

개요
Stacked Hourglass Networks는 앞서 포스팅 한 CPM과 더불어 ECCV 2016에 발표된 논문이다. 네트워크 아키텍쳐의 모듈이 모래시계를 쌓은 것과 비슷하게 생겼다하여 Stacked Hourglass Network라고 이름이 지어졌다. 해당 논문은 여러 단계를 거쳐 자세 추정의 정확도를 향상시키는 방법을 제안한다.
Stacked Hourglass Design
- 디자인의 시작은 이미지의 모든 스케일에서 정보를 포착할 필요성에 의해 시작된다.
- 다른 접근법들은 여러 해상도에서 독립적으로 처리되고 추후 특징의 결합 구조를 사용하지만 해당 아키텍쳐는 단일 파이프라인과 스킵 레이어를 사용한다.
- 인셉션 기반 설계에서 잔차 기반으로 모듈을 교체하는 등 여러가지 레이어 모듈을 교체하며 네트워크 디자인을 테스트 하였고 잔차모듈을 광범위하게 사용하는 현재의 모래시계 같이 생긴 모듈을 만들었다.
- 이를 End-to-end 로 스택하여 하나의 출력이 다음의 입력으로 사용한다. 이러한 스택된 구조의 핵심은 Loss 를 중간 중간에 적용할 수 있다는 점이다. 모든 모래시계 구조에 적용하는 건 비효율적일 수 있어서 이론 및 테스트 결과를 보면서 중간에 적용한다.
- 이러한 중간 감독(중간 단계에 손실을 적용하는)은 로컬 부터 글로벌 특징들을 통합한다.
Evaluation
- 성능 지표는 PCK(Percentage of Keypoints)를 사용하며 평가되며, FLIC와 MPII의 2가지 데이터 셋을 사용하여 평가된다. MPII의 경우 PCKh 메트릭을 사용한다.
- 비교군에는 CPM, DeepPose 등의 모델들이 있으며 같은 해에 나온 CPM보다 높은 성능을 보인다.
- 소거 연구에서는 샌드 글라스 모듈의 수를 줄일 때 레이어를 늘리는 식으로 아키텍쳐를 변경해가는 실험을 진행했으며 또한 손실 함수의 적용 위치에 따른 정확도 비교를 통해 스택 구조에서 적절한 손실함수의 위치와 전체 아키텍쳐의 효용성을 비교한다.
Further Analysis
- 그림 10을 보면 해당 모델이 1명의 관절을 추정하는 것에 초점이 맞춰져 있기 때문에 약간의 전처리의 차이로 예측되는 사람이 변경되는 것을 볼 수 있다.
- 우리가 폐색 혹은 가림이라고 말하는 occlusion은 맥락상 명확히 있는 경우와 아예 완전히 맥락 파악이 불가하도록 가려지는 경우가 있다.
결론
해당 논문은 인간의 자세 추정을 위한 CNN 기반의 신경망 아키텍쳐를 제안한다. 스택된 구조와 모래시계 모양의 구조를 사용하며, 이를 통해 다양한 스케일에서의 특징을 단일 파이프라인 기반으로도 잘 결합하도록 설계하였다. 모래시계 모양의 구조와 해당 모듈의 스택 구조는 top-down과 bottom-up의 처리를 결합시키며 손실함수를 통한 중간 감독을 통해 최종 예측의 정확도를 높인다.
번역
Abstract
이 연구는 인간의 자세 추정을 위한 새로운 합성곱 신경망 아키텍처를 소개합니다. 특징들은 모든 규모에서 처리되고, 신체와 관련된 다양한 공간적 관계를 가장 잘 포착하기 위해 통합됩니다. 우리는 중간 감독과 함께 사용되는 반복적인 상향식 및 하향식 처리 방식이 네트워크 성능 향상에 중요한 역할을 한다는 것을 보여줍니다. 우리는 이 아키텍처를 “스택된 샌드글래스” 네트워크라고 부르며, 이는 최종 예측 세트를 생성하기 위해 수행되는 풀링과 업샘플링의 연속적인 단계를 기반으로 합니다. FLIC 및 MPII 벤치마크에서 최첨단 결과를 달성하며 최근 모든 방법들을 능가합니다.
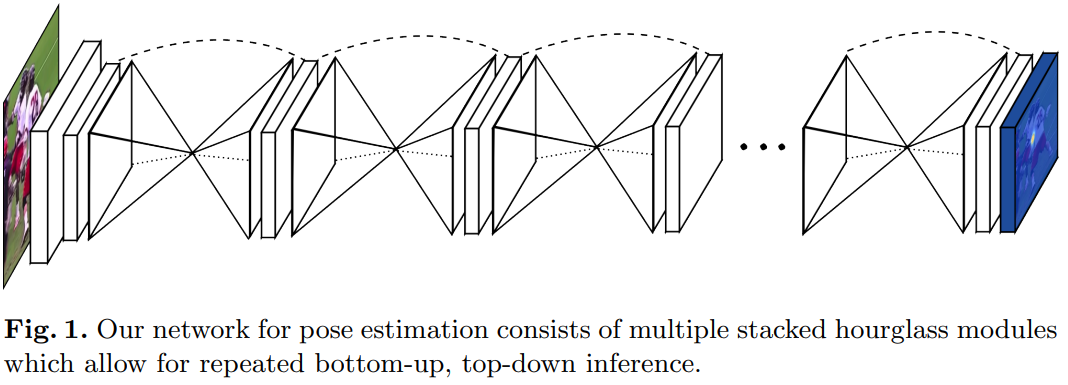
1. Introduction
비디오에서 사람을 이해하는 중요한 단계는 정확한 자세 추정입니다. 단일 RGB 이미지가 주어졌을 때, 우리는 신체의 중요한 키포인트의 정확한 픽셀 위치를 결정하고자 합니다. 사람의 자세와 사지 관절에 대한 이해는 행동 인식과 같은 상위 레벨의 작업에 유용하며, 인간-컴퓨터 상호작용 및 애니메이션과 같은 분야에서도 기본적인 도구로 사용됩니다.
시각적 문제로 잘 알려진 바와 같이, 자세 추정은 연구자들에게 수년간 다양한 어려움을 안겨 왔습니다. 좋은 자세 추정 시스템은 가려짐과 심한 변형에 강하고, 드문 자세나 새로운 자세에서도 성공적이어야 하며, 의복이나 조명과 같은 요인으로 인한 외관의 변화에 불변해야 합니다. 초기 연구에서는 이러한 어려움을 극복하기 위해 강력한 이미지 특징과 정교한 구조적 예측을 사용했습니다: 전자는 국부적인 해석을 생성하는 데 사용되고, 후자는 전역적으로 일관된 자세를 추론하는 데 사용됩니다.
