

개요
YOLOv6 v3.0 리포트의 얕은 리뷰
본 논문은 2023년도 아카이브에 올라왔다. 기존 YOLOv6를 기반으로 v3.0 이라는 이름을 붙여 리뉴얼 한 부분에 대한 리포트이다. 개선 내용을 간단히 요약하면 다음과 같다.
- BiC 모듈을 활용한 넥 구조 개선 및 SPPF를 개선한 SimCSPSPPF 활용
- 앵커 기반 및 앵커 프리 기반을 모두 활용하는 AAT 전략 제안
- 백본 및 넥의 단계 추가로 인한 성능 강화
- 자가 증류(self-distilation)전략 도입 및 DFL 대체 및 추론 시 제거
방법론
- 각 스케일에서의 피쳐맵 통합이 중요하기에 개선된 PAN(Path Aggregation Network)을 넥(Neck)으로 활용한다. 이 과정에서 각 피쳐맵의 객체의 위치 시그널을 강화하기 위한 BiC(Bi-Directional Concatenation) 모듈을 제안한다.
- 또한 기존 SPPF 블록을 CSP 스타일의 SimCSPSPPF 블록으로 단순화하여 이용한다. 이는 C5 단계에서 PAN의 넥 구조로 피처맵을 병합하기 전에 처리해주는 모듈로 보인다(그림 2 참조)
- 기본적으로 YOLOv6는 앵커 프리 탐지기 지만, 앵커 기반 방식의 학습 효율을 얻어오기 위해 앵커 기반 방식을 학습시에 붙이고 추론 시에 버리는 AAT(Anchor-Aided Traning)을 제안한다.
- 자기 증류(self-distillation) 방법을 통해 내부에서 교사 모델과 학생 모델을 통한 지식 증류를 적용한다. DFL Loss를 채택하여 박스 위치 회귀에 적용한다.
- 소형 모델에는 DLD(Decoupled Localization Distillation)을 적용한다.
실험
- YOLOv5, YOLOX, PP-YOLOE, YOLOv8 과의 비교를 진행하였고 전반적으로 각 스케일 대비 AP와 처리속도 면에서 전부 향상을 보였고 YOLOv8의 경우엔 정확도(AP)는 비슷했으나 FPS 측면에서 우위를 보였다.
- BiC+SimCSPSPPF / AAT / DLD 에 대한 소거 연구 진행(표 3)
- BiC 모듈의 경로 적용 소거 연구: Top-down & Bottom-up(표 4)
- YOLOv6의 스케일 별 SPP 블록의 비교 연구(표 5)
- YOLOv6의 스케일 별 AAT 소거 연구(표 6)
- 자기 증류(self-distillation) 기법의 학습 에폭에 따른 효용 실험(표 7)
- DLD와 학습 에폭에 따른 효용 실험(표 8)
결론
본 논문은 YOLOv6를 베이스로 아키텍쳐 변경 및 학습 개선 테크닉 적용을 통한 객체 감지 성능 향상을 이끌어냈다. v6 라는 타이틀을 달고 있지만 당시 성능-속도의 최신 버전이었던 v8 과 비슷한 정확도이면서 높은 속도를 보여주는 발전된 방법을 제안하여 실시간 객체감지기의 관점에서 더 진보된 모습을 보여주었다.
번역
Abstract
YOLO 커뮤니티는 첫 두 번의 릴리스 이후로 높은 기대감을 가지고 있습니다! 2023년의 토끼 해인 중국 설을 맞아, 우리는 네트워크 아키텍처와 학습 방식에 수많은 새로운 개선을 통해 YOLOv6를 재단장했습니다. 이번 릴리스는 YOLOv6 v3.0으로 명명되었습니다. 성능을 간단히 살펴보면, 우리의 YOLOv6-N은 NVIDIA Tesla T4 GPU로 테스트했을 때 COCO 데이터셋에서 1187 FPS의 처리 속도와 함께 37.5% AP를 기록합니다. YOLOv6-S는 484 FPS에서 45.0% AP를 기록하며, 같은 스케일의 다른 주류 감지기들(YOLOv5-S, YOLOv8-S, YOLOX-S 및 PPYOLOE-S)을 능가합니다. 한편, YOLOv6-M과 L은 각각 50.0% 및 52.8%로 유사한 추론 속도에서 다른 감지기보다 더 높은 정확도 성능을 달성합니다. 추가적으로, 확장된 백본과 넥 디자인을 갖춘 우리의 YOLOv6-L6는 실시간에서 최첨단 정확도를 달성합니다. 각 개선 구성 요소의 효과를 검증하기 위해 철저한 실험이 신중히 수행되었습니다. 우리의 코드는 https://github.com/meituan/YOLOv6 에서 공개됩니다.
