

개요
ECCV에 2018년도에 발표 된 Simple Baselines for Human Pose Estimation and Tracking의 얕은 리뷰. 자세 추정에 대한 상당한 진보와 발전 과정에서 알고리즘이나 시스템의 복잡성도 증가했는데, 간단하고 효과적인 구조만으로도 충분한 성능을 달성할 수 있음을 제시한다.
자세 추정과 추적이라는 2가지 task를 다루지만 추적 부분에 대해서는 기반이 되는 레퍼런스 [11]번 논문을 그대로 한다고 말한다. COCO 및 MPII 벤치마크에서 당시 최첨단 성능을 달성한다.
Pose Estimation Using A Deconvolution Head Network
- 해당 논문이 제시하는 baseline 아키텍쳐는 ResNet 백본을 사용한다.
- 마지막 컨볼루션 단계에서 디컨볼루션을 추가하여 업샘플링을 수행한다. 디컨볼루션 블록은 BN과 ReLU 활성화를 가진다.
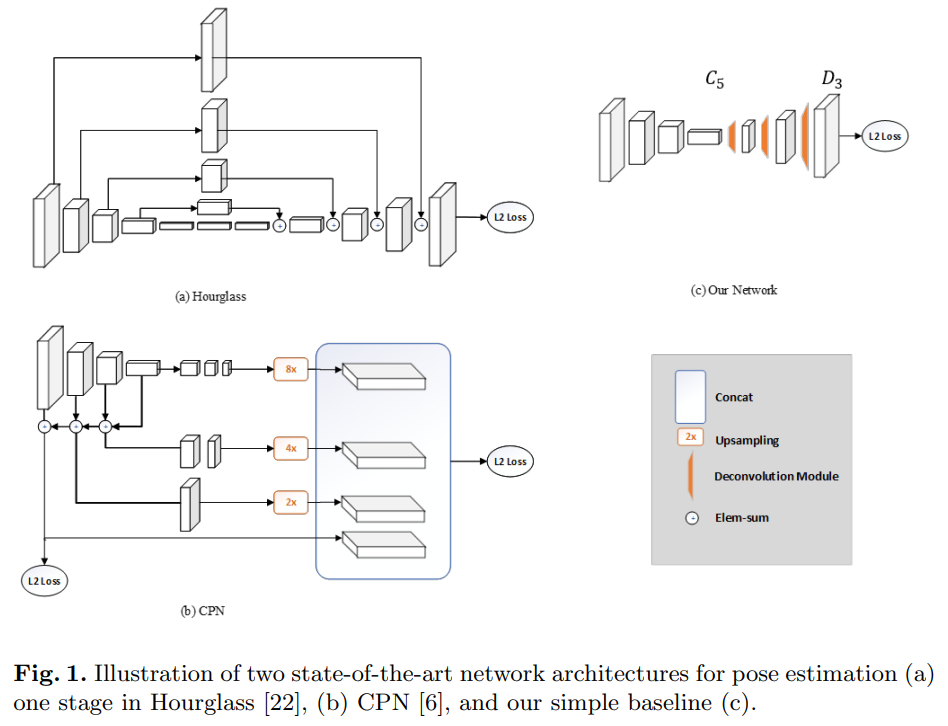
- Hourglass 네트워크와 CPN 과 구조를 비교하긴하지만 논문의 저자는 제일 성능이 좋음에도 불구하고 자신의 방법이 초기적이며 더 나은 아키텍쳐라고 말하는 것은 해당 논문의 의도가 아니라며 조심스러워 한다.
Pose Tracking Based on Optical Flow
- 해당 논문에서 다중 인물 포즈 추적 문제를 해결하는 방법을 설명한다. 각 프레임 별 자세 인스턴스 간의 유사도가 가장 높을 때 그리디 매칭 알고리즘을 통해 이루어진다.
- 단순 한 프레임의 디텍션 정보만을 사용하면 디텍션에 대한 오류가 발생하는 한계가 있다. 그래서 시간정보를 활용하여 인접 프레임으로부터 해당 프레임의 박스를 생성할 것을 제안한다. 정확히는 k-1 번째 프레임에서 k 번째 프레임으로 전달되는 관절 위치를 활용하여 해당 관절 좌표의 경계를 계산하여 바운딩 박스 위치를 추출한다.
- 유사성 계산 시 바운딩 박스의 IoU를 게산하는 것은 정확도가 낮다는 한계를 가지고 있어 포즈의 유사도를 계산하는 OKS를 활용할 것을 제안하는데, 단순 연속된 두 프레임의 유사도를 계산하는 것은 한게가 있으므로, 이전 여러 프레임을 통해 계산한다.
- 이를 통해 특정 길이($L_Q$) 의 디큐 자료구조를 사용하여 특정 프레임을 고려한 추적 기능을 구현한다.
실험
- 학습에 사용한 데이터는 COCO 2017 키포인트 데이터 셋을 사용하였으며, 학습에 사용된 디테일은 논문의 섹션 4.1를 참고한다.
- 소거연구에 대해서 히트맵 해상도, 커널 크기, 백본의 종류, 입력 이미지 크기에 대해서 테스트를 진행한다.
- 또한 Hourglass 및 CPN과 비교하여 해당 baselines 모델과의 비교 진행
- Joint Propagation을 통해 해당 방법론이 모델 별로 감지와 추적에 얼마나 성능을 향상 시키는 지를 확인한다.
- Pose Track 데이터 셋을 통해 단일 프레임에서의 포즈 추정 및 프레임 별 시간적 추적도 검증한다. 추적 성능의 경우 MOTA 추적 메트릭을 사용하여 평가한다. 표 5의 각 비교군에서 $S_{Multi-Flow}$ 방식이 가장 높은 성능을 달성함을 확인할 수 있다.
결론
해당 논문은 단순하고 간단한 구조의 아키텍쳐에서도 강력하고 좋은 성능을 유지하는 사람의 자세 추정과 추적을 위한 네트워크를 제안한다. ResNet 기반 백본에서 COCO 와 PoseTrack 같은 벤치마크 데이터 셋에서 좋은 성능을 달성한다.또한 관절 전파(Joint Propagation)와 흐름 기반의 포즈 유사성 방법론은 더 많은 사람들을 추적하여 추적 성능을 높일 수 있음을 보여준다.
번역
Abstract
최근 몇 년 동안 포즈 추정에 대한 상당한 진전이 있었으며, 포즈 추적에 대한 관심도 증가하고 있다. 동시에 전체 알고리즘과 시스템의 복잡성도 증가하여 알고리즘 분석과 비교가 더 어려워지고 있다. 이 연구는 간단하고 효과적인 기본 방법을 제공한다. 이러한 방법은 해당 분야에서 새로운 아이디어를 고취하고 평가하는 데 도움이 된다. 이 방법은 까다로운 벤치마크에서 최첨단 성과를 달성한다. 코드는 https://github.com/leoxiaobin/pose.pytorch에서 이용할 수 있다.