그러나 이 전통적인 파이프라인은 합성곱 신경망(ConvNets)에 의해 크게 재편되었습니다. 이는 여러 컴퓨터 비전 작업에서 성능이 폭발적으로 향상된 주요 동인입니다. 최근 자세 추정 시스템은 ConvNets를 주요 빌딩 블록으로 채택하여 대부분의 수작업 특징과 그래픽 모델을 대체했으며, 이 전략은 표준 벤치마크에서 극적인 성능 향상을 가져왔습니다.
우리는 이 궤적을 계속 따라가면서, 인간 자세를 예측하기 위한 새로운 “스택된 샌드글래스” 네트워크 설계를 소개합니다. 이 네트워크는 이미지의 모든 규모에서 정보를 포착하고 통합합니다. 우리는 이 설계를 네트워크의 최종 출력을 얻기 위해 사용된 풀링 및 후속 업샘플링 단계를 시각화하여 샌드글래스로 명명했습니다. 많은 픽셀 단위 출력을 생성하는 합성곱 접근법과 마찬가지로, 샌드글래스 네트워크는 매우 낮은 해상도로 풀링한 다음, 업샘플링하고 여러 해상도에서 특징을 결합합니다. 한편, 샌드글래스는 주로 대칭적인 토폴로지에서 이전 설계와 다릅니다.
우리는 단일 샌드글래스를 확장하여 여러 샌드글래스 모듈을 종단 간에 연속적으로 배치했습니다. 이는 규모에 걸친 반복적인 상향식, 하향식 추론을 가능하게 합니다. 중간 감독의 사용과 함께, 반복적인 양방향 추론은 네트워크의 최종 성능에 중요합니다. 최종 네트워크 아키텍처는 두 가지 표준 자세 추정 벤치마크(FIC 및 MPII 인간 자세)에서 최첨단 성능을 크게 향상시킵니다. MPII에서는 모든 관절에서 평균 2% 이상의 정확도 향상이 있었고, 무릎과 발목과 같은 더 어려운 관절에서는 4-5%의 향상이 있었습니다.

2. Related Work
Toshev 등은 “DeepPose”를 도입하여 인간 자세 추정 연구가 고전적 접근법에서 딥 네트워크로 전환되기 시작했습니다. Toshev 등은 네트워크를 사용하여 관절의 x,y 좌표를 직접 회귀 분석합니다. Tompson 등의 연구는 대신 이미지를 여러 해상도 뱅크에 병렬로 실행하여 다양한 규모에서 특징을 동시에 캡처하는 히트맵을 생성합니다. 우리의 네트워크 설계는 이들의 연구를 바탕으로 하여, 규모에 걸쳐 정보를 캡처하는 방법을 탐구하고, 다양한 해상도에서 특징을 결합하는 방법을 채택합니다.
Tompson 등에서 제안한 방법의 중요한 특징은 ConvNet과 그래픽 모델의 결합 사용입니다. 그들의 그래픽 모델은 관절 간의 전형적인 공간적 관계를 학습합니다. 최근 다른 연구자들도 유사한 방식으로 이를 다루었으며, 단항 점수 생성 및 인접 관절의 쌍별 비교 접근 방법에 변형을 가했습니다. Chen 등은 감지를 전형적인 방향으로 클러스터링하여, 분류기가 예측을 할 때 추가적인 정보를 제공하여 이웃 관절의 위치를 추정할 수 있게 합니다. 우리는 그래픽 모델이나 인간 신체의 명시적 모델링 없이 우수한 성능을 달성합니다.
여러 가지 연속적인 예측을 수행하는 자세 추정 방법의 예가 있습니다. Carreira 등은 이를 반복 오류 피드백(Iterative Error Feedback)이라고 부릅니다. 예측 세트는 입력과 함께 포함되며, 네트워크를 통과할 때마다 이 예측이 추가로 정제됩니다. 이 방법은 다단계 학습이 필요하고, 가중치는 각 반복마다 공유됩니다. Wei 등은 다단계 자세 머신 작업을 기반으로 하되, 이제 특징 추출을 위해 ConvNet을 사용합니다. 중간 감독을 사용하는 점을 고려할 때, 우리의 작업은 이러한 방법과 정신적으로 유사하지만, 우리의 빌딩 블록(샌드글래스 모듈)은 다릅니다. Hu & Ramanan은 우리의 것과 유사한 아키텍처를 가지고 있으며, 이는 여러 단계의 예측에 사용할 수 있지만, 그들의 모델은 상향식 및 하향식 계산 부분과 반복에 걸쳐 가중치를 연결합니다.
Tompson 등은 그들의 연구를 기반으로 예측을 정제하는 캐스케이드를 만듭니다. 이는 그들의 방법의 효율성을 높이고 메모리 사용을 줄이면서도 높은 정밀도 범위에서 로컬라이제이션 성능을 향상시키는 역할을 합니다. 한 가지 고려 사항은 많은 실패 사례에서 지역 창 내에서 위치 정제가 큰 개선을 제공하지 않는다는 점인데, 이는 오류 사례가 종종 가려지거나 잘못 할당된 팔다리로 구성되기 때문입니다. 이러한 상황에서는 지역 규모에서의 추가 평가가 예측을 개선하지 못할 것입니다.
자세 추정 문제에는 깊이 또는 움직임 신호와 같은 추가 특징을 사용하는 변형이 있습니다. 또한, 여러 사람을 동시에 주석 처리하는 더 어려운 작업이 있습니다. 추가적으로, Oliveira 등과 같이 완전한 합성곱 신경망을 기반으로 인간 부분 분할을 수행하는 작업도 있습니다. 우리의 작업은 단일 RGB 이미지에서 한 사람의 자세 키포인트 위치 지정 작업에만 집중합니다.
스택하기 전의 우리의 샌드글래스 모듈은 완전한 합성곱 신경망과 공간 정보를 여러 스케일에서 처리하여 밀집 예측을 수행하는 다른 설계와 밀접한 관련이 있습니다. Xie 등은 일반적인 아키텍처에 대한 요약을 제공합니다. 우리의 샌드글래스 모듈은 이러한 설계와 주로 상향식 처리(고해상도에서 저해상도로)와 하향식 처리(저해상도에서 고해상도로) 간의 용량 분포가 더 대칭적인 점에서 다릅니다. 예를 들어, 완전한 합성곱 신경망은 상향식 처리에서는 무겁지만, 하향식 처리에서는 가벼우며, 이는 여러 스케일에 걸친 예측을 (가중) 병합하는 것으로만 구성됩니다. 완전한 합성곱 신경망은 또한 여러 단계에서 학습됩니다.
