 학습률은 $1×10^{−3}$ 로 설정되며, 170번째와 200번째 에포크에서 각각 $1×10^{−4}$ 및 $1×10^{−5}$ 로 감소합니다. 전체 학습 과정은 각각 SimpleBaseline [38]과 HRNet [29]에 대해 140 및 210 에포크 내에 종료됩니다. TokenPose-S의 학습 과정은 [29]을 따릅니다. 본 논문에서는 [29,38,6,25]에 따른 두 단계의 상향식 인간 자세 추정 파이프라인을 사용하며, 먼저 사람 인스턴스를 검출하고 그 후 키포인트를 추정합니다. 우리는 COCO 검증 세트를 위해 [38]에서 제공한 56.4% AP를 가진 대중적인 사람 검출기를 채택했습니다. 또한, 모델 훈련에서 레이블 스무딩을 채택하여 더 나은 일반화를 위한 분류 작업에 흔히 사용되며(기본적으로 0.1로 설정하여 [32]를 따름), 실험은 4개의 NVIDIA Tesla V100 GPU에서 수행됩니다.
Results on the COCO val set.
COCO2017 검증 세트에서 다양한 입력 해상도(64×64, 128×128, 256×192, 384×288)에 걸쳐 2D 히트맵 기반 및 SimCC 기반 방법을 비교하는 광범위한 실험을 수행했습니다. 평가와 네트워크 훈련은 동일한 입력 크기 하에 진행됩니다. 일부 최고 성능의 CNN 기반 및 Transformer 기반 방법을 기준선으로 선택했습니다. 표 1에 제시된 결과는 특히 저해상도 입력 경우에 SimCC 기반 방법이 히트맵 기반 대조군보다 일관된 성능 우위를 보여줌을 나타냅니다. 예를 들어, SimCC 기반 HRNet-W48 [29]은 입력 크기 256×192에서 히트맵 기반 대조군보다 +0.8 AP 더 높은 성능을 나타냅니다. 또한, 저해상도 입력 크기인 64×64에서는 COCO 검증 세트에서 SimCC가 +11.2 AP의 훨씬 더 큰 성능 향상을 보입니다.
표 1에 제시된 결과에 따라, 우리는 다음과 같은 결론을 더 도출할 수 있습니다: 1) 히트맵 기반 접근법은 정제를 위한 후처리에 심각하게 의존하며, 이는 추가 계산 비용을 초래하고 전체 과정을 복잡하게 만듭니다. 예를 들어, TokenPose-S는 DARK [43] 후처리가 없을 경우 입력 크기 64×64에서 AP가 21.2 감소합니다; 2) 제안된 SimCC는 어떠한 정제 후처리 없이도 잘 작동하여, 히트맵 기반 방법에 비해 더 간단하고 효율적인 방식을 제공합니다. 예를 들어, 추가 후처리가 없는 SimCC 기반 HRNet-W48은 입력 크기 256×192에서 히트맵 기반 대조군(경험적 시프트 사용)보다 0.8 AP 높은 성능을 보입니다.
