

개요
YOLOv3: An Incremental Improvement 의 얕은 리뷰 포스팅. YOLOv1, YOLOv2에 이은 3번째 버전까지 계속해서 읽고 있습니다.
아카이브에 업로드 되어있지만 좀 처럼 흔한 논문(?)의 말투는 아니다. 구글을 찾아봐도 GPT-4o에게 온라인 검색을 부탁해도 공식적으로 특정 학회나 저널에 발표되지 않았다고 한다. 또한, 저자가 언급했 듯 기술 보고서(technical report)가 맞는 것 같다.
Bounding Box Prediction
박스 위치에 대한 예측은 YOLOv2(YOLO9000)의 방식의 $t_x, t_y, t_w, t_h$ 예측을 그대로 가져온다. 여기서 이러한 예측된 $t$ 들을 $\hat{t}$ 로 놓고 4개 각각의 $\hat{t} - t$ 를 활용하는(*는 임의로 표기 생략하였음) Sum squared error를 통해 학습을 시킨다. 그리드 셀의 오프셋 및 해당 그리드 셀 안에서의 상대적 중심좌표, 앵커박스의 너비, 높이에 대한 스케일 팩터 $t_w, t_h$ 를 학습하는 방식으로 이어진다.
또한, 아래의 번역에서 객체성으로 표현된 objectness score를 로지스틱 회귀를 통해 각 바운딩 박스 프라이어에 점수를 매겨 최대 1의 값을 부여한다. 예측된 앵커 박스가 최선이 아닌경우(최선은 1개만 나올 수 있으니) 해당 바운딩 박스의 정보(좌표와 objectness score, 클래스 스코어 등)중 objectness score에 대한 손실만 계산하여 클래스나 좌표에 대한 loss는 반영하지 않는다.
바운딩 박스에 대한 학습에 차별성을 가지는 부분으로 볼 수 있다.
앵커박스 오프셋에 대한 예측, 로지스틱 대신 선형 회귀를 통한 예측, Focal loss의 사용 등 다양한 기법들을 시도했으나 이는 성능을 떨어뜨렸다고 한다.
Class Prediction
기본적으로 YOLOv2에선 카테고리 정보에 대해서 각 클래스가 상호배타적이라는 전제하에 Softmax를 통해 학습했으나 YOLOv3에선 로지스틱 분류를 사용한다. 즉,출력 가능한 클래스에 대해서 Multi-label 학습을 한다고 볼 수 있다. 하나의 객체는 다양한 라벨을 가질 수 있고 이렇게 멀티 레이블 분류 후 스코어가 높은 하나의 클래스를 부여하는 것이 더 성능을 높이는 방법으로 제시한다.
Predictions Across Scales
R-CNN에서 결합하여 사용한 FPN(Feature Pyramid Network)에서 착안점을 얻어 서로 다른 해상도 스케일의 특징들을 결합하여 박스를 예측하려는 시도를 하였다. 각 스케일로부터 바운딩 박스를 1개 씩 예측하여 총 3개의 바운딩 박스를 예측하기 때문에 출력 텐서의 계산식이 $N\times N\times [3\times(4+1+80)]$ 이 되었다. 여기서 4+1은 박스좌표 및 객체성 점수, 80은 COCO의 클래스 개수이다. $N$ 은 그리드 셀 개수의 분할이 될 것이다. 그리고 백본의 5개의 residual block 중 마지막 3개의 출력을 사용하여 FPN을 통한 다중 스케일 출력을 도출한다. $416\times 416$ 입력에 대해서 $52\times 52, 26\times 26, 13\times 13$ 3개의 shape으로 부터 각각 255($3\times(4+1+80)$)개의 출력이 나오도록 처리한다.
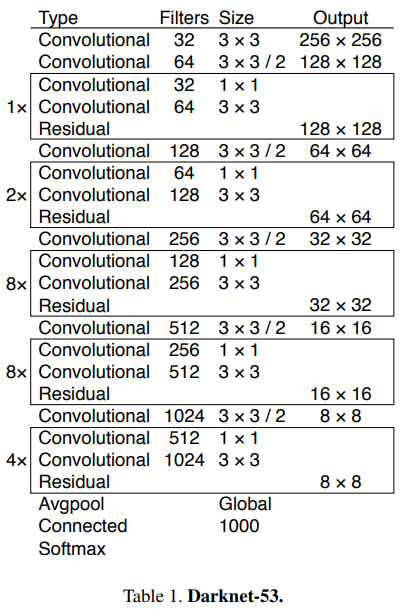
Darknet-53
그래서 YOLOv2 대비 결론적으로 내놓은 결과물이 새로운 Feature Extractor인 Darknet-53이다. 네이밍 규칙은 동일하게 53개의 convolution을 사용했기 때문에 그렇게 이름지어졌다. Resnet에서 사용한 residual block도 사용하여 shortcut connection을 구현하였다.
