

개요
딥러닝 분야에서 Transformer 구조의 개발 이후, 2022년에 NeurlIPS에 발표 된 ViTPose의 논문이다. 해당 논문의 벤치마크를 대상으로는 아직도 SOTA인 모델로 알고 있다.
해당 논문은 다음과 같은 4가지 항목에 대해서 ViTPose의 우수성을 언급한다.
- 단순성 측면에서 설계를 위한 특별한 도메인 지식이 필요하지 않을 정도로 간단하다.
- 이러한 구조의 단순성은 뛰어난 확장성을 제공한다.
- ViTPose의 학습 패러다임이 매우 유연하다.
- 규모가 작은 모델도 큰 모델의 지식 토큰을 이전받아 쉽게 성능을 향상 시킬 수 있다.
ViTPose
- 해당 논문의 아키텍쳐는 최대한 단순하게 유지하려하였다. 패치 임베딩 후 여러개의 트랜스포머 백본 이후 디코더 레이어를 통한 키포인트의 히트맵 회귀 구조이다.
- 트랜스포머 블록은 멀티 헤드 셀프 어텐션 레이어(MHSA)와 피드 포워드 네트워크(FFN)로 구성된다.
- 디코더는 기존의 2개의 디컨볼루션 블록으로 구성된 클래식 디코더와 더 단순하고 경량화된 디코더를 테스트 한다.
- 트랜스포머 레이어의 수를 다르게 하거나 피쳐 차원 수를 조정함으로써 모델 크기를 제어할 수 있다.
- 해당 논문에서는 ViT-B, ViT-L, ViT-H, ViTAE-G 백본을 사용하여 사이즈 별로 성능이 향상됨을 관찰한다.
- ImageNet 데이터를 이용하지 않고 포즈 관련된 데이터만을 이용하여 사전학습에 활용한다. 여기서는 MS COCO 와 AI 챌린저 데이터 셋을 이용하여 학습하였다고 한다.
- 입력 크기와 다운 샘플링 비율에 따른 유연성을 평가한다. 입력 해상도나 특징 해상도가 커질 수록 성능이 향상됨을 보인다.
- 어텐션의 연산 복잡도와 큰 메모리 사용량을 개선하기 위해 두가지 기술 Shift-Window(swin)과 Pooling Window 메커니즘을 채택하여 활용한다.
- MHSA, FFN을 고정한 채로 나머지 파라미터에 대한 파인튜닝으로 인한 일반화 성능을 확인한다.
- 디코더의 경량성 덕분에 백본 인코더를 공유하며 여러 데이터셋에 디코더만 변경해가며 성능을 확인한다.
- 지식 증류 기법을 통한 큰 규모에서 작은 규모 모델로의 학습 전이를 구현하여 손실을 설계하고 작은 네트워크에서도 쉬운 성능 향상을 도모한다.
실험결과
- 표 1을 통해 VIT 기반 백본 크기(ViT-B, ViT-L, ViT-H, ViTAE-G)를 학습 하이퍼 파라미터를 확인한다.
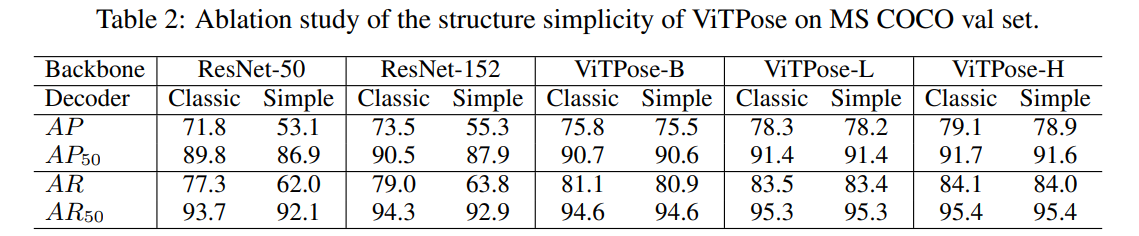
- 표 2를 통해 Simple Baseline과의 비교로 복잡한 디코더에 대한 중요성이 아닌 비전 트랜스포머 기반 아키텍쳐의 강력한 성능을 확인한다.
- 표 3을 통해 사전학습 된 데이터 별 차이를 확인한다. 이미지 넷이 제일 성능이 좋지만 데이터 셋 양이 압도적으로 제일 많음에 유의해야한다.
- 표 4를 통해 입력해상도에 따른 성능의 향상을 확인한다. 단, 정사각형 입력 해상도의 영향이 성능 향상에 크게 도움이 되진 않는 것으로 보인다.
- 표 5를 통해 어텐션 별 타입에 따른 메모리 사용량과 성능 향상을 확인한다. Shift와 Pooling Window를 서로 상호보완하며 같이 쓰는 것이 좋음을 시사한다.
- 표 6을 통해 모듈 별 파인튜닝에 대한 성능 영향을 확인하며 FFN을 고정하면 성능이 크게 떨어지는 것을 볼 수 있다.
- 표 7을 통해 여러 데이터 셋을 활용 시 성능 차이를 볼 수 있다. 백본은 공유했으며 디코더를 개별적으로 사용했다. MS COCO 데이터 셋만 사용할 때 보다 다른 데이터 셋을 같이 사용 시 성능이 좋음을 확인할 수 있다.
- 표 8을 통해 전이 시에 지식 토큰 증류 및 출력에 대한 증류를 상호 보완적으로 사용하여 성능을 올릴 수 있음을 시사한다.
- 표 9와 표 10을 통해 기존 최고 성능 모델 및 SOTA 모델들과의 성능을 비교한다. ViTPose+(ViTAE-G) 모델은 81.1AP를 달성하며 최고성능을 달성함을 볼 수 있다.
결론
해당 논문에서는 비전 트랜스포머 모듈을 이용한 자세 추정 모델에 대해 ViTPose 아키텍쳐를 제안한다. 복잡한 아키텍쳐를 지양하며 단순성을 강조하고, 다양한 규모로의 확장성과 다양한 데이터로의 유연성, 그리고 각 규모별 학습의 전이 가능성을 강조한다. 물론 NVIDIA A100이라는 엄청난 비용의 환경에서 학습되었지만 추론만을 이용할 경우 그리 비용이 높을 것으로 보이지 안으며, 기존 CNN 기반의 모델 대비 높은 성능을 보여줌을 알 수 있다.
번역
Abstract
특정 도메인 지식이 설계에 고려되지 않았음에도 불구하고, 기본적인 비전 트랜스포머는 시각적 인식 작업에서 뛰어난 성능을 보여주었습니다. 그러나 이러한 단순한 구조의 포즈 추정 작업에서의 잠재력을 밝히려는 노력은 거의 없었습니다. 본 논문에서는 ViTPose라는 간단한 베이스라인 모델을 통해, 모델 구조의 단순성, 모델 크기의 확장성, 학습 패러다임의 유연성, 그리고 모델 간 지식 이전 가능성과 같은 다양한 측면에서 기본적인 비전 트랜스포머의 포즈 추정 능력을 놀라울 정도로 잘 보여줍니다. 구체적으로, ViTPose는 주어진 사람 인스턴스의 특징을 추출하기 위해 단순하고 비계층적인 비전 트랜스포머를 백본으로 사용하며, 포즈 추정을 위해 경량화된 디코더를 사용합니다. ViTPose는 확장 가능한 모델 용량과 트랜스포머의 높은 병렬 처리 이점을 활용하여 1억에서 10억 개의 파라미터로 확장할 수 있으며, 이를 통해 처리량과 성능 간의 새로운 파레토 전선을 설정합니다. 또한, ViTPose는 어텐션 타입, 입력 해상도, 사전 학습 및 미세 조정 전략, 그리고 여러 포즈 작업을 처리하는 것에 있어서 매우 유연합니다. 우리는 또한 간단한 지식 토큰을 통해 대형 ViTPose 모델의 지식을 작은 모델로 쉽게 이전할 수 있음을 실험적으로 입증합니다. 실험 결과, 우리의 기본 ViTPose 모델은 까다로운 MS COCO 키포인트 검출 벤치마크에서 대표적인 방법들을 능가하며, 가장 큰 모델은 MS COCO 테스트-개발 세트에서 80.9 AP라는 새로운 최고 성능을 달성합니다. 코드와 모델은 https://github.com/ViTAE-Transformer/ViTPose 에서 이용할 수 있습니다.