1. Introduction
YOLO 시리즈는 속도와 정확도 사이의 탁월한 균형 덕분에 산업 응용 분야에서 가장 인기 있는 감지 프레임워크로 자리 잡았습니다. YOLO 시리즈의 선구적인 연구들로는 YOLOv1-3 [12−14]이 있으며, 이는 후속의 상당한 개선과 함께 새로운 1단계 감지기의 길을 열었습니다. YOLOv4 [1]는 감지 프레임워크를 백본, 넥, 헤드 등 여러 개의 독립된 부분으로 재구성하고, 단일 GPU에서의 학습에 적합한 프레임워크를 설계하기 위해 bag-of-freebies와 bag-of-specials을 검증했습니다. 현재, YOLOv5 [5], YOLOX [3], PP-YOLOE [17], YOLOv7 [16] 및 최근의 YOLOv8 [6]이 모두 효율적인 감지기 배포를 위한 경쟁 후보들입니다.
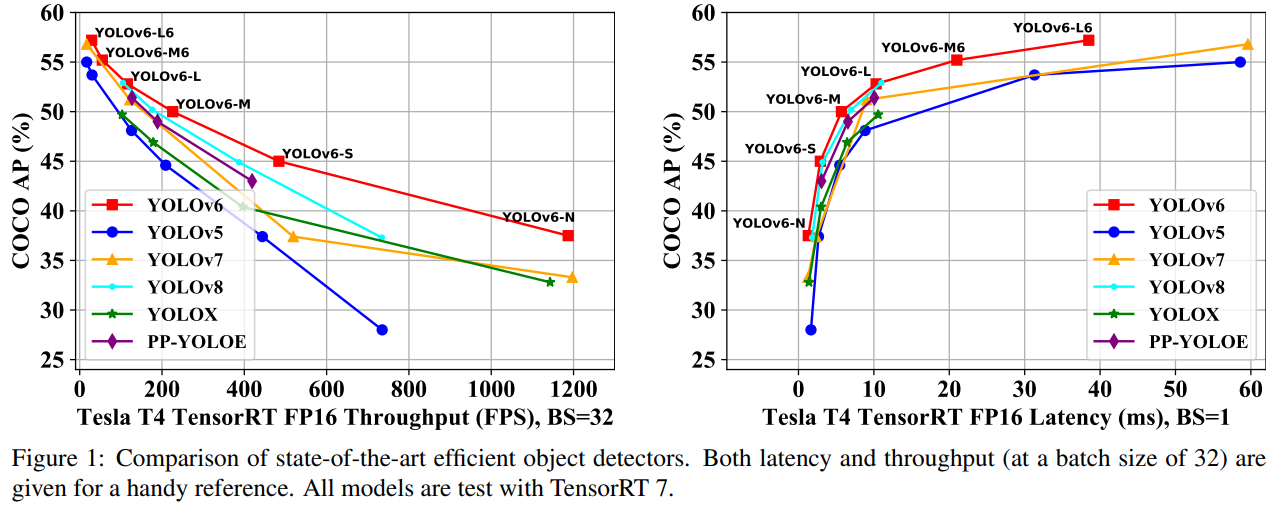
이번 릴리스에서 우리는 네트워크 설계와 학습 전략을 철저히 개선했습니다. 우리는 그림 1에서 YOLOv6와 유사한 규모의 다른 모델들과의 비교를 보여줍니다. YOLOv6의 새로운 기능은 다음과 같이 요약됩니다.
- 우리는 Bi-directional Concatenation (BiC) 모듈로 탐지기의 넥을 새롭게 하여 더 정확한 위치 신호를 제공합니다. SPPF [5]는 SimCSPSPPF 블록을 형성하도록 간소화되었으며, 이는 거의 속도 저하 없이 성능 향상을 가져옵니다.
- 우리는 앵커 기반과 앵커 프리 패러다임의 장점을 활용하면서 추론 효율성에 영향을 주지 않는 앵커 지원 학습(AAT) 전략을 제안합니다.
- 우리는 YOLOv6의 백본과 넥에 또 하나의 단계를 추가하여 고해상도 입력에서 COCO 데이터셋에서 새로운 최첨단 성능을 달성할 수 있도록 강화했습니다.
