

개요
YOLOv1부터 YOLOv10까지의 읽는 과정 중 하나. 그 중간중간에 기존 논문에 대한 개선 버전이 여러가지 트릭 및 방법을 사용하여 다양하게 나왔다. Scaled-YOLOv4도 그렇다. 해당 포스팅은 Scaled-YOLOv4: Scaling Cross Stage Partial Network 논문의 얕은 리뷰이다.
해당 논문은 CVPR 2021에 퍼블리시되었으며, Darknet 프레임워크 대신 Pytorch 프레임워크에서 개발되었다. Scaled-YOLOv4는 EfficientNet이 NAS를 이용해서 스케일을 확장한 것에서 착안해 경량 장비 및 임베디드 시스템부터 대용량 클라우드 시스템까지 적절한 모델을 제공하기 위해 스케일 확장 및 조절 방법을 연구했다. 그 결과로 YOLOv4-tiny와 YOLOv4-large를 개발하였다.
Model Scaling
- 모델 확장은 수치적으로 늘어나는 정량적인 비용들에 대한 확장이 있고, 저사양 장치나 고성능 장비 같은 장비에 따라 적용할 수 있는 정성적 요인들이 있다고 제안한다.
- 정량적 요인에 대한 모델 확장 요소로 이미지 크기, 레이어 수, 채널 수 등이 있다. 이를 모델 확장에 적용하면 각각 제곱, 선형, 제곱의 계수로 모델의 규모가 증가한다.
- CSPNet 아키텍쳐를 적용하면 파라미터와 연산량을 줄이면서 정확도를 향상시킬 수 있다. 그래서 ResNet, ResNext, Darknet에 테스트 하면서 CSP화 된 모델을 사용한다.
- 저사양 장치에 모델을 사용할 때 고려할 점으로는 연산량, 메모리 대역폭 등이 있는데 제일 큰 영향을 미치는 요인은 메모리 접근 비용(MAC)이다. 그 외에도 DRAM에 대한 IO 횟수 등이 있다.
Scaled-YOLOv4
- 저사양, 일반, 고사양 GPU 세개의 환경을 타겟으로 모델 아키텍쳐를 설계한다.
- 기본적으로 CSP화 된 Darknet53 백본을 사용하고, 넥의 연산량을 줄이기 위해 PAN 아키텍쳐도 CSP화 하였다. 이는 연산량을 40% 줄이는 효과를 보인다.
- 저사양 GPU를 위해 CSPOSANet 아키텍쳐를 사용하며 해당 모델을 YOLOv4-tiny로 명명한다.
- 고사양 GPU를 타겟으로 하여 입력 사이즈를 늘리고 스테이지 설계를 2의 제곱수로 늘려가며 너비 확장을 덧댄 YOLOv4-P5, YOLOv4-P6, YOLOv4-P7을 보인다.
실험 및 기존 모델과의 비교
- Scaled-YOLOv4는 기존의 YOLOv4보다 뛰어난 성능을 보이며 다양한 크기의 모델을 검증한다. 특히 YOLOv4-tiny는 임베디드 장치에서도 뛰어난 효율성을 보인다.
- Scaled-YOLOv4는 EfficientDet, RetinaNet등 최신 객체 감지 모델들에 비해 AP와 속도 면에서 모두 경쟁력을 갖추고 있다.
결론
Scaled-YOLOv4는 이 이후 나온 YOLOv5, YOLOv6 등의 논문에 앞서 본격적인 아키텍처에 scale에 따른 확장을 시작한 모델로 볼 수 있다. 앞선 시대에도 비슷한 작업이야 있었지만 본격적으로 저사양 GPU 부터 고성능 클라우드 GPU 서버까지 고려하여 모델의 스케일과 디테일을 연구한 작업물로 볼 수 있다. 그에 따라 객체 감지 모델의 유연성과 확장성에 대한 새로운 가능성을 제시한다.
번역
Abstract
우리는 CSP 접근법에 기반한 YOLOv4 객체 탐지 신경망이 확장 및 축소가 가능하며, 작은 네트워크와 큰 네트워크에 모두 적용 가능하면서도 최적의 속도와 정확도를 유지한다는 것을 보여줍니다. 우리는 깊이, 너비, 해상도뿐만 아니라 네트워크의 구조도 수정하는 네트워크 확장 방식을 제안합니다. YOLOv4-large 모델은 MS COCO 데이터셋에서 Tesla V100에서 ~16 FPS의 속도로 55.5% AP (73.4% AP50)의 최첨단 성능을 달성하였으며, 테스트 시간 증강을 통해 56.0% AP (73.3% AP50)를 달성합니다. 우리가 아는 한, 이것은 현재 출판된 모든 작업 중 COCO 데이터셋에서 가장 높은 정확도입니다. YOLOv4-tiny 모델은 RTX 2080Ti에서 ~443 FPS의 속도로 22.0% AP (42.0% AP50)를 달성하며, TensorRT, 배치 크기=4, FP16 정밀도를 사용하면 YOLOv4-tiny는 1774 FPS를 달성합니다.
1. Introduction
딥러닝 기반의 객체 탐지 기술은 우리의 일상생활에서 많은 응용 분야를 가지고 있습니다. 예를 들어, 의료 이미지 분석, 자율주행차, 비즈니스 분석, 그리고 얼굴 인식 등이 모두 객체 탐지에 의존합니다. 위에서 언급한 응용 프로그램에 필요한 컴퓨팅 시설은 클라우드 컴퓨팅 시설, 일반 GPU, IoT 클러스터 또는 단일 임베디드 장치일 수 있습니다. 효과적인 객체 탐지기를 설계하기 위해서는 모델 확장 기술이 매우 중요합니다. 이 기술은 다양한 유형의 장치에서 객체 탐지기가 높은 정확도와 실시간 추론을 달성할 수 있게 해주기 때문입니다.
가장 일반적인 모델 확장 기술은 백본의 깊이(신경망의 레이어 수)와 너비(레이어 내 필터 수)를 변경한 다음, 다양한 장치에 적합한 신경망을 학습시키는 것입니다. 예를 들어, ResNet 시리즈 중 ResNet-152와 ResNet-101은 클라우드 서버 GPU에서 자주 사용되며, ResNet-50과 ResNet-34는 개인용 컴퓨터 GPU에서 자주 사용되고, ResNet-18과 ResNet-10은 저사양 임베디드 시스템에서 사용할 수 있습니다. Cai 등 [2]은 단 한 번의 학습으로 다양한 장치 네트워크 아키텍처에 적용할 수 있는 기술을 개발하려고 시도합니다. 그들은 학습과 검색을 분리하고 지식 증류를 사용하여 여러 서브넷을 분리하여 학습하는 기술을 사용하여 전체 네트워크와 서브넷이 목표 작업을 처리할 수 있도록 합니다. Tan 등 [34]은 네트워크 아키텍처 검색(NAS) 기술을 사용하여 EfficientNet-B0에서 복합적 확장(너비, 깊이, 해상도)을 수행하는 방법을 제안했습니다. 그들은 이 초기 네트워크를 사용하여 주어진 계산량에 맞는 최적의 합성곱 신경망(CNN) 아키텍처를 검색하고 이를 EfficientNet-B1으로 설정한 후, 선형 확장 기법을 사용하여 EfficientNet-B2에서 EfficientNet-B7을 얻습니다. Radosavovic 등 [27]은 방대한 파라미터 검색 공간인 AnyNet에서 제약 조건을 요약하고 추가한 후, CNN의 최적 깊이, 병목 비율 및 너비 증가 비율을 찾기 위해 RegNet을 설계했습니다. 또한, 객체 탐지를 위해 특별히 제안된 NAS 및 모델 확장 방법이 있습니다 [6, 35].
