

개요
A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS 이라는 논문을 가져왔다. YOLOv5, YOLOv8은 오피셜 논문이 없어서 제 3자가 서베이 논문에서 분석 및 정리해놓은 구조 및 특징을 보면 이해하기 쉽다. 그래서 그에 해당하는 서베이 논문에서 YOLOv5, YOLOv8에 해당 하는 부분을 번역하며 이해해보고자 한다.
아래에 상세히 적힌 YOLOv5는 2020년 출시 당시 앵커 박스에 의존하는 형태로 제공되었었으나 지금은 현재 YOLOv5u 라고 해서 YOLOv8에 적용된 앵커 프리 segmentation 헤드를 적용한 객체 감지 모델 형태로 제공된다. 모델의 헤드가 변경되었으므로 후처리도 변경되었지 않을까 생각하는데 이는 개인적으로 실제 코드를 뜯어봐서 확인할 예정이다.
확실히 YOLOv5 부터 기존 Darknet 프레임워크를 버리고 Pytorch를 사용했는데 감지 성능까지 좋다보니 Tensorflow 프레임워크에서 에셋처럼 제공하던 SSD, EfficientDet 모델보다 더 경쟁력을 갖추지 않았나 하는 생각이 든다.
YOLOv5
YOLOv5 [80] 는 Ultralytics의 설립자이자 CEO인 Glen Jocher가 YOLOv4 이후 몇 달 후인 2020년에 출시했습니다. YOLOv4 섹션에 설명된 많은 개선 사항을 사용하지만 Darknet 대신 Pytorch에서 개발되었습니다. YOLOv5는 AutoAnchor라는 Ultralytics의 알고리즘을 통합합니다. 이 사전 학습 도구는 앵커 상자가 데이터 세트 및 이미지 크기와 같은 학습 설정에 적합하지 않은 경우 앵커 상자를 확인하고 조정합니다. 먼저 데이터 세트 레이블에 k-평균 함수를 적용하여 유전적 진화(GE=Genetic Evolution) 알고리즘의 초기 조건을 생성합니다. 그런 다음 GE 알고리즘은 기본적으로 CIoU 손실을 사용하여 이러한 앵커를 1000세대에 걸쳐 진화시킵니다. 그림 13은 YOLOv5의 상세 아키텍처를 보여줍니다.
