

개요
YOLOR에 이은 YOLOX 리포트의 얕은 리뷰.
과거 YOLOv5 까지 나온 시점(2021년)에서 주요 객체 감지 방식의 바전은 앵커-Free, 발전된 라벨 할당 전략, NMS-Free 방식 등의 연구에 집중 되었다. 본 논문은 이러한 발전 사항들을 YOLOv3를 베이스로 적용하여 향상된 객체감지 성능을 확인한 논문이다. 여기서 베이스는 YOLOv3-SPP 아키텍쳐를 사용했다고 한다. 또한 이를 ONNX, TensorRT 등의 여러 프레임워크로도 제공한다.
YOLOX 아키텍쳐
- 본 논문의 아키텍쳐는 DarkNet53 백본 및 SPP 레이어를 채택한 YOLOv3-SPP 구조를 베이스로 한다.
- COCO 2017 데이터를 활용한 300에폭의 학습, SGD 채택, 0.01의 학습률로 시작하는 cosine decay 및 선형 스케일링(batch 64) 적용, Weight Decay 적용, cls와 obj 헤드에 BCE 손실, reg 헤드(박스 위치)에 IoU 손실 적용, 랜덤 리사이즈 크롭을 제외한 증강 전략 채택 등의 전략을 가져간다.
- 벤치마크의 측정은 V100 GPU에서 FP16의 정밀도로 측정된다.
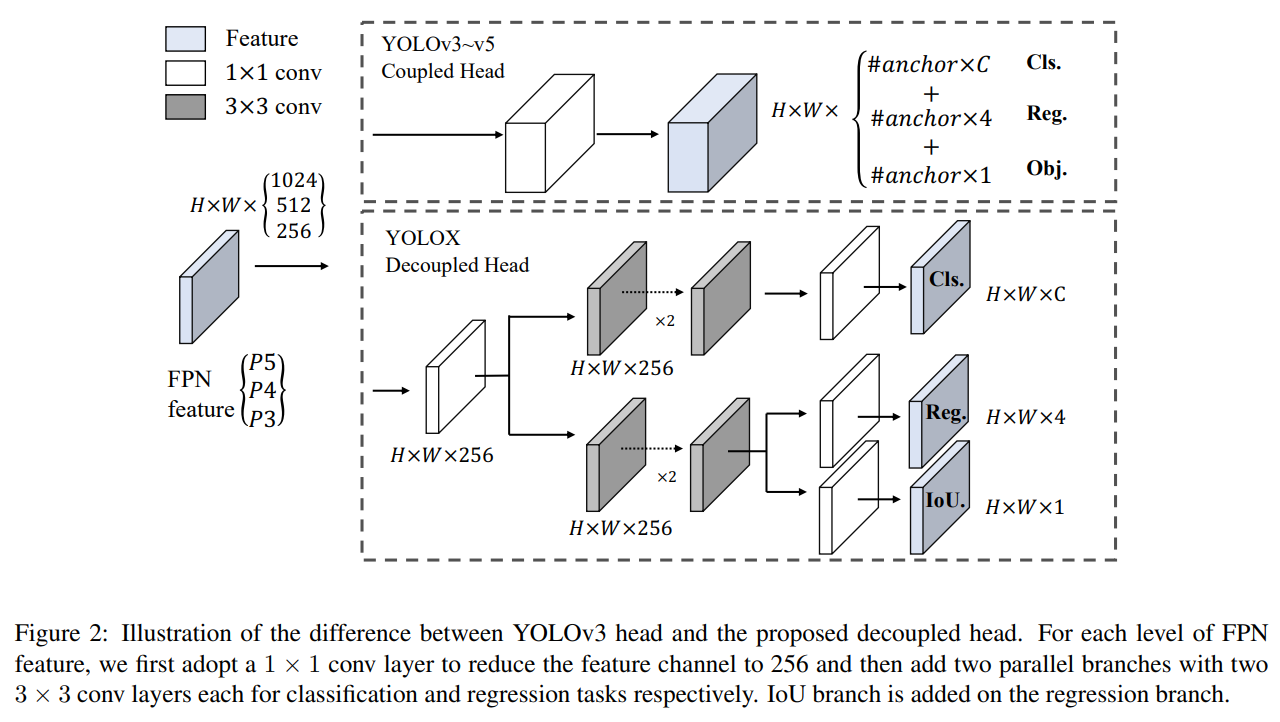
- 통합 헤드 대신 분리형 헤드를 채택하였다: 클래스 카테고리, 박스의 위치, 객체 헤드를 각각 분리
- 모자이크와 믹스업 증강을 추가로 채택하고 이미지 넷 데이터 셋에 대한 pretrained 된 가중치를 사용하지 않고 스크래치로 사용하였다.
- 앵커 프리 전략을 채택하여 각 그리드 별로 하나의 예측만 하게 한 뒤 좌상단 모서리를 기준으로의 오프셋, 바운딩 박스의 높이 너비 값을 예측한다.
- 기존의 앵커 방식의 객체감지는 데이터 셋의 도메인에 특화되며 일반화 되지 않는다. 또한 헤드의 복잡성을 증가시키고 예측 수를 증가시켜, 엣지 AI 시스템에서는 병목 현상을 일으킬 수 있다.