1 Introduction
인간 포즈 추정은 컴퓨터 비전 분야의 근본적인 작업 중 하나이며, 다양한 실제 응용 분야를 가지고 있습니다 [51, 29]. 이는 인간의 해부학적 키포인트를 로컬라이즈하는 것을 목표로 하며, 가림(occlusion), 잘림(truncation), 크기, 그리고 인간 외모의 변동성으로 인해 어려움이 있습니다. 이러한 문제를 해결하기 위해 딥러닝 기반의 방법이 빠르게 발전해 왔으며 [37, 42, 36, 50], 주로 합성곱 신경망(CNN)을 사용하여 이 어려운 작업을 다루고 있습니다.
최근 비전 트랜스포머는 다양한 비전 작업에서 큰 잠재력을 보여주었습니다 [13, 31, 10, 34, 32]. 이러한 성공에 영감을 받아, 포즈 추정 작업을 위해 다양한 비전 트랜스포머 구조가 도입되었습니다. 이들 중 대부분은 CNN을 백본으로 사용하고, 그 후에 정교한 구조의 트랜스포머를 사용하여 추출된 특징을 개선하고, 신체 키포인트 간의 관계를 모델링합니다. 예를 들어, PRTR [23]은 트랜스포머 인코더와 디코더를 모두 통합하여 캐스케이드 방식으로 추정된 키포인트의 위치를 점진적으로 개선합니다. TokenPose [27]와 TransPose [44]는 대신에 CNN이 추출한 특징을 처리하기 위해 인코더만으로 구성된 트랜스포머 구조를 채택합니다. 반면에, HRFormer [48]는 트랜스포머를 사용하여 직접 특징을 추출하고 다중 해상도 병렬 트랜스포머 모듈을 통해 고해상도 표현을 도입합니다. 이러한 방법들은 포즈 추정 작업에서 우수한 성능을 보여주었습니다. 그러나 이들은 특징 추출을 위한 추가적인 CNN이 필요하거나, 해당 작업에 적합하도록 트랜스포머 구조를 신중하게 설계해야 합니다. 이는 우리에게 반대 방향에서 생각할 동기를 부여합니다. 과연 단순한 비전 트랜스포머는 포즈 추정에서 얼마나 잘 수행할 수 있을까요?
이 질문에 대한 답을 찾기 위해, 우리는 ViTPose라는 간단한 베이스라인 모델을 제안하고 MS COCO 키포인트 데이터셋에서 그 잠재력을 입증합니다 [28]. 구체적으로, ViTPose는 주어진 사람 인스턴스의 특징 맵을 추출하기 위해 단순하고 비계층적인 비전 트랜스포머 [13]를 백본으로 사용하며, 백본은 MAE [15]와 같은 마스킹 이미지 모델링 사전 학습 태스크로 초기화를 수행합니다. 이후, 가벼운 디코더가 추출된 특징 맵을 업샘플링하고 키포인트에 대한 히트맵을 추정하는데, 이는 두 개의 디컨볼루션 레이어와 하나의 예측 레이어로 구성되어 있습니다. 모델에 정교한 설계가 없음에도 불구하고, ViTPose는 까다로운 MS COCO 키포인트 테스트-개발 세트에서 80.9 AP라는 최첨단(SOTA) 성능을 달성합니다. 이 논문은 알고리즘적 우월성을 주장하는 것이 아니라, 포즈 추정을 위한 우수한 성능을 가진 간단하고 견고한 트랜스포머 베이스라인을 제시하는 것임을 유의해야 합니다.
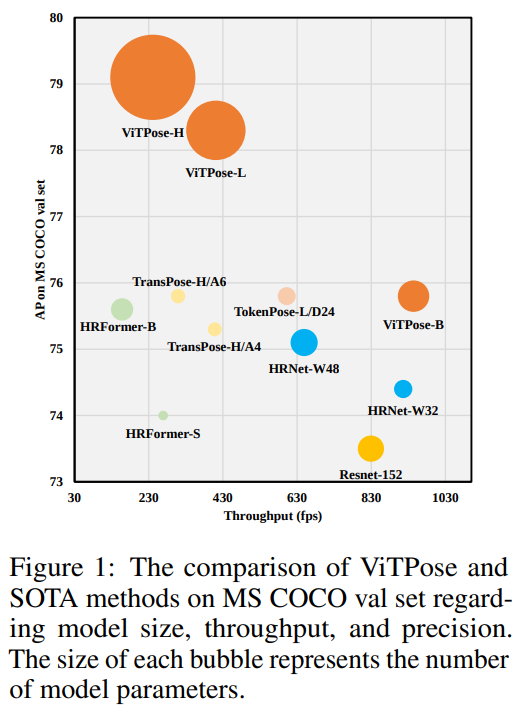
우수한 성능 외에도, 우리는 모델 구조의 단순성, 모델 크기의 확장성, 학습 패러다임의 유연성, 그리고 모델 간 지식 이전 가능성과 같은 다양한 측면에서 ViTPose의 놀라운 능력을 보여줍니다. 1) 단순성 측면에서, 비전 트랜스포머의 강력한 특징 표현 능력 덕분에 ViTPose 프레임워크는 매우 단순할 수 있습니다. 예를 들어, 백본 인코더 설계를 위해 특별한 도메인 지식이 필요하지 않으며, 여러 트랜스포머 레이어를 단순하게 쌓아 평면적이고 비계층적인 인코더 구조를 구성할 수 있습니다. 디코더는 추가적으로 업샘플링 레이어 하나와 그 뒤를 따르는 컨볼루션 예측 레이어로 간소화될 수 있으며, 이로 인한 성능 저하는 미미합니다. 이러한 구조적 단순성은 ViTPose가 더 나은 병렬 처리를 가능하게 하여 추론 속도와 성능 간의 새로운 파레토 프론티어를 달성할 수 있도록 합니다. 이는 그림 1에 나타나 있습니다. 2) 구조의 단순성은 ViTPose의 뛰어난 확장성을 제공합니다. 따라서 확장 가능한 사전 학습된 비전 트랜스포머의 빠른 개발로부터 이점을 얻습니다. 구체적으로, 서로 다른 수의 트랜스포머 레이어를 쌓고 특징 차원을 늘리거나 줄임으로써 모델 크기를 쉽게 제어할 수 있으며, 예를 들어 ViT-B, ViT-L, ViT-H를 사용하여 다양한 배포 요구사항에 따라 추론 속도와 성능을 균형 있게 조절할 수 있습니다. 3) 또한, 우리는 ViTPose가 학습 패러다임에서 매우 유연함을 입증합니다. ViTPose는 다양한 입력 해상도 및 특징 해상도에 적은 수정으로 잘 적응할 수 있으며, 더 높은 해상도 입력에 대해 더욱 정확한 포즈 추정 결과를 항상 제공합니다. 일반적인 관행인 단일 포즈 데이터셋에 대해 ViTPose를 학습하는 것 외에도, 매우 유연하게 추가 디코더를 추가하여 여러 포즈 데이터셋에 적응하도록 수정할 수 있으며, 이를 통해 공동 학습 파이프라인을 형성하고 성능을 크게 향상시킵니다. 이러한 학습 패러다임은 ViTPose의 디코더가 상당히 경량이기 때문에 추가적인 계산 비용이 거의 발생하지 않습니다. 또한, ViTPose는 더 작은 비라벨 데이터셋을 사용하여 사전 학습하거나 어텐션 모듈을 고정한 상태에서 미세 조정(finetuning)해도 최첨단(SOTA) 성능을 달성할 수 있으며, 완전한 사전 학습 미세 조정 패러다임보다 적은 학습 비용이 필요합니다. 4) 마지막으로, 작은 ViTPose 모델의 성능은 대형 ViTPose 모델로부터 추가적인 학습 가능한 지식 토큰을 통해 지식을 이전함으로써 쉽게 향상될 수 있으며, 이는 ViTPose의 우수한 지식 이전 가능성을 보여줍니다.
