

개요
The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation. 해당 논문은 2020년 CVPR에서 발표되었다.
분석
본 논문에서는 기존의 데이터 처리와 제안하는 데이터 처리를 설명하기 위한 수식과 기호가 많다. 원문 그대로 이해하는 것이 항상 제일 좋다고 생각한다.
표준 데이터 변환에는 원본 이미지 공간에서 사람의 영역을 cropped 혹은 리사이즈 하여 활용한다. 그리고 회전·확대·축소·뒤집기 등의 증강(augmentation)을 사용한다. 섹션 3.1.1의 Standard Data Transformation은 이러한 원본 이미지로부터 잘라내고(crop), 회전하고(rotation), 리사이즈하며(resize), 뒤집기(flip)을 하는 수식들이 적혀있다. 여기서의 문제는 이것들을 픽셀 단위로 계산하다보니, ‘뒤집기 후에 좌표가 1픽셀에서 2픽셀 정도씩 어긋난다’ 라는 점이다. 이걸 뒤늦게 보정해도 완벽하지 않아 ‘편향(bias)’가 남는다고 한다.
그래서 섹션 3.1.2에서 이러한 편향을 없앨 수 있는 비편향 데이터 변환(Unbiased Data Transformation)을 제안한다. 핵심은 픽셀 단위가 아닌 인접한 픽셀 사이의 물리적 거리라는 ‘유닛 렝스(unit length)’를 기준으로 이미지 크기 및 좌표 변환을 도입한다. 이를 통해 뒤집기(flipping) 시에 원본 좌표와 뒤집힌 좌표를 정확히 정렬할 수 있다고 한다. 이러한 unit length 단위를 사용하여 표준 방식의 편향을 없애는 핵심 아이디어를 전개한다.
그 후에 좌표를 히트맵으로 바꾸는 인코딩(encoding), 히트맵을 다시 좌표로 바꾸는 과정인 디코딩(decoding)의 수식과 해당 과정에서 생기는 systematic error를 분석한다. 히트맵은 정수좌표의 위치에 가우시안 분포의 형태로 픽셀값이 1에서 멀어지면 0에 가까워지도록 변환한다. 해당 과정에서 실제로는 부동소수점 일 수 있는 좌표 $k=(m, n)$을 정수로 round 하는 과정에서 양자화(quantization) 오차가 발생한다. 그래서 히트맵을 좌표로 변환하는 디코딩 과정에서 평균적으로 약 0.25 픽셀의 오차가 발생한다고 한다. 그래서 표준 기법에서는 Gradient를 통한 $\frac{1}{4}$ 유닛 렝스의 보정을 하면 최종오차를 절반으로 줄일 수 있다고 한다.
본 논문에서는 표준 방식에서 발생하는 systematic error를 줄이기 위해, 분류와 회귀를 결합한 새로운 인코딩-디코딩 방식을 제안한다. 새로운 인코딩 과정은 히트맵을 가우시안이 아닌 반경을 지정하여 1과 0의 값만 가지는 이진 히트맵으로 만든다. 또한 오프셋 맵을 구성하여 픽셀에서 실제 좌표 키포인트까지의 차이를 저장한다. 그리고 새로운 디코딩 단계에서는 네트워크의 출력을 가우시안 커널로 스무딩하여 가장 높은 점수의 위치 픽셀을 찾는다. 그 후 오프셋 맵에서 위치 보정량을 합산하여 최종 좌표를 구하면 더 이상적인 키포인트 좌표에 대한 학습을 구현할 수 있다고 한다. 이론적으로는 양자화 오류를 $\frac{1}{8}$로 줄이는 것이 아닌 0의 기댓값을 가지게하여 개선할 수 있다.
결론
본 논문은 Human Pose Estimation 의 학습 과정에서 데이터 처리 시 발생하는 편향문제를 해결함으로써, 기존 모델들의 성능을 개선함을 보인다. 이는 새로운 아키텍쳐를 제안한 것이 아니라 다양한 방법론에 사용할 수 있기에 범용성이 뛰어나다고 할 수 있다.
번역
Abstract
최근 인간 자세 추정(human pose estimation) 분야에서 최고 성능은 주로 상향식(top-down) 방법에 의해 주도되고 있습니다. 학습과 추론에서 근본적인 요소임에도 불구하고, 데이터 처리는 우리가 아는 한 현재까지 자세 추정 커뮤니티에서 체계적으로 고려되지 않았습니다. 본 논문에서는 이러한 문제에 주목하고, 상향식 자세 추정기의 핵심 난점이 편향된 데이터 처리(biased data processing)에 있음을 발견했습니다. 구체적으로, 데이터 변환(data transformation)과 인코딩-디코딩(encoding-decoding)을 포함하는 최신 기법들의 표준 데이터 처리를 조사한 결과, 일반적인 뒤집기(flipping) 전략으로 얻은 결과가 추론 시 원본과 정렬되지 않는 현상을 확인했습니다. 또한, 학습과 추론 과정 모두에서 표준 인코딩-디코딩에 통계적 오류(statistical error)가 존재합니다. 이 두 문제는 함께 작용하여 자세 추정 성능을 크게 저하시킵니다. 정량적 분석을 바탕으로, 우리는 이 딜레마를 해결하기 위한 원칙적인 방법을 제시합니다. 데이터는 픽셀 단위의 이산 공간(discrete space)이 아니라 픽셀 간격(unit length)에 기반한 연속 공간(continuous space)에서 처리되며, 인코딩-디코딩을 수행하기 위해 분류(classification)와 회귀(regression)를 결합한 접근법이 채택됩니다. 인간 자세 추정을 위한 비편향적 데이터 처리(Unbiased Data Processing, UDP)는 위 두 방법을 결합함으로써 달성할 수 있습니다. UDP는 기존 방법들의 성능을 큰 폭으로 향상시킬 뿐 아니라 결과 재현성과 향후 탐색 연구에도 중요한 역할을 합니다. 모델에 구애받지 않는 접근법인 UDP를 적용한 결과, COCO test-dev 세트에서 SimpleBaseline-ResNet50-256 × 192의 성능이 1.5 AP(70.2에서 71.7로), HRNet-W32-256 × 192의 성능이 1.7 AP(73.5에서 75.2로) 상승했습니다. UDP를 탑재한 HRNet-W48-384 × 288은 76.5 AP를 달성하며, 인간 자세 추정 분야의 새로운 최고 성능을 기록했습니다. 소스 코드는 추가 연구를 위해 공개되어 있습니다[1].
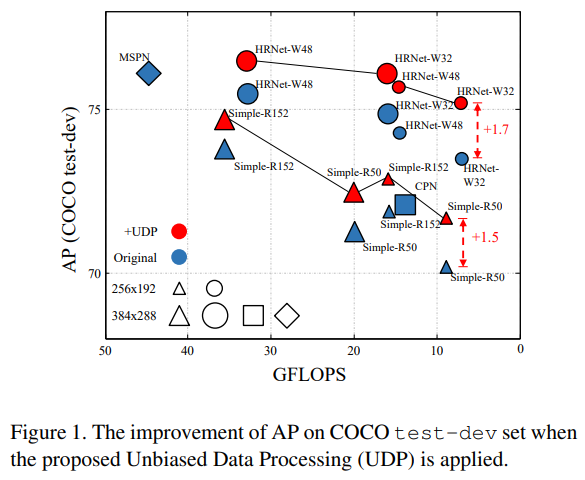
1. Introduction
[한글]:
인간 자세 추정(human pose estimation)은 영상 감시 [15]나 동작 인식 [4,37,36]과 같은 시각적 이해(visual understanding) 과제에서 매우 중요합니다. 최근 연구 커뮤니티는 단일 인물 [2,10,30,29,31,21,33] 자세 추정에서 다중 인물 [24,13,3,23,6,26,20,7] 자세 추정으로 큰 발전을 목격했으며, 이 중 다중 인물 자세 추정은 일반적으로 하향식(bottom-up) [24,13,3,20,22,7] 방법과 상향식(top-down) [23,6,11,32,26] 방법으로 나눌 수 있습니다.
