

개요
YOLOv10: Real-Time End-to-End Object Detection 의 번역 및 얕은 리뷰 포스팅. YOLOv1 부터 Yolov10 까지 달려온 논문들의 얕은 리뷰.
Abstract
지난 몇 년 간, YOLO는 계산 비용과 탐지 성능간의 효율적인 균형으로 실시간 객체 감지 분야에서 주요 패러다임이 되어습니다. 연구자들은 YOLO를 위한 아키텍쳐 설계, 최적화 목표, 데이터 증강 전략 등을 탐구하여 좋은 성과를 이루어왔습니다. 그러나 후처리를 위한 NMS에 대한 의존성이 YOLO의 End-to-End 배포를 방해고 추론 지연시간에 부정적인 영향을 미칩니다. 또한 YOLO의 다양한 구성요소 디자인은 종합적이고 철저한 검토가 부족하여 눈에 띄는 계산 중복이 존재하고 모델의 능력을 제한합니다. 이는 성능개선의 잠재성에서 최선의 효율은 아닙니다. 본 연구에선 후처리와 모델 아키텍쳐 측면에서 YOLO의 성능-효율성을 더욱 발전시키는 것을 목표로 합니다. 이를 위해, 우리는 YOLO에서 NMS 없는 학습을 위한 일관된 이중 할당(consistent dual assignments)를 제안하여 경쟁력 있는 성능과 낮은 추론 지연을 동시에 제공합니다. 또한 우리는 YOLO를 위한 전체적인 효율성-정확성 모델 설계 전략을 도입합니다. 우리는 효율성과 정확성 측면에서 YOLO의 다양한 구성 요소를 종합적으로 최적화하여 계산 오버헤드를 크게 줄이고 성능을 향상 시킵니다. 우리의 노력의 결과는 실시간 End-to-End 객체 감지를 위한 새로운 세대의 YOLO 시리즈인 YOLOv10 입니다. 광범위한 실험은 YOLOv10이 다양한 모델 규모에서 최첨단 성능과 효율성을 달성함을 보여줍니다. 예를 들어, YOLOv10-S는 COCO 데이터에 대해 유사한 AP 모델로 RT-DETR-R18보다 1.8배 빠르며, 매개변수와 FLOPs수는 2.8배 적습니다. YOLOv9-C와 비교하여 YOLOv10-B는 동일한 성능 대비 지연이 46% 적고 매개변수도 25% 적습니다.
- 기존 YOLO 아키텍쳐에서는 NMS에 대한 의존성이 추론 시간에 대한 방해요소다.
- 뿐만 아니라 컴포넌트 디자인이 계산 중복 및 모델 성능을 제한하는 요소들이 있다.
- YOLOv10을 제안하며 NMS 없는 학습 및 이중 할당을 통해 성능 및 효율성을 제고한다.
- 이전 버전의 모델 대비 동일 성능을 내는 YOLOv10의 모델들은 더 빠르고, 매개변수와 연산량이 더 적다.
Introduction
실시간 객체 감지는 컴퓨터 비전 분야에서 항상 주요 초점이 되어 왔으며, 낮은 지연시간 하에 이미지 내 객체의 카테고리와 위치를 정확하게 예측하는 것을 목표로 합니다. 이 기술은 자율 주행, 로봇 내비게이션, 객체 추적 등을 포함한 다양한 실용적인 응용 프로그램에서 채택되고 있습니다. 최근 몇 년간, 연구자들은 실시간 탐지를 달성하기 위해 CNN 기반 객체 감지기 고안에 집중해 왔습니다. 그 중, YOLO는 성능과 효율성 간의 능숙한 균형 덕분에 인기를 끌고 있습니다. YOLO의 디텍션 파이프 라인은 모델의 포워드 프로세스와 NMS 후처리로 구성됩니다. 그러나 두 부분에 여전히 결함이 있어 최적이 아닌 차선의 정확도와 지연 시간을 초래합니다.
특히 YOLO는 훈련 중에 일반적으로 일대다 레이블 할당 전략을 사용하여 하나의 실제 객체가 여러 양성 샘플에 해당합니다. 이 접근 방식은 우수한 성능을 제공하지만, 추론 중에는 최적의 양성 샘플을 선택하기 위해 NMS가 필요합니다. 이는 추론 속도를 저하시키고 NMS의 하이퍼 파라미터에 성능이 민감해지며, 결과적으로는 YOLO가 최적의 End-to-End 배포를 달성하지 못하게 방해합니다. 이 문제를 해결하기 위한 한 가지 방법은 최근에 도입 된 End-to-End DETR 아키텍쳐를 채택하는 것입니다. 예를 들어, RT-DETR은 효율적인 하이브리드 인코더와 최소 불확실성 쿼리 선택을 제시하여 DETR을 실시간 응용 프로그램의 영역으로 이끕니다. 그럼에도 불구하고, DETR 전개 중의 고유한 복잡성은 정확도와 속도 간의 최적 균형을 달성하는 능력을 방해합니다. 또 다른 방법은 CNN 기반 감지기를 위해 End-to-End 감지를 탐구하는 것으로, 이는 일반적으로 중복 예측을 억제하기 위해 일대일 할당 전략을 활용합니다. 그러나 이러한 방법은 보통 추가적인 추론의 오버헤드를 가져오거나 최적 이하의 성능을 달성합니다.
따라서 모델 아키텍쳐 설계는 여전히 YOLO에게 근본적인 도전 과제로 남아있으며, 이는 정확도와 속도에 중요한 영향을 미칩니다. 보다 효율적이고 효과적인 모델 아키텍쳐를 달성하기 위해 연구자들은 다른 디자인 전략을 탐구했습니다. 다양한 주요 계산 유닛으로는 DarkNet, CSPNet, EfficientRep, ELAN 등이 있으며, 이는 백본의 특징 추출 능력을 향상시키기 위한 것입니다. 넥(Neck)에는 PAN, BiC, GD, RepGFPN 등이 있으며, 이는 멀티 스케일 특징 융합을 향상 강화하기 위한 것입니다. 그 외에도 모델 스케일링 전략 재파라미터화 기법도 조사되었습니다. 이러한 노력들은 주목할 만한 진전을 이루었지만, 효율성과 정확성 측면에서 YOLO의 다양한 구성요소에 대한 종합적인 검토는 여전히 부족합니다. 그 결과, YOLO 내에는 여전히 상당한 계산의 중복이 존재하여 비효율적인 매개변수 활용과 최적 이하의 효율성을 초래합니다. 또한, 제한적인 모델 능력의 결과로 성능이 저하되어 정확도 향상을 위한 충분한 여지를 남깁니다.
본 연구에서는 이러한 문제를 해결하고 YOLO의 정확도-속도 경계를 더욱 발전시키는 것을 목표로 합니다. 우리는 후처리와 모델 아키텍쳐 파이프라인을 모두 대상으로 합니다. 이를 위해 우리는 먼저, 이중 라벨 할당 및 일관된 매칭 메트릭을 사용하여 NMS 없는 YOLO를 위해 일관된 이중 할당 전략을 제안하여 후처리에서 중복된 예측 문제를 해결합니다. 이를 통해 모델은 훈련 중에 풍부하고 조화로운 지도를 즐길 수 있으며 추론 동안에는 NMS의 필요성을 제거하여 높은 효율성의 경쟁력 있는 성능으로 이끕니다. 둘째로, 우리는 YOLO의 다양한 구성요소에 대한 종합적인 검토를 수행하여 모델 아키텍쳐를 위한 전체적 효율성-정확도 주도의 모델 설계 전략을 제안합니다. 효율성을 위해, 우리는 명시된 계산 중복을 줄이기 위한 가벼운 분류 헤드, 공간-채널 분리 다운샘플링, 랭크-유도 블록 디자인을 제안하고 더욱 효과적인 아키텍쳐를 달성합니다. 정확도를 위해, 우리는 대형 커널 컨볼루션을 탐구하고 모델 능력을 향상 시키기 위한 효과적인 부분 셀프 어텐션 모듈을 제안하여 저비용으로 성능 향상을 위한 잠재력을 활용합니다.