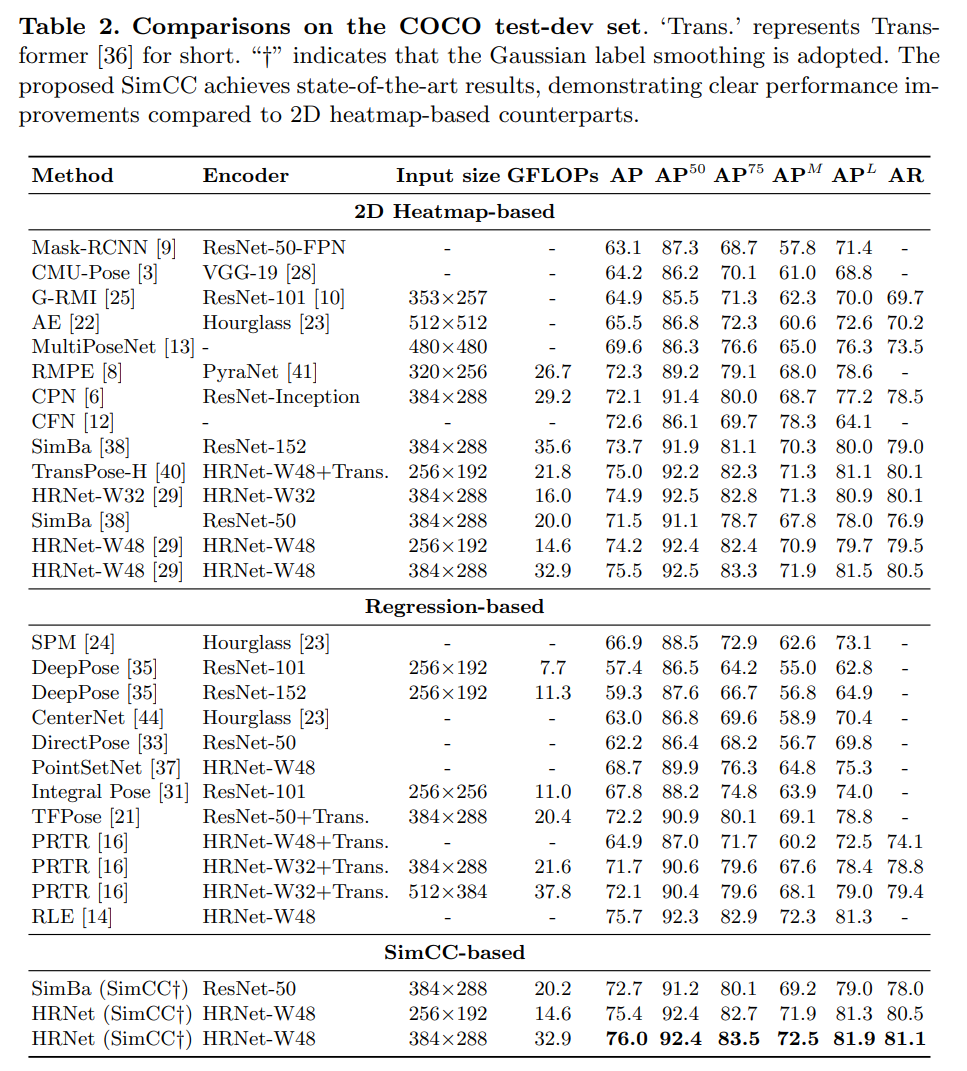
Results on the COCO test-dev set.
COCO 테스트-개발 세트에서 비교를 수행하고, 표 2에 결과를 제시합니다. SimCC 기반 HRNet-W48과 SimpleBaseline-Res50은 각각 입력 크기 384×288에서 히트맵 기반 대조군보다 +0.5 및 +1.2 AP 더 높은 성능을 보입니다.
Inference speed.
SimpleBaseline [38], TokenPose-S [18], HRNet-W48 [29]의 추론 속도에 대한 SimCC의 영향을 논의합니다. 여기서 ‘추론 속도’는 모델 피드포워드에 소요되는 평균 시간을 의미하며(배치 크기=1로 300개의 샘플을 계산합니다), FPS를 사용하여 추론 지연 시간을 정량적으로 나타냅니다. CPU 구현 결과는 동일한 기계인 Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz에서 제공합니다.
1) SimpleBaseline SimCC를 채택하면 SimpleBaseline의 비용이 많이 드는 디컨볼루션 계층을 제거할 수 있습니다. COCO 검증 세트에서 입력 크기 256×192로 SimpleBaseline-Res50 [38]을 통해 실험을 수행했습니다. 디컨볼루션 모듈이 없는 SimCC 기반 방법은 2D 히트맵 기반 대조군보다 +0.4 AP(70.8 vs. 70.4) 더 높은 성능과 23.5% 더 빠른 속도(21 vs. 17 FPS)를 보여줍니다. 디컨볼루션 모듈에 대한 더 구체적인 소거 연구는 4.2장에서 다룹니다.
2) TokenPose&HRNet SimpleBaseline [38]은 인코더-디코더 아키텍처를 사용하므로, 디코더 부분(디컨볼루션)을 SimCC의 분류기 헤드로 대체할 수 있습니다. 그러나 HRNet [29]과 TokenPose [18]의 경우, 디코더로 사용할 독립적인 모듈이 없습니다. SimCC를 적용하기 위해, 우리는 분류기 헤드를 원래 HRNet에 직접 추가하고 TokenPose의 MLP 헤드를 우리의 것으로 각각 교체합니다. 이는 원래 아키텍처에 대한 사소한 변경이므로 HRNet [29]에 대한 계산 오버헤드를 거의 발생시키지 않으며, TokenPose [18]의 경우 모델 매개 변수를 줄입니다. 따라서, SimCC는 HRNet과 TokenPose의 추론 지연 시간에 미미한 영향을 미칩니다. 예를 들어, HRNet-W48이 히트맵 또는 SimCC를 사용할 때 FPS는 입력 크기 256×192에서 거의 동일합니다(4.5/4.8).
