

개요
YOLOv11 리포트의 얕은 리뷰. 2024년 10월 23일에 아카이브에 업로드 되었다.
YOLO Vision 2024 컨퍼런스에서 해당논문은 발표되었으며, 최신의 고급 특징 추출 기법을 통해 파라미터 수를 더 적게 유지하면서 정확성을 향상 시킨다. Ultralytics의 기존 YOLOv8과 마찬가지로 범용 task 처리를 위해 개발되어 객체감지 외에도, Instance segmentation, Pose estimation, direction detecion 등 다양한 CV 작업을 지원한다.
YOLO의 Evolutuion
YOLO(v1)는 2015년에 처음 나왔으며 2024년에 나온 YOLOv10 은 NMS-Free 전략을 취하기까지 실시간 객체 탐지의 발전을 이끌어왔다.
YOLOv11은 특징 추출, 연산 효율성 및 다중 작업 기능에서 향상을 이룩하였다.
YOLOv11 이란?
- Ultralytics 리포지토리를 참고하여 디테일한 스크립트들을 돌려볼 수 있다.
- 객체 감지 뿐 아니라 자세 추정과 인스턴스 세그멘테이션에 주목할 만하다.
- 다양한 산업의 문제를 해결하는 것을 염두에 두어 성능과 실용(시간적 효용)성 간의 균형을 맞추려고 하였다.
개선점
YOLOv11의 아키텍쳐 개선점을 백본(Backbone), 넥(Neck), 헤드(Head)의 관점에서 살펴본다.
백본은 이전 버전(YOLOv10)과 유사한 구조를 가지지만 해당 백본 상에서 사용된 C2f 블록을 C3k2 블록으로 대체한다. 큰 합성곱 대신의 작은 합성곱 여러개를 사용함으로써 성능을 유지하면서 더 빠른 처리를 가능하게 한다. 또한 SPPF 후에 C2PSA(Cross Stage Patial with Spatial Attention)
넥 구조에선 헤드와 동일하게 C2f 블록을 C3k2 블록으로 대체한다. 연산 효율성이 증가되어 더 빠른 연산이 가능해져 피쳐맵들의 집계 과정의 성능을 향상 시킨다. 또한 C2PSA 모듈을 통해 이미지 내에서 중요한 영역에 대해 집중할 수 있게되어, 더 작거나 부분적으로 가려진 객체에 대하여 더 정확한 객체 감지를 가능하게 한다.
최종적인 출력을 만들어내는 헤드 부분에서는 여러개의 C3k2 블록을 사용하여 다양한 깊이에서 다중 스케일 처리를 하며 c3k 매개변수 값에 따라 유연한 특징 추출 분기를 보여준다. 이러한 C3k2 블록은 CBS 연산을 포함하는데 이는 컨볼루션 뒤에 배치정규화 및 실루(SiLU)활성화를 의미한다.
다양한 응용 분야
YOLOv11은 객체감지, 인스턴스 세그멘테이션, 자세 추정, 방향성 객체감지, 이미지 분류에 이르기까지 다양한 분야에 대해서 활용 가능하다.
결론
해당 리포트는 명확한 의도성 및 방향성을 가지고 작성된 리포트이므로 객관적인 수치 및 맥락의 차원에서 이해를 하면 좋을 것 같다. 하지만 YOLO 라는 궤가 걸어온 길을 생각하면 엄청난 진보와 발전을 이룩한 것도 사실이다. 본인은 YOLOv11 소스코드가 울트라리틱스 리포지토리에 통합되어 사용성 면에서 전 버전인 YOLOv8과 동일한 편의성을 제공해주어 더욱이 여러 테스크에 자연스럽게 녹아들 수 있다는 점을 최대한의 강점으로 보고 있다.
번역
Abstract
본 연구는 YOLO(You Only Look Once) 계열의 객체 탐지 모델의 최신 버전인 YOLOv11의 구조적 분석을 제시합니다. 우리는 모델의 성능 향상에 기여하는 C3k2 (커널 크기 2를 가진 Cross Stage Partial Block), SPPF (Spatial Pyramid Pooling - Fast), C2PSA (Convolutional block with Parallel Spatial Attention)와 같은 구조적 혁신을 검토합니다. 이들은 향상된 특징 추출 등 여러 측면에서 모델 성능을 향상시키는 데 기여합니다. 본 논문은 YOLOv11이 객체 탐지, 인스턴스 분할, 자세 추정, 방향성 객체 탐지(OBB) 등 다양한 컴퓨터 비전 작업에서 확장된 기능을 제공하는 것을 탐구합니다. 우리는 파라미터 수와 정확도 간의 균형에 중점을 두고 이전 버전과 비교하여 평균 정밀도(mAP) 및 계산 효율성 측면에서 모델의 성능 향상을 검토합니다. 또한, 본 연구는 엣지 장치에서 고성능 컴퓨팅 환경에 이르기까지 다양한 응용 요구를 충족하는 나노에서 초대형까지의 다양한 모델 크기에 걸친 YOLOv11의 다재다능함을 논의합니다. 우리의 연구는 YOLOv11이 객체 탐지의 광범위한 분야에서 차지하는 위치와 실시간 컴퓨터 비전 응용 프로그램에 미치는 잠재적 영향을 제공합니다.