이러한 접근 방식에 기반하여, 우리는 서로 다른 모델 스케일을 갖춘 새로운 실시간 End-to-End 감지기 계열인 YOLOv10-N/S/M/B/L/X를 달성하는 데 성공했습니다. 객체 감지기를 위한 표준 벤치마크, 즉 COCO에 대한 광범위한 실험은 우리의 YOLOv10이 다양한 모델 스케일에서, 계산-정확도 트레이드 오프 측면에서 과거의 SOTA 모델을 크게 능가할 수 있음을 입증합니다. 그림 1에 표시된 바와 같이, 우리의 YOLOv10-S/X는 각각 유사한 성능의 RT-DETR-R18/R101보다 각각 1.8배/1.3배 빠릅니다. YOLOv9-C와 비교했을 때, YOLOv10-B는 동일한 성능으로 46% 줄어든 지연을 달성합니다. 또한, YOLOv10은 매우 효율적인 매개변수 활용을 보여줍니다. 우리의 YOLOv10-L/X는 각각 1.8배, 2.3배 더 적은 매개변수로 0.3 AP, 0.5 AP 성능을 내며 YOLOv8-L/X를 능가합니다. YOLOv10-M은 YOLOv9-M/YOLO-MS와 비교하여 비슷한 AP를 달성하며, 각각 23%/31% 적은 매개변수를 가집니다. 우리는 우리의 연구가 분야의 발전과 더 많은 연구에 대해 영감을 주기를 바랍니다.
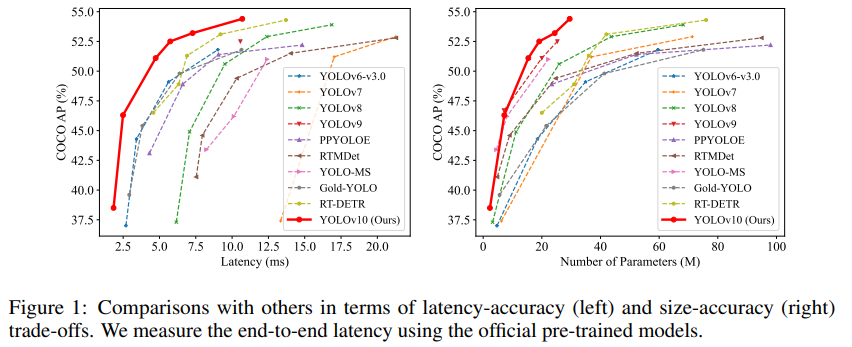
- 기존 YOLO의 객체 감지 파이프 라인은 모델 포워드 프로세스와 NMS 후처리로 구성되며, 이에는 결함이 있어 최적이 아닌 정확도와 지연을 초래한다.
- 기존의 모델 아키텍쳐 설계는 여러가지 기법들을 활용했지만 종합적인 검토가 부족하여 비효율적인 계산 중복이 존재하며 최선이 아닌 효율성을 낸다.
- NMS는 일대다 전략을 사용하여 실시간 달성에 방해되는 추론 속도 저하 문제가 있다.
- 우리는 모델 아키텍쳐 파이프라인과 후처리를 대상으로하여 정확도-속도의 경계를 향상 시킨다.
- 계산 중복을 줄이기 위한 가벼운 분류 헤드(lightweight classification head), 공간-채널 분리 다운샘플링(spatial-channel decoupled downsampling), 랭크-유도 블록 디자인(rank-guided block design) 등을 포함한 아키텍쳐 제안
- NMS 없는 YOLO 모델을 위해 이중 할당 전략을 제안하여 중복 예측 문제를 해결한다.
- 새로운 End-to-End 객체 감지기인 YOLOv10-N/S/M/B/L/X를 제안한다.
- 이는 기존의 SOTA 모델 들을 크게 능가하며 YOLOv8, YOLOv9, RT-DETR-R18/R101 등의 다양한 모델들과 비교하였을 때, 동일 성능 대비 적은 매개변수, 더 빠른 속도를 달성한다.
- 해당 논문에서 말하는 경계선(boundaries)은 그림1에서 보여지는 각 스케일 모델의 정확도-속도 성능 좌표가 만들어내는 라인을 말하는 것으로 보인다.
- 이를 향상 시킨다는 의미는 해당 경계를 더욱 좌상단으로 끌어올리는 것
Related Work
Real-time object detectos
실시간 객체 감지는 낮은 지연 하에 객체를 분류하고 위치를 찾는 것을 목표로 하며, 이는 실제 응용에 매우 중요합니다. 지난 몇 년 간 효율적인 감지기를 개발하기 위한 상당한 노력이 있었습니다. 특히, YOLO 시리즈가 주류로 두드러집니다. YOLOv1, YOLOv2, YOLOv3는 백본, 넥, 헤드의 세 부분으로 구성된 전형적인 감지 아키텍쳐를 식별합니다. YOLOv4와 YOLOv5는 DarkNet을 대체하기 위해 CSPNet 디자인을 도입하고 데이터 증강 전략, 향상된 PAN 및 더 다양한 모델 스케일 등을 결합하였습니다. YOLOv6는 넥과 백본에 각각 BiC와 SimCSPSPPF를 도입하고 앵커 지원 훈련(anchor-aided training)과 자기 증류(self-distillation) 전략을 사용합니다. YOLOv7은 풍부한 그라디언트 흐름 경로를 위한 E-ELAN을 도입하고 여러 학습 가능한 BOF(Bag-of-freebies) 방법을 탐구합니다. YOLOv8은 효과적인 특징 추출 및 융합을 위한 C2f 빌딩 블록을 제시합니다. Gold-YOLO는 다중 스케일 특징 융합 기능을 향상 시키기 위한 향상된 GD 메커니즘을 제안합니다. YOLOv9은 아키텍쳐를 개선하고 훈련 과정을 증강하기 위해 GELAN을 제안합니다.
End-to-end object detectos
End-to-end 객체 감지는 전통적인 파리프라인에서 벗어나 간소화된 아키텍쳐를 제공하면서 패러다임을 전환시키며 등장하였습니다. DETR은 트랜스포머 아키텍쳐를 도입하고 헝가리안 손실을 채택하여 일대일 매칭 예측을 달성하여 수작업 구성요소와 후처리를 제거합니다. 그 이후로 다양한 DETR 변형이 성능과 효율성을 향상시키기 위해 제안되었습니다. Deformable-DETR은 다중 스케일 변형이 가능한 어텐션 모듈을 활용하여 수렴 속도를 가속화 합니다. DINO는 대조 잡음 제거(contrastive denoising), 쿼리 선택 혼합(mix query selection) 및 look forward twice 설계를 DETR에 통합합니다. RT-DETR은 효율적인 하이브리드 인코더를 설계하고 정확도와 지연을 모두 개선하기 위해 최소 불확실성 쿼리 선택(uncertainty-minimal query selection)을 제안합니다. End-to-end 객체 감지를 달성하는 또 다른 방법은 CNN 감지기를 기반으로 합니다. Learnable NMS와 관계 네트워크는 탐지기에서 중복 된 예측을 제거하기 위한 또 다른 네트워크를 제안합니다. OneNet과 DeFCN은 FCN(fully convolution network)로 end-to-end 간 객체감지를 가능하게 하는 일대일 매칭 전략을 제안합니다. FCOS는 예측을 위한 최적의 샘플을 선택하기 위해 양성 샘플 선택기를 도입합니다.
