

개요
NIPS에 2014년에 발표된 Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation 논문의 얕은 리뷰
컨볼루션 네트워크와 공간 모델을 결합하여 통합시킨 자세 추정 학습 프레임워크르 제안하는 논문. 다중 해상도 스케일을 활용한 특징 추출로 MRF(마르코프 랜덤 필드)를 근사화하며, 역전파를 통한 학습을 구현한다. 두 모델의 결합 및 공동 훈련을 구현하여 기존 작업들의 성능을 크게 능가한다.
Model
- 입력은 한 명 이상의 사람이 포함된 RGB 이미지이고 출력은 인간 골격의 주요 관절 위치에 대한 픽셀 별 확률 히트맵이다.
- 컨볼루션, 활성화 함수, 풀링을 결합한 뱅크를 이용하여 원본 이미지의 저해상도 버전에서 추가 처리하여 고해상도와 저해상도출력을 교차 시킨다.
- 원본 입력이미지에 대한 뱅크에 대한 슬라이딩 윈도우 모델과 해상도를 줄이고 수용 영역을 줄인 뱅크를 결합하여 성능을 끌어올린다.
- 머리와 어깨의 관계에 대해서 해부학적으로 비정상적인 출력을 내는 것을 개선하기 위해 고차원 공간 모델(Spatial-Model)을 학습시킨다.
- 각 신체부위에 대한 쌍을 연결하는 그래프를 설계하고 이는 각 기존 신체부위 A를 기반으로 연결된 B가 픽셀 (i, j)에 위치할 확률을 모델링한다.
- 신체 부위 별 연관된 위치에 대한 확률 분포를 공간적으로 학습하도록 설계하였다.
- 부분 탐지기(Part-Detector)와 공간 모델(Spatial-Model)의 결합을 통해 단일 RGB 이미지로부터 관절이 위치할만한 확률 히트맵을 학습하고 공간 모델로 신체 관절 위치에 대한 성능향상을 이루어내어 좋은 성능을 달성한다.
Experiments
- FLIC과 extended-LSP 데이터 셋에서 실험 진행.
- FLIC-plus라는 FLIC과 독립된 데이터 셋을 직접 만들어 공정한 테스트 세트 성능 평가를 제안한다.
- 해당 데이터 셋은 FLIC의 학습 셋과 테스트 셋이 겹치는 부분이 있다는 점에서 착안하였고 FLIC의 테스트 셋과 FLIC-plus의 학습 셋은 충분한 독립성을 보장한다.
- 팔꿈치 및 손목 관절에서 기존 연구에 비해 좋은 성능을 보인다. LSP에 복잡한 포즈에는 덜 효과적이지만 학습 셋의 크기를 늘려 성능을 향상 시킬 수 있다고 한다.
결론
해당 논문은 컨볼루션 네트워크와 마르코프 랜덤 필드 기반의 공간 모델을 결합한 새로운 아키텍쳐를 제안한다. 이에 여러 스케일 특징을 반영할 수 있는 설계를 제공하며 공정한 평가를 위한 FLIC-plus 데이터 셋까지 구축하였다는 의의를 가진다. 심지어 이 당시에도 상용 하드웨어를 사용하여 실시간 프레임 속도로 작동할 수 있어 다양한 응용에 활용 될 수 있음을 시사한다.
번역
Abstract
이 논문은 깊은 합성곱 신경망(Convolutional Network)과 마코프 랜덤 필드(Markov Random Field)로 구성된 새로운 하이브리드 아키텍처를 제안합니다. 우리는 이 아키텍처가 단안 이미지에서 관절 인간 자세 추정(articulated human pose estimation) 문제에 성공적으로 적용되는 방법을 보여줍니다. 이 아키텍처는 신체 관절 위치 간의 기하학적 관계와 같은 구조적 도메인 제약을 활용할 수 있습니다. 우리는 이 두 모델 패러다임을 공동으로 훈련함으로써 성능이 향상되며, 기존의 최신 기술(state-of-the-art)을 크게 능가할 수 있음을 보여줍니다.
1 Introduction
이전의 많은 연구에도 불구하고, 인간의 신체 자세 추정, 특히 단안 RGB 이미지에서 인간 관절의 위치를 찾는 작업은 컴퓨터 비전에서 여전히 매우 도전적인 과제입니다. 관절 간의 복잡한 상호 의존성, 부분적 또는 완전한 관절 가림, 신체 형태, 의복 또는 조명 조건의 변이, 그리고 제한 없는 시야각은 매우 높은 차원의 입력 공간을 초래하여 단순한 탐색 방법으로는 문제를 해결할 수 없게 만듭니다.
이 문제에 대한 최근 접근 방식은 크게 두 가지 범주로 나뉩니다: 1) 전통적인 변형 가능한 부분 모델들 [27]과 2) 딥러닝 기반의 판별 모델들 [15, 30]. 하향식 부분 기반 모델들은 인간 신체가 자연스럽게 관절된 부분들로 나뉘기 때문에 이 문제에 대해 흔히 선택되는 방식입니다. 전통적으로 이러한 접근 방식은 SIFT [18]나 HoG [7]와 같은 저수준의 수작업으로 만든 특징들의 집합에 의존하며, 이것들을 표준 분류기나 더 높은 수준의 생성 모델에 입력합니다. 이러한 특징들이 탐지하려는 부분에 민감하고 입력 공간 내에서 발생할 수 있는 다양한 변형들(예: 조명의 변이)에 불변하도록 신경을 씁니다. 반면, 판별적 딥러닝 접근 방식은 훈련 세트의 변이에 대해 더 관대한 저수준 및 고수준 특징 집합을 학습하며, 최근에는 부분 기반 모델들을 능가하는 성과를 보였습니다 [27]. 그러나 인간 신체 구조에 대한 사전 지식(예: 관절 간 상호 연결성)에 대한 사전 지식을 이러한 네트워크에 통합하는 것은 어려운데, 이는 이러한 네트워크의 저수준 메커니즘을 해석하기가 어렵기 때문입니다.
