

개요
사람이 현상을 인지하는 것에 시각 외의 여러 감각을 활용하듯 인공 신경망도 그러기를 바라지만 기존의 컨볼루션 모델은 일반적으로 한가지 일을 잘하는 것에 능숙하다. 이미지로 부터 주어진 정보에 대한 명시적인 정보만 추출하기 때문이라고 본 논문의 저자는 언급한다. 여기서 이러한 정보를 여러 테스크에 적용하기 위해선 이미지로 부터 주어지는 암묵적인 정보들을 네트워크가 학습을 해야한다고 한다.
본 논문은 어떻게 해야 네트워크가 명시적인 정보 뿐 아니라 암묵적인 지식들을 학습하고 표현하는지에 대한 논의를 다룬다. 이러한 기능을 수행할 수 있는 통합 네트워크를 제안해서 여러 다양한 작업을 수행하며, 암묵적 지식학습에 다양한 방법을 실험 및 도구 활용 효과를 검증한다. 또한 이러한 암묵적 표현이 물리적인 특성에 대응 댈 수 있음을 보인다.
암묵적 지식에 대하여
- 일반적으로 암묵적 지식이라함은 관찰에 의해서 나타나는 특징(feature)은 아니다.
- 기본적으로 feature space에서의 목적 및 task에 맞는 학습 이후 prejection 된 특징들을 가짐을 볼 수 있다. 마치 피쳐들이 분류 되듯 몰려 있는 이미지를 연상하면 이해하기 쉽다(그림 3). 여기서 학습된 암묵적 특징과의 내적을 통해 차원을 줄임과 동시에 이를 다양한 task에 활용할 수 있다고 하는 것이다.
- 다중 테스크를 다루는 네트워크에서 멀티 헤드를 사용할 때 커널에 대한 공간 불일치 문제가 종종 나타나는데 이를 명시적으로 학습된 피쳐와 암묵적인 표현 과의 수학적 연산으로 최종적으로 정렬 시킬 수 있다고 한다(그림 4).
- 이러한 암묵적 지식의 학습은 좌표 예측, 앵커 검색 등 다양한 작업(task)에 활용될 수 있다.
통합 네트워크
- 기존 네트워크는 에러항에 대해서 최소화 하는 방식으로 학습을 전개한다. 이는 멀티 태스크에 대한 아키텍쳐에서 간단한 수학적 방법으로 에러를 최소화하는 것을 불가능하게 한다.
- 본 논문에서 제안하는 네트워크는 전체 아키텍쳐 중 부분에 대해 암묵적 지식을 연산하는 항을 넣는 것이다. 이는 덧셈, 곱셈, 연결 등의 연산으로 정의한다.
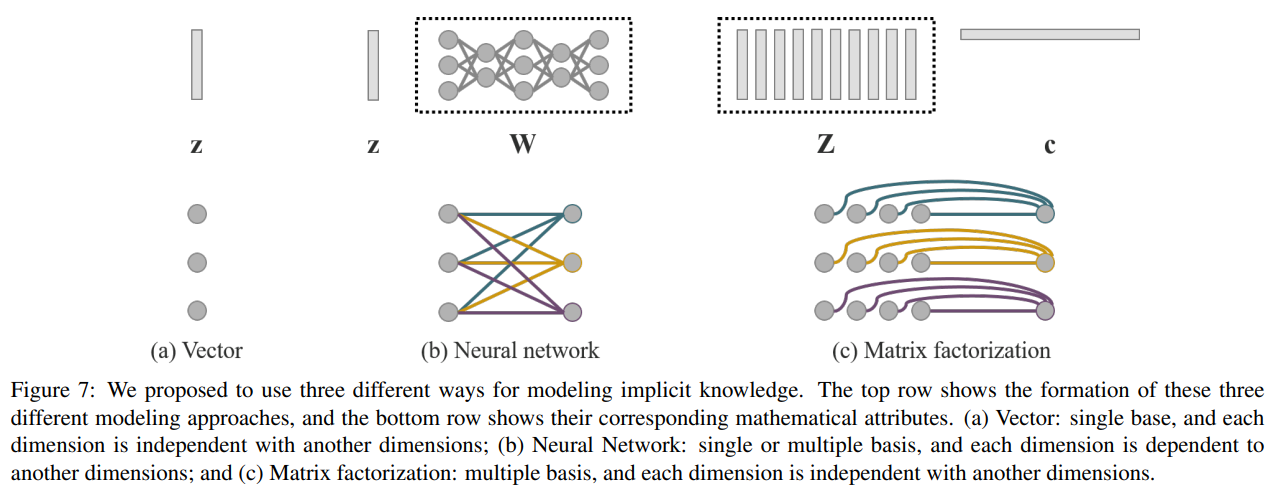
- 암묵적 지식의 모델링 자체에는 텐서(벡터, 행렬 포함), 네트워크, 행렬 분해(Matrix Factorization)으로 모델링 할 수 있다.
실험 결과
- 암묵적 지식 연산에 의한 특징 정렬, 예측 개선, 다중 작업(객체 감지 및 특징 임베딩)에서 AP를 향상시킴을 확인할 수 있다.
- 덧셈 연산 및 곱셈 연산에 따른 암묵적 지식의 적용은 해결하려는 테스크의 물리적 특성을 고려하여 적용하면 성능 향상을 얻을 수 있다.
- 행렬 분해 모델링을 사용한 암묵적 지식의 적용이 다른 방법에 비해 제일 성능이 좋았으며 여러 모델링 방법 자체에 대한 성능 향상을 확인하였다.
결론
단일 테스크 뿐 아니라 다중 테스크를 처리하는데에 필요한 네트워크 설계 및 학습을 위해 인간의 인지 구조와 비슷하게 암묵적 지식(implicit)을 사용하는 방법에 대해 제안하는 논문이다. 기존의 단일 작업을 처리하는 구조에서 해당 방법들을 사용했을 때에 동일 백본 네트워크 대비 성능이 올라감을 확인하였고 이는 여러 테스크(객체 감지 뿐 아니라 관절 추정 및 분할 등)의 여러 작업을 동시에 하는 모델 설계 시 좋은 효과를 볼 수 있음을 시사한다.