- 앵커 프리 버전에서 하나의 긍정 샘플만 채택하지만 중심 좌표의 3x3에 맞는 샘플(center sampling)을 가중치 업데이트에 positive 로 활용하여 negative 샘플과의 불균형을 완화시키고 성능을 향상시킨다.
- 기존 OTA에서 라벨 할당에 대한 전략은 Optimal Transport 문제로 공식화했는데 이를 실제 라벨과 예측 라벨에 대한 비용 식을 통해 Top-k를 사용하는 방식인 SimOTA 를 제안한다. 이는 훈련시간을 줄이며 탐지기의 성능도 향상 시킨다.
- 추가적으로 최종 출력까지 2개의 CNN 추가 및 1:1 라벨할당 등의 전략을 더해 End-to-end 방식으로 학습을 시도해보려했는데 이는 성능이 떨어지는 이슈가 있어 선택적으로 남겨두었다고 한다.
다른 모델과의 비교
- YOLOv5의 스케일 전략과 동일하게 YOLOX에 적용하여 비교시 약 1%~3%의 성능향상을 보였다.
- 소형 모델 들(Tiny, Nano)과의 비교 시 비슷한 파라미터 수로 더 높은 AP를 달성하였다.
- 또한 강력한 증강은 아키텍쳐의 스케일 사이즈가 어느정도 받쳐줘야 좋은 효과를 불러옴을 확인한다. 규모가 작은 모델에서는 증강 전략을 강하게 가져가는 것이 성능을 끌어올리는데에 큰 도움이 되지 않는다는 것을 확인한다.
결론
본 논문의 YOLOX-X 모델은 COCO 2017 test-dev 데이터 셋을 기준으로 YOLOv3, EfficientDet, YOLOv4, YOLOv5 등의 아키텍쳐와 비교하여 최고성능을 달성한다. 이러한 향상을 달성하기 위해 앵커 프리, 분리형 헤드, 발전된 라벨 할당 전략 등을 채택한다. 또한 다양한 스케일에서의 학습 전략 및 엣지 디바이스에서 활용할 수 있는 소형 모델의 성능도 효과적으로 향상 시킴을 보여준다.
추가적으로 CVPR 2021에서 열린 스트리밍 챌린지에서 1위를 하여 실시간 처리가 중요한 환경에서도 뛰어난 성능을 입증한다.
번역
Abstract
이 보고서에서는 YOLO 시리즈에 몇 가지 경험적 개선 사항을 제시하여 새로운 고성능 탐지기인 YOLOX를 구성합니다. 우리는 YOLO 탐지기를 앵커 프리 방식으로 전환하고, 분리형 헤드 및 선도적인 라벨 할당 전략인 SimOTA와 같은 고급 탐지 기술을 적용하여 광범위한 모델에 걸쳐 최첨단 성능을 달성합니다. YOLO-Nano는 단 0.91M 파라미터와 1.08G FLOPs로 COCO에서 25.3%의 AP를 달성하여 NanoDet보다 1.8% AP 우위를 기록했습니다. 산업에서 가장 널리 사용되는 탐지기 중 하나인 YOLOv3의 경우, COCO에서 47.3%의 AP를 달성하여 현재 최선의 실적보다 3.0% AP가 향상되었습니다. YOLOv4-CSP, YOLOv5-L과 비슷한 파라미터 양을 가진 YOLOX-L의 경우, Tesla V100에서 68.9 FPS의 속도로 COCO에서 50.0% AP를 달성하여 YOLOv5-L보다 1.8% AP가 향상되었습니다. 또한, 우리는 CVPR 2021에서 열린 자율주행 워크숍 스트리밍 인식 챌린지에서 단일 YOLOX-L 모델을 사용하여 1위를 차지했습니다. 이 보고서가 개발자와 연구자들에게 실질적인 장면에서 유용한 경험을 제공하길 바라며, ONNX, TensorRT, NCNN, Openvino를 지원하는 배포 버전도 제공합니다. 소스 코드는 https://github.com/Megvii-BaseDetection/YOLOX에서 확인할 수 있습니다.