Keywords: 사람 자세 추정, 사람 자세 추적
1 Introduction
다른 시각적 과제들과 마찬가지로, 인간 포즈 추정 문제에 대한 발전은 딥러닝에 의해 크게 진전되었다. [31, 30]의 선구적인 연구 이후, MPII 벤치마크 [3]에서의 성능은 3년 만에 약 80%의 PCKH@0.5 [30]에서 90% 이상 [22, 8, 7, 33]으로 포화 상태에 이르렀다. 더 최근의 도전적인 COCO 인간 포즈 벤치마크 [20]에서는 그 발전이 더욱 빨랐다. mAP 지표는 1년 만에 60.5 (COCO 2016 챌린지 우승자 [9, 5])에서 72.1 (COCO 2017 챌린지 우승자 [6, 9])로 증가했다. 포즈 추정의 빠른 성숙으로, 최근에는 “자연 환경에서의 동시 포즈 감지 및 추적”이라는 더 도전적인 과제가 도입되었다 [2].
동시에 네트워크 아키텍처와 실험 방법도 점차 복잡해지고 있다. 이는 알고리즘 분석 및 비교를 더욱 어렵게 만든다. 예를 들어, MPII 벤치마크 [3]의 주요 방법들 [22, 8, 7, 33]은 많은 세부 사항에서 상당한 차이가 있지만 정확도에서는 미미한 차이가 있다. 어떤 세부 사항이 중요한지 파악하기 어렵다. 또한, COCO 벤치마크의 대표적인 연구들 [21, 24, 12, 6, 5]도 복잡하지만 상당히 다르다. 이러한 작업들 간의 비교는 주로 시스템 수준에서 이루어지며, 그다지 유익하지 않다. 포즈 추적에 관해서는, 아직 많은 연구가 이루어지지 않았지만 [2], 문제의 차원과 해 공간이 증가함에 따라 시스템의 복잡성은 더욱 증가할 것으로 예상된다.
이 연구는 “간단한 방법이 얼마나 좋을 수 있는가?”라는 반대 방향의 질문을 통해 이 문제를 완화하고자 한다. 이 질문에 답하기 위해, 이 연구는 포즈 추정과 추적을 위한 기본 방법을 제공한다. 이 방법들은 매우 간단하지만 놀랍게도 효과적이다. 따라서, 이 방법들은 새로운 아이디어를 고무하고 그 평가를 간소화하는 데 도움이 될 것으로 기대된다. 코드는 사전 학습된 모델과 함께 연구 커뮤니티의 발전을 위해 공개될 예정이다.
우리의 포즈 추정은 백본 네트워크인 ResNet [13]에 몇 개의 디컨볼루션 레이어를 추가한 것에 기반을 둔다. 이는 깊은 저해상도 특성 맵에서 히트 맵을 추정하는 가장 간단한 방법일 것이다. 우리의 단일 모델의 최상의 결과는 COCO 테스트-개발 분할에서 73.7의 mAP로 최첨단을 달성했으며, 이는 COCO 2017 키포인트 챌린지의 단일 모델과 앙상블 모델 [6, 9]보다 각각 1.6%와 0.7% 향상된 것이다.
우리의 포즈 추적은 ICCV’17 PoseTrack 챌린지 [2] 우승자 [11]와 유사한 파이프라인을 따른다. 단일 인물 포즈 추정은 위에서 설명한 우리의 방법을 사용한다. 포즈 추적은 [11]과 동일한 그리디 매칭 방법을 사용한다. 우리의 유일한 수정은 광학 흐름 기반의 포즈 전파 및 유사성 측정을 사용하는 것이다. 우리의 최상의 결과는 mAP 점수 74.6과 MOTA 점수 57.8을 달성했으며, 이는 ICCV’17 PoseTrack 챌린지 [11, 26] 우승자의 59.6과 51.8보다 절대적으로 15% 및 6% 개선된 것이다. 이것이 새로운 최첨단 기술이다.
이 연구는 이론적 증거에 기반하지 않는다. 이는 간단한 기술에 기반하며, 종합적인 소거 실험을 통해 검증되었다. 더 나은 결과에도 불구하고, 우리는 이전 방법에 비해 알고리즘적 우월성을 주장하지 않는다. 우리는 이전 방법과의 완전하고 공정한 비교를 수행하지 않으며, 이는 어렵고 우리의 의도가 아니다. 앞서 언급한 바와 같이, 이 연구의 기여는 이 분야를 위한 견고한 기준선이다.
2 Pose Estimation Using A Deconvolution Head Network
ResNet [13]은 이미지 특징 추출을 위한 가장 일반적인 백본 네트워크이다. 포즈 추정에도 [24, 6]에서 사용된다. 우리의 방법은 ResNet의 마지막 합성곱 단계(C5) 위에 몇 개의 디컨볼루션 레이어를 간단히 추가한다. 전체 네트워크 구조는 그림 1(c)에 설명되어 있다. 우리는 이 구조를 채택했는데, 이는 깊고 저해상도 특징으로부터 히트맵을 생성하는 가장 간단한 방법이라고 할 수 있으며, 최첨단인 Mask R-CNN [12]에서도 채택되었기 때문이다.
기본적으로, 배치 정규화 [15]와 ReLU 활성화 [19]를 가진 세 개의 디컨볼루션 레이어가 사용된다. 각 레이어는 $4 × 4$ 커널을 가진 256개의 필터를 가진다. 스트라이드는 2이다. 마지막으로 모든 k 키포인트에 대한 예측 히트맵 {$H_1 … H_k$}를 생성하기 위해 $1 × 1$ 합성곱 레이어가 추가된다.
[30, 22]와 마찬가지로, 예측 히트맵과 대상 히트맵 간의 손실로 평균 제곱 오차(MSE)가 사용된다. 조인트 $k$ 에 대한 대상 히트맵 $\hat{H}_k$ 는 $k$ 번째 조인트의 실제 위치를 중심으로 한 2D 가우시안을 적용하여 생성된다.
Discussions 우리의 기준선의 단순성과 합리성을 이해하기 위해, 우리는 두 가지 최첨단 네트워크 아키텍처, 즉 Hourglass [22]와 CPN [6]을 참조로 논의한다. 이들은 그림 1에 설명되어 있다.
Hourglass [22]는 MPII 벤치마크에서 주도적인 접근법으로, 모든 주요 방법 [8, 7, 33]의 기초가 된다. 이는 반복적인 상향식 및 하향식 처리와 스킵 레이어 특징 연결을 갖춘 다단계 아키텍처를 특징으로 한다.
계단식 피라미드 네트워크(CPN) [6]은 COCO 2017 키포인트 챌린지 [9]에서 주도적인 방법이다. 또한 스킵 레이어 특징 연결 및 온라인 하드 키포인트 마이닝 단계를 포함한다.