이 연구에서는 단독으로 기존의 모든 다른 방법들을 능가하는 합성곱 신경망(ConvNet) 부분 탐지기와 부분 기반 공간 모델을 결합하여 통합된 학습 프레임워크를 제안합니다. 우리의 변환 불변 ConvNet 아키텍처는 중첩된 수용 영역을 가진 다중 해상도 특징 표현을 활용합니다. 추가적으로, 우리의 공간 모델은 MRF 반복 신뢰도 전파를 근사화할 수 있으며, 이는 이후 역전파를 통해 학습되고, 부분 탐지기와 동일한 학습 프레임워크를 사용하여 학습됩니다. 우리는 이 두 모델의 결합 및 공동 훈련이 성능을 향상시키고, 인간 신체 자세 인식 작업에서 기존의 최신 모델들을 크게 능가할 수 있음을 보여줍니다.
2 Related Work
“제약이 없는 이미지 도메인에서는, ‘형태 맥락(shape-context)’ 가장자리 기반 히스토그램이나 단순 실루엣 특징과 같은 다양한 아키텍처가 제안되었습니다. 전체 신체 특징을 추출, 학습 또는 추론하는 다양한 기술이 제안되었습니다. 일부는 지역 탐지기와 구조적 추론을 결합하여 대략적인 추적을 수행하거나, 사람에 의존한 추적을 수행합니다. 이와 유사한 접근법으로 ‘Pictorial Structures’를 사용하는 일반적인 기술이 있으며, Felzenszwalb 등은 이를 ‘변형 가능한 부분 모델(Deformable Part Models, DPM)’로 하여 이 접근법을 다루기 쉽게 만들었습니다. 그 후 많은 관련 모델들이 개발되었습니다. 더 복잡한 관절 관계를 모델링하는 알고리즘으로는 Yang과 Ramanan이 있으며, 이들은 선형 SVM으로 모델링된 유연한 템플릿 혼합을 사용합니다. Johnson과 Everingham은 신체 부분 탐지기 계단을 사용하여 더 판별력 있는 템플릿을 얻습니다. 가장 최근의 접근법들은 고차원 부분 관계를 모델링하는 것을 목표로 합니다. Pishchulin은 DPM 모델을 Poselet 사전 지식으로 확장하는 모델을 제안합니다.app과 Taskar는 포즈와 외관 정보를 모두 포함하는 다중 모달 모델을 제안합니다. Poselets 접근법을 따르는 Gkioxari 등의 Armlets 접근법은 부분 구성을 위한 반글로벌 분류기를 사용하며, 실제 데이터에서 좋은 성능을 보였지만, 팔에만 테스트되었습니다. 게다가, 이러한 모든 접근법은 HoG 특징, 가장자리, 윤곽선, 색상 히스토그램과 같은 수작업으로 만든 특징들을 사용한다는 점에서 한계를 가지고 있습니다.”
오늘날 많은 비전 작업, 특히 인간 자세 추정을 위한 가장 성능이 우수한 알고리즘들은 딥 컨볼루션 네트워크를 기반으로 합니다. Toshev 등은 ‘FLIC’ 및 ‘LSP’ 데이터 세트에서 최첨단 성능을 보여줍니다. 그러나 이들의 방법은 이미지로부터 자세 벡터를 직접 회귀하는 것이 비효율적이고 학습하기 어려운 매우 비선형적 매핑이기 때문에, 고정밀 영역에서의 부정확성을 겪고 있습니다.
신경망과 그래픽 모델의 공동 훈련은 이전에 Ning 등[22]에 의해 이미지 분할에서, 그리고 다양한 그룹에 의해 음성 및 언어 모델링에서 보고되었습니다[4, 21]. 우리가 알기로는 이러한 모델이 인간의 신체 부분 위치를 감지하고 위치를 파악하는 문제에 성공적으로 사용된 적은 없습니다. 최근 Ross 등[26]은 컴퓨터 비전 작업에서 3D 포인트 클라우드 분류 및 단일 이미지에서 3D 표면 추정을 위한 구조적 예측을 위해 메시지 전달 영감을 받은 절차를 사용했습니다. 이 연구와 달리, 우리는 메시지 파싱 영감을 받은 네트워크를 역전파에 더 적합하게 구성하여 기존의 신경망에서 구현할 수 있도록 합니다. Heitz 등[14]은 객체 탐지, 영역 레이블링, 기하학적 추론을 동시에 수행하기 위해 선행 분류기 계단을 훈련시킵니다. 그러나 계단의 순방향 특성 때문에 나중에 배치된 분류기는 이전 분류기가 특정 오류 모드를 수정하는 데 집중하도록 하거나 계단에서 나중에 배치된 분류기가 이전 분류기의 실수를 무시하도록 허용할 수 없습니다. Bergtholdt 등[2]은 부분 기반 모델을 사용한 객체 클래스 탐지 접근법을 제안하며, 여기서 완전히 연결된 그래프를 생성하고 A* 탐색을 사용하여 MAP 추론을 수행할 수 있지만, 단일 및 쌍방향 잠재력을 생성하는 데 SIFT 및 색상 특징에 의존합니다.
