

개요
Convolutional Pose Machines는 CVPR 2016에 등장하여 CNN 기반으로 자세 추정의 정확성을 높이는 방법을 제안한다. 이때부터 CNN기반의 다단계 방식을 제공하여 자세 추정 문제의 주요 개선들을 이룬다.
해당 논문에서는 ‘다단계’, ‘점진적’ 등의 키워드로 어떤 단계로 자세 추정의 성능을 개선해나가는지에 대한 방법론에 포인트를 놓으면 좋을 것 같다. 해당 CPM은 기존 ECCV2014에 발표 된 Pose Machines이라는 논문 아키텍쳐에 기반을 두고 있다. 또한 해당 논문에서는 CNN을 사용하여 학습할 때 생기는 기울기 소실(Gradient Vanishing) 문제에 대해서 이를 해결하는 방법도 제안한다.
Convolutional Pose Machine
- 기존 포즈 머신의 목표는 이미지에서 관절의 위치 $Y$ 를 예측하는 것이다. 이를 위해 멀티 클래스 예측기를 이용한다. 처음 단계는 이미지의 특징을 추출하고 이를 다시 입력으로 활용하는데, 이 때 기존 이미지 정보를 같이 활용한다. 그래서 이런 스테이지를 거듭할 때 특정 관절 위치에 대한 예측이 점점 정확해진다.
- 이를 CNN 기반에 다시 적용하여 Convolutional Pose Machine을 설계한다. 아키텍쳐 전체가 미분가능하여 End-to-end 학습이 가능해지며, 첫 단계의 총 7개의 컨볼루션 레이어는 점점 수용 영역을 넓혀가며 이미지 특징을 추출함과 동시에 P+1개의 포즈 신뢰도 맵을 형성한다.
- 두번째 단계부터 이미지의 특징 맵과 예측된 관절의 신뢰도 맵을 활용하여 해당 부위에 대한 예측을 복잡하고 장거리 관절에 대한 상관관계를 학습할 수 있도록하여 성능을 달성한다.
- 이렇게 많은 CNN 레이어를 가진 아키텍쳐는 기울기 소실 문제에 취약할 수 있지만, 해당 아키텍쳐의 순차적 예측 프레임워크는 반복적으로 신뢰도 맵을 생성하고 이를 다시 입력에 사용하기에 이를 반복적으로 정답에 도달하도록 유도하기에 이러한 기울기 소실 문제를 완화할 수 있다.
Experiments
- 기울기 소실 문제를 해결하기위해 네트워크 중간에 손실함수를 적용할 수 있는 intermediate supervision(중간 감독자)를 사용하였다. 그림 5를 보면 해당 중간 감독자가 있고 없음에 따라 그라디언트의 분산이 0 주변으로 급격히 몰리는 것을 볼 수 있다.
- ECCV’14에 나온 Pose Machine과 해당 논문의 CPM 비교 시 압도적인 성능 향상이 있음을 알 수 있다. 이는 기존 Pose Machine의 모듈을 컨볼루션 아키텍쳐로 대체함에서 기인한 것으로 본다.
- 학습에 대해서 4가지 케이스(아래 번역 내용 참조)를 테스트 하였을 때, 중간 감독자를 포함한 스크래치 학습이 제일 성능이 좋았다.
- 1단계 이후의 반복 구조에서 최대 5-6단계 정도에서 최대 성능을 발휘하는 것을 확인했다.
- 벤치마크에 대한 정량 평가는 3개의 데이터셋; MPII, LSP, FLIC에 대해서 테스트한다. Caffe 프레임워크를 사용하였으며 MPII는 PCKh 메트릭, LSP는 PCK 메트릭, FLIC도 PCK 메트릭을 사용하였다.
- MPII에 LSP 데이터를 더해 학습 시 PCKh에 대해서 약간의 성능 향상을 볼 수 있었다.
- LSP에 MPII를 더해 학습 시 PCK에 대해서 큰 성능 향상을 볼 수 있었고 이는 MPII의 라벨 품질이 LSP보다 훨씬 뛰어나기 때문이라 한다.
결론
해당 논문은 CNN 기반의 End-to-end 아키텍쳐를 제시하며, 이를 학습하는 과정에 있어서도 그라디언트 배니싱 문제를 해결하는 방법에 대해서도 제안한다. 특히 강조하고자 하는 특징은 마치 ResNet의 residual을 연상시키는데, 입력 이미지에 대한 정보와 관절 위치에 대한 출력을 다시 입력으로 하여 다음 스테이지에서 사용한다는 것. 이러한 순차 구조와 End-to-end 학습을 가능하게하는 컨볼루션 아키텍쳐를 사용함에 있어 기여했다고 생각한다. 또한 3가지 데이터 셋을 통한 벤치마크를 확인하면서 높은 성능을 달성함을 확인하였다.
번역
Abstract
Pose Machines는 풍부한 암시적 공간 모델을 학습하기 위한 순차적 예측 프레임워크를 제공합니다. 본 논문에서는 이미지 특징과 이미지 의존적 공간 모델을 학습하기 위한 자세 추정 작업에 대해 컨볼루션 신경망을 Pose Machine 프레임워크에 통합하는 체계적인 설계를 제시합니다. 이 논문의 기여는 관절형 자세 추정과 같은 구조화된 예측 작업에서 변수 간의 장기 의존성을 암묵적으로 모델링하는 것입니다. 우리는 이전 단계의 신뢰도 맵(belief maps)에서 직접 작동하는 컨볼루션 신경망으로 구성된 순차적 아키텍처를 설계하여, 명시적인 그래픽 모델 스타일의 추론 없이도 점점 더 정교한 부위 위치 추정치를 생성해내는 방식으로 이를 달성합니다. 우리의 접근 방식은 중간 감독을 강제하는 자연스러운 학습 목표 함수를 제공함으로써 학습 중 사라지는 기울기 문제를 해결하고, 이로 인해 역전파된 기울기를 보충하고 학습 절차를 조절합니다. 우리는 MPII, LSP, FLIC 데이터셋을 포함한 표준 벤치마크에서 최첨단 성능을 입증하고 경쟁 방법들을 능가하는 결과를 보여줍니다.
1. Introduction

우리는 관절형 자세 추정을 위한 Convolutional Pose Machines (CPMs)를 소개합니다. CPMs는 pose machine [29] 아키텍처의 장점인 이미지와 다중 부위 단서 간의 장거리 의존성 암시적 학습, 학습과 추론 간의 긴밀한 통합, 모듈형 순차적 설계를 계승하며, 이들을 컨볼루션 아키텍처가 제공하는 이점과 결합합니다. 데이터로부터 직접 이미지 및 공간 컨텍스트의 특징 표현을 학습할 수 있는 능력; 역전파를 통한 전역적인 공동 학습을 가능하게 하는 미분 가능 아키텍처; 그리고 대규모 학습 데이터셋을 효율적으로 처리할 수 있는 능력.
