

개요
객체감지 모델 논문 읽기와 별도로 2D Pose Estimation에 대한 논문 읽기도 진행한다. 3D Mesh 쪽이 아닌 2D는 큼지막하게 읽을 것들만 리뷰할 예정이다.
DeepPose는 딥러닝을 적용한 최초의 사람 관절 및 자세 추정 연구 중 하나다. 딥러닝 기반으로 관절의 위치를 추정하려는 초기에 문을 연 논문이기에 그 만큼 중요하다 생각된다. DeepPose는 CNN 및 딥러닝 기반으로 관절 위치를 추정하는 문제를 회귀 문제로 접근한다.
Deep Learning Model for Pose Estimation
- k개의 신체 관절 위치를 회귀하는 문제로 정의하여 각 관절은 x, y 좌표를 가진다.
- 각 신체 관절의 좌표를 인간 신체 스케일에 맞는 혹은 경계 상자에 맞도록 정규화하여 표기한다.
- 이미지 입력은 220 * 220 의 입력크기를 사용하며 네트워크 아키텍쳐는 AlexNet에서 착안하였다.
- L2 손실을 사용하며 각 관절별 오차에 대한 합을 이용하기에 모든 관절이 라벨링 되지 않은 경우에도 사용할 수 있다.
- 자세를 Refinement 하기 위한 추가 딥러닝 회귀를 통해 조금 더 높은 정확도 달성을 도모한다.
Experiments
- 데이터 셋은 영화 도메인의 FLIC와 스포츠 도메인의 LSP 데이터셋을 이용한다.
- 지름(diam)이라고 정의되는 것은 양쪽 어깨와 엉덩이 키포인트 사이의 거리로 정의한다.
- 성능 지표는 PCP(사지의 검출률 기준), PDJ(상체 지름의 특정 비율을 기준으로 관절 검출)의 두가지를 언급한다.
- 12코어 CPU 기준 이미지 당 0.1초의 처리 속도를 보인다. 다른 비교군 모델은 4초, 1.5초 등으로 더 느리며 훈련에 대해 높은 복잡성을 가진다.
- 해당 접근법이 FLIC와 LSP와 같은 복잡한 관절 구조 모두에 대해 잘 작동함을 확인한다.
- refinement를 위한 추가 DNN 회귀자에 대해서도 성능을 테스트하고 초기 단계에는 대략적인 관절 위치만 얻지만, 추가적인 단계를 거듭하면서 더욱 정확한 위치로 회귀되어 좋은 성능을 얻는다.
- 정확한 예측이 실패한 이미지 사례의 경우 추정된 자세가 정확하지 않더라도 어느정도 올바른 모양을 가지는 것을 볼 수 있다. 그리고 좌우 인덱스가 혼동되어 나오는 경우를 종종 볼수 있다.
결론
사람에 대한 자세 추정 테스크에 최초로 DNN을 적용한 사례로 알고 있다. 이 이후 자세 추정 문제에 대해서 딥러닝을 활용한 접근들이 많아졌으며, DNN 기반 접근법의 효용을 입증하게 된 계기가 된다. 신체의 부분 기반 모델에서 벗어나 이미지 전체 및 사람 전체를 고려하여 자세를 추정하는 기술을 보여 다양한 도메인의 데이터 셋에도 적용할 수 있는 일반화 성능을 보여주었다고 생각한다.
번역
Abstract
우리는 심층 신경망(DNNs)을 기반으로 한 인간 자세 추정 방법을 제안합니다. 자세 추정은 신체 관절을 향한 DNN 기반 회귀 문제로 구성됩니다. 우리는 높은 정확도의 자세 추정을 가능하게 하는 이러한 DNN 회귀자의 연쇄 구조를 제시합니다. 이 접근법은 자세를 전체적으로 추론할 수 있는 이점을 가지며, 최근 심층 학습의 발전을 활용한 단순하지만 강력한 공식화를 가지고 있습니다. 우리는 다양한 실제 이미지의 네 가지 학술적 벤치마크에서 최첨단 또는 더 나은 성능을 보이는 상세한 실증적 분석을 제시합니다.
1. Introduction

인간 자세 추정 문제는 인간 관절의 위치를 찾는 문제로 정의되며, 컴퓨터 비전 커뮤니티에서 상당한 주목을 받아왔습니다. 그림 1에서 이 문제의 몇 가지 도전 과제 - 강한 관절, 작고 거의 보이지 않는 관절, 가림 현상, 그리고 맥락을 포착해야 하는 필요성 - 을 볼 수 있습니다.
이 분야의 주요 연구들은 주로 첫 번째 도전 과제, 즉 모든 가능한 관절 자세의 큰 공간에서 검색해야 하는 필요성에서 비롯되었습니다. 부분 기반 모델은 관절을 모델링하는 데 자연스럽게 적합하며, 최근 몇 년 동안 효율적인 추론을 제공하는 다양한 모델들이 제안되었습니다.
그러나 이러한 효율성은 제한된 표현력이라는 대가를 치르게 됩니다 - 많은 경우 단일 부위에 대한 추론을 하는 지역 감지기를 사용하고, 무엇보다도 신체 부위 간의 모든 상호작용의 일부분만을 모델링함으로써 이러한 효율성을 얻습니다. 이러한 제한 사항들은 그림 1에 예시된 것처럼 인식되었으며, 전체적인 방식으로 자세를 추론하는 방법들이 제안되었지만 실제 문제에서는 성공이 제한적이었습니다.
이 연구에서 우리는 인간 자세 추정의 전체적인 관점을 채택합니다. 우리는 최근의 딥러닝 발전을 활용하여 심층 신경망(DNN)에 기반한 새로운 알고리즘을 제안합니다. DNN은 시각적 분류 작업에서 뛰어난 성능을 보여주었으며, 최근에는 객체 위치 추정에서도 우수한 성과를 보였습니다. 그러나 관절이 있는 객체의 정확한 위치 추정에 DNN을 적용하는 문제는 여전히 해결되지 않은 상태로 남아 있습니다. 이 논문에서는 이 문제에 대해 조명을 시도하고, DNN으로서의 전체적인 인간 자세 추정에 대한 단순하면서도 강력한 공식을 제시합니다.