그림 1에 나타난 세 가지 아키텍처를 비교하면, 우리의 방법은 [22, 6]과 고해상도 특징 맵 생성 방식에서 다르다는 것이 분명하다. 두 연구 [22, 6] 모두 업샘플링을 사용하여 특징 맵 해상도를 높이고, 다른 블록에 합성곱 매개변수를 배치한다. 반면에, 우리의 방법은 스킵 레이어 연결을 사용하지 않고 업샘플링 및 합성곱 매개변수를 디컨볼루션 레이어에 결합하는 훨씬 간단한 방식을 사용한다.
세 가지 방법의 공통점은 세 가지 업샘플링 단계와 세 가지 비선형 수준(가장 깊은 특징으로부터)이 고해상도 특징 맵과 히트맵을 얻기 위해 사용된다는 것이다. 위의 관찰과 우리의 기준선의 좋은 성능을 기반으로, 고해상도 특징 맵을 얻는 것이 중요하다는 것은 분명하지만, 방법은 상관없어 보인다. 이 논의는 초기적이고 휴리스틱하다는 점을 주의하라. 그림 1의 어느 아키텍처가 더 나은지 결론짓기는 어렵다. 이것은 이 연구의 의도가 아니다.
3 Pose Tracking Based on Optical Flow
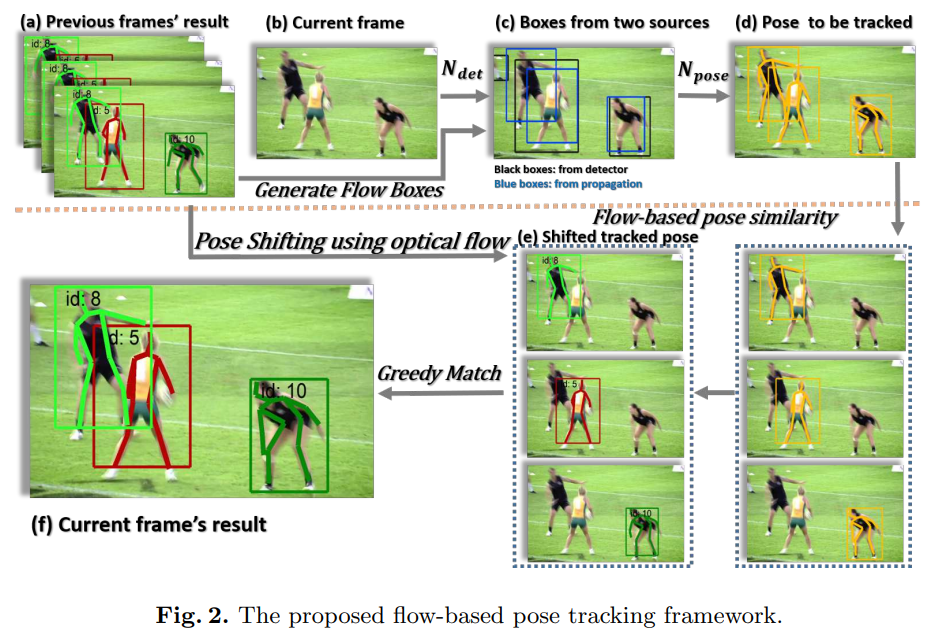
비디오에서 다중 인물 포즈 추적은 먼저 각 프레임에서 인간의 포즈를 추정하고, 그 다음 프레임을 넘어서 이 포즈에 고유한 ID를 할당하여 추적합니다. 우리는 인스턴스 $P$ 를 $P = (J, id)$로 나타내며, 여기서 $J = {j_i}_{1:N_k}$ 는 $N_J$ 개의 신체 관절 좌표 세트를 나타내고, $id$ 는 추적 id를 의미합니다. $k$ 번째 프레임 $I^k$ 를 처리할 때, 우리는 이미 처리된 인스턴스 세트 $\mathcal{P}^{k−1}={P_i^{k-1}}_{1:N_{k-1}}$ 을 $I^{k−1}$ 프레임에서 가지며, 이 프레임에서 할당될 $id$ 를 가지는 인스턴스 세트 $\mathcal{P}_k$ 는 $N_{k−1}$ 및 $N_k$ 의 인스턴스 수를 나타냅니다. 현재 프레임 $I^k$의 인스턴스 $P^k_j$ 가 이전 프레임 $I^{k−1}$ 의 인스턴스 $P^{k−1}_i$ 와 연결된다면 $id^{k−1}_i$ 는 $id^k_j$ 로 전파되고, 그렇지 않은 경우 새로운 $id$가 $P^k_j$ 에 할당되어 새로운 트랙을 나타냅니다.
ICCV’17 PoseTrack Challenge [2]의 우승자 [11]는 Mask R-CNN [12]을 사용하여 프레임에서 인간 포즈를 추정하고, Greedy 이분 그래프 매칭 알고리즘을 사용하여 프레임별로 온라인 추적을 수행하여 이 다중 인물 포즈 추적 문제를 해결했습니다.
그리디 매칭 알고리즘은 먼저 프레임 $I^{k−1}$ 의 $P^{k−1}_i$ 의 $id$ 를 프레임 $I^k$ 의 $P^k_j$ 에 할당하는데, 이는 $P^{k−1}_i$ 와 $P^k_j$ 사이의 유사도가 가장 높을 때 이루어집니다. 그런 다음 이 두 인스턴스를 고려에서 제외하고, 가장 높은 유사성을 가진 $id$ 할당 과정을 반복합니다. 프레임 $I^k$ 에서 인스턴스 $P^k_j$ 가 연결할 기존 $P^{k−1}_i$ 가 없을 경우, 새로운 $id$ 번호가 할당되어 새로운 인스턴스가 등장했음을 나타냅니다.
우리는 주로 [11]에서 이 파이프라인을 따르지만, 두 가지 차이가 있습니다. 하나는 인물 감지기에서 가져온 인간 박스와, 다른 하나는 광학 흐름을 사용하여 이전 프레임에서 생성된 박스입니다. 두 번째 차이는 그리디 매칭 알고리즘에서 사용되는 유사성 메트릭입니다. 우리는 광학 흐름 기반의 포즈 유사성 메트릭을 사용할 것을 제안합니다. 이 두 가지 수정 사항을 결합하여, 우리는 그림 2에 설명된 향상된 광학 흐름 기반 포즈 추적 알고리즘을 갖추게 되었습니다. 다음에서 우리는 우리의 광학 흐름 기반 포즈 추적 알고리즘을 자세히 설명할 것입니다.
3.1 Joint Propagation using Optical Flow
단일 이미지 레벨에 맞춰 설계된 검출기(예: Faster-RCNN [27], R-FCN [16])를 비디오에 적용하면, 비디오 프레임에 의해 발생한 모션 블러 및 가림 현상으로 인해 검출 누락과 잘못된 검출이 발생할 수 있다. 그림 2(c)에 나타난 바와 같이, 빠른 움직임으로 인해 검출기가 왼쪽의 검은 옷을 입은 사람을 놓친다. 시간 정보를 활용하면 더 견고한 검출을 생성할 수 있다 [36, 35].