- YOLO 시리즈를 기반으로 한 버전에 따른 제안의 특징들을 설명한다. YOLOv1 부터 직전 버전까지 한번 쯤 훑어 보는 것도 좋을 듯 하다.
- End-to-end 방식의 발전사를 설명하기위한 DETR의 등장부터 다양한 적용 기법, NMS를 없애거나 학습가능하도록 변형시키기 위한 선례들을 언급한다.
Methodology
Consistent Dual Assignments for NMS-free Training
훈련 중에 YOLO는 보통 TAL을 활용하여 각 인스턴스에 여러 양성 샘플을 할당합니다. 일대다 할당을 채택하면 풍부한 지도 신호가 생성되어 최적화가 용이해지고 우수한 성능을 달성할 수 있습니다. 그러나, 이는 YOLO가 NMS 후처리에 의존하게 만들어서 배포를 위한 최적 이하의 추론 효율성의 원인이 됩니다. 이전 작업들이 중복 예측을 억제하기 위해 일대일 매칭을 탐구했지만, 이는 보통 추가적인 추론 오버헤드를 도입하게 되거나 최적 이하의 성능을 제공합니다. 본 연구에서는 이중 레이블 할당(dual label assignments)과 일관된 매칭 메트릭(consistent matching metric)을 사용하여 YOLO를 위한 NMS 없는 훈련 전략을 제시하여 높은 효율성과 경쟁력 있는 성능을 동시에 달성합니다.
- 기존의 일대다 매칭은 하나의 실제 객체에 대해 여러개의 앵커 박스가 학습되는 할당으로 해석
- 이 일대다 할당은 학습하기에 용이하고 우수한 성능을 달성하지만 후처리에 대한 NMS가 단점
- 그래서 이중 레이블 할당 전략과 일관된 매칭 메트릭 전략 2가지를 사용하여 NMS를 배제한 학습 전략으로 높은 성능을 달성하는 것으로 보임
Dual label assignment detectos
일대다 할당과 달리, 일대일 매칭은 각 실제 값에 하나의 예측만 할당하여 NMS 후처리를 피합니다. 그러나 이는 약한 지도학습으로 이어져 최적 이하의 정확도와 수렴 속도를 초래합니다. 다행이도, 이 결함은 일대다 할당으로 보완될 수 있습니다. 이를 달성하기 위해, 우리는 두 전략의 장점을 결합하기 위한 YOLO에 대한 이중 레이블 할당을 도입합니다.
구체적으로, 그림 2(a)에 표시된 바와 같이, 우리는 YOLO를 위해 또 다른 일대일 헤드를 통합합니다. 이는 원래의 일대다 브랜치와 동일한 구조를 유지하고 동일한 최적화 목표를 채택하지만, 일대일 매칭을 활용하여 레이블 할당을 얻습니다. 훈련 중에는 두 헤드가 모델과 함께 공동으로 최적화되어 백본과 넥이 일대다 할당이 제공하는 풍부한 지도를 제공받을 수 있습니다. 추론 중에는 일대다 헤드를 버리고 일대일 헤드를 사용하여 예측을 수행합니다.
이것은 추가적인 추론 비용 없이 YOLO가 End-to-end 배포를 가능하게 합니다. 게다가, 일대일 매칭에서 우리는 최상위 선택(top one selection)을 채택하여 더 적은 추가 학습 시간으로 헝가리안 매칭과 동일한 성능을 달성합니다.
- 일대일 할당 헤드는 일대다 헤드에 비해 학습 시의 수렴효과 및 정확도가 떨어지는 것으로 보인다.
- 학습 시에는 일대다 헤드와 일대일 헤드를 모두 사용하여 같이 최적화 함으로써 높은 학습효과를 기대한다.
- 일대다 헤드와 일대일 헤드를 동시에 학습시키기 때문에 이중 레이블 할당이라고 칭한 것으로 보인다.
- 그리고 학습이 아닌 추론 시에는 일대일 헤드만 사용하도록 한다. 그래서 순수한 모델 아키텍쳐의 추론 시간 외에 후처리 비용이 들지 않는다.
- 일대일 매칭 시의 top one selection은 헝가리안 매칭과 동일한 성능을 달성한다고 한다.
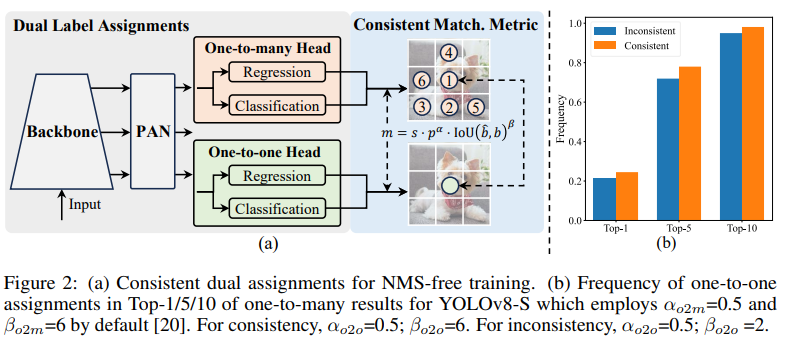
Consistent matching metric
할당 중에 일대일 및 일대다 접근법 모두 예측과 인스턴스 간의 일치 수준을 정량적으로 평가하기 위해 메트릭을 활용합니다. 두 가지 브랜치 모두를 위한 예측 인식 매칭을 달성하기 위해, 우리는 일관된 매칭 매트릭을 사용합니다. 즉,
여기서 $p$는 분류 점수이며, $\hat{b}$와 $b$는 각각 예측과 인스턴스의 바운딩 박스를 나타냅니다. $s$는 예측의 앵커 포인트가 인스턴스 내에 있는지를 나타내는 공간의 사전 정보를 나타냅니다. $\alpha$와 $\beta$는 의미 예측 작업과 위치 회귀 작업의 영향을 균형 있게 하는 두 가지 중요한 하이퍼파라미터입니다. 우리는 일대다와 일대일 메트릭을 각각 $m_{o2m}=m(\alpha_{o2m},\beta_{o2m})$와 $m_{o2o}=m(\alpha_{o2o},\beta_{o2o})$로 표시합니다. 이 메트릭은 두 헤드에 대한 레이블 할당 및 지도학습 정보에 영향을 미칩니다.
