

개요
YOLOv4: Optimal Speed and Accuracy of Object Detection 의 얕은 리뷰 포스팅. YOLOv1, YOLOv2, YOLOv3에 이은 4번째 버전까지 계속해서 읽고 있습니다. 포스팅 하단의 번역은 gpt-4o를 사용하였고 포스팅 중간의 본인의 얕은 이해를 언급합니다.
Introduction
CNN 기반의 객체감지 모델을 뜯어서 설명할 때 입력 이미지의 특징 추출을 위한 Backbone(feature extractor), Neck(멀티 스케일 간의 특징 연결), Head(디텍팅 결과를 도출하기 위한 연산) 구조를 명확히 구분지어 제시하였다. 해당 개념은 최신의 모델까지도 사용하는 개념이기에 이 당시 잘 정리 한 것 같다.
Related Work
BoF(Bag of freebies)
딥러닝 모델을 학습/추론으로 나누어 고려할 때, 추론 단계의 비용은 증가시키지 않으면서 학습 단계에서 개선을 접근하는 방법. 일반적으로 이미지의 밝기, 대비, 색조, 채도 및 노이즈를 조정하는 데이터 증강으로 이해한다. 또한 데이터 셋의 분포의 bias를 다루기 위해 학습 시 focal loss를 사용하는 방법도 있다. 그리고 다른 loss에 대해서 다양한 IoU 기반 방법도 있다(GIoU, DIoU, CIoU).
이러한 BoF에 속하는 다양한 기법들은 학습 시 적용한다는 특징이 있다.
BoS(Bag of specials)
해당 방법은 위에 언급한 BoF와 다르게 모듈에 추가되거나 추론 시에 추가되어 추론의 비용을 약간 증가시켜서 객체감지의 성능을 올리는 방법론을 의미한다.
우선 모델 아키텍쳐의 수용영역(receptive field)의 확장을 위해 SPP, ASPP, RFB 같은 기법들로 백본의 다양한 커널 사이즈로부터 이미지 특징을 추출하여 성능을 향상 시킨다.
어텐션 모듈 활용 방법으로는 SE(Squeeze-and-Excitation)과 SAM(Spatial Attention Module)을 언급한다. 이 두 모듈은 백본의 성능을 향상 시키고 모듈의 계산량을 약간 늘린다.
멀티 스케일 피쳐를 다루기 위한 방법으로 FPN 등의 다양한 특징 피라미드를 사용하는 모듈을 언급한다. 경량에 초점을 맞추며 SFAM, ASFF, BiFPN등을 언급하여 멀티 스케일의 특징 맵을 결합하는 기술을 언급한다.
또한 활성화 함수에 관한 것으로 tanh, sigmoid, ReLU, LReLU, PReLU, ReLU6, SELU, Swish, hard-Swish, Mish 등의 방법을 언급한다. 이 중 Swish와 Mish는 미분가능한 활성화 함수라는 특징을 가진다.
마지막으로 후처리에 사용되는 NMS에 대해 greedy NMS, soft NMS, DIoU NMS 등의 다양한 개선된 방법들을 언급한다.
Method
Architecture
새로 제안할 YOLOv4의 백본을 결정하기 위해 기본적으로 세가지. CSPResNeXt50 / CSPDarknet53 / EfficientNet-B3를 비교하여 표1에 표시한다. 여기서 객체감지를 수행하기 위해 중점적으로 보는 것은 컨볼루션 레이어의 개수, 파라미터의 수, 수용영역 크기 이다. 결과적으로 CSPDarkNet53을 채택한다.
그리고 YOLOv4의 아키텍쳐를 다음과 같이 간단히 정의한다.
YOLOv4 = CSPDarknet53 백본 + SPP 모듈 + PANet path-aggregation neck + YOLOv3의 앵커기반 헤드
BoF, BoS
이와 학습 및 추론을 위해 사용한 방법론은 다음과 같다. 방법론은 백본을 위한 것과 객체 감지를 위한 것으로 나뉜다.