우리는 광학 흐름에 표현된 시간 정보를 사용하여 인접 프레임에서 처리 중인 프레임의 박스를 생성할 것을 제안한다.
프레임 $I^{k−1}$ 에서 관절 좌표 세트 $J^{k−1}_i$ 을 가진 하나의 인물 인스턴스와 프레임 $I^{k−1}$ 과 $I^k$ 사이의 광학 흐름 필드 $F_{k−1→k}$가 주어졌을 때, 우리는 관절 좌표 세트 $J^{k−1}$ 을 $F_{k−1→k}$ 에 따라 전파하여 프레임 $I^k$ 에서 대응되는 관절 좌표 세트 $\hat{J}^k_i$를 추정할 수 있다. 더 구체적으로, $J^{k−1}_i$ 의 각 관절 위치 $(x, y)$ 에 대해, 전파된 관절 위치는 $(x + δx, y + δy)$ 가 되며, 여기서 $δx$ 와 $δy$ 는 관절 위치 $(x, y)$ 에서의 흐름 필드 값이다. 그런 다음 우리는 전파된 관절 좌표 세트 $\hat{J}^k_i$ 의 경계를 계산하고, 실험에서 15% 확장한 박스를 포즈 추정의 후보 박스로 확장한다.
처리 프레임에서 모션 블러 또는 가림으로 인해 인물 검출이 어려울 경우, 우리는 이전 프레임에서 인물들이 정확하게 검출된 박스를 전파할 수 있다. 그림 2(c)에 나타난 바와 같이, 이미지에서 왼쪽 검은 옷을 입은 사람에 대해 우리는 그림 2(a)의 이전 프레임에서 추적된 결과를 가지고 있으므로, 전파된 박스가 이 사람을 성공적으로 포함한다.
3.2 Flow-based Pose Similarity
바운딩 박스 IoU(교차-연합) 값을 유사성 메트릭($S_{Bbox}$)으로 사용하여 인스턴스를 연결하는 것은 인스턴스가 빠르게 움직일 때 박스가 겹치지 않거나, 혼잡한 장면에서는 박스가 인스턴스와 상응하는 관계를 가지지 않을 수 있기 때문에 문제가 될 수 있다. 더 세밀한 메트릭으로는 포즈 유사성($S_{pose}$)이 있을 수 있으며, 이는 Object Keypoint Similarity(OKS)를 사용하여 두 인스턴스 사이의 신체 관절 거리를 계산한다. 포즈 유사성도 포즈 변경으로 인해 동일 인물의 포즈가 프레임마다 다를 때 문제가 될 수 있다. 우리는 흐름 기반의 포즈 유사성 메트릭을 사용할 것을 제안한다.
프레임 $I^k$에서의 인스턴스 $J^k_i$ 와 프레임 $I^l$ 에서의 인스턴스 $J^l_j$ 가 주어졌을 때, 흐름 기반 포즈 유사성 메트릭은 다음과 같이 표현된다.
여기서 $OKS$ 는 두 인간 포즈 간의 Object Keypoint Similarity(OKS)를 계산하며, $\hat{J}^l_i$는 프레임 $I^k$ 에서 $I^l$ 로 광학 흐름 필드 $F_{k→l}$을 사용하여 $J^k_i$를 전파한 관절을 나타낸다.
다른 사람이나 물체에 의해 가려지면 사람은 자주 사라졌다가 다시 나타난다. 연속된 두 프레임만 고려하는 것은 충분하지 않으므로, 우리는 다중 프레임을 고려한 흐름 기반 포즈 유사성 $S_{Multi-flow}$를 도입하였으며, 이는 전파된 $\hat{J}_k$가 여러 이전 프레임에서 유래했음을 의미한다. 이를 통해 중간 프레임에서 사라진 인스턴스도 다시 연결할 수 있다.
3.3 Flow-based Pose Tracking Algorithm
우리는 광학 흐름을 사용한 관절 전파와 흐름 기반 포즈 유사성을 결합한 흐름 기반 포즈 추적 알고리즘을 제안한다. 이 알고리즘은 알고리즘 1에 제시되었다. 표 1은 알고리즘 1에서 사용된 표기법을 요약한다.
먼저, 우리는 포즈 추정 문제를 해결한다. 비디오에서 처리 중인 프레임에 대해, 인물 검출기에서 나온 박스와 이전 프레임에서 관절을 전파하여 생성된 박스는 바운딩 박스 NMS(Non-Maximum Suppression) 연산을 통해 통합된다. 관절 전파로 생성된 박스는 검출기의 누락된 검출을 보완하는 역할을 한다(예: 그림 2(c)). 그런 다음 우리는 이 박스를 통해 잘라내고 크기를 조정한 이미지를 사용하여 2장에서 제안한 포즈 추정 네트워크로 인간 포즈를 추정한다.
두 번째로, 우리는 추적 문제를 해결한다. 우리는 추적된 인스턴스를 고정된 길이 $L_Q$ 를 가진 이중 큐(Deque)에 저장하며, 이를 다음과 같이 나타낸다.
\[\begin{equation} Q = [\mathcal{P}_{k−1}, \mathcal{P}_{k−2}, ..., \mathcal{P}_{k−L_Q}] \end{equation}\]여기서 $\mathcal{P}_{k-1}$ 은 이전 프레임 $I^{k-i}$에서 추적된 인스턴스 세트를 의미하며 $Q$ 의 길이 $L_Q$ 는 매칭을 수행할 때 얼마나 많은 이전프레임이 고려되야 하는지를 나타낸다.
$Q$ 는 비디오의 첫 프레임에서 초기화되어 이전 여러 프레임의 연결 관계를 캡처하는 데 사용될 수 있다. $k$ 번째 프레임 $I^k$ 에서는 추적되지 않은 신체 관절 $\mathcal{J}^k$ 의 인스턴스 세트와 $Q$ 의 이전 인스턴스 세트 간의 흐름 기반 포즈 유사성 매트릭스 $M_{sim}$ 을 계산한다. 그런 다음 그리디 매칭과 $M_{sim}$ 을 사용하여 각 신체 관절 인스턴스 $\mathcal{J}$ 에 $id$ 를 할당하여 인스턴스 세트 $\mathcal{P}^k$ 를 얻는다. 마지막으로 $k$ 번째 프레임 인스턴스 세트 $\mathcal{P}^k$ 를 추가하여 추적된 인스턴스 $Q$ 를 업데이트한다.
4 Experiments
4.1 Pose Estimation on COCO
COCO 키포인트 챌린지 [20]는 여러 사람의 키포인트를 어려운 비제어 환경에서 로컬화할 것을 요구한다. COCO 학습, 검증, 테스트 세트는 20만 개 이상의 이미지와 키포인트가 라벨링된 25만 개의 사람 인스턴스를 포함한다. 이 중 15만 개의 인스턴스는 학습 및 검증을 위해 공개적으로 이용 가능하다. 우리의 모델은 COCO train2017 데이터셋(57K 이미지 및 150K 사람 인스턴스를 포함)에 대해서만 학습되었고 추가 데이터는 사용되지 않았다. 우리는 val2017 세트에서 소거 연구를 수행했고, 마지막으로 test-dev2017 세트에서 최종 결과를 보고하여 공개된 최신 결과와 공정하게 비교한다 [5, 12, 24, 6].