결론적으로, 이 논문의 기여점은 세 가지로 요약됩니다. 1) 우리는 인간 포즈 추정을 위한 간단하지만 효과적인 베이스라인 모델인 ViTPose를 제안합니다. 이 모델은 정교한 구조적 설계나 복잡한 프레임워크를 사용하지 않고도 MS COCO 키포인트 데이터셋에서 최첨단(SOTA) 성능을 달성합니다. 2) 단순한 ViTPose 모델은 구조의 단순성, 모델 크기의 확장성, 학습 패러다임의 유연성, 지식 이전 가능성과 같은 놀라운 능력을 보여줍니다. 이러한 능력들은 비전 트랜스포머 기반의 포즈 추정 작업에 강력한 베이스라인을 제공하며, 해당 분야의 향후 발전에 가능성을 제시할 것입니다. 3) ViTPose의 능력을 연구하고 분석하기 위해 인기 있는 벤치마크에서 종합적인 실험을 수행했습니다. 매우 큰 비전 트랜스포머 모델을 백본으로 사용한 경우, 즉 ViTAE-G [52]를 사용할 때, 단일 ViTPose 모델은 MS COCO 키포인트 테스트-개발 세트에서 최고 성능인 80.9 AP를 달성했습니다.
2 Related Work
2.1 Vision transformer for pose estimation
포즈 추정은 CNN [42]에서 비전 트랜스포머 네트워크로 빠르게 발전해 왔습니다. 초기 연구들은 트랜스포머를 더 나은 디코더로 간주하는 경향이 있으며 [23, 27, 44], 예를 들어 TransPose [44]는 CNN이 추출한 특징을 직접 처리하여 전역 관계를 모델링합니다. TokenPose [27]는 추가적인 토큰을 도입하여 가려진 키포인트의 위치를 추정하고, 서로 다른 키포인트 간의 관계를 모델링하는 토큰 기반 표현을 제안합니다. 특징 추출을 위한 CNN을 제거하기 위해, HRFormer [48]는 트랜스포머를 사용하여 고해상도 특징을 직접 추출하도록 제안되었습니다. HRFormer에서는 다중 해상도 특징을 점진적으로 융합하기 위한 정교한 병렬 트랜스포머 모듈이 제안됩니다. 이러한 트랜스포머 기반 포즈 추정 방법들은 인기 있는 키포인트 추정 벤치마크에서 우수한 성능을 보입니다. 하지만, 이들은 특징 추출을 위해 CNN이 필요하거나 트랜스포머 구조를 신중하게 설계해야 합니다. 포즈 추정 작업을 위한 단순한 비전 트랜스포머의 잠재력을 탐색하려는 노력은 거의 없었습니다. 본 논문에서는 이 격차를 메우고자 단순하면서도 효과적인 베이스라인 모델인 ViTPose를 제안합니다.
2.2 Vision transformer pre-training
ViT [13]의 성공에 영감을 받아, 다양한 비전 트랜스포머 백본들이 제안되었습니다 [31, 43, 40, 55, 39, 52, 38, 53]. 이들은 일반적으로 완전 지도 학습 환경에서 ImageNet-1K [12] 데이터셋을 사용하여 학습됩니다. 최근에는 단순한 비전 트랜스포머를 학습시키기 위한 자가 지도 학습 방법들 [15, 4]이 제안되었습니다. 마스킹 이미지 모델링(MIM)을 사전 과제로 사용하여 이러한 방법들은 단순한 비전 트랜스포머에 대한 좋은 초기화를 제공합니다. 본 논문에서는 포즈 추정 작업에 집중하고, MIM 사전 학습을 통해 단순한 비전 트랜스포머를 백본으로 채택합니다. 또한, 포즈 추정 작업을 위해 ImageNet-1K를 사용한 사전 학습이 필수적인지 여부를 탐색합니다. 놀랍게도, 더 작은 비라벨 포즈 데이터셋을 사용한 사전 학습도 포즈 추정 작업에 좋은 초기화를 제공할 수 있음을 발견했습니다.
3 ViTPose
3.1 The simplicity of ViTPose
Structure simplicity.