1. Introduction
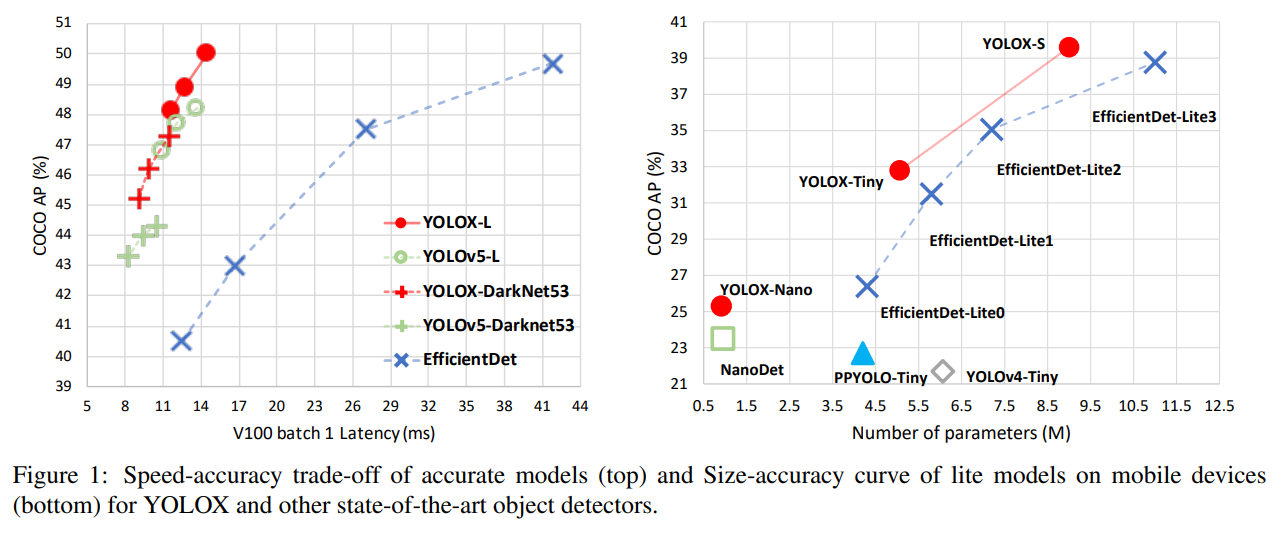
객체 탐지 기술이 발전함에 따라, YOLO 시리즈는 [23, 24, 25, 1, 7] 항상 실시간 응용을 위한 최적의 속도 및 정확도 상충 관계를 추구해 왔습니다. 이들은 당시 사용할 수 있는 가장 발전된 탐지 기술(예: YOLOv2 [24]의 앵커 [26], YOLOv3 [25]의 잔차 네트워크 [9])을 도입하여 모범 사례를 위한 구현을 최적화했습니다. 현재, YOLOv5 [7]는 COCO에서 13.7ms의 시간에 48.2% AP로 최고의 상충 성능을 보유하고 있습니다.
그러나 지난 2년 동안 객체 탐지 학계의 주요 발전은 앵커 프리 탐지기 [29, 40, 14], 고급 라벨 할당 전략 [37, 36, 12, 41, 22, 4], 그리고 종단 간 (NMS-free) 탐지기 [2, 32, 39]에 집중되었습니다. 이러한 기술들은 아직 YOLO 계열에 통합되지 않았으며, YOLOv4와 YOLOv5는 여전히 앵커 기반 탐지기로서 훈련을 위한 수작업 할당 규칙을 사용합니다.
이러한 최근의 발전 사항들을 YOLO 시리즈에 전달하며, 경험적 최적화를 수행하게 되었습니다. YOLOv4와 YOLOv5가 앵커 기반 파이프라인에 대해 다소 과도하게 최적화되었을 수 있음을 고려하여, YOLOv3 [25]를 시작점으로 선택했습니다(YOLOv3-SPP를 기본 YOLOv3로 설정했습니다). 실제로 YOLOv3는 제한된 계산 자원과 실용적인 응용 프로그램에서 소프트웨어 지원이 부족하기 때문에 여전히 산업에서 가장 널리 사용되는 탐지기 중 하나입니다.
그림 1에서 알 수 있듯이, 위에서 언급한 기술을 적용하여 YOLOv3의 성능을 향상시켜 COCO에서 640 × 640 해상도로 47.3%의 AP(YOLOX-DarkNet53)를 달성하여 현재 YOLOv3(44.3% AP, ultralytics 버전)의 최선 실적을 크게 능가합니다. 또한, 고급 CSPNet [31] 백본과 추가 PAN [19] 헤드를 채택한 고급 YOLOv5 아키텍처로 전환할 때, YOLOX-L은 640 × 640 해상도에서 COCO에서 50.0% AP를 달성하여 YOLOv5-L을 1.8% AP로 능가합니다. 우리는 또한 소형 모델에서 우리의 설계 전략을 테스트했습니다. YOLOX-Tiny와 YOLOX-Nano (단 0.91M 파라미터 및 1.08G FLOPS)는 각각 YOLOv4-Tiny와 NanoDet보다 10% AP와 1.8% AP로 더 나은 성능을 보였습니다.
우리는 ONNX, TensorRT, NCNN 및 Openvino를 지원하는 소스 코드를 https://github.com/Megvii-BaseDetection/YOLOX에서 공개했습니다. 또 한 가지 주목할 만한 점은, 우리는 CVPR 2021에서 열린 자율 주행 워크숍 스트리밍 인식 챌린지에서 YOLOX-L 단일 모델로 1위를 차지했다는 점입니다.
2. YOLOX
2.1. YOLOX-DarkNet53
우리는 YOLOv3 [25]과 Darknet53을 기반으로 선택했습니다. 이어지는 부분에서는 YOLOX의 전체 시스템 디자인을 단계별로 설명할 것입니다.
Implementation details
우리의 훈련 설정은 기본 모델에서 최종 모델까지 대부분 일관성을 유지합니다. 모델은 COCO train2017 [17]에서 5번의 워밍업 에포크를 포함하여 총 300 에포크 동안 훈련합니다. 우리는 훈련에 확률적 경사 하강법(SGD)을 사용합니다. 학습률은 $lr×BatchSize/64$ (선형 스케일링 [8])이며, 초기 학습률은 $lr=0.01$ 이고 코사인 학습률 스케줄을 사용합니다. 가중치 감쇠는 0.0005이며 SGD 모멘텀은 0.9 입니다. 배치 크기는 기본적으로 8개의 GPU 장치에 대해 128입니다. 다른 배치 크기에서도 단일 GPU 훈련이 잘 작동합니다. 입력 크기는 448에서 832까지 32단위로 균등하게 추출됩니다. 이 보고서에서 FPS와 지연 시간은 모두 단일 Tesla V100에서 FP16 정밀도로 측정되었습니다.