최신 상향식 방식 [6,32,16] 대부분은 네트워크 구조 설계에 초점을 맞추고 있지만, 우리는 또 다른 근본적 요소인 데이터 처리(data processing) 측면에 주목합니다. 모든 시각 인식(visual recognition) 과제는 데이터 처리와 함께 태어나며, 일반적으로 서로 다른 좌표계 간 변환이나 데이터 증강(data augmentation) 같은 데이터 처리 방식을 서로 공유합니다. 그러나 분류 [25], 물체 탐지(object detection) [17], 의미론적 분할(semantic segmentation) [19,8] 등 다른 과제들과 비교했을 때, 인간 자세 추정 알고리즘의 성능은 평가 원리 때문에 데이터 처리 방식에 훨씬 더 민감합니다. 인간 자세 추정의 평가에서는, 정답 레이블(ground truth)과 예측 결과 사이의 위치적 편차에 기반해 지표를 계산하는데[17,1], 이때 데이터 처리로 인해 발생하는 작은 체계적 편향(systematic bias)도 자세 추정기의 성능을 저하시킬 수 있습니다.
현재까지 우리가 아는 한, 인간 자세 추정 커뮤니티에서는 데이터 처리가 체계적으로 다루어지지 않았습니다. 이 주제에 주목해보면, 최신 기법 [6,32,16,26] 대부분이 다음의 두 가지 공통 문제를 겪고 있음을 발견합니다. (i) 뒤집기(flipping) 전략을 사용했을 때 추론 단계에서 결과가 원본과 정렬되지 않는 문제로, 이는 이산 공간(discrete space)에서 문제를 분석하고, 데이터 변환 시 영상 크기를 측정할 때 픽셀(pixel)을 사용하는 데서 비롯됩니다. (ii) 학습과 추론 과정 각각에서 발생하는 표준 인코딩-디코딩(encoding-decoding)의 통계적 오류(statistical error)입니다.
우리는 SimpleBaseline[32]과 HRNet[26]에서 사용된 편향된 데이터 처리 방식을 예시로 들어, 이러한 문제들을 해결하고자 합니다. 정량적 분석 결과, 앞서 언급한 두 문제가 결합되어 자세 추정 성능을 크게 저하시킨다는 사실을 확인했습니다. 이 분석 결과를 바탕으로, 우리는 이 딜레마를 해결하기 위해 원칙적인 비편향적 데이터 처리(Unbiased Data Processing, UDP)를 제안합니다. 구체적으로, 우리는 연속 공간(continuous space)에서의 데이터 변환을 분석하고, 영상 크기를 측정할 때 픽셀이 아니라 픽셀 간 간격(unit length)을 사용함으로써, 추론 단계에서 뒤집기를 수행했을 때 자세 결과가 정렬되도록 만들었습니다. 또한, 분류와 회귀를 결합한 자세 추정 기법[23]에서 영감을 받아, 제안한 데이터 변환과 협력하여 이론적으로 오류가 없는 인코딩-디코딩 방식을 고안해 성능을 한층 더 향상했습니다. 주목할 점은, UDP는 모델에 구애받지 않는 접근법이므로 대부분의 상향식 파이프라인에 적용할 수 있다는 것입니다. 난이도가 높은 COCO 인간 자세 추정 데이터셋에서, 제안된 UDP는 경쟁 기법들 중 새로운 최고 성능을 달성했습니다. 그림 1에서 보이듯이, COCO test-dev 세트에서 제안 기법은 SimpleBaseline에 대해 ResNet50-256 × 192와 ResNet152-256 × 192 구성에서 각각 1.5 AP(70.2에서 71.7로)와 1.0 AP(71.9에서 72.9로) 향상을 가져왔습니다. HRNet의 W32-256 × 192와 W48-256 × 192 구성에서는 각각 1.7 AP(73.5에서 75.2로)와 1.4 AP(74.3에서 75.7로) 향상을 달성했습니다. UDP를 탑재한 HRNet-W48-384 × 288은 76.5 AP(1.0 상승)를 기록하며, 인간 자세 추정의 새로운 최고 성능을 세웠습니다.
본 논문의 주요 기여점은 아래와 같이 요약할 수 있습니다.
- 본 논문은 인간 자세 추정에서 흔히 발생하는 편향된 데이터 처리 방식을 정량적으로 분석합니다. 흥미롭게도, 표준 데이터 변환과 인코딩-디코딩에서 발생하는 체계적 오류가 결합되어 상향식 파이프라인의 성능을 크게 저하시킨다는 사실을 발견했습니다. 우리가 아는 한, 이는 자세 추정 커뮤니티에서 데이터 처리를 체계적으로 다루는 첫 연구입니다.
- 분석 결과를 바탕으로, 본 논문은 unit length 기반 측정과 분류·회귀를 결합한 인코딩-디코딩 방식을 포함하는 원칙적인 비편향적 데이터 처리(UDP) 전략을 제시합니다. 제안된 UDP는 모델에 구애받지 않는 전략으로, 대부분의 상향식 자세 추정기에 적용 가능합니다. 우리는 UDP가 결과 재현성과 향후 연구에 있어 중요한 역할을 할 것으로 기대합니다.
- 난이도가 높은 COCO 인간 자세 추정 데이터셋에서, UDP는 다양한 백본(backbone)과 입력 크기에서 기존 최고 성능을 큰 폭으로 향상시킵니다. 구체적으로, UDP를 탑재한 HRNet-W48-384 × 288은 COCO test-dev 세트에서 76.5 AP를 달성하며, 인간 자세 추정 분야의 새로운 최고 성능을 기록했습니다. 주목할 점은, 제안 기법은 학습과 추론 과정에서 계산 부담을 무시할 만한 수준으로만 증가시킨다는 것입니다.
2. Related Work
Bottom-up methods
바텀업(bottom-up) 방식은 입력 영상에 있는 모든 사람에 대해, 여러 종류의 키포인트에 대한 히트맵(heatmap)을 예측하고 이를 이용해 사람 인스턴스로 묶는 과정을 통해 신원 정보가 없는 관절들을 먼저 감지하는 방식입니다. OpenPose [3]는 키포인트 히트맵과 쌍별 관계(부위 친화 필드, part affinity fields)를 예측하기 위한 두 개의 브랜치를 포함하는 모델을 제안했습니다. Newell 등[20] 은 하나의 네트워크에서 히트맵 예측과 그룹화 과정을 모두 수행합니다. 그룹화는 어소시에이션 임베딩(association embedding)을 이용하여, 각 키포인트에 태그(tag)를 할당하고 태그 벡터 간 L2 거리로 키포인트를 묶는 방식입니다. MultiPoseNet [14]은 사람 검출과 자세 추정을 동시에 수행하며, PRN이라는 기법을 통해 각 사람의 바운딩 박스 내 키포인트를 그룹화합니다. HigherHRNet [7]은 고해상도 특징 맵(high-resolution feature map)을 유지하여, 예측 정밀도를 효과적으로 향상시킵니다.