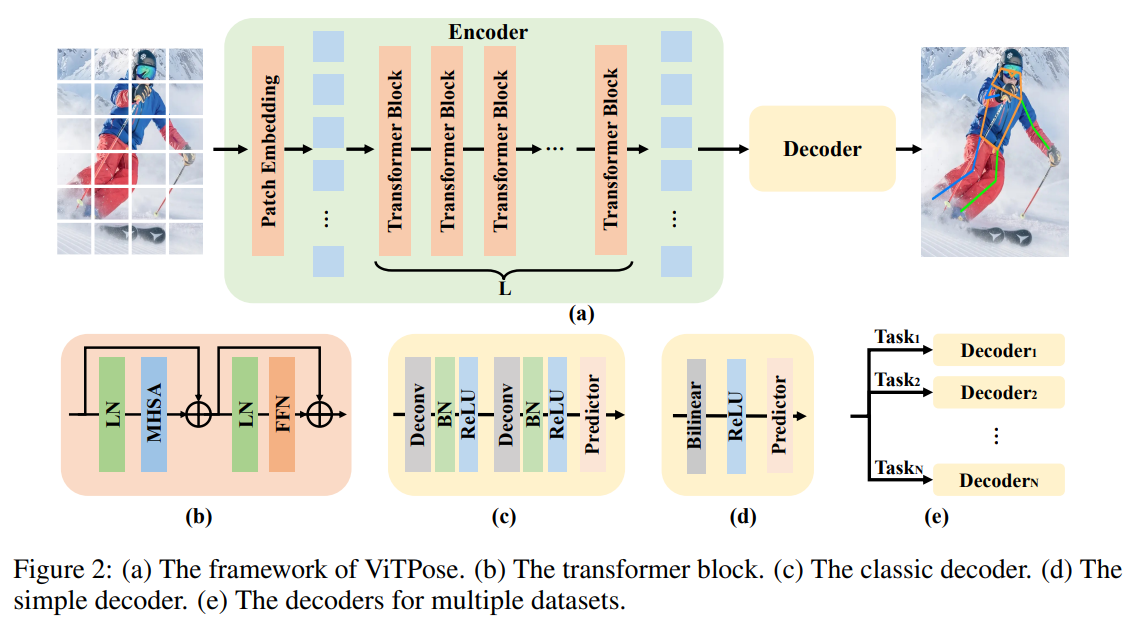
이 논문의 목표는 포즈 추정 작업을 위한 단순하면서도 효과적인 비전 트랜스포머 베이스라인을 제공하고, 단순하고 비계층적인 비전 트랜스포머의 잠재력을 탐색하는 것입니다 [13]. 따라서 우리는 구조를 최대한 단순하게 유지하며, 성능을 향상시킬 수 있을지라도 복잡한 모듈은 피하려고 합니다. 이를 위해 트랜스포머 백본 이후에 여러 디코더 레이어를 추가하여 키포인트에 대한 히트맵을 추정하도록 했으며, 이는 그림 2 (a)에 나타나 있습니다. 단순성을 위해 디코더 레이어에는 스킵 연결이나 교차 어텐션을 사용하지 않고, [42]와 마찬가지로 간단한 디컨볼루션 레이어와 예측 레이어만 사용합니다. 구체적으로, 사람 인스턴스 이미지 $X∈\mathcal{R}^{\mathcal{H}×\mathcal{W}×3}$ 가 입력으로 주어지면, ViTPose는 패치 임베딩 레이어를 통해 이미지를 토큰으로 임베딩하며, 즉 $F∈\mathcal{R}^{\frac{H}{d}×\frac{W}{d}×C}$ 가 됩니다. 여기서 $d$ (예: 기본값은 16)는 패치 임베딩 레이어의 다운샘플링 비율이고, $C$ 는 채널 차원입니다. 그 후 임베딩된 토큰들은 여러 트랜스포머 레이어를 통해 처리되며, 각 레이어는 멀티-헤드 자기 어텐션(MHSA) 레이어와 피드-포워드 네트워크(FFN)로 구성됩니다. 즉,
\[\begin{equation} F'_{i+1} = F_i+\text{MHSA}(\text{LN}(F_i)), \qquad F_{i+1} = F'_{i+1}+\text{FFN}(\text{LN}(F'_{i+1})) \end{equation}\]여기서 $i$ 는 $i$ 번째 트랜스포머 레이어의 출력을 나타내며, 초기 특징 $F_0=\text{PatchEmbed}(X)$ 는 패치 임베딩 레이어 이후의 특징을 나타냅니다. 각 트랜스포머 레이어에서 공간 및 채널 차원은 일정하다는 점을 유의해야 합니다. 우리는 백본 네트워크의 출력 특징을 $F_{out}∈\mathcal{R}^{\frac{H}{d}×\frac{H}{d}×C}$ 로 나타냅니다.
우리는 백본 네트워크에서 추출된 특징을 처리하고 키포인트를 로컬라이즈하기 위해 두 가지 종류의 경량 디코더를 채택했습니다. 첫 번째는 클래식 디코더입니다. 이 디코더는 두 개의 디컨볼루션 블록으로 구성되며, 각 블록은 배치 정규화 [19]와 ReLU [1]가 뒤따르는 디컨볼루션 레이어 하나를 포함합니다. 이전 방법들의 일반적인 설정 [42, 50]에 따라, 각 블록은 특징 맵을 2배 업샘플링합니다. 그런 다음, 커널 크기 $1×1$ 의 컨볼루션 레이어를 사용하여 키포인트의 로컬라이제이션 히트맵을 얻습니다. 즉,
\[\begin{equation} K = \text{Conv}_{1\times 1}(\text{Deconv}(\text{Deconv}(F_{out}))), \end{equation}\]여기서 $K∈\mathcal{R}^{\frac{H}{4}×\frac{W}{4}×N_k}$ 는 추정된 히트맵(각 키포인트에 하나씩)을 나타내며, $N_k$ 는 추정할 키포인트의 수로, MS COCO 데이터셋의 경우 17로 설정됩니다.
클래식 디코더가 단순하고 가볍지만, 우리는 ViTPose에서 또 다른 더 단순한 디코더를 시도했으며, 이는 비전 트랜스포머 백본의 강력한 표현 능력 덕분에 효과적임이 입증되었습니다. 구체적으로, 우리는 특징 맵을 4배로 직접 업샘플링한 후, ReLU와 커널 크기 $3×3$ 의 컨볼루션 레이어를 통해 히트맵을 얻습니다. 즉,
\[\begin{equation} K = \text{Conv}_{3\times 3}(\text{Bilinear}(\text{ReLU}(F_{out}))), \end{equation}\]이러한 더 단순한 디코더의 비선형 용량이 적음에도 불구하고, 이 디코더는 클래식 디코더 및 이전의 대표적인 방법에서 사용된 신중하게 설계된 트랜스포머 기반 디코더와 비교하여 경쟁력 있는 성능을 얻으며, ViTPose의 구조적 단순성을 입증합니다.
3.2 The scalability of ViTPose
ViTPose는 구조가 단순하기 때문에 배포 요구 사항에 따라 그림 1의 새로운 파레토 프론트에서 지점을 선택하고, 트랜스포머 레이어의 수를 다르게 쌓거나 특징 차원을 늘리거나 줄임으로써 모델 크기를 쉽게 제어할 수 있습니다. 이러한 측면에서 ViTPose는 다른 부분에 큰 수정을 가하지 않고도 확장 가능한 사전 학습 비전 트랜스포머의 빠른 개발로부터 이점을 얻을 수 있습니다. ViTPose의 확장성을 조사하기 위해, 우리는 다양한 모델 용량을 가진 사전 학습된 백본을 사용하고 MS COCO 데이터셋에서 이를 미세 조정(finetune)합니다. 예를 들어, 우리는 ViT-B, ViT-L, ViT-H [13], 그리고 ViTAE-G [52]를 포즈 추정에 클래식 디코더와 함께 사용하며, 모델 크기가 커짐에 따라 일관된 성능 향상을 관찰합니다. 사전 학습 중 패치 크기 14 × 14의 패치 임베딩을 사용하는 ViT-H와 ViTAE-G의 경우, 동일한 설정을 위해 ViT-B 및 ViT-L과 동일한 패치 크기 16 × 16으로 만들어 주기 위해 제로 패딩을 사용합니다.
3.3 The flexibility of ViTPose
Pre-training data flexibility.