3 Model
3.1 Convolutional Network Part-Detector
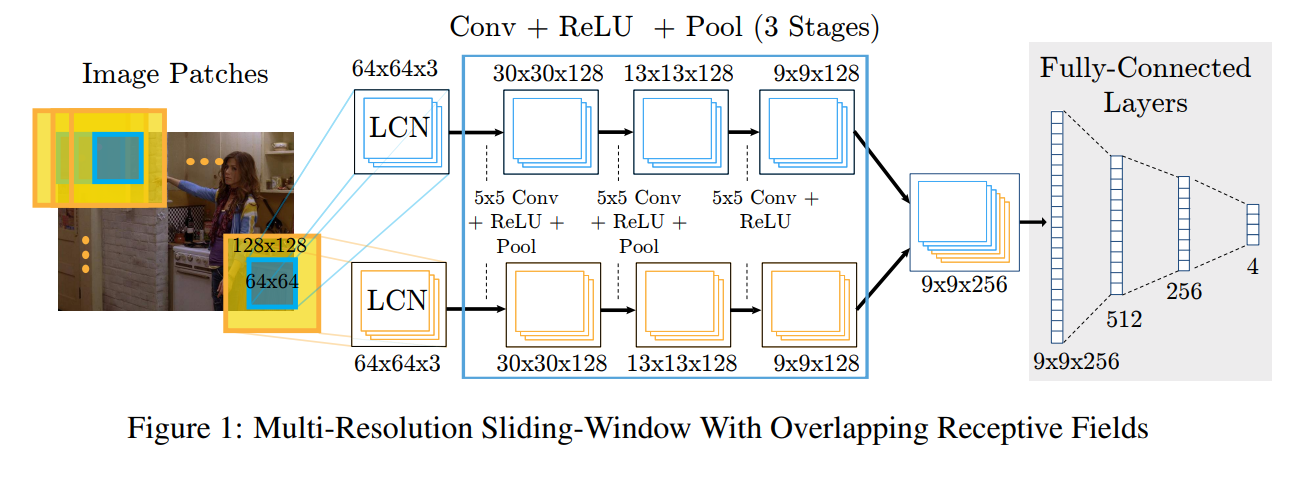
우리의 탐지 파이프라인의 첫 번째 단계는 신체 부분 위치 지정을 위한 심층 ConvNet 아키텍처입니다. 입력은 한 명 이상의 사람이 포함된 RGB 이미지이고 출력은 인간 골격의 주요 관절 위치에 대한 픽셀별 확률을 생성하는 히트맵입니다.
슬라이딩 윈도우 ConvNet 아키텍처는 그림 1에 표시되어 있습니다. 네트워크는 입력 이미지를 따라 슬라이드되어 각 신체 관절에 대한 밀집된 히트맵 출력을 생성합니다. 우리의 모델은 중첩된 수용 영역을 가진 다중 해상도 입력을 통합합니다. 그림 1의 상위 컨볼루션 뱅크는 64x64 해상도의 표준 입력 창을 보고, 하위 뱅크는 128x128의 더 큰 입력 맥락을 다운샘플링하여 64x64로 변환합니다. 입력 이미지는 로컬 대조 정규화(LCN [6])되며(저해상도 뱅크에서 앤티앨리어싱을 사용하여 다운샘플링한 후) 대략적인 라플라시안 피라미드를 생성합니다. 중첩된 맥락을 사용하는 이점은 네트워크가 적은 가중치 증가로 입력 이미지의 더 큰 부분을 볼 수 있게 한다는 점입니다. 라플라시안 피라미드의 역할은 네트워크 중복성을 최소화하기 위해 각 뱅크에 중복되지 않는 스펙트럼 콘텐츠를 제공하는 것입니다.
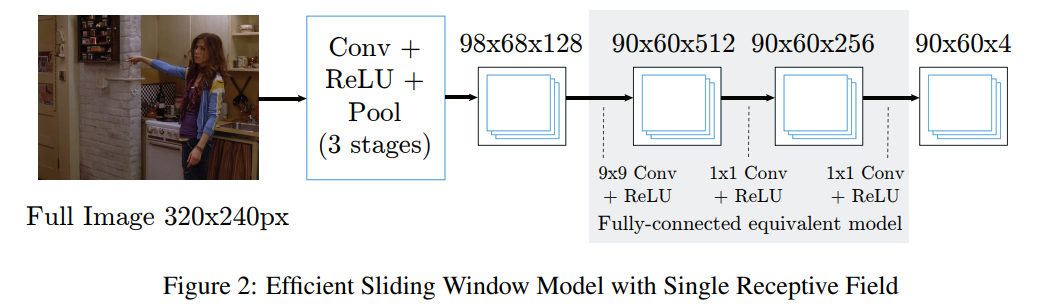
슬라이딩 윈도우 모델(그림 1)의 장점은 탐지기가 위치 불변성을 갖는다는 것입니다. 그러나 주요 단점은 중복된 합성곱 때문에 평가가 비용이 많이 든다는 점입니다. 최근 연구 [11, 28]에서는 전체 입력 이미지에서 합성곱 단계를 수행하여 밀집된 특징 맵을 효율적으로 생성함으로써 이 문제를 해결했습니다. 이러한 밀집된 특징 맵은 각 픽셀에서 완전히 연결된 네트워크를 복제하기 위해 합성곱 단계를 통해 처리됩니다. 단일 해상도 뱅크에 대한 슬라이딩 윈도우 모델의 등가이면서도 효율적인 버전이 그림 2에 나와 있습니다. 합성곱 단계에서 풀링이 발생하므로 출력 히트맵의 해상도는 입력 이미지보다 낮아집니다.
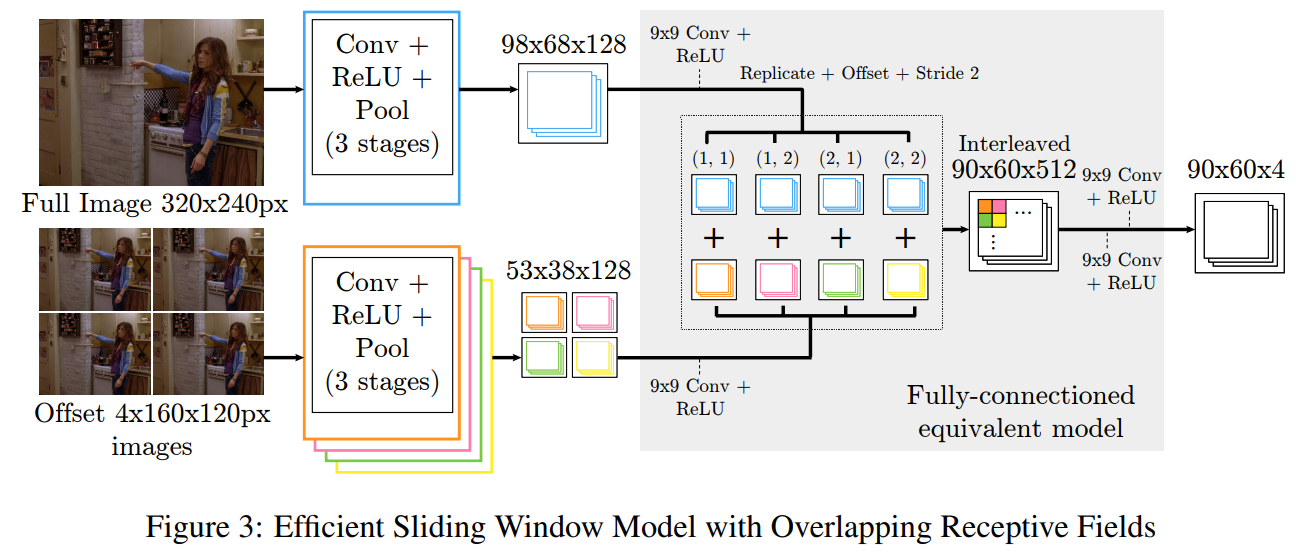
우리의 부분 탐지기는 다중 해상도 및 중첩된 수용 영역을 가진 효율적인 슬라이딩 윈도우 기반 아키텍처를 결합하며, 후속 모델이 그림 3에 나와 있습니다. 큰 맥락(저해상도) 합성곱 뱅크는 슬라이딩 윈도우 모델과 동일한 밀집된 출력을 생성하기 위해 저해상도 이미지에서 1/2 픽셀 간격을 요구하므로, 뱅크는 네 개의 다운샘플링된 이미지를 처리해야 하며, 각 이미지는 1/2 픽셀 오프셋을 갖고 동일한 가중치 합성곱을 사용합니다. 이 네 개의 출력은 고해상도 합성곱 특징과 함께 9x9 합성곱 단계를 거쳐 처리되며(512개의 출력 특징 포함), 이후 저해상도 뱅크의 출력이 추가되고 고해상도 뱅크의 출력과 교차됩니다.