우리는 자세 추정을 관절 회귀 문제로 공식화하고, 이를 DNN 설정에서 성공적으로 적용하는 방법을 제시합니다. 각 신체 관절의 위치는 전체 이미지와 7층 일반화된 합성곱 DNN을 입력으로 사용하여 회귀됩니다. 이 공식화에는 두 가지 장점이 있습니다: 첫째, DNN은 각 신체 관절의 전체 맥락을 포착할 수 있습니다 – 각 관절 회귀자는 전체 이미지를 신호로 사용합니다. 둘째, 이 접근법은 그래픽 모델 기반 방법보다 훨씬 간단하게 공식화할 수 있습니다 – 부위별 특징 표현 및 감지기를 명시적으로 설계할 필요가 없으며, 모델 토폴로지 및 관절 간 상호작용을 명시적으로 설계할 필요가 없습니다. 대신, 우리는 이 문제에 대해 일반적인 합성곱 DNN이 학습될 수 있음을 보여줍니다.
더 나아가, 우리는 DNN 기반의 자세 예측기의 연쇄 구조를 제안합니다. 이러한 연쇄 구조는 관절 위치 추정의 정확도를 높일 수 있습니다. 전체 이미지를 기반으로 한 초기 자세 추정에서 시작하여, 우리는 고해상도 하위 이미지를 사용하여 관절 예측을 정제하는 DNN 기반 회귀자를 학습합니다.
우리는 모든 보고된 결과에 대해 널리 사용되는 네 가지 벤치마크에서 최첨단 또는 그 이상의 성능을 보여줍니다. 우리의 접근법이 외형 및 관절 변동이 큰 사람의 이미지에서도 잘 작동함을 보여줍니다. 마지막으로, 우리는 교차 데이터셋 평가를 통해 일반화 성능을 보여줍니다.
2. Related Work
관절 있는 객체 전반과 특히 인간 자세를 부위의 그래프로 표현하는 아이디어는 컴퓨터 비전 초기부터 주장되어 왔습니다 [16]. Fishler와 Elschlager [8]가 도입한 일명 Pictorial Structures(PSs)는 Felzenszwalb와 Huttenlocher [6]가 거리 변환 트릭을 사용하여 실용적이고 실제적인 것으로 만들어졌습니다. 그 결과, 실용적으로 중요한 다양한 PS 기반 모델들이 개발되었습니다.
그러나 이러한 실용성은 이미지 데이터에 의존하지 않는 단순한 이진 잠재성을 가진 트리 기반의 자세 모델이라는 제한을 동반합니다. 그 결과, 연구는 실용성을 유지하면서 모델의 표현력을 강화하는 데 중점을 두었습니다. 이러한 목표를 달성하기 위한 초기 시도들은 더 풍부한 부위 탐지기를 기반으로 했습니다 [19, 1, 4]. 최근에는 복잡한 관절 관계를 표현하는 다양한 모델들이 제안되었습니다. Yang과 Ramanan [27]은 부위 혼합 모델을 사용합니다. 전체 모델 규모에서 PSs의 혼합을 포함한 혼합 모델은 Johnson과 Everingham [13]에 의해 연구되었습니다. 더 풍부한 고차원 공간 관계는 Tian et al. [25]의 계층적 모델에서 포착되었습니다. 고차원 관계를 포착하는 또 다른 접근 방식은 이미지 의존적 PS 모델을 사용하는 것으로, 이는 글로벌 분류기를 통해 추정될 수 있습니다 [26, 20, 18].
자세에 대해 전체적으로 추론하는 우리의 철학을 적용한 접근법들은 실용성이 제한적이었습니다. Mori와 Malik [15]은 각 테스트 이미지에 대해 레이블이 지정된 이미지 집합에서 가장 가까운 예제를 찾아 관절 위치를 전이하려고 합니다. 유사한 가장 가까운 이웃 설정이 Shakhnarovich et al. [21]에 의해 사용되었으며, 이들은 로컬 민감 해싱을 사용합니다. 최근에는 Gkioxari et al. [10]이 부위 구성에 대한 준 글로벌 분류기를 제안했습니다. 이 공식은 실제 데이터에서 매우 좋은 결과를 보여주었으나, 우리의 방법보다 표현력이 떨어지는 선형 분류기를 기반으로 하며 팔에만 테스트되었습니다. 마지막으로, 자세 회귀의 아이디어는 Ionescu et al. [11]에 의해 채택되었으나, 이들은 3D 자세에 대해 추론합니다.
우리 연구와 가장 가까운 연구는 포즈를 나타내는 임베딩에서 한 점으로 회귀하기 위해 Neighborhood Component Analysis와 함께 합성곱 신경망을 사용합니다 [24]. 그러나 이 연구는 네트워크의 연쇄 구조를 사용하지 않습니다. DNN 회귀자의 연쇄 구조는 얼굴 점의 위치 추정에 사용되었습니다 [22]. 유사한 얼굴 자세 추정 문제에서 Osadchy et al. [17]은 대조 손실로 훈련된 신경망 기반 자세 임베딩을 사용합니다.
3. Deep Learning Model for Pose Estimation
우리는 다음과 같은 표기법을 사용합니다. 자세를 표현하기 위해, 우리는 모든 k개의 신체 관절 위치를 $y=(…,\mathbf{y}_i^T,…)^T$ 로 정의된 자세 벡터에 인코딩합니다. 여기서 $\mathbf{y}_i$ 는 $i$번째 관절의 $x$와 $y$ 좌표를 포함합니다. 라벨이 지정된 이미지는 $(x,y)$ 로 표기되며, 여기서 $x$는 이미지 데이터를, $y$ 는 실제 자세 벡터를 나타냅니다.