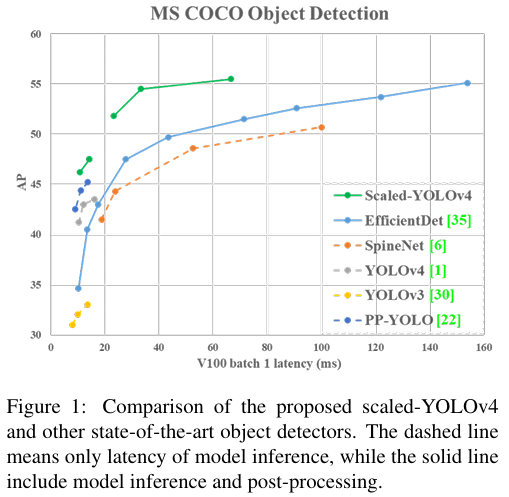
최신 객체 탐지기를 분석한 결과 [1, 3, 6, 26, 35, 40, 44], YOLOv4의 백본인 CSPDarknet53이 [1], 네트워크 아키텍처 검색 기술 [27]을 통해 얻은 거의 모든 최적의 아키텍처 특징과 일치하는 것을 발견했습니다. 따라서 우리는 YOLOv4를 기반으로 모델 확장 기술을 개발하여 scaled-YOLOv4를 제안했습니다. 제안된 scaled-YOLOv4는 그림 1에서와 같이 우수한 성능을 보여주었습니다. 제안된 scaled-YOLOv4에서는 선형 확장 상/하 모델의 상한과 하한을 논의하고, 작은 모델과 큰 모델의 모델 확장에서 주의해야 할 문제들을 각각 분석했습니다. 따라서 우리는 YOLOv4-large와 YOLOv4-tiny 모델을 체계적으로 개발할 수 있게 되었습니다. Scaled-YOLOv4는 속도와 정확도 간의 최적의 균형을 달성할 수 있으며, 15 FPS, 30 FPS, 60 FPS 영화뿐만 아니라 임베디드 시스템에서도 실시간 객체 탐지가 가능합니다.
이 논문의 기여를 요약하면 다음과 같습니다: (1) 경량 CNN의 계산 비용과 메모리 대역폭을 체계적으로 균형 맞출 수 있는 강력한 소형 모델 확장 방법을 설계했습니다; (2) 대형 객체 탐지기를 확장하기 위한 간단하면서도 효과적인 전략을 설계했습니다; (3) 모든 모델 확장 요소 간의 관계를 분석하고 가장 유리한 그룹 분할을 기반으로 모델 확장을 수행했습니다; (4) 실험을 통해 FPN 구조가 본질적으로 일회성 구조임을 확인했습니다; 그리고 (5) 위의 방법을 사용하여 YOLOv4-tiny와 YOLOv4-large를 개발했습니다.
2. Related work
2.1. Real-time object detection
객체 탐지기는 주로 1단계(one-stage) 객체 탐지기 [28, 29, 30, 21, 18, 24]와 2단계(two-stage) 객체 탐지기 [10, 9, 31]로 나눌 수 있습니다. 1단계 객체 탐지기의 출력은 하나의 CNN 연산만으로 얻을 수 있습니다. 2단계 객체 탐지기의 경우, 일반적으로 첫 번째 단계 CNN에서 얻은 높은 점수의 영역 제안을 두 번째 단계 CNN에 전달하여 최종 예측을 수행합니다. 1단계 객체 탐지기와 2단계 객체 탐지기의 추론 시간은 $T_{one} = T_{1st}$와 $T_{two} = T_{1st} + mT_{2nd}$ 로 표현할 수 있으며, 여기서 m은 신뢰도 점수가 임계값보다 높은 영역 제안의 수를 나타냅니다. 오늘날의 인기 있는 실시간 객체 탐지기는 거의 1단계 객체 탐지기입니다. 1단계 객체 탐지기는 주로 두 가지로 나뉩니다: 앵커 기반 [30, 18]과 앵커 없는 방식 [7, 13, 14, 36]. 모든 앵커 없는 방식 중에서 CenterNet [46]은 비최대 억제(NMS)와 같은 복잡한 후처리가 필요 없기 때문에 매우 인기가 있습니다. 현재 더 정확한 실시간 1단계 객체 탐지기는 앵커 기반의 EfficientDet [35], YOLOv4 [1], 그리고 PP-YOLO [22]입니다. 이 논문에서는 YOLOv4 [1]를 기반으로 모델 확장 방법을 개발했습니다.
2.2. Model scaling
전통적인 모델 확장 방법은 모델의 깊이를 변경하는 것, 즉 더 많은 합성곱 레이어를 추가하는 것입니다. 예를 들어, Simonyan 등 [32]이 설계한 VGGNet은 서로 다른 단계에 추가적인 합성곱 레이어를 쌓아 VGG-11, VGG-13, VGG-16, VGG-19 아키텍처를 설계하는 데 이 개념을 사용했습니다. 이후의 방법들은 일반적으로 모델 확장을 위한 동일한 방법론을 따릅니다. He 등 [11]이 제안한 ResNet의 경우, 깊이 확장을 통해 ResNet-50, ResNet-101, ResNet-152와 같은 매우 깊은 네트워크를 구축할 수 있습니다. 이후, Zagoruyko 등 [43]은 네트워크의 너비에 대해 고민했으며, 확장을 실현하기 위해 합성곱 레이어의 커널 수를 변경했습니다. 따라서 그들은 동일한 정확도를 유지하면서 wide ResNet (WRN)을 설계했습니다. WRN은 ResNet보다 더 많은 파라미터를 가지고 있지만, 추론 속도는 훨씬 더 빠릅니다. 이후 DenseNet [12]과 ResNeXt [41]은 깊이와 너비를 고려한 복합 확장 버전을 설계했습니다. 이미지 피라미드 추론의 경우, 실행 시간에 증강을 수행하는 일반적인 방법입니다. 입력 이미지를 받아 다양한 해상도로 스케일링한 후, 이 서로 다른 피라미드 스케일링을 훈련된 CNN에 입력합니다. 최종적으로 네트워크는 여러 세트의 출력을 통합하여 최종 출력을 생성합니다. Redmon 등 [30]은 위의 개념을 사용하여 입력 이미지 크기 스케일링을 수행합니다. 그들은 훈련된 Darknet53에 대해 더 높은 입력 이미지 해상도를 사용해 미세 조정을 수행하며, 이 단계를 실행하는 목적은 더 높은 정확도를 얻기 위함입니다.