Top-down methods
톱다운(top-down) 방식은 두 단계에 걸쳐 다중 인물 자세 추정을 수행합니다. 먼저 사람 탐지기를 통해 사람 바운딩 박스(person bounding box)를 구하고, 그 내부에서 키포인트 위치를 예측하는 식입니다. CPN [6]과 MSPN [16]은 캐스케이드(cascade) 네트워크를 사용하여 키포인트 예측을 정교화하며, COCO 키포인트 챌린지에서 선두적인 기법으로 꼽힙니다. SimpleBaseline [32]은 몇 개의 디컨볼루션(deconvolution) 레이어를 추가하여 출력 특징 맵의 해상도를 높입니다. 이는 구조가 단순하지만 성능 개선에 효과적입니다. HRNet [26]은 전 과정에서 고해상도 표현(high-resolution representations)을 유지하여, 공개 데이터셋에서 최첨단(state-of-the-art) 성능을 달성했습니다. Mask R-CNN [11]은 엔드-투-엔드(end-to-end) 프레임워크를 구축하며, 성능과 추론 속도 간에 우수한 균형을 이룹니다. 단일 인물 자세 추정은 고정된 스케일의 패치로 처리되므로, 다중 인물에 대한 많은 인기 벤치마크에서의 최신 최고 성능은 주로 톱다운 방식에 의해 달성됩니다.
Data processing in human pose estimation
톱다운 패러다임을 사용하는 인간 자세 추정에서의 데이터 처리는 주로 데이터 변환(data transformation), 데이터 증강(data augmentation), 인코딩-디코딩(encoding-decoding)으로 구성됩니다.
Data transformation
데이터 변환은 원본 영상, 네트워크 입력, 출력 등 서로 다른 좌표계 사이에서 키포인트 위치를 변환하는 과정을 말합니다. 이 과정에서 최신 기법 [6,32,16,26] 대부분은 영상을 픽셀(pixel) 단위로 측정하여, 추론 시 뒤집기(flipping) 전략을 사용할 때 결과가 정렬되지 않는 문제를 야기합니다. [32,26]은 뒤집은 이미지의 결과를 네트워크 입력 좌표계에서 1픽셀만 이동시켜 예측 오류를 억제하는 경험적 방식을 사용하고, [6,16]은 평균 결과를 2픽셀 이동시켜 유사한 효과를 얻습니다. 이러한 보정들은 어느 정도 효과가 있으나 한계가 있습니다.
Data augmentation
데이터 증강은 샘플의 다양성을 높이는 일반적인 전략으로, 알고리즘의 견고성을 향상시키는 데 도움이 됩니다. 대표적인 증강 기법으로는 랜덤 회전, 랜덤 스케일, 뒤집기, half body[26] 등이 있으며, 이 모든 데이터 증강은 원본 영상에서 네트워크 입력으로 변환되는 과정에서 수행됩니다.
encoding-decoding
마지막으로, 인코딩-디코딩은 관절 좌표(joint coordinates)와 히트맵(heatmaps) 간 변환을 의미하며, 이는 최초로[29]에서 제안되어 이후 [11,7,6,32,16,26] 등 최신 기법에 폭넓게 사용되었습니다. 학습 과정에서는 키포인트 위치를 중심으로 한 가우시안 분포를 사용하여 정답(ground truth)을 히트맵으로 인코딩하며 [27], 추론 과정에서 네트워크가 예측한 히트맵을 키포인트 좌표로 다시 변환(디코딩)합니다. 이 파이프라인은 키포인트 좌표를 직접 예측하는 것보다 우수한 성능을 보이지만 [27], 예측 정확도를 떨어뜨리는 체계적 오류(systematic error)를 야기합니다. 반면, 분류와 회귀를 결합한 인코딩-디코딩 패러다임 [23]은 오류가 없는(error-free) 접근 방식을 제공함으로써 톱다운 기법의 예측 정확도를 더욱 향상시키는 역할을 합니다.
3. Unbiased Data Processing for Human Pose Estimation
본 절에서는 최신 기법에서 사용되는 표준 데이터 처리 방식을 두 가지 측면(데이터 변환과 인코딩-디코딩)에서 분석합니다. 이후 이 분석을 바탕으로, 자세 추정기의 성능을 효과적으로 향상시키는 비편향적 데이터 처리 전략을 제안합니다.
Symbol Definition
본 논문에서는 세 가지 좌표계를 사용합니다. 즉, 원본 이미지 좌표계($O_s−X_s−Y_s$), 네트워크 입력 좌표계(잘린/리사이즈된 이미지 좌표계, $O_i−X_i−Y_i$), 그리고 네트워크 출력 좌표계(히트맵 좌표계, $O_o−X_o−Y_o$)입니다. 이 세 좌표계는 각각 원본 이미지 공간(위 첨자 $s$), 네트워크 입력 이미지 공간(위 첨자 $i$), 네트워크 출력 이미지 공간(위 첨자 $o$)을 정의합니다. 인코딩-디코딩과 관련된 히트맵은 네트워크 출력 이미지 공간에서 정의됩니다. 이후 설명에서는 위 첨자 $p$가 픽셀(pixel) 단위로 길이를 측정한다는 의미로 사용되며, 그 외 경우에는 해당 공간에 관련된 유닛 렝스(unit length)로 길이가 측정됩니다. 이미지 행렬과 이에 대응하는 키포인트 좌표는 각각 $\mathbf{I}$와 $\mathbf{k}$로 표기하며, 모자가 씌워진 기호 $\hat{\mathbf{k}}$ 는 해당 정답 레이블 $\mathbf{k}$에 대한 네트워크 예측 결과를 의미합니다.
3.1. Data Transformation
3.1.1 Analysis of the Standard Data Transformation
데이터 변환(data transformation)이란, 키포인트 위치를 서로 다른 좌표계 간에 잘라내기(cropping), 회전(rotation), 리사이즈(resizing), 뒤집기(flipping) 등의 방식으로 변환하는 과정을 의미합니다. 기존의 자세 추정 기법들은 영상을 픽셀(pixel) 단위로 측정하는데, 이는 이산 공간(discrete space)에서의 방식입니다. 그러나 위치 결정이라는 과제의 관점에서 보면, 픽셀은 사실상 (연속 공간인) 영상 평면 상의 샘플 지점 일부입니다. 예를 들어, 어떤 영상의 크기가 픽셀 단위로 $(^pw,^ph)$라면, 연속적인 영상 평면에서의 크기는 $(^pw−1,^ph−1)$이 됩니다. 픽셀을 기준으로 크기를 측정하는 방식은 추론 단계에서 사실상 표준으로 사용되는 뒤집기(flipping) 전략을 적용할 때 성능을 크게 저하시킬 수 있습니다 [32, 26].