이중 레이블 할당에서 일대다 브랜치는 일대일 브랜치보다 훨씬 더 풍부한 감독 신호를 제공합니다. 직관적으로 일대일 헤드의 감독을 일대다 헤드의 감독과 조화시킬 수 있다면, 우리는 일대일 헤드를 일대다 헤드의 최적 방향으로 최적화할 수 있습니다. 결과적으로, 일대일 헤드는 추론 중에 샘플의 품질을 향상시켜 더 나은 성능을 제공합니다. 이를 위해 먼저 두 헤드 간의 감독 격차를 분석합니다. 훈련 중에 발생하는 무작위성으로 인해, 우리는 두 헤드가 동일한 값으로 초기화되고 동일한 예측을 생성하는 상황을 전제로 조사를 시작합니다. 즉, 일대일 헤드와 일대다 헤드는 각 예측-인스턴스 쌍에 대해 동일한 $p$와 IoU를 생성합니다. 우리는 두 브랜치의 회귀 타겟(regression targets)이 충돌하지 않음을 주목합니다. 매칭된 예측은 동일한 타겟을 공유하고, 매칭되지 않은 예측은 무시됩니다. 따라서 감독의 격차는 서로 다른 분류 타겟에 있습니다. 주어진 인스턴스에서, 우리는 예측과의 최대 IoU를 $u^*$로, 최대 일대다 및 일대일 매칭 점수를 각각 $m_{o2m}^*$ 및 $m_{o2o}^*$로 표시합니다. 일대다 브랜치가 양성 샘플 $\Omega$를 생성하고 일대일 브랜치가 메트릭 $m_{o2o,i}=m_{o2m}^*\cdot m_{o2o}^*$로 $i$-번째 예측을 선택한다고 가정하면, 우리는 $j\in \Omega$에 대해 분류 타겟 $t_{o2m,j}=u^*\cdot \frac{m_{o2m,j}}{m_{o2m}^*} \leq u^*$와 $t_{o2o,i}=u^*\cdot \frac{m_{o2o,i}}{m_{o2o}^*}=u^*$를 도출할 수 있습니다. 따라서 두 브랜치 간의 감독 격차는 서로 다른 분류 목표의 1-와서스타인 거리로 도출될 수 있습니다. 즉,
우리는 $t_{o2m,i}$이 증가함에 따라 격차가 감소함을 관찰할 수 있습니다. 즉, $i$가 $\Omega$가 내에서 더 높은 순위를 차지합니다. 이는 $t_{o2m,i}=u^*$일 때 최소에 도달합니다. 즉 $i$가 $\Omega$ 내에서 가장 좋은 양성 샘플인 경우, 그림 2(a)에서 보여줍니다. 이를 달성하기 위해, 우리는 일관된 매칭 메트릭을 제시합니다. 즉, $\alpha_{o2o}=r\cdot\alpha_{o2m}$ 및 $\beta_{o2o}=r’\cdot\beta_{o2m}$, 이는 $m_{o2o}=m^r_{o2m}$을 의미합니다. 따라서 일대다 헤드에 가장 좋은 양성 샘플은 일대일 헤드에도 가장 좋습니다. 결과적으로, 두 헤드는 일관되고 조화롭게 최적화될 수 있습니다. 이를 간단히 하기 위해, 우리는 기본적으로 $r=1$을 취합니다. 즉, $\alpha_{o2o}=\alpha_{o2m}$ 및 $\beta_{o2o}=\beta_{o2m}$입니다. 향상된 감독 정렬을 확인하기 위해, 우리는 훈련 후 일대다 결과의 상위 1/5/10 내에서 일대일 매칭 쌍의 수를 셉니다. 그림 2(b)에서 볼 수 있듯이, 일관된 매칭 메트릭 하에서 정렬이 개선되었습니다. 수학적 증명의 더 포괄적인 이해를 위해서는 부록을 참조하십시오.
- 메트릭에 대한 수식은 $m$으로 표현한 것으로 보인다. 예측의 앵커 포인트 포함여부에 대한 prior $s$와 클래스 분류에 대한 스코어 $p$, 예측과 실제 인스턴스의 IoU(Intersection over Union) 정보를 활용하는 것으로 보인다.
- 일대다 헤드와 일대일 헤드의 지도(supervision)의 차이를 이해하는 것이 중요한 것으로 보인다.
- 회귀 타겟이 충돌하지 않는 다는 것은 일대일 헤드와 일대 헤드의 결과가 동일했다는 것을 의미한다. 그러므로 학습 시 일어나는 차이는 회귀가 아닌 분류에 대한 부분에서 발생한다.
- 분류 타겟 $t$에 대해서 일대다와 일대일 브랜치에서 최대 IoU인 $u^*$ 에 관한 관계식을 설명하였고 감독의 격차를 $A$로 정의하였다. 수식에선 감독 격차를 감소시키기 위해서 분류 타겟 $t_{o2m,i}$ 가 증가해야 함을 알수 있다.
- 즉 감독 격차 $A$가 가장 최소화 되기 위해서, 일대다 헤드의 결과와 일대일 헤드의 최상의 결과를 매칭하기 위한 메트릭을 $\alpha_{o2o}=r\cdot\alpha_{o2m}$ 및 $\beta_{o2o}=r’\cdot\beta_{o2m}$ 으로 제시하였고 $r=1$로 적용하였으로 $\alpha_{o2o}=\alpha_{o2m}$ 및 $\beta_{o2o}=\beta_{o2m}$이 된다.즉, 일대다 헤드에 가장 좋은 양성(정답) 샘플은 일대일 헤드에도 가장 좋다고 볼 수 있게 된다.
Holistic Efficiency-Accuracy Driven Model Design
후처리 외에도 YOLO의 모델 아키텍쳐는 효율성-정확도 트레이드오프에 큰 도전을 제기합니다. 이전 연구들이 다양한 디자인 전략을 탐구했지만, YOLO의 다양한 컴포넌트에 대한 종합적인 검토는 여전히 부족합니다. 결과적으로, 모델 아키텍쳐는 무시할 수 없는 계산 중복과 제약된 능력을 보여주며, 이는 높은 효율성과 성능을 달성하기 위한 잠재력을 방해합니다. 여기서 우리는 효율성과 정확성 측면에서 YOLO에 대한 전체적인 모델 설계를 수행하는 것을 목표로 합니다.
Efficiency driven model design
(1) Lightweight classificiation head.
YOLO의 구성 요소는 스템, 다운샘플링 레이어, 기본 빌딩 블록이 있는 단계, 그리고 헤드로 구성됩니다. 스템은 계산 비용이 적게 들기 때문에 나머지 세 부분에 대해서 효율성 주도 모델 디자인을 수행합니다. YOLO에서 분류 헤드와 회귀 헤드는 보통 동일한 아키텍쳐를 공유합니다. 그러나 이들은 계산 오버헤드에서 상당한 차이를 보입니다. 예를들어, YOLOv8-S에서 분류 헤드의 FLOPs와 매게변수 수(5.95G/1.51M)는 각각 회귀 헤드 (2.34G/0.64M)의 2.5배와 2.4배입니다. 그러나 분류 오류와 회귀 오류의 영향을 분석한 후(표 6 참조), 우리는 회귀 헤드가 YOLO의 성능에 더 중요한 역할을 한다는 것을 발견했습니다. 따라서 성능에 큰 영향을 주지 않고 분류 헤드의 오버헤드를 줄일 수 있습니다. 그러므로 우리는 분류 헤드를 위해 3x3 커널 크기의 두 개의 depthwise separable convolutions 과 1x1 convolution으로 구성된 가벼운 아키텍쳐를 채택합니다.
(2) Spatial-channel decoupled downsampling.
YOLO는 일반적으로 스트라이드 2의 정규 3x3 표준 convolutions을 사용하여 공간 다운 샘플링 ($H\times W$에서 $\frac{H}{2} \times \frac{W}{2}$)과 채널 변환 ($C$에서 $2C$)을 동시에 수행합니다. 이는 $O(\frac{9}{2}HWC^2)$의 무시할 수 없는 계산 비용과 $O(18C^2)$의 매개변수 수를 도입합니다. 대신, 우리는 공간 축소와 채널 증가 작업을 분리하여 더 효율적인 다운샘플링을 가능하게 할 것을 제안합니다. 구체적으로, 우리는 먼저 채널 자원을 조정하기 위해 pointwise convolution을 활용한 다음, depthwise convolution을 사용하여 공간 다운샘플링을 수행합니다. 이는 계산 비용을 $O(2HWC^2+\frac{9}{2}HWC)$로, 매개변수 수를 $O(2C^2+18C)$로 줄입니다. 동시에 다운샘플링 동안 정보 유지력을 극대화하여 지연 시간 감소와 함께 경쟁력 있는 성능을 제공합니다.
