

개요
원문: Learning to Reconstruct 3D Human Pose and Shape
via Model-fitting in the Loop
본인이 본 논문은 SMPL 모델링(포스팅)의 등장 이후 이를 최적화 기반 방식(Optimization-based)으로 단일 RGB 이미지로부터 3차원 모델 파라미터를 추출하는 SMPLify(포스팅)를 보았었다. 그 이후 입력을 단일 이미지 그 자체로 하여 특징 벡터를 통해 카메라 파라미터를 회귀하는 접근 + 적대적 모델의 판별자를 도입하여 성능을 끌어올린 모델 HMR(포스팅)도 읽었다. 이에 이어 SPIN이라고 불리는 Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop 논문을 살펴보고자 한다. 해당 논문은 ICCV 2019에 등재되었고, 3차원 자세를 효과적으로 추정하기 위해 회귀 기반의 모델 접근 방식과 관절 좌표 기반의 최적화 방식을 효율적으로 블렌딩하여 접근한 방법론이다.
SPIN

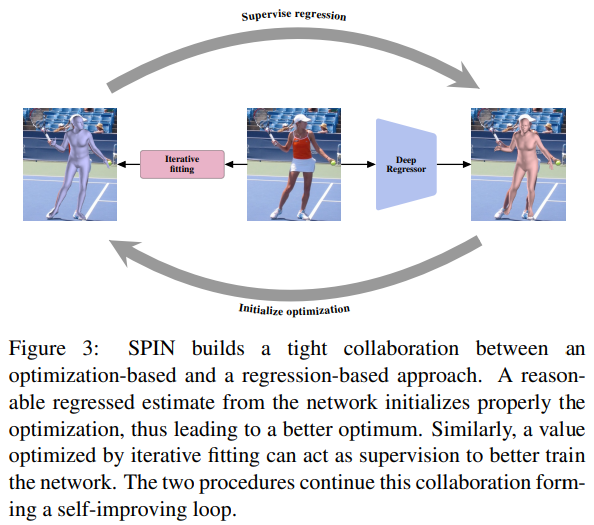
해당 논문의 모델링을 이해하기에 난이도가 높지 않았다. Sec 2. 에서는 기존의 3차원 자세를 추정하기까지의 발전과정들을 언급하며 2가지 접근 방법론을 말한다. 회기 기반의 모델 방식과 2차원-3차원 좌표 기반의 최적화 방식을 언급하는데, 어떤 방법이 더 좋다, 나쁘다를 떠나서 두 방법 간의 긴밀한 콜라보레이션을 주장한다.
일반적으로 입력이 이미지고 출력이 3차원 모델의 파라미터(SMPL의 입력 파라미터라고 생각하면 된다: $\beta, \theta$)를 예측하기 위해선 학습 과정에서의 데이터 셋이 필요하고, 이에 3차원 자세가 포함되어 있는 데이터를 사용한다. 3차원 포즈 혹은 Mesh 데이터는 주로 모션캡쳐 환경에서 수집되기에 일반적인 일상 이미지에는 해당 라벨인 Ground Truth가 있는 데이터 셋이 거의 없다. 이러한 문제를 해결하기 위해 해당 방법론을 제안한다.
간단히 보면 다음과 같은 구조를 가진다.
- 전체 모델의 앞단은 이미지를 입력으로 받고 리그레서 모델이 3차원 파라미터를 회귀 예측한다.
- 리그레서 예측한 파라미터 $\Theta_{reg}$ 는 최적화 루틴이라 불리는 약간의 수정된
SMPLify모듈로 들어가 최적화를 수행한다.- 최적화 된 파라미터는 $\Theta_{opt}$ 로 표시한다.
- 최적화 된 파라미터 $\Theta_{opt}$ 를 라벨로 하여 $\Theta_{reg}$ 와의 차이를 줄이는 방식으로 최적화를 수행한다.
- 해당 과정에서 관절의 재투영 오차 손실이나
SMPL의 3차원 Mesh 차이에 대한 손실도 일부 활용한다.
- 해당 과정에서 관절의 재투영 오차 손실이나
이를 통해 논문이 주장하는 Contribution은 다음과 같다.