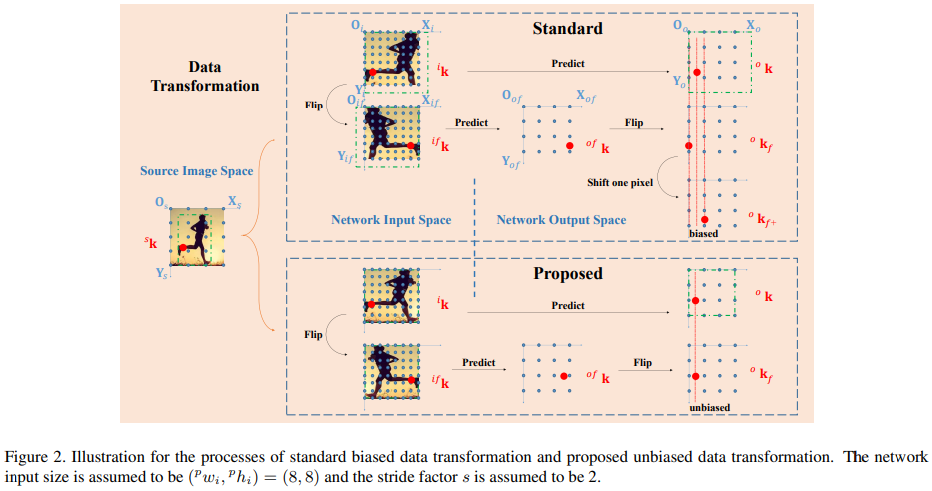
학습 과정에서 톱다운 파이프라인은 먼저 원본 이미지를 네트워크 입력 공간에서 사용할 증강(augmented) 샘플로 변환합니다. 네트워크 입력 영상 행렬을 $^iI$라 하고, 그 크기를 $(^pw_i,^ph_i)$, 해당하는 키포인트 좌표를 $^i\mathbf{k}$라 하겠습니다. 그림 2에서 보이듯이, 네트워크 입력을 원본 이미지 공간으로 매핑할 때, 원본 영상의 내용물 크기는 $O_s−X_s−Y_s$ 좌표계에서 중심 $(^sx_b, ^sy_b)$, 스케일 $(^sw_b, ^sh_b)$을 갖는 바운딩 박스(그림 2의 녹색 박스) 형태로 표현할 수 있습니다. 표준 기법 [32, 26]을 통해 구해지는 $^i\mathbf{k}$는 다음과 같이 나타낼 수 있습니다.
\[^i\mathbf{k} = \begin{bmatrix} \frac{^pw_ic\theta}{^sw_b} & -\frac{^pw_is\theta}{^sw_b} & \frac{^pw_i}{^sw_b}(-^sx_bc\theta+^sy_bs\theta+0.5^sw_b)\\ \frac{^ph_is\theta}{^sh_b} & -\frac{^ph_ic\theta}{^sh_b} & \frac{^ph_i}{^sh_b}(-^sx_bs\theta-^sy_bc\theta+0.5^sh_b)\\ 0 & 0 & 1 \\ \end{bmatrix} {^s\mathbf{k}} \tag{1}\]여기서 $cθ$와 $sθ$는 각각 $cos(θ)$와 $sin(θ)$를 의미하며, $θ$는 회전(rotation) 증강에서 사용되는 각도입니다. 이 변환 과정에 대한 자세한 내용은 부록(appendix)에 서술되어 있습니다. 또한, 네트워크 입력 행렬의 각 픽셀은 다음 식을 통해 원본 이미지로 역추적(backtrack)할 수 있습니다.
\[^s\mathbf{x} = \begin{bmatrix} \frac{^sw_bc\theta}{^pw_i} & \frac{^sw_bs\theta}{^ph_i} & -0.5^sw_bc\theta-0.5^sh_bs\theta+^sx_b\\ \frac{^sw_bs\theta}{^pw_i} & \frac{^sh_bc\theta}{^ph_i} & 0.5^sw_bs\theta-0.5^sh_bc\theta+^sy_b\\ 0 & 0 & 1 \\ \end{bmatrix} {^i\mathbf{x}} \tag{2}\]여기서 $^i\mathbf{x}$는 영상 행렬 $^iI$에서 각 픽셀의 좌표를 나타냅니다. 그림 2에서 보이듯이, 표준 방식으로 만든 증강 샘플은 다음 두 단계를 통해 생성된 결과와 동등하게 볼 수 있습니다.
- 원본 이미지에서 관심 영역을 잘라낸 뒤, $(^pw_i+1, ^ph_i+1)$ 크기로 리사이즈합니다(그림 2에 보이는 네트워크 입력 공간의 녹색 박스).
- 위에서 얻은 결과의 오른쪽 가장자리와 아래쪽 가장자리를 각각 1픽셀씩 제거하여, 최종적으로 $(^pw_i, ^ph_i)$ 크기의 영상을 얻습니다.
이 방법으로 생성된 학습 샘플은 의미론적으로 원본 샘플과 정렬되어 있으며(즉, 포즈 레이블의 위치가 제대로 유지됨), 히트맵의 크기가 $(^pw_o, ^ph_o)$일 때 표준 기법들은 스트라이드 계수 $s= ^pw_i / ^pw_io=^ph_i/^pho$ 를 통해 입력 키포인트 위치를 아래와 같이 변환합니다.
\[^o\mathbf{k}=\frac{1}{s}{^i\mathbf{k}} \tag{3}\]여기서 $^o\mathbf{k}$는 네트워크 출력 히트맵 상의 키포인트 좌표입니다. 학습 과정에서 네트워크는 입력 영상 정보를 바탕으로, $^o\mathbf{k}$ 위치를 중심으로 하는 응답 맵(response map)을 추론하는 패턴을 학습하게 됩니다.
추론 단계에서, 표준 기법은 네트워크 출력 결과 $^o\hat{\mathbf{k}}$ 를 다음 식 (4)를 통해 원본 이미지 공간으로 매핑합니다.
여기서 $^s\hat{\mathbf{k}}$는 원본 이미지 공간에서 최종 예측된 키포인트의 위치를 의미합니다. 이 변환은 다음 두 단계로 등가적으로 표현할 수도 있습니다.
- 네트워크 출력 히트맵의 크기를 $(^pw_o,^ph_o)$ 에서 $(^pw_o+1,^ph_o+1)$ 로 패딩(padding)합니다(그림 2의 네트워크 출력 공간에 있는 녹색 박스).
- 위에서 패딩한 히트맵을 원본 이미지의 해당 바운딩 박스로 매핑합니다.
이상적으로는 $^s\hat{\mathbf{k}}$ 가 $^s\mathbf{k}$ 와 동일해야 하지만, 뒤집기(flipping) 전략을 적용하면 결과에 편향이 발생합니다. 표준 기법은 네트워크 입력 영상을 뒤집는데, 그때 키포인트 $^i\mathbf{k}$가 다음과 같이 위치합니다.
\[^{if}\mathbf{k} = \begin{bmatrix} -1 & 0 & ^pw_i-1\\ 0 & 1 & 0\\ 0 & 0 & 1 \\ \end{bmatrix} {^i\mathbf{k}} \tag{5}\]$^{if}\mathbf{k}$ 는 뒤집힌 영상에서 $^i\mathbf{k}$ 에 해당하는 키포인트 위치입니다. $^{if}\mathbf{k}$ 는 뒤집힌 영상에서 $^i\mathbf{k}$ 에 해당하는 키포인트 위치입니다. 식 (3)에 따르면, 표준 기법은 출력 히트맵에서 키포인트를 다음처럼 예측합니다.
\[^{of}\hat{\mathbf{k}}=\frac{1}{s}{^{if}\mathbf{k}} \tag{6}\]그리고 뒤집어진 영상의 최종 결과 $^o\hat{\mathbf{k}}_f$ 는 다음과 같이 다시 뒤집어서 얻습니다.