YOLOv3 baseline
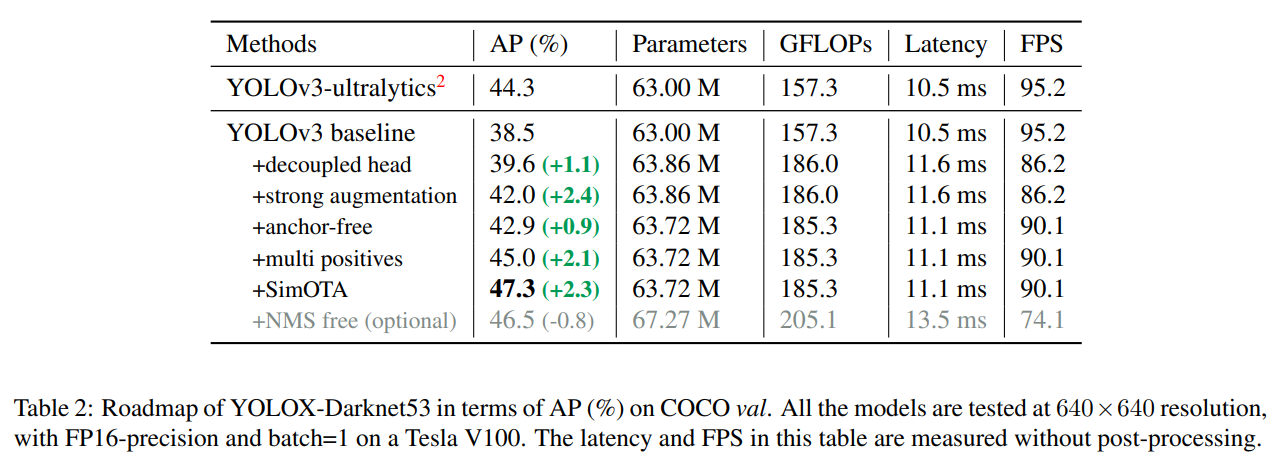
우리의 기본 모델은 DarkNet53 백본과 SPP 레이어를 채택하며, 일부 논문에서는 이를 YOLOv3-SPP라고 부릅니다 [1, 7]. 우리는 원래 구현 [25]와 비교하여 EMA 가중치 업데이트, 코사인 학습률 스케줄, IoU 손실 및 IoU-인식 분기를 추가하여 일부 훈련 전략을 약간 변경했습니다. 우리는 cls 및 obj 분기의 훈련을 위해 BCE 손실을, reg 분기의 훈련을 위해 IoU 손실을 사용합니다. 이러한 일반적인 훈련 트릭은 YOLOX의 주요 개선과 직교하므로 이를 기본 설정에 포함했습니다. 또한 우리는 데이터 증강을 위해 RandomHorizontalFlip, ColorJitter 및 멀티 스케일만 수행하고, RandomResizedCrop 전략을 버렸습니다. 그 이유는 RandomResizedCrop이 계획된 모자이크 증강과 어느 정도 중복된다는 것을 발견했기 때문입니다. 이러한 향상으로 인해, 우리의 기본 모델은 COCO val에서 38.5%의 AP를 달성했습니다. 이는 표 2에 나타나 있습니다.
Decoupled head
객체 탐지에서 분류와 회귀 작업 간의 충돌은 잘 알려진 문제입니다 [27, 34]. 따라서 분류와 위치 확인을 위한 분리형 헤드는 대부분의 1단계 및 2단계 탐지기에서 널리 사용됩니다 [16, 29, 35, 34]. 하지만 YOLO 시리즈의 백본과 피처 피라미드(FPN [13], PAN [20] 등)가 계속해서 발전하면서, 그들의 탐지 헤드는 여전히 그림 2에서와 같이 결합된 상태로 남아 있습니다.