키워드: 자동화, 컴퓨터 비전, YOLO, YOLOv11, 객체 감지, 실시간 이미지 처리
1 Introduction
컴퓨터 비전은 빠르게 발전하는 분야로, 기계가 시각 데이터를 해석하고 이해할 수 있도록 합니다 [1]. 이 분야의 핵심 요소는 객체 탐지[2]로, 이는 이미지나 비디오 스트림 내에서 객체를 정확하게 식별하고 위치를 지정하는 것을 포함합니다[3]. 최근 몇 년 동안 이 문제를 해결하기 위한 알고리즘 접근 방식에서 눈에 띄는 진전을 이루었습니다 [4].
객체 탐지에서 중요한 돌파구는 2015년 Redmon 등[5]이 제안한 You Only Look Once (YOLO) 알고리즘의 도입으로 나타났습니다. 이 혁신적인 접근 방식은 이름이 암시하듯 단일 패스로 전체 이미지를 처리하여 객체와 그 위치를 탐지합니다. YOLO의 방법론은 객체 탐지를 회귀 문제로 구성함으로써 전통적인 2단계 탐지 과정과 차별화됩니다 [5]. YOLO는 전체 이미지에 대해 경계 상자와 클래스 확률을 동시에 예측하는 단일 합성곱 신경망을 사용하여, 더 복잡한 전통적인 방법과 비교했을 때 탐지 파이프라인을 단순화합니다 [6].
YOLOv11은 YOLO 시리즈의 최신 버전으로, YOLOv1이 구축한 기반 위에 만들어졌습니다. YOLO Vision 2024 (YV24) 컨퍼런스에서 공개된 YOLOv11은 실시간 객체 탐지 기술에서 중요한 도약을 의미합니다. 이 새로운 버전은 구조와 훈련 방법 모두에서 상당한 향상을 도입하여 정확성, 속도, 효율성의 한계를 확장합니다.
YOLOv11의 혁신적인 설계는 고급 특징 추출 기법을 통합하여 적은 파라미터 수를 유지하면서도 더 세밀한 세부 사항을 포착할 수 있게 합니다. 이는 객체 탐지에서 분류에 이르기까지 다양한 컴퓨터 비전(CV) 작업에서 정확성을 향상시킵니다. 또한, YOLOv11은 처리 속도에서 놀라운 성과를 달성하여 실시간 성능 능력을 크게 향상시킵니다.
다음 섹션에서는 YOLOv11의 구조를 포괄적으로 분석하며, 주요 구성 요소와 혁신을 탐구할 것입니다. 우리는 YOLO 모델의 발전 과정을 검토하여 YOLOv11의 개발에 이르는 과정을 살펴볼 것입니다. 본 연구는 객체 탐지, 인스턴스 분할, 자세 추정, 방향성 객체 탐지 등 다양한 CV 작업에서 모델의 확장된 기능을 깊이 있게 탐구할 것입니다. 우리는 다양한 모델 크기에서의 다용성에 초점을 맞추어 이전 버전과 비교한 YOLOv11의 정확도와 계산 효율성 측면에서의 성능 향상을 검토할 것입니다. 마지막으로 우리는 실시간 CV 응용 프로그램에 대한 YOLOv11의 잠재적 영향과 객체 탐지 기술의 광범위한 분야에서의 위치를 논의할 것입니다.
2 Evolution of YOLO models
표 1은 YOLO 모델의 초기부터 최신 버전까지의 발전을 보여줍니다. 각 버전은 객체 탐지 기능, 계산 효율성 및 다양한 컴퓨터 비전 작업을 처리하는 다재다능함에서 중요한 개선을 가져왔습니다.