백본 네트워크의 ImageNet [12] 사전 학습은 좋은 초기화를 위한 사실상의 표준이었습니다. 하지만 이는 포즈 데이터 외의 추가적인 데이터를 필요로 하며, 이로 인해 포즈 추정 작업의 데이터 요구 사항이 높아집니다. 우리는 전체 학습 과정에서 포즈 데이터만을 사용하여 데이터 요구 사항을 완화할 수 있는지 여부에 관심을 가집니다. 데이터 유연성을 탐구하기 위해, ImageNet [12] 사전 학습의 기본 설정 외에도, 우리는 MAE [15]를 사용하여 MS COCO [28]와 MS COCO 및 AI 챌린저 [41]의 조합을 사용하여 백본을 사전 학습합니다. 이를 위해 이미지의 75% 패치를 무작위로 마스킹하고 해당 마스킹된 패치를 재구성합니다. 그런 다음, 우리는 사전 학습된 가중치를 사용하여 ViTPose의 백본을 초기화하고 MS COCO 데이터셋에서 모델을 미세 조정합니다. 놀랍게도 포즈 데이터의 양이 ImageNet에 비해 훨씬 적음에도 불구하고, 포즈 데이터로만 학습된 ViTPose는 경쟁력 있는 성능을 얻을 수 있으며, 이는 ViTPose가 다양한 규모의 데이터로부터 유연하게 좋은 초기화를 학습할 수 있음을 시사합니다.
Resolution flexibility.
우리는 ViTPose의 입력 이미지 크기와 다운샘플링 비율 $d$ 을 다양하게 변경하여 입력 및 특징 해상도에 대한 유연성을 평가합니다. 구체적으로, ViTPose를 더 높은 해상도의 입력 이미지에 적응시키기 위해, 우리는 단순히 입력 이미지를 리사이즈하고 해당 이미지에 맞추어 모델을 학습시킵니다. 또한 모델을 낮은 다운샘플링 비율, 즉 더 높은 특징 해상도에 적응시키기 위해, 우리는 패치 임베딩 레이어의 스트라이드를 조정하여 토큰을 겹쳐서 분할하고 각 패치의 크기를 유지합니다. 우리는 ViTPose의 성능이 더 높은 입력 해상도나 더 높은 특징 해상도에 따라 일관되게 향상됨을 보여줍니다.
Attention type flexibility.
고해상도 특징 맵에서 풀 어텐션을 사용하면 어텐션 계산의 이차적 연산 복잡도와 메모리 소비로 인해 큰 메모리 사용량과 계산 비용이 발생합니다. 상대적 위치 임베딩을 사용하는 윈도우 기반 어텐션 [25, 26]은 고해상도 특징 맵을 처리하는 데 필요한 메모리 부담을 완화하기 위해 탐색되었습니다. 하지만 단순히 모든 트랜스포머 블록에 윈도우 기반 어텐션을 사용하면 전역 컨텍스트 모델링 능력이 부족하여 성능이 저하됩니다. 이 문제를 해결하기 위해 우리는 두 가지 기술을 채택합니다. 즉, 1) Shift window: 어텐션 계산을 위해 고정된 윈도우를 사용하는 대신, 인접 윈도우 간의 정보를 전파하기 위해 shift-window 메커니즘 [31]을 사용합니다. 2) Pooling window: Shift window 메커니즘과는 별개로, 우리는 풀링을 통해 또 다른 해결책을 시도합니다. 구체적으로, 우리는 각 윈도우의 토큰을 풀링하여 윈도우 내의 전역 컨텍스트 특징을 얻습니다. 그런 다음 이러한 특징들은 각 윈도우에 입력되어 키와 값 토큰으로 작용하며, 윈도우 간의 특징 통신을 가능하게 합니다. 또한, 우리는 두 가지 전략이 상호 보완적이며, 추가적인 파라미터나 모듈 없이도 어텐션 계산의 간단한 수정만으로 성능을 향상시키고 메모리 사용량을 줄일 수 있음을 입증합니다.
Finetuning flexibility.
NLP 분야에서 입증된 바와 같이 [30, 2], 사전 학습된 트랜스포머 모델은 일부 파라미터만 조정하여도 다른 작업에 잘 일반화될 수 있습니다. 이것이 비전 트랜스포머에도 적용되는지 확인하기 위해, 우리는 모든 파라미터를 고정 해제한 상태, MHSA 모듈을 고정한 상태, 그리고 FFN 모듈을 고정한 상태로 각각 MS COCO에서 ViTPose를 미세 조정(finetune)했습니다. 우리는 경험적으로 MHSA 모듈을 고정한 상태에서도 ViTPose가 완전 미세 조정 설정과 비슷한 성능을 얻는다는 것을 입증했습니다.
Task flexibility.
ViTPose에서 디코더가 매우 단순하고 가벼우므로, 백본 인코더를 공유하여 여러 포즈 추정 데이터셋을 처리하기 위해 추가 비용 없이 여러 디코더를 채택할 수 있습니다. 우리는 각 반복(iteration)마다 여러 학습 데이터셋에서 인스턴스를 무작위로 샘플링하고, 이를 백본 및 디코더에 입력하여 각 데이터셋에 대응하는 히트맵을 추정합니다.
3.4 The transferability of ViTPose
작은 모델의 성능을 향상시키는 일반적인 방법 중 하나는 더 큰 모델로부터 지식을 이전하는 것입니다. 즉, 지식 증류(knowledge distillation) [17, 14]입니다. 구체적으로, 교사 네트워크 $T$ 와 학생 네트워크 $S$ 가 주어지면, 간단한 증류 방법은 출력 증류 손실 $L^{od}_{t→s}$ 을 추가하여 학생 네트워크의 출력을 교사 네트워크의 출력과 유사하게 만드는 것입니다. 즉,
\[\begin{equation} L^{od}_{t\rightarrow s} = \text{MSE}(K_s, K_t), \end{equation}\]여기서 $K_s$ 와 $K_t$ 는 동일한 입력이 주어졌을 때 학생과 교사 네트워크의 출력입니다.
위의 일반적인 방법 외에도, 우리는 큰 모델과 작은 모델을 연결하기 위해 토큰 기반 증류 방법을 탐구합니다. 이는 위의 방법을 보완하는 방식입니다. 구체적으로, 우리는 추가적인 학습 가능한 지식 토큰 $t$ 을 무작위로 초기화하고, 이를 교사 모델의 패치 임베딩 레이어 뒤의 시각 토큰에 추가합니다. 그런 다음, 잘 학습된 교사 모델을 고정하고, 지식 토큰만 몇 에포크 동안 조정하여 지식을 얻습니다. 즉,
\[\begin{equation} t^* = \arg \min_t(\text{MSE}(T({t;X}), K_{gt})), \end{equation}\]여기서 $K_{gt}$ 는 정답 히트맵이고, $X$ 는 입력 이미지이며, $T({t;X})$ 는 교사의 예측을 나타내며, $t^\ast$ 는 손실을 최소화하는 최적의 토큰을 나타냅니다. 그 후에 지식 토큰 $t^\ast$ 는 고정되고 학습 중에 학생 네트워크의 시각 토큰과 연결되어 교사 네트워크에서 학생 네트워크로 지식을 전이합니다. 따라서 학생 네트워크의 손실은 다음과 같습니다.
\[\begin{equation} L^{td}_{t\rightarrow s} = \text{MSE}(S({t^*;X}),K_{gt}), \quad \text{or} \quad L^{tod}_{t\rightarrow s} = \text{MSE}(S({t*;X}),K_t)+\text{MSE}(S({t*;X}),K_{gt}), \end{equation}\]여기서 $L_{t→s}^{td}$ 와 $L_{t→s}^{td+od}$ 는 각각 토큰 증류 손실과 출력 증류 손실 및 토큰 증류 손실의 결합을 나타냅니다.