결론
전문의 번역은 하단에 배치해놓았다. 궁금하신분은 한번 쭉 읽어보면 좋을 것 같다.
해당 논문의 모델 성능 평가 부분 및 Rebuttal 파트를 보면 저자의 상당한 불만사항(?) 들이 나열되어 있다. 2018년은 AI의 폭발적 성장기였다고 생각한다. 그 과정 상에서 적절한 메트릭의 진화과정 및 이해의 합일 과정에서 겪는 진동이라고 볼 수 있을 것 같다.
mAP50에서는 최고 성능을 달성함을 강조하며 비교 대상이었던 RetinaNet과 FPS 및 초당 처리성능을 비교하여 YOLOv3가 뛰어남을 강조하고 있다. 충분히 납득되는 포인트이다. IOU를 올려가며 나오는 mAP50-95 나 mAP75에서 성능평가가 뒤로 밀리는 부분에 대해서 뭐라뭐라 하지만 2024년 지금와서 보니 YOLO가 걸어왔던 길이 틀리지 않았다고 생각한다(약한 놈은 다 사라졌으니까).
번역
Abstract
우리는 YOLO의 몇 가지 업데이트를 발표합니다! 우리는 여러 가지 작은 디자인 변경을 통해 성능을 향상시켰습니다. 우리는 또한 이 새로운 네트워크를 훈련시켰으며, 꽤 훌륭합니다. 지난번보다 약간 더 크지만 더 정확합니다. 여전히 빠르니 걱정하지 마세요. $320×320$ 해상도에서 YOLOv3는 22ms에 28.2 mAP를 기록하며, SSD와 동일한 정확도를 가지지만 세 배 더 빠릅니다. 기존의 0.5 IOU mAP 감지 지표를 보면 YOLOv3는 꽤 좋습니다. Titan X에서 51ms에 57.9 $AP_{50}$ 를 달성했으며, 이는 198ms에 57.5 $AP_{50}$ 를 기록한 RetinaNet과 비교하여 유사한 성능이지만 3.8배 더 빠릅니다. 항상 그렇듯이, 모든 코드는 https://pjreddie.com/yolo/에서 온라인으로 제공됩니다.
1. Introduction
가끔은 1년 동안 그냥 대충 넘길 때가 있잖아요? 올해는 연구를 많이 하지 않았습니다. 트위터에 많은 시간을 보냈고, GANs를 조금 다뤄봤습니다. 작년의 약간의 모멘텀이 남아 있어서 YOLO를 약간 개선할 수 있었습니다. 하지만 솔직히 말하면, 정말 흥미로운 것은 없었고, 단지 조금 나아지게 만든 작은 변경 사항들뿐이었습니다. 다른 사람들의 연구도 조금 도왔습니다.
사실, 그것이 오늘 우리를 여기로 이끌었습니다. 카메라 준비 마감일이 있어서 YOLO에 제가 무작위로 만든 업데이트를 인용해야 하지만 출처가 없습니다. 그래서 기술 보고서를 준비했어요!
기술 보고서의 좋은 점은 서론이 필요 없다는 것입니다. 우리는 왜 여기에 있는지 모두 알고 있습니다. 그래서 이 서론의 끝은 나머지 논문을 위한 방향을 제시할 것입니다. 먼저 YOLOv3의 딜이 무엇인지 말씀드리겠습니다. 그 다음에 우리가 어떻게 하는지 알려드리겠습니다. 또한 우리가 시도했지만 실패한 것들에 대해서도 말씀드리겠습니다. 마지막으로 이것이 무엇을 의미하는지 숙고해보겠습니다.
2. The Deal
YOLOv3에 대한 개요는 다음과 같습니다: 우리는 주로 다른 사람들의 좋은 아이디어를 받아들였습니다. 또한 다른 것들보다 더 나은 새로운 분류기 네트워크를 훈련시켰습니다. 우리는 처음부터 전체 시스템을 설명하여 여러분이 모두 이해할 수 있도록 할 것입니다.