최근 몇 년 동안 네트워크 아키텍처 검색(NAS) 관련 연구가 활발하게 진행되었으며, NAS-FPN [8]은 특징 피라미드의 결합 경로를 탐색했습니다. NAS-FPN을 주로 단계 수준에서 실행되는 모델 확장 기술로 볼 수 있습니다. EfficientNet [34]의 경우, 깊이, 너비, 입력 크기를 기반으로 한 복합 확장 검색을 사용합니다. EfficientDet [35]의 주요 설계 개념은 객체 탐지기의 다양한 기능을 가진 모듈을 분해한 다음, 이미지 크기, 너비, #BiFPN 레이어 및 #박스/클래스 레이어에 대해 스케일링을 수행하는 것입니다. NAS 개념을 사용하는 또 다른 설계는 SpineNet [6]으로, 주로 네트워크 아키텍처 검색을 위한 물고기 모양의 객체 탐지기의 전체 아키텍처를 목표로 합니다. 이 설계 개념은 궁극적으로 스케일 조합 구조를 생성할 수 있습니다. NAS 설계를 가진 또 다른 네트워크는 RegNet [27]으로, 주로 단계 수와 입력 해상도를 고정하고, 각 단계의 깊이, 너비, 병목 비율 및 그룹 너비와 같은 모든 매개변수를 깊이, 초기 너비, 기울기, 양자화, 병목 비율, 그리고 그룹 너비로 통합합니다. 마지막으로 그들은 이 여섯 가지 매개변수를 사용하여 복합 모델 확장 검색을 수행합니다. 위의 방법들은 모두 훌륭한 연구이지만, 그 중 소수만이 서로 다른 매개변수 간의 관계를 분석합니다. 이 논문에서는 객체 탐지의 설계 요구 사항을 기반으로 시너지 효과가 있는 복합 확장 방법을 찾으려고 합니다.
3. Principles of model scaling
제안된 객체 탐지기에 대해 모델 확장을 수행한 후, 다음 단계는 정성적 요인과 함께 변경될 정량적 요인들을 처리하는 것입니다. 이러한 요인들에는 모델 추론 시간, 평균 정밀도 등이 포함됩니다. 정성적 요인들은 사용된 장비나 데이터베이스에 따라 다른 이득 효과를 가질 것입니다. 3.1절에서는 정량적 요인을 분석하고 설계할 것입니다. 3.2절과 3.3절에서는 각각 저사양 장치와 고성능 GPU에서 실행되는 소형 객체 탐지기에 관련된 정성적 요인들을 설계할 것입니다.
3.1. General principle of model scaling
효율적인 모델 확장 방법을 설계할 때 우리의 주요 원칙은 스케일이 증가/감소할 때, 증가/감소시키고자 하는 정량적 비용이 낮을수록/높을수록 좋다는 것입니다. 이 섹션에서는 다양한 일반적인 CNN 모델을 보여주고 분석하며, (1) 이미지 크기, (2) 레이어 수, (3) 채널 수의 변화에 직면했을 때의 정량적 비용을 이해하려고 합니다. 우리가 선택한 CNN은 ResNet, ResNext, 그리고 Darknet입니다.
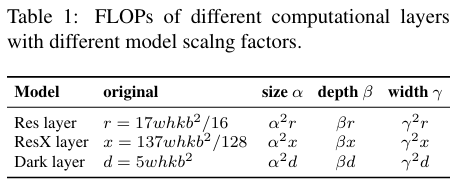
기본 레이어 채널이 $b$인 $k$-layer CNN의 경우, ResNet 레이어의 계산은 $k$*[conv(1 × 1, $b$/4) → conv(3 × 3, $b$/4) → conv(1 × 1, $b$)]이며, ResNext 레이어의 계산은 $k$*[conv(1 × 1, $b$/2) → gconv(3 × 3/32, $b$/2) → conv(1 × 1, $b$)]입니다. Darknet 레이어의 경우, 계산량은 $k$*[conv(1 × 1, $b$/2) → conv(3 × 3, $b$)]입니다. 이미지 크기, 레이어 수, 채널 수를 조정하는 데 사용할 수 있는 확장 계수를 각각 $α$, $β$, $γ$라고 하겠습니다. 이러한 확장 계수가 변할 때, FLOPs의 변화는 표 1에 요약되어 있습니다.
표 1에서 볼 수 있듯이, 크기, 깊이 및 너비의 확장은 계산 비용을 증가시킵니다. 각각은 제곱, 선형, 제곱 증가를 나타냅니다.
Wang 등 [37]이 제안한 CSPNet은 다양한 CNN 아키텍처에 적용될 수 있으며, 파라미터와 연산량을 줄여줍니다. 또한, 정확도를 향상시키고 추론 시간을 단축시킵니다. 우리는 ResNet, ResNeXt, Darknet에 이를 적용하여 계산량의 변화를 관찰했으며, 이는 표 2에 나타나 있습니다.
표 2에 나타난 수치에서 볼 수 있듯이, 위의 CNN을 CSPNet으로 변환한 후 새로운 아키텍처는 ResNet, ResNeXt, Darknet에서 각각 23.5%, 46.7%, 50.0%의 연산량(FLOPs)을 효과적으로 줄일 수 있습니다. 따라서 우리는 모델 확장을 수행하기 위한 최적의 모델로 CSP화된 모델을 사용합니다.

3.2. Scaling Tiny Models for Low-End Devices
저사양 장치의 경우, 설계된 모델의 추론 속도는 연산량과 모델 크기에만 영향을 받는 것이 아니라, 주변 하드웨어 자원의 제한도 고려해야 합니다. 따라서 소형 모델을 확장할 때는 메모리 대역폭, 메모리 접근 비용(MACs), DRAM 트래픽과 같은 요소도 고려해야 합니다. 이러한 요소들을 고려하기 위해 우리의 설계는 다음 원칙을 준수해야 합니다:
Make the order of computations less than $O(whkb^2)$
경량 모델은 대형 모델과는 달리 적은 양의 연산으로 요구되는 정확도를 달성하기 위해 파라미터 활용 효율이 더 높아야 합니다. 모델 확장을 수행할 때, 우리는 연산 차수가 가능한 한 낮게 유지되기를 바랍니다. 표 3에서, 우리는 DenseNet과 OSANet [15]의 연산 부하와 같은 효율적인 파라미터 활용이 적용된 네트워크를 분석합니다. 여기서 $g$는 성장률을 의미합니다.