4 Experiments
4.1 Implementation details
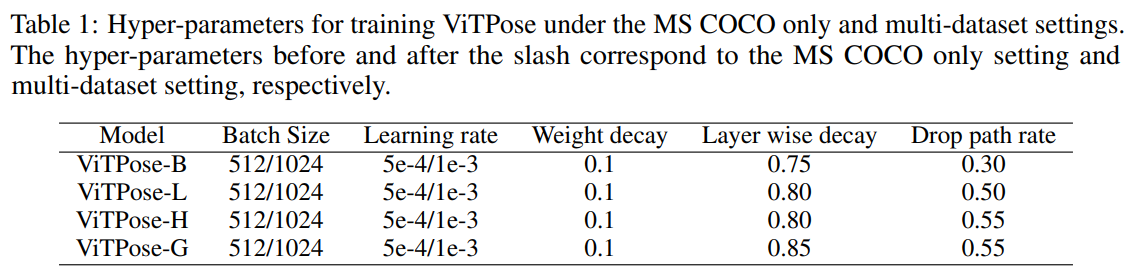
ViTPose는 인간 포즈 추정을 위한 일반적인 탑다운(top-down) 설정을 따르며, 즉, 검출기(detector)가 사람 인스턴스를 검출하고 ViTPose는 검출된 인스턴스의 키포인트를 추정하는 데 사용됩니다. SimpleBaseline [42]의 검출 결과는 MS COCO 키포인트 검증 데이터셋에서 ViTPose의 성능을 평가하는 데 사용됩니다. 우리는 ViT-B, ViT-L, ViT-H를 백본으로 사용하고, 해당 모델들을 각각 ViTPose-B, ViTPose-L, ViTPose-H로 명명합니다. 모델은 mmpose 코드베이스 [11]를 기반으로 8개의 A100 GPU에서 학습됩니다. 백본은 MAE [15] 사전 학습 가중치로 초기화됩니다. mmpose의 기본 학습 설정을 사용하여 ViTPose 모델을 학습하는데, 즉 256 × 192 입력 해상도와 학습률 5e-4의 AdamW [33] 옵티마이저를 사용합니다. Udp [18]는 후처리에 사용됩니다. 모델은 학습률이 170번째 및 200번째 에포크에서 10배 감소되는 방식으로 총 210 에포크 동안 학습됩니다. 우리는 각 모델에 대해 계층별 학습률 감소 [46]와 확률적 드롭 경로 비율을 조정하며, 최적 설정은 표 1에 제공됩니다.
4.2 Ablation study and analysis
The structure simplicity and scalability.
우리는 ViTPose를 각각 섹션 3.1에 설명된 클래식 디코더와 간단한 디코더로 학습했습니다. 또한, 참고를 위해 두 디코더를 사용하여 ResNet [16]을 백본으로 하는 SimpleBaseline [42]을 학습했습니다. 표 2는 그 결과를 보여줍니다. 간단한 디코더를 사용하면 ResNet-50과 ResNet-152 모두에 대해 약 18 AP가 감소하는 것으로 관찰됩니다. 그러나 비전 트랜스포머를 백본으로 사용하는 ViTPose는 ViT-B, ViT-L, 그리고 ViT-H의 경우 간단한 디코더와 함께 동작할 때, 성능 하락이 미미합니다(즉, AP가 0.3 미만). $AP_{50}$ 와 $AR_{50}$ 지표에서도 ViTPose는 두 디코더 중 어느 것을 사용하든 비슷한 성능을 보여주며, 단순한 비전 트랜스포머가 강력한 표현 능력을 가지고 있고 복잡한 디코더가 필요하지 않음을 보여줍니다. 또한 표에서 ViTPose의 성능은 모델 크기가 커짐에 따라 일관되게 향상되며, 이는 ViTPose의 우수한 확장성을 보여줍니다.
The influence of pre-training data.

즈 추정 작업에 ImageNet-1K 데이터가 필요한지 평가하기 위해, 우리는 백본 모델을 ImageNet-1k [12], MS COCO, 그리고 MS COCO [28]와 AI 챌린저 [41]의 조합과 같은 다양한 데이터셋을 사용하여 사전 학습합니다. ImageNet-1k 데이터셋의 이미지는 아이코닉하므로, 우리는 MS COCO와 AI 챌린저 학습 세트에서 사람 인스턴스를 잘라내어 새로운 사전 학습 데이터로 만듭니다. 모델은 각각 세 가지 데이터셋에서 1,600 에포크 동안 사전 학습되며, 이후 210 에포크 동안 MS COCO 데이터셋의 포즈 주석을 사용하여 미세 조정됩니다. 결과는 표 3에 요약되어 있습니다. MS COCO와 AI 챌린저 데이터를 조합하여 사전 학습을 수행할 때, ViTPose는 ImageNet-1k를 사용한 것과 비교하여 유사한 성능을 얻는 것을 볼 수 있습니다. 데이터셋의 볼륨은 ImageNet-1k의 절반에 불과하다는 점을 주목해야 합니다. 이는 다운스트림 작업의 데이터로 사전 학습을 수행하면 더 나은 데이터 효율성을 갖추게 되어, ViTPose가 사전 학습 데이터를 사용하는 데 유연함을 입증함을 시사합니다. 그러나 MS COCO 데이터만 사전 학습에 사용하면 AP가 1.3 감소합니다. 이는 MS COCO 데이터셋의 제한된 양 때문일 수 있으며, 즉 MS COCO의 인스턴스 수는 MS COCO와 AI 챌린저의 조합에 비해 세 배 적습니다. 또한, 잘라내기 작업 없이 MS COCO와 AI 챌린저의 이미지를 직접 사전 학습에 사용해도 ViTPose는 잘라내기 작업을 사용한 것과 비교하여 유사한 성능을 얻습니다. 이 관찰은 다운스트림 작업의 데이터 자체가 사전 학습 단계에서 더 나은 데이터 효율성을 가져올 수 있다는 결론을 더욱 입증합니다.
The influence of input resolution.

ViTPose가 서로 다른 입력 해상도에 잘 적응할 수 있는지 평가하기 위해, 우리는 다양한 입력 이미지 크기로 ViTPose를 학습했고, 결과는 표 4에 나타나 있습니다. ViTPose-B의 성능은 입력 해상도가 증가함에 따라 향상됩니다. 또한, 256 × 256과 같이 입력이 정사각형일 경우 해상도가 더 크더라도 성능 향상이 크지 않음을 알 수 있습니다. 그 이유는 MS COCO에서 사람 인스턴스의 평균 종횡비가 4:3이기 때문에 정사각형 입력 크기가 통계적으로 적합하지 않기 때문일 수 있습니다.
The influence of attention type.