(3) Rank-guided block design.
YOLO는 일반적으로 모든 단계에 대해 동일한 기본 빌딩 블록을 사용합니다. 예를 들어, YOLOv8의 병목 블록입니다. YOLO의 이러한 동질적인 설계를 철저히 조사하기 위해, 우리는 내재된 순위를 사용하여 각 단계의 중복성을 분석합니다. 구체적으로, 우리는 각 단계의 마지막 기본 블록에서 마지막 convolution의 수치 순위를 계산하며, 임계값보다 큰 특이값의 수를 셉니다. 그림 3.(a)는 YOLOv8의 결과를 나타내며, 깊은 단계와 큰 모델이 더 많은 중복성을 나타내는 경향이 있음을 보여줍니다. 이 관찰은 모든 단계에 동일한 블록 설계를 단순히 적용하는 것이 최고의 용량-효율성 트레이드오프에 최적이 아님을 시사합니다. 이를 해결하기 위해, 우리는 중복성이 있는 단계의 복잡성을 줄이기 위해 컴팩트 아키텍쳐 디자인을 사용하는 순위 유도 블록 디자인(rank-guided block design) 방식을 제안합니다. 우리는 먼저 그림 3.(b)에 표시된 바와 같이, 공간 혼합을 위한 저렴한 depthwise convolution과 채널 혼합을 위한 비용 효율적인 pointwise convolutions을 채택한 컴팩트 인버티드 블록(CIB) 구조를 제시합니다. 이는 ELAN 구조에 포함된 효율적인 기본 빌딩 블록으로 작용할 수 있습니다.(그림 3.(b)) 그런 다음, 우리는 경쟁력 있는 용량을 유지하면서 최고의 효율성을 달성하기 위해 순위 유도 블록 할당 전략을 제안합니다. 구체적으로, 주어진 모든 단계를 내제 순위(intrinsic rank)에 따라 오름 차순으로 정렬합니다. 우리는 리딩 스테이지에서 기본 블록을 CIB로 대체할 때의 성능 변화를 추가로 검사합니다. 주어진 모델과 비교하여 성능 저하가 없으면 다음 단계의 교체를 진행하고, 그렇지 않으면 과정을 중지합니다. 결과적으로, 우리는 성능을 저하시키지 않으면서 더 높은 효율성을 달성하기 위해 단계 및 모델 규모에 걸쳐 적응형 컴팩트 블록 디자인을 구현할 수 있습니다. 페이지 제한으로 인해, 알고리즘의 세부 사항은 부록에 제공합니다.
- 헤드 부분에서 효율성을 제고하기 위해 분류 헤드와 회귀 헤드를 검토하였고 같은 아키텍쳐 임에도 계산 오버헤드는 서로 다름을 알 수 있다. 성능에 대한 영향 분석결과 더 연산량이 작은 회귀 헤드가 YOLO의 성능에 더 중요한 역할을 한다는 것을 확인. 분류 헤드의 아키텍쳐를 변경하기로 함.
- 기존 YOLO는 다운샘플링과 채널 증가변환을 동시에하는데 이를 분리하는 것을 제안한다. 먼저 pointwise convolution 를 통해 채널을 조정하고 depthwise convolution를 통해 다운샘플링을 수행한다.
- 이는 기존 계산비용 $O(\frac{9}{2}HWC^2)$ 및 파라미터 수 $O(18C^2)$를 각각 $O(2HWC^2+\frac{9}{2}HWC)$ 와 $O(2C^2+18C)$로 감소시킨다.
- 기존 YOLO의 구조를 intrinsic rank에 따라 중복성을 검사한다. 백본과 넥이 단계에 따라 8단계까지 구분되며 스테이지의 마지막 컨볼루션에서 임계값 $\lambda_{max}/2$ 보다 큰 값의 수를 센다. 규모가 큰 모델일 수록 값이 작은 스테이지가 많으며 이 모델이 더 많은 중복성을 내포한느 것으로 보는 것으로 추정된다.
- 이러한 중복성을 해결하기 위해 rank-guided block design을 제시하고, 이에 들어가는 모듈로 CIB(compact inverted block)을 제안한다.
- 중복성의 오름차순에 따라 해당 스테이지의 기본 블록을 CIB로 교체하고 성능 변화를 추가로 검사한다. 성능 저하가 없으면 단계별로 교체하여 성능을 저하시키지 않으면서 높은 효율성을 달성한다.
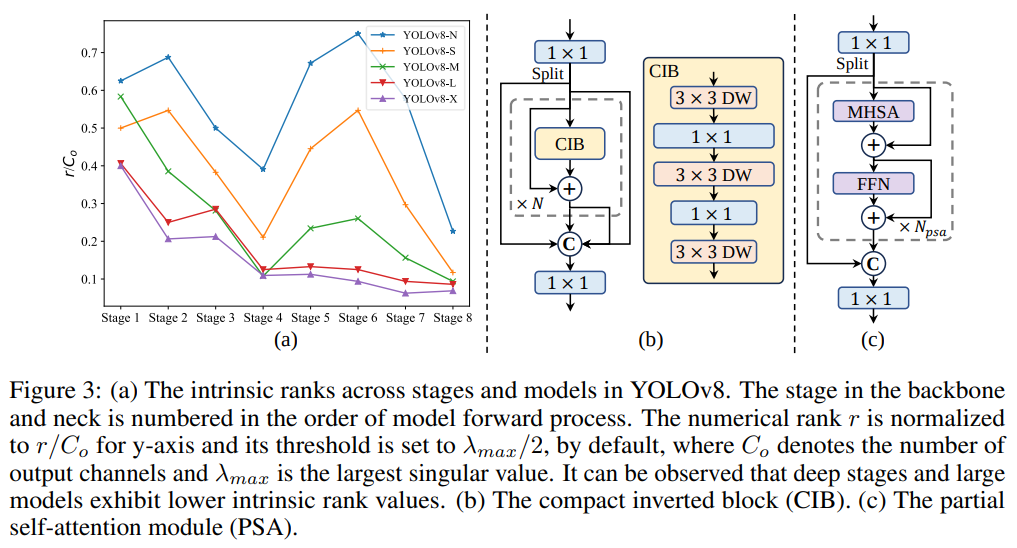
Accuracy driven model design.
우리는 최소한의 비용으로 성능을 향상시키기 위해 대형 커널 컨볼루션(large-kernel convolution)과 셀프 어텐션(self-attention)의 추가를 추가로 탐구합니다.
(1) Large-kernel convolution.
large-kernel depthwise convolution을 사용하는 것은 수용 영역을 넓히고 모델의 성능을 향상 시키는 효과적인 방법입니다. 그러나 모든 단계에서 이를 단순히 사용하는 것은 작은 개체를 탐지하기 위해 사용되는 얕은 특징에 오염(성능저하)를 가져올 수 있으며, 고해상도의 스테이지에서 상당한 I/O 오버헤드와 지연을 초래할 수 있습니다. 따라서 우리는 깊은 단계에서 CIB 내에 large-kernel depthwise convolutions을 활용할 것을 제안합니다. 구체적으로 우리는 CIB 내의 두 번째 $3\times3$ depthwise convolution의 커널 크기를 $7\times7$로 늘립니다. 추가적으로, 우리는 구조적 재파라미터화 기술을 사용하여 또 다른 $3\times3$ depthwise convolution 브랜치를 도입하여 추론 오버헤드 없이 최적화 문제를 완화합니다. 또한, 모델 크기가 증가함에 따라 수용 영역이 자연스럽게 확장되며, 대형 커널 컨볼루션의 이점이 감소합니다. 따라서 우리는 작은 모델 규모에 대해서만 large-kernel convolution을 채택합니다.