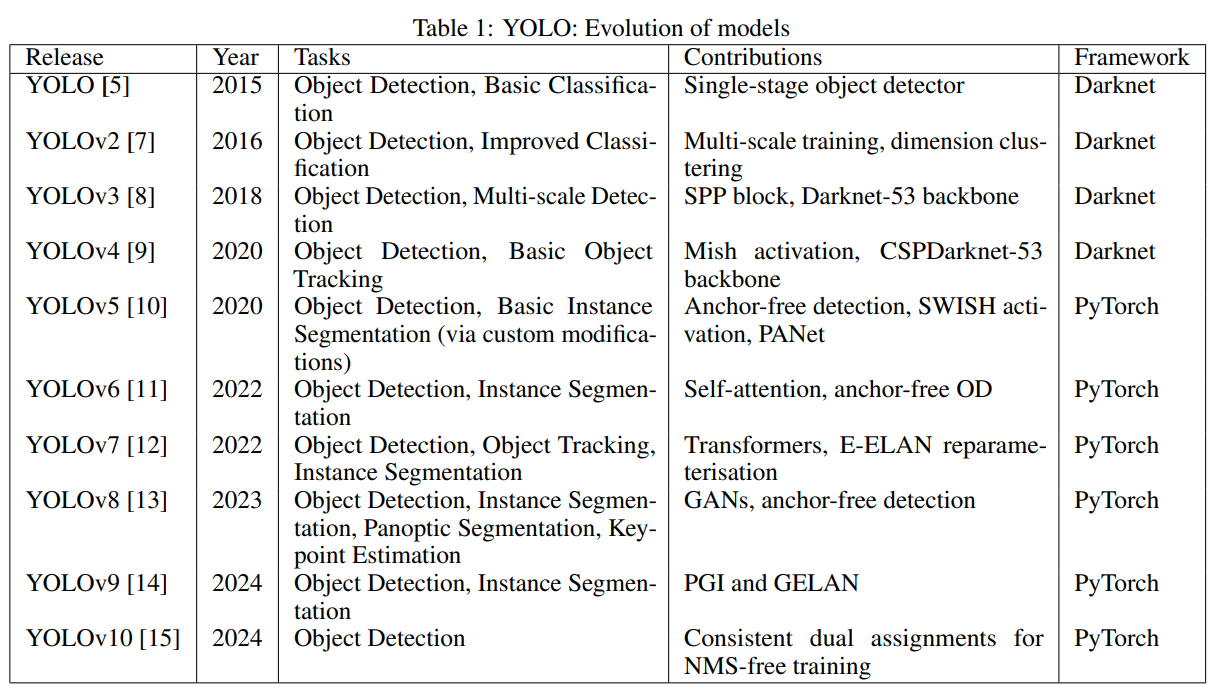
이 발전은 객체 탐지 기술의 빠른 진보를 보여주며, 각 버전은 새로운 기능을 도입하고 지원되는 작업의 범위를 확장하고 있습니다. 원래 YOLO의 획기적인 단일 단계 탐지에서 YOLOv10의 NMS 없는 훈련에 이르기까지 이 시리즈는 실시간 객체 탐지의 한계를 꾸준히 확장해왔습니다.
최신 버전인 YOLOv11은 특징 추출, 효율성 및 다중 작업 기능에서 추가적인 향상을 통해 이 유산을 이어가고 있습니다. 이후 분석에서는 YOLOv11의 구조적 혁신, 특히 개선된 백본과 넥 구조를 포함하여 객체 탐지, 인스턴스 분할, 자세 추정 등 다양한 컴퓨터 비전 작업에서의 성능을 심도 있게 탐구할 것입니다.
3 What is YOLOv11?
YOLO 알고리즘의 발전은 YOLOv11[16]의 도입으로 새로운 정점을 맞이하며, 이는 실시간 객체 탐지 기술에서 중요한 진보를 의미합니다. 이 최신 버전은 이전 버전의 강점을 기반으로 하여 다양한 CV 응용 분야에서 활용성을 확장하는 새로운 기능을 도입했습니다.
YOLOv11은 향상된 적응력을 통해 기존 객체 탐지를 넘어선 확장된 CV 작업 범위를 지원함으로써 차별화됩니다. 그중에서도 자세 추정과 인스턴스 분할이 주목할 만하며, 이는 모델의 다양한 분야에서의 적용 가능성을 넓혀줍니다. YOLOv11의 설계는 정확성과 효율성을 높여 다양한 산업의 특정 문제를 해결하기 위해 성능과 실용성 간의 균형을 맞추는 데 중점을 둡니다.
이 최신 모델은 실시간 객체 탐지 기술의 지속적인 발전을 보여주며, CV 응용 분야에서 가능성의 한계를 확장합니다. 그 다재다능함과 성능 향상은 YOLOv11을 이 분야에서 중요한 진전으로 자리매김하게 하여 다양한 분야에서 실제 적용을 위한 새로운 길을 열어줄 가능성이 있습니다.
4 Architectural footprint of Yolov11
YOLO 프레임워크는 경계 상자 회귀와 객체 분류 작업을 동시에 처리하는 통합된 신경망 아키텍처를 도입하여 객체 탐지에 혁신을 가져왔습니다 [17]. 이 통합 접근 방식은 완전 미분 가능한 설계를 통해 종단 간 훈련 가능성을 제공하며, 기존의 2단계 탐지 방식과는 큰 차이를 보입니다.
YOLO 아키텍처의 핵심은 세 가지 기본 구성 요소로 이루어져 있습니다. 첫 번째로 백본(backbone)은 주요 특징 추출기로서, 합성곱 신경망을 이용해 원시 이미지 데이터를 다중 스케일 특징 맵으로 변환합니다. 두 번째로 넥(neck) 구성 요소는 중간 처리 단계로서, 다양한 스케일에서 특징 표현을 집계하고 향상시키기 위해 특수화된 층을 사용합니다. 세 번째로 헤드(head) 구성 요소는 예측 메커니즘으로 작용하여 정제된 특징 맵을 기반으로 객체 위치 지정 및 분류에 대한 최종 출력을 생성합니다.
