

개요
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose 논문의 번역 및 얕은 리뷰. 해당 논문은 2017년 CVPR에서 발표되었다.
단안 컬러 이미지로부터 사람의 3D 자세 추정 문제를 다룬다. 기존 연구들과 다르게 볼류메트릭 방법을 제안한다. 추가로 Coarse-to-Fine 학습 기법을 제안하여 더 정교한 학습을 달성하는 방법론을 설명한다.
방법론
- 볼류메트릭 방식
- 이미지로부터 직접적인 좌표회귀를 하지 않고 voxel의 형태로 이산화된 표현을 제안한다.
- 이는 마치 2D Human Pose를 이미지에서 회귀 방식으로 좌표를 바로 추정하지 않고 좌표 위치의 확률 분포인 히트맵 방식으로 표현하는 것과 상당히 유사하다고 생각된다.
- Coarse-to-fine
- 이러한 voxel 의 높은 차원의 필요성 때문에, 네트워크가 이미지로 부터 한번에 세번째 차원을 예측하면 오버헤드가 커진다.
- 그래서 처음엔 z-axis를 낮게 가져가다가 점점 키우는 방식으로 반복적 정제 방식으로 접근한다.
- Decoupled architecture
- 하나의 엔드투엔드 네트워크 내부를 분리하여 2D 키포인트 히트맵을 에측하는 부분을 넣고 이와 더불어 이미지 피쳐맵을 동시에 활용하여 3D를 예측하는 방식으로 수행한다.
- 2D 키포인트 히트맵만을 활용할 경우 이미지의 특징이 반영되지 않는다고 한다.
실험
- 사용된 데이터 셋은 Human3.6M, HumanEva-I, KTH Football II, MPII 데이터 셋이다.
- 평가에 사용된 성능 지표는 Per joint 3D Error, Reconstruction Error, 3D PCP(Percentage of Correctly estimated Parts) 지표를 사용하엿으며 3D PCP는 KTH 같은 특정 데이터 셋에서만 사용된다.
- 볼류메트릭 방식과 좌표 직접 회귀 방식의 성능 비교 실행
- Hourglass 구조의 나이브한 스택과 Coarse-to-fine 방식의 학습 성능 차이 확인
- Decoupled 구조의 이미지 특징 반영여부에 따른 성능 차이 확인
- 각 데이터 셋에 대한 메트릭 확인 뿐 아니라 MPII 데이터 셋에 대한(2D 정답밖에 없는) 3D 추정의 정성적 결과를 확인한다.
결론
본 논문은 3차원 사람 자세 추정 문제를 볼류메트릭 표현으로 접근하여 마치 2D의 히트맵 표현과 유사한 접근 방식을 제안하며, coarse-to-fine 학습 방식으로 효율적인 성능을 달성하는 방식을 제안한다. 추가로 과거의 비교군 대비 압도적인 높은 성능을 달성함을 알 수 있다.
2017년도 SimpleBaseline3D 와 더불어 급격한 성능향상의 시작이라고 생각된다.
번역
Abstract
이 논문은 단일 컬러 이미지에서 3D 인간 포즈를 추정하는 과제를 다룹니다. 엔드투엔드 학습 패러다임이 전반적으로 성공을 거두었음에도 불구하고, 최고 성능을 보이는 접근법들은 2D 관절 위치 추정을 위한 합성곱 신경망(ConvNet)과 그 후에 3D 포즈를 복원하기 위한 최적화 단계를 포함하는 두 단계 솔루션을 사용합니다. 본 논문에서는 현재 ConvNet 기반 접근법에서 3D 포즈 표현이 핵심적인 문제임을 지적하고, 이 작업을 위해 엔드투엔드 학습의 가치를 검증하는 데 있어 두 가지 중요한 기여를 제시합니다. 먼저, 피사체 주변의 3D 공간을 세분화하여 이산화(fine discretization)하고, 각 관절에 대한 voxel 단위 확률을 예측하기 위해 ConvNet을 학습시키는 방안을 제안합니다. 이는 3D 포즈에 대한 자연스러운 표현을 형성하며, 관절 좌표를 직접 회귀하는 방식보다 성능을 크게 향상시킵니다. 둘째로, 초기 추정을 더욱 개선하기 위해서 거칠게(coarse)에서 정교하게(fine) 진행되는 예측 방식을 도입합니다. 이 과정은 차원의 급격한 증가 문제를 해결하고, 이미지 특징을 반복적으로 처리하며 점진적으로 정제하는 것을 가능하게 합니다. 제안된 접근법은 표준 벤치마크에서 최신 기법들을 모두 능가하며, 평균적으로 30%를 초과하는 상대적 오류 감소를 달성합니다. 또한, 우리는 우리의 볼류메트릭(volumetric) 표현을 관련된 구조에 적용하는 방법을 연구하는데, 이는 엔드투엔드 접근법과 비교했을 때 최적의 해법은 아니지만, 대응되는 3D 정답(ground truth)이 없는 경우에도 학습을 가능하게 하며, 실제 환경(in-the-wild) 이미지에 대해서도 흥미로운 결과를 제시할 수 있다는 점에서 실용적인 가치를 지닙니다.
1. Introduction
단일 단안(monocular) 이미지에서 사람의 전신 3D 포즈를 추정하는 문제는 오랜 컴퓨터 비전 연구 초기부터 [18] 많은 주목을 받아온 미해결 과제입니다. 문제 자체가 ill-posed하기 때문에, 연구자들은 일반적으로 3D 인간 포즈 추정을 간소화된 환경에서 접근해 왔습니다. 예를 들어, 배경 제거가 가능하다고 가정하는 방식 [1], 실제 정답(groundtruth) 2D 관절 위치를 활용하여 3D 포즈를 추정하는 방식 [26, 43], 추가적인 카메라 뷰를 사용하는 방식 [7, 15], 그리고 시간적 일관성(temporal consistency)을 이용하여 단일 프레임 예측을 개선하는 방식 [38, 3] 등이 이에 해당합니다. 이러한 다양한 가정과 추가 정보의 활용은 이 과제가 가진 난이도를 잘 보여줍니다.
합성곱 신경망(ConvNets)과 같은 더욱 강력한 판별적(discriminative) 접근법이 도입되면서, 이처럼 제한적인 가정들의 상당 부분이 완화되었습니다. 엔드투엔드 학습 방법들은 3D 포즈를 단일 이미지에서 직접 추정하기 위해, 이를 좌표 회귀 [19, 35], 이미지와 포즈 간 최근접 이웃(nearest neighbor) [20], 또는 포즈 클래스로의 분류 [27] 문제로 다룹니다. 하지만 현재까지 이러한 접근법들은 [45, 6] 등 보다 전통적인 두 단계 파이프라인보다 성능이 떨어져 왔습니다. 이 두 단계 접근법에서는, ConvNet이 오직 2D 관절 위치 추정 용도로만 사용되고, 3D 포즈는 후처리 최적화 단계에서 생성됩니다. 정확한 2D 관절 위치 추정과 강력하고 표현력이 높은 3D 사전 지식(3D priors)을 결합하는 방식은 매우 효과적임이 입증되었습니다. 본 연구에서는, ConvNet이 단순 2D 관절 위치 이상의 훨씬 풍부한 정보를 제공할 수 있음을 보입니다.