COCO 평가에서는 객체 키포인트 유사성(OKS)을 정의하고, 주요 경쟁 메트릭으로 10개의 OKS 임계값에 대한 평균 정밀도(AP)를 사용한다 [9]. OKS는 객체 검출에서 IoU와 동일한 역할을 한다. 이는 예측된 점과 실제 점 사이의 거리를 사람의 크기로 정규화하여 계산된다.
Training
실제 인물 상자는 고정된 가로 세로 비율(예: 높이 : 너비 = 4 : 3)로 만들어지며, 상자의 높이 또는 너비를 확장하여 설정된다. 그런 다음 이미지에서 잘라내고 고정된 해상도로 크기를 조정한다. 기본 해상도는 256 : 192이다. 이는 공정한 비교를 위해 최신 방법 [6]과 동일하다. 데이터 증강에는 스케일(±30%), 회전(±40도), 및 뒤집기가 포함된다.
우리의 ResNet [13] 백본 네트워크는 ImageNet 분류 작업 [28]에서 사전 학습을 통해 초기화된다. 포즈 추정을 위한 학습에서 기본 학습률은 1e-3이다. 90 에포크에서는 1e-4로, 120 에포크에서는 1e-5로 감소한다. 총 140 에포크가 있다. 미니 배치 크기는 128이다. Adam [18] 옵티마이저가 사용되며, GPU 서버에서 4개의 GPU가 사용된다.
깊이 50, 101, 152 레이어의 ResNet이 실험되었으며, 별도로 언급되지 않는 한 기본적으로 ResNet-50이 사용된다.
Testing
[24, 6]과 유사하게, 두 단계의 상향식 패러다임이 적용된다. 검출의 경우, 기본적으로 우리는 COCO val2017에서 사람 범주에 대해 56.4의 AP를 가진 faster-RCNN [27] 검출기를 사용한다. [6, 22]에서의 일반적인 방법을 따라, 관절 위치는 원본 이미지와 뒤집힌 이미지의 평균 히트맵에서 예측된다. 가장 높은 응답에서 두 번째로 높은 응답까지의 방향에서 1/4의 오프셋이 사용되어 최종 위치를 얻는다.
Ablation Study
표 2는 섹션 2에서 설명한 우리의 기준선에 대한 다양한 옵션을 조사합니다.
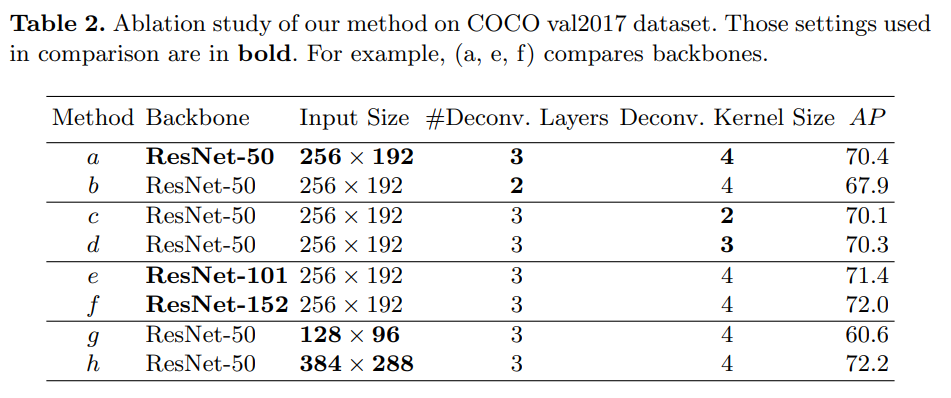
- Heat map resolution (히트맵 해상도) 방법 (a)은 3개의 디컨볼루션 레이어를 사용하여 64 × 48 히트맵을 생성합니다. 방법 (b)는 2개의 디컨볼루션 레이어로 32 × 24 히트맵을 생성합니다. 방법 (a)는 모델 용량이 약간 증가했지만, (b)보다 2.5 AP가 더 높습니다. 기본적으로 3개의 디컨볼루션 레이어가 사용됩니다.
- Kernel size (커널 크기) 방법 (a, c, d)는 더 작은 커널 크기가 AP를 약간 감소시키며, 커널 크기가 4에서 2로 줄어들면서 0.3 포인트가 감소함을 보여줍니다. 기본적으로 4 크기의 디컨볼루션 커널이 사용됩니다.
- Backbone (백본) 대부분의 시각 작업에서와 같이, 더 깊은 백본 모델이 더 나은 성능을 보입니다. 방법 (a, e, f)는 더 깊은 백본 모델을 사용함으로써 성능이 점진적으로 향상됨을 보여줍니다. ResNet-50에서 ResNet-101로 AP가 1.0 증가하고, ResNet-50에서 ResNet-152로 AP가 1.6 증가합니다.
- Image size (이미지 크기) 방법 (a, g, h)는 이미지 크기가 성능에 중요함을 보여줍니다. 방법 (a)에서 (g)로 갈수록 이미지 크기가 절반으로 줄어들면서 AP가 감소합니다. 반면, 상대적으로 75%의 연산이 절약됩니다. 방법 (h)는 더 큰 이미지 크기를 사용하며, 연산 비용이 증가하는 대신 방법 (a)보다 1.8 AP가 증가합니다.
Comparison with Other Methods on COCO val2017
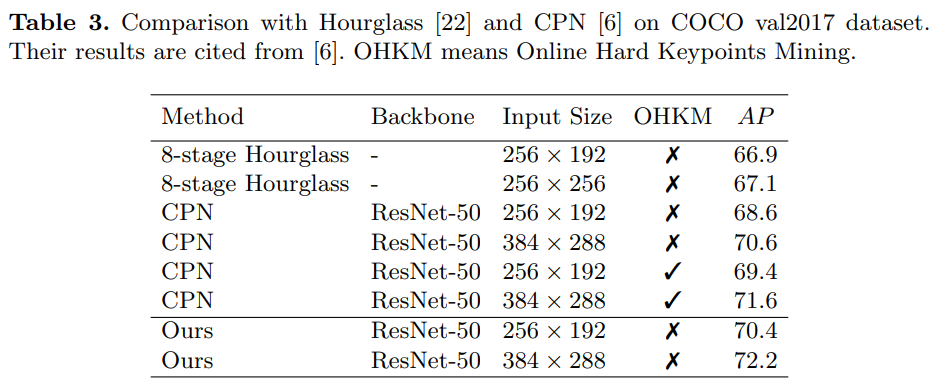
표 3은 우리의 결과를 8단계 Hourglass [22] 및 CPN [6]과 비교합니다. 세 가지 방법 모두 유사한 상향식 2단계 패러다임을 사용합니다. 참고로, Hourglass [22]와 CPN [6]의 인물 검출 AP는 55.3이며, 우리의 56.4와 비교할 만합니다.