일반적인 CNN의 경우, 표 3에 나열된 $g, b, k$ 간의 관계는 $k « g < b$ 입니다. 따라서 DenseNet의 연산 복잡도의 차수는 $O(whgbk)$ 이고, OSANet의 경우 $O(\max(whbg, whkg^2))$ 입니다. 위 두 모델의 연산 복잡도는 ResNet 시리즈의 $O(whkb^2)$ 보다 낮습니다. 따라서 우리는 연산 복잡도가 더 작은 OSANet의 도움을 받아 소형 모델을 설계합니다.

Minimize/balance size of feature map
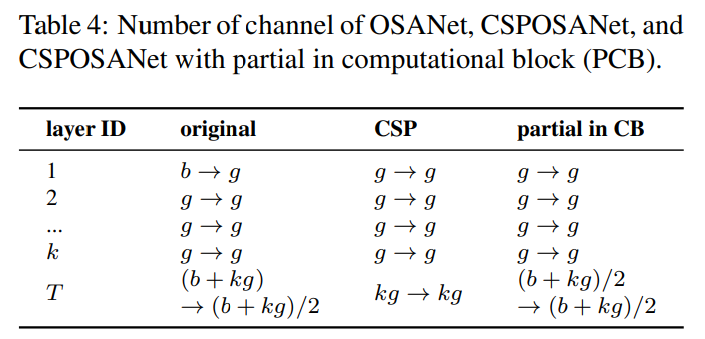
계산 속도 측면에서 최적의 균형을 달성하기 위해, 우리는 CSPOSANet의 계산 블록 사이에서 그라디언트 절단을 수행하는 새로운 개념을 제안합니다. 원래 CSPNet 설계를 DenseNet 또는 ResNet 아키텍처에 적용하는 경우, 이 두 아키텍처의 $j^{th}$ 레이어 출력이 $1^{st}$ 에서 $(j−1)^{th}$ 레이어 출력의 통합이기 때문에 전체 계산 블록을 하나로 취급해야 합니다. OSANet의 계산 블록이 PlainNet 아키텍처에 속하기 때문에, 계산 블록의 어느 레이어에서든 CSPNet을 적용하면 그라디언트 절단 효과를 얻을 수 있습니다. 우리는 이 기능을 사용하여 기본 레이어의 $b$ 채널과 계산 블록에 의해 생성된 $kg$ 채널을 다시 계획하고, 이를 같은 수의 채널을 가진 두 경로로 나눕니다. 이는 표 4에 나타나 있습니다.
채널 수가 $b+kg$ 일 때, 이 채널을 두 경로로 나누고자 한다면, 가장 좋은 분할 방법은 이를 두 개의 동일한 부분으로 나누는 것입니다, 즉 $(b+kg)/2$ 입니다. 하드웨어의 대역폭 $τ$ 를 실제로 고려할 때, 소프트웨어 최적화를 고려하지 않으면, 가장 좋은 값은
$ceil((b+kg)/2τ)×τ$ 입니다. 우리가 설계한 CSPOSANet은 채널 할당을 동적으로 조정할 수 있습니다.
Maintain the same number of channels after convolution
저사양 장치의 연산 비용을 평가하기 위해서는 전력 소비도 고려해야 하며, 전력 소비에 가장 큰 영향을 미치는 요인은 메모리 접근 비용(MAC)입니다. 일반적으로 합성곱 연산에 대한 MAC 계산 방법은 다음과 같습니다:
\[\begin{equation} MAC = hw(C_{in}+C_{out}) + KC_{in}C_{out} \end{equation}\]여기서 $h, w, C_{in}, C_{out}, K$ 는 각각 특징 맵의 높이와 너비, 입력 및 출력 채널 수, 합성곱 필터의 커널 크기를 나타냅니다. 기하학적 부등식을 계산하여 $C_{in}=C_{out}$ 일 때 가장 작은 MAC을 도출할 수 있습니다 [23].
Minimize Convolutional Input/Output (CIO)
CIO [4]는 DRAM IO 상태를 측정할 수 있는 지표입니다. 표 5에는 OSA, CSP, 그리고 우리가 설계한 CSPOSANet의 CIO가 나와 있습니다. $kg>b/2$ 일 때, 제안된 CSPOSANet이 최상의 CIO를 얻을 수 있습니다.

3.3. Scaling Large Models for High-End GPUs
CNN 모델을 확장한 후 정확도를 향상시키고 실시간 추론 속도를 유지하려면, 복합 확장을 수행할 때 객체 탐지기의 다양한 확장 요소들 중 최적의 조합을 찾아야 합니다. 일반적으로 객체 탐지기의 입력, 백본, 넥의 확장 요소를 조정할 수 있습니다. 조정할 수 있는 잠재적 확장 요소들은 표 6에 요약되어 있습니다.

이미지 분류와 객체 탐지의 가장 큰 차이점은 전자는 이미지에서 가장 큰 구성 요소의 범주를 식별하는 것만 필요하지만, 후자는 이미지에서 각 객체의 위치와 크기를 예측해야 한다는 점입니다. 1단계 객체 탐지기에서는 각 위치에 해당하는 특징 벡터를 사용하여 해당 위치의 객체의 범주와 크기를 예측합니다. 객체 크기를 더 잘 예측하는 능력은 기본적으로 특징 벡터의 수용 영역에 의존합니다. CNN 아키텍처에서 수용 영역과 가장 직접적으로 관련된 것은 단계(stage)이며, 특징 피라미드 네트워크(FPN) 아키텍처는 더 높은 단계가 큰 객체를 예측하는 데 더 적합하다고 알려줍니다. 표 7에서는 수용 영역과 여러 매개변수 간의 관계를 설명합니다.

표 7에서 볼 수 있듯이, 너비 확장은 독립적으로 운영될 수 있습니다. 입력 이미지 크기가 증가하면, 큰 객체에 대한 더 나은 예측 효과를 얻으려면 네트워크의 깊이 또는 단계 수를 증가시켜야 합니다. 표 7에 나열된 매개변수들 중 {$\text{size}^{input}$, #stage}의 조합이 가장 큰 영향을 미칩니다. 따라서 확장을 수행할 때 먼저 $\text{size}^{input}$, #stage에 대한 복합 확장을 수행한 후, 실시간 요구 사항에 따라 깊이와 너비에 대한 확장을 각각 수행합니다.
4. Scaled-YOLOv4
이 섹션에서는 일반 GPU, 저사양 GPU, 고사양 GPU를 위한 Scaled YOLOv4 설계에 중점을 둡니다.