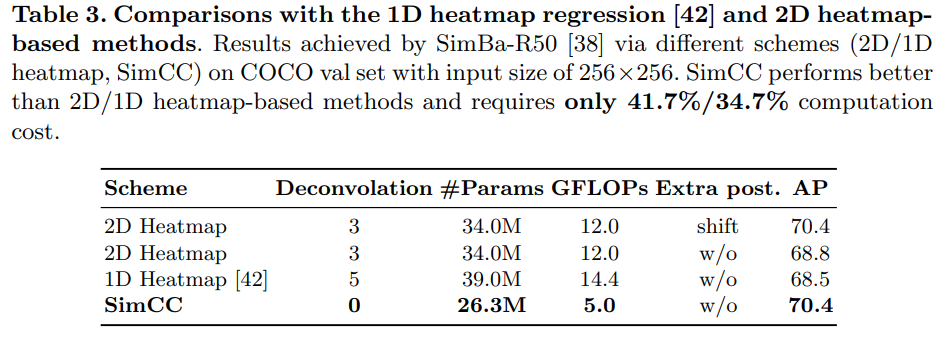
Is 1D heatmap regression a promising solution for HPE?
우리는 얼굴 랜드마크를 위해 처음 설계된 1D 히트맵 [42]을 HPE 분야로 확장하는 성능도 연구합니다. 표 3은 1D 히트맵 회귀 [42]가 모델 매개 변수와 계산 비용을 증가시키지만 2D 히트맵 기반 대조군보다 성능이 오히려 더 낮음을 보여줍니다. 그 원인으로는 얼굴 랜드마크와 HPE의 핵심 과제가 다르기 때문일 수 있습니다: 얼굴 랜드마크는 강체 변형을 갖는 반면 인간의 관절은 훨씬 높은 자유도를 가집니다. [42]의 협업 주의 모듈과 분리 계층은 얼굴 랜드마크 작업에 대해서만 경험적으로 효과가 있음이 검증되었으며, 다른 분야(예: HPE)로의 일반화는 불확실합니다.
4.2 Ablation Study
Splitting factor
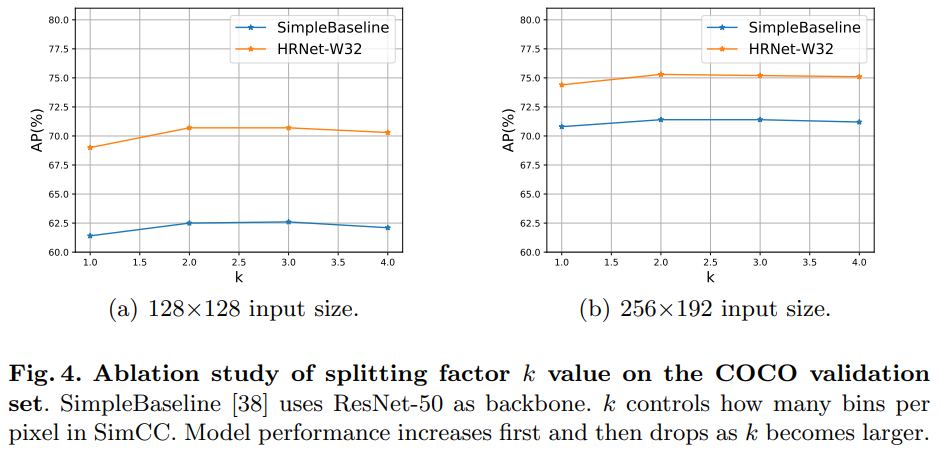
$k.$ 분할 계수 $k$ 는 SimCC에서 픽셀당 구간(bin)의 개수를 조절합니다. 구체적으로, $k$ 가 클수록 SimCC의 양자화 오류는 작아집니다. 그러나 $k$ 가 증가하면 모델 학습이 더 어려워집니다. 따라서 양자화 오류와 모델 성능 간의 균형이 필요합니다. 우리는 다양한 입력 해상도에서 SimpleBaseline [38] 및 HRNet [29]을 기반으로 $k∈{1,2,3,4}$ 를 테스트했습니다. 그림 4에 나타난 바와 같이, 모델 성능은 $k$ 가 증가함에 따라 처음에는 증가하고 이후 감소하는 경향을 보입니다. HRNet-W32 [29]의 경우, 입력 크기 128×128 및 256×192에서 $k=2$ 가 권장 설정입니다. SimBa-Res50 [38]의 경우, 입력 크기 128×128에서는 $k=3$, 256×192에서는 $k=2$ 가 권장됩니다.
Upsampling modules.