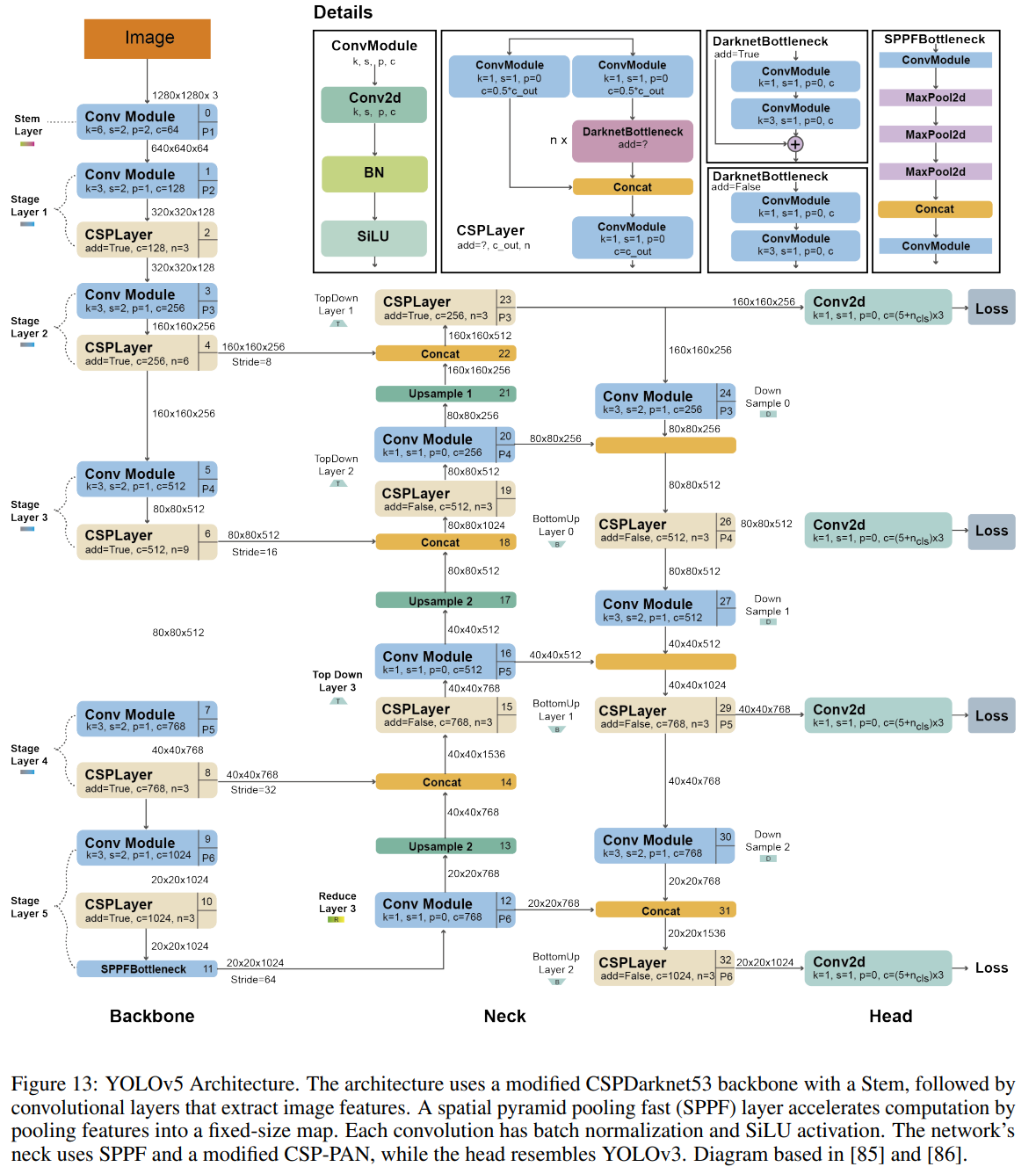
YOLOv5 Architecture
백본(backbone)은 CSPDarknet53의 수정된 버전으로, 큰 윈도우 크기를 가진 스트라이드된 컨볼루션 층(Stem)으로 시작하여 메모리와 계산 비용을 줄입니다. 그 후 입력 이미지에서 관련 특징을 추출하는 컨볼루션 층들이 뒤따릅니다. SPPF(spatial Pyramid Pooling Fast) 층과 그 다음의 컨볼루션 층들은 다양한 스케일에서 특징을 처리하며, 업샘플 층은 특징 맵의 해상도를 증가시킵니다. SPPF 층은 다양한 스케일의 특징을 고정 크기의 특징 맵으로 풀링하여 네트워크 계산 속도를 높이는 것을 목표로 합니다. 각 컨볼루션은 배치 정규화(BN)와 SiLU 활성화 [81]가 뒤따릅니다. 넥(neck)은 SPPF와 수정된 CSP-PAN을 사용하며, 헤드(head)는 YOLOv3와 유사합니다.
YOLOv5는 Mosaic, 복사 붙여넣기 [82], 랜덤 어파인 변환, MixUp [83], HSV 증강, 랜덤 수평 반전, 그리고 albumentations 패키지 [84]에서 제공하는 기타 증강 기법들을 사용합니다. 또한 그리드 감도를 개선하여 그라디언트 폭주에 더 안정적으로 만듭니다.
YOLOv5는 다섯 가지 스케일 버전을 제공합니다: YOLOv5n (nano), YOLOv5s (small), YOLOv5m (medium), YOLOv5l (large), 그리고 YOLOv5x (extra large). 이들은 각각의 어플리케이션과 하드웨어 요구사항에 맞게 컨볼루션 모듈의 폭과 깊이가 다릅니다. 예를 들어, YOLOv5n과 YOLOv5s는 저자원 기기를 목표로 한 경량 모델이며, YOLOv5x는 고성능을 위해 최적화되어 있지만, 속도 측면에서는 희생이 따릅니다.
이 문서 작성 시점에 출시된 YOLOv5 버전은 v7.0이며, 분류 및 인스턴스 분할 기능이 포함된 YOLOv5 버전도 포함됩니다.