(2) Partial self-attention (PSA).
셀프 어텐션은 뛰어난 글로벌 모델링 능력 때문에 다양한 시각적 작업에 너리 사용됩니다. 그러나 이는 높은 계산 복잡도와 메모리 사용량을 보입니다. 이를 해결하기 위해, 널리 퍼져있는 어텐션 헤드의 중복성을 고려하여, 우리는 그림 3.(c)에 표시된 바와 같이 효율적인 partial self-attention(PSA) 모듈 설계를 제시합니다. 구체저으로, 우리는 $1\times1$ 컨볼루션 후에 채널 전반에 걸쳐 특징을 두 부분으로 균등하게 분할합니다. 우리는 멀티 헤드 셀프 어텐션 모듈(MHSA)과 피드 포워드 네트워크(FFN)으로 구성된 $N_{PSA}$ 블록에 한 부분만 입력합니다. 그 다음 두 부분을 연결하고 $1\times1$ 컨볼루션으로 융합합니다. 또한, 우리는 [21]을 따라 쿼리와 키의 바이어스를 MHSA의 값의 절반으로 할당하고 빠른 추론을 위해 LayerNorm을 BatchNorm으로 대체합니다. 추가적으로, PSA는 가장 낮은 해상도의 Stage 4 이후에만 배치되어 셀프 어텐션의 이차 계산 복잡도로 인한 과도한 오버헤드를 피합니다. 이렇게 하면, 글로벌 표현 학습 능력이 더 낮은 계산 비용으로 YOLO에 통합되어 모델의 능력을 향상시키고 성능을 개선합니다.
- depthwise convolution의 커널 사이즈를 늘리는 것이 성능을 향상시키는 좋은 방법이지만 작은 개체를 감지하거나 I/O 오버헤드에 악영향을 가져올 수 있으므로 깊은 스테이지에서 CIB의 컨볼루션 커널을 3*3에서 7*7로 적용하고 re-parametrization을 활용한 3*3 브랜치를 도입하여 추론 오버헤드 없이 + 수용영역 증가를 달성한다.
- 또한 컨볼루션에 대한 커널 증가는 규모가 작은 모델에만 적용한다.
- 계산 복잡도와 메모리 사용량을 효율적으로 한 부분 셀프 어텐션(PSA) 모듈을 제안하며 이를 Stage 4 이후에만 적용한다. 이는 셀프 어텐션의 글로벌 학습 능력을 YOLO에 효율적으로 녹일 수 있다.
- PSA의 위치는 1*1 컨볼루션 후에 붙이고 다시 1*1으로 융합한다.
Experiments
Implementation Details
우리는 YOLOv8을 기준 모델로 선택했는데, 이는 훌륭한 지연-정확도 균형과 다양한 모델 크기로 제공되기 때문입니다. 우리는 NMS 없는 훈련을 위해 일관된 이중 할당(consistent dual assignments)을 사용하고, 이를 기반으로 전체적인 효율성-정확성 주도 모델 설계를 수행하여 YOLOv10 모델을 제공합니다. YOLOv10은 YOLOv8과 동일한 변형 모델을 가지며 N/S/M/L/X 입니다. 또한, 우리는 YOLOv10-M의 너비 스케일 팩터를 단순히 증가시킨 새로운 변형 모델 YOLOv10-B를 도출했습니다. 우리는 동일한 기초부터 학습 설정 하에서 COCO에서 제안된 디텍터를 검증했습니다. 또한, 모든 모델의 지연 시간은 T4 GPU와 TensorRT FP16에서 테스트되었습니다.
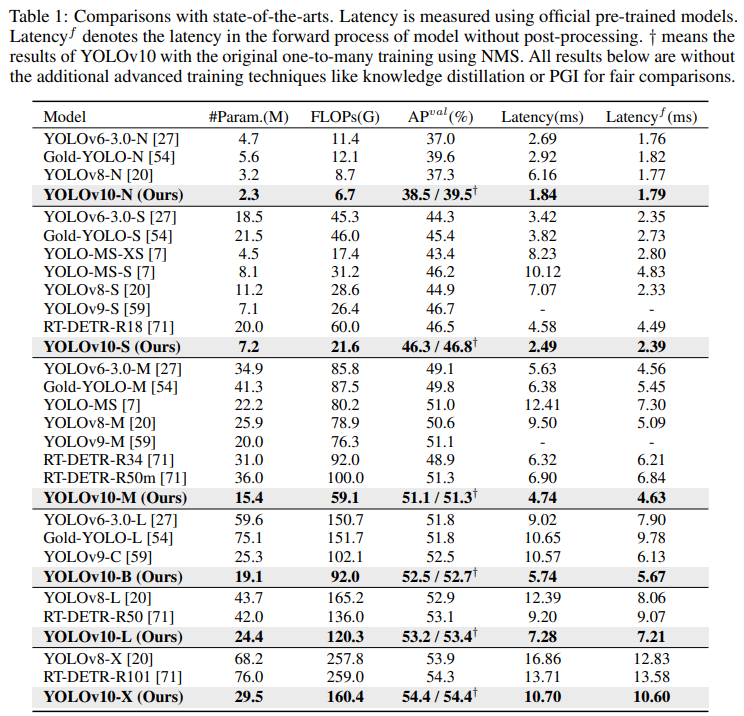
- $\text{Latency}^f$ 은 NMS 후처리 없는 지연 시간을 나타낸다.
- $\dagger$는 일대다 헤드를 사용한 YOLOv10의 결과를 나타낸다. 없는 것이 일대일 헤드의 결과.
Comparison with state-of-the-arts
표 1에 나타난 바와 같이, 우리의 YOLOv10은 다양한 모델 규모에서 최첨단 성능과 End-to-end 지연 시간을 달성합니다. 우리는 먼저 YOLOv10을 기준 모델인 YOLOv8과 비교합니다. N/S/M/L/X 다섯 변형 모델에서 우리의 YOLOv10은 각각 1.2% / 1.4% / 0.5% / 0.3% / 0.5%의 AP 향상, 28% / 36% / 41% / 44% / 57% 적은 매개변수, 70% / 65% / 50% / 41% / 37% 낮은 지연 시간을 달성합니다. 다른 YOLO와 비교할 때, YOLOv10은 또한 정확도와 계산 비용 간의 우수한 균형을 보여줍니다. 특히, 경량 및 소형 모델의 경우, YOLOv10-N/S는 YOLOv6-3.0-N/S 보다 각각 1.5 AP 및 2.0 AP 더 우수하며, 51% / 61% 적은 매개변수와 41% / 52% 적은 계산을 가집니다. 중형 모델의 경우, YOLOv9-C / YOLO-MS와 비교할 때, YOLOv10-B / M은 동일하거나 더 더 낮은 성능하에서 각각 46% / 62% 지연 시간 감소를 누립니다. 대형 모델의 경우, Gold-YOLO-L과 비교할 때, 우리의 YOLOv10-L은 68% 적은 매개변수와 32% 낮은 지연 시간을 보여주며, 1.4% AP의 상당한 향상을 이룹니다. 추가적으로, RT-DETR과 비교할 때, YOLOv10은 상당한 성능 및 지연 시간 향상을 달성합니다. 특히, YOLOv10-S/X는 유사한 성능 하에서 RT-DETR-R18/R101 보다 각각 1.8배 및 1.3배 빠른 추론 속도를 달성합니다. 이 결과물들은 YOLOv10의 실시간 종단 간 탐지기로서의 우수성을 잘 보여줍니다. 우리는 또한 원래의 일대다 훈련 방식을 사용하여 YOLOv10을 다른 YOLO와 비교합니다. 우리는 이 상황에서 모델의 포워드 프로세스의 성능과 지연 시간($\text{Latency}^f$)을 고려합니다. 표 1에 나타난 바와 같이, YOLOv10은 또한 다양한 모델 규모에서 최첨단 성능과 효율성을 보여주며, 우리의 아키텍쳐 설계의 효과를 나타냅니다.