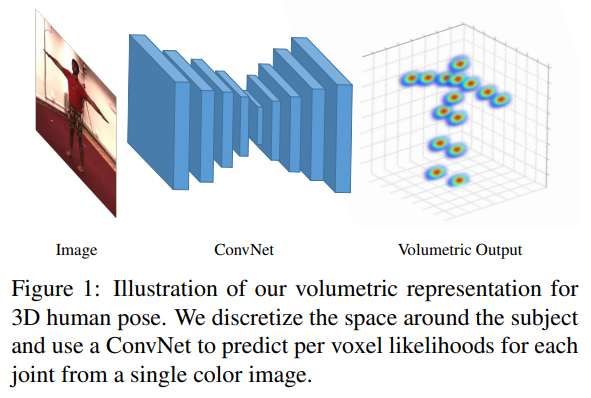
3D 인간 포즈 문제에서 ConvNet의 잠재력을 최대한 활용하기 위해, 우리는 다음과 같은 사항을 제안하고, 이를 실험적으로 정당화합니다. 먼저, 3D 포즈 추정을 이산화된(discretized) 3D 공간에서의 키포인트(keypoint) 위치 찾기 문제로 정의합니다. 즉, 관절의 좌표를 직접 회귀(예: [19, 35])하는 대신, 이 3D 볼륨에서 각 관절의 voxel 별 확률(likelihood)을 예측하도록 ConvNet을 학습시킵니다. Figure 1에서 보여주듯이 이러한 볼륨 기반(volumetric) 표현은 우리의 3D 문제 특성에 훨씬 잘 부합하며 학습을 개선해 줍니다. 구체적으로, 모든 관절에 대해 볼륨 기반 감독(volumetric supervision)은 3D 공간의 각 voxel마다 정답(groundtruth)을 네트워크에 제공합니다. 이는 단순히 월드 좌표(world coordinates) 집합을 제공하는 것보다 훨씬 풍부한 정보를 제공합니다. 그리고 실험 결과는 제안된 감독 방식이 우수함을 입증합니다.
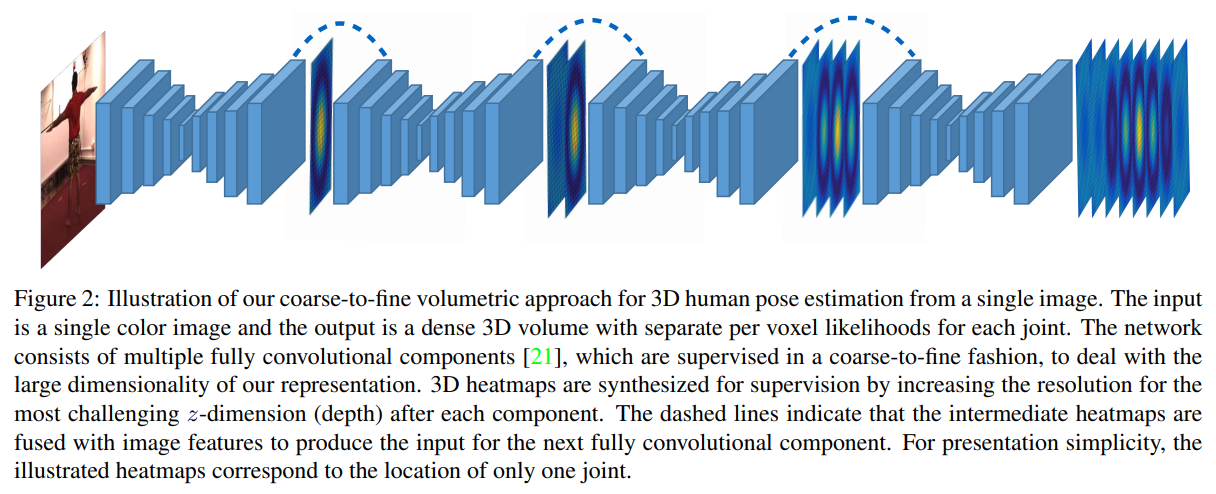
둘째로, 볼류메트릭 표현(Volumetric representation)의 차원 증가 문제를 해결하기 위해, 우리는 coarse-to-fine 예측 기법을 제안합니다. 2D 포즈 사례에서도 입증되었듯이, 중간(intermediate) 감독(supervision)과 반복(iterative) 추정은 특히 효과적인 전략입니다 [40, 8, 21]. 그러나 우리의 볼류메트릭 표현에서는 단순히 더 많은 구성 요소를 층층이 쌓고 추정을 세밀하게 다듬는 방식이, 실험적으로 보았을 때 효과적인 해결책이 아닙니다. 대신, 우리는 처리 과정에서 가장 난이도가 높은 z 차원(깊이)에 대해, 감독용 볼륨(supervision volume)의 해상도를 점진적으로 높입니다. Figure 2에 개략적으로 나타낸 이러한 coarse-to-fine 감독 기법은, 각 단계 후에 더 정확한 추정을 가능하게 합니다. 우리는 이 방식이 단순히 더 많은 구성 요소를 무작정 쌓는 것보다 우수함을 실험적으로 입증합니다.
우리의 제안 기법은 표준 벤치마크에서 최신(state-of-the-art) 성능을 달성하며, ConvNet의 2D 출력을 후처리하는 ConvNet-only 방식이나 하이브리드 방식보다 더 우수한 성능을 보입니다. 추가적으로, 2D 관절 위치 추정과 3D 관절 복원을 분리하는 구조에서 우리의 볼류메트릭 표현을 활용하는 연구도 진행합니다. 구체적으로, 우리는 두 개의 독립적인 네트워크(한 네트워크의 출력을 다른 네트워크의 입력으로 활용)를 사용하고, 서로 대응되지 않는 두 개의 데이터 소스(예: 첫 번째 구성 요소 학습을 위한 2D 라벨링 이미지, 그리고 별도로 두 번째 구성 요소 학습을 위한 독립적인 3D 데이터 소스(MoCap 등))를 이용합니다. 이러한 구조가 (예: 실제 환경(in-the-wild) 이미지에서 3D 포즈 예측) 같은 실용적인 이점을 갖추고 있으나, 대응되는 3D 정답(groundtruth)이 있는 이미지로 학습할 수 있는 경우, 엔드투엔드 방식에 비해 성능이 떨어진다는 점을 우리는 실험적으로 확인했습니다. 이 결과는 2D 관절 위치 추정을 중간 단계로 활용하기보다, 가능한 한 이미지로부터 3D 포즈를 직접 예측하는 것의 이점을 다시금 강조합니다.