YOLOv5는 오픈 소스이며 Ultralytics에 의해 활발히 유지 관리되고 있으며, 250명 이상의 기여자가 참여하고 있으며 자주 새로운 개선이 이루어집니다. YOLOv5는 사용하기 쉽고, 훈련 및 배포가 용이합니다. Ultralytics는 iOS와 Android용 모바일 버전을 제공하며, 라벨링, 훈련 및 배포를 위한 다양한 통합 기능을 제공합니다.
MS COCO 데이터 세트 test-dev 2017에서 평가한 YOLOv5x는 640픽셀의 이미지 크기로 50.7%의 AP를 달성했습니다. 32의 배치 크기를 사용하면 NVIDIA V100에서 200FPS의 속도를 달성할 수 있습니다. 1536픽셀의 더 큰 입력 크기와 TTA(test-time augmentation)를 사용하면 YOLOv5는 55.8%의 AP를 달성합니다.
YOLOv8
YOLOv8 [113]는 YOLOv5를 개발한 회사인 Ultralytics에서 2023년 1월에 출시했습니다. YOLOv8은 다섯 가지 크기 버전으로 제공됩니다: YOLOv8n (nano), YOLOv8s (small), YOLOv8m (medium), YOLOv8l (large) 및 YOLOv8x (extra large). YOLOv8은 객체 감지, 분할, 자세 추정, 추적 및 분류와 같은 다양한 비전 작업을 지원합니다.
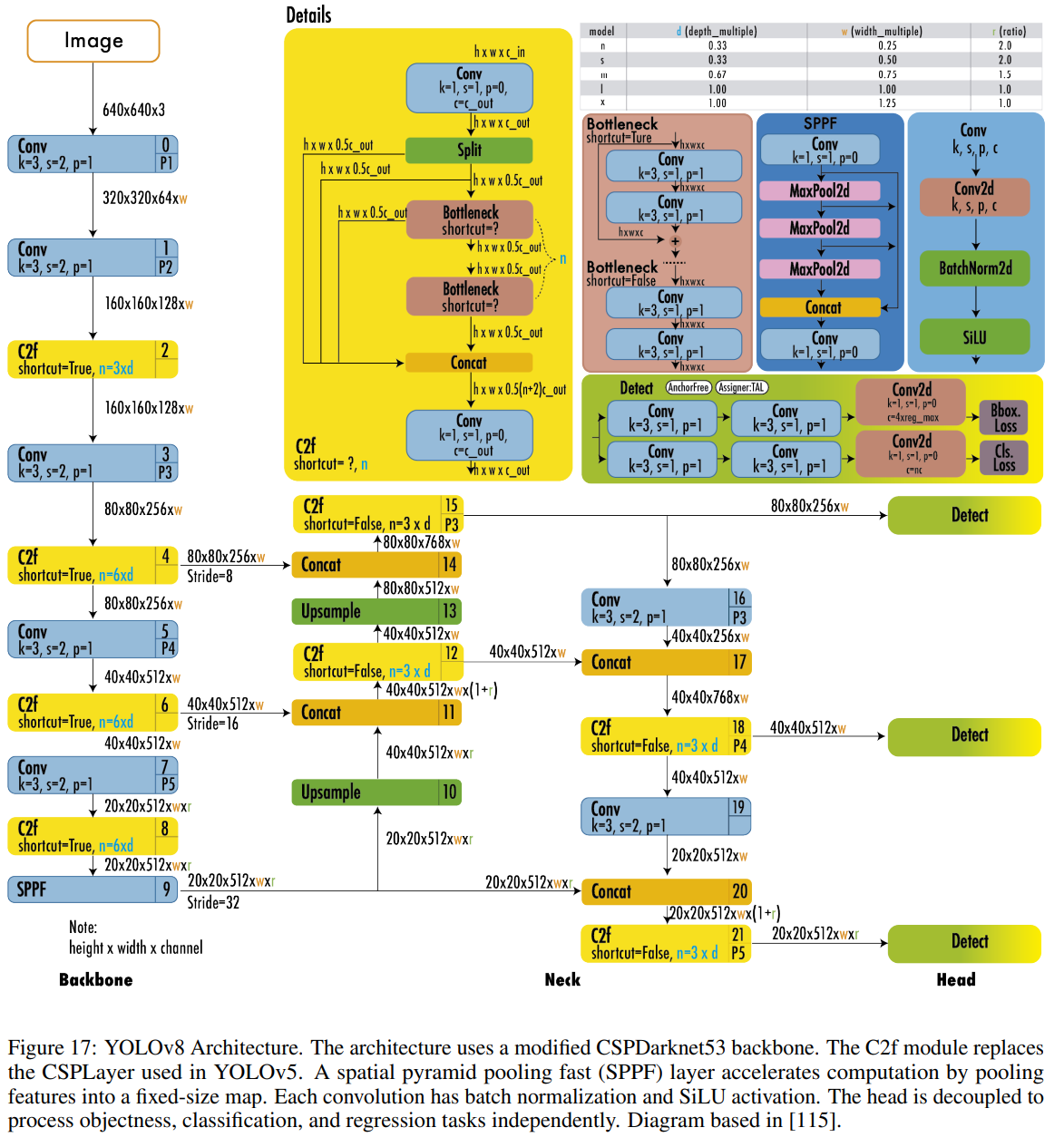
YOLOv8 Architecture
그림 17은 YOLOv8의 상세 아키텍처를 보여줍니다. YOLOv8은 YOLOv5와 유사한 백본을 사용하며, CSPLayer에 몇 가지 변경 사항이 적용되어 이제 C2f 모듈로 불립니다. C2f 모듈(두 개의 컨볼루션이 있는 크로스 스테이지 부분 병목)은 고수준 특징을 문맥 정보와 결합하여 탐지 정확도를 향상시킵니다.