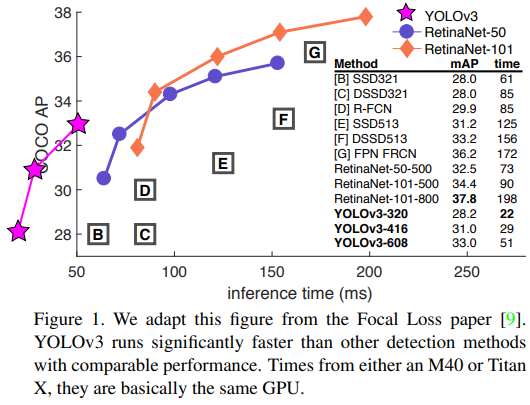
이 그림은 Focal Loss 논문에서 가져왔습니다. YOLOv3는 비교 가능한 성능을 가진 다른 감지 방법보다 훨씬 빠르게 실행됩니다. M40 또는 Titan X에서의 시간은 기본적으로 동일한 GPU입니다.
2.1. Bounding Box Prediction
YOLO9000을 따라 우리의 시스템은 차원 클러스터를 앵커 박스로 사용하여 바운딩 박스를 예측합니다. 네트워크는 각 바운딩 박스에 대해 $t_x, t_y, t_w, t_h$ 의 4가지 좌표를 예측합니다. 셀이 이미지의 왼쪽 상단 모서리에서 ($c_x,c_y$)만큼 오프셋되면 바운딩 박스 프라이어의 너비와 높이가 $p_w,p_h$ 일 때, 예측은 다음과 같습니다:
\[\begin{align} b_x &= \sigma(t_x)+c_x \\ b_y &= \sigma(t_y)+c_y \\ b_w &= p_we^{t_w} \\ b_h &= p_he^{t^h} \end{align}\]훈련 중에는 제곱 오차 합 손실을 사용합니다. 일부 좌표 예측에 대한 실제 값이 $\hat{t}_*$ 일 경우, 우리의 그래디언트는 실제 값(실제 바운딩 박스에서 계산된 값)에서 우리의 예측값을 뺀 값입니다: $\hat{t}_* - t_*$. 이 실제 값은 위의 방정식을 역으로 계산하여 쉽게 구할 수 있습니다.
YOLOv3는 로지스틱 회귀를 사용하여 각 바운딩 박스에 대해 객체성 점수를 예측합니다. 바운딩 박스 프라이어가 다른 모든 바운딩 박스 프라이어보다 실제 객체와 더 많이 겹치면 이 값은 1이 되어야 합니다. 바운딩 박스 프라이어가 최선이 아니지만 일정 임계값 이상으로 실제 객체와 겹치는 경우, 우리는 예측을 무시합니다. 우리는 0.5의 임계값을 사용합니다. [17]과 달리, 우리의 시스템은 각 실제 객체에 대해 하나의 바운딩 박스 프라이어만 할당합니다. 바운딩 박스 프라이어가 실제 객체에 할당되지 않은 경우, 좌표 또는 클래스 예측에 대한 손실은 발생하지 않고 객체성에만 손실이 발생합니다.
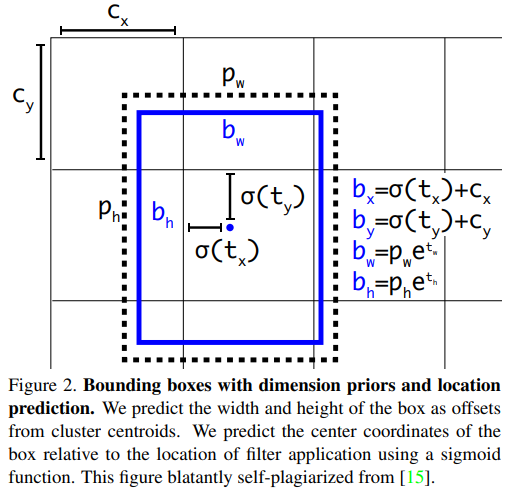
차원 우선값과 위치 예측을 사용한 바운딩 박스. 우리는 클러스터 중심에서 오프셋으로 상자의 너비와 높이를 예측합니다. 시그모이드 함수를 사용하여 필터 적용 위치에 대한 상자의 중심 좌표를 예측합니다. 이 그림은 [15]에서 명백하게 자가 표절한 것입니다.
2.2. Class Prediction
각 박스는 다중 레이블 분류를 사용하여 바운딩 박스가 포함할 수 있는 클래스를 예측합니다. 우리는 소프트맥스를 사용하지 않으며, 이는 좋은 성능을 위해 불필요하다는 것을 발견했기 때문입니다. 대신 독립적인 로지스틱 분류기를 사용합니다. 훈련 중에는 클래스 예측에 대해 이진 교차 엔트로피(binary cross-entropy) 손실을 사용합니다.