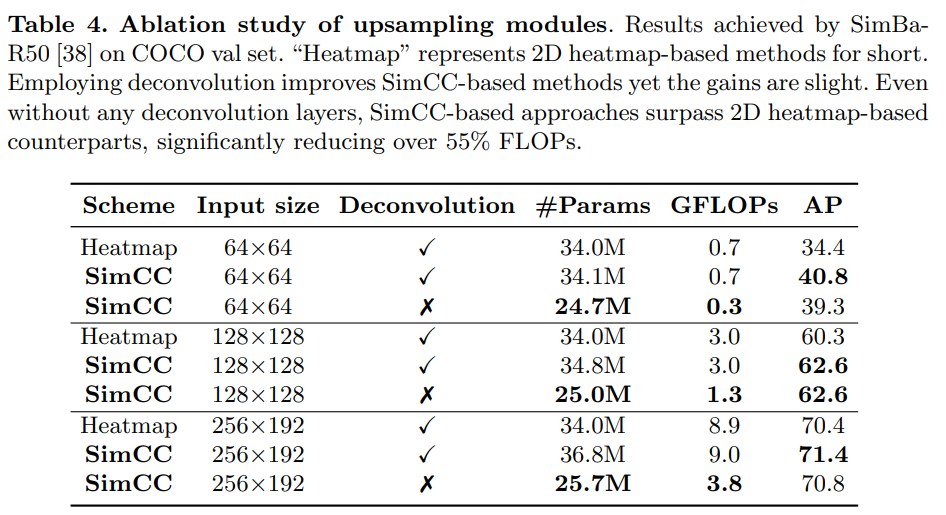
업샘플링 모듈은 일반적으로 계산 비용이 많이 들고 네트워크의 추론 속도를 크게 늦추지만, 히트맵 기반 방법에서는 필수적입니다. 따라서 SimCC를 적용하여 HPE에서 업샘플링 모듈에 대한 의존성을 줄일 수 있는지 탐구하는 것이 실질적인 의미가 있습니다. SimpleBaseline [38]에서 채택한 업샘플링 모듈은 백본과 독립적이므로 쉽게 제거할 수 있습니다. 따라서 우리는 SimpleBaseline [38]을 기반으로 디컨볼루션 모듈이 있는 경우와 없는 경우에 대한 SimCC의 소거 연구를 수행했습니다. 표 4는 COCO2017 검증 데이터셋에서의 결과를 보여줍니다. 히트맵과 비교하여, SimCC는 SimpleBaseline의 비용이 많이 드는 디컨볼루션 계층을 제거할 수 있게 하여 다양한 입력 해상도에서 일관된 계산 비용 감소를 가져옵니다. 예를 들어, 입력 크기 256×192에서 업샘플링 모듈이 없는 SimCC 기반 SimpleBaseline-Res50은 업샘플링 모듈이 있는 히트맵 기반 대조군보다 +0.4 AP 높은 성능을 보여주며 GFLOPs를 57.3% 줄입니다.
Label smoothing.
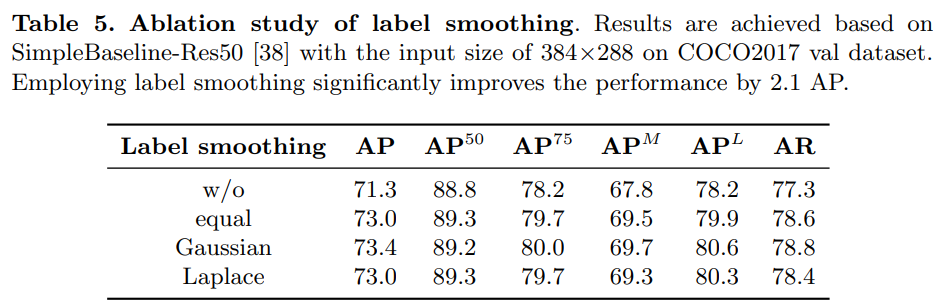
레이블 스무딩 [32]은 분류 작업에서 일반화를 향상시키기 위해 흔히 사용되는 전략입니다. 제안된 방법에 대한 영향을 조사하기 위해, SimCC를 기반으로 SimpleBaseline-Res50 [38]을 다양한 레이블 스무딩 전략({w/o, 균등, 가우시안, 라플라스})으로 학습했습니다. 표 5는 레이블 스무딩 전략이 차이를 만든다는 것을 보여줍니다. 따라서, SimCC를 더욱 향상시키는 유망한 방법으로 자기 적응적인 방식으로 휴리스틱 레이블 스무딩 전략을 대체하는 것이 될 수 있습니다. 추가 논의는 본 논문의 범위를 벗어나므로 향후 연구 과제로 간주합니다.
