
데이터셋 준비
데이터 셋에 대한 준비는 기존 TF2 Models Object Detection API 학습하기 게시글을 참고한다. 게시글 링크: link
여기서 학습을 위한 사전 준비는 다음과 같다.
- TF record 준비
- Label_map 준비
- 학습하려는 Model zoo 다운로드
- pipeline.config 셋팅
TF record 준비와 Label_map.txt 를 준비하는 과정은 TF2의 그것과 전혀 다를바가 없다. 단 본인은 tensorflow 디렉토리에서 TF2를 학습 시키기 위한 models 디렉토리와 TF1을 학습 시키기 위한 r1.13.0 브랜치의 models 디렉토리를 다음과 같이 구분한다.
models 디렉토리는 TF2와 TF1(tf 1.15.x에 한해서)을 모두 학습할 수 있지만 TF2를 위한 리포지토리(Master branch)로 간주한다. models_r1.13은 TF1을 위한 리포지토리(r1.13.0)로 간주한다.
tensorflow
├─ models/
├─ models_r1.13/
│ ├─ community/
│ ├─ official/
│ ├─ orbit/
│ ├─ research/
│ └─ ...
├─ data/
├─ model_zoo/
│ ├─ tf1/
│ └─ tf2/
└─ train/
├─ tf1/
└─ tf2/
Model zoo에서 학습하려는 페이지는 model zoo 마스터 브랜치를 들어가던, r1.13.0 브랜치를 들어가던 상관 없다. 해당 링크를 들어가면 마스터 브랜치의 TF1 버전의 model zoo 링크로 이동한다.
들어가보면 coco 데이터셋으로 학습한 pre-trained 모델, 모바일 용 모델, pixel Edge TPU 모델, Kitti 데이터 셋으로 학습한 pre-trained 모델 등 여러가지 모델들을 받을 수 있다. 본인은 일반적으로 coco 데이터셋으로 학습 한 모델을 transfer learning으로 fine-tuning 하여 모델들을 학습한다.
pipeline.config 파일의 수정도 TF2 버전과 동일해서 링크를 보고 수행한다면 문제 없이 수정하여 학습을 준비 할 수 있다.
models 리포지토리 수정
why
models 리포지토리를 왜 수정해야하는가를 살펴보면 우리가 학습에 사용하려는 code의 --help 옵션을 확인해보면 알 수 있다. {models_path}/research/object_detection 으로 이동해서 일단 --help옵션으로 아래의 해당 코드를 실행해본다.
# in models/research/object_detection
$ python model_main.py --help
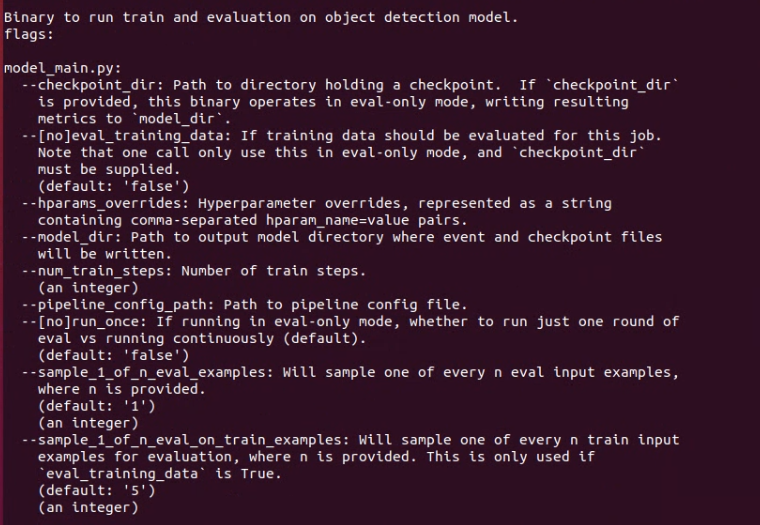
이미지를 보면 알 수 있지만 TF2랑은 다르게 --checkpoint_every_n 옵션이 존재하지 않는다. 우리가 학습을 25000 steps을 할수도, 100000 steps을 할수도 있기에 그래도 우리가 원하는 체크포인트 생성 빈도는 조절을 할 수 있어야한다. 신경을 쓰지않는다면 기본으로 설정된 값으로 체크포인트 생성 갯수와 체크포인트 생성 빈도를 가진채로 학습이 진행된다. 이를 통제하기 위해선 model_main.py 안에 있는 코드를 수정해준다.
where
해당 코드 내부를 보면 tf.estimator.RunConfig() 클래스의 인스턴스를 선언하는 부분이 있다. 학습에 필요한 Config를 선언하는 부분이다. 기존 내용은 다음과 같은 내용밖에 선언되어 있지 않다.
config = tf.estimator.RunConfig(model_dir=FLAGS.model_dir
해당 클래스 생성자의 원형을 찾아본다. 대략적으로 코드는 {환경}/lib/{파이썬}/site-package/tensorflow_estimator/python/estimator/run_config.py 에 있다. 해당 클래스 내에서 클래스의 생성자 부분을 보면 다음과 같다.