Model Analyses
Ablation study.
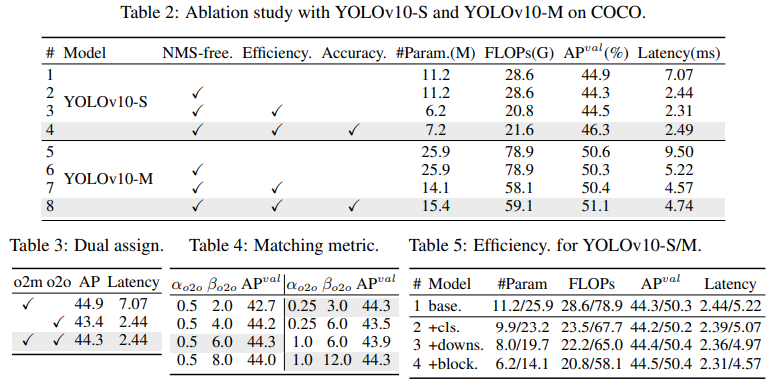
우리는 표 2에 YOLOv10-S 및 YOLOv10-M을 기반으로 한 소거 연구 결과를 제시합니다. 일관된 이중 할당을 사용한 NMS 없는 훈련이 YOLOv10-S의 End-to-end 간 지연 시간을 4.63ms 줄이면서도 44.3% AP의 경쟁력 있는 성능을 유지함을 알 수 있습니다. 또한, 우리의 효율성 주도 모델 디자인은 11.8M 매개변수와 20.8 GFLOPs로 줄이고 YOLOv10-M의 지연 시간을 0.65ms로 줄여 그 효과를 잘 보여줍니다. 또한, 우리의 정확성 주도 모델 디자인은 YOLOv10-S와 YOLOv10-M의 AP를 각각 1.8 및 0.7 증가시키며, 각각 0.18ms 및 0.17ms의 지연 오버헤드만으로 그 우수성을 잘 입증합니다.
Analyses for NMS-free training.
- Dual label assignments: 우리는 NMS 없는 YOLO를 위해 이중 레이블 할당을 제시하며, 이는 훈련 중 일대다(o2m) 브랜치의 풍부한 감독과 추론 중 일대일(o2o) 브랜치의 높은 효율성을 제공합니다. 우리는 표 2의 YOLOv8-S (#1)을 기반으로 그 이점을 검증합니다. 구체적으로 우리는 각각 o2m 브랜치만을 사용한 학습과 o2o 브랜치만을 사용한 학습의 기준을 도입합니다. 표 3에 표시된 바와 같이, 우리의 이중 레이블 할당은 최고의 AP-latency 트레이드오프를 달성합니다.
- Consistent matching metric. 우리는 일대일 헤드를 일대다 헤드와 더 조화롭게 만들기 위해 일관된 매칭 메트릭을 도입합니다. 우리는 표 2의 YOLOv8-S (#1)을 기반으로 다른 $\alpha_{o2o}$ 및 $\beta_{o2o}$ 하에서 그 이점을 검증합니다. 표 4에 표시된 바와 같이, 제안된 일관된 매칭 메트릭, 즉 $\alpha_{o2o}=r \cdot\alpha_{o2m}$ 및 $\beta_{o2o}= r’\cdot\beta_{o2m}$ 는 최적의 성능을 달성할 수 있으며, 여기서 일대다 헤드의 $\alpha_{o2m}=0.5$ 및 $\beta_{o2m}=6.0$ 입니다. 이러한 개선은 두 브랜치 간의 감독 격차 감소(Eq. (2))에 기인할 수 있으며, 이는 두 브랜치 간의 지도 정렬을 향상시킵니다. 또한, 제안된 일관된 매칭 메트릭은 철저한 하이퍼파라미터 튜닝의 필요성을 제거하여 실제 시나리오에서 매력적입니다.
Analyses for NMS-free training.
우리는 YOLOv10-S/N을 기반으로 효율성 주도 디자인 요소를 점진적으로 통합하기 위한 실험을 수행합니다. 우리의 기준 모델은 효율성-정확성 주도 모델 디자인이 있는 YOLO-v10-S/M 모델입니다. 즉, 표 2에서 #2/#6 입니다. 표 5에 나타난 바와 같이, 경량 분류 헤드, 공간-채널 분리 다운샘플링, 순위 유도 블록 디자인을 포함한 각 디자인 컴포넌트는 매개변수 수, FLOPs 및 지연 시간의 감소에 기여합니다. 중요하게도, 이러한 개선은 경쟁력 있는 성능을 유지하면서 달성됩니다.
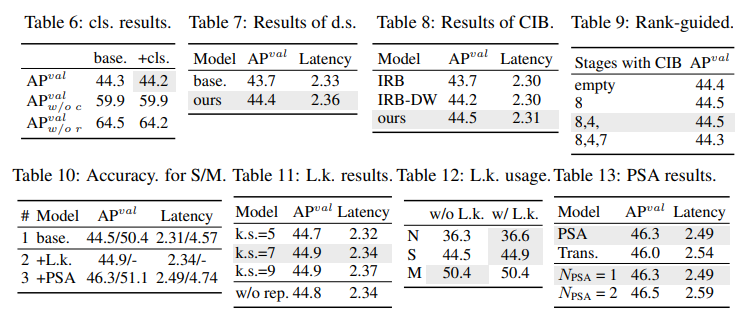
- Lightweight classification head: 우리는 [6]처럼 표5의 #1과 #2의 YOLOv10-S를 기반으로 예측의 카테고리 및 위치 오류가 성능에 미치는 영향을 분석합니다. 구체적으로, 우리는 일대일 할당에 의해 예측을 인스턴스에 맞춥니다. 그런 다음, 예측된 카테고리 점수를 인스턴스 레이블로 대체하여 분류 오류가 없는 $AP_{\omega/oc}^{val}$를 얻습니다. 유사하게, 예측된 위치를 인스턴스의 위치로 대체하여 회귀 오류가 없는 $AP_{\omega/or}^{val}$를 얻습니다. 표 6에 나타난 바와 같이, $AP_{\omega/or}^{val}$는 $AP_{\omega/oc}^{val}$보다 훨씬 높아 회귀 오류를 제거함녀서 더 큰 개선을 달성함을 보여줍니다. 따라서 성능 병목 현상은 회귀 작업에 더 많이 존재합니다. 따라서 경량 분류 헤드를 채택하면 성능을 저하시키지 않으면서 더 높은 효율성을 허용할 수 있습니다.
- Spatial-channel decoupled downsampling: 우리는 효율성을 위해 다운샘플링 작업을 분리하며, 먼저 pointwise convolution(PW)으로 채널 차원을 증가시키고, 그런 다음 depthwise convolution(DW)으로 해상도를 줄여 최대 정보 유지를 달성합니다. 우리는 표 5의 #3 YOLOv10-S를 기반으로 DW에 의한 공간 축소 후 PW에 의한 채널 변조의 기본 방식과 비교합니다. 표 7에 나타난 바와 같이, 우리의 다운샘플링 전략은 다운샘플링 동안 더 적은 정보 손실을 누리며 0.7%의 AP 향상을 달성합니다.