- 백본 (BoF): CutMix와 Mosaic 데이터 증강, DropBlock 정규화, 클래스 레이블 스무딩
- 백본 (BoS): Mish 활성화, 교차 단계 부분 연결 (CSP), 다중 입력 가중 잔여 연결 (MiWRC)
- 객체 감지 (BoF): CIoU-손실, CmBN, DropBlock 정규화, Mosaic 데이터 증강, 자기 대립 훈련, 그리드 감도 제거, 단일 실제값에 대한 다중 앵커 사용, 코사인 에닐링 스케줄러, 최적의 하이퍼 파라미터, 무작위 훈련 형태
- 객체 감지 (BoS): Mish 활성화, SPP-블록, SAM-블록, PAN 경로 집계 블록, DIoU-NMS
이제 YOLOv3까지 와는 다르게 활성화 함수를 Mish를 사용한다. 그 외에도 다양한 성능 향상을 위한 방법론이 도입된다.
실험 및 결론
섹션 4에는 위와 같은 방법론들의 효과를 입증하기 위한 방대한 실험에 대한 내용이 적혀있다. 제안한 방법론이 한두개가 아니어서 이에 대한 ablation study도 엄청 많고 심지어 GPU도 NVIDIA의 3개의 세대를 거쳐 실시간 사용성을 테스트 하였다. 이 때가 NVIDIA의 급격한 기술의 발전의 시대여서 GEFROCE 게이밍 그래픽 카드만 가지고도 딥러닝 학습에 활용하고 CUDA 라이브러리를 사용자 친화적으로 쉽게 다뤘던 시기로 기억한다.
그래서 결론적으로 YOLOv4는 객체 감지 모델의 하드웨어 장벽을 낮추는 데에도 기여하고 한창 발전의 시기에 ‘성능의 향상을 위해 이것까지 해봤다’의 좋은 표본이 아닐까 생각된다.
번역
Abstract
많은 특징들이 다수 존재하며, 이들은 컨볼루션 신경망(CNN) 정확도를 향상시키는 것으로 알려져 있습니다. 이러한 특징들의 조합을 대규모 데이터셋에서 실제로 테스트하고, 그 결과에 대한 이론적 정당화를 수행할 필요가 있습니다. 일부 특징들은 특정 모델과 문제에만 독점적으로 작동하거나 소규모 데이터셋에만 적용되지만, 배치 정규화(batch-normalization)와 잔여 연결(residual-connections) 같은 특징들은 대부분의 모델, 작업 및 데이터셋에 적용 가능합니다. 우리는 이러한 보편적인 특징들이 가중 잔여 연결(Weighted-Residual-Connections, WRC), 교차 단계 부분 연결(Cross-Stage-Partial-connections, CSP), 교차 미니 배치 정규화(Cross mini-Batch Normalization, CmBN), 자기 대립 훈련(Self-adversarial-training, SAT) 및 미시 활성화(Mish-activation)를 포함한다고 가정합니다. 우리는 새로운 특징들(WRC, CSP, CmBN, SAT, Mish 활성화, 모자이크 데이터 증강, CmBN, DropBlock 정규화 및 CIoU 손실)을 사용하며, 이들 중 일부를 결합하여 최첨단 결과를 달성했습니다: MS COCO 데이터셋에서 43.5% AP(65.7% AP_50)를 Tesla V100에서 실시간 속도 약 65 FPS로 기록했습니다. 소스 코드는 https://github.com/AlexeyAB/darknet에 있습니다.
1. Introduction
대부분의 CNN 기반 객체 탐지기는 주로 추천 시스템에만 적용됩니다. 예를 들어, 도시 비디오 카메라를 통해 빈 주차 공간을 검색하는 것은 느리지만 정확한 모델에 의해 실행되는 반면, 자동차 충돌 경고는 빠르지만 부정확한 모델과 관련이 있습니다. 실시간 객체 탐지기의 정확성을 향상시키면 추천 시스템을 위한 힌트를 생성하는 것뿐만 아니라 독립형 프로세스 관리 및 인간 입력 감소에도 사용할 수 있습니다. 일반 GPU에서 실시간 객체 탐지기를 운영하면 저렴한 가격으로 대량 사용이 가능합니다. 가장 정확한 현대 신경망은 실시간으로 작동하지 않으며, 대규모 미니 배치 크기로 훈련하기 위해 많은 GPU를 필요로 합니다. 우리는 기존 GPU에서 실시간으로 작동하고 훈련에 단 하나의 기존 GPU만 필요한 CNN을 통해 이러한 문제를 해결합니다.