스택하기 전의 샌드글래스 모듈은 conv-deconv 및 인코더-디코더 아키텍처와도 관련이 있습니다. Noh 등은 conv-deconv 아키텍처를 사용하여 의미론적 분할을 수행하며, Rematas 등은 이를 사용하여 객체의 반사도 맵을 예측합니다. Zhao 등은 재구성 손실을 추가하여 지도 학습, 비지도 학습, 반지도 학습을 위한 통합 프레임워크를 개발합니다. Yang 등은 스킵 연결 없이 이미지 생성을 위해 인코더-디코더 아키텍처를 사용합니다. Rasmus 등은 비지도/반지도 특징 학습을 위한 특수한 “조절된” 스킵 연결을 사용한 잡음 제거 자동 인코더를 제안합니다. 이러한 네트워크의 대칭적인 토폴로지는 유사하지만, 작업의 본질은 unpooling 또는 deconv 레이어를 사용하지 않는다는 점에서 상당히 다릅니다. 대신, 우리는 단순한 가장 가까운 이웃 업샘플링과 하향식 처리를 위한 스킵 연결에 의존합니다. 우리의 작업의 또 다른 주요 차이점은 여러 샌드글래스를 스택하여 반복적인 상향식, 하향식 추론을 수행하는 것입니다.
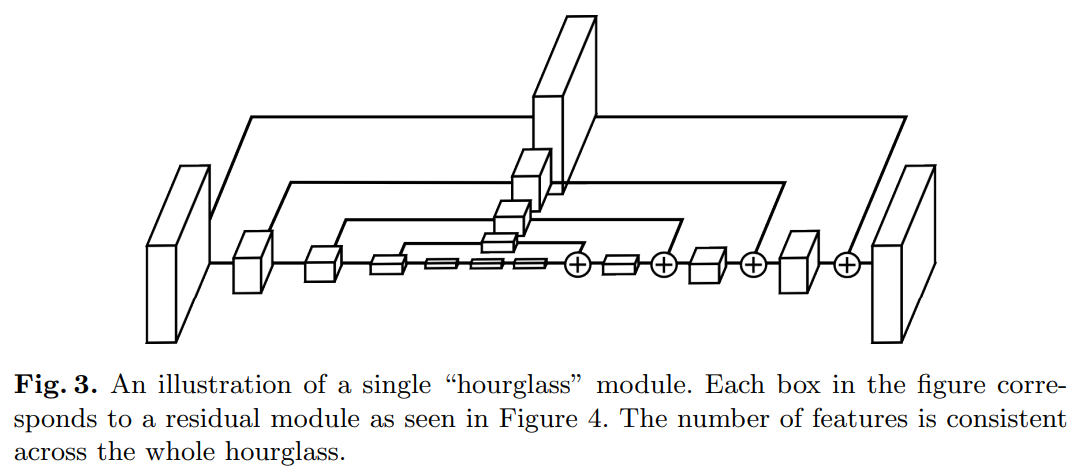
3. Network Architecture
3.1 Hourglass Design
샌드글래스의 디자인은 모든 스케일에서 정보를 포착할 필요성에 의해 동기부여되었습니다. 얼굴과 손과 같은 특징을 식별하는 데는 국부적인 증거가 필수적이지만, 최종 자세 추정은 전체 신체에 대한 일관된 이해를 요구합니다. 사람의 방향, 사지의 배열, 인접 관절의 관계 등은 이미지의 다른 스케일에서 가장 잘 인식되는 단서들입니다. 샌드글래스는 이러한 모든 특징을 포착하고 이를 결합하여 픽셀 단위의 예측을 출력할 수 있는 간단하고 최소한의 디자인을 가지고 있습니다.
네트워크는 스케일에 걸쳐 특징을 효과적으로 처리하고 통합할 수 있는 메커니즘을 가져야 합니다. 일부 접근법은 이미지가 여러 해상도에서 독립적으로 처리되고 나중에 네트워크에서 특징이 결합되는 별도의 파이프라인을 사용하여 이를 해결합니다. 대신, 우리는 각 해상도에서 공간 정보를 보존하기 위해 스킵 레이어가 포함된 단일 파이프라인을 사용하기로 선택했습니다. 네트워크는 4x4 픽셀에서 가장 낮은 해상도에 도달하며, 이미지 전체 공간에 걸쳐 특징을 비교할 수 있는 더 작은 공간 필터를 적용할 수 있습니다.
샌드글래스는 다음과 같이 설정됩니다: 합성곱과 맥스 풀링 레이어가 사용되어 특징을 매우 낮은 해상도로 처리합니다. 각 맥스 풀링 단계에서 네트워크는 분기하여 원래 풀링 전 해상도에서 더 많은 합성곱을 적용합니다. 가장 낮은 해상도에 도달한 후 네트워크는 업샘플링과 스케일에 걸쳐 특징을 결합하는 상향식 순서를 시작합니다. 두 인접 해상도에 걸친 정보를 결합하기 위해 우리는 Tompson 등이 설명한 과정을 따르며, 하위 해상도의 최근접 이웃 업샘플링을 수행한 후 두 특징 세트를 요소별로 더합니다. 샌드글래스의 토폴로지는 대칭적이어서 하향식으로 내려가는 각 레이어에 상응하는 상향식 레이어가 존재합니다.
네트워크의 출력 해상도에 도달한 후, 최종 네트워크 예측을 생성하기 위해 두 번의 연속적인 1x1 합성곱이 적용됩니다. 네트워크의 최종 출력은 각 픽셀에서 관절의 존재 확률을 예측하는 히트맵 세트입니다. 전체 모듈(최종 1x1 레이어 제외)은 그림 3에 나와 있습니다.