요약하자면, 우리는 다음 네 가지 기여를 제시합니다:
- 엔드투엔드 학습 패러다임을 활용하여, 3D 인간 포즈 추정을 voxel 공간에서의 3D 키포인트 위치 찾기 문제로 정의한 최초의 연구입니다.
- 리의 표현에서 발생하는 대규모 차원 문제를 해결하고, 반복적 처리를 통한 추가적 이점을 제공하기 위해 coarse-to-fine 예측 기법을 제안합니다.
- 제안한 기법은 2D 포즈 추정에 ConvNet을 사용하는 ConvNet-only 방식과 하이브리드 방식 모두를 능가하며, 표준 벤치마크에서 평균 30% 이상 상대 오류(relative error)를 줄이는 최신 성능(state-of-the-art) 을 달성합니다.
- 엔드투엔드 학습이 불가능한 상황에서도 우리의 볼류메트릭 표현이 실용적으로 활용될 수 있음을 보이고, 실제 환경(in-the-wild) 이미지에 대해서도 유의미한 결과를 제시합니다.
2. Related work
3D 인간 포즈 추정에 관한 연구는 매우 방대하여 다양한 환경에서 문제를 다루는 여러 기법들이 존재합니다. 이 장에서는 ConvNet 기반 접근법에 초점을 맞추어, 우리 연구와 가장 밀접한 관련이 있는 작업들을 살펴보고자 합니다. 보다 포괄적인 문헌 검토를 위해서는 최근 서베이 논문 [29]를 참고하시기 바랍니다.
최근의 ConvNet-only 접근법 대부분은 3D 포즈 추정을 좌표 회귀(coordinate regression) 문제로 정의하며, 목표 출력은 골반(pelvis) 같은 알려진 루트 관절을 기준으로 한 인체 관절의 공간적 x, y, z 좌표입니다. Li와 Chan [19]은 2D 관절 분류 맵을 사용하여 네트워크를 사전 학습(pretrain)합니다. Tekin 등 [35]은 사전 학습된 오토인코더(autoencoder)를 네트워크 내부에 포함시켜, 출력에 대한 구조적 제약을 부과합니다. Ghezelghieh 등 [13]은 시점(viewpoint) 예측을 보조 과제로 활용하여, 네트워크에 전역 관절 구성 정보를 제공합니다. Zhou 등 [44]는 회귀된 포즈의 타당성을 보장하기 위해 운동학(kinematic) 모델을 삽입합니다. Park 등 [22]은 2D 관절 예측 결과를 이미지 특징과 연결(concatenate)하여 3D 관절 위치 추정을 향상시킵니다. Tekin 등 [36]은 연속된 프레임에서 시공간(spatiotemporal) 특징을 추출하여, 관절 예측에 시간 정보를 추가합니다. 위와 같은 방법들과 달리, 우리는 인체 포즈를 볼류메트릭(volumetric) 형태로 표현하고, 각 관절마다 voxel 단위 확률(likelihood)을 별도로 회귀합니다. 이는 네트워크 성능 면에서 상당한 이점을 제공하며, 관절 좌표의 저차원 벡터를 사용하는 방식보다 훨씬 풍부한 출력을 제공합니다.
Li 등 [20]은 고전적 회귀 패러다임에 대한 대안적 접근법을 제안합니다. 학습 과정에서, 이들은 컬러 이미지와 3D 포즈 사이의 공통 임베딩(embedding)을 학습합니다. 테스트 시에는, 테스트 이미지를 각 후보 포즈와 결합하여 네트워크에 입력하고, 네트워크 스코어가 가장 높은 후보 포즈가 해당 입력 이미지에 할당됩니다. 이는 일종의 최근접 이웃(nearest neighbor) 분류 방식으로, 여러 번의 네트워크 순방향(forward) 연산이 필요하기 때문에 매우 비효율적입니다. 한편, Rogez와 Schmid [27]은 포즈 추정을 분류(classification) 문제로 간주합니다. 미리 정의된 포즈 클래스 집합이 주어지면, 각 이미지는 가장 높은 스코어를 갖는 클래스에 할당됩니다. 이는 유효한 전역 포즈 예측을 보장하지만, 원본 클래스에 속한 포즈들로 한정되므로 대략적인 포즈 추정치만을 제공합니다. 비효율적인 최근접 이웃 접근법 및 거친(coarse) 분류 접근법과 달리, 우리의 볼륨 회귀(volume regression)는 더 정확한 3D 관절 위치 추정을 가능하게 하면서도 효율적입니다.
엔드투엔드 학습에 대한 관심에도 불구하고, ConvNet-only 접근법들은 관절의 2D 위치를 찾기 위해 ConvNet을 사용하고, 뒤이은 최적화 단계를 통해 3D 포즈를 생성하는 방식보다 성능이 낮습니다. Zhou 등 [45]은 표준 2D 포즈 ConvNet으로 관절을 찾은 뒤, 일련의 단안(monocular) 이미지에 대해 최적화 기법을 적용하여 3D 포즈를 복원합니다. 이와 유사하게, Du 등 [10]은 인체의 높이맵(height-map)을 추가하여 2D 관절 위치 추정을 개선합니다. Bogo 등 [6]은 2D ConvNet이 예측한 관절을 기반으로 통계적 신체 형상 모델(statistical body shape model)을 맞춤(fit)으로써 인체 전체 형상을 복원합니다. 반면, 우리의 접근법은 단일 네트워크만으로 최신 성능(state-of-the-art) 을 달성합니다. 또한, 팔다리 길이에 제약을 가하기 위한 pictorial structures 최적화나 시간적 필터링(temporal filtering) 같은 후처리에 용이한 풍부한 3D 출력을 제공합니다.
3D 인간 포즈에 ConvNet을 적용하는 맥락에서 제기되는 또 다른 문제는 학습 데이터가 부족하다는 점입니다. Chen 등 [9]은 그래픽 렌더러를 이용하여 실제 정답(groundtruth)이 알려진 이미지를 생성합니다. 마찬가지로, Ghezelghieh 등 [13]은 합성된 예시(synthesized examples)를 이용해 학습 세트를 확장합니다. Rogez와 Schmid [27]은 실제 환경(in-the-wild) 이미지의 일부 요소들을 결합하여, 3D 포즈가 알려진 추가 이미지를 생성하는 콜라주(collage) 기법을 제안합니다. 하지만 이러한 합성 예시의 통계적 특성이 실제 이미지와 일치한다는 보장은 없습니다. 이러한 데이터 부족 문제를 살펴보기 위해, 우리는 3D Interpreter Network [41]에서 아이디어를 얻었습니다. 이 네트워크는 3D 포즈 추정 작업을 단일 ConvNet 내에서 2D 위치 추정과 3D 복원으로 분리합니다. 반면, 우리는 미리 정의된 선형 기저(linear basis)를 사용하지 않고, 우리의 볼류메트릭 표현을 통해 3D 관절 위치를 직접 예측합니다. 이는 엔드투엔드 학습이 불가능한 상황에서도 우리 볼류메트릭 표현이 실용적으로 활용될 수 있음을 보여줍니다.