번역
Abstract
사람들은 시각, 청각, 촉각 그리고 과거의 경험을 통해 세상을 “이해”합니다. 인간의 경험은 일반적인 학습(이를 명시적 지식이라고 부릅니다) 또는 무의식적으로(이를 암묵적 지식이라고 부릅니다) 학습될 수 있습니다. 이러한 경험들은 일반적인 학습이나 무의식적으로 학습된 후 뇌에 저장됩니다. 이러한 풍부한 경험을 방대한 데이터베이스로 활용하여 인간은 이전에 본 적이 없는 데이터도 효과적으로 처리할 수 있습니다. 본 논문에서는 인간의 뇌가 일반 학습과 무의식적 학습을 통해 지식을 배우는 것처럼, 암묵적 지식과 명시적 지식을 함께 인코딩할 수 있는 통합 네트워크를 제안합니다. 이 통합 네트워크는 다양한 작업을 동시에 수행할 수 있는 통합된 표현을 생성할 수 있습니다. 우리는 커널 공간 정렬, 예측 개선, 다중 작업 학습을 컨볼루션 신경망에서 수행할 수 있습니다. 결과는 암묵적 지식이 신경망에 도입될 때 모든 작업의 성능이 향상된다는 것을 보여줍니다. 우리는 제안된 통합 네트워크에서 학습된 암묵적 표현을 추가로 분석했으며, 이 네트워크는 다양한 작업의 물리적 의미를 포착하는 데 뛰어난 능력을 보였습니다. 본 연구의 소스 코드는 다음에서 확인할 수 있습니다: https://github.com/WongKinYiu/yolor.
1. Introduction

그림 1에서 볼 수 있듯이, 인간은 동일한 데이터를 여러 각도에서 분석할 수 있습니다. 그러나 훈련된 컨볼루션 신경망(CNN) 모델은 일반적으로 하나의 목적만을 수행할 수 있습니다. 일반적으로 훈련된 CNN에서 추출할 수 있는 특징들은 다른 유형의 문제들에 잘 적응하지 못하는 경향이 있습니다. 위 문제의 주요 원인은 우리가 뉴런에서 특징만 추출하고 CNN에서 풍부한 암묵적 지식을 사용하지 않기 때문입니다. 실제 인간의 뇌가 작동할 때, 앞서 언급한 암묵적 지식은 뇌가 다양한 작업을 수행하도록 효과적으로 도울 수 있습니다.
암묵적 지식은 무의식 상태에서 학습된 지식을 의미합니다. 그러나 암묵적 학습이 어떻게 작동하는지, 암묵적 지식을 어떻게 얻는지에 대한 체계적인 정의는 없습니다. 일반적인 신경망 정의에서 얕은 층에서 얻은 특징들은 명시적 지식이라고 부르며, 깊은 층에서 얻은 특징들은 암묵적 지식이라고 부릅니다. 본 논문에서는 관찰과 직접적으로 대응되는 지식을 명시적 지식이라고 부릅니다. 모델에 내재되어 있으며 관찰과 관련이 없는 지식은 암묵적 지식이라고 부릅니다.
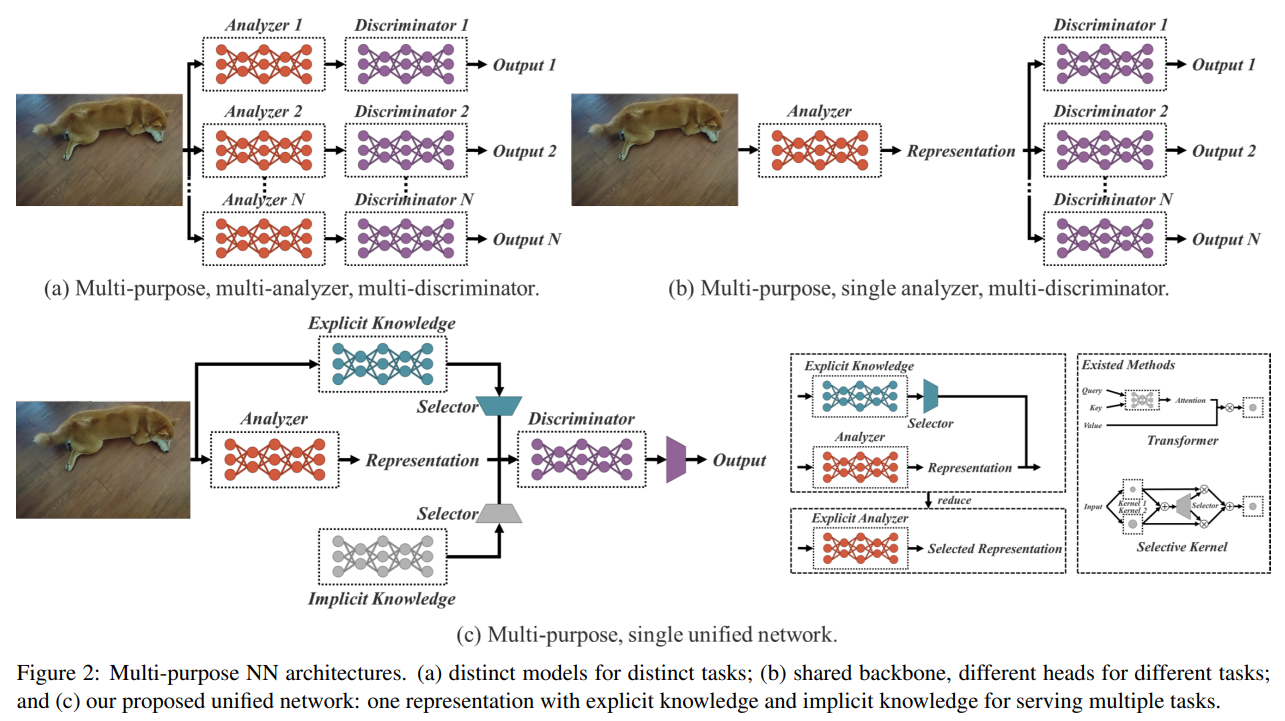
우리는 암묵적 지식과 명시적 지식을 통합하는 통합 네트워크를 제안하며, 학습된 모델이 일반적인 표현을 포함하도록 합니다. 이 일반적인 표현은 다양한 작업에 적합한 하위 표현을 가능하게 합니다. 그림 2.(c)는 제안된 통합 네트워크 아키텍처를 보여줍니다.