또한, 관절 좌표가 절대 이미지 좌표에 있으므로, 이를 인간 신체나 그 일부를 둘러싸는 상자 $b$에 대해 정규화하는 것이 유리함을 증명합니다. 간단한 경우, 상자는 전체 이미지를 나타낼 수 있습니다. 이러한 상자는 중심 $b_c∈R^2$ 와 너비 $b_w$, 높이 $b_h$ 로 정의됩니다: $b=(b_c, b_w, b_h)$. 그런 다음 관절 $\mathbf{y}_i$ 는 상자 중심에 의해 이동되고 상자 크기에 의해 스케일링되어 $b$로 정규화됩니다:
추가적으로, 우리는 동일한 정규화를 자세 벡터의 요소들에도 적용할 수 있으며, $N(\mathbf{y};b)=(…,N(\mathbf{y}_i;b)^T,…)^T$ 로 정규화된 자세 벡터를 얻게 됩니다. 마지막으로, 약간의 표기 남용으로 $N(x;b)$ 를 사용하여 상자 $b$에 의해 이미지 $x$를 자른 것을 나타내며, 이는 사실상 이미지를 상자로 정규화합니다. 간결함을 위해 $N(⋅)$로 전체 이미지 상자 $b$에 대한 정규화를 나타냅니다.
3.1. Pose Estimation as DNN-based Regression
이 연구에서는 자세 추정 문제를 회귀로 간주하며, 이미지 $x$에 대해 정규화된 자세 벡터로 회귀하는 함수 $ψ(x;θ)∈ \mathbb{R}^{2k}$ 를 학습하고 사용합니다. 여기서 $θ$는 모델의 매개변수를 나타냅니다. 따라서, 방정식 (1)에서의 정규화 변환을 사용하여 절대 이미지 좌표에서의 자세 예측 $y^∗$ 는 다음과 같이 표현됩니다:
\[\begin{equation} y^*=N^{-1}(\psi(N(x);\theta)) \end{equation}\]단순한 공식화에도 불구하고, 이 방법의 강력함과 복잡성은 합성곱 심층 신경망(DNN)에 기반한 $ψ$ 에 있습니다. 이러한 합성곱 네트워크는 여러 층으로 구성되며, 각 층은 선형 변환에 이어 비선형 변환이 뒤따릅니다. 첫 번째 층은 미리 정의된 크기의 이미지를 입력으로 받아 픽셀 수에 세 가지 색상 채널을 곱한 크기를 가집니다. 마지막 층은 회귀의 목표 값을 출력하며, 이 경우 $2k$ 개의 관절 좌표를 출력합니다.
우리는 $ψ$의 구조를 Krizhevsky et al. [14]의 이미지 분류 작업에 기반하고 있으며, 이는 객체 위치 추정에서도 뛰어난 결과를 보여주었습니다 [23]. In a nutshell, the network consists of 7 layers (see Fig. 2 left). C는 합성곱 층을, $LRN$ 은 국소 응답 정규화 층을, $P$ 는 풀링 층을, $F$ 는 완전 연결 층을 나타냅니다. $C$와 $F$ 층만 학습 가능한 매개변수를 포함하며, 나머지는 매개변수가 없습니다. $C$와 $F$층 모두 선형 변환에 이어 비선형 변환으로 구성되며, 우리 경우에는 정류된 선형 단위입니다. $C$ 층의 경우, 크기는 $width × height × depth$로 정의되며, 첫 두 차원은 공간적 의미를 가지며 깊이는 필터의 수를 정의합니다. 각 층의 크기를 괄호 안에 적으면, 네트워크는 다음과 같이 간결하게 설명될 수 있습니다:
처음 두 개의 $C$ 층의 필터 크기는 $11×11$ 및 $5×5$이며, 나머지 세 개의 필터 크기는 $3×3$입니다. 풀링은 세 개의 층 이후에 적용되며, 해상도 감소에도 불구하고 성능 향상에 기여합니다. 네트워크의 입력은 $220×220$ 크기의 이미지이며, 이 이미지는 스트라이드 4를 통해 네트워크에 입력됩니다. 위 모델의 전체 매개변수 수는 약 4000만 개입니다.
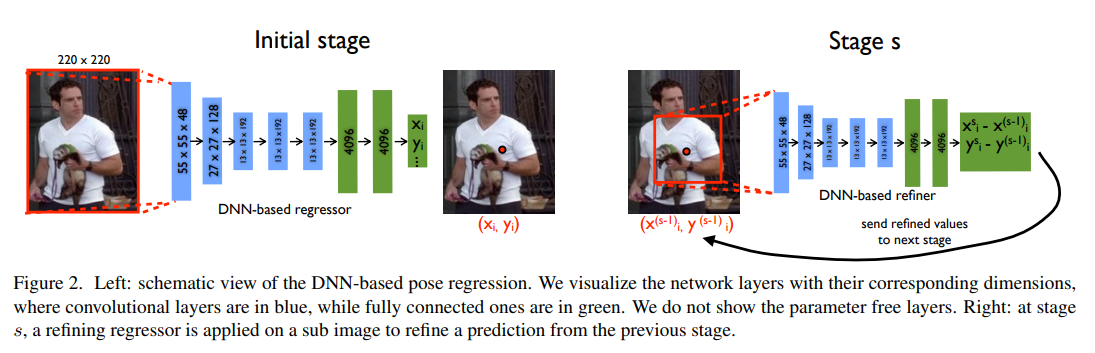
일반적인 DNN 아키텍처의 사용은 분류와 위치 추정 문제 모두에서 뛰어난 결과를 보여준다는 점에서 동기부여됩니다. 실험 섹션에서 우리는 그러한 일반적인 아키텍처를 사용하여 모델을 학습시킬 수 있으며, 이는 자세 추정에서도 최첨단 또는 그 이상의 성능을 달성할 수 있음을 보여줍니다. 더 나아가, 이러한 모델은 진정으로 전체적인 모델로, 최종 관절 위치 추정은 전체 이미지의 복잡한 비선형 변환을 기반으로 합니다.