CPMs는 각 부위의 위치에 대한 2D 신뢰도 맵을 반복적으로 생성하는 컨볼루션 신경망 시퀀스로 구성됩니다. CPM의 각 단계에서 이미지 특징과 이전 단계에서 생성된 신뢰도 맵이 입력으로 사용됩니다. 신뢰도 맵은 다음 단계에 각 부위의 위치에 대한 공간적 불확실성의 표현적 비모수 인코딩을 제공하여, CPM이 부위 간 관계에 대한 풍부한 이미지 의존적 공간 모델을 학습할 수 있게 합니다. 이러한 신뢰도 맵을 그래픽 모델이나 특수 후처리 단계를 사용해 명시적으로 해석하는 대신, 우리는 중간 신뢰도 맵에서 직접 작동하고 부위 간 관계의 암묵적 이미지 의존적 공간 모델을 학습하는 컨볼루션 신경망을 학습합니다. 제안된 다단계 아키텍처는 완전히 미분 가능하며, 따라서 역전파를 사용하여 끝에서 끝으로 학습될 수 있습니다.
CPM의 특정 단계에서는 부위 신뢰도의 공간적 컨텍스트가 다음 단계에 강력한 모호성 해소 단서를 제공합니다. 그 결과, CPM의 각 단계는 각 부위 위치에 대한 점점 더 정교해진 예측을 가진 신뢰도 맵을 생성합니다(그림 1 참조). 부위 간 장거리 상호작용을 포착하기 위해, 우리의 순차적 예측 프레임워크의 각 단계에서 네트워크의 설계는 이미지와 신뢰도 맵 모두에서 큰 수용 영역을 확보하는 것을 목표로 합니다. 실험을 통해, 신뢰도 맵에서 큰 수용 영역이 장거리 공간적 관계를 학습하는 데 중요하며 정확성을 향상시키는 것을 발견했습니다.
CPM에서 여러 컨볼루션 신경망을 구성하면, 학습 중 기울기 소실 문제의 위험이 있는 많은 계층을 가진 전체 네트워크가 됩니다. 이 문제는 역전파된 기울기가 네트워크의 많은 계층을 통과하면서 강도가 약해지기 때문에 발생할 수 있습니다. 최근 연구에서는 중간 계층에서 매우 깊은 네트워크를 감독하는 것이 학습에 도움이 된다는 것을 보여주고 있지만, 이는 대부분 분류 문제로 제한되어 왔습니다. 본 연구에서는 자세 추정과 같은 구조화된 예측 문제에서, CPM이 기울기를 보충하고 네트워크를 주기적으로 중간 감독을 통해 점점 더 정확한 신뢰도 맵을 생성하도록 안내하는 체계적인 프레임워크를 자연스럽게 제시하는 방법을 보여줍니다. 우리는 또한 이러한 순차적 예측 아키텍처의 다양한 훈련 방식을 논의합니다.
우리의 주요 기여는 (a) 컨볼루션 아키텍처의 순차적 구성을 통해 암시적 공간 모델을 학습하는 것과 (b) 그래픽 모델 스타일의 추론 없이 구조화된 예측 작업을 위해 이미지 특징과 이미지 의존적 공간 모델을 학습하도록 이러한 아키텍처를 설계하고 훈련하는 체계적인 접근 방식입니다. 우리는 MPII, LSP, FLIC 데이터셋을 포함한 표준 벤치마크에서 최첨단 결과를 달성했으며, 반복적인 중간 감독으로 다단계 아키텍처를 공동으로 훈련한 효과를 분석합니다.
2. Related Work
관절형 자세 추정의 고전적인 접근 방식은 pictorial structures 모델로, 신체 부위 간의 공간적 상관관계가 연결된 팔다리를 결합하는 운동학적 우선 조건과 함께 트리 구조의 그래픽 모델로 표현됩니다. 이러한 방법들은 사람의 모든 팔다리가 보이는 이미지에서 성공적이었지만, 트리 구조 모델로는 포착되지 않는 변수 간 상관관계 때문에 이미지 증거를 이중으로 계산하는 등의 특성적 오류가 발생하기 쉽습니다. Kiefel 등의 연구는 pictorial structures 모델을 기반으로 하지만, 기저 그래프 표현에서 차이를 보입니다. 계층적 모델은 서로 다른 규모와 크기의 부위 간 관계를 계층적 트리 구조로 나타냅니다. 이러한 모델들의 기본 가정은 더 큰 부위(관절 대신 전체 팔다리에 해당)가 종종 쉽게 감지할 수 있는 판별적 이미지 구조를 가지며, 결과적으로 더 작고 감지하기 어려운 부위의 위치를 추론하는 데 도움을 줄 수 있다는 것입니다. 비트리 모델은 대칭성, 차폐 및 장거리 관계를 포착하는 추가적인 엣지를 통해 트리 구조를 강화하는 루프를 도입하는 상호작용을 포함합니다. 이러한 방법들은 학습과 테스트 시점 모두에서 대개 근사 추론에 의존해야 하며, 따라서 정확한 공간적 관계 모델링과 효율적인 추론을 허용하는 모델 간에 균형을 맞추어야 하며, 종종 빠른 추론을 위해 간단한 파라메트릭 형태로 나타납니다. 반면, 순차적 예측 프레임워크를 기반으로 한 방법들은 변수 간의 잠재적으로 복잡한 상호작용을 포함하는 암시적 공간 모델을 직접 추론 절차를 학습하여 획득합니다.
최근 관절형 자세 추정을 위한 작업에서 컨볼루션 아키텍처를 사용하는 모델에 대한 관심이 급증하고 있습니다. Toshev 등은 표준 컨볼루션 아키텍처를 사용하여 데카르트 좌표를 직접 회귀하는 접근 방식을 취했습니다. 최근 연구에서는 이미지를 신뢰도 맵으로 회귀시키고, 회귀된 신뢰도 맵에서 이상치를 제거하기 위해 수작업으로 설계된 에너지 함수나 공간 확률 우선순위의 휴리스틱 초기화가 필요한 그래픽 모델을 사용합니다. 이들 중 일부는 정밀도 개선을 위한 전용 네트워크 모듈도 사용합니다. 본 연구에서는 회귀된 신뢰도 맵이 수작업으로 설계된 우선순위를 사용하지 않고 암시적 공간 의존성을 학습하기 위해 큰 수용 영역을 가진 추가적인 컨볼루션 네트워크에 입력으로 사용될 수 있음을 보여주며, 신중한 초기화나 전용 정밀도 개선 없이도 모든 정밀도 영역에서 최첨단 성능을 달성했습니다. Pfister 등은 암시적 공간 모델을 포착하기 위해 큰 수용 영역을 가진 네트워크 모듈을 사용했습니다. 컨볼루션의 미분 가능성 덕분에, 우리의 모델은 글로벌하게 훈련될 수 있으며, Tompson 등과 Steward 등도 공동 훈련의 이점을 논의했습니다.
Carreira 등은 오류 피드백을 사용하여 부위 감지를 반복적으로 개선하는 심층 네트워크를 훈련하지만, Toshev 등과 마찬가지로 데카르트 표현을 사용하여 공간적 불확실성을 보존하지 않으며, 이는 고정밀 영역에서 더 낮은 정확도를 초래합니다. 본 연구에서는 순차적 예측 프레임워크가 신뢰도 맵에서 보존된 불확실성을 활용하여 풍부한 공간적 컨텍스트를 인코딩하고, 중간 지역 감독을 강화하여 기울기 소실 문제를 해결하는 방법을 보여줍니다.