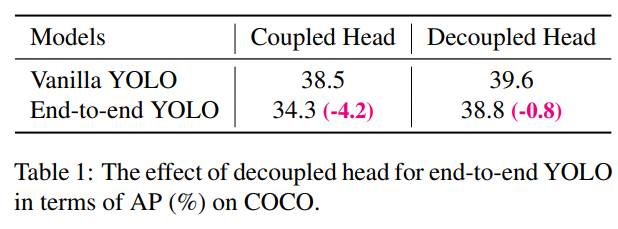
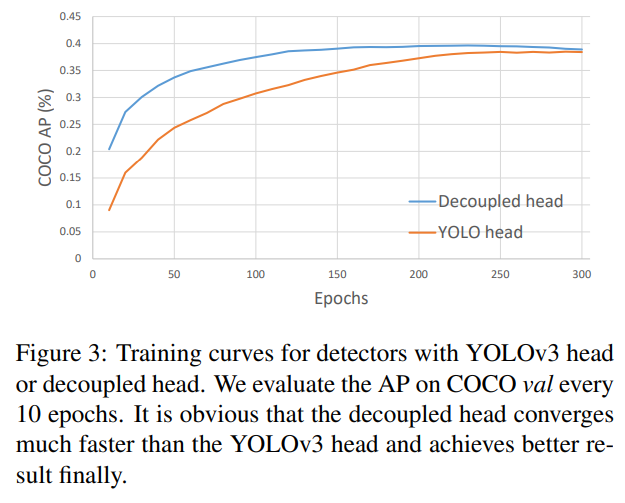
우리의 두 가지 분석 실험은 결합된 탐지 헤드가 성능에 해를 끼칠 수 있음을 보여줍니다. 1) YOLO의 헤드를 분리형 헤드로 교체하면 그림 3에서 볼 수 있듯이 수렴 속도가 크게 향상됩니다. 2) 분리형 헤드는 YOLO의 end-to-end 버전에 필수적입니다(다음에 설명될 예정). 표 1에서 알 수 있듯이, 결합된 헤드를 사용하면 end-to-end 속성이 4.2% AP 감소하는 반면, 분리형 헤드를 사용하면 이 감소가 0.8% AP로 줄어듭니다. 따라서 우리는 그림 2에서와 같이 YOLO 탐지 헤드를 라이트 분리형 헤드로 교체합니다. 구체적으로, 이는 채널 차원을 줄이기 위한 1 × 1 컨볼루션 레이어와 각각 두 개의 3 × 3 컨볼루션 레이어를 가진 두 개의 병렬 분기로 구성됩니다. 우리는 V100에서 batch=1로 추론 시간을 보고하며, 표 2에서 라이트 분리형 헤드는 1.1ms의 추가 지연 시간(11.6ms 대 10.5ms)을 발생시킵니다.
Strong data augmentation
우리는 YOLOX의 성능을 향상시키기 위해 Mosaic과 MixUp을 데이터 증강 전략에 추가했습니다. Mosaic은 ultralytics-YOLOv3에서 제안된 효율적인 증강 전략으로, 이후 YOLOv4 [1], YOLOv5 [7], 그리고 다른 탐지기 [3]에서도 널리 사용되었습니다. MixUp [10]은 원래 이미지 분류 작업을 위해 설계되었지만 BoF [38]에서 객체 탐지 훈련용으로 수정되었습니다. 우리는 모델에서 MixUp과 Mosaic 구현을 채택하고 마지막 15 에포크 동안 이를 종료하여, 표 2에서 42.0% AP를 달성했습니다. 강력한 데이터 증강을 사용한 후, 우리는 ImageNet 사전 학습이 더 이상 유익하지 않다는 것을 발견했고, 따라서 모든 후속 모델을 처음부터 훈련했습니다.
Anchor-free
YOLOv4 [1]와 YOLOv5 [7]는 모두 YOLOv3 [25]의 원래 앵커 기반 파이프라인을 따릅니다. 하지만 앵커 메커니즘에는 여러 가지 알려진 문제가 있습니다. 첫째, 최적의 탐지 성능을 달성하려면 훈련 전에 클러스터링 분석을 수행하여 최적의 앵커 집합을 결정해야 합니다. 이러한 클러스터된 앵커는 도메인 특화되어 있고 일반화되지 않습니다. 둘째, 앵커 메커니즘은 탐지 헤드의 복잡성을 증가시키고, 각 이미지에 대한 예측 수를 증가시킵니다. 일부 엣지 AI 시스템에서는 장치 간에 예측량을 이동시키는 것(e.g., NPU에서 CPU로)이 잠재적인 지연 병목 현상을 일으킬 수 있습니다.
앵커 프리 탐지기 [29, 40, 14]는 지난 2년간 빠르게 발전했습니다. 이러한 연구들은 앵커 프리 탐지기의 성능이 앵커 기반 탐지기와 동등할 수 있음을 보여주었습니다. 앵커 프리 메커니즘은 좋은 성능을 위해 필요한 설계 매개변수의 수를 크게 줄이며, 이는 대부분의 경우 히스테릭 튜닝과 여러 트릭(e.g., 앵커 클러스터링 [24], 그리드 센서티브 [11])을 요구합니다. 이를 통해 탐지기, 특히 훈련 및 디코딩 단계가 상당히 간단해졌습니다 [29].
YOLO를 앵커 프리 방식으로 전환하는 것은 매우 간단합니다. 우리는 각 위치에 대한 예측을 3에서 1로 줄이고, 그리드의 좌상단 모서리를 기준으로 한 두 개의 오프셋과 예측된 상자의 높이와 너비라는 네 가지 값을 직접 예측하게 합니다. 우리는 각 객체의 중심 위치를 긍정 샘플로 할당하고, [29]에서 수행한 것처럼 각 객체에 대한 FPN 레벨을 지정하기 위해 스케일 범위를 미리 정의합니다. 이러한 수정은 탐지기의 파라미터와 GFLOPs를 줄이고 속도를 높이지만, 더 나은 성능을 얻습니다—표 2에서 42.9% AP를 달성했습니다.
Multi positives
YOLOv3의 할당 규칙을 일관되게 유지하기 위해, 위의 앵커 프리 버전은 각 객체에 대해 단 하나의 긍정 샘플(중심 위치)만 선택하고 다른 고품질 예측을 무시합니다. 하지만 이러한 고품질 예측을 최적화하면 긍정/부정 샘플링의 불균형을 완화할 수 있는 유익한 그래디언트를 제공할 수 있습니다. 우리는 단순히 중심 3×3 영역을 긍정 샘플로 할당하며, 이를 FCOS [29]에서 “중심 샘플링”이라고 부릅니다. 탐지기의 성능은 표 2에서 45.0% AP로 개선되었으며, 이는 현재 ultralytics-YOLOv3 (44.3% AP)의 최선 실적을 이미 능가했습니다.