Hourglass [22, 6]과 비교할 때, 우리의 기준선은 AP에서 3.5의 향상을 보였습니다. 두 방법 모두 입력 크기 256 × 192를 사용하며, Online Hard Keypoints Mining(OHKM)은 사용되지 않았습니다.
CPN [6]과 우리의 기준선은 동일한 ResNet-50 백본을 사용합니다. OHKM이 사용되지 않은 경우, 우리의 기준선은 입력 크기 256 × 192에서 CPN [6]보다 AP가 1.8 높고, 입력 크기 384 × 288에서는 1.6 AP가 더 높습니다. CPN [6]에서 OHKM이 사용된 경우에도, 우리의 기준선이 두 입력 크기에서 AP가 0.6 더 높습니다.
Hourglass [22] 및 CPN [6]의 결과는 [6]에서 인용되었으며, 우리가 구현한 것은 아닙니다. 따라서 성능 차이는 구현상의 차이에서 비롯될 수 있습니다. 그럼에도 불구하고, 우리의 기준선이 비슷한 결과를 보이지만 더 간단하다고 결론 내릴 수 있을 것입니다.
Comparisons on COCO test-dev dataset
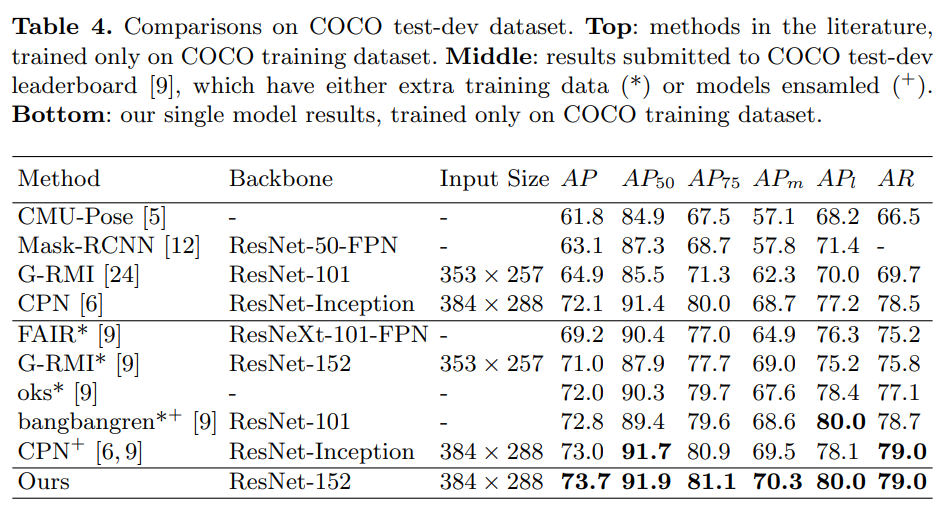
표 4는 COCO 키포인트 리더보드 [9]와 COCO test-dev 데이터셋에서 문헌에 기록된 다른 최신 방법들의 결과를 요약합니다. 여기서 우리의 기준선은 COCO std-dev 스플릿 데이터셋에서 사람 검출 AP가 60.9인 인물 검출기를 사용합니다. 참고로, CPN [6]은 COCO minival 스플릿 데이터셋에서 사람 검출 AP가 62.9인 인물 검출기를 사용합니다.
다중 인물 포즈 추정을 위한 하향식 접근 방식인 CMU-Pose [5]와 비교할 때, 우리의 방법이 현저히 더 우수합니다. G-RMI [24]와 CPN [6]은 우리와 유사한 상향식 파이프라인을 가지고 있습니다. G-RMI 역시 ResNet을 백본으로 사용하며, 동일한 ResNet-101 백본을 사용할 때, 우리의 방법이 작은 입력 크기(256 × 192)와 큰 입력 크기(384 × 288) 모두에서 G-RMI보다 우수한 성능을 보입니다. CPN은 ResNet-Inception [29]이라는 더 강력한 백본을 사용합니다. 증거로, ImageNet 검증 세트에서 ResNet-Inception의 top-1 오류율은 18.7%, ResNet-152는 21.4%입니다 [29]. 그러나 동일한 입력 크기(384 × 288)에서, 우리의 결과 73.7은 CPN의 단일 모델과 앙상블 모델(각각 72.1 및 73.0)을 능가합니다.
4.2 Pose Estimation and Tracking on PoseTrack

PoseTrack [2] 데이터셋은 비디오에서 다중 인물 포즈 추정 및 추적을 위한 대규모 벤치마크입니다. 이는 단일 프레임에서의 포즈 추정뿐만 아니라, 프레임 간 시간적 추적도 요구합니다. 총 66,374 프레임을 포함한 514개의 비디오가 있으며, 이는 각각 300개의 학습 비디오, 50개의 검증 비디오, 208개의 테스트 비디오로 나뉩니다.
학습 비디오에서는 중앙의 30개 프레임에 주석이 달려 있습니다. 검증 및 테스트 비디오의 경우 중앙의 30개 프레임 외에도, 긴 거리 관절 추적을 평가하기 위해 매 4번째 프레임마다 주석이 달려 있습니다. 주석에는 15개의 신체 키포인트 위치, 고유한 인물 ID, 각 인물 인스턴스에 대한 머리 바운딩 박스가 포함됩니다.
이 데이터셋에는 세 가지 작업이 있습니다. 작업 1은 [25]에서처럼 평균 정밀도(mAP) 메트릭을 사용하여 단일 프레임 포즈 추정을 평가합니다. 작업 2는 또한 포즈 추정을 평가하지만, 프레임 간 시간 정보의 사용을 허용합니다. 작업 3은 다중 객체 추적 메트릭을 사용하여 추적을 평가합니다. 우리의 추적 기준선은 시간 정보를 사용하므로, 작업 2 및 3의 결과를 보고합니다. 우리의 포즈 추정 기준선이 작업 1에서도 가장 우수한 성능을 보였지만, 간결성을 위해 여기서는 보고되지 않았습니다.
Training
우리의 포즈 추정 모델은 4.1장에서 COCO에서 사전 학습된 모델을 미세 조정한 것입니다. 키포인트만 주석이 달려 있기 때문에, 우리는 모든 키포인트의 바운딩 박스를 길이로 15% 확장하여 인물 인스턴스의 실제 바운딩 박스를 얻습니다(양쪽에서 각각 7.5%). 4.1장에서와 동일한 데이터 증강이 사용되었습니다. 학습 중에는 기본 학습률이 1e-4입니다. 10 에포크에서는 1e-5로, 15 에포크에서는 1e-6로 감소합니다. 총 20 에포크가 있습니다. 다른 하이퍼파라미터는 4.1장에서와 동일합니다.