\[^{o}\hat{\mathbf{k}}_f = \begin{bmatrix} -1 & 0 & ^pw_o-1\\ 0 & 1 & 0\\ 0 & 0 & 1 \\ \end{bmatrix} {^{of}\hat{\mathbf{k}}} = \begin{bmatrix} 1 & 0 & -\frac{s-1}{s}\\ 0 & 1 & 0\\ 0 & 0 & 1 \\ \end{bmatrix} {^{o}\hat{\mathbf{k}}} \tag{7}\]여기서 $^o\hat{\mathbf{k}}_f$ 는 $^o\hat{\mathbf{k}}$ 와 정확히 일치하지 않으며, $O_o-X_o$ 방향으로 $-\frac{s-1}{s}$ 만큼 오프셋(offset)이 생깁니다. [32, 26]에서 제시된 바와 같이 $^o\hat{\mathbf{k}}$ 와 $^o\hat{\mathbf{k}_s}$ 를 직접 평균을 취하면,
\[^{o}\hat{\mathbf{k}}_a=\frac{^o\hat{\mathbf{k}}_f+^o\hat{\mathbf{k}}}{2} \tag{8}\]$O_o-X_o$ 방향의 오차는 다음과 같습니다.
\[^oe(x) = \vert x(^o\mathbf{k})-x(^o\hat{\mathbf{k}_a}) \vert =\vert -\frac{s-1}{2s} \vert \tag{9}\]표준 방식 [32, 26]은 평균 연산 전에 뒤집힌 결과를 1픽셀만큼 이동시켜 이 차이를 줄입니다.
\[^{o}\hat{\mathbf{k}}_{f+} = \begin{bmatrix} 1 & 0 & 1\\ 0 & 1 & 0\\ 0 & 0 & 1 \\ \end{bmatrix} {^{o}\hat{\mathbf{k}}_k} = \begin{bmatrix} 1 & 0 & \frac{1}{s}\\ 0 & 1 & 0\\ 0 & 0 & 1 \\ \end{bmatrix} {^{o}\hat{\mathbf{k}}} \tag{10}\]이를 통해 최종 오차는 $^oe(x)’= \vert \frac{1}{s2} \vert$ 로 줄어듭니다. $s>2$ 인 경우 $^oe(x)’<^oe(x)$ 가 되므로, 대부분의 기존 기법에서 이 방식이 사용됩니다. 직관적으로 $^oe(x)’$ 에 대한 보상(compensation)은 결과를 더 정확하게 만들 수 있으나, 이런 직접적인 보정이 기여하는 정도는 제한적입니다. 섹션 3.2에서 이 비효율성에 대한 자세한 분석을 제시합니다. 또한, $^oe(x)’$ 를 원본 이미지 좌표계 $(O_s−X_s−Y_s)$ 로 다시 매핑하고 식 (4)에서 $θ=0$ 인 경우를 고려하면,
\[^se(x)'=\vert \frac{1}{2s} \times \frac{^sw_b}{^pw_i} \vert = \vert \frac{^sw_b}{2{^pw_i}}\vert \tag{11}\]이때 $^sw_b$는 추론 과정에서 고정된 값입니다. 따라서 더 큰 네트워크 입력 크기는 $^eo(x)’$ 로 인해 발생하는 예측 오차를 줄이는 데 유리합니다. 다시 말해, 표준 기법은 입력 해상도가 높을수록 이점을 얻고, 입력 해상도가 낮을수록 정확도 손실이 커집니다.
3.1.2 The Proposed Data Transformation
본 논문에서는 오정렬(misalignment) 문제를 해결하기 위한 원칙적 방법을 제안합니다. 구체적으로, 우리는 유닛 렝스(unit length)를 영상 크기 측정 기준으로 채택하는데, 이는 특정 공간에서 인접한 두 픽셀 사이의 거리를 의미합니다. 이 개념에 기반하여, 네트워크 입력 공간에서의 정답 레이블 $^i\mathbf{k}$은 다음 변환을 통해 얻어져야 합니다.
\[^{i}\mathbf{k} = \begin{bmatrix} \frac{^pw_i-1}{^sw_b/c\theta} & -\frac{^pw_i-1}{^sw-b/s\theta} & \frac{^pw_i-1}{^sw_i}(-^sx_bc\theta+^sy_bs\theta+0.5^sw_b)\\ \frac{^ph_i-1}{^sh_b/s\theta} & -\frac{^ph_i-1}{^sh-b/c\theta} & \frac{^ph_i-1}{^sh_i}(-^sx_bs\theta+^sy_bc\theta+0.5^sh_b)\\ 0 & 0 & 1 \\ \end{bmatrix} {^s\mathbf{k}} \tag{12}\]또한, 네트워크 입력 이미지 행렬 내 각 픽셀을 원본 이미지 공간으로 역추적(backtrack)하려면 다음 식을 사용합니다.
\[^{s}\mathbf{x} = \begin{bmatrix} \frac{^sw_bc\theta}{^pw_i-1} & \frac{^sh_bs\theta}{^ph_i-1} & -0.5^sw_bc\theta-0.5^sh_bs\theta+^sx_b\\ -\frac{^sw_bs\theta}{^pw_i-1} & \frac{^sh_bc\theta}{^ph_i-1} & 0.5^sw_bs\theta-0.5^sh_bc\theta+^sy_b\\ 0 & 0 & 1 \\ \end{bmatrix} {^i\mathbf{x}} \tag{13}\]히트맵 상에서 정답 레이블을 생성할 때는 맵을 연속 공간으로 측정해야 하며, 다음과 같은 계수 $t=(^pw_i-1)/(^pw_o-1)=(^ph_i-1)/(^ph_o-1)$ 를 사용합니다.
\[^o\mathbf{k}=\frac{1}{t} {^i\mathbf{k}} \tag{14}\]이렇게 하면 뒤집힌 영상 결과 $^o\hat{\mathbf{k}}_f$ 가 원본 결과 $^o\hat{\mathbf{k}}$ 와 정확히 정렬됩니다. 마지막으로, 원본 이미지 공간에서의 예측 $^s\hat{\mathbf{k}}$ 는 다음 역변환(inverse transformation)을 통해 구합니다.
\[^{s}\hat{\mathbf{k}} = \begin{bmatrix} \frac{^sw_bc\theta}{^pw_o-1} & \frac{^sh_bs\theta}{^ph_o-1} & -0.5^sw_bc\theta-0.5^sh_bs\theta+^sx_b\\ -\frac{^sw_bs\theta}{^pw_o-1} & \frac{^sh_bc\theta}{^ph_o-1} & 0.5^sw_bs\theta-0.5^sh_bc\theta+^sy_b\\ 0 & 0 & 1 \\ \end{bmatrix} {^o\hat{\mathbf{k}}} \tag{15}\]3.2. Encoding and Decoding
앞선 분석은 키포인트 위치와 히트맵 간 인코딩-디코딩 과정이 정확하다는 전제($\hat{\mathbf{k}}=\mathbf{k}$) 하에서 이루어졌습니다. 그러나 이 전제는 표준 기법 [32, 26]에는 적용되지 않습니다. 이어지는 내용에서는 먼저 표준 인코딩-디코딩에서 발생하는 체계적 오류($∣\hat{\mathbf{k}}−\mathbf{k}∣$)를 살펴보고, 이 오류가 앞선 결론들에 어떻게 영향을 미치는지를 보여줍니다. 이 절에서는 네트워크 출력 히트맵 좌표계 $O_o−X_oY_o$ 만 사용합니다.