위의 통합 네트워크를 구성하는 방법은 압축 감지와 딥러닝을 결합하는 것입니다. 주된 이론적 기초는 이전 연구 [16, 17, 18]에서 찾을 수 있습니다. [16]에서는 확장된 사전을 통해 잔여 오류를 재구성하는 효과를 증명했습니다. [17, 18]에서는 희소 코딩을 사용하여 CNN의 특징 맵을 재구성하고 이를 더 견고하게 만들었습니다. 이 연구의 기여는 다음과 같이 요약됩니다:
- 우리는 다양한 작업을 수행할 수 있는 통합 네트워크를 제안합니다. 이 네트워크는 암묵적 지식과 명시적 지식을 통합하여 일반적인 표현을 학습하며, 이를 통해 다양한 작업을 완료할 수 있습니다. 제안된 네트워크는 매우 적은 추가 비용(매개변수와 계산의 양의 1/1000 이하)으로 모델의 성능을 효과적으로 향상시킵니다.
- 우리는 암묵적 지식 학습 과정에 커널 공간 정렬, 예측 개선, 다중 작업 학습을 도입하고, 그들의 효과를 검증했습니다.
- 우리는 벡터, 신경망, 또는 행렬 분해를 암묵적 지식을 모델링하는 도구로 사용하는 방법을 각각 논의하고, 동시에 그 효과를 검증했습니다.
- 제안된 암묵적 표현이 특정 물리적 특성에 정확히 대응할 수 있음을 확인했으며, 이를 시각적으로도 제시했습니다. 또한, 목표의 물리적 의미를 따르는 연산자들이 있으면, 이를 통해 암묵적 지식과 명시적 지식을 통합할 수 있으며, 이는 배가 효과를 낼 수 있음을 확인했습니다.
- 최첨단 기법들과 결합하여, 제안된 통합 네트워크는 물체 감지에서 Scaled-YOLOv4-P7 [15]과 유사한 정확도를 달성했으며, 추론 속도가 88% 증가했습니다.
2. Related work
우리는 이 연구 주제와 관련된 문헌 검토를 수행합니다. 이 문헌 검토는 주로 세 가지 측면으로 나뉩니다: (1) 명시적 딥러닝: 입력 데이터를 기반으로 자동으로 특징을 조정하거나 선택할 수 있는 몇 가지 방법을 다룹니다, (2) 암묵적 딥러닝: 암묵적 지식 학습 및 암묵적 미분 도함수와 관련된 문헌을 다룹니다, 그리고 (3) 지식 모델링: 암묵적 지식과 명시적 지식을 통합할 수 있는 몇 가지 방법을 나열합니다.
2.1. Explicit deep learning
명시적 딥러닝은 다음과 같은 방법으로 수행될 수 있습니다. 그중 Transformer [14, 5, 20]는 하나의 방법이며, 주로 쿼리, 키 또는 값을 사용하여 셀프 어텐션을 얻습니다. Non-local networks [21, 4, 24]는 또 다른 어텐션을 얻는 방법으로, 주로 시간과 공간에서 쌍방향 어텐션을 추출합니다. 또 다른 일반적으로 사용되는 명시적 딥러닝 방법 [7, 25]은 입력 데이터에 의해 적절한 커널을 자동으로 선택하는 것입니다.
2.2. Implicit deep learning
암묵적 딥러닝 범주에 속하는 방법은 주로 암묵적 신경 표현 [11]과 심층 평형 모델 [2, 3, 19]입니다. 전자는 주로 이산 입력을 매개변수화된 연속 매핑 표현으로 변환하여 다양한 작업을 수행하는 것이며, 후자는 암묵적 학습을 잔차 형태의 신경망으로 변환하여 평형점 계산을 수행하는 것입니다.
2.3. Knowledge modeling
지식 모델링 범주에 속하는 방법으로는 희소 표현 [1, 23]과 메모리 네트워크 [22, 12]가 주로 포함됩니다. 전자는 예시, 사전 정의된 완전한 또는 학습된 사전을 사용하여 모델링을 수행하며, 후자는 다양한 형태의 임베딩을 결합하여 메모리를 형성하고, 메모리를 동적으로 추가하거나 변경할 수 있도록 합니다.
3. How implicit knowledge works?
이 연구의 주요 목적은 암묵적 지식을 효과적으로 학습할 수 있는 통합 네트워크를 구축하는 것이며, 먼저 암묵적 지식을 학습하고 추론을 빠르게 수행하는 방법에 초점을 맞춥니다. 암묵적 표현 $\mathbf{z}_i$ 가 관찰과 무관하므로, 이를 상수 텐서 $Z={\mathbf{z}_1,\mathbf{z}_2,…,\mathbf{z}_k }$ 로 생각할 수 있습니다. 이 섹션에서는 상수 텐서로서의 암묵적 지식이 다양한 작업에 어떻게 적용될 수 있는지 소개합니다.
3.1. Manifold space reduction
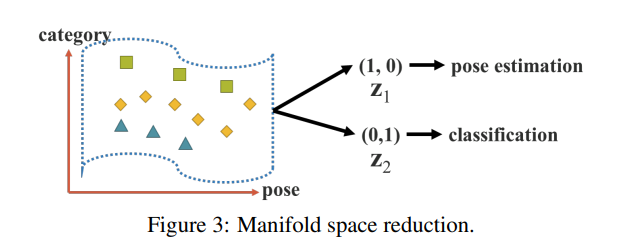
우리는 좋은 표현이 속한 매니폴드 공간에서 적절한 투영을 찾아내고, 이후 목표 작업들이 성공적으로 수행될 수 있도록 해야 한다고 믿습니다. 예를 들어, 그림 3에서처럼 목표 카테고리를 투영 공간의 초평면을 통해 성공적으로 분류할 수 있다면, 그것이 최선의 결과일 것입니다. 위의 예에서, 우리는 투영 벡터와 암묵적 표현의 내적을 취하여 매니폴드 공간의 차원을 줄이는 목표를 달성하고, 다양한 작업을 효과적으로 수행할 수 있습니다.