SimOTA
고급 라벨 할당은 최근 몇 년간 객체 탐지에서 중요한 발전 중 하나입니다. 우리의 연구 OTA [4]를 기반으로, 고급 라벨 할당에 대한 네 가지 핵심 통찰을 도출했습니다: 1). 손실/품질 인식, 2). 중심 우선순위, 3). 각 실제 값에 대해 동적으로 할당되는 긍정 앵커 수 (동적 top-k로 약칭), 4). 전체적인 관점. OTA는 위 네 가지 규칙을 모두 충족하며, 따라서 우리는 이를 후보 라벨 할당 전략으로 선택했습니다.
구체적으로, OTA [4]는 전역적 관점에서 라벨 할당을 분석하고, 할당 절차를 최적 수송(OT) 문제로 공식화하여 현재 할당 전략 중 최고 성능(SOTA)을 달성했습니다 [12, 41, 36, 22, 37]. 그러나 실무에서 우리는 Sinkhorn-Knopp 알고리즘을 통한 OT 문제 해결이 훈련 시간에 25% 추가를 가져와, 300 에포크 훈련에 상당히 비싸다는 것을 발견했습니다. 따라서 우리는 이를 동적 top-k 전략으로 단순화하여 SimOTA라고 명명하여 근사 해를 얻었습니다.
여기서 SimOTA를 간단히 소개합니다. SimOTA는 먼저 각 예측-실제 값 쌍에 대한 비용 [4, 5, 12, 2] 또는 품질 [33]에 의해 나타내어지는 쌍별 매칭 정도를 계산합니다. 예를 들어, SimOTA에서 실제 값 $g_i$ 와 예측 $p_j$ 간의 비용은 다음과 같이 계산됩니다:
여기서 $λ$ 는 균형 계수입니다. $L_{ij}^{cls}$ 와 $L_{ij}^{reg}$ 는 실제 값 $g_i$ 와 예측 $p_j$ 간의 분류 손실과 회귀 손실입니다. 그런 다음, 실제 값 $g_i$ 에 대해, 우리는 고정된 중심 영역 내에서 비용이 가장 적은 상위 $k$ 예측을 긍정 샘플로 선택합니다. 마지막으로, 그 긍정 예측의 해당 그리드를 긍정으로 할당하고, 나머지 그리드는 부정으로 처리합니다. $k$ 값은 각 실제 값에 따라 달라질 수 있다는 점을 유의하십시오. 자세한 내용은 OTA [4]의 동적 $k$ 추정 전략을 참조하십시오.
SimOTA는 훈련 시간을 줄일 뿐만 아니라 Sinkhorn-Knopp 알고리즘에서 추가적인 솔버 하이퍼파라미터도 피할 수 있습니다. 표 2에서 보듯이, SimOTA는 탐지기의 AP를 45.0%에서 47.3%로 향상시켜 SOTA ultralytics-YOLOv3보다 3.0% AP 더 높은 성능을 보이며, 고급 할당 전략의 강력함을 보여줍니다.
End-to-end YOLO
우리는 [39]를 따라 두 개의 추가 컨볼루션 레이어, 1:1 라벨 할당, 그리고 그래디언트 중단을 추가했습니다. 이를 통해 탐지기가 end-to-end 방식으로 작동할 수 있지만, 표 2에서 보듯이 성능과 추론 속도가 약간 감소합니다. 따라서 우리는 이를 최종 모델에는 포함되지 않은 선택적 모듈로 남겨둡니다.
2.2. Other Backbones
DarkNet53 외에도, 우리는 다른 크기의 백본을 사용하여 YOLOX를 테스트했으며, YOLOX는 모든 대응 모델에 대해 일관된 성능 향상을 달성했습니다.
Modified CSPNet in YOLOv5
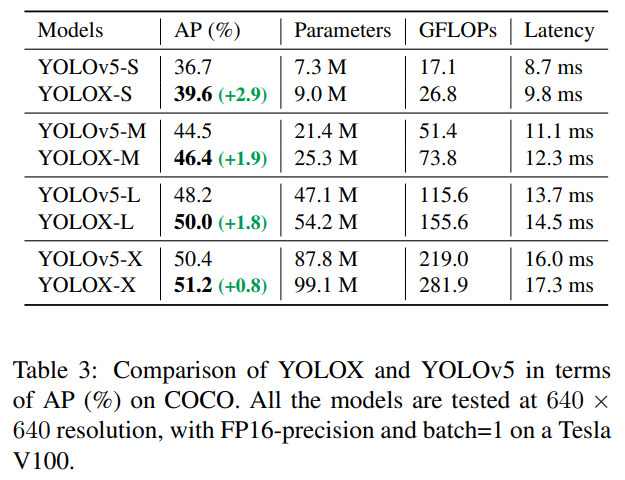
공정한 비교를 위해, 우리는 수정된 CSPNet [31], SiLU 활성화 및 PAN [19] 헤드를 포함한 YOLOv5의 백본을 채택했습니다. 우리는 또한 YOLOX-S, YOLOX-M, YOLOX-L, YOLOX-X 모델을 생산하기 위해 YOLOv5의 스케일링 규칙을 따릅니다. 표 3에서 YOLOv5와 비교했을 때, 우리의 모델은 AP에서 약 3.0%에서 1.0% 정도의 일관된 성능 향상을 보이며, 끝 부분의 시간이 증가했습니다. (이는 분리형 헤드로 인해 발생).