이 확립된 아키텍처를 기반으로 YOLOv11은 YOLOv8이 마련한 기초를 확장하고 향상시키며, 그림 1에 표시된 것처럼 우수한 탐지 성능을 달성하기 위해 구조적 혁신과 파라미터 최적화를 도입했습니다. 다음 섹션에서는 YOLOv11에 구현된 주요 구조적 수정 사항을 자세히 설명합니다.
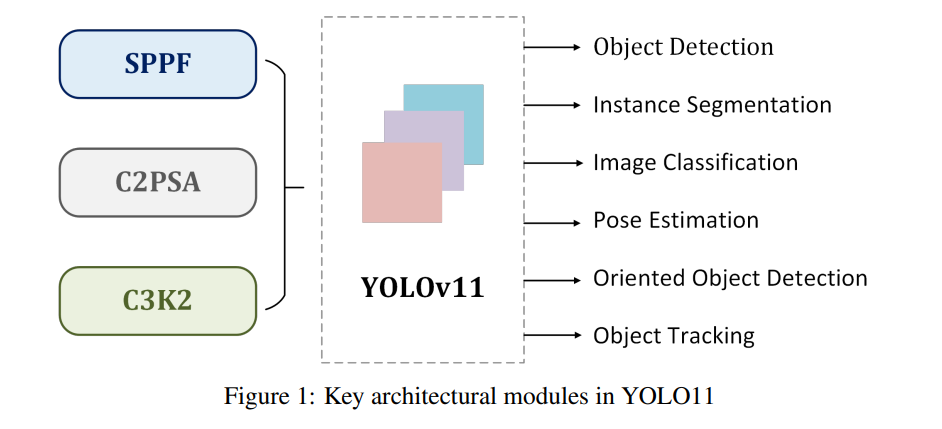
4.1 Backbone
백본은 YOLO 아키텍처의 중요한 구성 요소로, 입력 이미지에서 여러 스케일로 특징을 추출하는 역할을 담당합니다. 이 과정은 다양한 해상도의 특징 맵을 생성하기 위해 합성곱 층과 특수 블록을 쌓는 작업을 포함합니다.
4.1.1 Convolutional Layers
YOLOv11은 초기 합성곱 층을 사용하여 이미지를 다운샘플링하는 이전 버전과 유사한 구조를 유지합니다. 이러한 층은 특징 추출 과정의 기초를 형성하며, 공간 차원을 점진적으로 줄이면서 채널 수를 늘립니다. YOLOv11에서 중요한 개선 사항은 이전 버전에서 사용된 C2f 블록을 대체하는 C3k2 블록의 도입입니다 [18]. C3k2 블록은 교차 단계 부분(CSP) 병목의 더 효율적인 구현입니다. 이는 YOLOv8[13]에서처럼 큰 합성곱 하나 대신 작은 합성곱 두 개를 사용합니다. C3k2의 “k2”는 작은 커널 크기를 의미하며, 이는 성능을 유지하면서도 더 빠른 처리를 가능하게 합니다.
4.1.2 SPPF and C2PSA
YOLO11은 이전 버전의 공간 피라미드 풀링 - 빠른(SPPF) 블록을 유지하면서 그 후에 새로운 공간 주의가 적용된 교차 단계 부분(C2PSA) 블록을 도입합니다 [18]. C2PSA 블록은 특징 맵에서 공간 주의를 향상시키는 주목할 만한 추가 요소입니다. 이 공간 주의 메커니즘은 모델이 이미지 내에서 중요한 영역에 더 효과적으로 집중할 수 있도록 합니다. C2PSA 블록은 특징을 공간적으로 풀링하여 YOLO11이 관심 있는 특정 영역에 집중할 수 있게 하여 다양한 크기와 위치의 객체에 대한 탐지 정확성을 잠재적으로 향상시킵니다.
4.2 Neck
넥(neck)은 다양한 스케일의 특징을 결합하여 예측을 위해 헤드로 전달합니다. 과정은 일반적으로 서로 다른 레벨의 특징 맵을 업샘플링하고 연결하여 모델이 다중 스케일 정보를 효과적으로 포착할 수 있도록 합니다.
4.2.1 C3k2 Block
YOLOv11은 넥(neck)에서 C2f 블록을 C3k2 블록으로 대체하여 중요한 변화를 도입합니다. C3k2 블록은 더 빠르고 효율적으로 설계되어 특징 집계 과정의 전체 성능을 향상시킵니다. 업샘플링과 연결 후, YOLOv11의 넥에는 이 향상된 블록이 포함되어 속도와 성능이 개선됩니다 [18].
4.2.2 Attention Mechanism
YOLOv11에 주목할 만한 추가 요소는 C2PSA 모듈을 통한 공간 주의(spatial attention) 증가입니다. 이 주의 메커니즘은 모델이 이미지 내의 중요한 영역에 집중할 수 있도록 하여, 특히 더 작거나 부분적으로 가려진 객체에 대해 더 정확한 탐지가 가능하게 합니다. C2PSA의 도입은 이 특정 주의 메커니즘이 없는 이전 버전 YOLOv8과 YOLOv11을 구별시킵니다 [18].