3.2. Kernel space alignment
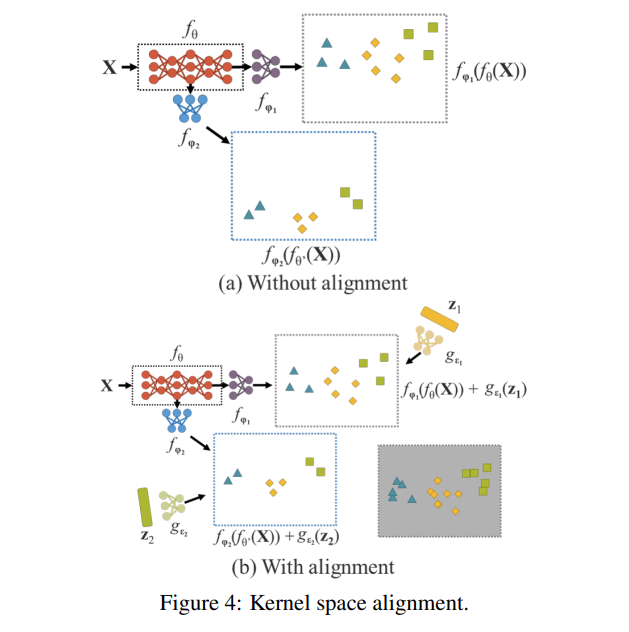
다중 작업 및 다중 헤드 신경망에서 커널 공간 불일치는 자주 발생하는 문제입니다. 그림 4.(a)는 다중 작업 및 다중 헤드 신경망에서 커널 공간 불일치의 예를 보여줍니다. 이 문제를 해결하기 위해 출력 특징과 암묵적 표현의 덧셈과 곱셈을 수행하여, 커널 공간을 이동, 회전, 확장하여 각 신경망의 출력 커널 공간을 정렬할 수 있습니다(그림 4.(b) 참조). 이러한 작동 방식은 다양한 분야에서 널리 사용될 수 있으며, 예를 들어 큰 물체와 작은 물체의 특징 정렬, 지식 증류를 통한 대형 모델과 소형 모델의 통합, 제로샷 도메인 전이 처리 등의 문제에도 활용될 수 있습니다.
3.3. More functions
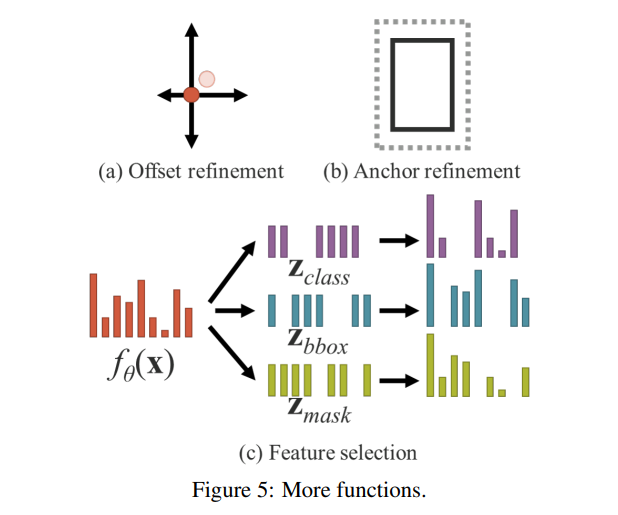
다양한 작업에 적용할 수 있는 기능 외에도 암묵적 지식은 더 많은 기능으로 확장될 수 있습니다. 그림 5에서 설명된 것처럼, 덧셈을 도입함으로써 신경망이 중심 좌표의 오프셋을 예측할 수 있습니다. 또한, 곱셈을 도입하여 앵커 기반 객체 탐지기에서 자주 필요한 앵커의 하이퍼 파라미터 집합을 자동으로 검색할 수도 있습니다. 또한, 점곱과 연결을 각각 사용하여 다중 작업 특징 선택을 수행하고 후속 계산을 위한 사전 조건을 설정할 수 있습니다.
4. Implicit knowledge in our unified networks
이 섹션에서는 기존 네트워크와 제안된 통합 네트워크의 목표 함수를 비교하고, 다목적 네트워크 훈련에서 암묵적 지식을 도입하는 것이 왜 중요한지 설명할 것입니다. 동시에 이 연구에서 제안된 방법의 세부 사항도 설명할 것입니다.
4.1. Formulation of implicit knowledge
Conventional Networks(기존 네트워크)
기존 네트워크 훈련의 목표 함수를 (1)과 같이 나타낼 수 있습니다:
\[\begin{equation}\begin{aligned} y = f_\theta(x) + \epsilon\\ \text{minimize } \epsilon \end{aligned}\end{equation}\]여기서 $x$ 는 관찰값이고, $θ$ 는 신경망의 매개변수 집합이며, $f_θ$ 는 신경망의 작동을 나타내며, $ϵ$ 은 오류 항이고, $y$ 는 주어진 작업의 목표입니다.
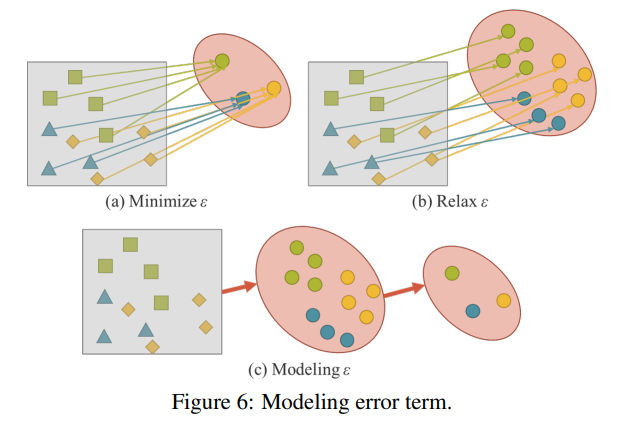
기존 신경망의 훈련 과정에서, 일반적으로 $ϵ$ 을 최소화하여 $f_θ(x)$ 가 목표에 최대한 가깝게 만듭니다. 이는 그림 6.(a)에서처럼 동일한 목표를 가진 서로 다른 관찰값들이 $f_θ$ 에 의해 얻어진 하위 공간의 하나의 점에 해당하기를 기대한다는 것을 의미합니다. 다시 말해, 우리가 기대하는 해결 공간은 현재 작업 $t_i$ 에 대해서만 판별력을 가지며, 다른 잠재적 작업 $T ∖ t_i$ 에는 불변입니다. 여기서 $T={t_1,t_2,…,t_n}$ 입니다.