Testing
우리의 흐름 기반 추적 기준선은 인물 검출기의 성능과 밀접하게 관련이 있으며, 이는 전파된 박스가 검출기로부터의 박스에 영향을 미칠 수 있기 때문입니다. 그 효과를 조사하기 위해, 우리는 더 빠르지만 덜 정확한 R-FCN [16]과 더 느리지만 더 정확한 FPN-DCN [10] 두 가지 검출기로 실험합니다. 두 검출기 모두 ResNet-101 백본을 사용하며, 공용 구현에서 얻었습니다 [1]. PoseTrack 데이터셋에서의 추가적인 검출기 미세 조정은 수행되지 않았습니다.
[11]과 유사하게, 우리는 먼저 신뢰도가 낮은 검출을 제외하며, 이는 mAP 메트릭을 감소시키지만 MOTA 추적 메트릭을 증가시킵니다. 또한, MOT 추적 메트릭은 점수에 상관없이 잘못된 양성에 대해 동일하게 페널티를 부과하므로, 우리는 [11]에서처럼 먼저 신뢰도가 낮은 관절을 제외한 후 결과를 생성합니다. 우리는 검증 세트에서 데이터 기반 방식으로 박스 및 관절 드롭 임계값을 선택했으며, 각각 0.5와 0.4로 설정했습니다.
광학 흐름 추정을 위해, FlowNet 계열에서 가장 빠른 모델인 FlowNet2S [14]를 사용하였으며, 이는 [23]에서 제공됩니다. 우리는 PoseTrack 평가 툴킷을 사용하여 검증 세트의 결과를 산출하고, 평가 서버에서 테스트 세트의 최종 결과를 보고합니다.
우리의 주요 소거 연구는 입력 크기 256×192의 ResNet-50에서 수행되었으며, 이는 최신 기술과 비교해도 이미 강력합니다. 우리의 최고 결과는 입력 크기 384×288의 ResNet-152에서 나왔습니다.
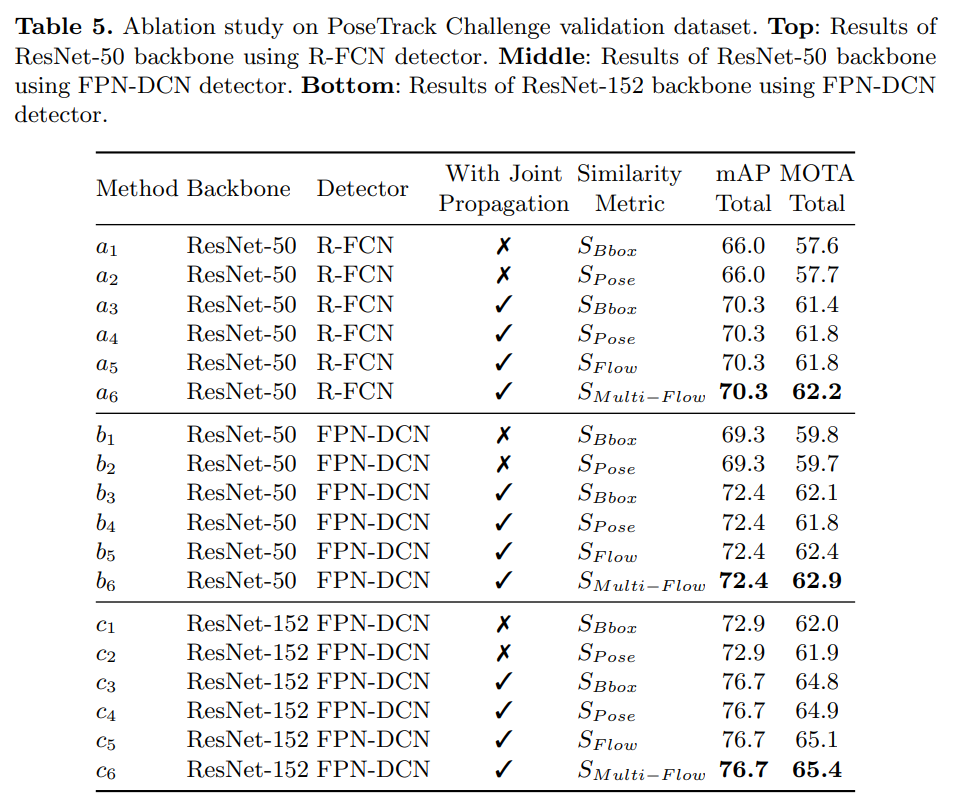
Effect of Joint Propagation
표 5는 관절 전파에서 나온 박스를 사용하면 다양한 백본과 검출기를 사용할 때 mAP와 MOTA 메트릭 모두에서 향상이 있음을 보여줍니다. R-FCN 검출기를 사용할 때, 관절 전파에서 나온 박스를 사용하면 (방법 a₃ 대 a₁) mAP에서 4.3%와 MOTA에서 3.8%의 향상을 보입니다. 더 나은 FPN-DCN 검출기를 사용할 때, 관절 전파에서 나온 박스를 사용하면 (방법 b₃ 대 b₁) mAP에서 3.1%와 MOTA에서 2.3%의 향상을 보입니다. ResNet-152를 백본으로 사용할 때 (방법 c₃ 대 c₁), mAP에서 3.8%, MOTA에서 2.8%의 향상이 있습니다. 이러한 향상은 더 많은 박스 때문만은 아닙니다. [11]에서 언급된 바와 같이, 단순히 더 많은 박스를 유지하면 (예: 작은 임계값을 사용하여) mAP가 향상되지만 더 많은 잘못된 긍정 결과가 도입되기 때문에 MOTA는 감소할 것입니다. 관절 전파는 mAP와 MOTA 메트릭을 모두 향상시키며, 이는 동영상 프레임에서 모션 블러나 가림으로 인해 검출기에 의해 놓친 사람들을 더 많이 찾아낸다는 것을 나타냅니다.
또한 흥미로운 점은 덜 정확한 R-FCN 검출기가 관절 전파로부터 더 많은 이득을 본다는 것입니다. 예를 들어, ResNet-50에서 FPN-DCN과 R-FCN 검출기 사이의 차이는 mAP에서 3.3%, MOTA에서 2.2%에서 (a₁에서 b₁로) mAP에서 2.1%, MOTA에서 0.4%로 감소합니다 (a₃에서 b₃로). 또한, 방법 a₃는 mAP에서 1.0%, MOTA에서 1.6% 더 나은 성능을 보이며, 이는 약한 검출기 R-FCN이 관절 전파와 결합되면 강한 검출기 FPN-DCN 단독보다 더 나은 성능을 발휘할 수 있음을 나타냅니다. 반면, 전자는 관절 전파가 빠르기 때문에 더 효율적입니다.