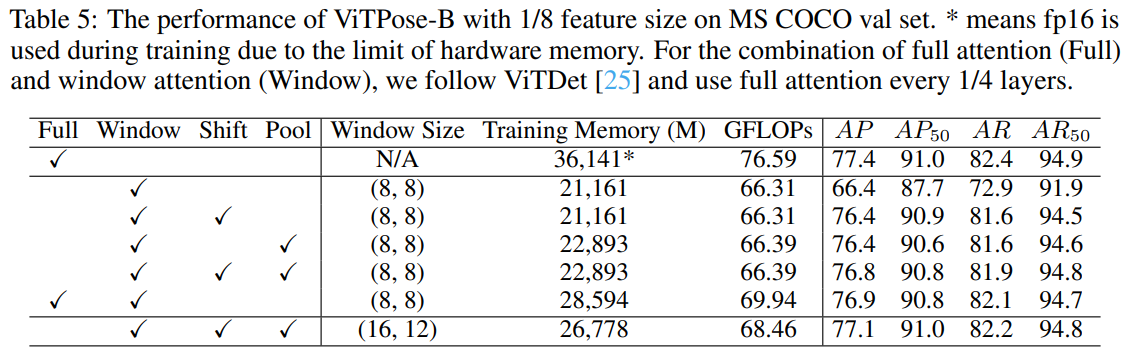
HRNet [36]과 HRFormer [48]에서 입증된 바와 같이, 고해상도 특징 맵은 포즈 추정 작업에 유리합니다. ViTPose는 패치 임베딩 레이어의 다운샘플링 비율을 1/16에서 1/8로 조정하여 쉽게 고해상도 특징을 생성할 수 있습니다. 또한 트랜스포머 레이어의 이차적 계산 복잡성으로 인해 발생하는 메모리 부족 문제를 완화하기 위해, 섹션 3.3에서 설명한 대로 shift와 풀링 메커니즘을 사용하는 윈도우 어텐션을 사용할 수 있습니다. 결과는 표 5에 제시되어 있습니다. ‘Shift’와 ‘Pool’은 각각 shift 윈도우와 풀링 윈도우 메커니즘을 나타냅니다. 1/8 특징 크기로 풀 어텐션을 직접 사용하면 MS COCO 검증 데이터셋에서 77.4 AP로 최고의 성능을 얻지만, 혼합 정밀도 학습 모드에서도 큰 메모리 사용량을 초래합니다. 윈도우 어텐션은 메모리 문제를 완화할 수 있지만, 전역 컨텍스트 모델링의 부족으로 인해 성능이 저하되며, 예를 들어 77.4 AP에서 66.4 AP로 감소합니다. Shift 윈도우와 풀링 윈도우 메커니즘은 전역 컨텍스트 모델링을 위한 윈도우 간 정보 교환을 촉진하여 메모리 사용량이 10% 미만으로 증가하면서도 성능을 10 AP만큼 크게 향상시킵니다. 두 메커니즘을 함께 적용하면(5번째 행), 성능은 76.8 AP로 더욱 향상되며, 이는 풀 어텐션과 윈도우 어텐션을 함께 사용하는 ViTDet [25]의 전략(6번째 행)과 비교하여 상당하지만 메모리 사용량이 훨씬 적습니다. 즉, 76.8 AP 대 76.9 AP와 22.9G 메모리 대 28.6G 메모리입니다. 표 5의 5번째 행과 마지막 행을 비교하면 윈도우 크기를 (8 × 8)에서 (16 × 12)로 늘려 성능을 76.8 AP에서 77.1 AP로 향상시킬 수 있으며, 이는 풀 어텐션과 윈도우 어텐션을 결합한 설정보다도 우수한 성능을 보여줍니다.
The influence of partially finetuning.

비전 트랜스포머가 부분적인 미세 조정을 통해 포즈 추정 작업에 적응할 수 있는지 평가하기 위해, 우리는 ViTPose-B 모델을 세 가지 설정으로 미세 조정했습니다. 즉, 완전한 미세 조정, MHSA 모듈 고정, 그리고 FFN 모듈 고정입니다. 표 6에서 보이듯이, MHSA 모듈이 고정된 경우, 완전한 미세 조정과 비교했을 때 성능이 약간 떨어집니다(75.1 AP 대 75.8 AP). $AP_{50}$ 지표는 두 설정에 대해 거의 동일합니다. 그러나 FFN 모듈을 고정하고 MHSA 모듈만 미세 조정할 때, AP가 3.0만큼 크게 떨어집니다. 이 결과는 비전 트랜스포머의 FFN 모듈이 작업 특화 모델링에 더 큰 역할을 한다는 것을 시사합니다. 반면에, MHSA 모듈은 더 작업에 구애받지 않으며, 예를 들어 MIM 사전 학습 작업이든 특정 포즈 추정 작업이든 관계없이 특징 유사성에 기반하여 토큰 관계를 모델링합니다.
The influence of multi-dataset training.

ViTPose의 디코더가 상당히 단순하고 가볍기 때문에, 우리는 각 데이터셋에 대해 개별 디코더와 공유 백본을 사용하여 ViTPose를 다중 데이터셋 공동 학습 패러다임으로 쉽게 확장할 수 있습니다. 구체적으로, 우리는 MS COCO [28], AI 챌린저 [41], MPII [3] 데이터셋을 다중 데이터셋 학습에 사용합니다. MS COCO 검증 데이터셋에 대한 결과는 표 7에 나와 있습니다. 다른 데이터셋에 대한 결과는 부록에서 확인할 수 있습니다. 우리는 다중 데이터셋 학습 후 모델을 직접 평가에 사용하며, MS COCO에서 추가로 미세 조정하지 않았음을 주목하세요. 세 가지 데이터셋 모두를 사용하여 학습할 때, ViTPose의 성능은 75.8 AP에서 77.1 AP로 일관되게 향상되는 것을 확인할 수 있습니다. MPII의 데이터 양은 MS COCO와 AI 챌린저의 조합에 비해 훨씬 작지만(40K 대 500K), 학습에 MPII를 사용하는 것만으로도 AP가 0.1만큼 증가하여 ViTPose가 서로 다른 데이터셋의 다양한 데이터를 잘 활용할 수 있음을 나타냅니다.
The analysis of transferability.

ViTPose의 전이 가능성을 평가하기 위해, 우리는 ViTPose-L에서 ViTPose-B로 지식을 전이하기 위해 고전적인 출력 증류와 제안된 지식 토큰 증류를 모두 사용합니다. 결과는 표 8에서 확인할 수 있습니다. 토큰 기반 증류는 미미한 메모리 사용량 증가와 함께 ViTPose-B에 대해 0.2 AP의 이득을 가져오는 반면, 출력 증류는 0.5 AP의 성능 향상을 가져옵니다. 두 증류 방법은 서로 보완적이며, 두 방법을 함께 사용할 때 76.6 AP를 달성하여 ViTPose 모델의 뛰어난 전이 가능성을 검증합니다.