마지막으로, 우리는 다중 뷰(multi-view) 포즈 추정 연구([12, 31, 4, 11] 등)와 명시적으로 비교하지는 않지만, 이산화된 3D 공간에서 3D 인간 포즈를 표현하는 방식이 이전에도 다중 뷰 환경([7, 15, 23] 등)에서 사용되었다는 점은 흥미롭습니다. 이때는 서로 다른 시점(viewpoint)에서의 예측을 수용하기 위해 적용되었습니다. 단일 뷰 포즈 추정 관점에서, 이는 랜덤 포레스트(random forests) [16] 접근법 맥락에서도 고려된 적이 있는데, 이 방식은 약 3분 정도의 긴 실행 시간이 소요되었으며, pictorial structures 모델을 이용한 추가 정제(refinement) 단계가 필요했습니다.
이에 반해, 우리 네트워크는 단일 순방향(forward) 연산만으로 수 밀리초 이내에 전체 볼륨 예측을 수행할 수 있으며, (물론 여전히 적용할 수는 있지만) 추가 정제 단계 없이도 최신 성능(state-of-the-art) 을 달성합니다. 또한, 과도한 차원 문제를 해결하기 위해 coarse-to-fine 예측 기법과 결합되어 있습니다.
3. Technical approach
다음 소절들은 우리의 기술적 접근법을 요약합니다. Section 3.1에서는 제안된 3D 인간 포즈 볼류메트릭 표현과 그 장점에 대해 설명합니다. 이어서, Section 3.2에서는 출력 표현의 높은 차원성을 해결하기 위한 우리의 coarse-to-fine 예측 기법을 다룹니다. 마지막으로, Section 3.3에서는 우리의 볼류메트릭 표현을, 분리된( decoupled ) 구조에서 어떻게 활용하는지와, 이를 우리가 제시한 coarse-to-fine 볼류메트릭 예측 방식과 비교했을 때의 상대적 장점에 관해 논의합니다.
3.1. Volumetric representation for 3D human pose
ConvNet을 활용한 3D 인간 포즈 추정 문제는 주로 좌표 회귀(coordinate regression) 방식으로 접근되어 왔습니다. 이 경우, 네트워크의 목표 출력은 인체의 $N$개 관절에 대한 $x, y, z$ 좌표를 이어 붙인, $3N$ 차원의 벡터입니다. 학습 시에는 $\mathcal{L}_2$ 회귀 손실이 사용됩니다:
\[\mathcal{L} = \sum_{n=1}^N\Vert x^n_{gt}-x^n_{pr}\Vert_2^2 \tag{1}\]여기서 $x_{gt}^n$ 은 실제 정답(groundtruth), $x_{pr}^n$ 은 관절 $n$에 대한 예측 위치입니다. 각 관절의 위치는 루트 관절을 기준으로 전역(global) 좌표로 표현하거나, 운동학적 트리(kinematic tree)에서 상위 관절(parent joint)을 기준으로 국소(local) 좌표로 표현할 수 있습니다. 두 번째 방식은 Li 등 [19]에서도 논의된 것처럼(예: 작은 지역적 편차를 학습하기가 더 수월함), 일부 장점을 가지지만, 작은 오차가 운동학적 트리의 자식 관절로 위계적으로 확산될 수 있다는 문제를 여전히 안고 있습니다. 전반적으로, 이 좌표 회귀 방식은 단순함에도 불구하고 문제를 매우 비선형적으로 만들며, 학습 과정에 여러 문제를 야기합니다. 이러한 문제들은 2D 인간 포즈 연구 [37, 24]에서도 이미 지적된 바 있습니다.
학습 성능을 향상하기 위해, 우리는 3D 인간 포즈를 위한 볼류메트릭(volumetric) 표현을 제안합니다. 피사체 주변 공간을 각 차원별로 균일하게 이산화(discretized)합니다. 각 관절마다 $w×h×d$ 크기의 볼륨을 생성하고, 관절 $n$이 $(i,j,k)$ 위치에 존재할 확률(likelihood)을 예측한 값을 $p^n_{(i,j,k)}$라고 합시다. 이 네트워크를 학습시키기 위해서는 감독(supervision) 역시 볼류메트릭 형태로 제공됩니다. 각 관절의 목표(target)는, 3D 격자상에서 관절의 실제 위치 $x_{gt}^=(x,y,z)$ 를 중심으로 하는 3D 가우시안(3D Gaussian)이 들어 있는 볼륨입니다:
여기서 실험에서는 $σ=2$ 값을 사용합니다. 학습 시에는 평균제곱오차(mean squared error) 손실을 적용합니다:
\[\mathcal{L}=\sum_{n=1}^N\sum_{i,j,k}\Vert G_{(i,j,k)}(x^n_{gt})-p^n_{(i,j,k,)}\Vert \tag{3}\]이론적으로 네트워크 출력은 $(w×h×d×N)$ 형태의 4차원이 되지만, 실제 구현에서는 이를 채널 방식으로 구성하므로, 우리의 출력은 $w×h×dN$ 형태의 3차원이 됩니다. 각 3D 격자에서 응답(response)이 가장 큰 voxel을 해당 관절의 3D 위치로 선택합니다.
볼류메트릭 표현의 큰 장점 중 하나는, 직접적인 3D 좌표 회귀라는 매우 비선형적인 문제를 이산화된 공간에서 다루기 수월한 예측 형태로 전환한다는 점입니다. 이 경우, 예측 과정에서 각 관절의 위치를 단 하나로 확정하는 대신, 각 voxel에 대한 신뢰도(confidence) 값을 제공하므로, 네트워크가 목표 매핑을 학습하기가 더 용이해집니다. 이와 유사한 주장이 2D 포즈 문제에서도 이미 제시되어, 픽셀 좌표 대신 픽셀 단위 확률을 예측하는 것이 유리함을 입증한 바 있습니다 [37, 24]. 네트워크 구조 관점에서, 볼류메트릭 표현의 중요한 이점은 예측을 위해 전합성곱(fully convolutional) 네트워크를 활용할 수 있다는 것입니다. 여기서 우리는 hourglass 설계 [21]를 채택했습니다. 이는 좌표 회귀나 포즈 분류를 위한 완전연결(fully connected) 계층을 사용하는 것보다 더 적은 수의 네트워크 파라미터를 요구합니다. 마지막으로 예측된 출력 측면에서, 밀집 3D 히트맵(dense 3D heatmaps) 형태의 우리 네트워크 예측은 정확도가 높을 뿐 아니라, 이후 후처리 단계에도 유용하게 활용됩니다. 예를 들어, [7, 23]과 같은 3D Pictorial Structures 모델을 사용하여 구조적 제약을 부과할 수 있습니다. 또 다른 방법으로는, 여러 입력 프레임이 사용 가능한 상황에서 필터링(framework) 기법에 이 밀집 예측을 활용할 수도 있습니다.