Tiny and Nano detectors
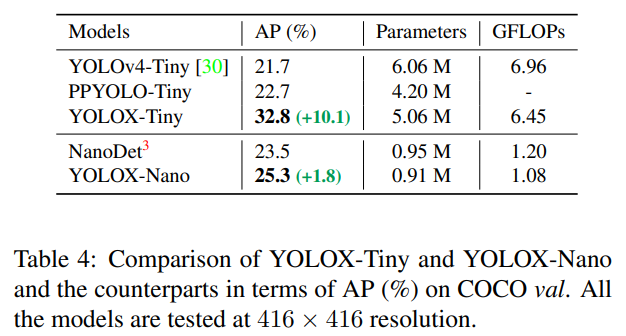
우리는 YOLOX-Tiny 모델을 더 축소하여 YOLOv4-Tiny [30]와 비교했습니다. 모바일 장치의 경우, 우리는 깊이별 컨볼루션을 채택하여 YOLOX-Nano 모델을 구성했으며, 이 모델은 단 0.91M 파라미터와 1.08G FLOPs만을 사용합니다. 표 4에서 볼 수 있듯이, YOLOX는 더 작은 모델 크기에도 불구하고 대응 모델보다 우수한 성능을 발휘합니다.
Model size and data augmentation
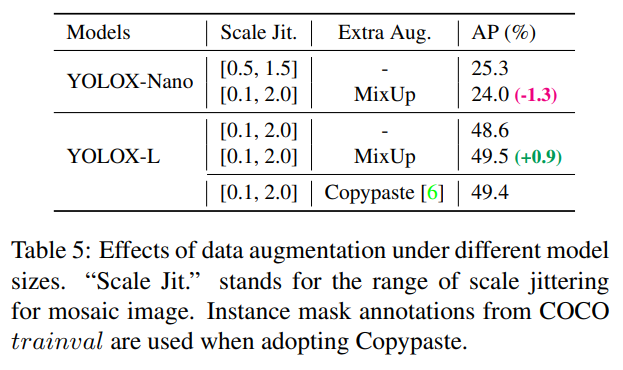
우리의 실험에서, 모든 모델은 2.1에서 설명한 대로 거의 동일한 학습 일정과 최적화 파라미터를 유지했습니다. 하지만 우리는 적합한 증강 전략이 모델 크기에 따라 다르다는 것을 발견했습니다. 표 5에서 알 수 있듯이, YOLOX-L에 MixUp을 적용하면 AP가 0.9% 향상되지만, YOLOX-Nano와 같은 작은 모델에서는 증강을 약화시키는 것이 더 좋습니다. 구체적으로, 우리는 MixUp 증강을 제거하고 작은 모델을 훈련할 때 모자이크를 약화시키며 (스케일 범위를 [0.1, 2.0]에서 [0.5, 1.5]로 줄임), 즉 YOLOX-S, YOLOX-Tiny, YOLOX-Nano에서 이와 같은 수정은 YOLOX-Nano의 AP를 24.0%에서 25.3%로 향상시킵니다.
대형 모델의 경우, 더 강력한 증강이 더 유용하다는 것도 발견했습니다. 사실, 우리의 MixUp 구현은 [38]에서의 원본 버전보다 일부 더 무겁습니다. Copypaste [6]에서 영감을 받아, 우리는 두 이미지를 혼합하기 전에 무작위로 샘플링된 스케일 팩터로 지터링했습니다. 스케일 지터링이 있는 MixUp의 성능을 이해하기 위해, 우리는 YOLOX-L에서 Copypaste와 비교했습니다. Copypaste는 추가 인스턴스 마스크 주석을 필요로 하지만 MixUp은 그렇지 않습니다. 그러나 표 5에서 알 수 있듯이, 이 두 방법은 경쟁력 있는 성능을 달성했으며, 인스턴스 마스크 주석이 없는 경우에는 스케일 지터링이 있는 MixUp이 Copypaste의 적절한 대체가 될 수 있음을 나타냅니다.