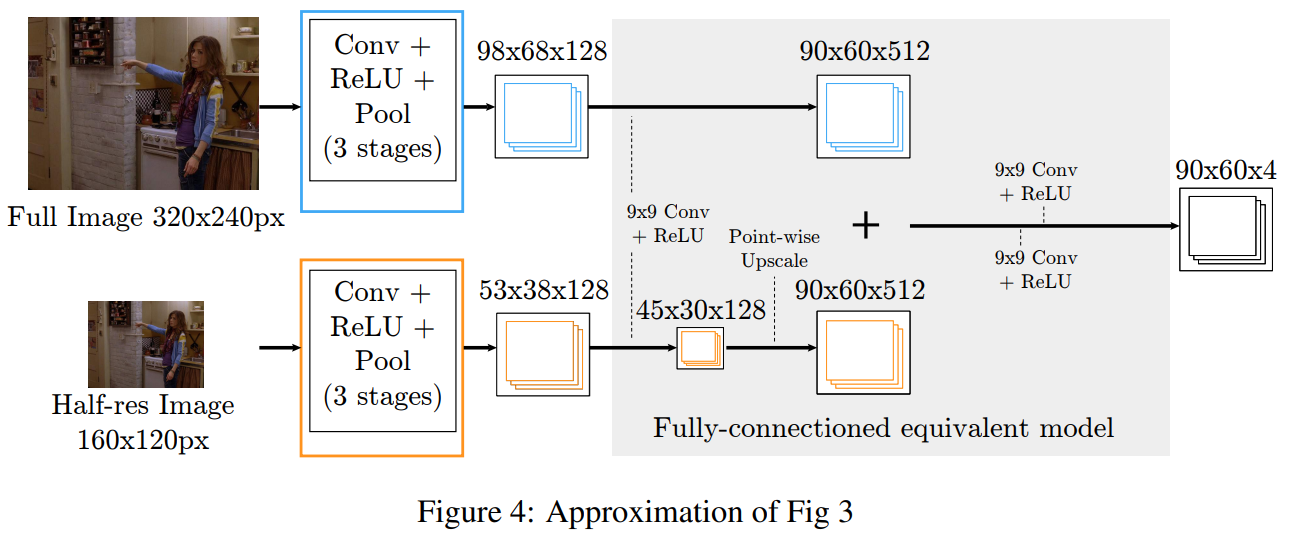
훈련 시간을 개선하기 위해, 우리는 저해상도 단계를 그림 4에 나와 있는 것처럼 단일 합성곱 뱅크로 대체하고 결과적인 특징 맵을 업스케일링합니다. 우리의 실제 구현에서는 3개의 해상도 뱅크를 사용합니다. 간소화된 아키텍처는 더 이상 그림 1의 원래 슬라이딩 윈도우 네트워크와 동등하지 않지만, 저해상도 합성곱 특징이 효과적으로 축소되고 완전 연결된 단계로 복제됩니다. 그러나 성능 손실이 최소임을 경험적으로 확인했습니다.
네트워크의 지도 학습은 Nesterov Momentum을 사용한 배치 확률적 경사 하강법(SGD)을 통해 수행됩니다. 우리는 예측 출력과 목표 히트맵 간의 거리를 최소화하기 위해 평균 제곱 오차(MSE) 기준을 사용합니다. 목표는 작은 분산을 가진 2D 가우시안이며, 지상 진리 관절 위치에 중심이 맞춰져 있습니다. 학습 시간 동안 우리는 입력 이미지의 임의 뒤집기 및 크기 조정과 같은 무작위 변동도 수행하여 일반화 성능을 향상시킵니다.
3.2 Higher-Level Spatial-Model
부분 탐지기(섹션 3.1)의 성능은 검증 세트에서 많은 잘못된 긍정(오탐)과 해부학적으로 잘못된 자세를 예측합니다. 예를 들어, 얼굴 탐지를 위한 피크가 대응하는 어깨 탐지 피크에서 비정상적으로 멀리 있을 때가 그렇습니다. 따라서 개선된 부분 탐지기 맥락에도 불구하고 피드 포워드 네트워크는 여전히 신체 부위의 제약 조건을 전체 신체 자세 범위에 대해 암묵적으로 학습하는 데 어려움을 겪고 있습니다. 우리는 관절 간 연결성을 제약하고 전체적인 자세 일관성을 강제하기 위해 고차원 공간 모델(Spatial-Model)을 사용합니다. 이 단계의 기대는 이미 지상 진리 자세와 가까운 탐지 성능을 향상시키는 것이 아니라, 해부학적으로 잘못된 오탐수를 제거하는 것입니다.