- 우리는 YOLOv6의 소형 모델 성능을 향상시키기 위해 새로운 자가 증류(self-distillation) 전략을 도입했으며, 학습 중 DFL [8]의 무거운 분기를 향상된 보조 회귀 분기로 사용하고, 추론 시 속도 저하를 피하기 위해 이를 제거합니다.
2. Method
2.1. Network Design
실제로, 여러 스케일에서의 특징 통합은 객체 감지에서 중요한 효과적인 구성 요소임이 입증되었습니다. 특징 피라미드 네트워크(FPN) [9]는 상위 레벨의 의미적 특징과 하위 레벨 특징을 상향식 경로를 통해 통합하여 더 정확한 위치 정보를 제공합니다. 이후 계층적 특징 표현 능력을 향상시키기 위해 양방향 FPN에 대한 여러 연구 [2,4,10,15]가 있었습니다. PANet [10]은 FPN 상단에 추가적인 하향식 경로를 추가하여 하위 및 상위 레벨 특징의 정보 경로를 단축하며, 이를 통해 하위 레벨 특징으로부터 정확한 신호 전파를 촉진합니다. BiFPN [15]은 다양한 입력 특징에 대해 학습 가능한 가중치를 도입하고, 높은 효율성을 유지하면서 PAN의 성능을 향상시킵니다. PRB-FPN [2]은 양방향 융합과 관련 개선을 통해 병렬 FP 구조로 정확한 위치 지정을 위한 고품질 특징을 유지하도록 제안되었습니다.
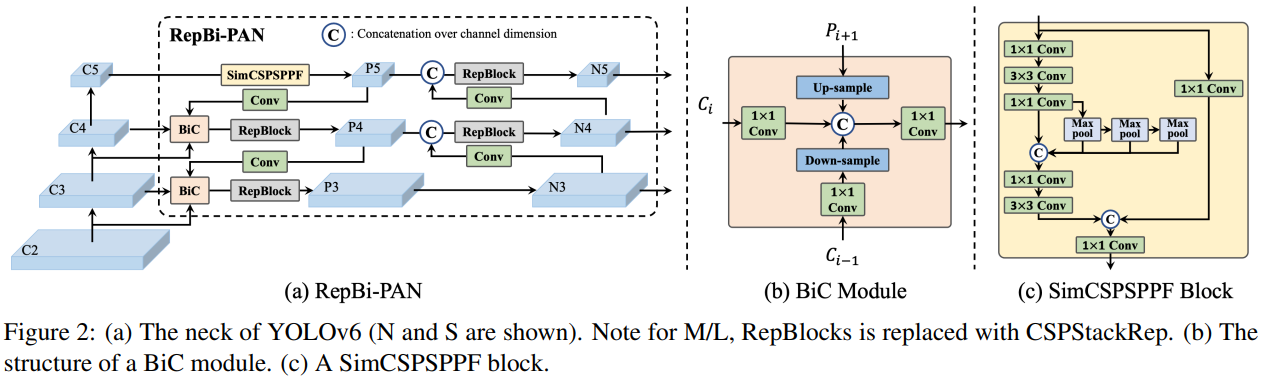
위의 연구들을 기반으로, 우리는 개선된 PAN을 탐지 넥으로 설계했습니다. 과도한 계산 부담 없이 위치 신호를 강화하기 위해, 우리는 인접한 세 개의 레이어의 특징 맵을 통합하여 백본의 하위 레벨 특징 $C_{i−1}$ 을 $P_i$ 에 융합하는 Bi-directional Concatenation(BiC) 모듈을 제안합니다 (그림 2). 이 경우, 소형 객체의 위치 지정을 위해 중요한 더 정확한 위치 신호가 보존될 수 있습니다.
또한, 우리는 표현 능력을 강화하는 CSP 스타일의 SimCSPSPPF 블록으로 SPPF 블록 [5]을 단순화했습니다. 특히 [16]의 SimSPPCSPC 블록을 은닉층의 채널 수를 줄이고 공간 피라미드 풀링을 재조정하여 수정했습니다. 또한, 작은 모델의 경우 RepBlock 또는 큰 모델의 경우 CSPStackRep 블록을 사용하여 CSPBlock을 업그레이드하고 이에 따라 너비와 깊이를 조정합니다. YOLOv6의 넥은 RepBi-PAN으로 명명되었으며, 그 구조는 그림 2에 나와 있습니다.