추가적으로, DNN을 사용하면 특정 도메인에 맞는 자세 모델을 설계할 필요가 없습니다. 대신에, 이러한 모델과 특징은 데이터를 통해 학습됩니다. 회귀 손실이 관절 간의 명시적인 상호작용을 모델링하지는 않지만, 이러한 상호작용은 7개의 숨겨진 층 모두에 의해 암묵적으로 포착됩니다 — 모든 내부 특징은 모든 관절 회귀자에 의해 공유됩니다.
Training
[14]와의 차이점은 손실입니다. 분류 손실 대신, 우리는 마지막 네트워크 층 위에 선형 회귀를 훈련시켜 예측과 실제 자세 벡터 간의 $L_2$ 거리를 최소화하여 자세 벡터를 예측합니다. 실제 자세 벡터는 절대 이미지 좌표로 정의되고, 이미지마다 자세의 크기가 다르기 때문에, 우리는 방정식 (1)에서의 정규화를 사용하여 훈련 세트 $D$를 정규화합니다:
\[\begin{equation} D_N={(N(x), N(\mathbf{y}))\vert (x,\mathbf{y}) \in D} \end{equation}\]그런 다음 최적의 네트워크 매개변수를 얻기 위한 $L_2$ 손실은 다음과 같습니다:
\[\begin{equation} \arg \min_{\theta} \sum_{(x,y)\in D_N} \sum_{i=1}^k \Vert\mathbf{y}_i - \psi_i(x;\theta)\Vert_2^2 \end{equation}\]명확성을 위해 개별 관절에 대한 최적화를 작성했습니다. 위의 목표는 일부 이미지에 대해 모든 관절이 라벨링되지 않은 경우에도 사용할 수 있음을 유의해야 합니다. 이 경우, 합계에서 해당 항목들이 생략됩니다.
위의 매개변수 $θ$는 분산 온라인 구현에서 역전파를 사용하여 최적화됩니다. 크기 128의 각 미니 배치에 대해 적응형 기울기 업데이트가 계산됩니다 [3]. 가장 중요한 매개변수인 학습률은 0.0005로 설정됩니다. 모델은 많은 수의 매개변수를 가지고 있고 사용된 데이터셋의 크기가 상대적으로 작기 때문에, 우리는 다수의 랜덤하게 변환된 이미지 자르기(섹션 3.2 참조), 좌/우 뒤집기 및 $F$ 층에 대한 DropOut 정규화를 0.6으로 설정하여 데이터를 증강합니다.
3.2. Cascade of Pose Regressors
이전 섹션의 자세 공식화는 관절 추정이 전체 이미지를 기반으로 하며, 따라서 맥락에 의존한다는 장점을 가지고 있습니다. 그러나 고정된 입력 크기 220 × 220 때문에, 네트워크는 세부 사항을 살펴보는 능력이 제한됩니다 – 이는 거친 스케일에서 자세 특성을 포착하는 필터를 학습합니다. 이것들은 대략적인 자세를 추정하는 데 필요하지만 항상 신체 관절을 정확하게 위치시키기에는 불충분합니다. 이미 많은 매개변수의 수를 더 증가시킬 수 있기 때문에 입력 크기를 쉽게 늘릴 수 없음을 유의하십시오. 더 나은 정밀도를 달성하기 위해, 우리는 자세 회귀자의 연쇄 구조를 훈련시키기를 제안합니다. 첫 번째 단계에서는, 연쇄 구조가 이전 섹션에서 설명한 대로 초기 자세를 추정하는 것으로 시작합니다. 후속 단계에서는, 추가적인 DNN 회귀자들이 이전 단계에서 관절 위치의 변위를 실제 위치로 예측하도록 훈련됩니다. 따라서 각 후속 단계는 현재 예측된 자세의 정제 과정으로 간주될 수 있으며, 이는 그림 2에 나타나 있습니다.
또한, 각 후속 단계는 예측된 관절 위치를 사용하여 이미지의 관련 부위에 집중합니다 – 하위 이미지는 이전 단계에서 예측된 관절 위치 주변에서 잘리고, 이 관절에 대한 자세 변위 회귀자가 이 하위 이미지에 적용됩니다. 이렇게 해서, 후속 자세 회귀자들은 더 높은 해상도의 이미지를 보게 되며, 더 미세한 스케일의 특징을 학습하여 궁극적으로 더 높은 정밀도를 달성하게 됩니다.
우리는 연쇄 구조의 모든 단계에서 동일한 네트워크 아키텍처를 사용하지만, 서로 다른 네트워크 매개변수를 학습합니다. 전체 $S$개의 연쇄 단계 중에서 단계 $s∈{1,…,S}$에 대해 학습된 네트워크 매개변수를 $θ_s$ 로 나타냅니다. 따라서, 자세 변위 회귀자는 $ψ(x;θ_s)$ 로 표현됩니다. 주어진 관절 위치 $y_i$ 를 정제하기 위해, 우리는 $y_i$ 주변의 하위 이미지를 포착하는 관절 경계 상자 $b_i$ 를 고려합니다: $b_i(\mathbf{y};σ)=(y_i,σ\text{diam}(y))$ 이때 중심은 $i$번째 관절이고, 차원은 $σ$에 의해 스케일링된 자세 지름입니다. 자세의 지름 $\text{diam}(y)$ 는 인간 상체에서 반대편 관절, 예를 들어 왼쪽 어깨와 오른쪽 엉덩이 사이의 거리로 정의되며, 구체적인 자세 정의와 데이터셋에 따라 달라집니다. 위의 표기법을 사용하여, 단계 $s=1$에서는 전체 이미지를 포함하거나 사람 감지기에 의해 얻어진 경계 상자
$b_0$ 로 시작합니다. 우리는 초기 자세를 얻습니다:
각 후속 단계 $s≥2$에서 모든 관절 $i∈{1,…,k}$ 에 대해, 우리는 이전 단계 $(s−1)$ 에서 정의된 하위 이미지 $b_i^{s−1}$ 에 회귀자를 적용하여 먼저 정제된 변위 $y_i^s - y_i^{s−1}$ 를 회귀합니다. 그런 다음, 새로운 관절 상자 $b_i^s$ 를 추정합니다:
\[\begin{equation} \text{Stage } s = \mathbf{y}_i^s \leftarrow \mathbf{y}_i^{s-1} + N^{-1}(\psi_i(N(x;b);\theta_s);b) \end{equation}\] \[\text{for } b= b_i^{(s-1)} \\\] \[\begin{equation} b_i^s \leftarrow(\mathbf{y}_i^s, \sigma\text{diam}(\mathbf{y}^s), \sigma\text{diam}(\mathbf{y}^s)) \end{equation}\]우리는 섹션 4.1에서 설명된 대로 결정된 고정된 단계 수 $S$ 에 대해 연쇄 구조를 적용합니다.