3. Method
3.1. Pose Machines
우리는 p번째 해부학적 랜드마크(이하 부위)의 픽셀 위치를 $Y_p \in \mathcal{Z}\subset \mathbb{R}^2$ 로 나타내며, 여기서 $Z$ 는 이미지 내 모든 $(u,v)$ 위치의 집합입니다. 우리의 목표는 모든 $P$ 부위에 대한 이미지 위치 $Y=(Y_1,…,Y_P)$ 를 예측하는 것입니다. pose machine[29] (그림 2a 및 2b 참조)는 계층 구조의 각 단계에서 각 부위의 위치를 예측하도록 훈련된 다중 클래스 예측기 $g_t(\cdot)$의 시퀀스로 구성됩니다. 각 단계 $t\in{1…T}$ 에서, 분류기 $g_t$ 는 이미지에서 위치 $z$ 로부터 추출된 특징 $\mathbf{x}_z\in\mathbb{R}^d$ 과 단계 $t$ 에서 각 $Y_p$ 주변의 이웃에서 이전 분류기로부터의 컨텍스트 정보를 기반으로 각 부위 $Y_p=z, ∀z∈\mathcal{Z}$ 에 위치를 할당하는 신뢰도를 예측합니다. 따라서 첫 번째 단계 $t=1$ 의 분류기는 다음과 같은 신뢰도 값을 생성합니다:
\[\begin{equation} g_1(\mathbf{x}_z) \rightarrow \{b_1^p(Y_p = z)\}_{p \in \{0...P\}} \end{equation}\]여기서 $b_1^p(Y_p=z)$ 는 이미지 위치 $z$ 에서 첫 번째 단계에서 $p$ 번째 부위를 할당하는 분류기 $g_1$ 이 예측한 점수입니다. 우리는 이미지에서 모든 위치 $z=(u,v)^T$ 에서 평가된 $p$ 부위의 모든 신뢰도를 $b_t^p\in\mathbb{R}^{w×h}$ 로 나타내며, 여기서 $w$ 와 $h$는 각각 이미지의 너비와 높이입니다. 즉,
\[\begin{equation} b_t^p[u, v] = b_t^p(Y_p = z). \end{equation}\]편의를 위해, 모든 부위에 대한 신뢰도 맵의 집합을 $b_t\in\mathbb{R}^{w\times h\times (P+1)}$ 로 나타냅니다.(배경을 위한 하나를 포함한 $P$ 부위)
후속 단계에서, 분류기는 (1) 이미지 데이터 $\mathbf{x}_z^′∈\mathbb{R}^d$ 의 특징과 (2) 각 $Y_p$ 주변 에서 이전 분류기로부터의 컨텍스트 정보를 바탕으로 각 부위 $Y_p=z, ∀_z∈\mathcal{Z}$ 에 위치를 할당하는 신뢰도를 예측합니다:
여기서 $ψ_t>1(⋅)$ 는 신뢰도 $b_{t−1}$ 에서 컨텍스트 특징으로의 매핑입니다. 각 단계에서 계산된 신뢰도는 각 부위의 위치에 대한 점점 더 정교해진 예측치를 제공합니다. 우리는 후속 단계의 이미지 특징 $\mathbf{x}_z^′$ 가 첫 번째 단계에서 사용된 이미지 특징 $\mathbf{x}$ 와 다를 수 있도록 허용합니다. [29]에서 제안된 Pose Machine은 예측을 위한 부스팅된 랜덤 포레스트 (${g_t}$), 모든 단계에서 고정된 수작업 이미지 특징 $(x^′=x)$, 그리고 모든 단계를 가로지르는 공간적 컨텍스트를 포착하기 위한 고정된 수작업 컨텍스트 특징 맵 ($ψ_t(⋅)$)을 사용했습니다.
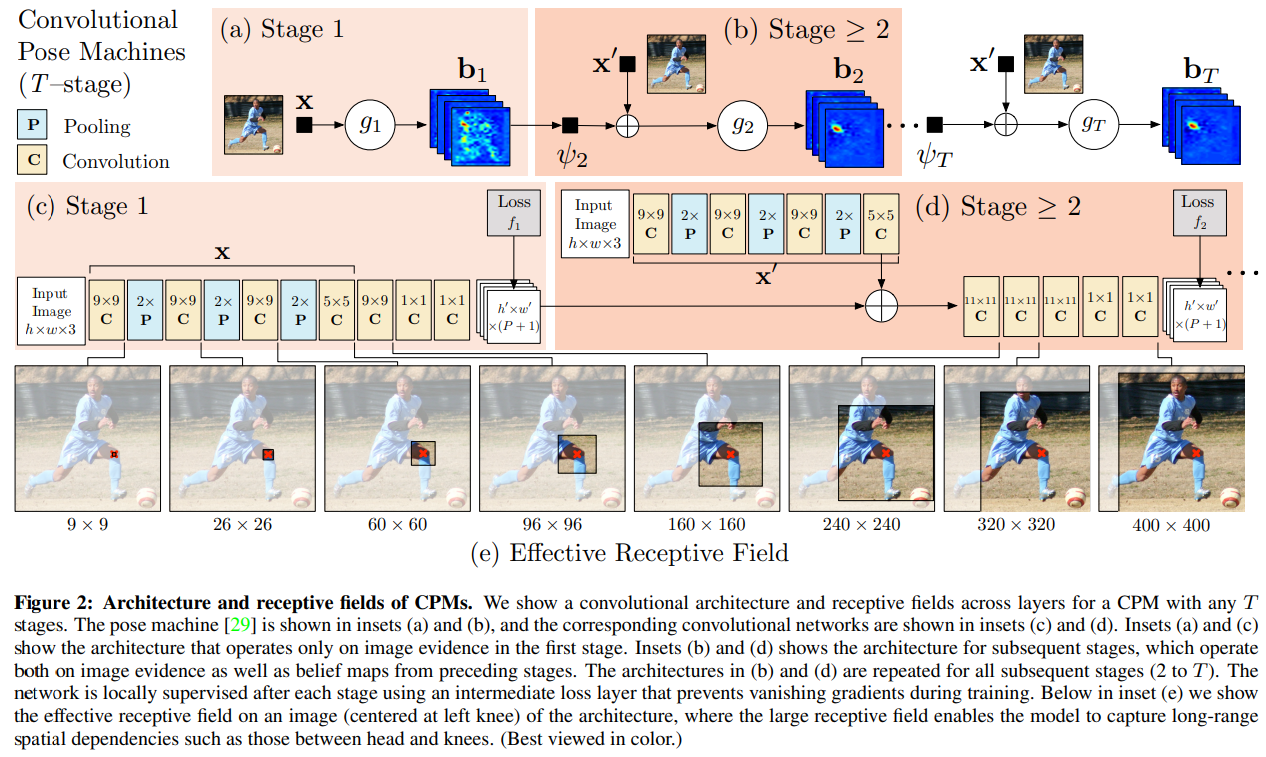
3.2. Convolutional Pose Machines
우리는 포즈 머신의 예측 및 이미지 특징 계산 모듈이 데이터를 통해 이미지 및 컨텍스트 특징 표현을 직접 학습할 수 있는 딥 컨볼루션 아키텍처로 대체될 수 있는 방법을 보여줍니다. 컨볼루션 아키텍처는 또한 완전히 미분 가능하다는 장점이 있어, CPM의 모든 단계를 끝에서 끝까지 공동으로 학습할 수 있게 합니다. 우리는 딥 컨볼루션 아키텍처의 장점과 포즈 머신 프레임워크가 제공하는 암시적 공간 모델링을 결합한 CPM의 설계를 설명합니다.