2.2. Anchor-Aided Training
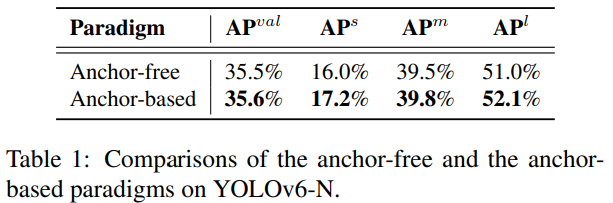
YOLOv6는 더 높은 추론 속도를 추구하기 위해 앵커 프리 감지기로 설계되었습니다. 그러나 우리는 실험적으로 앵커 프리 방식과 비교했을 때 같은 설정 하에서 YOLOv6-N이 앵커 기반 패러다임을 통해 추가적인 성능 향상을 얻는다는 것을 확인했습니다. 이는 표 1에 나타나 있습니다. 또한, 초기 YOLOv6 버전에서는 훈련의 안정성을 높이기 위해 앵커 기반 ATSS [18]가 웜업 레이블 할당 전략으로 채택되었습니다.
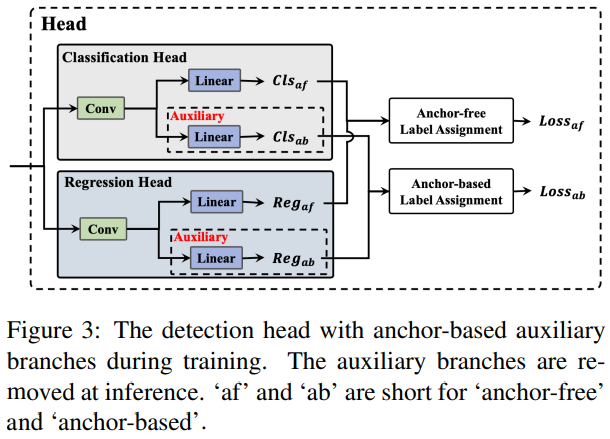
이를 바탕으로 우리는 앵커 지원 학습(AAT)을 제안하며, 앵커 기반 보조 분기를 도입하여 앵커 기반 및 앵커 프리 패러다임의 장점을 결합합니다. 이들은 분류 헤드와 회귀 헤드 모두에 적용됩니다. 그림 3은 보조 기능을 포함한 탐지 헤드를 보여줍니다.
학습 단계에서 보조 분기와 앵커 프리 분기는 독립적인 손실로부터 학습하며 신호는 함께 전파됩니다. 따라서 보조 분기로부터 추가적인 내장된 가이드 정보가 주 앵커 프리 헤드에 통합됩니다. 추론 시 보조 분기가 제거되어 속도 저하 없이 정확도 성능을 향상시키는 점을 주목할 만합니다.
2.3. Self-distillation
YOLOv6 초기 버전에서는 자기 증류(self-distillation)가 대형 모델(예: YOLOv6-M/L)에만 도입되었으며, 교사 모델과 학생 모델의 클래스 예측 간 KL 발산을 최소화하는 기본적인 지식 증류 기법을 적용합니다. 한편, DFL [8]은 박스 회귀에 대한 자기 증류를 수행하기 위한 회귀 손실로 채택되었으며, 이는 [19]와 유사합니다.
지식 증류 손실은 다음과 같이 공식화됩니다.
여기서 $p_t^{cls}$ 와 $p_s^{cls}$ 는 각각 교사 모델과 학생 모델의 클래스 예측을 나타내며, $p_t^{reg}$ 와 $p_s^{reg}$ 는 박스 회귀 예측을 나타냅니다. 전체 손실 함수는 다음과 같이 공식화됩니다.
\[\begin{equation} L_{total} = L_{det} + \alpha{L_{KD}} \end{equation}\]여기서 $L_{det}$ 는 예측과 레이블로 계산된 탐지 손실입니다. 하이퍼파라미터 $α$ 는 두 손실을 균형 있게 조절하기 위해 도입되었습니다. 학습 초기 단계에서는 교사의 소프트 레이블이 학습하기 더 쉽습니다. 학습이 진행됨에 따라 학생의 성능이 교사와 일치하게 되면서 하드 레이블이 학생들에게 더 많은 도움이 됩니다. 이를 갱신하기 위해, 우리는 $α$ 에 코사인 가중 감쇠(cosine weight decay)를 적용하여 교사로부터 받은 하드 및 소프트 레이블 정보를 동적으로 조정합니다. $α$ 의 공식은 다음과 같습니다.
\[\begin{equation} \alpha =-0.9 \ast ((1-\cos(\pi\ast E_i/E_{max}))/2)+1, \end{equation}\]여기서 $E_i$ 는 현재 학습 에포크를 나타내며, $E_{max}$ 는 최대 학습 에포크를 나타냅니다.