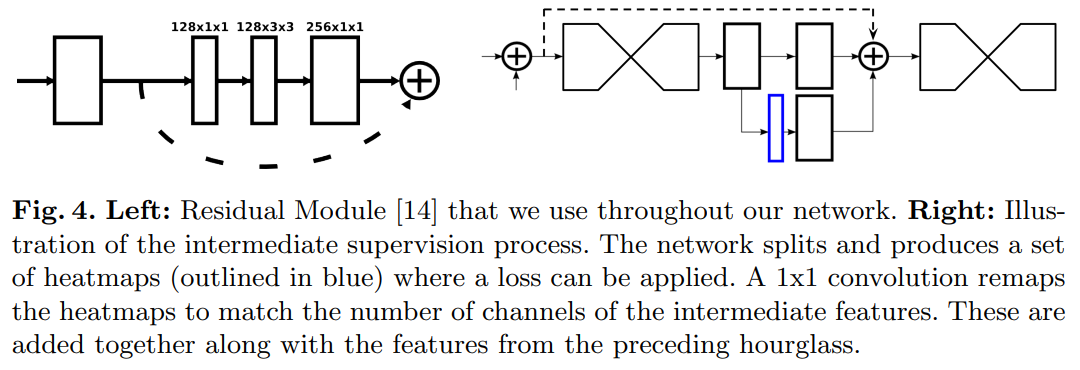
3.2 Layer Implementation
전체 샌드글래스 모양을 유지하면서도 레이어의 구체적인 구현에는 여전히 약간의 유연성이 있습니다. 서로 다른 선택은 네트워크의 최종 성능과 학습에 적당한 영향을 미칠 수 있습니다. 우리는 네트워크에서 레이어 설계를 위한 여러 옵션을 탐색했습니다. 최근 연구는 1x1 합성곱과 축소 단계의 가치를 보여주었으며, 더 큰 공간적 문맥을 포착하기 위해 연속적인 작은 필터를 사용하는 이점도 밝혀졌습니다. 예를 들어, 5x5 필터를 두 개의 3x3 필터로 교체할 수 있습니다. 우리는 이러한 통찰에 기반하여 서로 다른 레이어 모듈을 교체하며 전체 네트워크 디자인을 테스트했습니다. 큰 필터가 있는 표준 합성곱 레이어와 축소 단계가 없는 기존 방법에서 He 등과 “Inception” 기반 설계에서 제시한 잔차 학습 모듈과 같은 새로운 방법으로 전환한 후 네트워크 성능이 향상되었습니다. 이러한 유형의 설계로 초기 성능이 개선된 후에도 다양한 추가 탐색과 레이어에 대한 수정은 성능이나 학습 시간에 거의 영향을 미치지 않았습니다.
우리의 최종 디자인은 잔차 모듈을 광범위하게 사용합니다. 3x3보다 큰 필터는 절대 사용되지 않으며, 병목 현상은 각 레이어에서 총 매개변수 수를 제한하여 전체 메모리 사용을 줄입니다. 우리의 네트워크에서 사용된 모듈은 그림 4에 나와 있습니다. 이를 전체 네트워크 디자인의 맥락에서 설명하자면, 그림 3의 각 상자는 하나의 잔차 모듈을 나타냅니다.
3.3 Stacked Hourglass with Intermediate Supervision
우리는 여러 개의 샌드글래스를 종단 간에 스택하여, 하나의 출력이 다음 입력으로 사용되도록 함으로써 네트워크 아키텍처를 한 단계 더 발전시켰습니다. 이를 통해 네트워크는 반복적인 상향식, 하향식 추론 메커니즘을 가지게 되어 전체 이미지에 걸쳐 초기 추정치와 특징을 재평가할 수 있습니다. 이 접근법의 핵심은 손실을 적용할 수 있는 중간 히트맵의 예측입니다. 예측은 각 샌드글래스를 통과한 후 생성되며, 이때 네트워크는 로컬 및 글로벌 문맥에서 특징을 처리할 기회를 가집니다. 이후의 샌드글래스 모듈은 이러한 고수준 특징을 다시 처리하여 더 높은 차원의 공간적 관계를 평가하고 재평가할 수 있습니다. 이는 여러 반복 단계와 중간 감독을 통해 강력한 성능을 입증한 다른 자세 추정 방법과 유사합니다.
단일 샌드글래스 모듈만을 사용하여 중간 감독을 적용하는 것의 한계를 고려하십시오. 초기 예측 세트를 생성하기에 적절한 파이프라인의 위치는 어디일까요? 대부분의 고차원 특징은 업샘플링이 발생할 때를 제외하면 낮은 해상도에서만 존재합니다. 네트워크가 업샘플링을 수행한 후 감독이 제공되면, 이러한 특징들이 더 큰 글로벌 문맥에서 서로에 대해 재평가될 방법이 없습니다. 네트워크가 예측을 최적화하도록 하려면 이러한 예측은 로컬 스케일에서만 평가될 수 없습니다. 다른 관절 예측과의 관계뿐만 아니라 전체 이미지의 일반적인 문맥과 이해가 중요합니다. 풀링 전에 파이프라인에서 더 일찍 감독을 적용하는 것도 가능하지만, 이 시점에서 주어진 픽셀의 특징은 상대적으로 국부적인 수용장을 처리한 결과이므로 중요한 글로벌 단서를 인식하지 못합니다.
스택된 샌드글래스와 함께 반복적인 상향식, 하향식 추론은 이러한 문제를 완화합니다. 로컬 및 글로벌 단서는 각 샌드글래스 모듈 내에서 통합되며, 네트워크가 초기 예측을 생성하도록 요구하는 것은 네트워크가 전체 네트워크의 중간 단계에서 이미지에 대한 고수준의 이해를 가지도록 합니다. 이후의 상향식, 하향식 처리 단계는 이러한 특징을 더 깊이 재고할 수 있게 합니다.
스케일 간의 이동을 위한 이 접근법은 특징의 공간적 위치를 유지하는 것이 최종 위치 지정 단계를 수행하는 데 필수적이기 때문에 특히 중요합니다. 관절의 정확한 위치는 네트워크가 내리는 다른 결정에 필수적인 단서입니다. 자세 추정과 같은 구조화된 문제에서는 출력이 장면에 대한 일관된 이해를 형성하기 위해 결합해야 하는 다양한 특징들의 상호작용입니다. 모순되는 증거와 해부학적 불가능성은 어디선가 실수가 있었음을 알려주는 주요 신호이며, 앞뒤로 이동함으로써 네트워크는 전체적인 일관성을 고려하고 재고하면서 정확한 지역 정보를 유지할 수 있습니다.
우리는 추가적인 1x1 합성곱을 사용하여 중간 예측을 더 많은 채널로 매핑함으로써 특징 공간으로 다시 통합합니다. 이러한 예측은 이전 샌드글래스 단계에서 출력된 특징과 함께 샌드글래스에서 중간 특징으로 다시 더해집니다(그림 4에서 시각화됨). 결과 출력은 다음 샌드글래스 모듈의 입력으로 직접 사용되어 또 다른 예측 세트를 생성합니다. 최종 네트워크 설계에서는 8개의 샌드글래스가 사용됩니다. 중요한 점은 샌드글래스 모듈 간에 가중치가 공유되지 않으며, 모든 샌드글래스의 예측에 동일한 정답을 사용하여 손실이 적용된다는 것입니다. 손실과 정답에 대한 세부 사항은 아래에서 설명됩니다.