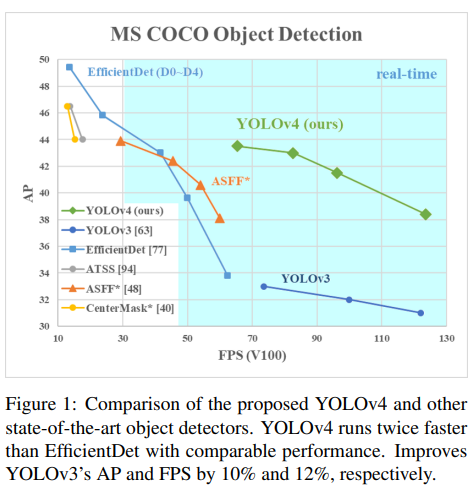
그림 1은 제안된 YOLOv4와 다른 최첨단 객체 탐지기들의 비교를 보여줍니다. YOLOv4는 유사한 성능을 유지하면서 EfficientDet보다 두 배 빠르게 실행됩니다. 또한 YOLOv3의 AP와 FPS를 각각 10% 및 12% 향상시킵니다.
이 작업의 주요 목표는 저연산량 이론적 지표(BFLOP)가 아닌 생산 시스템에서 객체 탐지기의 빠른 운영 속도를 설계하고 병렬 계산을 최적화하는 것입니다. 우리는 설계된 객체가 쉽게 훈련되고 사용되기를 바랍니다. 예를 들어, 일반 GPU를 사용하여 훈련하고 테스트하는 사람이라면 누구나 그림 1에 표시된 YOLOv4 결과와 같이 실시간, 고품질 및 신뢰성 있는 객체 탐지 결과를 달성할 수 있습니다. 우리의 기여는 다음과 같이 요약됩니다:
- 우리는 효율적이고 강력한 객체 탐지 모델을 개발합니다. 이를 통해 누구나 1080 Ti 또는 2080 Ti GPU를 사용하여 매우 빠르고 정확한 객체 탐지기를 훈련할 수 있습니다.
- 우리는 객체 탐지기의 훈련 과정에서 최신 Bag-of-Freebies 및 Bag-of-Specials 방법의 영향을 검증합니다.
- 우리는 최신 방법을 수정하여 CBN, PAN, SAM 등을 포함한 단일 GPU 훈련에 더 효율적이고 적합하게 만듭니다.
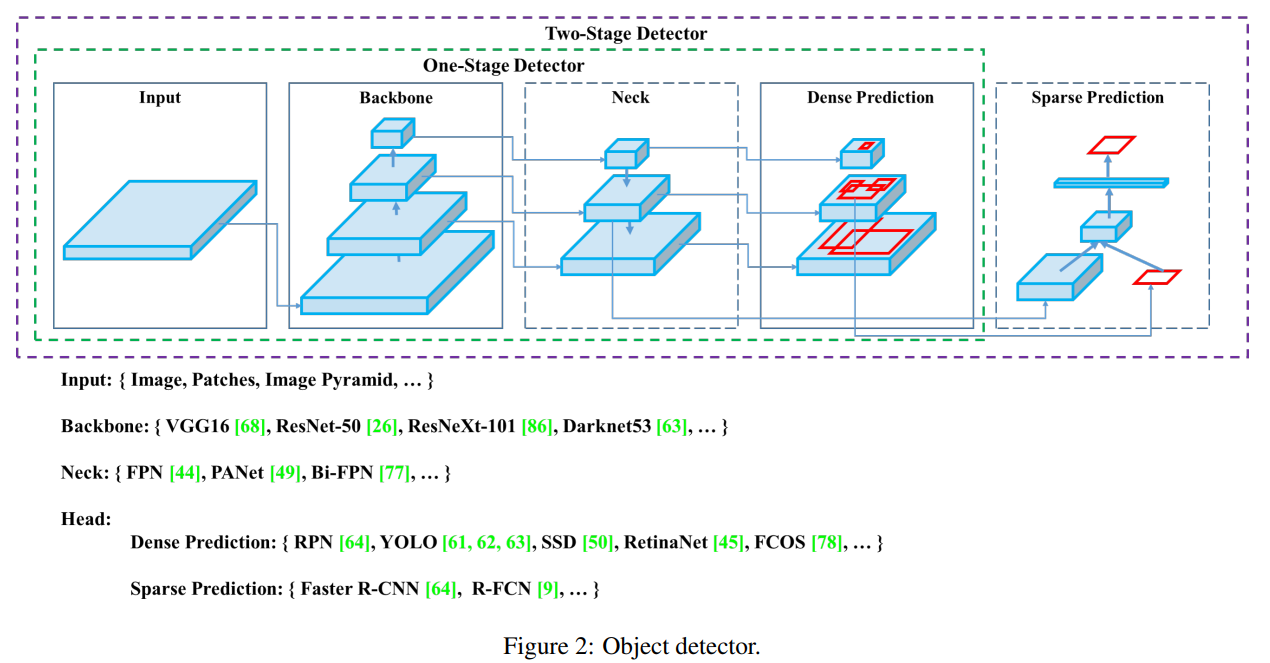
2. Related work
2.1. Object detection models
현대 탐지기는 보통 두 부분으로 구성됩니다. ImageNet에서 사전 훈련된 백본과 객체의 클래스와 경계 상자를 예측하는 데 사용되는 헤드입니다. GPU 플랫폼에서 실행되는 탐지기의 경우 백본은 VGG, ResNet, ResNeXt, 또는 DenseNet일 수 있습니다. CPU 플랫폼에서 실행되는 탐지기의 경우 백본은 SqueezeNet, MobileNet, 또는 ShuffleNet일 수 있습니다. 헤드 부분은 일반적으로 단일 단계 객체 탐지기와 두 단계 객체 탐지기로 분류됩니다. 가장 대표적인 두 단계 객체 탐지기는 R-CNN 시리즈로, fast R-CNN, faster R-CNN, R-FCN, Libra R-CNN을 포함합니다. 두 단계 객체 탐지기를 앵커 없는 객체 탐지기로 만드는 것도 가능합니다. 예를 들어 RepPoints 같은 경우입니다. 단일 단계 객체 탐지기의 가장 대표적인 모델은 YOLO, SSD, RetinaNet입니다. 최근 몇 년간 앵커 없는 단일 단계 객체 탐지기가 개발되었습니다. 이 유형의 탐지기로는 CenterNet, CornerNet, FCOS 등이 있습니다. 