4.1. CSP-ized YOLOv4
YOLOv4는 일반 GPU에서 실시간 객체 탐지를 위해 설계되었습니다. 이 하위 섹션에서는 YOLOv4를 재설계하여 YOLOv4-CSP로 만들고, 속도/정확도 간의 최적의 균형을 달성합니다.
백본(Backbone): CSPDarknet53 설계에서 크로스-스테이지 프로세스에 대한 다운샘플링 합성곱의 계산은 잔차 블록에 포함되지 않습니다. 따라서 각 CSPDarknet 단계의 연산량은 $whb^2(9/4+3/4+5k/2)$ 로 추정할 수 있습니다. 위에서 도출된 공식을 통해 CSPDarknet 단계가 $k>1$ 이 충족될 때만 Darknet 단계보다 더 나은 계산적 이점을 가질 것임을 알 수 있습니다. CSPDarknet53의 각 단계에 속한 잔차 레이어 수는 각각 1-2-8-8-4입니다. 더 나은 속도/정확도 균형을 얻기 위해 첫 번째 CSP 단계를 원래 Darknet 잔차 레이어로 변환합니다.
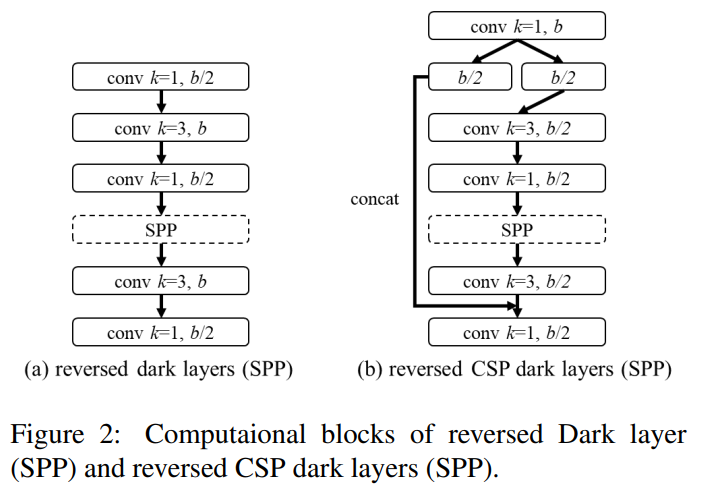
Neck: 연산량을 효과적으로 줄이기 위해, 우리는 YOLOv4의 PAN [20] 아키텍처를 CSP-화했습니다. PAN 아키텍처의 연산 목록은 그림 2(a)에 나와 있습니다. 이 아키텍처는 주로 서로 다른 특징 피라미드에서 오는 특징을 통합한 다음, 숏컷 연결 없이 두 세트의 역방향 Darknet 잔차 레이어를 통과시킵니다. CSP-화 이후, 새로운 연산 목록의 아키텍처는 그림 2(b)에 나와 있습니다. 이 새로운 업데이트는 연산량을 40% 효과적으로 줄입니다.
SPP: SPP 모듈은 원래 neck의 첫 번째 연산 목록 그룹의 중간 위치에 삽입되었습니다. 따라서 우리는 CSPPAN의 첫 번째 연산 목록 그룹의 중간 위치에 SPP 모듈을 삽입했습니다.
4.2. YOLOv4-tiny
YOLOv4-tiny는 저사양 GPU 장치를 위해 설계되었으며, 설계는 3.2절에서 언급된 원칙을 따릅니다.
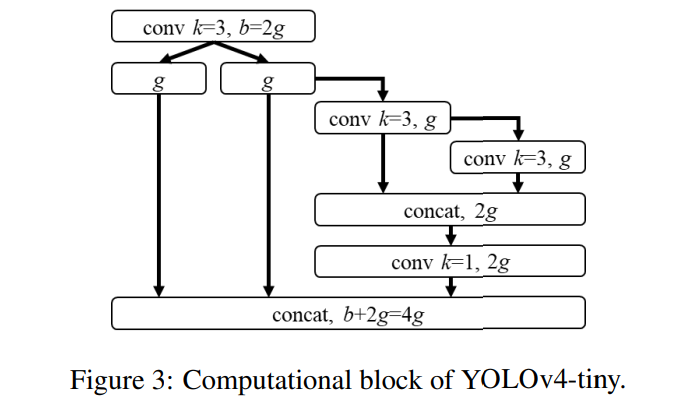
우리는 YOLOv4의 백본을 구성하기 위해 PCB 아키텍처를 가진 CSPOSANet을 사용할 것입니다. 우리는 성장률로서 $g=b/2$ 를 설정하고, 이를 최종적으로 $b/2+kg=2b$ 로 성장시킵니다. 계산을 통해 $k=3$ 을 도출했으며, 그 구조는 그림 3에 나와 있습니다. 각 단계의 채널 수와 넥 부분에 대해서는 YOLOv3-tiny의 설계를 따릅니다.
4.3. YOLOv4-large
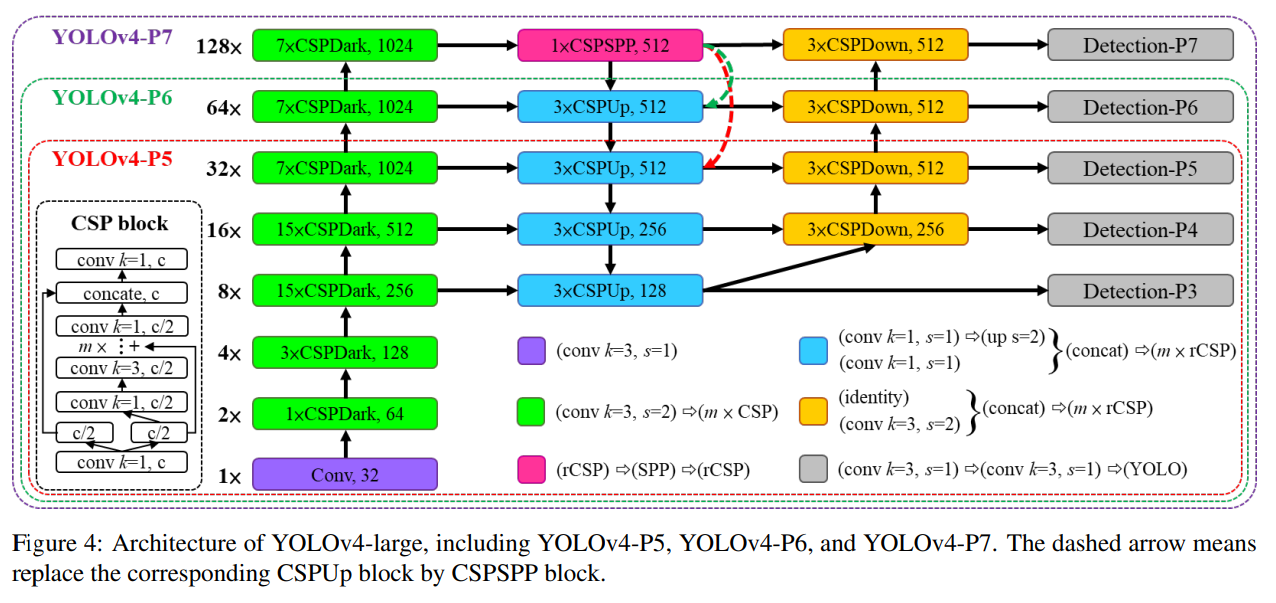
YOLOv4-large는 클라우드 GPU를 위해 설계되었으며, 주요 목적은 객체 탐지의 높은 정확도를 달성하는 것입니다. 우리는 완전히 CSP-화된 모델 YOLOv4-P5를 설계하고, 이를 YOLOv4-P6 및 YOLOv4-P7로 확장했습니다.