3.4 Training Details

우리는 FLIC와 MPII Human Pose라는 두 가지 벤치마크 데이터셋에서 우리의 네트워크를 평가합니다. FLIC는 영화에서 가져온 5003개의 이미지(3987개의 학습용, 1016개의 테스트용)로 구성됩니다. 이 이미지들은 대부분 인물이 카메라를 정면으로 바라보고 있는 상반신을 주석으로 달았습니다. MPII Human Pose는 약 25,000개의 이미지로 구성되며, 여러 사람의 주석이 달린 40,000개의 샘플(28,000개의 학습용, 11,000개의 테스트용)을 제공합니다. 테스트 주석은 제공되지 않으므로, 모든 실험에서 우리는 학습 이미지의 하위 집합에서 학습하고 약 3000개의 샘플로 구성된 별도의 검증 세트에서 평가합니다. MPII는 다양한 인간 활동에서 가져온 이미지들로 구성되어 있으며, 다양한 전체 몸체 포즈를 가진 도전적인 배열이 특징입니다.
주어진 입력 이미지에 여러 사람이 보이는 경우가 자주 있습니다. 그러나 그래픽 모델이나 다른 후처리 단계 없이 네트워크가 어느 사람이 주석을 받아야 하는지 판단하는 데 필요한 모든 정보를 이미지가 전달해야 합니다. 우리는 네트워크가 중앙에 있는 사람만을 주석 처리하도록 학습시켜 이 문제를 해결합니다. 이는 FLIC에서 torsobox 주석에 따라 x축을 중심으로 설정하여 수행됩니다 - 수직 조정이나 스케일 정규화는 수행되지 않습니다. MPII의 경우, 모든 이미지에 제공된 스케일 및 중심 주석을 사용하는 것이 표준입니다. 각 샘플에 대해 이러한 값은 타겟 사람 주위의 이미지를 자르는 데 사용됩니다. 모든 입력 이미지는 256x256 픽셀로 리사이즈됩니다. 우리는 회전(+/- 30도) 및 스케일링(.75-1.25)을 포함한 데이터 증강을 수행합니다. 이미지의 위치 이동 증강은 피하는데, 이는 네트워크가 어느 사람이 주석 처리되어야 하는지를 결정하는 중요한 단서가 타겟 사람의 위치이기 때문입니다.
네트워크는 Torch7을 사용하여 학습되며, 최적화를 위해 rmsprop을 사용하고 학습률은 2.5e-4입니다. 학습은 12GB NVIDIA TitanX GPU에서 약 3일이 걸립니다. 검증 정확도가 안정화되면 학습률을 5배 낮춥니다. 배치 정규화도 학습 개선을 위해 사용됩니다. 네트워크의 단일 순방향 패스는 75ms가 걸립니다. 최종 테스트 예측을 생성하기 위해 우리는 원본 입력과 이미지의 뒤집힌 버전을 네트워크에 통과시켜 히트맵을 평균합니다(검증 시 평균 1% 향상을 고려). 네트워크의 최종 예측은 주어진 관절에 대해 히트맵의 최대 활성화 위치입니다.
Tompson 등과 동일한 기술이 감독에 사용됩니다. 평균 제곱 오차(MSE) 손실이 예측된 히트맵과 관절 위치에 중심이 있는 2D 가우시안(표준 편차 1픽셀)으로 구성된 실제 히트맵을 비교하여 적용됩니다. 높은 정밀도 임계값에서 성능을 향상시키기 위해 예측은 원래 이미지의 좌표 공간으로 변환되기 전에 그 다음으로 높은 이웃 방향으로 4분의 1픽셀 만큼 오프셋됩니다. MPII Human Pose에서는 일부 관절에 해당하는 실제 주석이 없습니다. 이러한 경우, 관절이 잘리거나 심하게 가려져 있으므로, 감독을 위해 0으로 된 실제 히트맵이 제공됩니다.
4. Results
4.1 Evaluation
평가는 표준 Percentage of Correct Keypoints (PCK) 메트릭을 사용하여 수행되며, 이는 정답과의 정규화된 거리 내에 있는 검출의 비율을 보고합니다. FLIC의 경우 거리는 흉부 크기로 정규화되며, MPII의 경우 머리 크기의 일부로 정규화됩니다(PCKh로 지칭).
FLIC
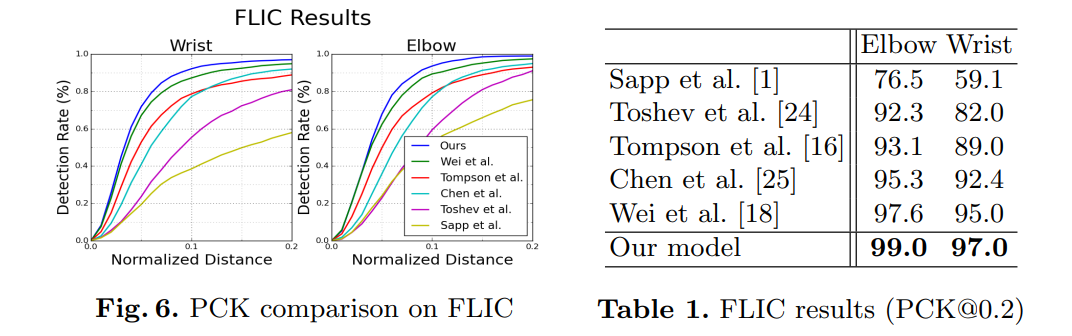
결과는 그림 6과 표 1에서 볼 수 있습니다. FLIC에서 우리의 결과는 매우 경쟁력이 있으며, 팔꿈치에서 99% PCK@0.2 정확도, 손목에서 97%를 달성했습니다. 이러한 결과가 관찰자 중심의 결과임을 유의할 필요가 있으며, 이는 다른 연구자들이 FLIC에서 출력물을 평가한 방식과 일치합니다.