Training
네트워크 매개변수 $θ_1$ 는 섹션 3.1의 방정식 (4)에 따라 훈련됩니다. 후속 단계 $s≥2$ 에서는 훈련이 동일하게 수행되지만 중요한 차이점이 있습니다. 훈련 예제 $(x,\mathbf{y})$의 각 관절 $i$ 는 이전 단계에서 얻은 동일한 관절에 대한 예측을 중심으로 한 다른 경계 상자 $(\mathbf{y}_i^{(s−1)},σ\text{diam}(\mathbf{y}^{(s−1)}),σ\text{diam}(\mathbf{y}^{(s−1)}))$ 를 사용하여 정규화됩니다. 이를 통해 우리는 이전 단계의 모델을 기반으로 해당 단계의 훈련을 조정합니다.
딥러닝 방법은 큰 용량을 가지고 있기 때문에, 우리는 각 이미지와 관절에 대해 여러 정규화를 사용하여 훈련 데이터를 증강합니다. 이전 단계의 예측만 사용하는 대신, 우리는 시뮬레이션된 예측을 생성합니다. 이는 훈련 데이터의 모든 예제에 걸쳐 관찰된 변위 $(y_i^{(s−1)}−y_i)$ 의 평균과 분산에 해당하는 평균과 분산을 가진 2차원 정규 분포 $\mathcal{N}_i^{(s−1)}$ 에서 임의로 샘플링된 벡터에 의해 관절 $i$에 대한 실제 위치를 임의로 변위시켜 수행됩니다. 완전히 증강된 훈련 데이터는 처음에 예제를 샘플링하고 원본 데이터에서 균일하게 관절을 샘플링한 다음, $\mathcal{N}_i^{(s−1)}$ 에서 샘플링된 변위 $δ$에 기반한 시뮬레이션된 예측을 생성하여 정의할 수 있습니다:
연쇄 구조의 단계 $s$ 에 대한 훈련 목표는 각 관절에 대해 올바른 정규화를 사용하여 방정식 (4)와 동일하게 수행됩니다:
\[\begin{equation} \theta_s = \arg\min_\theta \sum_{(x, \mathbf{y}_i)\in D_A^s} \Vert\mathbf{y}_i - \psi_i(x;\theta) \Vert_2^2 \end{equation}\]4. Empirical Evaluation
4.1. Setup
Datasets
인간 자세 추정을 위한 다양한 벤치마크가 존재합니다. 이 연구에서는 제안된 DNN과 같은 큰 모델을 훈련하기에 충분한 수의 훈련 예제를 가지고 있으며, 현실적이고 도전적인 데이터셋을 사용합니다.
우리가 사용하는 첫 번째 데이터셋은 [20]에서 소개된 FLIC(Frames Labeled In Cinema)로, 인기 있는 할리우드 영화에서 얻은 4000개의 훈련 이미지와 1000개의 테스트 이미지로 구성됩니다. 이 이미지들은 다양한 자세와 특히 다양한 의상을 입은 사람들을 포함합니다. 라벨이 지정된 각 인간의 경우, 10개의 상체 관절이 라벨링됩니다.
우리가 사용하는 두 번째 데이터셋은 Leeds Sports Dataset(LSP) [12]와 그 확장판 [13]이며, 이를 LSP로 통칭합니다. 이 데이터셋들은 합쳐서 11000개의 훈련 이미지와 1000개의 테스트 이미지를 포함합니다. 이 데이터셋들은 스포츠 활동 이미지로, 외형과 특히 관절에 대한 도전이 상당히 큽니다. 게다가, 대부분의 사람들은 150픽셀 높이를 가지며, 이는 자세 추정을 더욱 어렵게 만듭니다. 이 데이터셋에서, 각 사람의 전체 몸이 총 14개의 관절로 라벨링됩니다.
위의 모든 데이터셋에 대해, 우리는 자세 $y$의 지름을 양쪽 어깨와 엉덩이 사이의 거리로 정의하며, 이를 $
\text{diam}(y)$ 로 나타냅니다. 모든 데이터셋에서 관절은 인간의 몸을 동적으로 모방하는 트리 형태로 배열되어 있다는 점에 유의해야 합니다. 이는 포즈 트리에서 인접한 관절 쌍으로 사지를 정의할 수 있게 합니다.
Metrics
공개된 결과와 비교할 수 있도록 두 가지 널리 받아들여진 평가 지표를 사용할 것입니다. 정확한 부분 비율(PCP)은 사지의 검출률을 측정하며, 예측된 두 관절 위치와 실제 사지 관절 위치 사이의 거리가 사지 길이의 절반 이하일 때 사지가 검출된 것으로 간주됩니다 [5]. PCP는 초기에는 평가를 위한 선호 지표였으나, 보통 감지하기 어려운 짧은 사지, 예를 들어 하박 같은 경우에는 불이익을 준다는 단점이 있습니다.