최근 개발된 객체 탐지기는 백본과 헤드 사이에 몇 개의 레이어를 삽입하는데, 이 레이어들은 일반적으로 다양한 단계에서 특징 맵을 수집하는 데 사용됩니다. 이를 객체 탐지기의 목(neck)이라고 부를 수 있습니다. 보통 목은 여러 개의 상향 경로와 하향 경로로 구성됩니다. 이 메커니즘을 갖춘 네트워크에는 특징 피라미드 네트워크(FPN), 경로 집계 네트워크(PAN), BiFPN, NAS-FPN이 포함됩니다.
위의 모델 외에도, 일부 연구자들은 새로운 백본(DetNet, DetNAS) 또는 새로운 전체 모델(SpineNet, HitDetector)을 직접 구축하는 데 중점을 두고 있습니다.
요약하자면, 일반적인 객체 탐지기는 여러 부분으로 구성됩니다:
- 입력(Input): 이미지, 패치, 이미지 피라미드
- 백본(Backbone): VGG16, ResNet-50, SpineNet, EfficientNet-B0/B7, CSPResNeXt50, CSPDarknet53
- 목(Neck)
- 추가 블록: SPP, ASPP, RFB, SAM
- 경로 집계 블록: FPN, PAN, NAS-FPN, 완전 연결 FPN, BiFPN, ASFF, SFAM
- 헤드(Head)
- 밀집 예측 (단일 단계):
- RPN, SSD, YOLO, RetinaNet (anchor based)
- CornerNet, CenterNet, MatrixNet, FCOS (anchor free)
- 희소 예측 (두 단계):
- Faster R-CNN, R-FCN, Mask R-CNN (anchor based)
- RepPoints (anchor free)
- 밀집 예측 (단일 단계):
2.2. Bag of freebies
보통 기존 객체 탐지기는 오프라인으로 훈련됩니다. 따라서 연구자들은 이점을 활용하여 추론 비용을 증가시키지 않으면서 객체 탐지기의 정확도를 높일 수 있는 더 나은 훈련 방법을 개발하고자 합니다. 우리는 이러한 방법들을 훈련 전략만 변경하거나 훈련 비용만 증가시키는 방법을 “bag of freebies”라고 부릅니다. 객체 탐지 방법에서 자주 채택되고 bag of freebies의 정의에 부합하는 것은 데이터 증강입니다. 데이터 증강의 목적은 입력 이미지의 다양성을 증가시켜 설계된 객체 탐지 모델이 다양한 환경에서 얻은 이미지에 대해 더 높은 견고성을 가지도록 하는 것입니다. 예를 들어, 광학 왜곡 및 기하학적 왜곡은 두 가지 일반적으로 사용되는 데이터 증강 방법이며, 이들은 객체 탐지 작업에 확실히 도움이 됩니다. 광학 왜곡을 다룰 때, 우리는 이미지의 밝기, 대비, 색조, 채도 및 노이즈를 조정합니다. 기하학적 왜곡의 경우, 우리는 무작위로 크기 조정, 자르기, 뒤집기 및 회전을 추가합니다.