3.2. Coarse-to-fine prediction
2D 인간 포즈의 경우에 특히 효과적이었던 설계 선택(design choice) 중 하나는 네트워크 출력에 대한 반복적(iterative) 처리를 적용하는 것입니다 [8, 40, 21]. 단일 구성 요소에서 단일 출력을 내는 대신, 네트워크가 여러 처리 단계를 거쳐 예측을 수행하도록 강제됩니다. 이 중간 예측(intermediate predictions)은 점차 정제되어 더 정확한 추정치를 만들어냅니다. 또한, 초기 단계의 출력에 중간(intermediate) 감독(supervision)을 적용하면 더 풍부한 그라디언트 신호가 제공되는데, 이는 [17, 34]에서 실험적으로 효과적인 학습 방식임이 입증되었습니다.
2D 포즈 맥락에서 반복적 정제(iterative refinement)가 성공을 거둔 점에 영감을 받아, 우리는 점진적인 정제 기법(gradual refinement scheme)도 고려합니다. 실험적으로 보았을 때, 여러 구성 요소를 단순히 나열해 쌓는 방식은 우리의 표현이 갖는 높은 차원성 때문에 점차 효용이 감소함을 발견했습니다. 실제로, 관절이 16개이고 3D 해상도가 $64×64×64$인 경우, 400만 개 이상의 voxel에 대해 확률(likelihood)을 추정해야 합니다. 이러한 차원의 저주(curse of dimensionality)를 해결하기 위해, 우리는 coarse-to-fine 예측 기법을 제안합니다. 구체적으로, 초기 단계에서는 가장 난이도가 높고(기술적으로 관측하기 어려운) z 차원에 대해, 해상도가 더 낮은 형태의 목표(target)를 사용하여 감독을 수행합니다. 정확히는, 각 관절마다 $64×64×d$ 크기의 타깃을 사용하며, $d$는 일반적으로 $\lbrace 1,2,4,8,16,32,64\rbrace$ 중 하나를 취합니다. 이 감독 기법을 나타낸 예시가 Figure 2에 제시되어 있습니다.
이러한 전략은 학습 효율을 높여주며, 여러 구성 요소를 한 번에 쌓아도 과적합(overfitting)이나 차원 문제로 인한 성능 저하 없이 그 장점을 누릴 수 있게 합니다. 직관적으로, 초기 처리 단계에서는 더 쉬운 형태의 과업이 네트워크에 주어지고, 복잡도는 점차적으로 증가합니다. 이는 모든 사용 가능한 정보가 처리되고 통합되는 맨 마지막 단계까지 어려운 의사결정을 미루도록 하여, 최종 추론을 더 효과적으로 수행할 수 있게 합니다.
3.3. Decoupled architecture with volumetric target
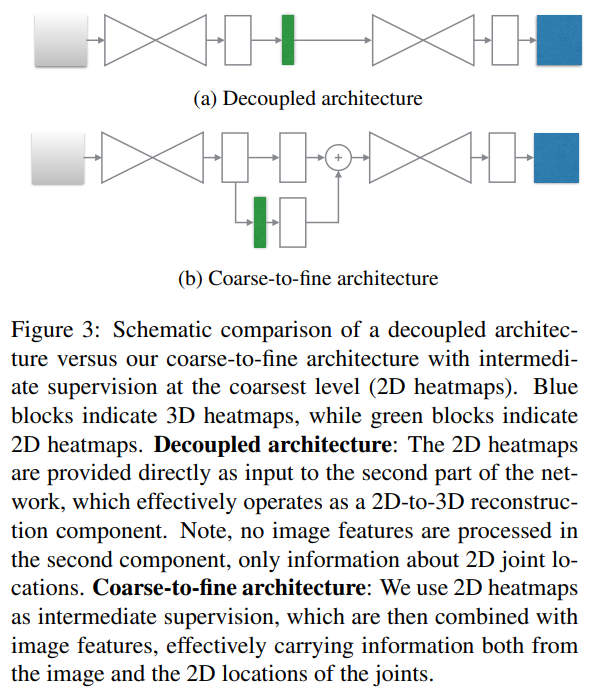
제안된 볼류메트릭 표현의 다재다능함을 더욱 입증하기 위해, 우리는 엔드투엔드(end-to-end) 학습이 불가능한 시나리오에서도 이를 활용합니다. 이는 일반적으로 실제 환경(in-the-wild) 이미지에서 주로 발생하는 상황으로, 3D 정답(groundtruth)을 대규모로 정확하게 수집하기가 어려운 경우입니다. 3D Interpreter Network [41]에서 영감을 받아, 우리는 3D 포즈 추정을 두 단계로 분리(decouple)합니다. 첫 번째는 2D 키포인트 히트맵을 예측하고, 이어서 우리의 볼류메트릭 표현을 사용하여 3D 관절 위치를 추론하는 순서입니다. 첫 번째 단계는 실제 환경 이미지를 2D 라벨링한 데이터로 학습할 수 있으며, 두 번째 단계는 오직 3D 데이터(예: MoCap)만 필요합니다. 이 각각의 데이터 소스는 독립적으로 풍부하게 구할 수 있습니다.
이러한 학습 전략은 실제 적용 사례에서 유용하며, 실제 환경 이미지에 대한 흥미로운 결과를 도출합니다(Section 4.6 참고). 하지만, 학습에 사용할 수 있는 대응 3D 정답이 존재하는 경우에는 엔드투엔드 방식보다 최적의 해법이 아닙니다. Figure 3은 두 개의 hourglass 블록을 사용하는 단순화된 구조에서 각각의 아키텍처를 도식적으로 비교해 보여줍니다. 중간 감독의 해상도를 $d=1$로 설정하여 2D 히트맵이 만들어지는 경우, 분리된(decoupled) 구조가 우리 coarse-to-fine 아키텍처와 유사함을 확인할 수 있습니다. 두 아키텍처 간 결정적인 차이는, 우리 coarse-to-fine 접근법이 생성된 2D 히트맵을 중간 이미지 특징(intermediate image features)과 결합한다는 점입니다. 이를 통해 네트워크의 나머지 부분은 이미지 자체와 2D 관절 위치에 대한 정보를 동시에 처리할 수 있습니다. 반면, 분리된 네트워크는 2D 히트맵을 직접 활용해 3D 위치를 복원하려고 시도할 뿐, 이미지 기반 근거(image-based evidence)는 추가로 사용하지 않습니다. 2D 히트맵이 크게 잘못된 경우, 3D 예측이 쉽게 엇나갈 수 있습니다. Section 4.4에서는, 대응되는 3D 정답을 가진 이미지가 존재할 때, 우리가 제안한 coarse-to-fine 아키텍처가 분리된 아키텍처보다 더 뛰어난 성능을 보인다는 사실을 실험적으로 보입니다.