Jain 등[15]과 유사하게, 우리는 각 신체 부위의 공간적 위치 분포에 대한 MRF와 유사한 모델로 공간 모델(Spatial-Model)을 공식화합니다. 그러나 그들의 모델의 가장 큰 단점은 신체 부위 우선값과 그래프 구조가 명시적으로 수작업으로 제작된다는 점입니다. 반면, 우리는 우선 모델을 학습하고 암묵적으로 공간 모델의 구조를 학습합니다. [15]와 달리, 우리는 공간 모델에서 모든 신체 부위를 서로 짝을 이루는 방식으로 연결하여 완전히 연결된 그래프를 만듭니다. 부분 탐지기(섹션 3.1)는 각 신체 부위 위치에 대한 단항 포텐셜을 제공합니다. 그래프의 짝수 포텐셜은 합성곱 우선값을 사용하여 계산되며, 이는 한 신체 부위의 위치에 대한 조건부 분포를 모델링합니다. 예를 들어, 신체 부위 $B$가 중심 픽셀에 위치해 있으면 합성곱 우선값 $P_{A∣B}(i,j)$ 는 신체 부위 $A$가 픽셀 위치 $(i,j)$ 에 발생할 확률입니다. 신체 부위 $A$ 에 대해 우리는 최종 주변 확률 $\bar{p}_A$ 를 다음과 같이 계산합니다:
\[\begin{equation} \bar{p}_A=\frac{1}{Z}\prod_{v\in V}(p_{A|v}*p_v + b_{v\rightarrow A}) \end{equation}\]여기서 $v$는 조인트 위치, $p_{A \bar v}$ 는 위에서 설명한 조건부 prior, $b_{v\rightarrow a}$ 는 조인트 $v$ 에서 $A$ 로 메시지의 배경 확률을 설명하는 데에 사용되는 편향 항이며 $Z$ 는 분할 함수입니다. 방정식 1의 평가 결과는 합-곱 신뢰도 전파의 단일 라운드와 유사합니다. 우리의 공간 모델이 트리 구조가 아니기 때문에 전역 최적화로의 수렴은 보장되지 않습니다. 그러나 결과(Fig 8b)에서 알 수 있듯이, 추론된 솔루션은 데이터셋 내의 모든 자세에 대해 충분히 정확합니다. 학습된 쌍 분포는 그래프 구조에서 어떤 쌍 에지가 제거되어야 할 때 순수하게 균일합니다. 그림 5는 강한 어깨 탐지의 존재를 통합함으로써 공간 모델이 얼굴 히트맵에서 해부학적으로 잘못된 강한 이상값을 제거할 수 있는 실제 예를 보여줍니다. 간단히 하기 위해 어깨와 얼굴 관절만 보여졌지만, 이 예는 모든 신체 부위 쌍을 통합하도록 확장될 수 있습니다. 그림 5에 표시된 어깨 히트맵에 잘못된 거짓 부정이 있었다면(즉, 올바른 어깨 위치에서 탐지가 없을 경우), 배경 편향 $b_{v→A}$ 을 추가함으로써 출력 히트맵이 감지된 얼굴 영역에 최대값이 없는 것을 방지할 수 있습니다.
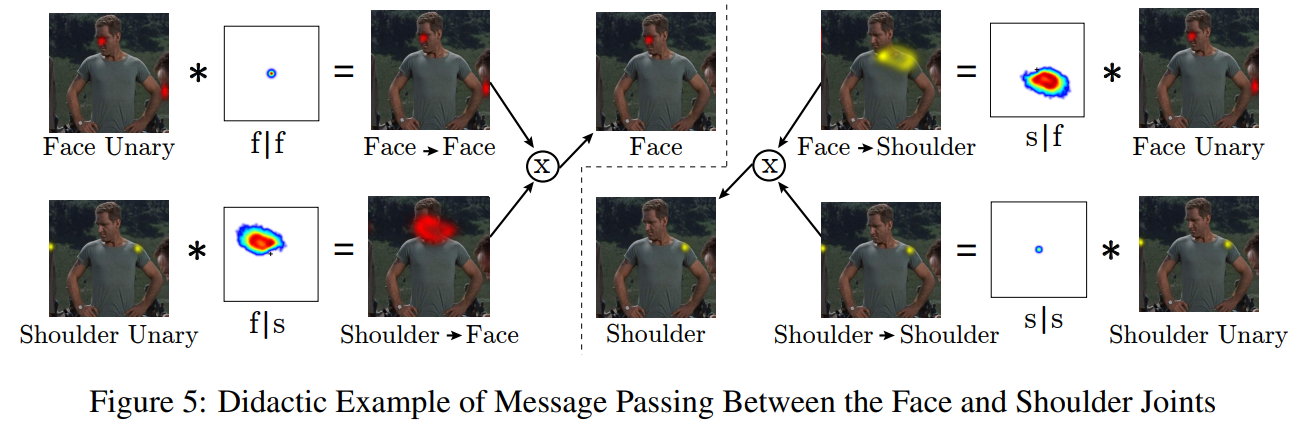
그림 5는 FLIC [27] 데이터셋에서 학습된 얼굴과 어깨 부위에 대한 조건부 분포를 포함하고 있습니다. 임의의 부위 $A$ 에 대해 분포 $P_{A∣A}$ 는 동일 맵이며, 따라서 어느 관절에서 자신에게 전달되는 메시지는 단항 분포입니다. FLIC 데이터셋은 얼굴의 오른쪽 어깨가 바로 아래 오른쪽에 위치한 정면 포즈에 편향되어 있기 때문에, 모델은 이러한 신체 부위들 간의 올바른 공간 분포를 학습하고, 어깨와 얼굴 사이의 예상 변위를 설명하는 공간 위치에서 높은 확률을 가집니다. 더 다양한 포즈 범위를 다루는 데이터셋(예: LSP [17] 데이터셋)에서는 이러한 분포가 덜 제한적일 것이며, 따라서 이 간단한 공간 모델은 덜 효과적일 것으로 예상됩니다.