- Compact inverted block (CIB): 우리는 CIB를 컴팩트 기본 빌딩 블록으로 도입합니다. 우리는 표 5의 #4 YOLOv10-S를 기반으로 그 효과를 검증합니다. 구체적으로, 우리는 표 8에 나타난 바와 같이 43.7% AP의 최적 이하를 달성하는 기준으로 inverted residual block(IRB)을 도입합니다. 그런 다음, 우리는 그것에 3 x 3 depthwise convolution(DW)을 추가하여 “IRB-DW”로 표시하며, 이는 0.5% AP 향상을 가져옵니다. “IRB-DW”와 비교할 때, 우리의 CIB는 최소한의 오버헤드로 또 다른 DW를 앞에 추가하여 0.3% AP 향상을 달성하며, 이는 그 우수성을 나타냅니다.
- Rank-guided block design: 우리는 모델 효율성을 향상시키기 위해 컴팩트 블록 디자인을 적응적으로 통합하기 위해 순위 유도 블록 디자인을 도입합니다. 우리는 표 5의 #3 YOLOv10-S를 기반으로 그 이점을 검증합니다. 내재된 순위(intrinsic rank)에 따라 오름차순으로 정렬된 단계는 Stage 8-4-7-3-5-1-6-2로, 그림 3.(a)와 같습니다. 표 9에 나타난 바와 같이, 각 단계의 병목 블록을 효율적인 CIB로 점진적으로 교체할 때, 우리는 Stage 7에서 성능 저하를 관찰합니다. 따라서 내재된 순위가 낮고 중복성이 많은 Stage 8 및 4에서 우리는 성능을 저하시키지 않으면서 효율적인 블록 디자인을 채택할 수 있습니다. 이 결과들은 순위 유도 블록 디자인이 더 높은 모델 효율성을 위한 효과적인 전략으로 작용할 수 있음을 나타냅니다.
Analyses for accuracy driven model design.
우리는 YOLOv10-S/M을 기반으로 정확성 주도 디자인 요소를 점진적으로 통합한 결과를 제시합니다. 우리의 기준 모델은 효율성 주도 디자인을 통합한 후의 YOLOv10-S/M 모델입니다. 즉, 표 2의 #3/#7 입니다. 표 10에 나타난 바와 같이, large-kernel convolution과 PSA 모듈의 채택은 YOLOv10-S에 대해 각각 0.03ms 및 0.15ms의 최소 지연 시간 증가로 0.4% AP 및 1.4% AP의 상당한 성능 향상을 가져옵니다. large-kernel convolution은 YOLOv10-M에는 사용되지 않음을 유의하십시오 (표 12 참조).
- Large-kernel convolution: 우리는 먼저 표 10의 #2 YOLOv10-S를 기반으로 다른 커널 크기의 효과를 조사합니다. 표 11에 나타난 바와 같이, 성능은 커널 크기가 증가함에 따라 향상되고 7x7 커널 크기 주변에서 정체되며, 이는 큰 수용 영역의 이점을 나타냅니다. 또한, 학습 중 재파라미터화 브랜치를 제거하면 0.1% AP 저하가 발생하며, 이는 최적화에 대한 효과를 보여줍니다. 또한, 우리는 YOLOv10-N/S/M을 기반으로 모델 규모에 따른 Large-kernel convolution의 이점을 조사합니다. 표 12에 나타난 바와 같이, 이는 고유의 광범위한 수용 영역 때문에 대형 모델, 즉 YOLOv10-M에는 개선을 가져오지 않습니다. 따라서 우리는 소형 모델, 즉 YOLOv10-N/S에 대해서만 해당 방법론을 채택합니다.
-
Partial self-attention (PSA): 우리는 최소한의 비용으로 글로벌 모델링 능력을 통합하여 성능을 향상시키기 위해 PSA를 도입합니다. 우리는 먼저 표 10의 #3 YOLOv10-S를 기반으로 그 효과를 검증합니다. 구체적으로, 우리는 트랜스포머 블록, 즉 FFN 다음의 MHSA를 기준으로 도입하며, 이를 “Trans”로 표시합니다. 표 13에 나타난 바와 같이, PSA는 0.05ms의 지연 시간 감소와 함께 0.3% AP 향상을 가져옵니다. 성능 향상은 어텐션 헤드의 중복성을 완화하여 셀프 어텐션에서 최적화 문제를 경감시킨 것에 기인할 수 있습니다. 또한 우리는 다른 $N_{PSA}$의 영향을 조사합니다. 표 13에 나타난 바와 같이, $N_{PSA}$를 2로 증가시키면 0.1ms 지연 오버헤드와 함께 0.2% AP 향상을 가져옵니다. 따라서, 우리는 높은 효율성을 유지하면서 모델 능력을 향상시키기 위해 기본적으로 $N_{PSA}$를 1로 설정합니다.
- Section 4. Experiments의 내용은 YOLOv10의 성능을 주로 S 스케일 모듈을 기준으로 비교군 모델 및 소거연구에 대한 효과를 확인한 결과로서 따로 해석 코멘트를 달지 않는다.
Conclusion
이 논문에서 우리는 YOLO의 탐지 파이프라인 전반에 걸쳐 후처리와 모델 아키텍쳐를 모두 타겟으로 합니다. 후처리에 대해 우리는 NMS 없는 훈련을 위한 일관된 이중 할당을 제안하여 효율적인 종단 간 탐지를 달성합니다. 모델 아키텍쳐에 대해 우리는 성능-효율성 트레이드오프를 개선하는 전체적인 효율성-정확성 주도 모델 설계 디자인을 도입합니다. 이는 새로운 실시간 종단 간 객체 감지기인 YOLOv10을 제공합니다. 광범위한 실험은 YOLOv10이 다른 고급 감지기와 비교하여 최첨단 성능과 지연 시간을 달성하여 그 우수성을 잘 입증함을 보여줍니다.
- 해당 논문에서 보여준 개선 요소들은 양이 그리 방대하진 않다. NMS 후처리를 없애기 위한 경량 분류 헤드, 공간-채널 분리 다운샘플링, CIB를 활용한 순위 유도 블록 디자인 정도를 이해하면 되고, 정확도와 지연의 트레이드오프 효율을 고려한 모델 설계 측면에서 CIB 내의 Large-kernel convolution 및 PSA 도입을 이해하면 될 것 같다.
- 놀라운 것은 각 요소들의 성능 입증을 위해 여타 봐온 논문들 보다 비교 실험을 많이 한 것 같다. 각 요소 하나하나의 효율성을 입증하기 위해 당연히 필요한 것이겠지만 테이블이 많은 만큼 각 요소의 영향을 명확하게 분석해놓은 것에 연구자들의 노력을 느낀다.
해당 논문의 부록(Appendix)에는 많은 내용이 있다.
- 학습 시 파라미터 디테일
- 일관된 매칭 메트릭의 수식의 유도
- 순위-유도 블록 디자인의 알고리즘 세부 사항
- COCO에서의 YOLOv10의 자세한 성능: mAP0.5, 0.75뿐 아니라 다양한 스케일에 걸친 - 표 15
- 전체적 효율성-정확성 주도 모델 설계에 대한 추가적 분석
- 시각화 결과
- 핵심 기여
- 한계 사항
더욱 관심이 있는 사람들은 부록의 내용도 한번 읽어보기를 권고하며 한계 사항 정도에 대한 정리로 포스팅의 마무리를 한다.
- Object365와 같은 대규모 데이터셋 에대한 학습을 진행하진 않았다.
- 또한 NMS가 없는 모델에 대한 성능은 여전히 일대다 학습에 비해 어느정도 낮은 방향의 격차가 있을 수 있다. 특히 YOLOv10-N/S와 같은 작은 모델에서 보인다.
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding YOLOv10: Real-Time End-to-End Object Detection

댓글남기기