4.3 Head
YOLOv11의 헤드(head)는 객체 탐지와 분류 측면에서 최종 예측을 생성하는 역할을 합니다. 넥(neck)에서 전달된 특징 맵을 처리하여, 이미지 내 객체에 대한 경계 상자와 클래스 레이블을 최종적으로 출력합니다.
4.3.1 C3k2 Block
헤드 섹션에서 YOLOv11은 여러 개의 C3k2 블록을 사용하여 특징 맵을 효율적으로 처리하고 정제합니다. C3k2 블록은 헤드 내 여러 경로에 배치되어, 다양한 깊이에서 다중 스케일 특징을 처리하는 역할을 합니다. C3k2 블록은 c3k 매개변수 값에 따라 유연성을 보여줍니다:
- c3k = False일 때: C3k2 모듈은 표준 병목 구조를 사용하여 C2f 블록과 유사하게 동작합니다.
- c3k = True일 때: 병목 구조는 C3 모듈로 대체되어, 더 깊고 복잡한 특징 추출이 가능합니다.
C3k2 블록의 주요 특성:
- 더 빠른 처리: 작은 합성곱 두 개를 사용함으로써 큰 합성곱 하나에 비해 계산 오버헤드를 줄여 더 빠른 특징 추출이 가능합니다.
- 파라미터 효율성: C3k2는 CSP 병목의 더 압축된 버전으로, 학습 가능한 파라미터 수 측면에서 아키텍처가 더 효율적입니다.
또 다른 주목할 만한 추가 요소는 커널 크기를 사용자 정의할 수 있어 유연성이 향상된 C3k 블록입니다. C3k의 적응성은 이미지에서 더 세부적인 특징을 추출하는 데 특히 유용하며, 탐지 정확도 향상에 기여합니다.
4.3.2 CBS Blocks
YOLOv11의 헤드는 C3k2 블록 후에 여러 CBS(Convolution-BatchNorm-SiLU) [19] 층을 포함합니다. 이러한 층은 다음을 통해 특징 맵을 추가로 정제합니다:
- 정확한 객체 탐지를 위한 관련 특징 추출.
- 배치 정규화를 통해 데이터 흐름의 안정화 및 정규화.
- 비선형성을 위한 Sigmoid Linear Unit (SiLU) 활성화 함수 사용으로 모델 성능 향상.
CBS 블록은 특징 추출 및 탐지 과정의 기본 구성 요소로 작용하여, 정제된 특징 맵이 경계 상자 및 분류 예측을 위해 다음 층으로 전달되도록 보장합니다.
4.3.3 Final Convolutional Layers and Detect Layer
각 탐지 분기는 Conv2D 층 세트로 끝나며, 이는 경계 상자 좌표와 클래스 예측을 위한 필요한 출력 수로 특징을 줄입니다. 최종 탐지(Detect) 층은 다음을 포함하여 이러한 예측을 통합합니다:
- 이미지 내 객체 위치를 지정하기 위한 경계 상자 좌표.
- 객체 존재를 나타내는 객체 점수.
- 탐지된 객체의 클래스를 결정하는 클래스 점수.
5 Key Computer Vision Tasks Supported by YOLO11
YOLOv11은 다양한 CV 작업을 지원하며, 다양한 응용 분야에서의 다재다능함과 성능을 보여줍니다. 다음은 주요 작업의 개요입니다:
- 객체 감지: YOLOv11은 이미지나 비디오 프레임 내에서 객체를 식별하고 위치를 지정하는 데 뛰어나며, 각 탐지된 항목에 대한 경계 상자를 제공합니다 [20]. 이 기능은 감시 시스템, 자율 주행 차량, 소매 분석 등에서 정확한 객체 식별이 중요한 경우에 응용됩니다 [21].
- 인스턴스 분할: 간단한 탐지를 넘어서 YOLOv11은 이미지 내에서 개별 객체를 픽셀 수준까지 식별하고 분리할 수 있습니다 [20]. 이 세밀한 분할은 정밀한 장기나 종양 경계를 위한 의료 영상과, 상세한 결함 탐지를 위한 제조업에서 특히 유용합니다 [21].
- 이미지 분류: YOLOv11은 전체 이미지를 사전에 정해진 범주로 분류할 수 있으며, 이는 전자 상거래 플랫폼에서 제품 분류 또는 생태학적 연구에서 야생 동물 모니터링과 같은 응용에 이상적입니다 [21].
- 자세 추정: 이 모델은 이미지나 비디오 프레임 내 특정 키포인트를 탐지하여 움직임이나 자세를 추적할 수 있습니다. 이 기능은 피트니스 추적 응용 프로그램, 스포츠 성과 분석, 그리고 동작 평가가 필요한 다양한 의료 응용에 유용합니다 [21].
- 방향성 객체 탐지 (OBB): YOLOv11은 회전된 객체의 더 정확한 위치 지정을 가능하게 하는 방향 각도를 가진 객체 탐지 기능을 도입합니다. 이 기능은 항공 영상 분석, 로봇 공학, 그리고 객체 방향이 중요한 창고 자동화 작업에서 특히 유용합니다 [21].