범용 신경망의 경우, 우리는 얻어진 표현이 $
T$ 에 속하는 모든 작업을 처리할 수 있기를 바랍니다. 따라서 그림 6.(b)에서처럼 매니폴드 공간에서 각 작업의 해결책을 동시에 찾을 수 있도록 $ϵ$ 을 완화해야 합니다. 그러나 위의 요구 사항은 우리가 원핫 벡터의 최대값 또는 유클리드 거리의 임계값과 같은 간단한 수학적 방법을 사용하여 $t_i$ 의 해결책을 얻는 것을 불가능하게 만듭니다. 이 문제를 해결하기 위해서는 오류 항 $ϵ$ 을 모델링하여 서로 다른 작업의 해결책을 찾아야 합니다(그림 6.(c) 참조).
Unified Networks(통합 네트워크)
제안된 통합 네트워크를 훈련하기 위해, 우리는 명시적 지식과 암묵적 지식을 함께 사용하여 오류 항을 모델링하고, 이를 다목적 네트워크 훈련 프로세스를 안내하는 데 사용합니다. 훈련에 대한 해당 방정식은 다음과 같습니다:
\[\begin{equation}\begin{aligned} y = f_\theta(x) + \epsilon + g_\phi(\epsilon_{ex}(x),\epsilon_{im}(z)) \\ \text{minimize }\epsilon + g_\phi(\epsilon_{ex}(x),\epsilon_{im}(z)) \end{aligned}\end{equation}\]여기서 $ϵ_{ex}$ 와 $ϵ_{im}$ 은 각각 명시적 오류와 암묵적 오류를 모델링하는 연산이며, $x$ 는 관찰값이고 $z$ 는 잠재 코드입니다. $g_ϕ$ 는 명시적 지식과 암묵적 지식에서 정보를 결합하거나 선택하는 작업별 연산입니다.
명시적 지식을 $f_\theta$ 에 통합하는 몇 가지 기존 방법이 있으므로, (2)를 (3)으로 다시 쓸 수 있습니다.
여기서 $\star$ 는 $f_{\theta}$ 와 $g_{\phi}$ 를 결합할 수 있는 가능한 연산자를 나타냅니다. 본 논문에서는 3장에서 소개된 덧셈, 곱셈, 연결 연산자를 사용합니다.
오류 항을 처리하는 유도 과정을 여러 작업으로 확장하면, 다음 방정식을 얻을 수 있습니다:
여기서 $Z = { z_1, z_2,…, z_T}$ 는 서로 다른 작업 $T$ 의 암묵적 잠재 코드 집합입니다. $\Phi$ 는 $Z$ 에서 암묵적 표현을 생성하는 데 사용되는 매개변수입니다. $\Psi$ 는 명시적 표현과 암묵적 표현의 다양한 조합에서 최종 출력 매개변수를 계산하는 데 사용됩니다.
다양한 작업을 위해, 우리는 모든 $z \in Z$ 에 대한 예측을 얻기 위해 다음 공식을 사용할 수 있습니다:
모든 작업에 대해, 우리는 공통된 통합 표현 $f_{\theta}(\mathbf{x})$ 으로 시작하여, 작업별 암묵적 표현 $g_{\Phi}(\mathbf{z})$ 을 거치고, 마지막으로 작업별 판별자 $d_{\Psi}$ 를 사용하여 작업을 완료합니다.
4.2. Modeling implicit knowledge
우리가 제안한 암묵적 지식은 다음과 같은 방법으로 모델링될 수 있습니다.
벡터 / 행렬 / 텐서:
\[\begin{align} \mathbf{z} \end{align}\]벡터 $\mathbf{z}$ 를 암묵적 지식의 사전 정보로 직접 사용하고, 이를 암묵적 표현으로 사용합니다. 이때, 각 차원이 서로 독립적임을 가정해야 합니다.
신경망:
\[\begin{align} \mathbf{W}\mathbf{z} \end{align}\]벡터 $\mathbf{z}$ 를 암묵적 지식의 사전 정보로 사용한 후, 가중치 행렬 $\mathbf{W}$ 를 사용하여 선형 결합 또는 비선형화를 수행하여 암묵적 표현으로 변환합니다. 이때, 각 차원이 서로 종속적임을 가정해야 합니다. 더 복잡한 신경망을 사용하여 암묵적 표현을 생성하거나, 마르코프 체인을 사용해 서로 다른 작업 간의 암묵적 표현 상관 관계를 시뮬레이션할 수 있습니다.
행렬 분해:
\[\begin{align} \mathbf{Z^Tc} \end{align}\]여러 벡터를 암묵적 지식의 사전 정보로 사용하며, 이 암묵적 사전 기반 $\mathbf{Z}$ 와 계수 $\mathbf{c}$ 는 암묵적 표현을 형성합니다. 또한, $\mathbf{c}$ 에 희소 제약을 추가하여 희소 표현으로 변환할 수 있습니다. 추가적으로, $\mathbf{Z}$ 와 $\mathbf{c}$ 에 비음수 제약을 부과하여 이를 비음수 행렬 분해(NMF) 형태로 변환할 수 있습니다.
4.3. Training
우리 모델이 처음에는 암묵적 지식에 대한 사전 정보가 없다고 가정합니다. 즉, 이는 명시적 표현 $f_{\theta}(x)$ 에 영향을 미치지 않습니다. 결합 연산자가 $\star \in {\text{덧셈, 연결}}$ 일 때, 초기 암묵적 사전 $z \sim N(0, \sigma)$, 그리고 결합 연산자가 곱셈일 때 $z \sim N(1, \sigma)$ 입니다. 여기서 $\sigma$ 는 거의 0에 가까운 매우 작은 값입니다. $z$ 와 $\phi$ 는 모두 훈련 과정에서 역전파 알고리즘으로 학습됩니다.