4. Empirical evaluation
4.1. Datasets
우리는 3D 인간 포즈를 위한 표준 벤치마크 세 가지(Human3.6M [14], HumanEva-I [30], KTH Football II [15])에서, 우리 coarse-to-fine 볼류메트릭 접근법의 광범위한 정량적 평가 결과를 제시합니다. 또한 3D 정답(groundtruth)이 없는 MPII 인간 포즈 데이터셋 [2]에 대해서는 정성적(qualitative) 결과를 제공합니다.
Human3.6M
11명의 피험자(subject)가 “Walking”, “Sitting”, “Phoning” 등의 다양한 동작을 수행하는 영상을 포함합니다. 우리는 기존 연구 [20, 45]와 동일한 평가 프로토콜을 따릅니다. 구체적으로, S1, S5, S6, S7, S8 피험자를 학습에 사용했고, S9와 S11 피험자를 테스트에 사용했습니다. 원본 비디오는 초당 50프레임에서 10프레임으로 다운샘플링했습니다. 모든 카메라 뷰를 활용하였으며, 동작별 모델을 따로 학습하는 대신 [20, 45], 모든 동작에 대해 하나의 모델을 학습하였습니다.
HumanEva-I
Human3.6M에 비해 더 적은 피험자 수와 동작 수를 가진 소규모 데이터셋입니다. 표준 프로토콜 [16, 42]에 따라, S1, S2, S3 피험자의 “Walking”과 “Jogging”에 대해 평가를 진행했습니다. 이들 피험자와 동작의 학습 시퀀스는 학습에, 해당 검증(Validation) 시퀀스는 테스트에 사용했습니다. Human3.6M 평가와 마찬가지로, 모든 사용자와 동작의 프레임을 활용해 단일 모델을 학습합니다.
KTH Football II$
이 이미지들은 프로 축구 경기 영상에서 가져온 것이며, 이 중 극히 일부에 대해서만 3D 정답(groundtruth)이 제공됩니다. 제공되는 소량의 정답 역시 여러 시점(view)에서 얻은 수동 2D 주석을 결합하여 생성된 것이므로, 정확도가 높지 않습니다. 이러한 상황에서는 이미지-기반에서 직접 3D로 학습하기가 현실적으로 어렵습니다. 대신, Section 3.3에서 설명한 분리된(decoupled) 아키텍처 내에서 우리의 볼류메트릭 표현을 적용하여 얻은 결과를 보고합니다. 구체적으로는, 첫 번째 네트워크 구성요소(이미지를 2D 히트맵으로 변환)를 이 데이터셋의 이미지로 학습하되, 이는 2D 정답을 제공하기 때문에 가능합니다. 두 번째 네트워크 구성요소(2D 히트맵에서 3D 히트맵으로 변환)는 Human3.6M 데이터셋의 모든 MoCap 학습 데이터를 사용합니다. 다른 연구 [7, 36]들과 마찬가지로, “Player 2”의 “Sequence 1”과 “Camera 1”에서 추출된 프레임에 대한 결과를 보고합니다.
MPII
실제 환경(in-the-wild) 이미지를 포함한 대규모 2D 포즈 데이터셋으로, 2D 주석은 제공되지만 3D 정답은 없습니다. KTH와 마찬가지로, 이 데이터셋만으로는 이미지에서 직접 3D로 학습하기가 현실적이지 않습니다. 따라서, 우리는 분리된(decoupled) 아키텍처와 우리의 볼류메트릭 표현을 활용했습니다. 이 경우 정량적 성능 평가가 불가능하므로, 오직 정성적 결과만 제시합니다.
4.2. Evaluation metrics
Human3.6M의 경우, 대부분의 기법들은 per joint 3D error를 보고하는데, 이는 추정된 관절과 실제 정답(groundtruth) 관절 간의 평균 유클리드 거리를 의미합니다. 이는 추정된 3D 포즈와 실제 3D 포즈 간에 루트 관절(여기서는 골반)을 정렬한 뒤 계산됩니다. Human3.6M과 HumanEva-I에 대한 결과를 보고하기 위해 일부 기법들이 사용하는 대안적 지표로는 reconstruction error가 있습니다. 이는 유사 변환(similarity transformation)을 고려했을 때의 관절별 3D 오차로 정의됩니다. 즉, 추정된 3D 포즈를 Procrustes 기법을 통해 실제 포즈에 맞춰 정렬한 뒤 오차를 측정하는 방식입니다. 마지막으로, KTH 데이터셋의 경우에는 추정된 관절 중 3D에서 올바르게 예측된 부분의 비율, 즉 3D PCP [7]가 보고됩니다. 이때도 마찬가지로, 뎁스(depth) 애매성을 해소하기 위해 루트 관절(여기서는 가슴 중심)을 정렬하여 평가합니다.
4.3. Implementation details
우리의 볼류메트릭 공간에서, x-y 격자는 이미지 내의 2D 경계 상자를 균일하게 이산화(discretization)한 것이고, z 격자는 루트 관절을 중심으로 [−1,1] 범위(미터 단위)를 균일하게 이산화한 것입니다. 이는 각 관절에 대한 이미지 좌표와, 루트 관절 기준으로 측정한 거리(깊이)를 함께 예측한다는 의미입니다. 루트 관절의 깊이값이 주어지면, 각 관절의 절대 깊이와 x-y 차원 상의 거리 단위(metric) 좌표를 복원할 수 있습니다. 구성 요소 분석(Section 4.4)에서는 루트 관절의 실제 정답(groundtruth) 깊이를 사용하고, 다른 방법들과의 비교(Section 4.5)에서는 각 데이터셋의 평균 골격 크기를 기반으로 이 깊이를 추정합니다. 더 자세한 내용은 보충 자료(supplementary material)에 수록되어 있습니다.
네트워크 구조 관점에서, Figure 2에 나타낸 전합성곱(fully convolutional) 구성 요소는 hourglass 설계 [21]에 기반하고 있습니다. 우리는 공개된 코드를 사용해 이 구조를 충실히 재현하였습니다. 마찬가지로, 회전 증강($±30^\circ$), 스케일 증강(0.75–1.25배), 좌우 뒤집기(left-right flipping) 등의 동일한 학습 기법을 적용하고, 배치 크기가 4인 상태에서 rmsprop으로 최적화하며, 학습률은 $2.5×10^{−4}$ 로 설정했습니다.
각 개별 데이터셋의 학습과 관련하여, Human3.6M의 경우 네트워크 모델을 처음부터(scratch) 학습하며, 일반적으로 4에폭(대략 31만 번의 반복) 정도 수행합니다. HumanEva-I에서는 학습 세트 크기가 상당히 작기 때문에, 모델을 처음부터 학습하여 120에폭(대략 23만5천 번의 반복)을 진행합니다. 마지막으로, KTH에서의 2D 관절 위치 추정 네트워크는 MPII로 사전에 학습된(stacked hourglass) 공개 모델 [21]을 활용하고, 20에폭(약 3만 번의 반복) 정도 파인튜닝(fine-tuning)합니다.
4.4. Component evaluation
우리의 접근법에 포함된 각 구성 요소를 평가하기 위해, 가장 포괄적인 벤치마크로 알려진 Human3.6M 데이터셋을 사용하여 결과를 보고합니다.