- 회귀 기반 방식과 최적화 기반 방식의 콜라보 제안
- 데이터 셋의 3D Ground Truth 가 없어도 학습이 가능
- 명시적인 네트워크로 구축된 모델 기반 학습이고 기존 2D 키포인트 재투영 손실에 대한 개선에 기여
- 3차원 자세 추정 테스크에 대해 SOTA 달성
Notation
논문에서 언급하고 정의하는 수학 기호들에 대해 이해하고 이어서 읽으면 될 듯 하다. 대부분은 SMPL의 표기와 겹쳐 이해가 어렵지 않다.
- $\mathcal{M}(\theta, \beta)$: (6890, 3) 형상을 가진 3차원 Mesh 모델을 지칭. 이 때 Mesh 의 정점의 개수인 $N=6890$ 이다.
- $X$: $k=23$ 의 $k \times 3$ 의 3차원 관절 좌표
- $W$: $\mathcal{M}$ 을 입력으로 하여 $X$ 를 출력으로 하는 선형 리그레션 연산
Regression network
해당 회귀 네트워크는 HMR의 그것을 도입했다고 논문에 나와있다. 다만, 3D Rotation 방식을 도입하여 조금의 차이가 있다고 한다. 여기서 말하는 3D Rotation 방식이 어떻게 다른지 직관적으로는 잘 이해가 되지 않으나 해당 부분은 두 프로젝트 코드의 시행 결과를 비교해보아야 알 듯 하다. 그리고 해당 리그레서 네트워크의 회귀 연산을 $f$ 로 정의한다. 입력은 이미지이고 출력은 HMR의 리그레서 부분과 동일한 Pose, Shape, Camera 파라미터다. 표현은 $\Theta$ 로 한다.
회귀 과정을 단계적으로 살펴보면 다음과 같다.
- 회귀 네트워크는 이미지를 입력으로 받아 3차원 모델 파라미터를 예측한다.
- 즉, 회귀 된 $\Theta_{reg}$ 는 $\theta_{reg}, \beta_{reg}$ 와 카메라 파라미터 $\Pi_{reg}$ 로 구성된다.
- 기억이 맞다면 각 72, 10, 3 의 갯수로(총 85개의 출력) 표현된다.
- 회귀 모델이 추정한 $\theta_{reg}, \beta_{reg}$ 은
SMPL을 통해 Mesh 버텍스 $\mathcal{M}$ 로 유도 된다. - 유도 된 $\mathcal{M}$ 은 3차원 관절 키포인트 $X$ 를 유도할 수 있고, 해당 $X$ 는 카메라 파라미터 $\Pi_{reg}$ 를 통해 투영(Projection)되어 2차원 관절 $J_{reg}$ 를 유도해 낸다.
- 이 과정까지 왔다면 다음 식1 처럼 기존 논문들에서 활용한 2차원 관절 재투영 손실을 정의할 수 있다.
해당 손실(Loss)에 대해서는 학습 효과가 약하다는 논의가 있다고 한다.
Optimization Routine
최적화 루틴은 SMPLify의 목적함수를 사용하는데, 상호관통항(interpenetration)을 제외하고 사용한다. 아래의 식을 최소화하도록 학습하게 하는 것이 목적이다.
- $E_J$ 는 3차원 관절을 투영한 것과 2차원 관절간의 가중치 패널티
- $E_\theta$ 는 Pose Prior 중 하나로 Gaussian Mixture 를 데이터에 맞게 학습한 항
- $E_a$ 는 무릎과 팔꿈치의 비정상적인 자세를 막기위한 손실 항
- $E_\beta$ 는 PCA로 표현된 Shape 파라미터의 2차 손실 항
해당 과정에서는 회귀 네트워크에서 나온 3차원 모델 파라미터를 초기값으로 하여 최적화 과정을 수행한다. 그렇게 하는 이유를 중요시 하는데, 평균 파라미터를 사용하여 최적화 과정의 초기값으로 설정해버리면 학습 과정이 로컬 미니멈(local minimum)에 빠질 수 있기 때문이라 한다. 즉, 이 과정은 학습을 진행하면 할 수 록 최적화 과정을 위한 회귀 모델의 초기 값이 학습하는 데이터에 잘 fitting 되므로 회귀 모듈과 최적화 과정의 연계가 성능을 끌어올리는 데에 효율적이라고 생각하는 충분한 근거가 될 수 있다.