4.4. Inference
암묵적 지식은 관찰 $x$ 와 무관하므로, 암묵적 모델 $g_ϕ$ 가 아무리 복잡하더라도, 추론 단계가 실행되기 전에 이를 상수 텐서 집합으로 축소할 수 있습니다. 즉, 암묵적 정보의 형성은 우리 알고리즘의 계산 복잡성에 거의 영향을 미치지 않습니다. 또한, 위의 연산자가 곱셈인 경우, 후속 레이어가 합성곱 레이어이면 아래 (9)를 사용하여 통합합니다. 덧셈 연산자를 만날 때, 이전 레이어가 합성곱 레이어이고 활성화 함수가 없는 경우, 아래 (10)을 사용하여 통합합니다.
\[\begin{equation}\begin{aligned} \mathbf{x}_{(l+1)} &= \sigma(W_l(g_\phi(\mathbf{z})\mathbf{x}_l)+b_l) \\ &= \sigma(W'(\mathbf{x}_l)+b_l), \text{where} W'_l=W_lg_\phi(\mathbf{z}) \end{aligned}\end{equation}\] \[\begin{equation}\begin{aligned} \mathbf{x}_{(l+1)} &= W_l(\mathbf{x}_l)+ b_l + g_\phi(\mathbf{z}) \\ &= W_l(\mathbf{x}_l) +b_l, \text{where} \ b'_l=b_l + g_\phi(\mathbf{z}) \end{aligned}\end{equation}\]5. Experiments
우리의 실험은 MSCOCO 데이터셋 [9]을 사용하였으며, 이 데이터셋은 여러 작업에 대한 정확한 정답을 제공합니다. 포함된 작업으로는 1물체 탐지, 2인스턴스 분할, 3파놉틱 분할, 4키포인트 탐지, 5재료 분할, 6이미지 캡션, 7다중 레이블 이미지 분류, 그리고 8롱테일 물체 인식이 있습니다. 이러한 풍부한 주석 내용을 가진 데이터는 컴퓨터 비전 관련 작업뿐만 아니라 자연어 처리 작업을 지원하는 통합 네트워크 훈련에 도움이 됩니다.
5.1. Experimental setup
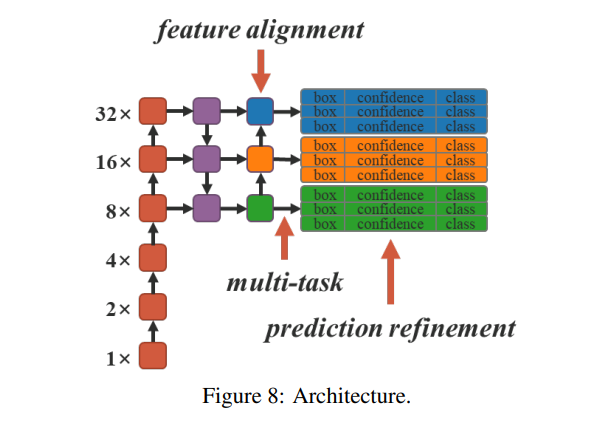
실험 설계에서 우리는 암묵적 지식을 세 가지 측면에 적용하기로 결정했습니다. 이는 1.FPN에 대한 특징 정렬, 2. 예측 개선, 그리고 3. 단일 모델에서의 다중 작업 학습입니다. 다중 작업 학습에 포함된 작업은 1. 객체 감지, 2. 다중 레이블 이미지 분류, 그리고 3. 특징 임베딩입니다. 우리는 실험에서 YOLOv4-CSP [15]를 기준 모델로 선택했으며, 그림 8에서 화살표로 표시된 지점에서 모델에 암묵적 지식을 도입했습니다. 모든 훈련 하이퍼파라미터는 Scaled-YOLOv4 [15]의 기본 설정과 비교되었습니다.
5.2, 5.3, 5.4절에서는 가장 단순한 벡터 암묵적 표현과 덧셈 연산자를 사용하여 암묵적 지식이 도입되었을 때 다양한 작업에 미치는 긍정적인 영향을 검증합니다. 5.5절에서는 명시적 지식과 암묵적 지식의 다양한 조합에 대해 서로 다른 연산자를 사용하여 이러한 조합의 효과를 논의할 것입니다. 5.6절에서는 서로 다른 접근 방식을 사용하여 암묵적 지식을 모델링할 것입니다. 5.7절에서는 암묵적 지식 도입 유무에 따른 모델을 분석합니다. 마지막으로, 5.8절에서는 암묵적 지식을 사용하여 객체 탐지기를 훈련한 후 최신 기법과 성능을 비교할 것입니다.
5.2. Feature alignment for FPN
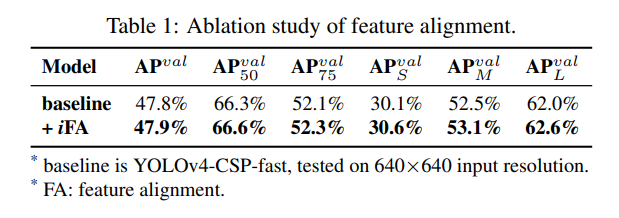
우리는 FPN의 각 특징 맵에 암묵적 표현을 추가하여 특징 정렬을 수행했으며, 이에 대한 실험 결과는 표 1에 나타나 있습니다. 표 1에서 나타난 결과를 보면, 특징 공간 정렬을 위한 암묵적 표현을 사용한 후 $AP_S$, $AP_M$, $AP_L$ 을 포함한 모든 성능이 약 0.5% 향상된 것을 알 수 있습니다. 이는 매우 중요한 개선입니다.
5.3. Prediction refinement for object detection
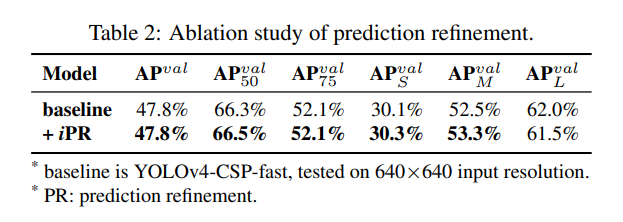
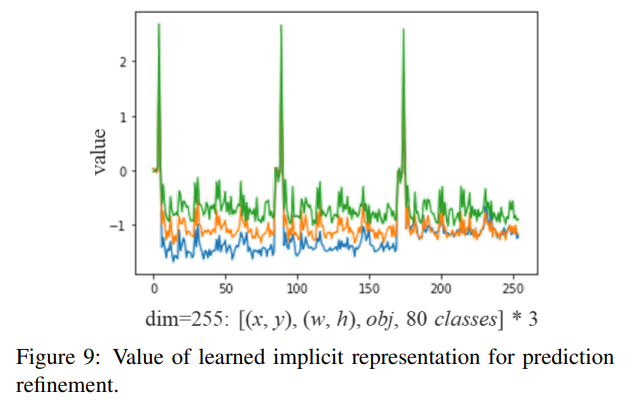
YOLO 출력 레이어에 암묵적 표현을 추가하여 예측 개선을 수행했습니다. 표 2에서 볼 수 있듯이, 거의 모든 지표 점수가 향상되었습니다. 그림 9는 암묵적 표현 도입이 탐지 결과에 어떻게 영향을 미치는지 보여줍니다. 객체 탐지의 경우, 암묵적 표현에 대한 사전 지식을 제공하지 않더라도 제안된 학습 메커니즘은 여전히 각 앵커의 $(x,y)$, $(w,h)$, $(obj)$, $(classes)$ 패턴을 자동으로 학습할 수 있습니다.