우리의 실제 구현에서는 위의 분포를 에너지로 간주하여 $Z$ 의 평가를 피합니다. 우리는 세 가지 이유로 분할 함수(Partition Function)를 포함하지 않습니다. 첫째, 우리는 네트워크의 최대 출력값에만 관심이 있으며, 따라서 출력 에너지가 정규화된 분포에 비례하기만 하면 됩니다. 둘째, 부분 탐지기 및 공간 모델 매개변수는 모두 픽셀 위치에 따라 동일한 공유 가중치(합성곱) 매개변수만 포함하고 있기 때문에, 역전파 동안 분할 함수를 평가하는 것은 경사 가중치에 상수 값을 추가하는 것과 동일하게 작용하여 배치당 학습률 조정자를 적용하는 것과 같을 것입니다. 마지막으로, 파트의 수가 사전에는 알려져 있지 않기 때문에(이미지에는 라벨이 없는 사람이 있을 수 있음), 그리고 분포 $p_v$ 가 단일 사람의 부위 위치를 설명하기 때문에, 우리는 파트 모델 출력을 정규화할 수 없습니다. 최종 모델은 방정식 1의 수정입니다:
\[\begin{equation} \bar{e}_A=(\sum_{v\in V}[\log(\text{SoftPlus}(e_{A|v})*\text{ReLU}(e_v)+\text{SoftPlus}(b_{v\rightarrow A}))]) \end{equation}\] \[\begin{align} \text{where:} \text{SoftPlus}(x) = 1/\beta \log(1+\exp(\beta x)), 1/2 \leq \beta \leq 2 \\ \text{ReLU}(x) = max(x, \epsilon), 0 < \epsilon < 0.01 \end{align}\]위 공식은 더 이상 MRF와 정확히 동일하지 않지만, 여전히 방정식 1의 공간적 제약을 만족스럽게 인코딩합니다. 방정식 2의 네트워크 기반 구현은 그림 6에 나와 있습니다. 방정식 2는 방정식 1의 외부 곱셈을 로그 공간 덧셈으로 대체하여 수치적 안정성을 향상시키고 합성곱 출력 경사도의 결합을 방지합니다(로그 공간에서의 덧셈은 손실 함수의 합성곱 출력에 대한 편미분이 다른 단계의 출력에 의존하지 않음을 의미합니다). 가중치, 편향 및 입력 히트맵에 SoftPlus 및 ReLU 단계를 포함하면 0보다 큰 합성곱 출력을 유지할 수 있어 로그 단계로 이어지는 값에 대한 수치적 문제를 방지합니다. 마지막으로 SoftPlus 단계는 학습 중에 연속적이고 0이 아닌 가중치 및 편향 경사도를 유지하기 위해 사용됩니다. 이 수정된 공식으로 방정식 2는 역전파와 SGD를 사용하여 학습됩니다.
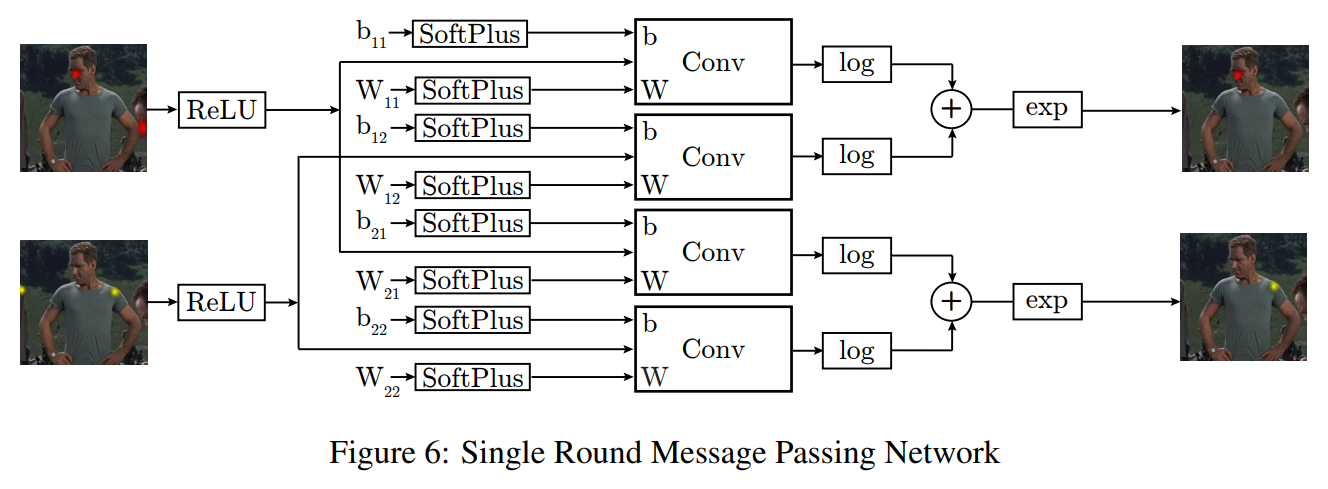
합성곱 크기는 최대 관절 변위가 합성곱 창 내에서 처리되도록 조정됩니다. 90x60 픽셀 히트맵 출력을 위해, 이는 128x128 크기의 큰 합성곱 커널로 이어지며, 관절 변위 반경 64 픽셀을 처리하기 위해 설정됩니다(픽셀 손실을 방지하기 위해 히트맵 입력에 패딩이 추가됩니다). 따라서 이러한 큰 커널에 대해 우리는 FFT 합성곱을 사용하며, 이는 Mathieu 등[19]의 GPU 구현을 기반으로 합니다.
합성곱 가중치는 훈련 예시에서 생성된 관절 변위의 경험적 히스토그램을 사용하여 초기화됩니다. 이러한 초기화는 학습 성능을 향상시키고, 훈련 시간을 단축하며, 최적화 안정성을 향상시킵니다. 훈련 중에는 히트맵 입력을 무작위로 뒤집고 크기를 조정하여 일반화 성능을 향상시킵니다.
3.3 Unified Model
공간 모델(섹션 3.2)이 역전파를 사용하여 학습되기 때문에, 우리는 부분 탐지기와 공간 모델 단계를 단일 통합 모델로 결합할 수 있습니다. 이를 위해, 우리는 먼저 부분 탐지기를 별도로 훈련하고 히트맵 출력을 저장합니다. 그런 다음 이 히트맵을 사용하여 공간 모델을 학습합니다. 마지막으로, 학습된 부분 탐지기와 공간 모델을 결합하고 전체 네트워크를 통해 역전파를 수행합니다.