MPII
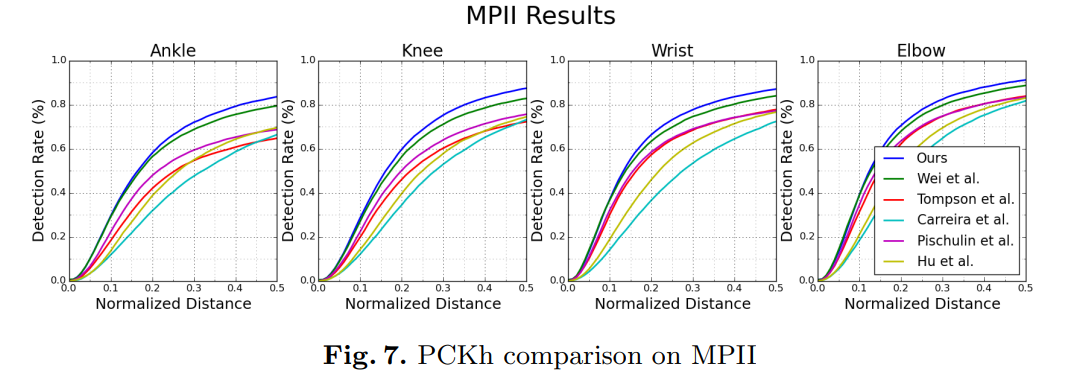
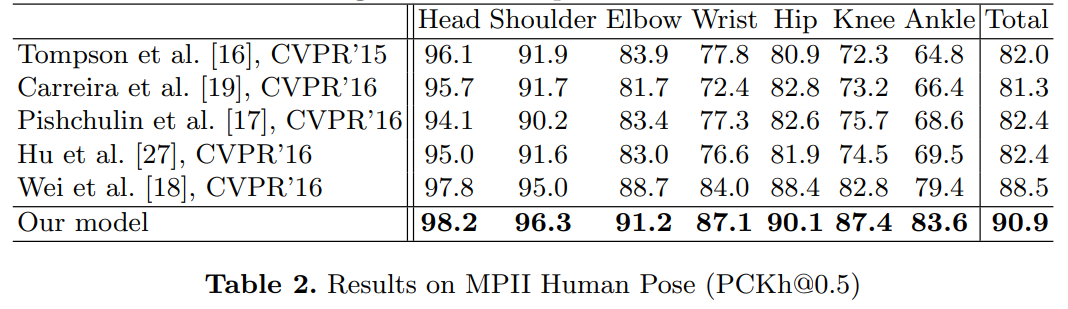
우리는 MPII Human Pose 데이터셋의 모든 관절에서 최첨단 성과를 달성했습니다. 모든 수치는 표 2와 그림 7에서 볼 수 있습니다. 손목, 팔꿈치, 무릎, 발목과 같은 어려운 관절에서 우리는 가장 최근의 최첨단 결과를 평균 3.5% (PCKh@0.5) 개선했으며, 평균 오류율은 16.3%에서 12.8%로 감소했습니다. 최종 팔꿈치 정확도는 91.2%, 손목 정확도는 87.1%입니다. MPII에서 네트워크가 만든 예측 예시는 그림 5에서 볼 수 있습니다.
4.2 Ablation Experiments
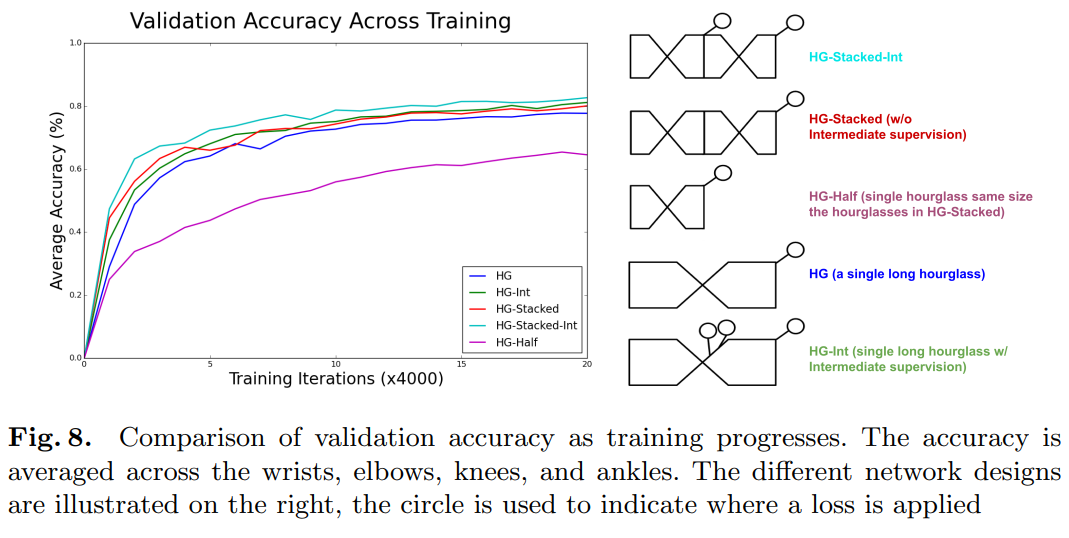
우리는 이 작업에서 두 가지 주요 설계 선택을 탐구합니다: 샌드글래스 모듈을 함께 스택하는 효과와 중간 감독의 영향입니다. 이들은 상호 독립적이지 않으며, 전체 아키텍처 디자인에 따라 중간 감독을 어떻게 적용할 수 있는지에 제한이 있습니다. 개별적으로 적용되면 각각이 성능에 긍정적인 영향을 미치며, 함께 적용되면 학습 속도와 최종 자세 추정 성능이 더욱 향상됩니다. 우리는 몇 가지 다른 네트워크 설계의 학습 속도를 살펴봅니다. 그 결과는 학습이 진행됨에 따라 검증 세트에서의 평균 정확도를 보여주는 그림 8에서 볼 수 있습니다. 정확도 메트릭은 실험 간의 차별화를 용이하게 하기 위해 머리와 흉부와 관련된 관절을 제외한 모든 관절을 고려합니다.
첫째, 스택된 샌드글래스 디자인의 효과를 탐구하기 위해, 성능 변화가 아키텍처 모양의 함수이며 더 크고 깊은 네트워크로 용량이 증가한 것에 기인하지 않음을 증명해야 합니다. 이를 비교하기 위해, 우리는 그림 3과 같이 각각의 해상도에서 단일 잔차 모듈을 가진 8개의 샌드글래스 모듈을 스택한 기본 네트워크에서 작업합니다. 우리는 다양한 네트워크 배열을 위해 이러한 레이어를 섞을 수 있습니다. 샌드글래스 수를 줄이면 각 샌드글래스의 용량이 증가합니다. 예를 들어, 해당 네트워크는 4개의 샌드글래스를 스택하고 각 해상도에서 두 개의 연속적인 잔차 모듈을 가질 수 있습니다(또는 두 개의 샌드글래스와 네 개의 잔차 모듈). 이는 그림 9에 설명되어 있습니다. 모든 네트워크는 동일한 매개변수와 레이어 수를 공유하지만, 더 많은 중간 감독이 적용되면 약간의 차이가 도입됩니다.