이 공식은 Open Images Dataset과 같은 더 복잡한 도메인으로 이동할 때 도움이 됩니다. 이 데이터셋에는 많은 겹치는 레이블이 있습니다 (예: Woman과 Person). 소프트맥스를 사용하면 각 박스에 정확히 하나의 클래스가 있다는 가정을 하게 되지만, 이는 종종 사실이 아닙니다. 다중 레이블 접근 방식이 데이터를 더 잘 모델링합니다.
2.3. Predictions Across Scales
YOLOv3는 3가지 다른 스케일에서 박스를 예측합니다. 우리 시스템은 피라미드 네트워크 개념을 사용하여 이러한 스케일에서 특징을 추출합니다. 기본 특징 추출기에서 여러 개의 합성곱 계층을 추가합니다. 마지막 계층은 바운딩 박스, 객체성 및 클래스 예측을 인코딩하는 3차원 텐서를 예측합니다. COCO와의 실험에서 우리는 각 스케일로부터 총 3개의 박스를 예측하여 텐서는 $N\times N\times [3\times (4+1+80)]$ 이 됩니다. 여기서 4는 바운딩 박스 오프셋, 1은 객체성 예측, 80은 클래스 예측입니다.
다음으로 이전 두 계층에서 피처 맵을 가져와서 2× 업샘플링합니다. 또한 네트워크 초기의 피처 맵을 가져와서 업샘플된 피처와 병합합니다. 이 방법은 업샘플된 피처로부터 더 의미 있는 의미론적 정보를 얻고 초기 피처 맵으로부터 더 세밀한 정보를 얻을 수 있게 합니다. 그런 다음 이 결합된 피처 맵을 처리하기 위해 몇 가지 합성곱 계층을 추가하고, 결국 유사한 텐서를 예측하지만 이제 두 배의 크기로 예측합니다.
우리는 최종 스케일에 대해 박스를 예측하기 위해 동일한 디자인을 한 번 더 수행합니다. 따라서 3번째 스케일에 대한 우리의 예측은 초기 네트워크의 세밀한 특징뿐만 아니라 이전의 모든 계산으로부터 이점을 얻습니다.
우리는 여전히 k-평균 클러스터링을 사용하여 바운딩 박스 우선값을 결정합니다. 우리는 단순히 9개의 클러스터와 3개의 스케일을 임의로 선택한 다음 클러스터를 스케일에 고르게 나누었습니다. COCO 데이터셋에서 9개의 클러스터는 다음과 같았습니다: $(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)$.
2.4. Feature Extractor
우리는 새로운 네트워크를 사용하여 특징 추출을 수행합니다. 우리의 새로운 네트워크는 YOLOv2에서 사용된 네트워크, Darknet-19, 그리고 그 새로운 잔차 네트워크의 혼합 접근 방식입니다. 우리의 네트워크는 연속적인 $3×3$ 및 $1×1$ 합성곱 계층을 사용하지만 이제 몇 가지 shortcut 연결도 있으며, 크기도 상당히 큽니다. 53개의 합성곱 계층이 있어서 우리는 이것을…. 기다려 보세요….. Darknet-53이라고 부릅니다!
이 새로운 네트워크는 Darknet-19보다 훨씬 강력하고 여전히 ResNet-101 또는 ResNet-152보다 효율적입니다. 여기 몇 가지 ImageNet 결과가 있습니다:
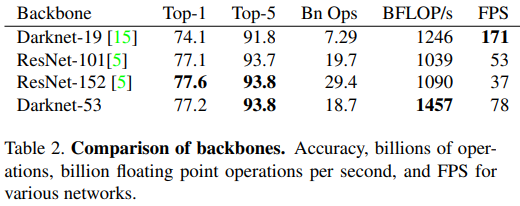
각 네트워크는 동일한 설정으로 훈련되고 $256×256$ 에서 단일 크롭 정확도로 테스트되었습니다. 실행 시간은 $256×256$ 에서 Titan X에서 측정되었습니다. 따라서 Darknet-53은 최첨단 분류기와 동등한 성능을 보이지만, 부동 소수점 연산이 적고 속도가 더 빠릅니다. Darknet-53은 ResNet-101보다 뛰어나고 1.5배 빠릅니다. Darknet-53은 ResNet-152와 유사한 성능을 보이며 2배 빠릅니다.