- 객체 추적: 이미지나 비디오 프레임의 연속에서 객체를 식별하고 경로를 추적합니다 [21]. 이 실시간 추적 기능은 교통 모니터링, 스포츠 분석, 보안 시스템과 같은 응용에 필수적입니다.
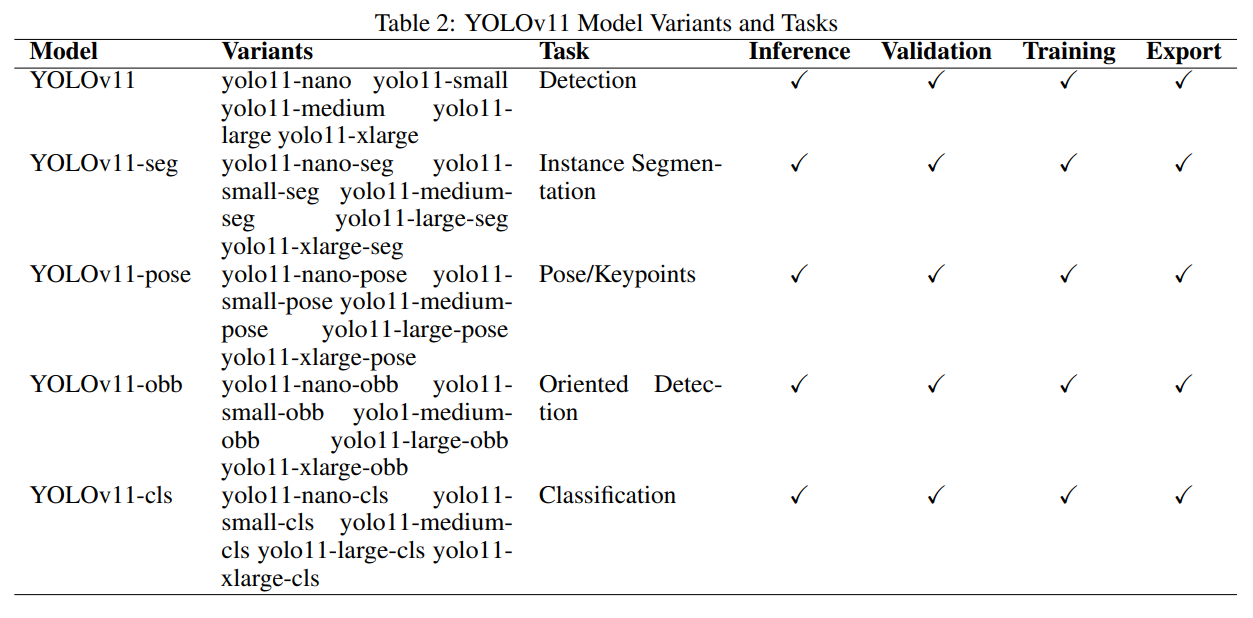
표 2는 YOLOv11 모델 변형과 해당 작업을 개괄적으로 보여줍니다. 각 변형은 객체 탐지에서 자세 추정에 이르는 특정 사용 사례를 위해 설계되었습니다. 또한, 모든 변형은 추론, 검증, 훈련, 내보내기와 같은 핵심 기능을 지원하여 YOLOv11을 다양한 CV 응용을 위한 다재다능한 도구로 만듭니다.
6 Advancements and Key Features of YOLOv11
YOLOv11은 2024년 초에 도입된 이전 버전 YOLOv9 및 YOLOv10이 마련한 기초 위에 구축된 객체 탐지 기술에서의 중요한 진전을 나타냅니다. Ultralytics의 이 최신 버전은 향상된 아키텍처 설계, 더 정교한 특징 추출 기법, 그리고 정제된 훈련 방법론을 보여줍니다. YOLOv11의 빠른 처리, 높은 정확도, 계산 효율성의 시너지는 이를 Ultralytics의 포트폴리오 중 가장 강력한 모델 중 하나로 자리매김하게 합니다 [22]. YOLOv11의 주요 강점은 정제된 아키텍처로, 까다로운 상황에서도 미세한 세부 사항을 탐지할 수 있도록 돕는 데 있습니다. 모델의 향상된 특징 추출 기능은 이미지 내의 더 넓은 범위의 패턴과 복잡한 요소를 식별하고 처리할 수 있도록 합니다. 이전 버전과 비교하여 YOLOv11은 몇 가지 주목할 만한 개선 사항을 도입합니다:
- 복잡도 감소와 함께 향상된 정밀도: YOLOv11m 변형은 COCO 데이터셋에서 YOLOv8m 대비 22% 적은 파라미터를 사용하면서도 더 높은 평균 정밀도(mAP) 점수를 달성하여 정확도를 유지하면서 계산 효율성을 개선했습니다 [23].
- 다양한 CV 작업에서의 다재다능함: YOLOv11은 자세 추정, 객체 인식, 이미지 분류, 인스턴스 분할, 방향 경계 상자(OBB) 탐지 등 다양한 CV 응용 분야에서 뛰어난 능력을 보여줍니다 [23].