3.2.1 Keypoint Localization Using Local Image Evidence
컨볼루션 포즈 머신의 첫 번째 단계는 로컬 이미지 증거만을 기반으로 부위 신뢰도를 예측합니다. 그림 2c는 딥 컨볼루션 네트워크를 사용하여 로컬 이미지 증거로부터 부위를 감지하는 데 사용되는 네트워크 구조를 보여줍니다. 증거는 로컬인데, 이는 네트워크의 첫 번째 단계에서 수용 영역이 출력 픽셀 위치 주변의 작은 패치로 제한되기 때문입니다. 우리는 다섯 개의 컨볼루션 레이어와 두 개의 $1×1$ 컨볼루션 레이어로 구성된 네트워크 구조를 사용하여 완전히 컨볼루션 아키텍처를 구성합니다. 실제로 일정한 정밀도를 달성하기 위해 입력된 자른 이미지를 $368×368$ 크기로 정규화하며(자세한 내용은 섹션 4.2 참조), 위에서 보여진 네트워크의 수용 영역은 $160×160$ 픽셀입니다. 네트워크는 각 $160×160$ 이미지 패치에서 로컬 이미지 증거로부터 회귀하여 해당 이미지 위치에서 각 부위에 대한 점수를 나타내는 $P+1$ 크기의 출력 벡터로 전환하는 방식으로 깊이 있는 네트워크를 이미지에 걸쳐 슬라이딩하는 것으로 효과적으로 볼 수 있습니다.
3.2.2 Sequential Prediction with Learned Spatial Context Features
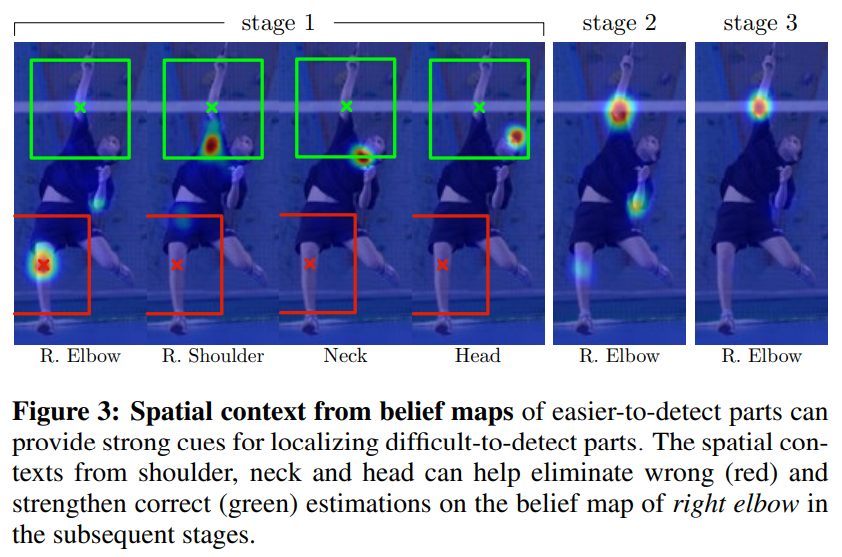
머리와 어깨처럼 일관된 외형을 가진 랜드마크에 대한 탐지율은 높을 수 있지만, 인간 골격의 운동 사슬에서 아래쪽에 위치한 랜드마크는 구성과 외형의 큰 변동성으로 인해 정확도가 훨씬 낮습니다. 부위 위치 주변의 신뢰도 맵의 풍경은 비록 잡음이 있더라도 매우 유용할 수 있습니다. 그림 3에 나타난 바와 같이, 오른쪽 팔꿈치와 같은 어려운 부위를 탐지할 때, 오른쪽 어깨의 신뢰도 맵에서 날카로운 피크가 강력한 단서로 사용될 수 있습니다. 이후 단계의 예측기 $(g_{t>1})$ 는 이미지 위치 $z$ 주변의 영역에서 잡음이 있는 신뢰도 맵의 공간적 컨텍스트 $(ψ_t>1(⋅))$ 를 사용하여 부위가 일관된 기하학적 구성으로 나타난다는 사실을 활용하여 예측을 개선할 수 있습니다. 포즈 머신의 두 번째 단계에서, 분류기 $g_2$ 는 CPM의 이전 단계에서 각 부위에 대한 특징 함수 $ψ$ 를 통해 신뢰도에서 계산된 특징과 이미지 특징 $\mathbf{x}_z^2$ 을 입력으로 받아들입니다. 특징 함수 $ψ$는 이전 단계의 신뢰도 맵의 풍경을 다양한 부위의 위치 $z$ 주변의 공간 영역에서 인코딩하는 역할을 합니다. 컨볼루션 포즈 머신에서는 컨텍스트 특징을 계산하는 명시적 함수가 없습니다. 대신, 우리는 $ψ$ 를 이전 단계의 신뢰도에 대한 예측기의 수용 영역으로 정의합니다.
네트워크 설계는 부위 간 잠재적으로 복잡하고 장거리 상관관계를 학습할 수 있도록 충분히 큰 두 번째 단계 네트워크의 출력층에서 수용 영역을 달성하는 것을 목표로 합니다. 단순히 이전 단계의 출력에 특징을 제공함으로써(그래픽 모델에서 잠재 함수 지정과는 반대로), 이후 단계의 컨볼루션 레이어는 가장 예측력이 높은 특징을 선택하여 컨텍스트 정보를 자유롭게 결합할 수 있게 합니다. 첫 번째 단계의 신뢰도 맵은 작은 수용 영역으로 이미지를 로컬에서 검사한 네트워크에서 생성됩니다. 두 번째 단계에서는 동등한 수용 영역을 급격히 증가시키는 네트워크를 설계합니다. 큰 수용 영역은 정밀도를 희생하면서 풀링을 하거나, 파라미터 수를 증가시키는 대가로 컨볼루션 필터의 커널 크기를 늘리거나, 학습 중 기울기 소실 문제에 직면할 위험을 무릅쓰고 컨볼루션 레이어 수를 증가시킴으로써 달성할 수 있습니다. 우리의 네트워크 설계와 후속 단계 $(t≥2)$ 에 대한 해당 수용 영역이 그림 2d에 나와 있습니다. 우리는 모델의 파라미터 수를 고려하여, $8×$ 다운스케일된 히트맵에서 큰 수용 영역을 달성하기 위해 여러 컨볼루션 레이어를 사용하는 것을 선택했습니다. 우리는 stride-8 네트워크가 높은 정밀도 영역에서도 stride-4 네트워크만큼 잘 작동하며, 더 큰 수용 영역을 달성하기가 더 쉽다는 것을 발견했습니다. 우리는 또한 포즈 머신의 구조를 따르며 공간적 컨텍스트가 이미지 의존적이 되도록 하고 오류 수정을 허용하기 위해 이미지 특징 맵에 대해 유사한 구조를 반복합니다.