@estimator_export('estimator.RunConfig')
class RunConfig(object):
"""This class specifies the configurations for an `Estimator` run."""
def __init__(self,
model_dir=None,
tf_random_seed=None,
save_summary_steps=100,
save_checkpoints_steps=_USE_DEFAULT,
save_checkpoints_secs=_USE_DEFAULT,
session_config=None,
keep_checkpoint_max=5,
keep_checkpoint_every_n_hours=10000,
log_step_count_steps=100,
train_distribute=None,
device_fn=None,
protocol=None,
eval_distribute=None,
experimental_distribute=None,
experimental_max_worker_delay_secs=None,
session_creation_timeout_secs=7200):
각 파라미터에 대한 설명은 코드를 직접 참고한다.
해당 생성자의 파라미터 중 우리가 체크포인트 생성에 대해 통제를 위한 파라미터들이 있다. 바로 --save_checkpoints_steps, --keep_checkpoint_max이다. 각 옵션은 체크포인트 1개가 생성되기 위한 필요 스텝 수와 체크포인트를 최대 몇 개까지 저장할 것인가에 대한 값을 가진다.
how
그렇다고 우리가 이런 복잡한 경로에서 클래스의 생성자를 직접 수정하긴 좀 문제가 있다. 해당 코드는 pip install tensorflow로 받는 코드기에 이 코드를 직접 수정하는 것은 좋은 방식이 아니다. 그래서 아까 model_main.py에서 이 클래스 인스턴스가 선언된 부분에서 파라미터를 넣어서 바꿔줄 수 있다. 그리고 하드코딩 된 값으로 넣어줄 수도 있지만 이를 tensorflow의 FLAGS로 감싸줘서 마치 일반적인 파이썬의 Argument Parser 처럼 실행 시 입력 파라미터를 받는 방식으로 해당 값을 처리할 수 있다. model_main.py를 다음과 같이 수정한다.
...
...
flags.DEFINE_boolean(
'run_once', False, 'If running in eval-only mode, whether to run just '
'one round of eval vs running continuously (default).'
)
# 추가
flags.DEFINE_integer('checkpoint_every_n', 1000, 'Integer defining how often we checkpoint.')
FLAGS = flags.FLAGS
def main(unused_argv):
...
...
config = tf.estimator.RunConfig(model_dir=FLAGS.model_dir,
save_checkpoints_steps=FLAGS.checkpoint_every_n,
keep_checkpoint_max=50)
추가해준 옵션 파라미터 이름은 checkpoint_every_n 이고 기본값과 설명은 TF2 의 Models 리포지토리 안에 있는 model_main_tf2.py에서 그대로 가져왔다. 또한 keep_checkpoint_max 파라미터를 값을 50으로 추가했는데 이는 기본값이 5로 되어있는데 즉, 학습이 진행됨에 따라 최대 5개까지만 저장하던 체크포인트르 최대 50개까지 저장하도록 바꿔주는 것이다. 학습자가 사용하는 서버의 저장공간이 적다면 값을 더 적게 수정하면 된다.
네트워크 모델 학습
위와 같이 코드를 수정하고 난 뒤에는 TF2와 흡사하게 모델학습을 진행할 수 있다. 물론 TF1이 먼저 나온 버전으로서 TF2를 계속 언급하는게 조금 그렇긴하다. 그래도 본인의 블로그를 보고 따라하는 사람이 있다면 TF1과 TF2를 최대한 사용자가 편하게 학습을 할 수 있도록 셋팅하는 것은 어느정도 이해를 할 것이라 생각한다.
네트워크 모델 학습에 들어가는 파라미터는 우리가 설정한 --checkpoint_every_n과 --model_dir, --pipeline_config_path이다. 위 파라미터를 적어서 코드를 작성해보면 다음과 같다.
$ python model_main.py \
--checkpoint_every_n={steps} \ # ex. 5000
--model_dir={tensorflow_path}/train/tf2/{model_name}/
--pipeline_config_path={tensorflow_path}/train/tf2/{model_name}/pipeline.config
기존에 checkpoint_every_n은 없지만 우리가 해당 파라미터를 추가하고 옵션을 연결해줬으니 이제 작동한다는 점을 기억하자.
TF1은 TF2와 가지는 큰 차이점이 학습에 Estimator 라이브러리를 사용하는데 이는 학습 중에 체크포인트를 생성 시 자동으로 Evaluation 과정을 수행해준다. TF2는 GPU를 사용하여 train을 돌리고 환경변수인 CUDA_VISIBLE_DEIVCES를 공백으로 주어 CPU를 사용하는 eval 과정을 수행하는데, 그것과는 차이를 가지는 것이 특징이다.
백그라운드 실행
학습에 시간이 많이 소요되고, 외부 GPU 서버같은 곳을 원격으로 접속하고 본인 PC는 제때 종료해야한다면 백그라운드 실행을 할 수 있다. 이에 필요한 명령어는 nohup이다. 이 방식은 TF2에도 똑같이 적용할 수 있다. 형식은 다음과 같다.
nohup {백그라운드에서 실행할 명령어} > {기록할 로그 파일} &
그래서 실제로 코드에 적용을 한다면 다음과 같이 사용할 수 있을 것이다. 아래와 같이 실행한다면 model_dir 경로에 train.log라는 파일로 학습 내용이 로그파일로 기록되게 된다. 물론 텐서보드에 대한 이벤트로그는 별도로 남게되어 학습의 경과를 지켜볼 수 있다.
$ nohup python model_main.py \
--checkpoint_every_n={steps} \ # ex. 5000
--model_dir={tensorflow_path}/train/tf2/{model_name} \
--pipeline_config_path={tensorflow_path}/train/tf2/{model_name}/pipeline.config \
> {tensorflow_path}/train/tf2/{model_name}/train.log &

댓글남기기