Darknet-53은 또한 초당 최고 측정 부동 소수점 연산을 달성합니다. 이는 네트워크 구조가 GPU를 더 잘 활용하여 평가가 더 효율적이고 더 빠르다는 것을 의미합니다. 주로 ResNet이 계층이 너무 많고 효율적이지 않기 때문입니다.
2.5. Training
우리는 여전히 하드 네거티브 마이닝이나 그런 것을 사용하지 않고 전체 이미지를 훈련시킵니다. 우리는 멀티 스케일 훈련, 많은 데이터 증강, 배치 정규화 등 모든 표준적인 방법을 사용합니다. 우리는 Darknet 신경망 프레임워크를 사용하여 훈련 및 테스트를 진행합니다.
3. How We Do
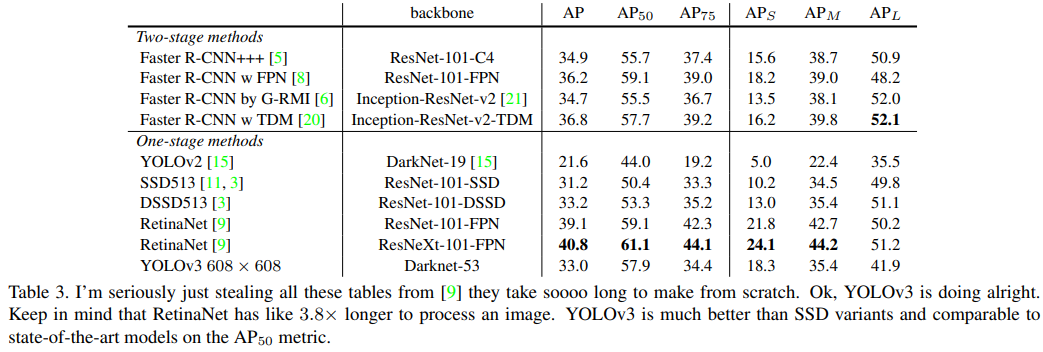
나는 정말로 이 모든 표를 [9]에서 가져왔습니다. 처음부터 만들려면 너무 오래 걸립니다. 좋아요, YOLOv3는 잘하고 있습니다. RetinaNet이 이미지를 처리하는 데 약 3.8배 더 오래 걸린다는 점을 염두에 두세요. YOLOv3는 SSD 변형보다 훨씬 더 좋으며, $AP_{50}$ 메트릭에서 최첨단 모델과 비교할 만합니다.
YOLOv3는 꽤 좋습니다! 표 3을 보세요. COCO의 이상한 평균 mAP 측면에서 YOLOv3는 SSD 변형과 동등하지만, 속도는 $3×$ 더 빠릅니다. 그러나 이 메트릭에서는 여전히 RetinaNet과 같은 다른 모델보다 뒤처집니다.
그러나 IOU=.5에서의 “구형” 감지 메트릭인 mAP (또는 차트의 $AP_{50}$)을 보면 YOLOv3는 매우 강력합니다. 이는 RetinaNet과 거의 동등하고 SSD 변형보다 훨씬 높습니다. 이는 YOLOv3가 객체에 대해 적절한 박스를 생성하는 데 뛰어난 매우 강력한 감지기임을 나타냅니다. 그러나 IOU 임계값이 증가함에 따라 성능이 크게 저하되어 YOLOv3가 객체와 박스를 완벽하게 맞추는 데 어려움을 겪고 있음을 나타냅니다.
과거에 YOLO는 작은 객체에서 어려움을 겪었습니다. 그러나 이제 그 추세가 반전된 것을 볼 수 있습니다. 새로운 멀티 스케일 예측으로 YOLOv3는 비교적 높은 $AP_S$ 성능을 보입니다. 그러나 중간 크기와 큰 크기의 객체에서는 상대적으로 성능이 떨어집니다. 이를 근본적으로 해결하기 위해서는 더 많은 조사가 필요합니다.
$AP_{50}$ 메트릭에서 정확도와 속도를 비교할 때 (그림 5를 참조) YOLOv3가 다른 감지 시스템보다 상당한 이점을 가지고 있음을 알 수 있습니다. 즉, 더 빠르고 더 좋습니다.
4. Things We Tried That Didn’t Work
YOLOv3를 작업하는 동안 많은 것들을 시도했습니다. 그 중 많은 것이 실패했습니다. 기억나는 것들을 여기에 적어보았습니다.
Anchor box $x,y$ offset predictions.
우리는 $x,y$ 오프셋을 박스 너비나 높이의 배수로 예측하는 일반적인 앵커 박스 예측 메커니즘을 사용해 보았습니다. 우리는 이 공식을 사용하면 모델 안정성이 감소하고 잘 작동하지 않는다는 것을 발견했습니다.