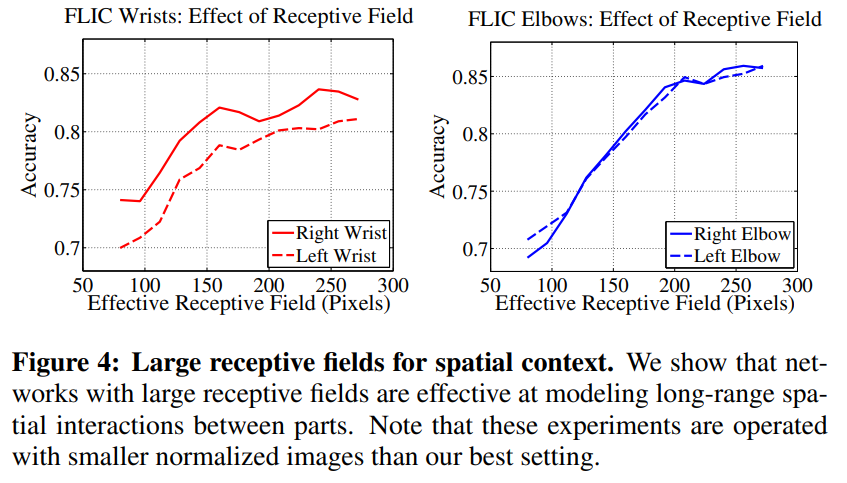
우리는 수용 영역의 크기가 커짐에 따라 정확도가 향상된다는 것을 발견했습니다. 그림 4에서 우리는 원본 이미지에서 수용 영역의 크기를 변경하면서, 파라미터 수를 크게 변경하지 않고 아키텍처를 조정하여 FLIC 데이터셋에서 정확도가 어떻게 향상되는지를 보여줍니다. 이 실험은 크기가 $304 × 304$ 로 정규화된 입력 이미지에 대한 일련의 실험을 통해 이루어졌습니다. 우리는 유효 수용 영역이 커짐에 따라 정확도가 향상되고, 약 250 픽셀에서 포화 상태에 도달하기 시작하는 것을 확인할 수 있는데, 이는 정규화된 객체의 크기와 대략 일치합니다. 수용 영역 크기에 따른 정확도 향상은 네트워크가 실제로 부위 간의 장거리 상호작용을 인코딩하며, 이는 유익하다는 것을 시사합니다. 그림 2에서 우리의 최고 성능 설정에서는 자른 이미지를 368 × 368 픽셀로 더 큰 크기로 정규화하여 더 나은 정밀도를 얻으며, 첫 번째 단계의 신뢰도 맵에 대한 두 번째 단계 출력의 수용 영역은 31 × 31로 설정되며, 이는 원본 이미지에서는 400 × 400 픽셀에 해당하고, 이 반경은 보통 어떤 부위의 쌍이라도 커버할 수 있습니다. 더 많은 단계가 있을수록 유효 수용 영역은 더욱 커집니다. 다음 섹션에서는 최대 6단계에 이르는 결과를 보여줍니다.
3.3. Learning in Convolutional Pose Machines
위에서 설명한 포즈 머신의 설계는 많은 레이어를 가질 수 있는 깊은 아키텍처로 이어집니다. 이와 같은 많은 레이어를 가진 네트워크를 훈련시키는 것은 기울기 소실 문제에 취약할 수 있습니다. Bradley와 Bengio 등이 관찰한 바와 같이, 출력 레이어와 입력 레이어 사이의 중간 레이어 수가 많아질수록 역전파된 기울기의 크기가 감소합니다.
다행히도, 포즈 머신의 순차적 예측 프레임워크는 이 문제를 해결하기 위한 딥 아키텍처를 훈련시키는 자연스러운 접근 방식을 제공합니다. 포즈 머신의 각 단계는 각 부위의 위치에 대한 신뢰도 맵을 반복적으로 생성하도록 훈련됩니다. 우리는 각 부위에 대해 예측된 신뢰도 맵과 이상적인 신뢰도 맵 간의 $l_2$ 거리를 최소화하는 손실 함수를 각 단계 $t$ 의 출력에 정의하여 네트워크가 반복적으로 이러한 표현에 도달하도록 유도합니다. 부위 $p$에 대한 이상적인 신뢰도 맵은 $b_∗^p(Y_p=z)$ 로 작성되며, 이는 각 신체 부위 $p$ 의 실제 위치에 가우시안 피크를 넣어 생성됩니다. 따라서 각 단계의 각 레벨에서 출력에서 최소화하려는 비용 함수는 다음과 같이 주어집니다:
전체 아키텍처에 대한 전체 목표는 각 단계의 손실을 더하여 얻어지며 다음과 같이 주어집니다:
\[\begin{equation} \mathcal{F}=\sum_{t=1}^T f_t\cdot \end{equation}\]우리는 네트워크의 모든 $T$ 단계를 공동으로 훈련하기 위해 표준 확률적 경사 하강법을 사용합니다. 모든 후속 단계에서 이미지 특징 $\mathbf{x}^′$ 를 공유하기 위해, 우리는 단계 $t≥2$ 에서 해당하는 컨볼루션 레이어의 가중치를 공유합니다 (그림 2 참조).
4. Evaluation
4.1. Analysis
Addressing vanishing gradients.