3.2.1 Analysis of the Standard Encoding-decoding
The standard encoding method.
정식으로, 히트맵 상의 정답 레이블 점 $\mathbf{k}=(m,n)$ 이 주어졌을 때, [26, 32]는 먼저 레이블 점 좌표를 정수 형태로 양자화하여 $\mathbf{k}_q$ 를 구합니다.
\[\mathbf{k}_q=(m_q,n_q)=\mathcal{R}(\mathbf{k})=(\mathcal{R}(m), \mathcal{R}(n)) \tag{16}\]여기서 $\mathcal{R}$ 은 반올림(rounding) 연산을 의미합니다. 이후 $\mathbf{k}_q$ 를 중심으로 하는 히트맵은 다음과 같이 생성됩니다.
\[\mathcal{H}(x, y, \mathbf{k}_q)=\exp(-\frac{(x-m_q)^2+(y-n_q)^2}{2\delta^2}) \tag{17}\]여기서 $(x,y)$는 히트맵의 각 요소 좌표를, $δ$는 고정된 공간 분산(spatial variance)을 나타냅니다.
The standard decoding method.
학습된 네트워크 예측 $\hat{\mathcal{H}}(x,y,\hat{\mathbf{k}})$ 가 있고, $\hat{\mathcal{H}}=\mathcal{H}$ 라는 이상적 조건에서 [26, 32]는 우선 응답(response)이 가장 높은 위치를 찾는 방식으로 디코딩을 수행합니다.
\[\hat{\mathbf{k}}_q = (\hat{m}_q, \hat{n}_q) = argmax(\hat{\mathcal{H}}) \tag{18}\]식 (17)과 (18)에 따르면, 히트맵에서 예측된 키포인트의 $x$ 좌표는 다음과 같습니다.
\[\hat{m}_q = \begin{cases} \mathcal{F}(m) & \text{if } m-\mathcal{F}(m)<0.5 \\ \mathcal{C}(m) & \text{otherwise} \\ \end{cases} \tag{19}\]여기서 $\mathcal{F}$ 와 $\mathcal{C}$ 는 각각 바닥(floor), 천장(ceil) 연산을 의미합니다. 이상적으로 $\hat{\mathbf{k}}_q$ 위치가 $\mathbf{k}_q$ 와 동일하다고 할 때, $\mathbf{k}$ 가 영상 평면에서 균일하게 분포한다고 가정하면, 각 방향에서의 기댓오차 $E(\vert m-\hat{m}_q\vert)$ 와 $E(\vert n-\hat{n}_q\vert)$ 는 모두 $1/4$ 유닛 렝스이고, 분산은 $1/48$ 입니다. 이 오차를 줄이기 위해 [26, 32]는 응답의 기울기($∇$)를 이용하여 $\hat{\mathbf{k}}_q$ 를 각각 0.25 유닛 렝스만큼 이동시킵니다.
\[\hat{\mathbf{k}} = \hat{\mathbf{k}}_q+0.25\nabla(\hat{\mathcal{H}})|_{\mathbf{x=\hat{\mathbf{k}}_q}} \tag{20}\]$∇$는 기울기 연산자이며, 이 연산을 통해 디코딩 결과 분포는 아래와 같이 바뀝니다.
\[\hat{m} = \begin{cases} \mathcal{F}(m)+0.25 & \text{if } m-\mathcal{F}(m) < 0.5 \\ \mathcal{C}(m)-0.25 & \text{otherwise} \end{cases} \tag{21}\]이에 따라 각 방향에서의 기댓오차 $E(\vert m-\hat{m}\vert)=E(\vert n-\hat{n}\vert)=1/8$ 유닛 렝스로 줄어들고, 분산은 $1/192≈0.0052$ 가 됩니다.
이제 $E(\vert m-\hat{m}\vert )$ 를 원본 이미지 좌표계 $(O_s-X_sY_s)$ 로 매핑하고, $θ=0$ 인 식 (4)를 고려하면 다음을 얻습니다.
오차 $E(\vert m-\hat{m}\vert)$ 와 $E(\vert n-\hat{n}\vert)$ 를 고려해보면, 고정된 스트라이드 계수 $s$를 사용하는 표준 기법 [32, 26] 또한 더 높은 네트워크 입력 해상도에서 이점을 얻을 수 있습니다.
3.1절에서 언급된 추론 단계 뒤집기(flipping)로 인한 테스트 오차 $^o(x)’=\frac{1}{2s}$ 는 오차 분포에 영향을 미칩니다. 예를 들어 특정 스트라이드 계수 $s=4$ [32, 26]인 경우, 예측 히트맵이 $\hat{\mathcal{H}}’= \mathcal{H}(x,y,m+0.125,n+0.125)$ 로 변경되어, 디코딩 결과 분포는 아래와 같이 됩니다.
그리고 $O_o-X_o$ 방향에서의 기댓오차는 $1/32$ 유닛 렝스가 추가되어 $E(\vert m-\hat{m}’\vert)=5/32$, 분산은 $V(\vert m-\hat{m}’\vert)=37/3072≈0.012$ 로 계산됩니다. 디코딩 오류가 지배적이므로, 데이터 변환 오류가 최종 예측 성능에 미치는 영향은 작습니다. 만약 데이터 변환 오류만 보정해도, 그 기여도는 훈련 과정에서 불안정성을 야기하는 정도보다 더 작을 수 있습니다.
통계적 관점에서 보면, $\hat{m}’$ 에 $-\frac{1}{2s}$ 유닛 렝스만큼 직접 보상(compensation)해주면 $^oe(x)’$ 로 인한 영향을 완전히 제거할 수 있습니다. 즉 $E(\vert m-(\hat{m}-0.125)\vert)=1/8$ 은 $E(\vert m- \hat{m} \vert)$ 와 정확히 동일하고, $V(\vert m-(\hat{m}’-0.125)\vert)=1/192$ 역시 $V(\vert m-\hat{m}\vert)$ 와 동일합니다. 이러한 보상은 효과적이지만 한계가 있으며, 표준 방식이 야기하는 통계적 오류를 없애기 위해서는 추가적인 인코딩-디코딩 방법이 필요합니다.
3.2.2 The Proposed Encoding-decoding
[23]의 아이디어에 착안하여, 우리는 분류(classification)와 회귀(regression)를 결합한 인코딩-디코딩 방식을 도입합니다. 이 방식의 오류 기댓값은 0이 되도록 설계되어 있습니다. 먼저 각 정답 레이블 $\mathbf{k}=(m,n)$ 은 하나의 히트맵으로 인코딩됩니다.
\[\mathcal{H}(x,y,\mathbf{k})= \begin{cases} 1 & \text{if } (x-m)^2=(y-n)^2 < R \\ 0 & \text{otherwise} \end{cases} \tag{24}\]그리고 두 개의 오프셋 맵(offset map)이 정의됩니다.
\[\mathcal{X}(x,y,\mathbf{k})=m-x \tag{25}\] \[\mathcal{Y}(x,y,\mathbf{k})=n-y \tag{26}\]디코딩 시에는 우선 가우시안 커널 $K$를 이용해 히트맵을 필터링하여, 가장 높은 응답(response)이 정답 레이블 $\mathbf{k}$ 주변에 위치하도록 합니다. 그리고 나서 최고 점수 위치는 다음과 같이 찾습니다.