- 최적화된 속도와 성능: 정제된 아키텍처 설계와 간소화된 훈련 파이프라인을 통해 YOLOv11은 정확도와 계산 효율성 간의 균형을 유지하면서 더 빠른 처리 속도를 달성합니다 [23].
- 간소화된 파라미터 수: 파라미터 수의 감소는 YOLOv11의 전체 정확도에 큰 영향을 미치지 않으면서 모델 성능을 가속화하는 데 기여합니다 [22].
- 고급 특징 추출: YOLOv11은 백본과 넥 아키텍처 모두에서 개선을 도입하여, 특징 추출 능력을 향상시키고 이에 따라 더 정확한 객체 탐지를 가능하게 합니다 [23].
- 맥락 적응성: YOLOv11은 클라우드 플랫폼, 엣지 장치, NVIDIA GPU에 최적화된 시스템 등 다양한 배포 시나리오에서의 다재다능함을 보여줍니다 [23].
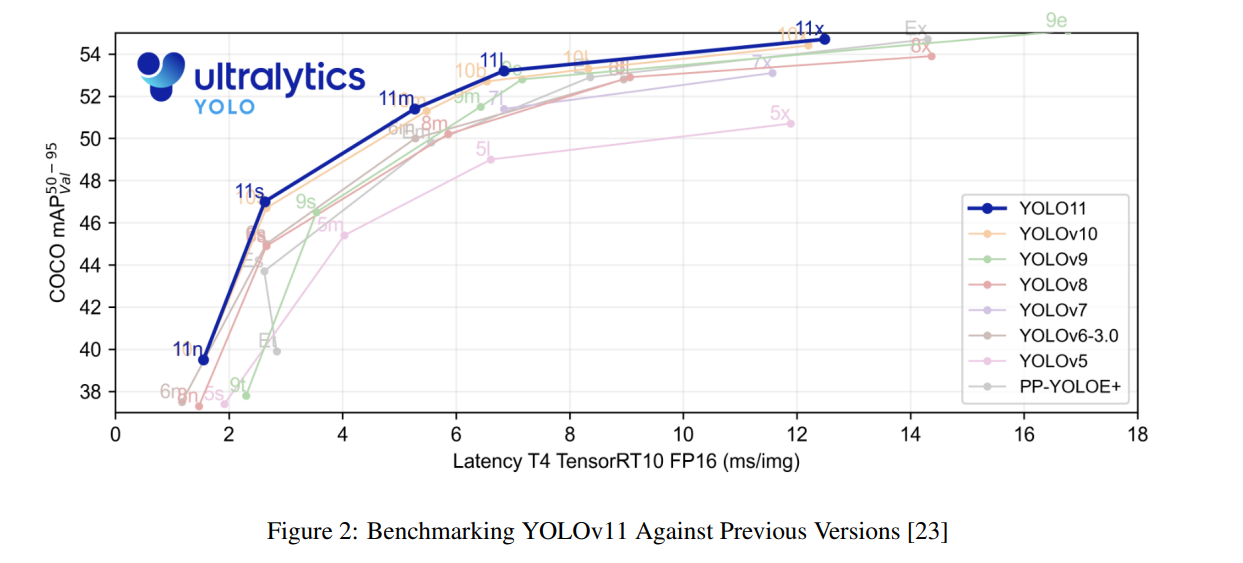
YOLOv11 모델은 이전 버전과 비교하여 추론 속도와 정확도 모두에서 상당한 발전을 보여줍니다. 벤치마크 분석에서 YOLOv11은 YOLOv5[24]와 같은 이전 변형부터 최신 변형인 YOLOv10에 이르기까지 여러 이전 버전과 비교되었습니다. 그림 2에 제시된 바와 같이, YOLOv11은 이러한 모델들을 지속적으로 능가하여 COCO 데이터셋에서 우수한 mAP를 달성하면서도 더 빠른 추론 속도를 유지합니다 [25].
그림 2에 나타난 성능 비교 그래프는 몇 가지 주요 통찰을 제공합니다. YOLOv11 변형들(11n, 11s, 11m, 11x)은 각 모델이 해당 지연 시간에서 더 높은 COCO $\text{mAP}^{50-95}$ 점수를 달성하며, 뚜렷한 성능 경계를 형성합니다. 특히, YOLOv11x는 약 13ms의 지연 시간에서 약 54.5% $\text{mAP}^{50-95}$ 를 달성하여 모든 이전 YOLO 버전을 능가합니다. 중간 변형들, 특히 YOLOv11m은 이전 세대의 더 큰 모델과 유사한 정확도를 달성하면서도 처리 시간이 크게 줄어든 뛰어난 효율성을 보여줍니다.