Linear $x,y$ predictions instead of logistic.
우리는 로지스틱 활성화 대신 선형 활성화를 사용하여 $x,y$ 오프셋을 직접 예측하는 것을 시도했습니다. 이는 mAP에서 몇 포인트 감소로 이어졌습니다.
Focal loss.
우리는 포컬 로스를 사용해 보았습니다. 이는 우리의 mAP를 약 2 포인트 떨어뜨렸습니다. YOLOv3는 이미 포컬 로스가 해결하려는 문제에 대해 강력할 수 있습니다. 왜냐하면 객체성 예측과 조건부 클래스 예측이 분리되어 있기 때문입니다. 따라서 대부분의 예에서 클래스 예측으로 인한 손실이 없습니다? 또는 뭔가? 우리는 완전히 확신하지 않습니다.
Dual IOU thresholds and truth assignment.
Faster R-CNN은 훈련 중에 두 개의 IOU 임계값을 사용합니다. 예측이 .7만큼 진실값과 겹치면 긍정적인 예제로, $[.3−.7]$ 에서는 무시되고, 모든 진실값 객체에 대해 .3 미만이면 부정적인 예제로 간주됩니다. 우리는 유사한 전략을 시도했지만 좋은 결과를 얻을 수 없었습니다.
우리는 현재의 공식을 매우 좋아하며, 적어도 국지적인 최적화에 있는 것 같습니다. 이러한 기술 중 일부는 결국 좋은 결과를 낼 수 있을 가능성이 있으며, 아마도 훈련을 안정시키기 위해 약간의 조정이 필요할 것입니다.
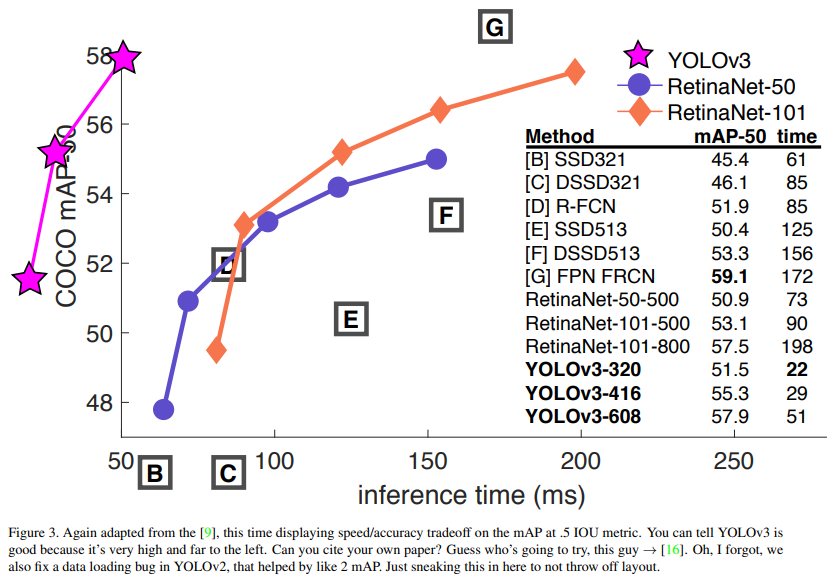
다시 [9]에서 가져온 그림으로, 이번에는 .5 IOU 메트릭에서 mAP에 대한 속도/정확도 트레이드오프를 보여줍니다. YOLOv3가 좋다는 것을 알 수 있습니다. 왜냐하면 매우 높고 왼쪽에 위치해 있기 때문입니다. 자신의 논문을 인용할 수 있나요? 누가 시도할 것 같나요? 바로 이 사람 → [16]. 아, 잊었네요. 우리는 YOLOv2의 데이터 로딩 버그도 수정했는데, 이는 mAP를 약 2만큼 증가시켰습니다. 레이아웃을 망치지 않기 위해 여기에 슬쩍 넣습니다.
5. What This All Means
YOLOv3는 좋은 감지기입니다. 빠르고 정확합니다. COCO 평균 AP에서 .5와 .95 IOU 메트릭 사이에서는 그렇게 훌륭하지 않습니다. 하지만 .5 IOU의 옛 감지 메트릭에서는 매우 좋습니다.