Effect of Flow-based Pose Similarity
표 5에서 흐름 기반 포즈 유사성이 바운딩 박스 유사성과 포즈 유사성과 비교할 때 더 나은 성능을 보였습니다. 예를 들어, 다중 프레임을 사용하는 흐름 기반 유사성(방법 b₆)과 단일 프레임(방법 b₅)은 바운딩 박스 유사성(방법 b₃)보다 MOTA에서 각각 0.8%와 0.3% 더 나은 성능을 보였습니다.
사람이 빠르게 움직이고 박스가 겹치지 않을 때, 흐름 기반 포즈 유사성은 바운딩 박스 유사성보다 우수합니다. 흐름 기반 포즈 유사성을 사용하는 방법 b₆는 다중 프레임을 고려하며, 이전 프레임만 고려하는 방법 b₅와 비교했을 때 MOTA가 0.5% 개선되었습니다. 이러한 개선은 가림으로 인해 사람이 잠시 사라졌다가 다시 나타나는 경우에서 비롯됩니다.
Comparison with State-of-the-Art
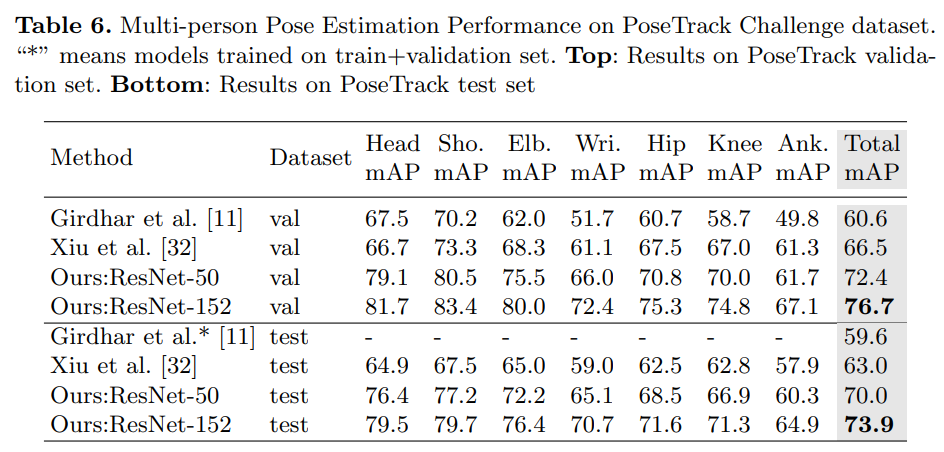
우리는 PoseTrack 데이터셋의 작업 2와 작업 3에서의 결과를 보고합니다. 표 5에서 확인되었듯이, 방법 b₆와 c₆는 최상의 설정이며, 여기서 사용됩니다. 백본은 각각 ResNet-50과 ResNet-152이며, 검출기는 FPN-DCN [10]입니다.
표 6은 포즈 추정(작업 2)에 대한 결과를 보여줍니다. 우리의 작은 모델(ResNet-50)은 이미 다른 방법들보다 큰 차이로 성능이 우수합니다. 우리의 더 큰 모델(ResNet-152)은 최신 기술을 더욱 향상시킵니다. 검증 세트에서 [11]과 비교하여 mAP에서 16.1%의 절대적인 개선을 보였으며, 이는 ICCV’17 PoseTrack 챌린지의 우승자입니다. 또한 최근 작업 [32]보다 10.2% 개선되었습니다.
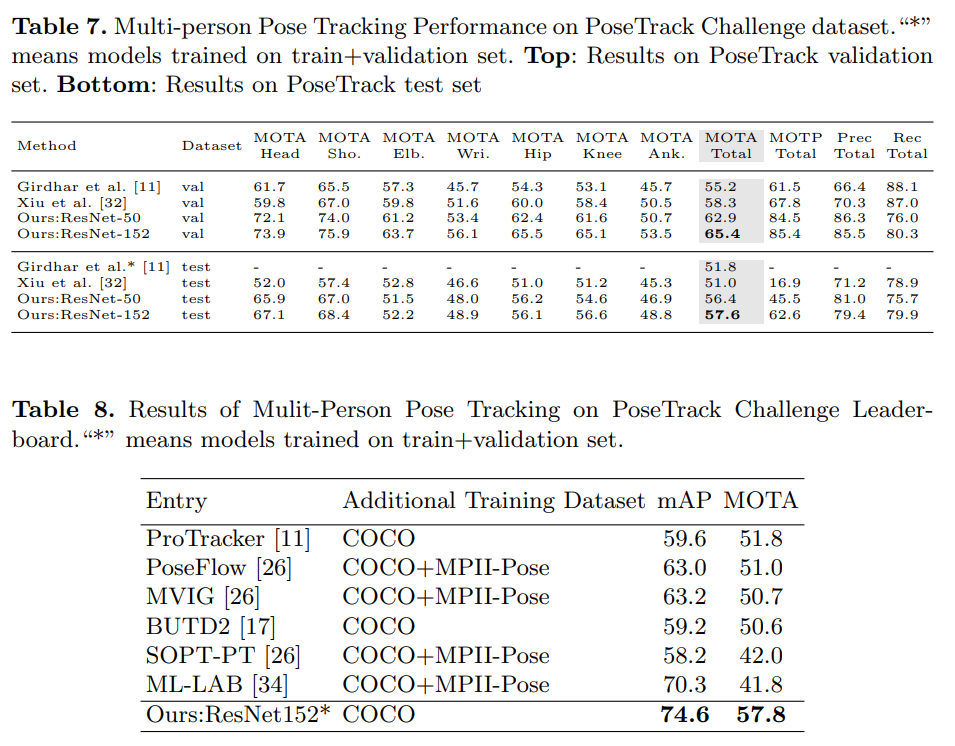
표 7은 포즈 추적(작업 3)에 대한 결과를 보고합니다. 검증 세트와 테스트 세트에서 [11]과 비교했을 때, 우리의 큰 모델(ResNet-152)은 각각 MOTA에서 10.2와 5.8의 개선을 보였습니다 (55.2와 51.8에서). 최근 연구 [32]와 비교했을 때, 우리의 최상 모델(ResNet-152)은 검증 세트와 테스트 세트에서 각각 7.1%와 6.6%의 개선을 보였습니다. 우리의 작은 모델(ResNet-50)도 [11, 32]보다 우수한 성능을 보였습니다.
표 8은 PoseTrack 리더보드에서의 결과를 요약합니다. 우리의 기준선은 모든 공개 항목을 큰 차이로 능가합니다. 모든 방법이 크게 다르며, 이 비교는 시스템 수준에서만 이루어진다는 점을 유의하십시오.
5 Conclusions
우리는 포즈 추정 및 추적을 위한 간단하고 강력한 기준선을 제시합니다. 이 기준선은 어려운 벤치마크에서 최신 기술 결과를 달성합니다. 이들은 종합적인 소거 연구를 통해 검증되었습니다. 이러한 기준선이 아이디어 개발과 평가를 용이하게 하여 이 분야에 기여하길 바랍니다.
Bin Xiao, Haiping Wu, Yichen Wei Simple Baselines for Human Pose Estimation and Tracking

댓글남기기