\[\hat{\mathbf{k}}_h=argmax{(\hat{\mathcal{H}}\otimes K)} \tag{27}\]여기서 $⊗$는 합성곱(convolution)을 의미하고, $K$ 는 방사형 기저(radial based) 함수에 따라 생성된 커널입니다.
\[K(x,y,N,\sigma) = \frac{\exp{(-\frac{(x-N)^2+(y-N)^2}{2\sigma^2})}}{\sum_x\sum_y\exp{(-\frac{(x-N)^+(y-N)^2}{2\sigma^2})}} \tag{28}\]이때 커널의 크기는 $2N+1$ 입니다. 마지막으로, 예측 좌표는 아래와 같이 오프셋 맵을 반영해 수정합니다.
\[\hat{\mathbf{k}} = \hat{\mathbf{k}}_h+[\hat{\mathcal{X}}(\hat{\mathbf{k}}_h,\mathbf{k})\otimes K,\hat{\mathcal{Y}}(\hat{\mathbf{k}}_h,\mathbf{k})\otimes K]^T \tag{29}\]여기서 $K$ 는 예측된 두 오프셋 맵을 스무딩(smoothing)하기 위해 사용됩니다. 이와 같은 방식으로, 이상적인 조건(즉, $\hat{\mathcal{H}}=\mathcal{H}, \hat{\mathcal{X}}=\mathcal{X}, \hat{\mathcal{Y}}=\mathcal{Y}$)에서는 예측값 $\hat{\mathbf{k}}$ 가 정답 $\mathbf{k}$ 와 이론적으로 동일해지며, 오류 기댓값이 0이 됩니다.
4. Experiments
4.1. Implementation Details
우리 모델은 COCO train 하위 집합으로 학습되었으며, 이 데이터셋에는 대략 57,000장의 이미지와 150,000개의 사람 인스턴스가 포함되어 있습니다. 제안된 UDP는 약 5,000장의 이미지로 구성된 val 세트와 20,000장의 이미지로 구성된 test-dev 세트에서 평가합니다. AP 평가 지표는 Object Keypoint Similarity(OKS)에 기반하여 산출됩니다. 우리는 비교를 위해 [32, 26]의 학습 설정을 엄격히 따랐습니다. 추론 시에는 HTC [5] 탐지기를 사용해 사람 인스턴스를 검출합니다. 멀티스케일 테스트를 적용했을 때, COCO val 세트 [17]에서 80개 클래스 기준 AP와 사람(person) AP는 각각 52.9와 65.1입니다. 이 탐지 결과를 사용해 HRNet [26]과 SimpleBaseline [32]의 COCO val 세트 결과를 재현하여 공정한 비교를 진행했습니다. 모든 결과는 단일 모델(single model)에 대한 성능이며, 뒤집기(flipping) 테스트 전략만 사용했습니다.
4.2. Comparison with State-of-the-arts
Results on the val set.
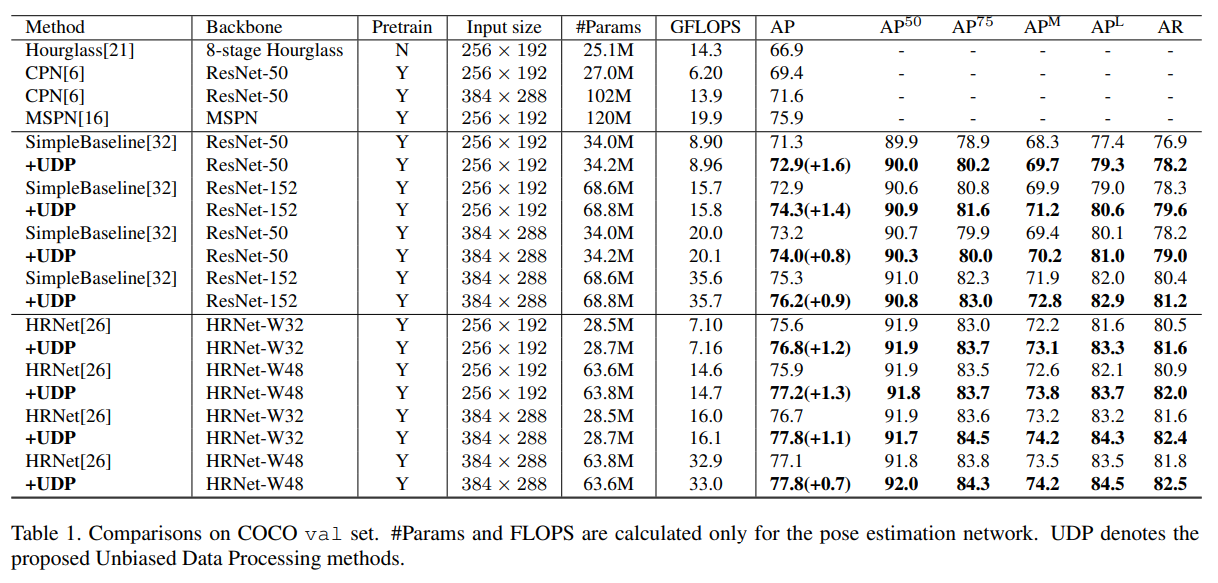
제안 기법과 최신 기법들의 결과는 표 1에 나와 있습니다. 우리는 SimpleBaseline [32]과 HRNet [26]이라는 최신 인간 자세 추정 기법들에 UDP를 적용했을 때의 성능 향상을 보고합니다. SimpleBaseline에서 ResNet-50 백본을 사용할 경우, AP가 각각 1.6(71.3에서 72.9로)과 1.4(72.9에서 74.3으로) 상승했습니다. 더 큰 백본을 사용할 경우에는 각각 0.8과 0.9 정도 향상됩니다. 다양한 백본과 입력 크기를 사용하는 HRNet에 대해, 제안된 UDP는 1.2 AP, 1.3 AP, 1.1 AP, 0.7 AP의 향상을 보였습니다. 주요 특징을 요약하면, (i) 서로 다른 백본에서 개선이 일관되게 나타나 UDP의 견고함을 보여주며, (ii) 작은 네트워크 입력을 사용할 때 얻는 개선 폭이 큰 네트워크 입력을 사용할 때보다 훨씬 크다는 점입니다. 이는 네트워크 입력 크기가 클수록 최신 기법에서 발생하는 데이터 처리 오류를 효과적으로 억제할 수 있음을 시사합니다.
Results on the test-dev set.