이러한 단점을 해결하기 위해, 최근에는 관절의 검출률이 다른 검출 기준을 사용하여 보고되고 있습니다 – 예측된 관절과 실제 관절 사이의 거리가 상체 지름의 특정 비율 이내일 경우 관절이 검출된 것으로 간주됩니다. 이 비율을 조정하여 다양한 정도의 위치 정밀도에 대한 검출률을 얻습니다. 이 지표는 모든 관절에 대해 동일한 거리 임계값을 기반으로 검출 기준이 설정되기 때문에 PCP의 단점을 완화합니다. 우리는 이 지표를 검출된 관절의 비율(PDJ)이라고 부릅니다.
Experimental Details
모든 실험에서 우리는 동일한 네트워크 아키텍처를 사용합니다. [7]에서 영감을 받아, 우리는 FLIC에서 신체 감지기를 사용하여 초기에는 인간 신체 경계 상자의 대략적인 추정을 얻습니다. 이것은 얼굴 감지기를 기반으로 하며, 감지된 얼굴 직사각형이 고정된 스케일러로 확대됩니다. 이 스케일러는 모든 라벨링된 관절을 포함하도록 훈련 데이터에서 결정됩니다. 이 얼굴 기반 신체 감지기는 대략적인 추정을 제공하지만, 이는 우리의 접근법에 좋은 출발점을 제공합니다. LSP의 경우, 초기 경계 상자로 전체 이미지를 사용합니다. 이는 인간이 설계상 비교적 꽉 맞게 잘려있기 때문입니다.
알고리즘 하이퍼파라미터를 결정하기 위해 두 데이터셋에 대해 50개의 이미지를 포함하는 작은 홀드아웃 세트를 사용했습니다. 매개변수의 최적성을 측정하기 위해 모든 관절에 대해 PDJ 0.2에서의 평균을 사용했습니다. 포즈 크기의 일부로서 정제된 관절 경계 상자의 크기를 정의하는 스케일러 $σ$ 는 다음과 같이 결정됩니다: FLIC의 경우, 우리는 {0.8, 1.0, 1.2} 값을 탐색한 후 $σ=1.0$ 을 선택했습니다. LSP의 경우, {1.5, 1.7, 2.0, 2.3}을 시도한 후 $σ=2.0$ 을 사용했습니다. 연쇄 단계 $S$ 의 수는 알고리즘이 홀드아웃 세트에서 더 이상 개선되지 않을 때까지 훈련 단계에 의해 결정됩니다. FLIC와 LSP 모두에서 우리는 $S=3$ 에 도달했습니다.
일반화를 개선하기 위해, $s=2$에서 시작하는 각 연쇄 단계에 대해, 우리는 섹션 3.2에서 설명한 대로 각 관절에 대해 무작위로 이동 된 자르기 상자를 40개 샘플링하여 훈련 데이터를 증강합니다. 따라서, LSP의 경우 14개의 관절과 이미지를 미러링한 후, 훈련 예제 수를 샘플링하면 $11000 × 40 × 2 × 14 = 12M$ 이 됩니다. 이는 우리와 같은 대규모 네트워크를 훈련시키는 데 필수적입니다.
제시된 알고리즘은 효율적인 구현을 가능하게 합니다. 실행 시간은 12코어 CPU에서 측정한 결과, 이미지당 약 0.1초입니다. 이것은 다른 접근법들과 비교하여 유리하며, 현재 최첨단 접근법 중 일부는 더 높은 복잡성을 가지고 있습니다: [20]은 약 4초, [27]은 1.5초가 소요됩니다. 그러나, 훈련 복잡성은 더 높습니다. 초기 단계는 약 100명의 워커(worker)에서 3일 이내에 훈련되었으며, 대부분의 최종 성능은 12시간 후에 달성되었습니다. 각 정제 단계는 섹션 3.2에서의 데이터 증강 때문에 초기 단계보다 40배 더 많은 데이터를 사용하여 7일 동안 훈련되었습니다. 더 많은 데이터를 사용한 것이 성능 향상으로 이어졌음을 유의하십시오.
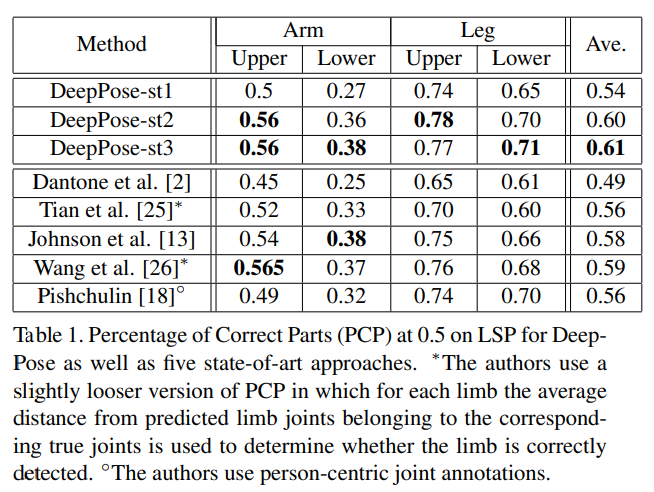
4.2. Results and Discussion
Comparisons
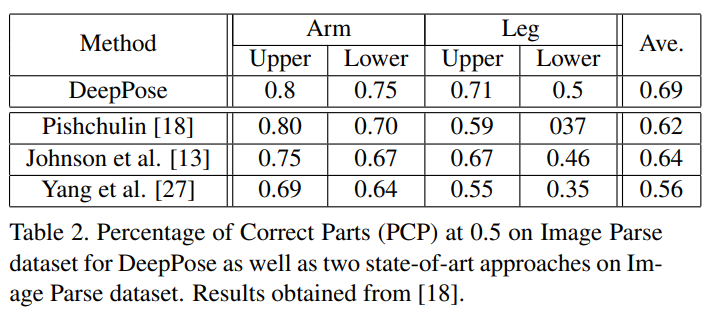
우리는 다른 접근법들과의 비교 결과를 제시합니다. 우리는 그림 1에서 PCP 지표를 사용하여 LSP에서 비교합니다. 우리는 가장 도전적인 네 가지 사지 – 하박, 상박, 다리 – 그리고 비교된 모든 알고리즘에 대한 이러한 사지들의 평균 값을 보여줍니다. 우리는 분명히 다른 모든 접근법보다 우수하며, 특히 다리에 대한 더 나은 추정을 달성했습니다. 예를 들어, 상체 다리의 경우, 우리는 다음으로 좋은 성능을 보인 방법에 대해 0.74에서 0.78을 얻었습니다. 다른 접근법들이 특정 사지에 대해 강점을 보이지만, 다른 어떤 데이터셋도 모든 사지에서 일관되게 우위를 점하지 않는다는 점을 주목할 만합니다. 반대로, DeepPose는 모든 도전적인 사지에 대해 강력한 결과를 보여줍니다.