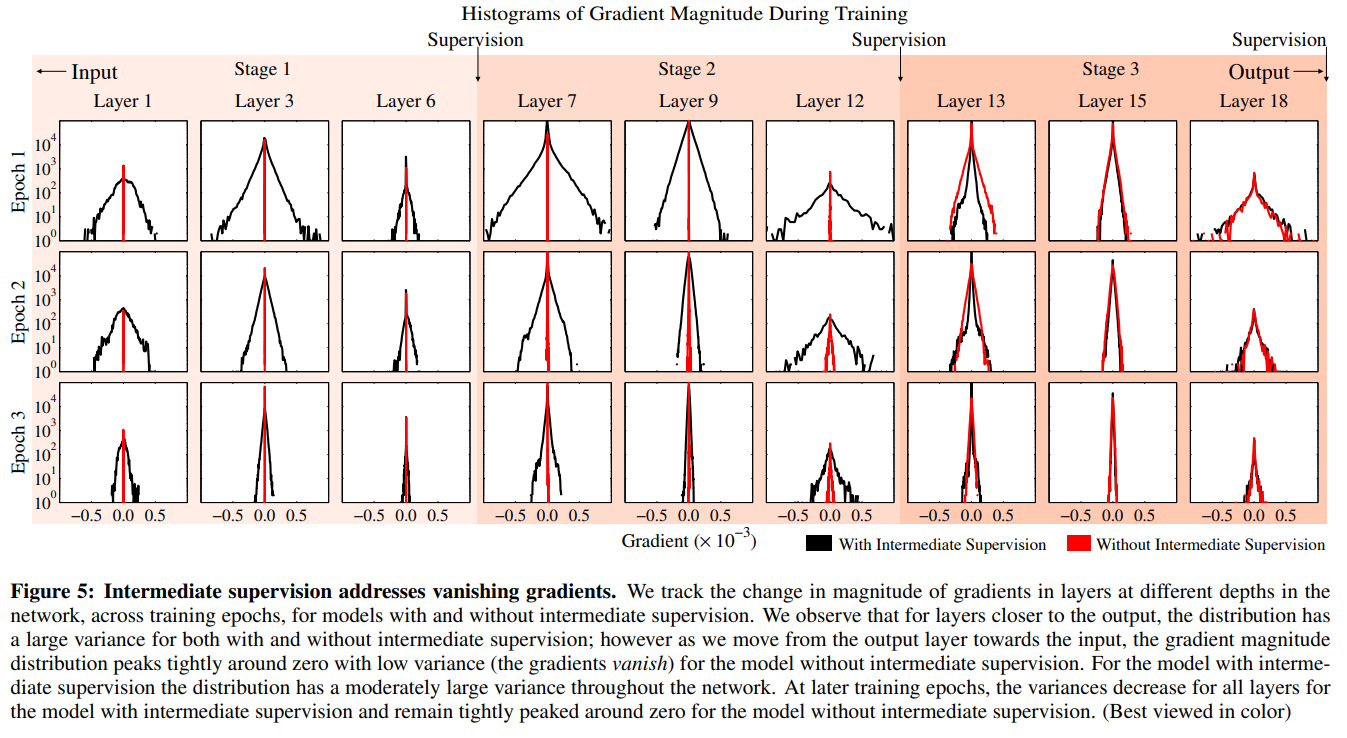
방정식 5에서 목표는 네트워크의 다양한 부분에서 작동하는 분해 가능한 손실 함수를 설명합니다(그림 2 참조). 구체적으로, 합산 내의 각 항은 네트워크를 통해 중간 단계에서 효과적으로 감독을 시행하는 방식으로 각 단계 $t$ 이후에 네트워크에 적용됩니다. 중간 감독은 전체 아키텍처가 많은 레이어를 가질 수 있더라도, 중간 손실 함수가 각 단계에서 기울기를 보충하기 때문에 기울기 소실 문제에 빠지지 않는다는 장점이 있습니다.
우리는 중간 감독이 있는 모델과 없는 모델에 대해, 훈련 에포크 전반에 걸쳐 아키텍처의 서로 다른 깊이에서 기울기 크기의 히스토그램을 관찰함으로써 이 주장을 확인합니다(그림 5 참조). 초기 에포크에서는 출력 레이어에서 입력 레이어로 이동함에 따라, 중간 감독이 없는 모델에서 기울기 분포가 기울기 소실로 인해 0 주변에서 급격히 피크를 이루는 것을 관찰합니다. 중간 감독이 있는 모델은 모든 레이어에서 훨씬 더 큰 분산을 가지며, 이는 중간 감독 덕분에 모든 레이어에서 학습이 실제로 일어나고 있음을 시사합니다. 또한 훈련이 진행됨에 따라 기울기 크기 분포의 분산이 감소하여 모델의 수렴을 가리키는 것을 알 수 있습니다.
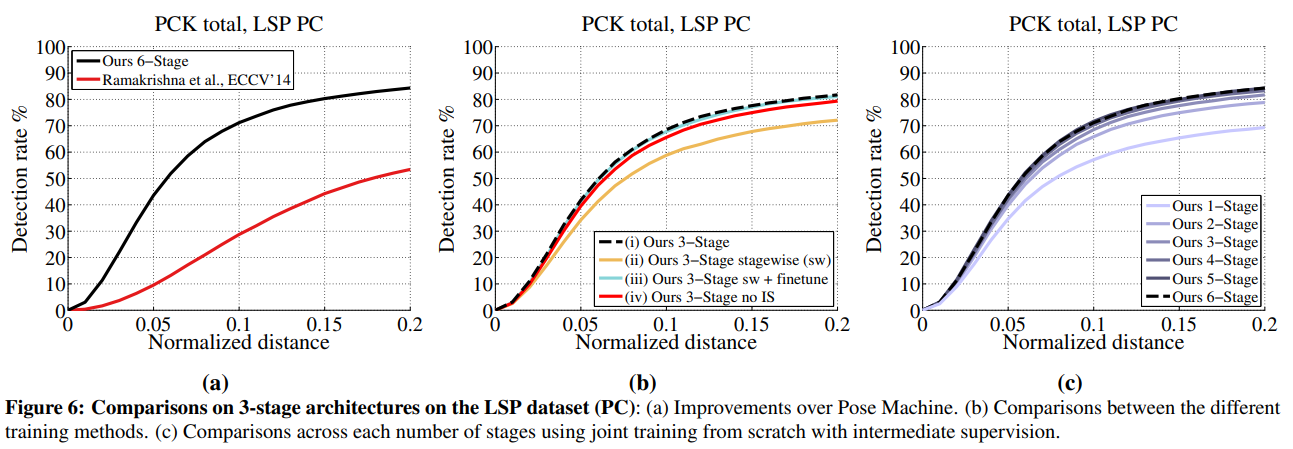
Benefit of end-to-end learning.
그림 6a에서 우리는 포즈 머신의 모듈을 적절하게 설계된 컨볼루션 아키텍처로 대체하면, 이전 접근 방식([29])보다 고정밀 영역(PCK@0.1)에서 42.4%포인트, 저정밀 영역(PCK@0.2)에서 30.9%포인트의 큰 향상이 있음을 확인할 수 있습니다.
Comparison on training schemes.
우리는 LSP 데이터셋에서 사람 중심(PC) 주석을 사용하여 그림 6b에 나타난 네트워크 훈련의 다양한 변형을 비교합니다. 단계 간 공동 훈련과 중간 감독의 이점을 입증하기 위해, 우리는 모델을 네 가지 방법으로 훈련합니다:
- (i) 중간 감독을 강화하는 글로벌 손실 함수를 사용하여 처음부터 훈련
- (ii) 단계별; 각 단계를 피드포워드 방식으로 훈련하고 쌓는 방식
- (iii) (i)와 동일하지만, (ii)에서의 가중치로 초기화된 방식
- (iv) (i)와 동일하지만, 중간 감독이 없는 방식. 우리는 네트워크 (i)가 다른 모든 훈련 방법보다 뛰어나다는 것을 발견했으며, 이는 단계 간 중간 감독과 공동 훈련이 실제로 좋은 성능을 달성하는 데 중요한 역할을 한다는 것을 보여줍니다. (ii) 단계별 훈련은 차선의 수준에서 포화되고, (iii)의 공동 미세 조정은 이 차선 수준에서 (i)에 근접한 정확도 수준으로 향상되지만, 훈련 반복이 효과적으로 더 길어집니다.
Performance across stages.
우리는 그림 6c에서 LSP 데이터셋(PC)에서 각 단계별 성능 비교를 보여줍니다. 우리는 성능이 5단계까지 단조롭게 증가하는 것을 보여줍니다. 이후 단계의 예측기는 이전 단계 신뢰도 맵에서 큰 수용 영역의 컨텍스트 정보를 사용하여 부위와 배경 간의 혼동을 해결합니다. 우리는 6단계에서 수익이 감소하는 것을 확인할 수 있으며, 이는 우리가 LSP 및 MPII 데이터셋에 대해 이 논문에서 최고의 결과를 보고하기 위해 선택한 단계 수입니다.