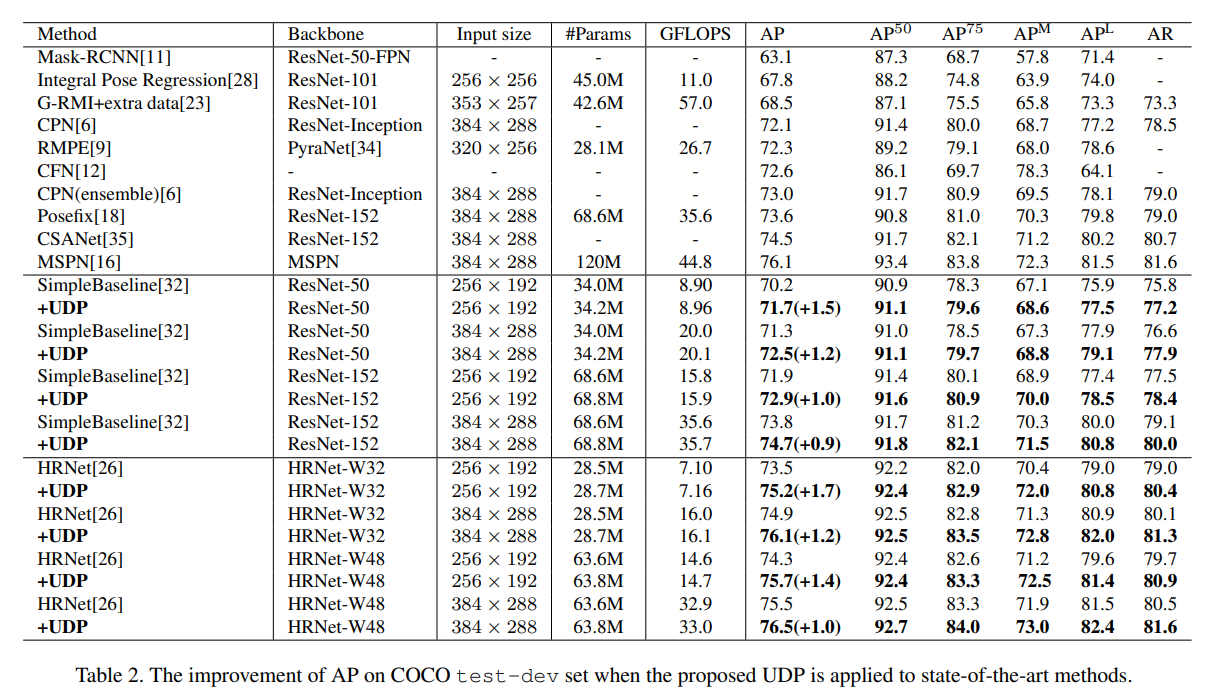
표 2는 COCO test-dev 세트에서 UDP의 성능을 보여줍니다. 결과는 val 세트보다 더 큰 성능 향상을 나타내며, 이는 제안된 UDP 기법의 뛰어난 일반화(generalization) 성능을 시사합니다. 구체적으로, SimpleBaseline에 대해서는 ResNet50-256×192 구성에서 1.5 AP(70.2에서 71.7로), ResNet152-256×192 구성에서 1.0 AP(71.9에서 72.9로) 향상을 달성했습니다. HRNet의 W32-256×192와 W48-256×192 구성에 대해서는 각각 1.7 AP(73.5에서 75.2로), 1.4 AP(74.3에서 75.7로) 성능이 향상되었습니다. UDP를 탑재한 HRNet-W48-384×288은 76.5 AP를 달성하며, 인간 자세 추정의 새로운 최고 성능을 기록했습니다. 주목할 점은, 제안 기법은 학습과 추론 과정에서의 계산량을 거의 증가시키지 않는다는 것입니다.
4.3. Ablation Study

이 절에서는 HRNet-W32 백본과 256×192 입력 크기를 사용하여 에블레이션(소거) 연구를 진행합니다. 먼저 [26]에서 사용한 1픽셀 이동 연산의 효과를 보고합니다. 표 3에 나타난 것처럼, 방법 F는 뒤집힌(flipped) 영상의 히트맵을 1픽셀만큼 이동시키며, 이는 방법 E 대비 2.3 AP의 향상을 가져옵니다. 그런데 방법 E로 얻은 결과는 뒤집기 전략을 사용하지 않은 방법 A보다도 훨씬 낮습니다. 이처럼 이전에 보고되지 않은 1픽셀 이동 기법 [32, 6, 26, 16]은 다른 연구들과의 비교를 불공정하게 만들 가능성이 있습니다.
다음으로, [26]에서 언급된 기존 정밀도 오류 $^oe(x)’$ 를 직접 보정하기 위해, 우리는 $\hat{\mathbf{k}}_a$ 를 $O_o-X_o$ 방향으로 $-\frac{1}{2s}$ 유닛 렝스만큼 이동시킵니다. 표 3에 따르면, 이 보정(방법 G)은 방법 F 대비 0.2 AP의 향상을 달성합니다. 이는 합리적이지만 작은 폭의 개선입니다. 3.2절에서 분석했듯이, 이러한 보정이 오류 분포에 미치는 영향은 제한적이며, 인코딩-디코딩에서 기인하는 체계적 오류가 성능에 더 지배적인 영향을 줍니다.
다음으로, 우리는 표준 데이터 변환을 제안된 데이터 변환으로만 교체했습니다. 이 수정(방법 H, 75.7 AP)은 1픽셀 이동과 $^oe(x)’$ 에 대한 추가 보정을 요구하는 방법 G(75.8 AP)와 유사한 효과를 냅니다. 제안된 데이터 변환은 추론에서 비편향(unbiased) 결과를 보장하며, 1픽셀 이동이나 잔여 오류 $^oe(x)’$ 를 보정하는 등 복잡한 후처리를 하지 않아도 되도록 해 줍니다. 또한 방법 H(75.7 AP)와 방법 G(75.8 AP)는 모두 방법 E(73.3 AP)와 비교했을 때 큰 성능 향상을 가져오는데, 이는 결과 재현성을 위해 비편향 데이터 변환이 얼마나 중요한지를 보여줍니다.
한편, 표준 인코딩-디코딩 방식을 제안된 방식으로 교체해보았습니다. 이 수정은 1픽셀 이동 없이 74.5 AP(방법 I), 1픽셀 이동 시 76.6 AP(방법 J)를 달성하며, 각각 표준 방식 [26]의 방법 E와 F 대비 1.2 AP, 1.0 AP의 성능 향상을 보여줍니다. 제안된 무오류(error-free) 인코딩-디코딩 방식은 공정한 비교 상황에서 자세 추정 문제에서의 우수성을 입증합니다. 아울러 비편향 데이터 변환은 방법 검증에서 정밀하고 공정한 비교를 가능케 하며, 이는 향후 연구에서 중요해질 것으로 예상됩니다. 마지막으로, 방법 K는 기존 HRNet(방법 F)에 제안된 비편향 데이터 처리 방식을 적용하여 1.2 AP의 인상적인 성능 향상을 보여줍니다.
5. Conclusion and Future Work
본 논문에서는 인간 자세 추정에서 흔히 발생하는 편향된 데이터 처리 과정을 정량적으로 분석했습니다. 그 결과, 표준 데이터 변환과 인코딩-디코딩에서 발생하는 체계적 오류가 결합되어 상향식(top-down) 파이프라인의 성능을 크게 저하시킨다는 사실을 발견했습니다. 이러한 분석을 바탕으로, 본 논문은 유닛 렝스(unit length) 기반 측정과 분류·회귀 결합 인코딩-디코딩 방식을 포함하는 원칙적인 비편향 데이터 처리(UDP) 전략을 제안합니다. 제안된 UDP는 모델에 구애받지 않는(model-agnostic) 전략으로, 다양한 상향식 자세 추정기에 적용 가능합니다. 실험 결과, UDP는 다양한 백본과 입력 크기를 사용하는 난이도 높은 COCO 데이터셋에서 기존 최고 성능을 큰 폭으로 향상시켰을 뿐 아니라, 결과 재현성과 향후 연구를 위한 중요성도 입증했습니다. 향후 연구에서는 제안된 UDP를 얼굴 랜드마크 추정, 앵커(anchor) 없는 물체 검출(anchor-free object detection), 3차원 인간 자세 추정 등에 적용할 예정입니다.
Junjie Huang, Zheng Zhu, Feng Guo, Guan Huang, Dalong Du The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation

댓글남기기