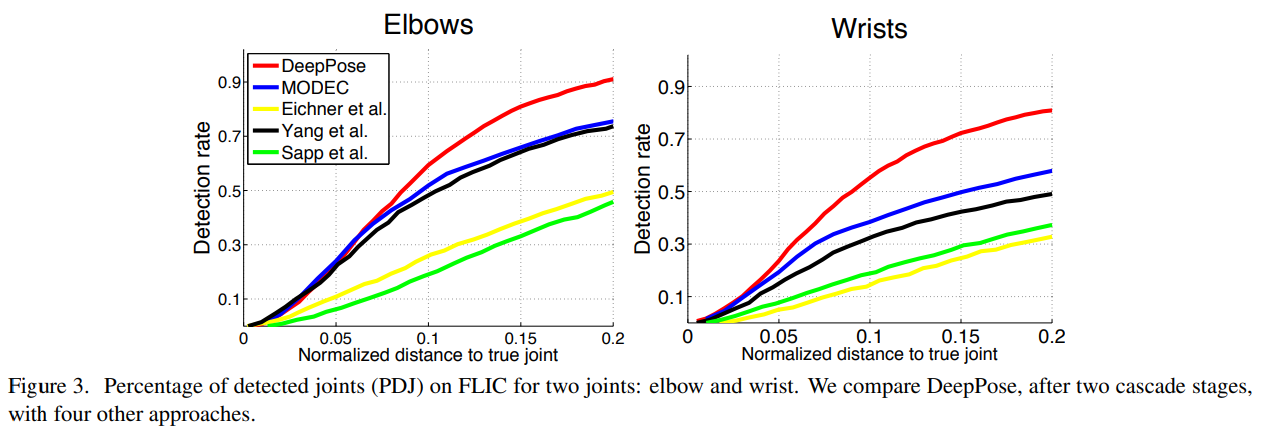
PDJ 지표를 사용하면 예측과 실제 값 사이의 거리 임계값을 변경하여 감지를 정의할 수 있습니다. 이 임계값은 감지율이 플로팅되는 위치 정밀도로 간주될 수 있습니다. 따라서 원하는 다양한 정밀도에 따라 접근법을 비교할 수 있습니다. 우리는 그림 3에서 FLIC에 대한 결과를 제시하며, 추가적인 네 가지 방법과 비교하고, 그림 4에서 LSP에 대한 결과를 제시합니다. 각 데이터셋에 대해, 우리는 각 데이터셋의 프로토콜에 따라 훈련하고 테스트합니다. 이전 실험과 유사하게, 우리는 모든 다섯 가지 알고리즘을 능가합니다. 우리의 이익은 낮은 정밀도 영역에서 더 크며, 관절을 정확하게 위치시키지 않고 대략적인 자세를 감지하는 경우에 그렇습니다. FLIC에서, 정규화된 거리 0.2에서 우리는 다음으로 좋은 성능을 보인 방법에 비해 팔꿈치와 손목의 감지율이 각각 0.15와 0.2 증가했습니다. LSP에서, 정규화된 거리 0.5에서 우리는 0.1의 절대 증가를 얻었습니다. LSP의 정규화된 거리 0.2의 낮은 정밀도 영역에서, 우리는 다리에서 비슷한 성능을 보여주었고, 팔에서는 약간 낮은 성능을 보였습니다. 이는 DNN 기반 접근법이 7개의 변환 층을 사용하여 관절 좌표를 계산하며, 그 중 일부는 최대 풀링을 포함한다는 사실에 기인할 수 있습니다.
또 다른 관찰은 우리의 접근법이 외형이 무거운 영화 데이터와 LSP의 스포츠 이미지와 같은 복잡한 관절 구조 모두에 대해 잘 작동한다는 점입니다.
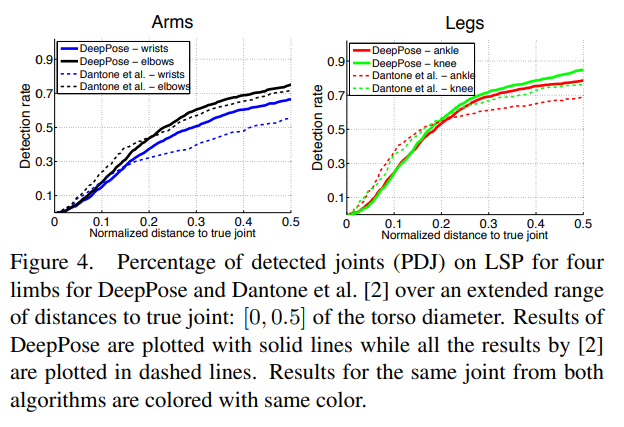
Effects of cascade-based refinement
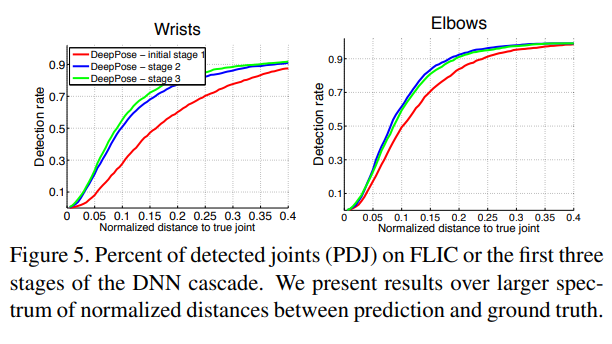
단일 DNN 기반 관절 회귀자는 대략적인 관절 위치를 제공합니다. 그러나 더 높은 정밀도를 얻기 위해서는, 초기 예측을 정제하는 역할을 하는 연쇄 구조의 후속 단계들이 매우 중요합니다. 이를 확인하기 위해, 그림 5에서 초기 예측과 두 가지 후속 연쇄 단계에 대한 다른 정밀도의 관절 검출을 제시합니다. 예상대로, 정제 과정의 주요 이득은 정규화된 거리 [0.15, 0.2]의 고정밀 영역에서 발생합니다. 또한, 주요 이득은 정제의 한 단계를 거친 후에 달성됩니다. 그 이유는 후속 단계들이 각 관절 주변의 더 작은 하위 이미지를 사용하게 되기 때문입니다. 그리고 후속 단계들이 더 높은 해상도의 입력을 보지만, 맥락은 더 제한적입니다.