YOLOv8은 앵커 프리 모델을 사용하며, 객체성, 분류, 회귀 작업을 독립적으로 처리하기 위해 분리된 헤드를 갖추고 있습니다. 이 디자인은 각 브랜치(branch)가 자신의 작업에 집중할 수 있도록 하며 모델의 전반적인 정확도를 향상시킵니다. YOLOv8의 출력 층에서는 객체성 점수를 위한 활성화 함수로 시그모이드 함수를 사용하여 바운딩 박스가 객체를 포함할 확률을 나타냅니다. 클래스 확률을 위해 소프트맥스 함수를 사용하여 객체가 가능한 각 클래스에 속할 확률을 나타냅니다.
YOLOv8은 CIoU [76]와 DFL [114] 손실 함수를 사용하여 바운딩 박스 손실과 분류 손실을 위한 이진 교차 엔트로피를 계산합니다. 이러한 손실 함수들은 특히 작은 객체를 처리할 때 객체 탐지 성능을 향상시켰습니다.
YOLOv8은 또한 YOLOv8-Seg 모델이라고 불리는 의미 분할 모델을 제공합니다. 백본은 CSPDarknet53 특징 추출기이며, 전통적인 YOLO 넥 아키텍처 대신 C2f 모듈이 뒤따릅니다. C2f 모듈 뒤에는 두 개의 분할 헤드가 있으며, 이는 입력 이미지에 대한 의미 분할 마스크를 예측하는 방법을 학습합니다. 이 모델은 YOLOv8과 유사한 탐지 헤드를 가지고 있으며, 다섯 개의 탐지 모듈과 예측 층으로 구성됩니다. YOLOv8-Seg 모델은 다양한 객체 탐지 및 의미 분할 벤치마크에서 최첨단 결과를 달성하면서도 높은 속도와 효율성을 유지합니다.
YOLOv8은 명령줄 인터페이스(CLI)에서 실행할 수 있으며, PIP 패키지로도 설치할 수 있습니다. 또한, 라벨링, 훈련 및 배포를 위한 다양한 통합 기능이 함께 제공됩니다.
MS COCO 데이터셋 test-dev 2017에서 평가된 결과, YOLOv8x는 640픽셀 이미지 크기로 53.9%의 AP를 달성했으며(동일한 입력 크기에서 YOLOv5의 50.7%와 비교), NVIDIA A100과 TensorRT에서 280 FPS의 속도를 기록했습니다.
Juan Terven, Diana Cordova-Esparza A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS

댓글남기기