그림 4는 YOLOv4-P5, YOLOv4-P6, YOLOv4-P7의 구조를 보여줍니다. 우리는 $\text{size}^{input}$, #stage에 대한 복합 확장을 수행하도록 설계했습니다. 각 단계의 깊이 스케일을 $2^{d_{si}}$ 로 설정하고, $d_s$ 를 [1, 3, 15, 15, 7, 7, 7]로 설정했습니다. 마지막으로, 추론 시간을 제약 조건으로 사용하여 추가적인 너비 확장을 수행했습니다. 우리의 실험 결과, YOLOv4-P6은 너비 확장 계수가 1일 때 30 FPS 비디오에서 실시간 성능을 달성할 수 있음을 보여줍니다. YOLOv4-P7의 경우, 너비 확장 계수가 1.25일 때 16 FPS 비디오에서 실시간 성능을 달성할 수 있습니다.
5. Experiments
우리는 제안된 scaled-YOLOv4를 검증하기 위해 MSCOCO 2017 객체 탐지 데이터셋을 사용합니다. 우리는 ImageNet 사전 학습 모델을 사용하지 않으며, 모든 scaled-YOLOv4 모델은 처음부터 학습되었고, 사용된 도구는 SGD 옵티마이저입니다. YOLOv4-tiny를 학습하는 데 사용된 시간은 600 에포크이며, YOLOv4-CSP를 학습하는 데 사용된 시간은 300 에포크입니다. YOLOv4-large의 경우, 먼저 300 에포크를 실행한 후 더 강력한 데이터 증강 방법을 사용하여 추가로 150 에포크를 학습합니다. 학습률의 앵커와 같은 하이퍼 파라미터의 라그랑지안 승수, 다양한 데이터 증강 방법의 정도를 결정하기 위해 k-means와 유전 알고리즘을 사용합니다. 하이퍼 파라미터와 관련된 모든 세부 사항은 부록에 설명되어 있습니다.
5.1. Ablation study on CSP-ized model
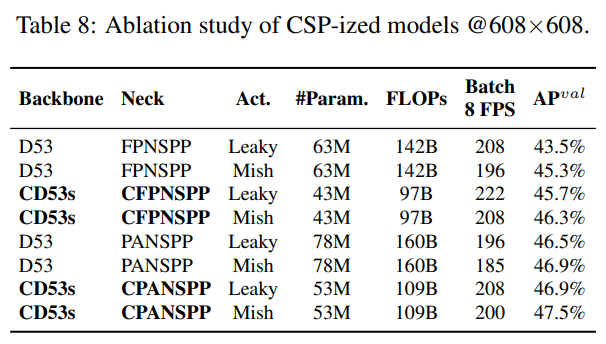
이 하위 섹션에서는 다양한 모델을 CSP-화하고, CSP-화가 파라미터 수, 연산량, 처리량 및 평균 정밀도에 미치는 영향을 분석합니다. 우리는 백본으로 Darknet53(D53)을 사용하고, FPN과 SPP(FPNSPP) 및 PAN과 SPP(PANSPP)를 목으로 선택하여 소거 연구를 설계합니다. 표 8에는 다양한 DNN 모델을 CSP-화한 후의 $\text{AP}^{val}$ 결과가 나열되어 있습니다. 우리는 LeakyReLU(Leaky)와 Mish 활성화 함수를 각각 사용하여 사용된 파라미터 양, 연산량 및 처리량을 비교합니다. 모든 실험은 COCO minval 데이터셋에서 수행되었으며, 결과 AP는 표 8의 마지막 열에 나와 있습니다.
표 8에 나열된 데이터를 보면, CSP-화된 모델은 파라미터와 연산량을 32% 크게 줄였으며, Batch 8 처리량과 AP 모두에서 개선을 가져왔음을 알 수 있습니다. 동일한 프레임 속도를 유지하려면, CSP-화 이후 모델에 더 많은 레이어 또는 더 고급의 활성화 함수를 추가할 수 있습니다. 표 8에 나와 있는 수치를 보면, CD53s-CFPNSPP-Mish와 CD53s-CPANSPP-Leaky 모두 D53-FPNSPP-Leaky와 동일한 Batch 8 처리량을 가지지만, 각각 1% 및 1.6%의 AP 향상을 나타내며, 더 낮은 연산 자원을 사용합니다. 위의 개선된 수치에서 모델 CSP-화가 가져온 큰 이점을 확인할 수 있습니다. 따라서 우리는 YOLOv4-CSP의 백본으로 표 8에서 가장 높은 AP를 기록한 CD53s-CPANSPP-Mish를 사용하기로 결정했습니다.
5.2. Ablation study on YOLOv4-tiny
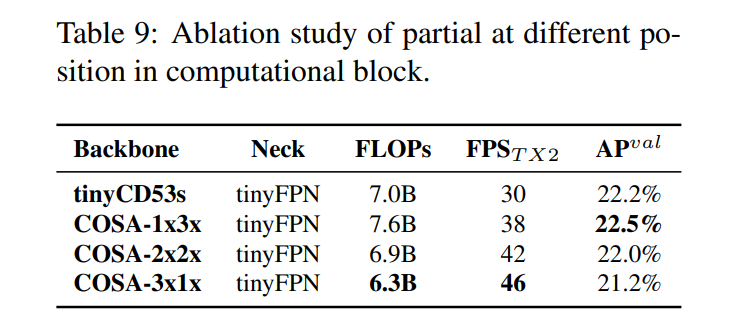
이 하위 섹션에서는 계산 블록에 부분적 기능이 포함된 CSPNet을 사용할 때 얼마나 유연하게 설계될 수 있는지를 보여주는 실험을 설계했습니다. 우리는 또한 CSP-Darknet53과 비교했으며, 여기에서는 너비와 깊이를 선형 축소했습니다. 결과는 표 9에 나와 있습니다.