정제가 도움이 되는 사례들은 그림 6에 시각화되어 있습니다. 초기 단계는 대략적으로 올바른 자세를 추정하는 데 성공하지만, 이 자세는 올바르게 “스냅”되지 않습니다. 예를 들어, 세 번째 줄에서는 자세가 올바른 형태이지만, 크기가 잘못되었습니다. 두 번째 줄에서는 예측된 자세가 이상적인 자세에서 북쪽으로 변환되었습니다. 대부분의 경우, 연쇄 구조의 두 번째 단계는 이 스냅 문제를 해결하고 관절을 더 잘 정렬합니다. 첫 번째 줄과 같은 드문 경우에는, 추가적인 연쇄 단계가 개별 관절을 개선합니다.

Cross-dataset Generalization
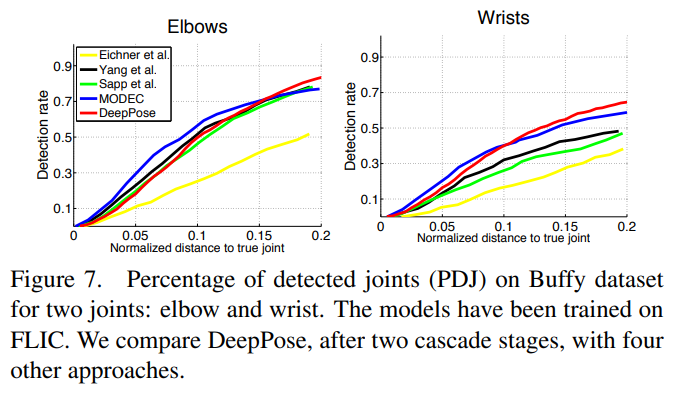
우리 알고리즘의 일반화 속성을 평가하기 위해, 우리는 LSP와 FLIC에서 훈련된 모델을 두 가지 관련 데이터셋에 사용했습니다. LSP에서 훈련된 전신 모델은 Image Parse 데이터셋 [19]의 테스트 부분에서 테스트되었으며, 결과는 표 2에 제시되었습니다. ImageParse 데이터셋은 스포츠를 하는 사람들을 포함하는 LSP와 유사하지만, 다른 활동에 참여한 개인 사진 모음에서 온 많은 사람들을 포함하고 있습니다. 또한, FLIC에서 훈련된 상체 모델은 전체 Buffy 데이터셋 [7]에 적용되었습니다. 우리는 우리의 접근 방식이 다른 접근 방식과 비교하여 최첨단 성능을 유지할 수 있음을 알 수 있습니다. 이는 우수한 일반화 능력을 보여줍니다.
Example poses

우리 알고리즘의 성능을 더 잘 이해하기 위해, 우리는 그림 8의 LSP 이미지에서 추정된 자세 샘플을 시각화합니다. 우리는 우리의 알고리즘이 다양한 조건에서 대부분의 관절에 대해 올바른 자세를 얻을 수 있음을 알 수 있습니다: 뒤집힌 사람들(1열, 1열), 심한 단축(1열, 3열), 비정상적인 자세(3열, 5열), 3열, 2열 및 6열에서 가려진 팔과 같은 가려진 사지, 비정상적인 조명 조건(3열, 3열). 대부분의 경우, 추정된 자세가 정확하지 않을 때에도 여전히 올바른 모양을 가지고 있습니다. 예를 들어, 마지막 줄에서는 예측된 사지 중 일부가 실제 위치와 일치하지 않지만, 자세의 전체적인 모양은 올바릅니다. 일반적인 실패 모드는 사람이 뒤에서 촬영되었을 때 좌측과 우측을 혼동하는 것입니다(6열, 6열). FLIC에서의 결과(그림 9 참조)는 보통 더 나으며, 가끔 하박에서 눈에 띄는 실수가 나타납니다.

5. Conclusion
우리는 인간 자세 추정에 딥 뉴럴 네트워크(DNN)를 처음으로 적용한 것으로 알고 있습니다. 관절 좌표에 대한 DNN 기반 회귀로 문제를 정식화하고, 그러한 회귀자의 연쇄 구조를 제시함으로써, 문맥을 포착하고 전체적으로 자세를 추론하는 데 유리합니다. 결과적으로, 우리는 여러 도전적인 학술 데이터셋에서 최첨단 또는 그 이상의 결과를 달성할 수 있었습니다.
또한, 원래 분류 작업을 위해 설계된 일반적인 컨볼루션 신경망을 사용하여 다른 위치 지정 작업에 적용할 수 있음을 보여줍니다. 미래에는 일반적인 위치 지정 문제와 특히 자세 추정에 더 적합하게 맞춰질 수 있는 새로운 아키텍처를 연구할 계획입니다.
Acknowledgements
데이터 및 유익한 논의에 도움을 주신 Luca Bertelli, Ben Sapp, Tianli Yu에게 감사드립니다.
Alexander Toshev, Christian Szegedy DeepPose: Human Pose Estimation via Deep Neural Networks

댓글남기기