4.2. Datasets and Quantitative Analysis
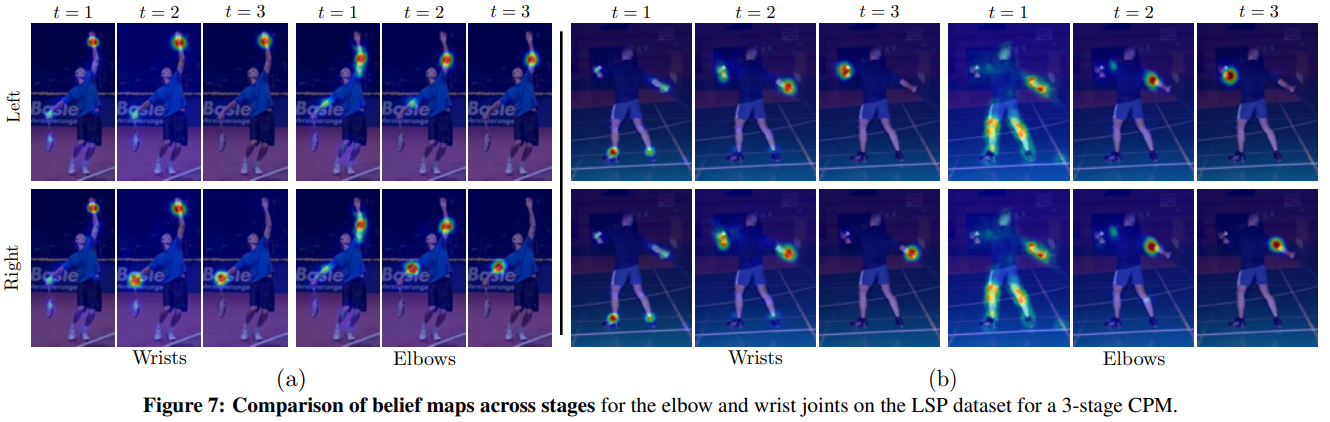
이 섹션에서는 MPII, LSP, FLIC 데이터셋을 포함한 다양한 표준 벤치마크에서의 수치 결과를 제시합니다. 훈련을 위해 368 × 368로 정규화된 입력 샘플을 얻기 위해, 먼저 이미지를 대략 동일한 크기로 조정한 다음, 데이터셋에서 제공된 중심 위치 및 대략적인 스케일 추정값에 따라 이미지를 자르거나 패딩합니다. 이러한 정보가 없는 LSP와 같은 데이터셋에서는 관절 위치나 이미지 크기에 따라 이를 추정합니다. 테스트를 위해서도 유사한 리사이징과 크롭핑(또는 패딩)을 수행하지만, 필요한 경우에만 이미지 크기에서 중심 위치와 스케일을 추정합니다. 또한, 주어진 스케일 추정의 부정확성을 처리하기 위해, 최종 예측을 위해 서로 다른 스케일(주어진 스케일 주변에서 변형된)에서의 신뢰도 맵을 병합합니다.
우리는 딥러닝을 위해 Caffe 라이브러리를 사용하여 모델을 정의하고 구현합니다. 우리는 완전한 재현성을 보장하기 위해 아키텍처, 학습 파라미터, 설계 결정 및 데이터 증강에 대한 세부 사항과 함께 소스 코드를 공개합니다.
MPII Human Pose Dataset.
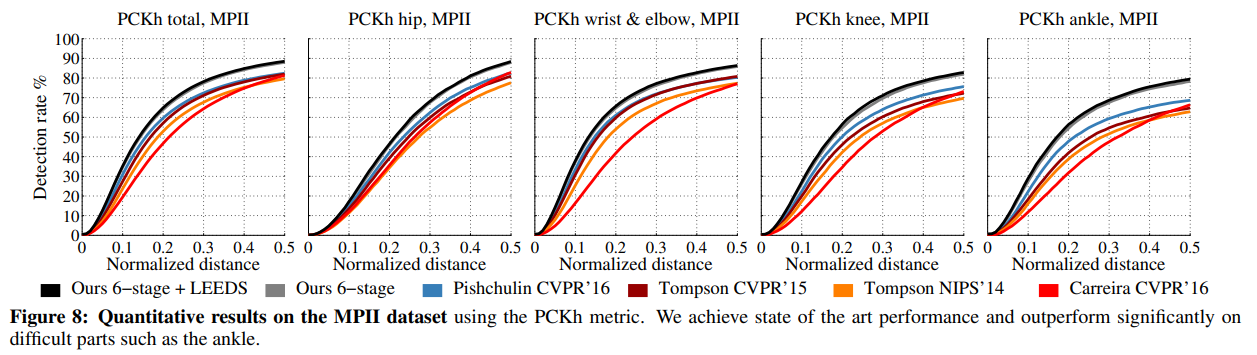
우리는 그림 8에서 28,000개 이상의 훈련 샘플로 구성된 MPII 인간 자세 데이터셋에서의 결과를 보여줍니다. 우리는 [−40°, 40°] 범위의 회전 각도와 [0.7, 1.3] 범위의 스케일링, 그리고 수평 반전을 통해 데이터를 무작위로 증강하기로 선택했습니다. 평가는 PCKh 지표에 기반하며, 여기서 오류 허용 오차는 대상의 머리 크기를 기준으로 정규화됩니다. 관심 있는 사람의 근처에 여러 사람이 있는 경우가 자주 있기 때문에(데이터셋에서 대략적인 중심 위치가 제공됨), 우리는 훈련을 위해 두 세트의 이상적인 신뢰도 맵을 만들었습니다: 하나는 주 관심 대상의 근처에 나타나는 모든 사람들의 모든 피크를 포함하고, 두 번째 유형은 주 관심 대상에만 피크를 배치하는 것입니다. 우리는 첫 번째 신뢰도 맵 세트를 첫 번째 단계의 손실 레이어에 제공하며, 초기 단계는 예측을 위해 지역적 이미지 증거에만 의존합니다. 우리는 두 번째 유형의 신뢰도 맵을 모든 후속 단계의 손실 레이어에 제공합니다. 우리는 또한 모든 후속 단계에 주 관심 대상의 중심을 나타내는 가우시안 피크를 가진 추가 히트 맵을 제공하는 것이 유익하다는 것을 발견했습니다.