표 9에 나와 있는 수치에서 알 수 있듯이, 설계된 PCB 기술은 모델을 더 유연하게 만들 수 있으며, 이러한 설계는 실제 요구에 따라 조정될 수 있습니다. 위의 결과로부터 선형 축소가 한계가 있음을 확인했습니다. 제한된 운영 조건에서는 tinyCD53s의 잔차 추가가 추론 속도의 병목현상이 되며, 이는 동일한 연산량을 가진 COSA 아키텍처보다 프레임 속도가 훨씬 낮습니다. 또한 제안된 COSA가 더 높은 AP를 얻을 수 있음을 확인했습니다. 따라서 우리는 실험에서 최고의 속도/정확도 균형을 달성한 COSA-2x2x를 YOLOv4-tiny 아키텍처로 선택했습니다.
5.3. Ablation study on YOLOv4-large
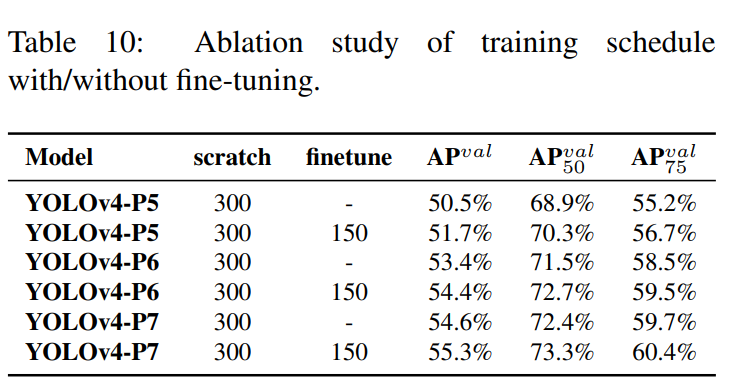
표 10에서는 YOLOv4 모델이 처음부터 학습한 단계와 파인 튜닝 단계를 거쳐 얻은 AP를 보여줍니다.
5.4. Scaled-YOLOv4 for object detection
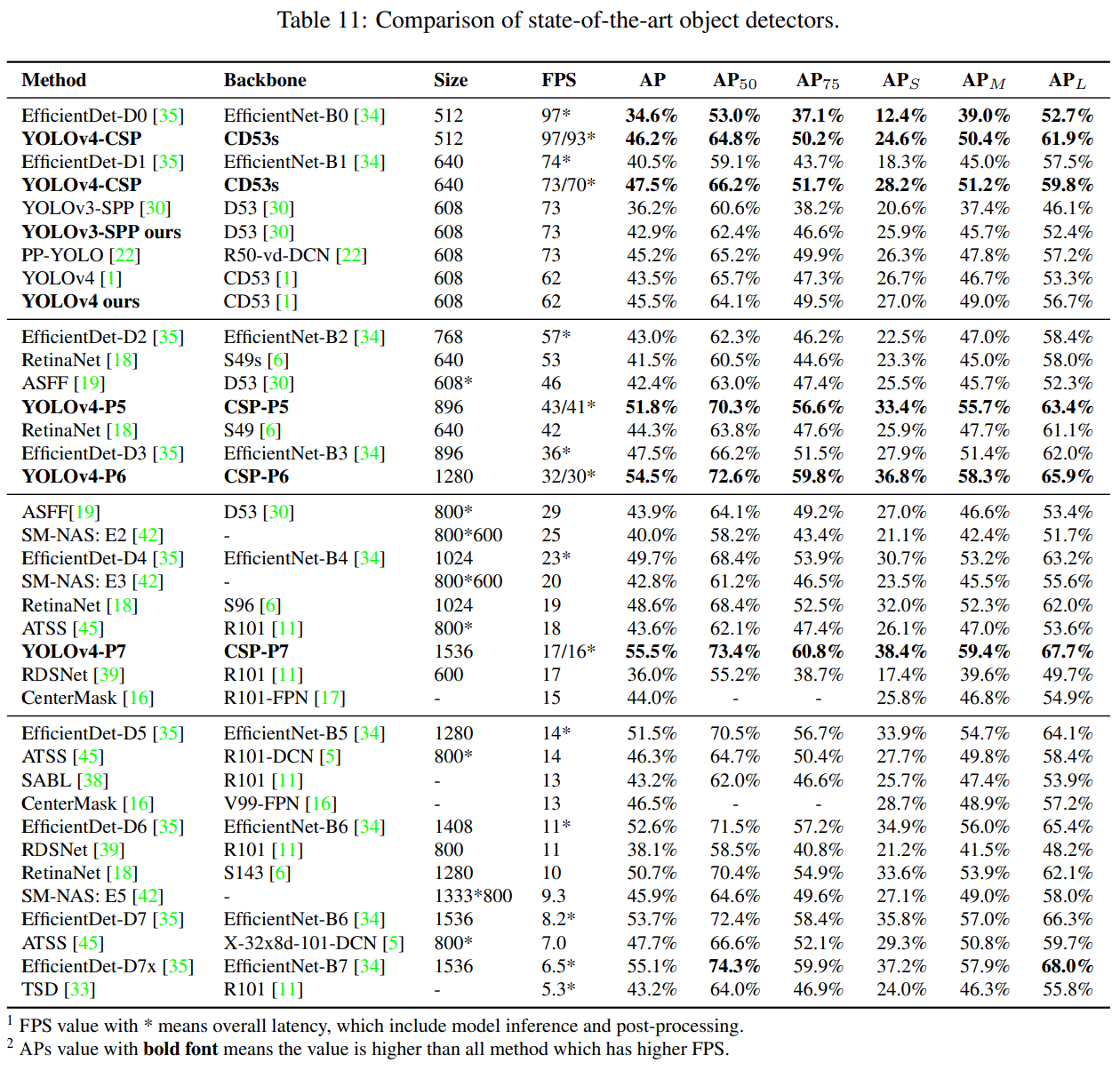
우리는 다른 실시간 객체 탐지기와 비교했으며, 그 결과는 표 11에 나와 있습니다. [$\text{AP}, \text{AP}{50}, \text{AP}{75}, \text{AP}{S}, \text{AP}{M}, \text{AP}_{L}$] 항목에서 굵게 표시된 값은 해당 항목에서 모델이 최고의 성능을 발휘함을 나타냅니다. YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7을 포함한 모든 scaled YOLOv4 모델이 모든 지표에서 파레토 최적임을 확인할 수 있습니다. YOLOv4-CSP를 EfficientDet-D3와 동일한 정확도로 비교했을 때(47.5% vs 47.5%), 추론 속도는 1.9배 빠릅니다. YOLOv4-P5를 EfficientDet-D5와 동일한 정확도로 비교했을 때(51.8% vs 51.5%), 추론 속도는 2.9배 빠릅니다. YOLOv4-P6과 YOLOv4-P7을 각각 EfficientDet-D7 및 EfficientDet-D7x와 비교했을 때, 두 경우 모두 YOLOv4-P6은 3.7배, YOLOv4-P7은 2.5배 빠릅니다. 모든 scaled-YOLOv4 모델은 최첨단 결과를 달성했습니다.