4.3 CrowdPose
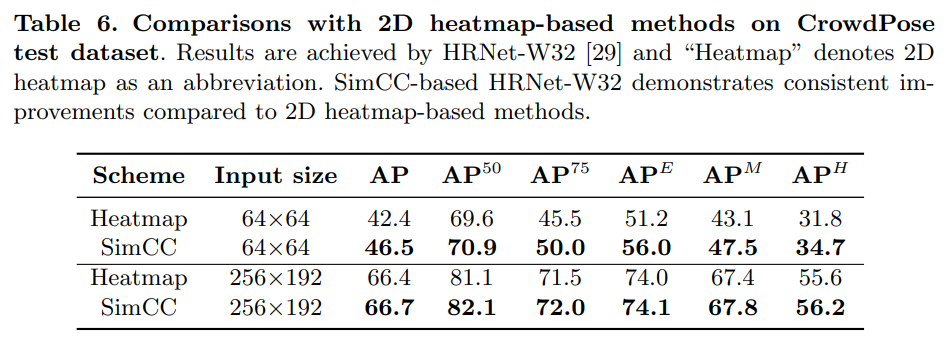
SimCC의 밀집된 자세 장면에서의 성능에 대해 우려할 수 있습니다. 따라서 COCO 키포인트 데이터셋보다 훨씬 많은 밀집 장면을 포함하는 CrowdPose [15] 데이터셋에서 제안된 SimCC의 효과를 추가로 설명합니다. CrowdPose에는 20K 이미지와 80K 사람 인스턴스가 있습니다. 학습, 검증, 테스트 하위 집합은 각각 약 10K, 2K 및 8K 이미지를 포함합니다. COCO [19]와 유사한 평가 지표를 여기서 채택하였으며, 추가적으로 $AP^E$ (상대적으로 쉬운 샘플에 대한 AP 점수)와 $AP^H$ (더 어려운 샘플에 대한 AP 점수)를 사용합니다. 우리는 원 논문 [15]을 따라 사람 검출기로 YoloV3 [26]를 채택하고 배치 크기는 64로 설정했습니다. CrowdPose 테스트 데이터셋에서 입력 크기 64×64 및 256×192로 비교 실험을 수행했습니다. 표 6의 결과는 SimCC 기반 방법이 히트맵 기반 대조군보다 더 높은 성능을 보임을 보여줍니다.
4.4 MPII Human Pose Estimation
MPII 인간 자세 데이터셋 [1]에는 16개의 관절 레이블을 가진 40K 사람 샘플이 포함되어 있습니다. MPII 데이터셋에서 사용된 데이터 증강은 COCO 데이터셋과 동일하다는 점을 지적합니다.
Results on the validation set.
우리는 HRNet [29]의 평가 절차를 따릅니다. 올바른 키포인트에 대한 머리 정규화 확률 (PCKh) [1] 점수가 모델 평가에 사용됩니다. 결과는 표 7에 제시되어 있습니다. 입력 크기 256×256에서 SimCC 기반 방법은 PCKh@0.5에서 경쟁력 있는 성능을 달성하며, 더 엄격한 측정인 PCKh@0.1에서 명확한 성능 향상을 보여줍니다.
5 Limitation and Future Work
본 논문에서 소개된 SimCC는 상향식 인간 자세 추정 설정에서 작동합니다. 하향식 다중 인물 자세 추정으로 전환하면, 여러 사람의 존재로 인해 식별 모호성이 발생합니다. 향후 연구로는 AE [22]와 유사한 방식으로 추가 임베딩을 도입하여 후보 좌표 $x$ 및 $y$ 값 간의 매칭 문제를 해결하는 것이 있습니다.
6 Conclusion
본 논문에서는 간단하지만 유망한 좌표 표현 방식(SimCC)을 탐구합니다. 이는 키포인트 위치 지정 작업을 수평 및 수직 축에 대한 두 개의 독립적인 1D 벡터로 구분하여 $x$ 및 $y$ 좌표로 표현하는 두 가지 분류 하위 작업으로 간주합니다. 실험 결과는 2D 구조가 우수한 성능을 유지하기 위한 좌표 표현의 핵심 요소가 아닐 수 있음을 경험적으로 보여줍니다. 제안된 SimCC는 모델 성능에서 히트맵 기반 표현에 비해 우위를 보여줍니다. 또한, HPE를 위한 경량 모델 설계에 대한 새로운 연구를 고무시킬 수 있습니다.
Yanjie Li, Sen Yang, Peidong Liu, Shoukui Zhang, Yunxiao Wang, Zhicheng Wang, Wankou Yang, Shu-Tao Xia SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation

댓글남기기