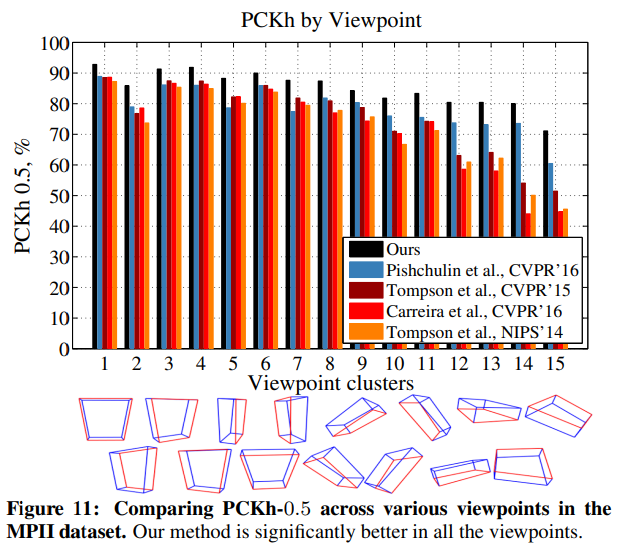
우리의 총 PCKh-0.5 점수는 87.95%(LSP 훈련 데이터를 추가하면 88.52%)로, 가장 근접한 경쟁자보다 6.11% 더 높습니다. 특히 가장 어려운 부위인 발목에서 우리의 PCKh-0.5 점수는 78.28%(LSP 훈련 데이터를 추가하면 79.41%)로, 가장 근접한 경쟁자보다 10.76% 더 높다는 점이 주목할 만합니다. 이 결과는 발목이 머리와 다른 더 잘 인식되는 부위에서 가장 먼 부위임을 감안할 때, 우리 모델이 장거리 문맥을 포착할 수 있는 능력을 보여줍니다. 그림 11은 특히 어려운 비정면 시야에서, 우리의 정확도가 [1]에서 정의된 다양한 시야각 전반에 걸쳐 다른 방법들보다 일관되게 현저히 더 높다는 것을 보여줍니다. 요약하면, 우리 방법은 모든 부위에서, 모든 정밀도에서, 모든 시야각에서 정확도를 향상시키며, 다른 데이터로부터의 사전 훈련 없이, 혹은 [28, 39]와 같은 구조화된 예측 작업의 사후 추론 파싱이나 초기화를 통해 이와 같은 높은 정확도를 달성한 최초의 방법입니다. 우리의 방법은 또한 [38]와 같이 위치 정밀 조정을 위한 다른 모듈이 필요 없이, 스트라이드-8 네트워크로 높은 정밀도의 정확도를 달성할 수 있습니다.
Leeds Sports Pose (LSP) Dataset.
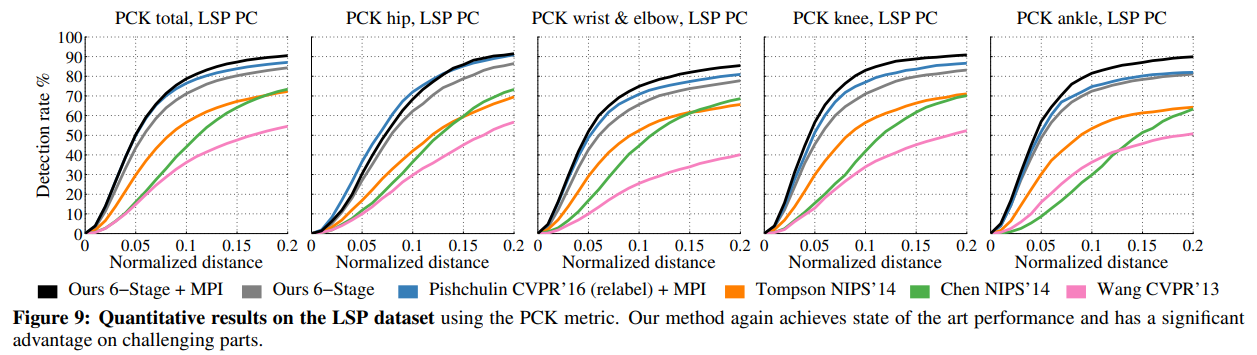
우리는 11,000개의 훈련 이미지와 1,000개의 테스트 이미지로 구성된 Extended Leeds Sports Dataset에서 우리의 방법을 평가합니다. 우리는 사람 중심(Personal-Centric, PC) 주석을 기반으로 훈련하고, Percentage Correct Keypoints (PCK) 지표를 사용하여 우리의 방법을 평가합니다. MPII 데이터셋과 동일한 증강 스키마를 사용하여, 우리 모델은 다시 한번 84.32%(MPII 훈련 데이터를 추가할 경우 90.5%)의 최첨단 성능을 달성합니다. 여기서 MPII 데이터를 추가하면 성능이 크게 향상되며, 이는 MPII의 레이블링 품질이 LSP보다 훨씬 뛰어나기 때문입니다. LSP 데이터셋의 노이즈가 많은 레이블 때문에, Pishchulin 등은 원래 고해상도 이미지와 더 나은 레이블링 품질로 데이터셋을 재현했습니다.
FLIC Dataset.
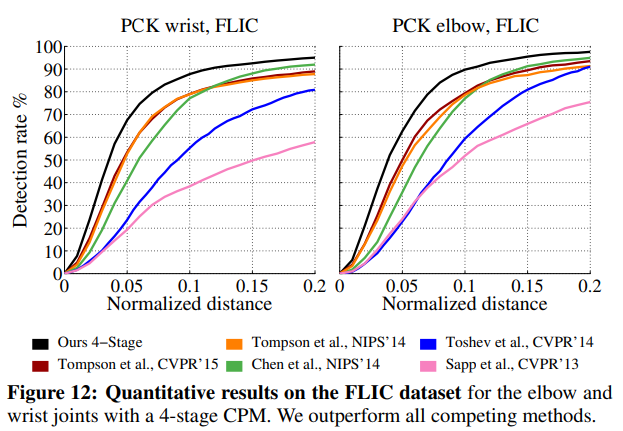
우리는 3,987개의 훈련 이미지와 1,016개의 테스트 이미지로 구성된 FLIC 데이터셋에서 우리의 방법을 평가합니다. 우리는 그림 12에서 팔꿈치와 손목 관절에 대한 Sapp et al.이 도입한 지표에 따라 정확도를 보고합니다. 마찬가지로, 우리는 팔꿈치에서 97.59%, 손목에서 95.03%로 모든 이전 방법을 PCK@0.2에서 능가합니다. 더 높은 정밀도 영역에서는 우리의 이점이 더욱 두드러집니다: PCK@0.05에서 손목에서 14.8%포인트, 팔꿈치에서 12.7%포인트, PCK@0.1에서 손목에서 8.9%포인트, 팔꿈치에서 9.3%포인트입니다.

5. Discussion
컨볼루션 포즈 머신은 그래픽 모델 스타일의 추론이 필요 없이 컴퓨터 비전에서 구조적 예측 문제를 해결하기 위한 엔드투엔드 아키텍처를 제공합니다. 우리는 컨볼루션 네트워크로 구성된 순차적 아키텍처가 단계 간 점점 더 정교하게 다듬어지는 불확실성 보존 신뢰도를 전달함으로써 포즈에 대한 공간 모델을 암묵적으로 학습할 수 있음을 보여주었습니다. 변수 간의 공간적 종속성과 관련된 문제는 의미론적 이미지 레이블링, 단일 이미지 깊이 예측, 객체 탐지와 같은 컴퓨터 비전의 여러 영역에서 발생하며, 향후 작업에서는 이러한 문제에 우리의 아키텍처를 확장하는 것이 포함될 것입니다. 우리의 접근법은 모든 주요 벤치마크에서 최첨단의 정확도를 달성하지만, 특히 여러 사람이 가까이 있을 때 주로 실패하는 사례를 관찰했습니다. 하나의 엔드투엔드 아키텍처에서 여러 사람을 처리하는 것도 도전적인 문제이며, 미래 연구에서 흥미로운 주제가 될 것입니다.
Shih-En Wei, Varun Ramakrishna, Takeo Kanade, Yaser Sheikh Convolutional Pose Machines

댓글남기기