특히 주목할 만한 점은 저지연 영역(2-6ms)에서의 성능 향상으로, YOLOv11s는 이전에 훨씬 낮은 정확도의 모델과 연관되었던 속도에서 약 47% $\text{mAP}^{50-95}$ 의 높은 정확도를 유지합니다. 이는 속도와 정확도가 모두 중요한 실시간 응용에 있어 중요한 진보를 나타냅니다. YOLOv11의 개선 곡선은 모델 변형 전반에 걸쳐 더 나은 확장 특성을 보여주며, 이전 세대에 비해 추가 계산 자원을 더 효율적으로 활용함을 시사합니다.
7 Discussion
YOLO11은 이전 버전을 기반으로 혁신적인 개선을 도입하여 객체 탐지 기술에서 중요한 도약을 이룹니다. 이 최신 버전은 다양한 CV 작업에서 놀라운 다재다능함과 효율성을 보여줍니다.
- 효율성 및 확장성: YOLO11은 나노에서 초대형까지 다양한 모델 크기를 도입하여 다양한 응용 요구에 부응합니다. 이러한 확장성은 자원이 제한된 엣지 장치에서 고성능 컴퓨팅 환경에 이르기까지 다양한 시나리오에서의 배포를 가능하게 합니다. 특히 나노 변형은 이전 버전에 비해 인상적인 속도와 효율성 향상을 보여주며, 실시간 응용에 이상적입니다.
- 구조적 혁신: 이 모델은 특징 추출 및 처리 능력을 향상시키는 새로운 구조적 요소를 통합합니다. C3k2 블록, SPPF, C2PSA와 같은 새로운 요소의 도입은 더 효과적인 특징 추출 및 처리를 가능하게 합니다. 이러한 개선은 모델이 복잡한 시각 정보를 더 잘 분석하고 해석할 수 있도록 하여 다양한 시나리오에서 탐지 정확도를 향상시킬 가능성을 제공합니다.
- 다중 작업 능력: YOLO11의 다재다능함은 객체 탐지를 넘어 인스턴스 분할, 이미지 분류, 자세 추정, 방향성 객체 탐지와 같은 작업을 포함합니다. 이러한 다방면적 접근은 YOLO11을 다양한 CV 문제에 대한 종합적인 솔루션으로 위치시킵니다.
- 향상된 주의 메커니즘: YOLO11의 주요 발전은 정교한 공간 주의 메커니즘, 특히 C2PSA 구성 요소의 통합입니다. 이 기능은 모델이 이미지 내 중요한 영역에 더 효과적으로 집중할 수 있게 하여 객체를 탐지하고 분석하는 능력을 향상시킵니다. 향상된 주의 능력은 특히 복잡하거나 부분적으로 가려진 객체를 식별하는 데 유익하며, 객체 탐지 작업에서 흔히 발생하는 문제를 해결합니다. 이러한 공간 인식 개선은 특히 까다로운 시각 환경에서 YOLO11의 전반적인 성능 향상에 기여합니다.
- 성능 벤치마크: 비교 분석 결과 YOLO11의 성능이 특히 더 작은 변형에서 뛰어남이 드러났습니다. 나노 모델은 파라미터가 약간 증가했음에도 불구하고 이전 모델에 비해 향상된 추론 속도와 초당 프레임(FPS)을 보여줍니다. 이러한 개선은 YOLO11이 계산 효율성과 탐지 정확성 간의 균형을 잘 유지함을 시사합니다.
- 실제 응용에 대한 영향: YOLO11의 발전은 다양한 산업에 중요한 영향을 미칩니다. 향상된 효율성과 다중 작업 기능은 자율 주행 차량, 감시 시스템, 산업 자동화 응용에 특히 적합하게 만듭니다. 양한 규모에서 우수한 성능을 발휘할 수 있는 모델의 능력은 성능을 저해하지 않고 자원이 제한된 환경에서도 배포할 수 있는 새로운 가능성을 열어줍니다.
8 Conclusion
YOLOv11은 성능과 다재다능함이 결합된 매력적인 조합을 제공하며 CV 분야에서 중요한 진전을 나타냅니다. 이 YOLO 아키텍처의 최신 버전은 정확도와 처리 속도에서 현저한 개선을 보여주며, 동시에 필요한 파라미터 수를 줄였습니다. 이러한 최적화는 YOLOv11을 엣지 컴퓨팅에서 클라우드 기반 분석에 이르기까지 광범위한 응용에 특히 적합하게 만듭니다.
객체 탐지, 인스턴스 분할, 자세 추정 등 다양한 작업에서의 모델 적응성은 이를 감정 탐지[26], 헬스케어[27], 그리고 다양한 기타 산업[17]과 같은 다양한 산업에 유용한 도구로 자리매김하게 합니다. 매끄러운 통합 기능과 향상된 효율성은 이를 CV 시스템을 구현하거나 업그레이드하려는 기업에게 매력적인 선택지로 만듭니다. 요약하자면, 향상된 특징 추출, 최적화된 성능, 넓은 작업 지원이 결합된 YOLOv11은 연구와 실용적인 응용 모두에서 복잡한 시각 인식 문제를 해결하기 위한 강력한 솔루션으로 자리 잡고 있습니다.
Rahima Khanam, Muhammad Hussain YOLOv11: An Overview of the Key Architectural Ehancements

댓글남기기