Volumetric representation
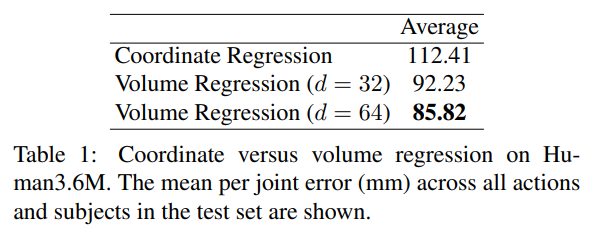
우리의 첫 번째 목표는, 이산화(discretized)된 공간에서의 회귀(regression)가 좌표 회귀보다 큰 이점을 제공함을 보이는 것입니다. 두 방식 모두 단일 hourglass를 사용하는 가장 간단한 설정으로 구현했습니다. 두 아키텍처의 유일한 차이는, 볼류메트릭 예측을 위한 네트워크는 완전히 합성곱 계층(fully convolutional)으로만 구성되고, 좌표 회귀의 경우 네트워크 마지막에 완전연결층(fully connected layer)을 사용한다는 점입니다. 결과는 Table 1에 제시했습니다. 좌표 회귀의 경우 112.41mm라는 오류값이 나오며, 이는 최근 보고된 좌표 회귀 기반 결과 [19, 35, 22, 44]와 유사한 수준입니다. 반면, 볼류메트릭 출력 타깃을 사용할 경우 가장 높은 깊이 해상도 설정에서 오차가 85.82mm까지 크게 감소함을 확인했습니다.
Coarse-to-fine prediction
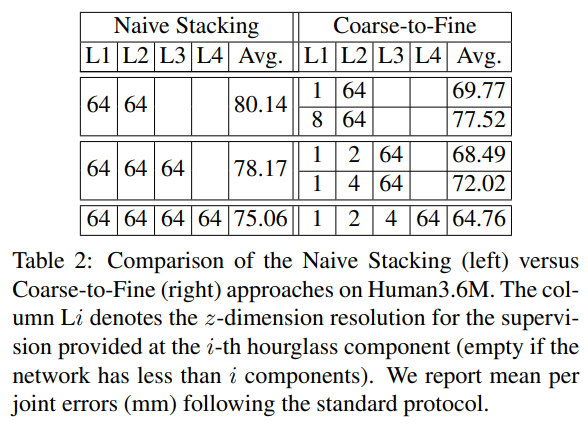
우리의 네트워크에 대한 또 다른 중요한 개선점은, 이미지 특징에 대한 반복적(iterative) 처리 과정입니다. 가장 단순한 방법은 여러 hourglass를 겹쳐 쌓는 것인데, 이는 도움이 되지만, Table 2(나이브 스태킹, Naive stacking)에 나타나 있듯이, 점차 성능이 감소합니다.. 반면, 우리의 coarse-to-fine 감독(supervision) 방식은 hourglass를 2개, 3개, 4개 사용했을 때(각각 Table 2, Coarse-to-Fine 참조), 나이브 방식보다 더 높은 성능을 보입니다. 실제로 hourglass를 2개만 사용한 우리의 coarse-to-fine 버전(오차 69.77mm)은, hourglass를 4개 쌓은 나이브 스태킹 네트워크(오차 75.06mm)보다 더 우수한 성능을 내는데, 이는 더 깊은 네트워크 대비 절반 미만의 파라미터를 사용함에도 불구하고 달성된 결과입니다.
Decoupled network with volumetric representation
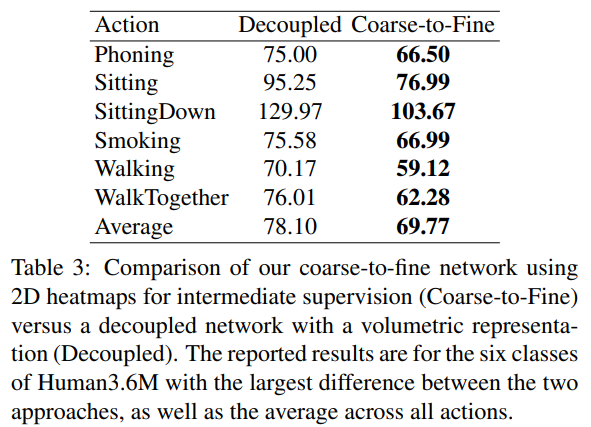
볼류메트릭 표현을 결합한 분리된(decoupled) 네트워크: 우리는 Section 3.3에서 설명한 대로, 볼류메트릭 표현과 결합된 분리된 네트워크의 사용을 연구합니다. 우리의 목표는 2D 위치를 중간 표현으로 사용하는 대신, 이미지 특징으로부터 직접 3D 포즈를 예측하는 방식이 갖는 이점을 입증하는 것입니다. 두 가지 관련 네트워크를 개략적으로 나타낸 도식은 Figure 3에서 다시 확인할 수 있습니다. 우리는 두 네트워크 모두를 엔드투엔드(end-to-end)로 학습시켜, 엔드투엔드 학습의 이점이 아니라 네트워크 구조 자체의 성능을 평가합니다. (실제로, 분리된 네트워크의 두 구성 요소를 독립적으로 학습하면 성능이 떨어지는 것으로 확인되었습니다.) 비교 결과는 Table 3에 제시되어 있습니다. 우리는 모든 동작에 대한 평균과 함께, 두 네트워크 간 편차가 가장 큰 여섯 가지 동작에 대한 결과도 제공합니다. 모든 동작, 그리고 전체 평균에서도 더 정확할 뿐 아니라, 우리의 coarse-to-fine 방식은 “Sitting”이나 “Sitting Down”같이 난이도가 높은 동작에서 특히 큰 개선폭을 보입니다. 이 경우, 심한 자가 가림(self-occlusion)으로 인해 2D 관절 위치 추정이 자주 실패하여, 두 번째 하위 네트워크에는 부정확한 2D 히트맵이 전달됩니다. 이미지 특징도 함께 처리하지 않으면, 3D 위치 추정은 실패할 수밖에 없습니다. 이는 3D 위치 추정을 위해 이미지 정보를 직접 활용하는 것이, 과정을 분리하는 방안에 비해 얼마나 큰 이점을 제공하는지를 보여줍니다.