또한 SMPLify 과정은 이미지 1장 당 최적화가 오래걸리는 것이 단점이었는데, 이를 GPU를 통한 배치단위의 병렬처리를 함으로써 처리량을 향상시켰다고 한다. 단, SMPLify에서는 보이지 않는(occlusion) 관절에 대해 DeepCut의 예측 스코어를 사용하였는데, 해당 SPIN 방식에서는 동일한 스코어로 전제한다. 이는 가려져 있는 관절들에 대해 학습에 대한 부정적인 결과를 줄 수 있다는 우려를 남겼다.
Loss
앞선 회귀 네트워크 부분에서는 관절의 재투영 손실만으로는 학습효과가 부족하다고 주장했다. 그래서 해당 논문에서 추가로 도입한 손실 함수가 2가지 더 있다. 아래의 식3, 식4와 같다.
\[L_{\text{3D}} \Vert \Theta_{reg}-\Theta_{opt} \Vert\] \[L_{M} \Vert M_{reg}-M_{opt} \Vert\]이를 통해, 실제로 네트워크가 2차원 관절의 재투영 손실 뿐 아니라, 3차원 파라미터 자체와 형상에 대한 것을 학습하므로 효율적이라고 말한다. HMR에서도 3차원 파라미터에 대한 손실을 이미 도입했었다. 해당 아이디어에서 착안하고 더 발전 시킨 것이지 않을까 싶다.
또한, threshold를 도입하여 관절 재투영 오차를 기반으로 해당 임계값 이하인 이미지들에 대해서는 위에서 언급한 재투영 손실(식1)만을 적용한다. shape 파라미터에 대해서도 표준편차 $\pm 3\sigma$ 인 범위에서는 L2 손실을 적용하여 $\beta$ 에 대한 항만 적용한다고 한다. 이는 너무 극단적인 값들의 학습을 평균으로 모으는 효과가 있다.
Code
기존 포스팅과는 다르게 깃허브의 원본 리포지토리만으로도 2024년 4월 기준 코드를 돌려보는 데에 아무런 문제가 없었다.
- SPIN: https://github.com/nkolot/SPIN
Pytorch 의 최근 버전들이 전부 cuda 11.x 버전을 사용하는 것에 대해 이슈가 있을 까 했는데 해당 리포지토리에 접속해보면 원작자가 cuda11_fix 라는 브랜치를 작업해두어 현재의 코드를 돌리는데 아무런 문제가 없게 해놓았다. 정말 감사한 일이다.
본인이 conda 환경 활용하여 해당 리포지토리를 가동한 환경은 다음과 같다. readme.md에는 python3.10 을 이용하는 것으로 보였는데 본인은 3.8 버전에서 테스트 성공하였다. SMPLify 부터 지금의 SPIN까지 코드를 다뤄보는 것은 전부 학습이 아닌 데모만 돌려보고 있다는 점을 기억하자.
- Python 3.8.18(conda env)
- torch 2.0.1+cu118
- torchvision 0.15.2+cu118
필요한 모델 가져오기
리드미 페이지에도 있지만 해당 데모를 돌리기 위해서 필요한 모델파일을 다운로드 받아야한다. 설명이야 있지만 리포지토리에 있는 fetch_data.sh 파일을 실행시키면 된다.
$ ./fetch_data.sh
그리고 SMPL 의 성별 중립 모델이 필요하다고 한다. 해당 모델은 전 리뷰인 HMR 리포지토리안에서도 받을 수 있었는데 링크를 참고해도 좋다. 원래 정식 루트는 막스플랑크의 SMPLify 홈페이지에서 회원 가입 및 로그인을 하고 라이센스를 준수하여 다운로드 받아야한다.
demo.py & hmr.py
hmr
재미있는 것은 demo.py의 실행 메인부분에 hmr 인스턴스를 불러온다는 점이다. SPIN은 HMR과 거의 유사한 리그레서를 사용한다하였고, 애초에 models/hmr.py 라는 이름으로 hmr의 클래스가 선언되어 있다. 해당 논문(hmr)의 언급된 내용과 같이 resnet50 모델을 기반으로 특징 벡터 2048개의 채널을 추출해주는 인코더를 로드하는 것으로 보인다. (demo.py의 line 104, hmr.py의 line 154 참조) 그래서 기본적으로 해당 클래스에 대한 가중치 파일이라고 들어가는 것이 resnet50에 대한 가중치 + SMPL의 평균 파라미터(SMPLify 최적화 초기화를 위한) + SMPLify 최적화 루틴 레이어에 대한 가중치 등 몇개의 파일로 구성되어 있다.