4.3 Comparison with SOTA methods
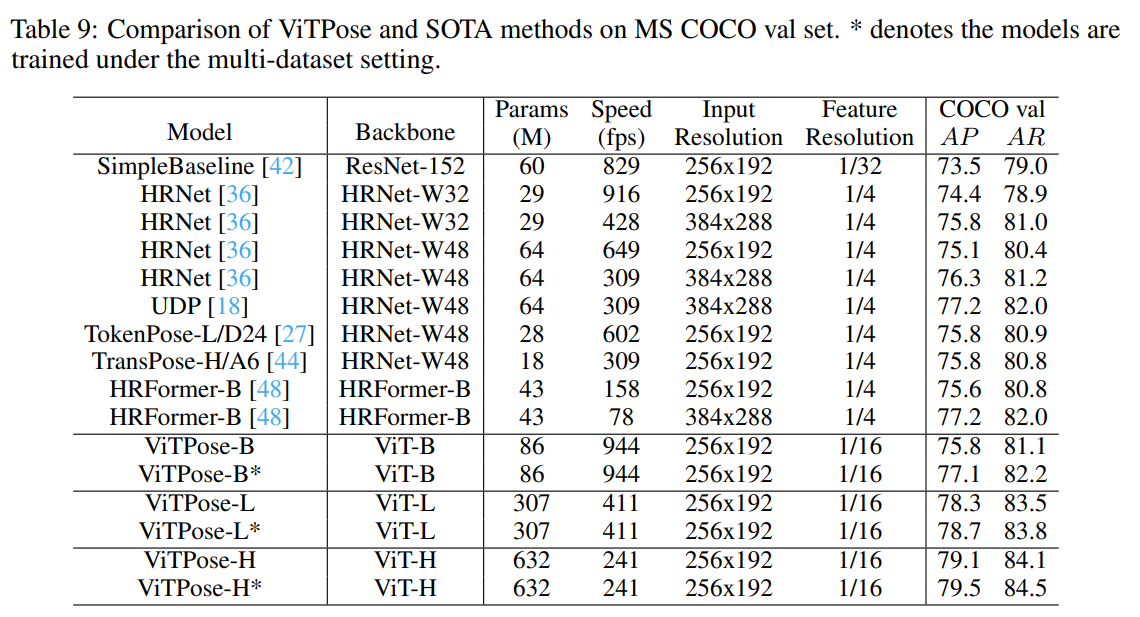
이전 분석에 근거하여, 우리는 포즈 추정 작업을 위해 256 × 192 입력 해상도와 다중 데이터셋 훈련을 사용하였으며, 그 결과를 표 9 및 표 10에 있는 MS COCO 검증 및 테스트-개발 데이터셋에 대해 보고합니다. 모든 방법의 속도는 배치 크기 64로 단일 A100 GPU에서 기록되었습니다. 비록 ViTPose의 모델 크기가 크지만, 처리량과 정확도 간의 균형이 잘 맞아 일반적인 비전 트랜스포머가 강력한 표현 능력을 가지고 있으며 현대 하드웨어에 적합함을 보여줍니다. 또한, ViTPose는 더 큰 백본에서도 우수한 성능을 보입니다. 예를 들어, ViTPose-L은 검증 데이터셋에서 ViTPose-B보다 훨씬 더 나은 성능을 보여줍니다(즉, 78.3 AP vs 75.8 AP, 83.5 AR vs 81.1 AR). ViTPose-L은 유사한 추론 속도를 가진 기존의 SOTA CNN 및 트랜스포머 모델(UDP 및 TokenPose 포함)을 능가하였습니다. 유사한 결론을 ViTPose-H(15번째 행)와 HRFormer-B(9번째 행)의 성능을 비교함으로써 얻을 수 있으며, ViTPose-H는 훈련에 MS COCO 데이터만 사용했음에도 더 나은 성능과 더 빠른 추론 속도를 보여줍니다(즉, 79.1 AP vs 75.6 AP, 241 fps vs 158 fps). 또한, HRFormer [48]과 비교하여 ViTPose는 구조가 하나의 브랜치만을 포함하고 상대적으로 작은 특징 해상도(1/16)를 사용하기 때문에 추론 속도가 더 빠릅니다(HRFormer의 1/4과 비교). 다중 데이터셋 훈련을 통해 ViTPose 모델의 성능이 더욱 향상되어 ViTPose의 우수한 확장성과 유연성을 암시합니다. 이러한 관찰 결과는 적절한 훈련과 데이터가 제공될 경우 일반적인 비전 트랜스포머 자체가 서로 다른 키포인트 간의 관계를 잘 모델링하고 포즈 추정 작업을 위해 선형 분리가 잘 되는 특징을 인코딩할 수 있음을 보여줍니다.

그 후 우리는 ViTAE-G [52] 백본을 사용하는 훨씬 강력한 모델인 ViTPose-G를 구축했습니다. 이 모델은 10억 개의 파라미터, 더 큰 입력 해상도(576 × 432), MS COCO 및 AI 챌린저 데이터를 사용하여 ViTPose의 성능 한계를 더욱 탐구합니다. 또한, Bigdet [7]의 더 강력한 디텍터도 사용되어 COCO 데이터셋의 person 클래스에서 68.5 AP의 결과를 제공합니다. Table 10에서 보여지는 바와 같이, ViTAE-G 백본을 가진 단일 ViTPose 모델은 MS COCO test-dev 세트에서 80.9 AP로 모든 이전 SOTA 방법들을 능가하며, 이전의 최고 성능 모델인 UDP++은 17개의 모델을 앙상블하여 약간 더 나은 디텍터(68.6 AP on the person class of COCO dataset)와 함께 80.8 AP를 달성합니다. 세 개의 모델을 앙상블한 후, ViTPose는 81.1 AP의 최고 성능을 달성했습니다.
4.4 Subjective results

우리는 또한 MS COCO 데이터셋에서 ViTPose의 포즈 추정 결과를 시각화했습니다. 그림 3에서 보여지듯이, ViTPose는 중대한 가려짐, 다양한 자세 및 다양한 크기를 가진 도전적인 사례에서도 정확한 포즈 추정 결과를 생성할 수 있으며, 이는 뛰어난 표현 능력 덕분입니다.
5 Limitation and Discussion
본 논문에서는 간단하지만 효과적인 비전 트랜스포머 기반 포즈 추정 베이스라인인 ViTPose를 제안합니다. 구조적으로 복잡한 디자인 없이도 ViTPose는 MS COCO 데이터셋에서 SOTA (State-Of-The-Art) 성능을 달성합니다. 그러나 ViTPose의 잠재력은 복잡한 디코더나 FPN 구조와 같은 고급 기술을 활용하여 아직 완전히 탐색되지 않았으며, 이러한 요소들이 성능을 더욱 향상시킬 수 있습니다. 또한 ViTPose는 단순성, 확장성, 유연성, 전이 가능성과 같은 흥미로운 특성을 보여주지만, 이를 더 깊이 이해하기 위해 추가 연구가 필요할 것입니다. 예를 들어, 프롬프트 기반 튜닝을 통해 ViTPose의 유연성을 추가로 입증하는 것이 가능할 수 있습니다. 이외에도, ViTPose는 동물 포즈 추정 [47, 9, 45] 및 얼굴 키포인트 검출 [21, 6]과 같은 다른 포즈 추정 데이터셋에도 적용될 수 있습니다. 이러한 부분은 향후 연구 과제로 남겨둡니다.
6 Conclusion
본 논문은 비전 트랜스포머 기반 인간 포즈 추정의 간단한 베이스라인으로 ViTPose를 소개합니다. 본 연구는 다양한 포즈 추정 작업에서 단순성, 확장성, 유연성, 전이 가능성을 입증하였으며, MS COCO 데이터셋에 대한 광범위한 실험을 통해 이를 잘 정당화했습니다. 큰 백본 ViTAE-G를 사용한 단일 ViTPose 모델은 MS COCO 테스트-개발 세트에서 최고 80.9 AP를 달성했습니다. 우리는 이 연구가 커뮤니티에 유용한 통찰력을 제공하고 향후 컴퓨터 비전 작업에서 플레인 비전 트랜스포머의 잠재력을 탐구하는 추가 연구에 영감을 줄 수 있기를 바랍니다.
Acknowledgement
Mr. Yufei Xu, Dr. Jing Zhang, 그리고 Mr. Qiming Zhang은 ARC FL-170100117 및 IH-180100002의 지원을 받았습니다.
Yufei Xu, Jing Zhang, Qiming Zhang, Dacheng Tao ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation

댓글남기기