주목할 점은 DFL [8] 도입으로 인해 회귀 분기에서 추가 파라미터가 필요하며, 이는 소형 모델의 추론 속도에 큰 영향을 미칩니다. 따라서 우리는 성능을 저하시키지 않고 성능을 향상시키기 위해 소형 모델용으로 Decoupled Localization Distillation (DLD)을 특별히 설계했습니다. 구체적으로, DFL을 포함하기 위해 무거운 보조 향상된 회귀 분기를 추가합니다. 자기 증류 동안, 학생 모델은 단순 회귀 분기와 향상된 회귀 분기를 장착하고, 교사 모델은 보조 분기만을 사용합니다. 단순 회귀 분기는 하드 레이블로만 학습되는 반면, 보조 분기는 교사와 하드 레이블로부터의 신호에 따라 업데이트됩니다. 증류 이후에는 단순 회귀 분기를 유지하고 보조 분기는 제거됩니다. 이 전략을 통해 증류 과정에서 DFL을 위한 무거운 회귀 분기의 장점을 추론 효율성에 영향을 주지 않고 상당히 유지할 수 있습니다.
3. Experiments
3.1. Comparisons
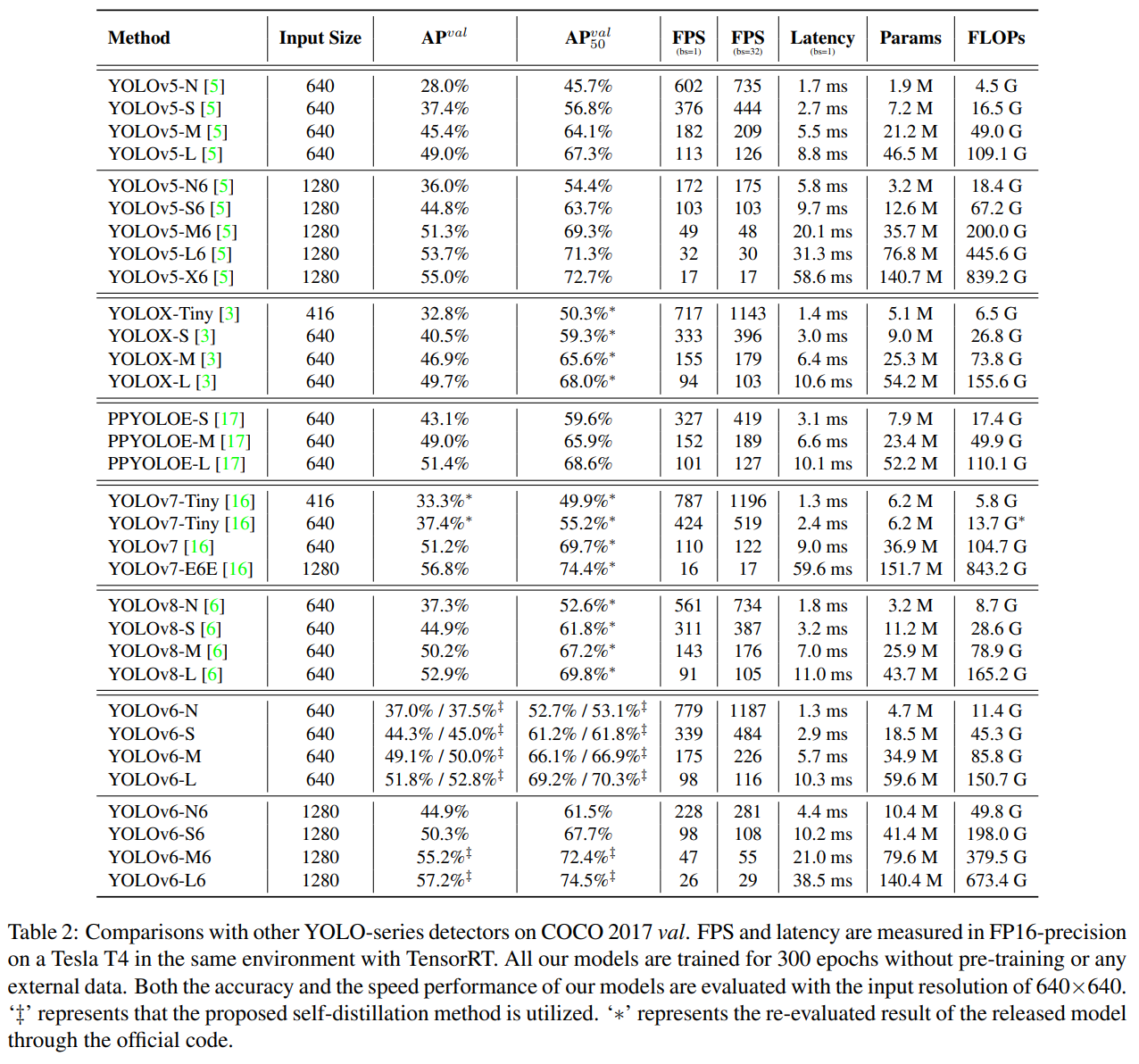
평가는 YOLOv6의 초기 버전 [7]과 일관되게 진행되었으며, 배포 시의 처리량과 GPU 지연 시간에 중점을 둡니다. 모든 공식 모델의 속도 성능은 동일한 Tesla T4 GPU에서 FP16 정밀도로 TensorRT [11]를 사용하여 테스트되었습니다. 우리는 업그레이드된 YOLOv6을 YOLOv5 [5], YOLOX [3], PPYOLOE [17], YOLOv7 [16] 및 YOLOv8 [6]과 비교합니다. YOLOv7-Tiny의 성능은 416 및 640의 입력 크기에서 공개된 코드 및 가중치에 따라 재평가되었습니다. 결과는 표 2 및 그림 1에 나타나 있습니다. YOLOv5-N/YOLOv7-Tiny (입력 크기=416)과 비교했을 때, YOLOv6-N은 각각 9.5%/4.2%로 크게 향상되었습니다. 