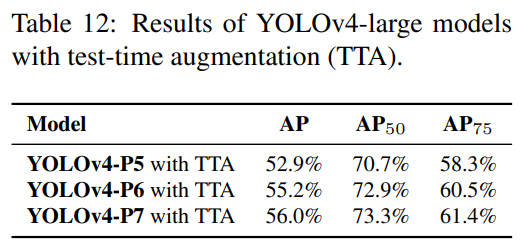
YOLOv4-large 모델의 테스트 시 증강(TTA) 실험 결과는 표 12에 나와 있습니다. TTA가 적용된 후 YOLOv4-P5, YOLOv4-P6, YOLOv4-P7은 각각 1.1%, 0.7%, 0.5% 높은 AP를 얻었습니다.
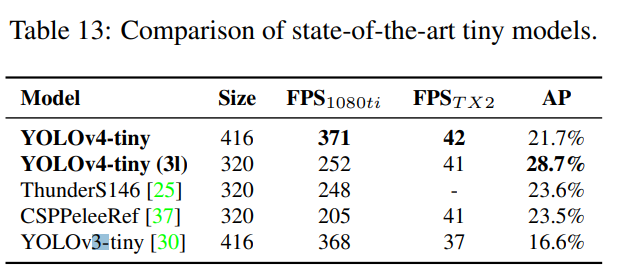
우리는 YOLOv4-tiny의 성능을 다른 소형 객체 탐지기들과 비교하였으며, 그 결과는 표 13에 나와 있습니다. YOLOv4-tiny가 다른 소형 모델들과 비교하여 최고의 성능을 달성했음을 확인할 수 있습니다.
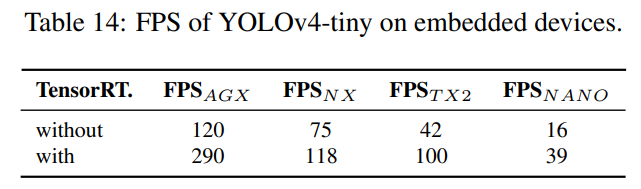
마지막으로, 우리는 Xavier AGX, Xavier NX, Jetson TX2, Jetson NANO를 포함한 다양한 임베디드 GPU에서 YOLOv4-tiny를 테스트했습니다. 우리는 또한 TensorRT FP32(지원되는 경우 FP16)를 사용하여 테스트를 진행했습니다. 다양한 모델에서 얻은 모든 프레임 속도는 표 14에 나와 있습니다. YOLOv4-tiny는 어떤 장치를 사용하더라도 실시간 성능을 달성할 수 있음을 확인할 수 있습니다. FP16과 배치 크기 4를 채택하여 Xavier AGX 및 Xavier NX를 테스트할 경우, 프레임 속도는 각각 380 FPS와 199 FPS에 도달할 수 있습니다. 또한 TensorRT FP16을 사용하여 일반 GPU RTX 2080ti에서 YOLOv4-tiny를 실행할 경우, 배치 크기가 각각 1과 4일 때 프레임 속도는 각각 773 FPS와 1774 FPS에 도달할 수 있습니다. 이는 매우 빠른 속도입니다.
5.5. Scaled-YOLOv4 as na¨ıve once-for-all model
이 절에서는 FPN과 유사한 아키텍처가 순진한 once-for-all 모델임을 보여주는 실험을 설계했습니다. 여기에서 우리는 YOLOv4-P7의 상향식 경로와 탐지 분기의 일부 단계를 제거했습니다. YOLOv4-P7\P7과 YOLOv4-P7\P7\P6는 학습된 YOLOv4-P7에서 {P7}과 {P7, P6} 단계를 제거한 모델을 나타냅니다. 그림 5는 서로 다른 입력 해상도를 가진 가지치기된 모델과 원래 YOLOv4-P7 사이의 AP 차이를 보여줍니다.
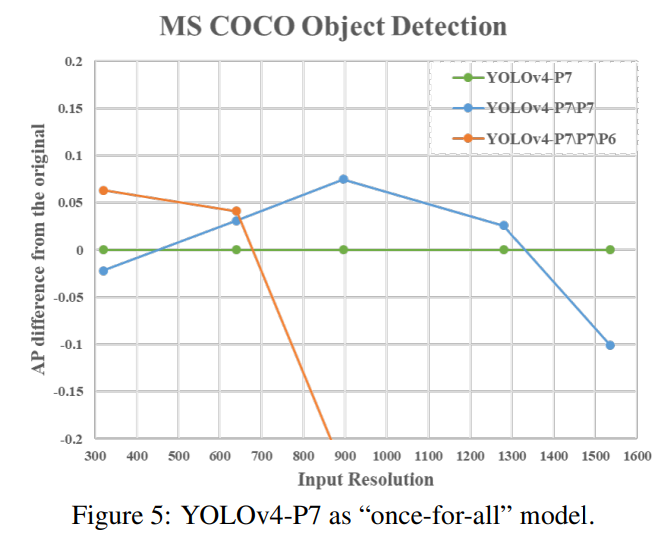
우리는 YOLOv4-P7이 높은 해상도에서 최고의 AP를 기록한 반면, YOLOv4-P7\P7과 YOLOv4-P7\P7\P6는 각각 중간 및 낮은 해상도에서 최고의 AP를 기록한 것을 확인할 수 있습니다. 이는 FPN과 유사한 모델의 서브넷을 사용하여 객체 탐지 작업을 잘 수행할 수 있음을 의미합니다. 또한 모델 아키텍처와 객체 탐지기의 입력 크기를 복합적으로 축소하여 최상의 성능을 얻을 수 있습니다.
6. Conclusions
우리는 CSP 접근법에 기반한 YOLOv4 객체 탐지 신경망이 상향 및 하향으로 확장 가능하며, 소형 및 대형 네트워크 모두에 적용 가능함을 보여주었습니다. 이에 따라 YOLOv4-large 모델은 test-dev COCO 데이터셋에서 56.0%의 AP로 최고 정확도를 달성하였고, TensorRT-FP16을 사용하여 RTX 2080Ti에서 YOLOv4-tiny 소형 모델은 1774 FPS라는 매우 높은 속도를 기록했습니다. 다른 YOLOv4 모델들도 최적의 속도와 정확도를 달성했습니다.
7. Acknowledgements
저자들은 계산 및 저장 자원을 제공해 준 National Center for High-performance Computing (NCHC)에 감사를 표합니다. 코드의 상당 부분은 https://github.com/AlexeyAB, https://github.com/WongKinYiu, 그리고 https://github.com/glenn-jocher 에서 차용되었습니다. 그들의 훌륭한 작업에 감사드립니다.
Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao Scaled-YOLOv4: Scaling Cross Stage Partial Network

댓글남기기