이 통합된 미세 조정은 성능을 더욱 향상시킵니다. 우리는 공간 모델이 가능한 히트맵 활성화의 출력 차원을 효과적으로 줄일 수 있기 때문에, 부분 탐지기가 가용 학습 용량을 사용하여 정확한 타겟 활성화를 더 잘 지역화할 수 있다고 가정합니다.
4 Results
섹션 3.1과 3.2의 모델은 Torch7 [6] 프레임워크 내에서 구현되었습니다(비표준 단계에 대한 사용자 정의 GPU 구현 포함). 부분 탐지기 학습은 약 48시간, 공간 모델 학습은 12시간이 걸리며, 두 네트워크를 통한 단일 이미지의 순방향 전파는 51ms가 소요됩니다.
우리는 FLIC [27] 및 확장된 LSP [17] 데이터셋에서 우리의 아키텍처를 평가했습니다. 이 데이터셋은 아마존 Mechanical Turk을 사용하여 생성된 2D 지상 진리 관절 정보가 포함된 정지 RGB 이미지로 구성됩니다. FLIC 데이터셋은 주로 정면을 향해 서 있는 포즈를 취한 헐리우드 영화의 배우들로 구성된 5003장의 이미지로 이루어져 있으며, 1016장의 이미지는 테스트에 사용됩니다. 반면, 확장된 LSP 데이터셋은 스포츠를 하는 운동선수들의 더 다양한 포즈(10442개의 학습 이미지 및 1000개의 테스트 이미지)를 포함하고 있습니다. FLIC 데이터셋에는 한 장면에 여러 사람이 등장하는 프레임이 많이 포함되어 있지만, 장면에서 한 사람의 관절 위치만 라벨링되어 있습니다. 따라서 장면에서 라벨링된 사람을 위한 대략적인 상체 경계 상자가 제공됩니다. 우리는 이 데이터를 사용하여 추가적인 ‘상체 관절 히트맵’을 공간 모델의 입력에 포함시켜 복잡한 장면에서 올바른 특징 활성화를 선택할 수 있도록 학습시킵니다.
FLIC 전체 데이터셋에는 20,928개의 학습 이미지가 포함되어 있지만, 이 중 많은 학습 세트 이미지가 1016개의 테스트 세트 장면에서 나온 샘플을 포함하고 있어 FLIC 테스트 세트에서 불공정한 과적합이 발생할 수 있습니다. 따라서 우리는 새로운 데이터셋 FLIC-plus(http://cims.nyu.edu/~tompson/flic-plus.htm)를 제안합니다. 이는 FLIC-plus 데이터셋에서 17,380개의 이미지 하위 집합입니다. 이 데이터셋을 만들기 위해, 우리는 아마존 Mechanical Turk를 사용하여 FLIC 테스트 세트와 FLIC-plus 학습 세트 모두에 대해 고유한 장면 레이블을 생성했습니다. 그런 다음 FLIC 테스트 세트와 장면을 공유한 FLIC-plus 학습 세트의 모든 이미지를 제거했습니다. 원래 3987 FLIC 학습 세트 샘플 중 253개의 샘플 이미지가 테스트 세트 샘플과 동일한 장면에서 왔기 때문에(위 절차에 의해 제거됨), 우리는 이러한 이미지를 다시 추가하여 FLIC-plus 학습 세트가 원래 FLIC 학습 세트의 상위 집합이 되도록 했습니다. 이 절차를 사용하여 FLIC-plus의 추가 샘플이 FLIC 테스트 세트 샘플과 충분히 독립적임을 보장할 수 있습니다.
테스트 세트 성능 평가를 위해 Sapp 등[27]이 제안한 측정값을 사용합니다. 주어진 정규화된 픽셀 반경(각 샘플의 상체 높이로 정규화)에 대해, 예측된 UV 관절 위치와 지상 진리 위치 간의 거리가 주어진 반경 내에 있는 테스트 세트의 이미지 수를 계산합니다.
그림 7a와 7b는 팔꿈치 및 손목 관절에 대한 FLIC 테스트 세트에서 우리의 모델 성능을 각각 보여주며, FLIC 및 FLIC-plus 학습 세트를 사용하여 학습되었습니다. LSP 데이터셋에서의 성능은 그림 7c와 8a에 나와 있습니다. LSP 평가에서는 이전 연구와의 공정한 비교를 위해 사람 중심(또는 비관찰자 중심) 좌표를 사용합니다[30, 8]. 우리의 모델은 이 두 가지 도전적인 데이터셋에서 기존 최첨단 기술을 상당한 차이로 능가합니다.