또한 처리량과 지연 시간 측면에서 최고의 속도 성능을 제공합니다. YOLOX-S/PPYOLOE-S와 비교했을 때, YOLOv6-S는 더 높은 속도와 함께 AP를 3.5%/0.9% 개선할 수 있습니다. YOLOv6-M은 유사한 속도에서 YOLOv5-M보다 AP가 4.6% 높으며, 더 높은 속도에서 YOLOX-M/PPYOLOE-M보다 AP가 3.1%/1.0% 높습니다. 또한 YOLOv5-L보다 더 정확하고 빠릅니다. YOLOv6-L은 같은 지연 시간 제한에서 YOLOX-L/PPYOLOE-L보다 3.1%/1.4% 더 정확합니다. YOLOv8 시리즈와 비교했을 때, 우리 YOLOv6는 모든 크기의 모델에서 정확도와 지연 시간 면에서 유사한 성능을 달성하면서도 처리량 성능이 상당히 우수합니다.
최신 기법들과 비교하기 위해, 우리는 [5]를 따라 백본 상단에 추가적인 단계를 추가하여 대형 객체 감지를 위한 상위 수준의 특징(C6)을 제공합니다. 이에 따라 넥도 확장되었습니다. C6 특징을 가진 모든 크기의 YOLOv6 모델은 각각 YOLOv6-N6/S6/M6/L6로 명명되었습니다. 또한 이미지 해상도가 640에서 1280으로 조정되었습니다. 특징 보폭은 8에서 64로 범위가 지정되어 고해상도 이미지에서 매우 작은 객체와 대형 객체에 대한 정확한 감지를 가능하게 합니다. 표 2에 나열된 실험 결과는 확장된 YOLOv6가 정확도에서 큰 향상을 얻었음을 보여줍니다. 확장된 YOLOv5 (즉, YOLOv5-N6/S6/M6/L6/X6)와 비교했을 때, 우리의 모델은 유사한 추론 속도에서 훨씬 더 높은 AP를 가집니다. 최첨단 YOLOv7-E6E와 비교했을 때, YOLOv6-L6는 AP가 0.4% 향상되었으며 배치 크기 1에서 63% 더 빠르게 실행됩니다.
3.2. Ablation Study
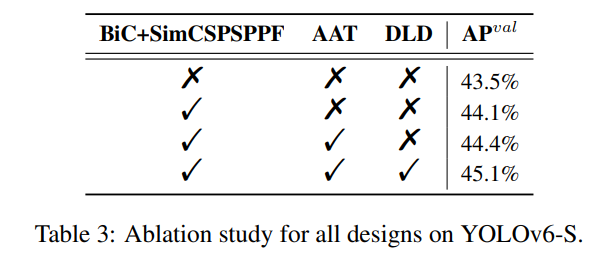
표 3의 실험 결과는 이 작업에서의 모든 기여 요소의 효과를 보여줍니다. BiC와 SimCSPSPPF를 적용한 개선된 네트워크는 AP가 0.6% 향상되었습니다. AAT와 DLD를 추가하면, 정확도가 각각 0.3% 및 0.7%씩 추가로 향상됩니다.