어쨌든 우리는 왜 메트릭을 바꾸었을까요? 원래 COCO 논문에는 다음과 같은 수수께끼 같은 문장이 있습니다: “평가 서버가 완료되면 평가 메트릭에 대한 전체 논의가 추가될 것입니다”. Russakovsky 등은 사람들이 .3과 .5의 IOU를 구별하는 데 어려움을 겪는다고 보고합니다! “사람들이 IOU가 0.3인 바운딩 박스를 시각적으로 검사하고 IOU가 0.5인 바운딩 박스와 구별하는 것은 놀라울 정도로 어렵습니다.” 사람이 차이를 구별하는 데 어려움을 겪는다면, 그것이 얼마나 중요할까요?
하지만 아마도 더 나은 질문은: “이 감지기를 이제 가지고 무엇을 할 것인가?” 일 것입니다. 이 연구를 수행하는 많은 사람들이 Google과 Facebook에 있습니다. 적어도 기술이 좋은 손에 있고 절대 여러분의 개인 정보를 수집하여 판매하는 데 사용되지 않을 것이라고 생각합니다…. 잠깐, 그게 바로 사용될 용도라고요?? 아.
그런데 시각 연구에 막대한 자금을 지원하는 다른 사람들은 군대이며, 그들은 새로운 기술로 많은 사람들을 죽이는 끔찍한 일을 한 적이 없습니다… 아, 기다려…
저는 컴퓨터 비전을 사용하는 대부분의 사람들이 국립 공원에서 얼룩말의 수를 세거나, 집 주변을 돌아다니는 고양이를 추적하는 것처럼 행복하고 좋은 일을 하고 있기를 바랍니다. 그러나 컴퓨터 비전은 이미 의심스러운 용도로 사용되고 있으며, 연구자로서 우리는 적어도 우리의 연구가 미칠 수 있는 해악을 고려하고 이를 완화할 방법을 생각할 책임이 있습니다. 우리는 세상에 그만큼 빚지고 있습니다.
끝으로, 저에게 @ 보내지 마세요. (드디어 트위터를 그만두었기 때문입니다).
Rebuttal
Reddit 댓글 작성자들, 실험실 동료들, 이메일을 보내준 사람들, 그리고 복도에서 지나가며 외쳐준 사람들에게 그들의 사랑스럽고 진심 어린 말에 대해 감사하고 싶습니다. 만약 당신이 나처럼 ICCV 리뷰를 하고 있다면 아마도 읽어야 할 다른 37개의 논문이 있을 것이며, 이를 마지막 주까지 미루게 될 것이고, 그 분야의 전설이 당신에게 리뷰를 끝내야 한다고 이메일을 보낼 것입니다. 하지만 그들이 무슨 말을 하는지 완전히 이해할 수 없고 아마도 그들은 미래에서 온 것일 수도 있습니다? 어쨌든, 이 논문은 과거에 당신의 과거 자신이 한 모든 작업이 없었다면 지금과 같은 모습이 되지 않았을 것입니다. 그리고 당신이 그것에 대해 트윗했다면 나는 몰랐을 것입니다. 그냥 말하는 겁니다.
리뷰어 #2 일명 Dan Grossman (lol 블라인딩 하는 사람이 누가 있나요) 는 우리의 그래프에 하나가 아닌 두 개의 0이 아닌 원점이 있다는 점을 여기서 지적하라고 주장합니다. 당신 말이 맞습니다 Dan, 그것은 우리가 단지 2-3% mAP를 놓고 싸우고 있다는 것을 인정하는 것보다 훨씬 더 좋아 보이기 때문입니다. 하지만 여기 요청된 그래프가 있습니다. FPS로도 하나 추가했는데, FPS로 플롯하면 우리가 정말 좋아 보이기 때문입니다.
리뷰어 #4 일명 Reddit의 JudasAdventus는 “재미있는 읽을거리였지만 MSCOCO 메트릭스에 대한 반론은 좀 약한 것 같다”고 썼습니다. 음, 나는 항상 당신이 나를 배신할 사람이라는 것을 알고 있었습니다 Judas. 프로젝트를 진행할 때 그 결과가 그저 괜찮게 나올 때 실제로 한 일이 꽤 멋졌다는 것을 정당화할 방법을 찾아야 하는 것처럼 말이죠? 기본적으로 나는 그것을 시도하고 있었고 COCO 메트릭에 대해 약간 비판적인 태도를 취했습니다. 하지만 이제 이 언덕을 차지했으니 이 언덕에서 죽을 수도 있습니다.