5.4. Canonical representation for multi-task
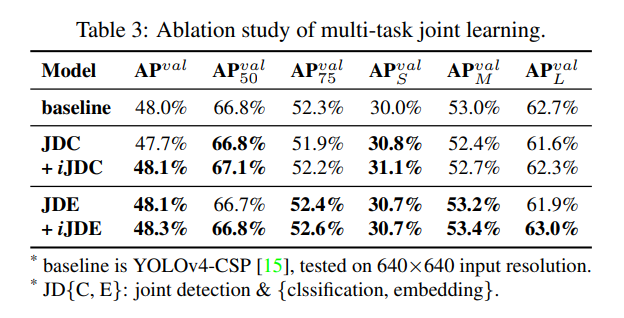

여러 작업을 동시에 공유할 수 있는 모델을 훈련하고자 할 때, 손실 함수에 대한 합동 최적화 과정이 수행되어야 하기 때문에 여러 작업 간에 상호작용이 발생하게 됩니다. 이러한 상황은 개별 모델을 따로 훈련한 후 통합하는 것보다 최종 성능이 더 나빠질 수 있습니다. 이를 해결하기 위해, 우리는 다중 작업을 위한 표준 표현을 훈련할 것을 제안합니다. 우리의 아이디어는 각 작업 분기에 암묵적 표현을 도입하여 표현력을 강화하는 것이며, 그 효과는 표 3에 나열되어 있습니다. 표 3에서 나타난 데이터를 보면, 암묵적 표현이 도입되지 않은 경우에도 다중 작업 훈련 후 일부 지표는 향상되었고, 일부는 감소했습니다. 합동 탐지 및 분류(JDC)에 암묵적 표현을 도입한 후 +iJDC에 해당하는 모델 범주에서 전반적인 지표 점수가 크게 향상되었고, 단일 작업 훈련 모델의 성능을 능가한 것을 명확히 확인할 수 있습니다. 암묵적 표현이 도입되지 않은 경우와 비교했을 때, 중간 크기 및 큰 크기 물체에서 모델 성능이 각각 0.3% 및 0.7% 향상되었습니다. 합동 탐지 및 임베딩(JDE) 실험에서, 특징 정렬에 의해 암묵적 표현이 내포된 특성 때문에 지표 점수 개선 효과가 더욱 두드러집니다. 표 3에 나열된 JDE 및 +iJDE에 해당하는 지표 점수 중, +iJDE의 모든 지표 점수가 암묵적 표현을 도입하지 않은 지표를 능가했습니다. 그중에서도 큰 물체에 대한 AP는 1.1%까지 증가했습니다.
5.5. Implicit modeling with different operators
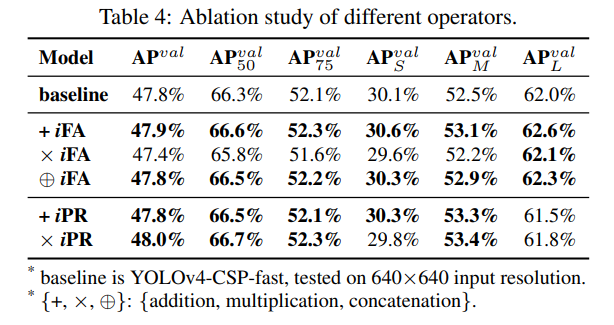
표 4는 그림 10에 표시된 다양한 연산자를 사용하여 명시적 표현과 암묵적 표현을 결합한 실험 결과를 보여줍니다. 특징 정렬에 대한 암묵적 지식 실험에서는 덧셈과 연결이 모두 성능을 향상시키는 반면, 곱셈은 성능을 저하시키는 것으로 나타났습니다. 특징 정렬의 실험 결과는 물리적 특성과 완전히 일치합니다. 이는 전역 이동과 모든 개별 클러스터의 확장 문제를 처리해야 하기 때문입니다. 예측 개선을 위한 암묵적 지식 실험에서는, 출력 차원을 변경하는 연결 연산자 대신 덧셈과 곱셈 연산자의 효과만 비교했습니다. 이 실험에서는 곱셈 적용이 덧셈 적용보다 더 나은 성능을 보였습니다. 이유를 분석한 결과, 중심 이동은 예측을 실행할 때 덧셈 디코딩을 사용하고, 앵커 크기 조정은 곱셈 디코딩을 사용하는 것으로 나타났습니다. 중심 좌표는 그리드로 제한되므로 영향이 적고, 인위적으로 설정된 앵커가 더 큰 최적화 공간을 가지므로 개선이 더 중요합니다.
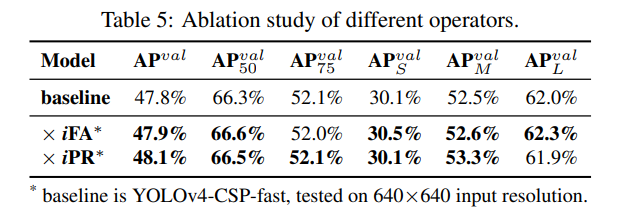
위 분석을 바탕으로, 우리는 두 가지 실험 세트를 설계했습니다 – {×iFA, ×iPR}. 첫 번째 실험 세트 – ×iFA에서는 특징 공간을 앵커 클러스터 수준으로 분할하여 곱셈과 결합하였고, 두 번째 실험 세트 – ×iPR에서는 예측에서 너비와 높이에 대해 곱셈 개선만 수행했습니다. 위 실험 결과는 표 5에 설명되어 있습니다. 표 5에서 나타난 결과에 따르면, 해당 수정 이후 다양한 지표의 점수가 종합적으로 향상된 것을 알 수 있습니다. 이 실험은 명시적 지식과 암묵적 지식을 결합할 때, 결합된 레이어의 물리적 의미를 먼저 고려해야 곱셈 효과를 얻을 수 있음을 보여줍니다.