3.2.1 Network Design
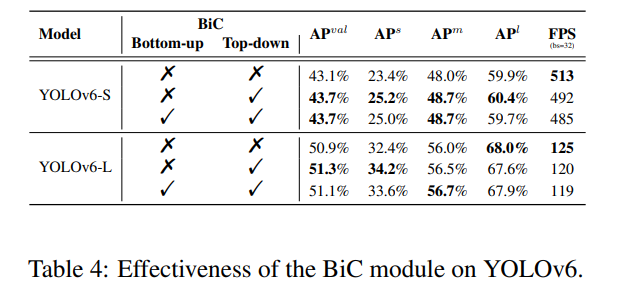
우리는 제안된 BiC 모듈의 효과를 검증하기 위해 일련의 실험을 수행했습니다. 표 4에서 볼 수 있듯이, PAN의 상향식 경로에만 BiC 모듈을 적용하면 YOLOv6-S/L에서 각각 0.6%/0.4%의 AP 개선이 이루어지며, 효율성 손실은 무시할 만합니다. 반면, 하향식 경로에 BiC 모듈을 도입하려 할 때는 정확도에서 긍정적인 이득이 얻어지지 않았습니다. 그 이유는 하향식 경로의 BiC 모듈이 서로 다른 스케일의 특징에 대해 탐지 헤드를 혼란스럽게 만들기 때문일 가능성이 있습니다. 따라서 우리는 상향식 경로에만 BiC 모듈을 채택했습니다. 또한, BiC 모듈은 작은 객체 감지 성능을 인상적으로 향상시킨다는 결과가 나타났습니다. YOLOv6-S와 YOLOv6-L 모두에서 작은 객체에 대한 감지 성능이 1.8% 향상되었습니다.
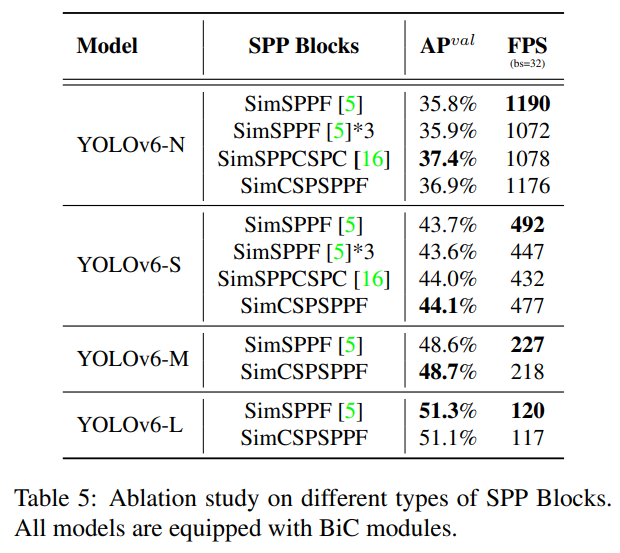
또한, 우리는 SPPF [5]와 SPPCSPC [16]의 단순화된 변형(SimSPPF 및 SimSPPCSPC로 표시) 및 SimCSPSPPF 블록을 포함하여 다양한 유형의 SPP 블록의 영향을 탐구합니다. 추가적으로, 우리는 SimSPPF 블록을 백본의 상위 세 개의 특징 맵(P3, P4, P5)에 적용하여 그 효과를 검증하였으며, 이를 SimSPPF*3으로 표시합니다. 실험 결과는 표 5에 나와 있습니다. SimSPPF를 많이 사용하면 계산 복잡성이 증가하면서 정확도에서 거의 이득이 없음을 관찰했습니다. SimSPPCSPC는 YOLOv6-N/S에서 각각 1.6%/0.3% AP로 SimSPPF보다 뛰어난 성능을 보이며, 추론 속도를 크게 감소시킵니다. SimSPPF와 비교했을 때, 우리 SimCSPSPPF 버전은 YOLOv6-N/S/M에서 각각 1.1%/0.4%/0.1%의 성능 향상을 제공합니다. 추론 효율성 측면에서 SimCSPSPPF 블록은 SimSPPCSPC보다 거의 10% 더 빠르며 SimSPPF보다 약간 느립니다. 더 나은 정확도-효율성 균형을 위해 YOLOv6-N/S에는 SimCSPSPPF 블록이 도입되었고, YOLOv6-M/L에는 SimSPPF 블록이 채택되었습니다.