보세요, 문제는 mAP가 이미 좀 망가져 있어서 이를 업데이트하면 몇 가지 문제를 해결하거나 적어도 업데이트된 버전이 더 나은 이유를 정당화해야 합니다. 그리고 내가 큰 문제로 삼은 것은 정당화의 부족이었습니다. PASCAL VOC의 경우, IOU 임계값은 “실제 데이터의 바운딩 박스의 부정확성을 고려하여 의도적으로 낮게 설정되었습니다.” COCO가 VOC보다 더 나은 라벨링을 가지고 있나요? COCO는 세그멘테이션 마스크를 가지고 있어서 라벨이 더 신뢰할 만하고, 따라서 부정확성에 대해 덜 걱정할 수 있을 것입니다. 그러나 다시 말하지만, 내 문제는 정당화의 부족이었습니다.
COCO 메트릭은 더 나은 바운딩 박스를 강조하지만, 그 강조는 다른 것을 강조하지 않는다는 것을 의미합니다. 이 경우 분류 정확도입니다. 더 정밀한 바운딩 박스가 더 나은 분류보다 더 중요하다고 생각할 만한 좋은 이유가 있나요? 잘못 분류된 예는 약간 이동된 바운딩 박스보다 훨씬 더 명확합니다.
mAP는 이미 망가졌습니다. 중요한 것은 클래스별 순위만이 중요하기 때문입니다. 예를 들어, 테스트 세트에 이 두 이미지만 있다면, mAP에 따르면 이러한 결과를 생성하는 두 감지기는 동일하게 좋은 것입니다:
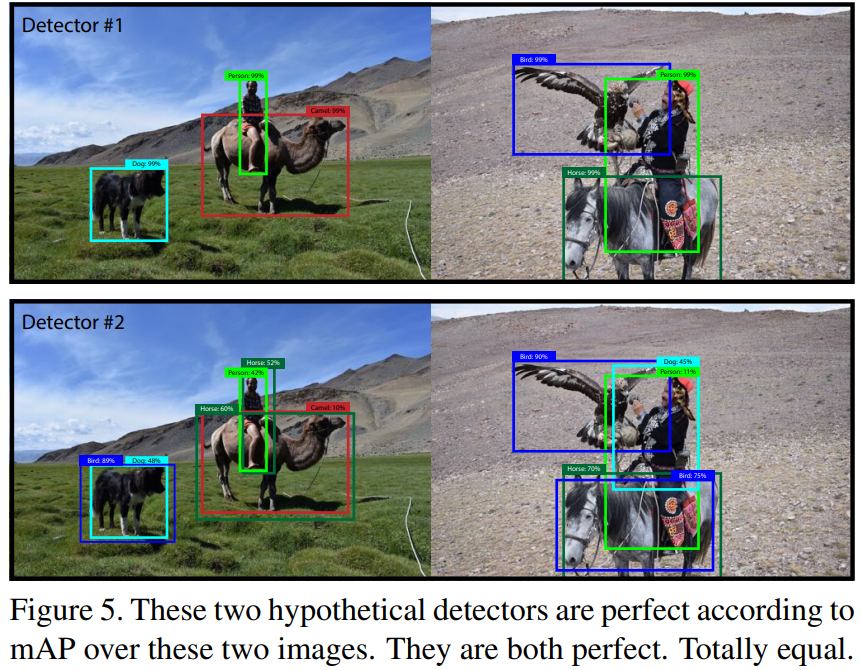
이 두 가상의 감지기는 이 두 이미지에 대한 mAP에 따르면 완벽합니다. 둘 다 완벽합니다. 완전히 동일합니다.
이것은 분명히 mAP 문제에 대한 과장된 표현이지만, 내가 새롭게 수정한 요점은 “실제 세계”에서 사람들이 신경 쓰는 것과 현재 메트릭 간에 명백한 차이가 있다는 것입니다. 따라서 새로운 메트릭을 만들려면 이러한 차이에 집중해야 한다고 생각합니다. 그리고 이미 mean average precision인데, COCO 메트릭을 뭐라고 부르죠? mean average precision?
여기 제안이 있습니다. 사람들이 실제로 신경 쓰는 것은 이미지와 감지기가 주어졌을 때, 감지기가 이미지에서 객체를 얼마나 잘 찾고 분류할 수 있는가입니다. 클래스별 AP를 제거하고 전역 평균 정확도를 사용하는 것은 어떨까요? 아니면 이미지별로 AP를 계산하고 이를 평균내는 방법은 어떨까요?
어쨌든 박스는 멍청합니다. 나는 아마도 마스크를 진정으로 믿는 사람일 것입니다. 단, YOLO가 이를 학습하게 할 수는 없습니다.
Joseph Redmon, Ali Farhadi YOLOv3: An Incremental Improvement

댓글남기기