3. Comparison with the SOTA
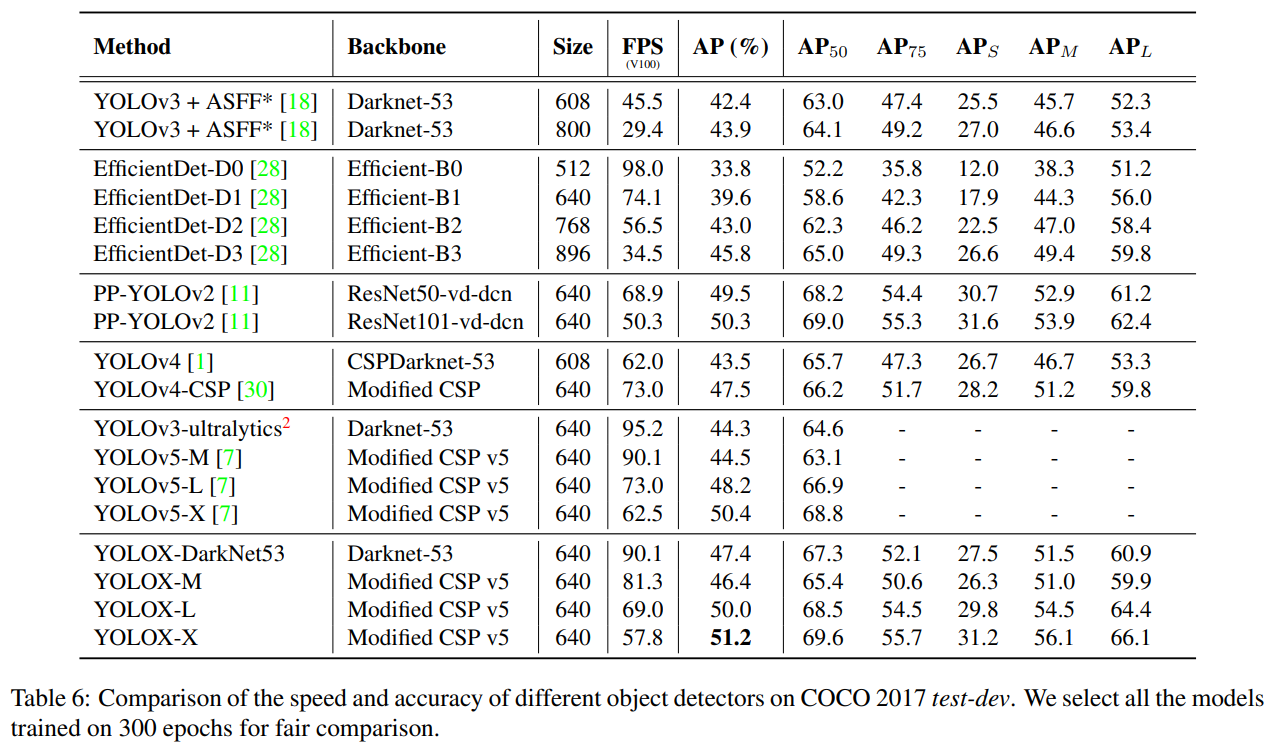
표 6에서와 같이 SOTA 비교 표를 보여주는 전통이 있습니다. 그러나 이 표에서 모델들의 추론 속도는 종종 제어되지 않는다는 점을 유념해야 하며, 속도는 소프트웨어와 하드웨어에 따라 달라집니다. 따라서 우리는 그림 1에서 모든 YOLO 시리즈에 대해 동일한 하드웨어와 코드 베이스를 사용하여, 어느 정도 제어된 속도/정확도 곡선을 그렸습니다.
우리는 Scale-YOLOv4 [30] 및 YOLOv5-P6 [7]와 같은 더 큰 모델 크기를 가진 고성능 YOLO 시리즈가 있음을 확인했습니다. 또한 현재 Transformer 기반 탐지기 [21]는 정확도 SOTA를 약 60 AP로 밀어 올렸습니다. 시간과 자원 제한으로 인해 우리는 이 보고서에서 그러한 중요한 기능들을 탐구하지 않았지만, 이들은 이미 우리의 범위 내에 있습니다.
4. 1st Place on Streaming Perception Challenge (WAD at CVPR 2021)
WAD 2021의 스트리밍 인식 챌린지는 최근 제안된 지표인 스트리밍 정확도 [15]를 통해 정확도와 지연 시간을 공동 평가합니다. 이 지표의 핵심 통찰은 매 시간마다 전체 인식 스택의 출력을 공동으로 평가하여, 계산이 이루어지는 동안 무시해야 할 스트리밍 데이터의 양을 고려하도록 스택을 강제하는 것입니다 [15]. 우리는 30 FPS 데이터 스트림에서 이 지표의 최적 절충점을 추론 시간이 33ms 이하인 강력한 모델로 찾았습니다. 그래서 우리는 YOLOX-L 모델을 TensorRT로 최종 모델을 만들어 이 챌린지에서 1위를 차지했습니다. 더 자세한 내용은 챌린지 웹사이트 [5]를 참조하십시오.
5. Conclusion
이 보고서에서 우리는 YOLO 시리즈에 몇 가지 경험적 업데이트를 제시했으며, 이는 YOLOX라는 고성능 앵커 프리 탐지기를 형성했습니다. 분리형 헤드, 앵커 프리 및 고급 라벨 할당 전략과 같은 최신 고급 탐지 기술을 갖춘 YOLOX는 모든 모델 크기에서 다른 대응 모델보다 속도와 정확도 사이의 더 나은 절충점을 달성했습니다. 산업에서 여전히 가장 널리 사용되는 탐지기 중 하나인 YOLOv3의 아키텍처를 47.3% AP로 향상시켜 현재의 최고 성과보다 3.0% AP를 초과한 것은 주목할 만한 일입니다. 이 보고서가 개발자와 연구자들이 실제 장면에서 더 나은 경험을 얻는 데 도움이 되기를 바랍니다.
Acknowledge
이 연구는 중국 국가 핵심 R&D 프로그램(No. 2017YFA0700800)의 지원을 받았습니다. 또한 중국 박사후 과학 재단(2021M690375)과 베이징 박사후 연구 재단의 자금 지원을 받았습니다.
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun YOLOX: Exceeding YOLO Series in 2021

댓글남기기