3.2.2 Anchor-Aided Training
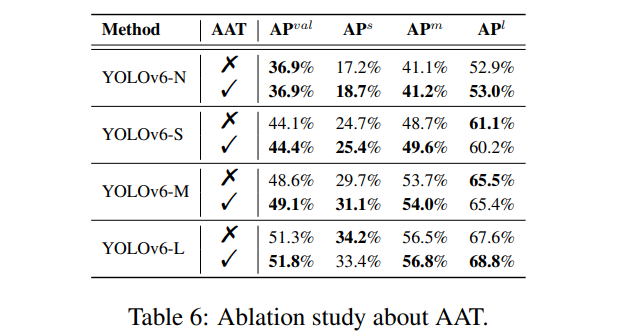
AAT의 장점이 YOLOv6에서 검증되었습니다. 표 6에서 볼 수 있듯이, YOLOv6-S/M/L에 대해 각각 0.3%/0.5%/0.5% AP 향상을 가져옵니다. 특히, 작은 객체($AP^s$)에 대한 정확도 성능이 YOLOv6-N/S/M에서 크게 향상되었습니다. YOLOv6-L의 경우, 큰 객체($AP^l$)에 대한 성능이 더욱 향상되었습니다.
3.2.3 Self-distillation
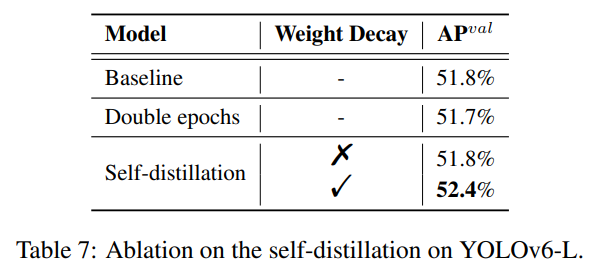
우리는 YOLOv6-L에서 제안된 자기 증류 방법을 검증했습니다. 공정한 비교를 위해, 자기 증류가 교사 모델을 얻기 위해 전체적인 추가 학습 주기를 필요로 하기 때문에, 베이스라인 외에 학습 에포크를 두 배로 하여 모델 성능을 검증했습니다. 표 7에서 볼 수 있듯이, 가중치 감쇠(weight decay) 전략 없이 베이스라인과 비교했을 때 성능 향상이 이루어지지 않았습니다. 학습 에포크를 두 배로 늘리는 것은 과적합으로 인해 오히려 더 나쁜 결과를 나타냈습니다. 가중치 감쇠를 도입한 후, 모델은 0.6% AP가 향상되었습니다.
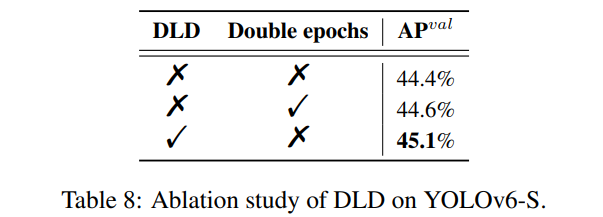
추가로, 소형 모델을 위해 특별히 설계된 DLD가 YOLOv6-S에서 절제 연구되었습니다. 대형 모델을 위한 자기 증류와 마찬가지로, 우리는 학습 에포크를 두 배로 한 모델과 결과를 비교했습니다. 표 8에서 볼 수 있듯이, DLD를 적용한 YOLOv6-S는 0.7% AP 향상을 제공하며, 학습 에포크를 두 배로 한 것보다 0.5% 더 우수한 성능을 보였습니다.
4. Conclusion
이 보고서에서, YOLOv6는 네트워크 설계 및 학습 전략 측면에서 업그레이드되어 실시간 객체 감지를 위한 최첨단 정확도를 달성하게 되었습니다. 앞으로 우리는 연구를 지속하면서 YOLOv6를 애플리케이션 친화적인 탐지 프레임워크로 최적화하기 위해 노력할 것이며, 객체 감지 기술의 발전과 함께 연구를 이어 나갈 것입니다.
Chuyi Li, Lulu Li, Yifei Geng, Hongliang Jiang, Meng Cheng, Bo Zhang, Zaidan Ke, Xiaoming Xu, Xiangxiang Chu YOLOv6 v3.0: A Full-Scale Reloading

댓글남기기