필요 파일:
- smpl_mean_params.npz
- model_checkpoint.pt
- resnet50 에 대한 가중치는
torchvision으로 부터 가져옴
smpl
그 뒤 SMPL 클래스 인스턴스를 생성한다. 위에서 SMPL의 성별 중립 모델을 다운로드 했다면 config.py의 제일 하단에 있는 SMPL_MODEL_DIR 옵션을 해당 경로로 수정해줘야한다.(config.py line 62) 본인이 받은 모델 파일 명은 neutral_smpl_with_cocoplus_reg.pkl 이었다.
SMPL_MODEL_DIR = 'data/neutral_smpl_with_cocoplus_reg.pkl'
renderer
그 뒤 렌더러 인스턴스도 생성해주는 것을 볼 수 있는데(demo.py line 115), 특이한 점은 opendr 이 아닌 pyrender 라이브러리를 사용했다는 점이다. 기존 코드들이 python 2 기반에 맞춰 작업했다보니 여간 불편한 점이 있었는데 python 3 에서 렌더링을 위해 문제없이 돌아가는 라이브러리를 사용하였다. 추후 나온 프로젝트 들에선 pytorch3d를 사용하는 프로젝트도 있다.
- 렌더러는 초점거리 5000과
SMPL의 face를 파라미터로 받아 인스턴스를 생성한다.
이 이후 이미지에 대한 전처리, 모델에 대한 피드포워드 과정은 사실 HMR의 그것과 다를 바 없다. 해당 모듈이 3차원 관절의 회전행렬, shape에 대한 $\beta$, 카메라 파라미터 $K$ 를 예측하고 이를 통해 SMPL 모델이 3D Mesh Vertices 로 변환한다. 버텍스와 카메라 이동 행렬은 렌더러에 의해 이미지와 합성되어 렌더링 된다.
train
해당 논문의 강점이 두 접근 방식을 콜라보하여 학습 효율성을 올린 것인 만큼 모델 학습에 대한 부분을 아예 안보고 넘어갈 순 없을 것 같다.
train/trainer.py의 init_fn() 부분을 보면 hmr, SMPL, SMPLify, 등 그 외에도 다양한 Loss들이 선언되어 있는 것을 볼 수 있다. 그 외에 train_step() 메소드를 보면 리그레서가 예측한 2D Keypoints 와 Ground Truth 2D Keypoints의 재투영 손실을 계산하는 항목도 볼 수 있고(line 243), 그 외에 다양한 loss 들을 계산하는 것을 볼 수 있다.
# Compute total loss
# The last component is a loss that forces the network to predict positive depth values
loss = self.options.shape_loss_weight * loss_shape +\
self.options.keypoint_loss_weight * loss_keypoints +\
self.options.keypoint_loss_weight * loss_keypoints_3d +\
self.options.pose_loss_weight * loss_regr_pose + self.options.beta_loss_weight * loss_regr_betas +\
((torch.exp(-pred_camera[:,0]*10)) ** 2 ).mean()
loss *= 60
회귀 된 pose와 shape에 대한 loss, 2D, 3D 관절 키포인트에 대한 loss 등의 여러 loss 가 합쳐져서 실제 SPIN의 loss 를 구현하고 있는 것을 볼 수 있다.
run demo
그래서 데모 자체에 대한 실행은 다음 명령어로 실행하였다.
$ python demo.py --checkpoint=data/model_checkpoint.pt --img=examples/im1010.jpg
이미지 파일은 처음부터 리포지토리에 포함되어 있고, .pt 파일은 위의 fetch_data.sh 파일을 통해 받아진다. 데모를 수행하는데에 성공했다면 다음과 같이 결과를 볼 수 있다.

Nikos Kolotouros, Georgios Pavlakos, Michael J. Black, Kostas DaniilidisLearning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop
https://github.com/nkolot/SPIN/
https://github.com/dongle94/hmr_python

댓글남기기