4.5. Comparison with state-of-the-art
Human3.6M
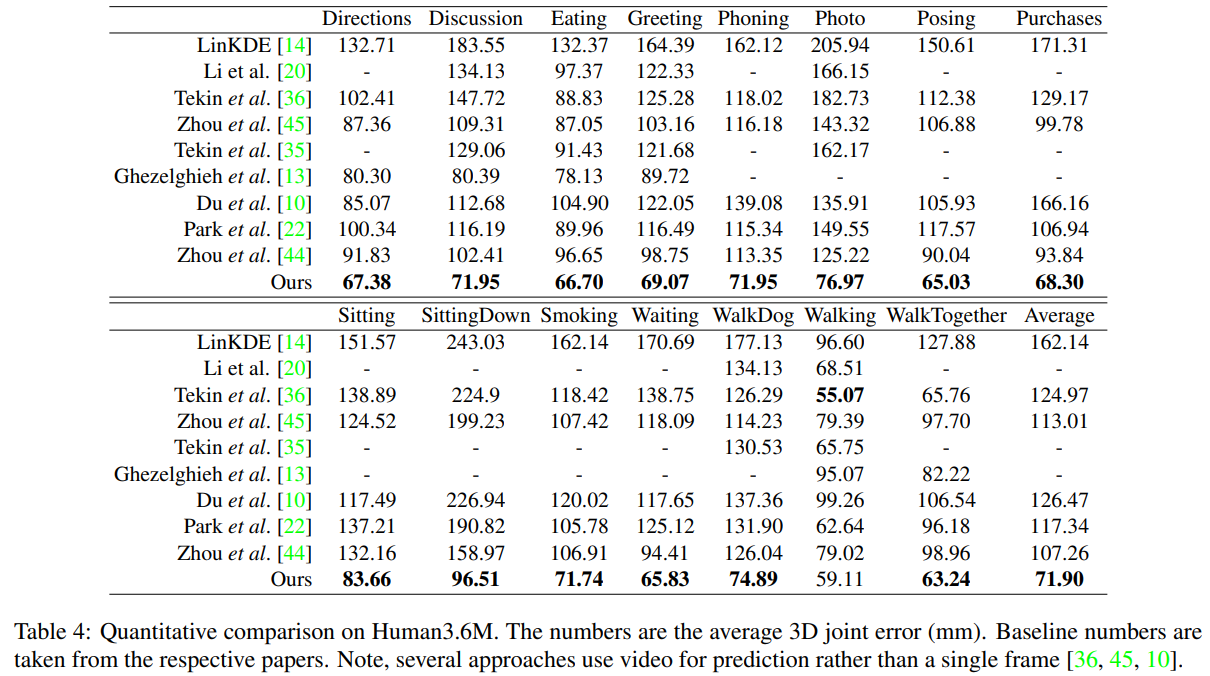

우리는 Human3.6M에서 보고된 기존 결과와 우리의 접근법을 비교합니다. Table 4는 관절별 평균 3D 오차를 제시합니다. 참고로, 일부 선행 연구 [36, 45, 10]는 단일 프레임이 아닌 연속된 프레임 시퀀스를 이용해 포즈를 예측한다는 점이 다릅니다. 그럼에도 불구하고, 우리 네트워크는 대부분의 동작에서 최신 성능(state-of-the-art) 을 달성하고, 평균적으로도 다른 모든 기법을 능가합니다. 일부 연구들은 결과를 보고할 때 reconstruction error를 사용하므로, 우리도 Table 5에서 이 지표로 평가를 수행했습니다. 이 경우에도, 우리 접근법은 다른 기준 기법 대비 큰 차이로 우수한 성능을 보입니다.
HumanEva-I
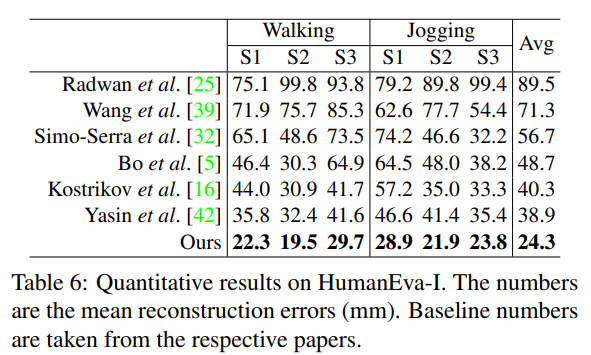
HumanEva-I에 대한 우리의 실험 결과는 Table 6에 제시되어 있으며, 최신 기법들의 결과와 함께 비교합니다. Human3.6M과 마찬가지로, 우리 네트워크는 공개된 다른 모든 기법을 상회합니다.
KTH Football II
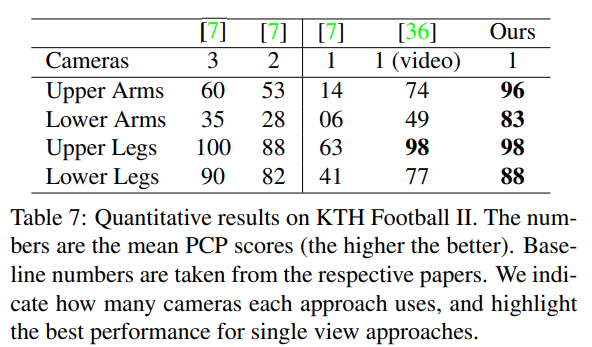
이 데이터셋에 대한 우리의 접근법 결과는 Table 7에 제시되며, 관련 기법들과 비교하였습니다. 참고로 Tekin 등 [36]은 단일 프레임이 아닌 동영상을 이용해 예측하고, Burenius 등 [7]은 멀티뷰(multi-view) 방식입니다. 그럼에도 불구하고, 우리는 단일 뷰 접근법 중 최고 성능을 달성하고, 멀티뷰 결과와도 경쟁할 만한 수준입니다.
4.6. Qualitative results

Figure 4는 앞서 언급한 데이터셋에서 가져온 이미지들에 대한 정성적(qualitative) 결과를 보여줍니다. 또한 실제 환경(in-the-wild)의 특성으로 인해 시각적 다양성이 큰 MPII 데이터셋에 대해서도 3D 재구성을 시연합니다. MPII 예시에는 난이도 높은 포즈들이 포함되어 있음에도 불구하고, 우리의 볼류메트릭 표현은 설득력 있는 3D 예측을 만들어냅니다.
5. Summary
본 논문은 단일 컬러 이미지로부터 3D 인간 포즈를 추정하는 까다로운 문제를 다루었습니다. 최근의 ConvNet 기반 접근법과 달리, 우리는 피사체 주변의 이산화된(discretized) 공간에서 3D 키포인트를 찾는 문제로 이를 정의했습니다. 우리는 이 볼류메트릭 표현을 coarse-to-fine 감독(supervision) 방식과 결합하여, 높은 차원 문제를 해결하고 반복적 처리를 가능케 했습니다. 그 결과, 표준 벤치마크에서 평균적으로 30%를 초과하는 상대적 오류 감소를 달성하며, 최신 성능(state-of-the-art) 을 얻는 데 우리의 기여들이 결정적인 역할을 했음을 입증했습니다. 나아가 우리는 분리된(decoupled) 구조 내에서도 볼류메트릭 표현을 활용함으로써, 엔드투엔드 학습이 어려운 상황에서도 실제 환경(in-the-wild) 이미지에 실용적으로 활용할 수 있음을 보였습니다.
Georgios Pavlakos, Xiaowei Zhou, Konstantinos G. Derpanis, Kostas Daniilidis Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose

댓글남기기