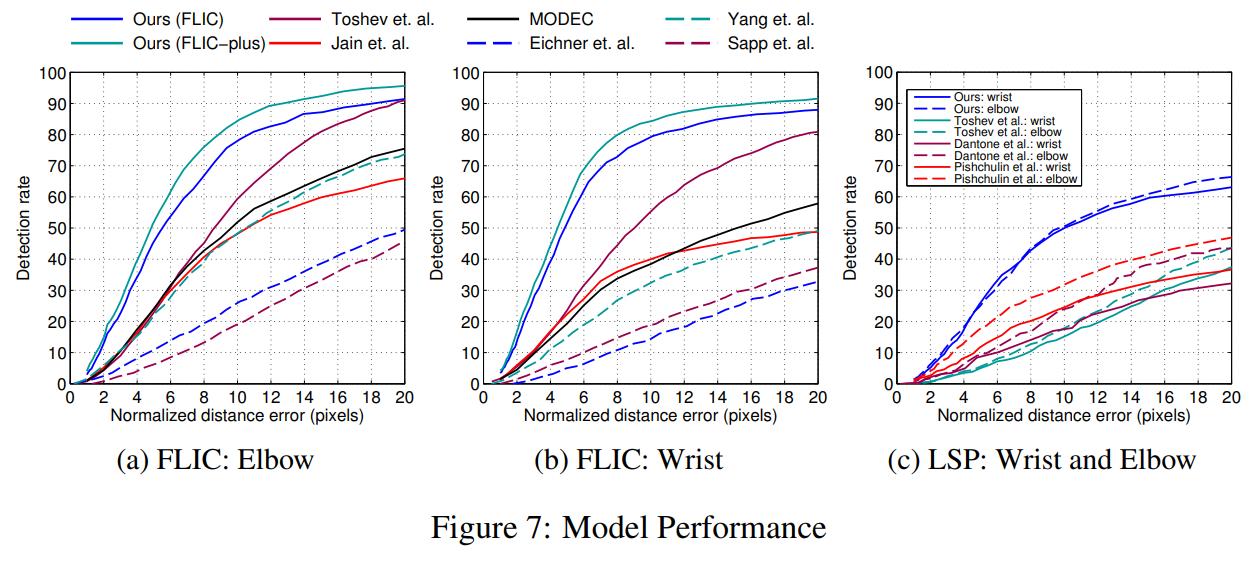
그림 8b는 간단한 공간 모델(Spatial-Model)에 의한 성능 향상을 보여줍니다. 예상대로 공간 모델은 낮은 반경 임계값에서는 정확도에 거의 영향을 미치지 않지만, 큰 반경에서는 성능을 8~12% 증가시킵니다. 두 모델의 통합 학습(독립적인 사전 학습 후)은 큰 반경 임계값에서 4~5%의 추가 탐지율을 제공합니다.
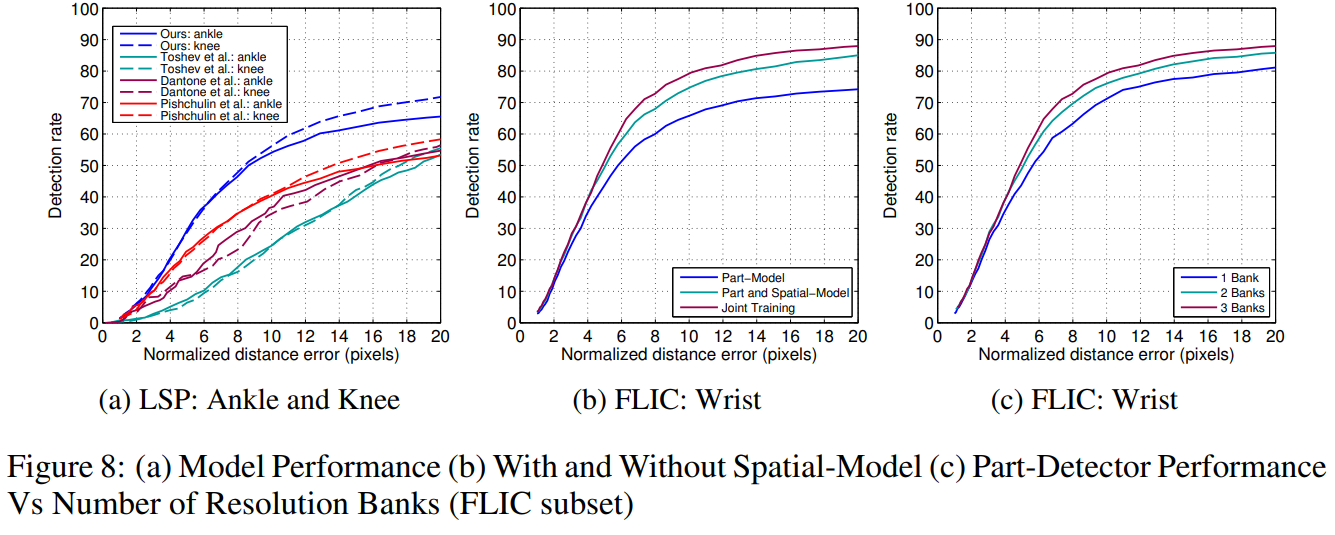
그림 8c에서 해상도 뱅크 수의 영향이 나타납니다. 예상대로 여러 해상도 뱅크가 추가될 때 큰 성능 향상을 확인할 수 있습니다. 또한 수용 영역의 크기와 네트워크에서 풀링 단계의 수와 크기도 성능에 큰 영향을 미친다는 점을 주목해야 합니다. 우리는 거친 메타 최적화를 사용하여 컴퓨팅 예산 내에서(순방향 전파당 100ms 미만) 최대 검증 세트 성능을 얻기 위해 네트워크 하이퍼파라미터를 조정합니다.
그림 9는 FLIC 및 LSP 테스트 세트의 다양한 입력에 대한 예측된 관절 위치를 보여줍니다. 우리 네트워크는 FLIC 데이터셋에서 설득력 있는 결과를 생성하지만(관절 위치 오류가 낮음), 단순한 공간 모델이 LSP 데이터셋의 다수의 복잡한 포즈에 덜 효과적이기 때문에 일부 이미지에서는 잘못된 관절 예측을 생성합니다. 우리는 훈련 세트의 크기를 늘리면 이러한 어려운 경우에 대한 성능이 향상될 것이라고 믿습니다.
5 Conclusion
우리는 새로운 ConvNet 부분 탐지기와 MRF에서 영감을 받은 공간 모델의 통합이 인간 신체 자세 인식 작업에서 기존 아키텍처를 크게 능가한다는 것을 보여주었습니다. 우리의 아키텍처는 상용 수준의 하드웨어를 사용하여 학습 및 추론을 수행하며, 거의 실시간 프레임 속도로 실행되어 다양한 응용 분야에서 이 기술을 실용적으로 사용할 수 있습니다.
향후 연구에서는 단순한 공간 모델의 복잡성과 표현력을 높여(특히 LSP와 같은 제약이 없는 데이터셋에서) 이러한 결과를 더욱 향상시키기를 기대합니다.
6 Acknowledgments
저자들은 Mykhaylo Andriluka에게 그의 지원에 대해 감사의 뜻을 표합니다. 이 연구는 해군 연구청(ONR)의 N000141210327 상에 의해 부분적으로 자금을 지원받았습니다.
Jonathan Tompson, Arjun Jain, Yann LeCun, Christoph Bregler Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation

댓글남기기