이러한 선택의 효과를 확인하기 위해, 우리는 먼저 샌드글래스의 각 단계에서 4개의 잔차 모듈을 가진 두 개의 스택된 네트워크와, 8개의 잔차 모듈을 가진 단일 샌드글래스를 비교합니다. 그림 8에서 이를 각각 HG-Stacked와 HG로 지칭합니다. 레이어와 매개변수 수가 거의 동일함에도 불구하고 스택된 디자인을 사용할 때 학습에서 약간의 개선을 볼 수 있습니다. 다음으로, 중간 감독의 영향을 고려합니다. 두 개의 스택된 네트워크의 경우 논문에서 설명한 절차를 따라 감독을 적용합니다. 이와 같은 아이디어를 단일 샌드글래스에 적용하는 것은 비상식적입니다. 왜냐하면 고차원의 글로벌 특징은 낮은 해상도에서만 존재하고, 파이프라인 후반까지 스케일 전반에 걸쳐 특징이 결합되지 않기 때문입니다. 우리는 네트워크의 다양한 지점에서, 예를 들어 풀링 전후와 다양한 해상도에서 감독을 적용하는 것을 탐구합니다. 가장 성능이 좋은 방법은 그림 8에서 HG-Int로 나타나며, 최종 출력 해상도 전에 두 번째로 높은 해상도에서 업샘플링 후 중간 감독이 적용되었습니다. 이 감독은 성능을 향상시키지만, 스태킹이 포함된 경우의 향상을 초과할 만큼 충분하지는 않습니다(HG-Stacked-Int).
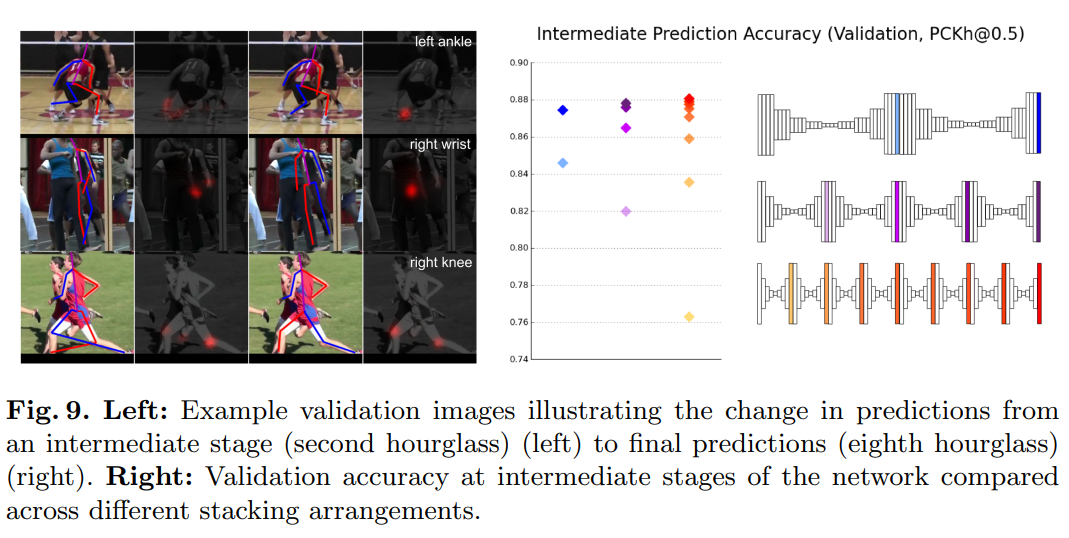
그림 9에서 우리는 매개변수 수가 거의 동일한 2-, 4-, 8-스택 모델의 검증 정확도를 비교하고, 중간 예측의 정확도를 포함합니다. 스태킹이 87.4%에서 87.8%로, 그리고 88.1%로 점진적으로 증가함에 따라 최종 성능에서 약간의 개선이 있습니다. 이 효과는 중간 단계에서 더 두드러집니다. 예를 들어, 각 네트워크의 중간 지점에서 중간 예측의 해당 정확도는 84.6%, 86.5%, 87.1%입니다. 8-스택 네트워크의 중간 지점에서의 정확도는 2-스택 네트워크의 최종 정확도보다 약간 낮습니다.
네트워크가 초기에 저지른 실수가 나중에 수정되는 것을 관찰하는 것은 흥미롭습니다. 몇 가지 예시는 그림 9에 시각화되어 있습니다. 일반적인 실수로는 다른 사람의 관절이 섞이는 것, 또는 왼쪽과 오른쪽의 잘못된 할당 등이 있습니다. 달리기 그림의 경우, 최종 히트맵에서 네트워크가 왼쪽과 오른쪽을 구분하는 데 여전히 약간의 모호함이 있음을 알 수 있습니다. 이미지의 모양을 고려할 때, 이러한 혼란은 정당화될 수 있습니다. 주목할만한 한 가지 사례는 네트워크가 처음에는 이미지에서 보이는 손목에 활성화되었지만, 추가 처리 후 히트맵이 원래 위치에서 전혀 활성화되지 않고 가려진 손목의 합리적인 위치를 선택한 중간 예입니다.
5. Further Analysis
5.1. Multiple People

일관성 문제는 이미지에 여러 사람이 있을 때 특히 중요해집니다. 네트워크는 누구에게 주석을 달지 결정해야 하지만, 정확히 누가 주석을 받아야 하는지를 전달하는 방법은 제한적입니다. 이 작업의 목적을 위해 제공된 유일한 신호는 타겟 사람의 중심 맞추기와 스케일링으로, 입력이 명확하게 해석될 수 있을 것이라고 믿고 있습니다. 불행히도, 이는 그림 10에서 보듯이 사람들이 매우 가까이 있거나 겹치는 경우에 모호한 상황으로 이어지기도 합니다. 우리는 한 사람을 위한 자세 예측을 생성하는 시스템을 학습시키고 있기 때문에, 모호한 상황에서 이상적인 출력은 하나의 인물의 관절에 대한 전념을 보여줄 것입니다. 예측의 품질이 낮더라도, 이는 주어진 작업에 대한 더 깊은 이해를 나타낼 것입니다. 손목 위치를 추정할 때, 그 손목이 누구에게 속하는지 무시하는 것은 자세 추정 시스템에서 바람직하지 않은 행동입니다.
그림 10의 결과는 MPII 테스트 이미지에서 가져온 것입니다. 네트워크는 소년과 소녀 모두에 대한 예측을 생성해야 하며, 이를 위해 각자의 중심 및 스케일 주석이 제공됩니다. 이 값들을 사용해 네트워크를 위한 입력 이미지를 자르면 그림의 첫 번째와 세 번째 이미지가 됩니다. 두 무용수의 중심 주석은 720x1280 이미지에서 단지 26픽셀 차이가 납니다. 질적으로, 두 입력 이미지 사이에서 가장 눈에 띄는 차이점은 스케일의 변화입니다. 이 차이는 네트워크가 전체적으로 추정을 변경하고 올바른 인물에 대한 주석을 예측하는 데 충분합니다.
여러 사람에 대한 주석 관리를 더 포괄적으로 하는 것은 이 작업의 범위를 벗어납니다. 시스템의 많은 실패 사례는 여러 사람의 관절이 혼동된 결과이지만, 인물이 심하게 겹치는 많은 예시에서 네트워크가 적절하게 단일 인물을 선택해 주석을 다는 것은 유망합니다.