5.6. Modeling implicit knowledge in different ways
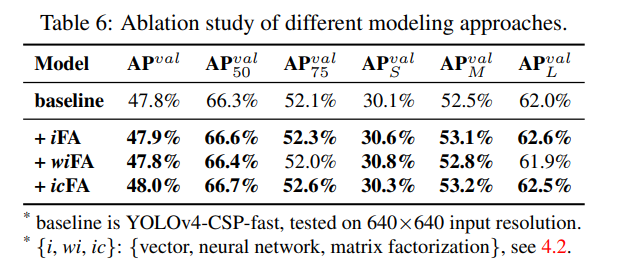
우리는 벡터, 신경망, 행렬 분해를 포함한 여러 방식으로 암묵적 지식을 모델링하려고 했습니다. 신경망 및 행렬 분해를 사용한 모델링의 경우, 암묵적 사전 차원의 기본값은 명시적 표현 차원의 두 배입니다. 이 실험 결과는 표 6에 나와 있습니다. 신경망이나 행렬 분해를 사용하여 암묵적 지식을 모델링하더라도 전반적인 효과가 개선되는 것을 알 수 있습니다. 그중에서도 행렬 분해 모델을 사용한 결과가 가장 좋았으며, 이는 $AP$, $AP_{50}$, $AP_{75}$ 의 성능을 각각 0.2%, 0.4%, 0.5% 향상시켰습니다. 이 실험을 통해 다양한 모델링 방법의 효과를 입증했습니다. 또한 암묵적 표현의 미래 가능성을 확인했습니다.
5.7. Analysis of implicit models
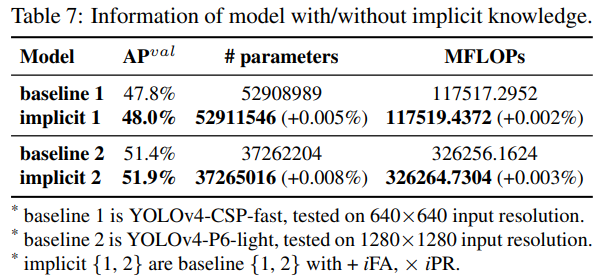
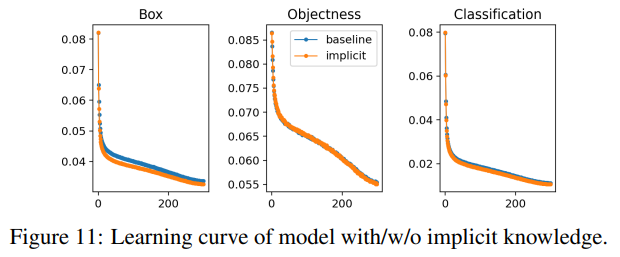
우리는 암묵적 지식이 있는/없는 모델의 파라미터 수, FLOPs, 학습 과정을 분석하고, 그 결과를 각각 표 7과 그림 11에 나타냈습니다. 실험 데이터에 따르면, 암묵적 지식이 포함된 모델에서는 파라미터와 계산량이 1만분의 1 이하로만 증가했으며, 이는 모델의 성능을 상당히 향상시킬 수 있으며, 학습 과정도 빠르고 정확하게 수렴할 수 있음을 발견했습니다.
5.8. Implicit knowledge for object detection

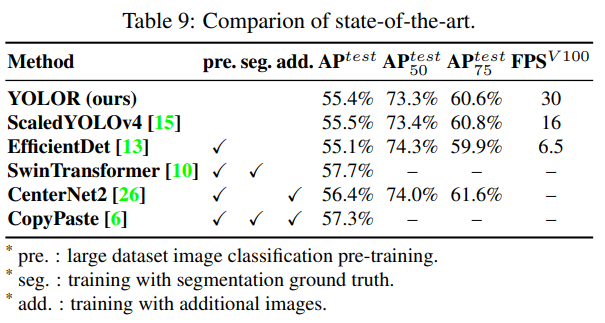
마지막으로, 우리는 제안된 방법의 효과를 객체 탐지의 최신 기술들과 비교했습니다. 암묵적 지식 도입의 이점은 표 8에 나와 있습니다. 전체 훈련 과정에서 우리는 scaled-YOLOv4 [15] 훈련 과정을 따랐으며, 처음 300 에포크는 처음부터 훈련하고, 그 후 150 에포크를 미세 조정했습니다. 표 9는 최신 기술들과의 비교를 설명합니다. 주목할 점은, 제안된 방법에는 추가적인 학습 데이터와 주석이 없다는 것입니다. 암묵적 지식의 통합 네트워크를 도입함으로써, 우리는 여전히 최신 기술과 맞먹는 충분한 결과를 달성했습니다.
6. Conclusions
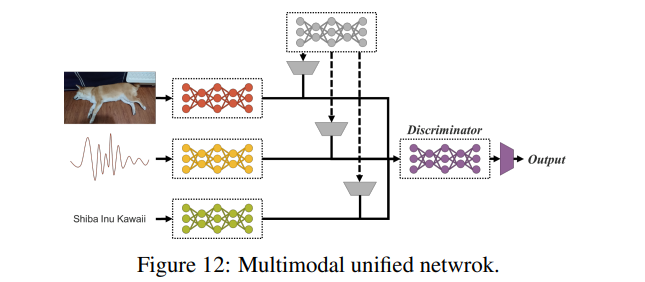
이 논문에서 우리는 암묵적 지식과 명시적 지식을 통합하는 통합 네트워크를 구축하는 방법을 제시하고, 단일 모델 아키텍처에서 다중 작업 학습에 여전히 매우 효과적이라는 것을 입증했습니다. 앞으로 우리는 그림 12에서처럼 다중 모달 및 다중 작업으로 학습을 확장할 것입니다.
7. Acknowledgements
저자들은 컴퓨팅 및 저장 자원을 제공한 NCHC(고성능 컴퓨팅 국립 센터)에 감사드립니다.
Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao You Only Learn One Representation: Unified Network for Multiple Tasks

댓글남기기