5.2 Occlusion
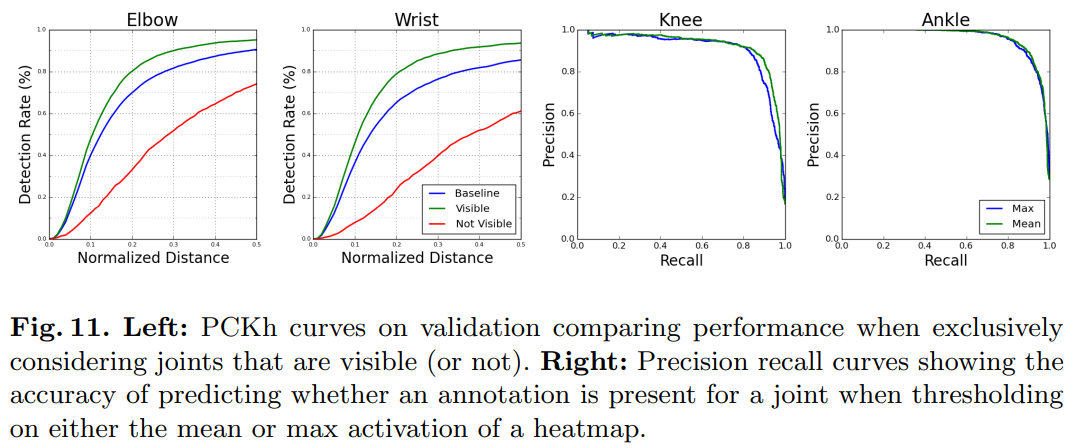
가림 성능을 평가하는 것은 어려울 수 있으며, 이는 종종 두 가지 명확한 범주로 나뉩니다. 첫 번째는 관절이 보이지 않지만 이미지의 맥락을 고려할 때 그 위치가 명확한 경우입니다. MPII는 일반적으로 이러한 관절에 대한 실제 위치를 제공하며, 추가적인 주석은 가시성이 부족함을 나타냅니다. 반면에 두 번째 상황은 특정 관절이 어디에 있을 수 있는지에 대한 정보가 전혀 없는 경우입니다. 예를 들어, 사람의 상반신만 보이는 이미지입니다. MPII에서는 이러한 관절에 대해 실제 주석이 제공되지 않습니다.
우리의 시스템은 추가 가시성 주석을 사용하지 않지만, 여전히 가시성이 성능에 미치는 영향을 살펴볼 수 있습니다. 보유된 검증 세트에서 주석이 달린 팔꿈치와 손목의 약 75%가 가시성으로 라벨링되었습니다. 그림 11에서는 전체 검증 세트에서 평균화된 성능을 가시성이 있는 관절의 3/4에 대한 성능과 나머지 1/4에 대한 성능과 비교합니다. 가시성 관절만 고려할 때, 손목 정확도는 85.5%에서 93.6%로 상승합니다(검증 성능은 테스트 세트 성능인 87.1%보다 약간 낮음). 반면에, 가려진 관절에 대한 성능은 61.1%입니다. 팔꿈치의 경우, 정확도는 가시성 관절의 기본값인 90.5%에서 95.1%로 상승하며, 가려진 관절에 대해서는 74.0%로 하락합니다. 가림은 분명히 중요한 도전 과제이지만, 네트워크는 대부분의 경우 강력한 추정을 제공합니다. 많은 예시에서, 네트워크 예측과 실제 주석은 둘 다 유효한 위치에 있는 동안 일치하지 않을 수 있으며, 이미지의 모호성으로 인해 어느 쪽이 진정으로 올바른지 판단할 방법이 없습니다.
우리는 관절이 심하게 가려지거나 잘려서 주석이 전혀 없는 극단적인 경우도 고려합니다. 자세 추정 시스템을 평가할 때 사용되는 PCK 메트릭은 네트워크가 이러한 상황을 얼마나 잘 인식하는지 반영하지 않습니다. 관절에 대해 제공된 실제 주석이 없으면 시스템이 내린 예측의 품질을 평가하는 것은 불가능하며, 따라서 최종 보고된 PCK 값에 포함되지 않습니다. 이러한 이유로, 완전히 가려지거나 잘린 관절에 대한 예측이 아무런 의미가 없더라도 모든 관절에 대한 예측을 생성해도 해가 되지 않습니다. 실제 시스템에서 사용하기 위해서는 메타 지식이 필수적이며, 특정 관절에 대해 좋은 예측을 할 수 없다는 이해가 매우 중요합니다. 우리는 네트워크가 관절에 대해 실제 주석이 있는지 여부를 일관되고 정확하게 예측하는 것을 관찰합니다.
우리는 발목과 무릎을 가장 자주 가려지는 것으로 분석합니다. 하반신이 자주 이미지에서 잘려나가기 때문에, 네트워크의 모든 관절 예측을 시각화할 경우, 예시 자세 그림은 이러한 상황에서 비합리적인 하반신 예측을 고려할 때 받아들일 수 없는 모습일 것입니다. 이러한 사례를 간단히 필터링하기 위해, 히트맵 활성화에 따라 관절에 대한 주석이 있는지를 얼마나 잘 결정할 수 있는지를 검토합니다. 우리는 히트맵의 최대값이나 평균값에 대한 임계값을 고려합니다. 해당 정밀도-재현율 곡선은 그림 11에서 볼 수 있습니다. 우리는 히트맵의 평균 활성화만을 기준으로 무릎에 대한 주석 존재를 AUC 92.1%로, 발목에 대한 주석 존재를 AUC 96.0%로 정확하게 평가할 수 있음을 발견했습니다. 이는 2958개의 샘플 검증 세트에서 수행되었으며, 이 중 16.1%의 무릎과 28.4%의 발목이 실제 주석을 가지고 있지 않습니다. 이는 히트맵이 이미지에서 잘림과 심각한 가림 사례를 나타내는 유용한 신호로 작용한다는 유망한 결과입니다.
6. Conclusion
우리는 인간 자세 추정을 생성하기 위한 스택된 모래시계 네트워크의 효과를 입증했습니다. 이 네트워크는 초기 예측을 재평가하고 평가하기 위한 간단한 메커니즘을 통해 다양한 도전적인 자세 세트를 처리합니다. 중간 감독은 네트워크를 훈련시키는 데 매우 중요하며, 스택된 모래시계 모듈의 맥락에서 가장 잘 작동합니다. 여전히 네트워크가 완벽하게 처리하지 못하는 어려운 사례가 존재하지만, 전체적으로 우리 시스템은 심각한 가림 및 근접한 여러 사람과 같은 다양한 도전에 대해 강력한 성능을 보여줍니다.
Alejandro Newell, Kaiyu Yang, Jia Deng Stacked Hourglass Networks for Human Pose Estimation

댓글남기기