위에서 언급한 데이터 증강 방법은 모두 픽셀 단위 조정이며, 조정된 영역의 모든 원래 픽셀 정보가 유지됩니다. 추가적으로, 데이터 증강에 참여한 일부 연구자들은 객체 가림 문제를 시뮬레이션하는 것에 중점을 두었습니다. 이들은 이미지 분류 및 객체 탐지에서 좋은 결과를 얻었습니다. 예를 들어, 랜덤 지우기 및 CutOut은 이미지에서 직사각형 영역을 무작위로 선택하고 무작위 값 또는 0의 보완 값으로 채울 수 있습니다. hide-and-seek 및 그리드 마스크의 경우, 이들은 이미지에서 여러 직사각형 영역을 무작위로 또는 균등하게 선택하고 이를 모두 0으로 대체합니다. 유사한 개념이 특징 맵에 적용된다면 DropOut, DropConnect 및 DropBlock 방법이 있습니다. 추가적으로, 일부 연구자들은 여러 이미지를 함께 사용하여 데이터 증강을 수행하는 방법을 제안했습니다. 예를 들어, MixUp은 두 이미지를 서로 다른 계수 비율로 곱하고 중첩한 후, 이러한 중첩된 비율로 레이블을 조정합니다. CutMix의 경우, 잘린 이미지를 다른 이미지의 직사각형 영역에 덮어씌우고, 혼합 영역의 크기에 따라 레이블을 조정합니다. 위에서 언급한 방법 외에도, 스타일 전송 GAN은 데이터 증강에 사용되며, 이러한 사용은 CNN이 학습한 텍스처 바이어스를 효과적으로 줄일 수 있습니다.
위에서 제안된 다양한 접근 방식과는 달리, 다른 bag of freebies 방법들은 데이터셋의 의미 분포에 편향이 있을 수 있는 문제를 해결하는 데 중점을 둡니다. 의미 분포 편향 문제를 다룰 때, 매우 중요한 문제는 서로 다른 클래스 간의 데이터 불균형 문제입니다. 이 문제는 종종 하드 네거티브 예제 마이닝 또는 온라인 하드 예제 마이닝을 통해 해결됩니다. 하지만 예제 마이닝 방법은 단일 단계 객체 탐지기에는 적용할 수 없습니다. 왜냐하면 이 유형의 탐지기는 밀집 예측 구조에 속하기 때문입니다. 따라서 Lin 등은 다양한 클래스 간의 데이터 불균형 문제를 해결하기 위해 focal loss를 제안했습니다. 또 다른 매우 중요한 문제는 서로 다른 카테고리 간의 연관 정도를 one-hot 하드 표현으로 나타내기가 어렵다는 것입니다. 이 표현 방식은 레이블링을 수행할 때 자주 사용됩니다. 제안된 레이블 스무딩은 하드 레이블을 소프트 레이블로 변환하여 훈련에 사용하는 것으로, 모델을 더 견고하게 만들 수 있습니다. 더 나은 소프트 레이블을 얻기 위해, Islam 등은 지식 증류 개념을 도입하여 레이블 정제 네트워크를 설계했습니다.
마지막 bag of freebies는 경계 상자(Bounding Box, BBox) 회귀의 목적 함수입니다. 전통적인 객체 탐지기는 일반적으로 평균 제곱 오차(MSE)를 사용하여 BBox의 중심 좌표와 높이 및 너비, 즉 {$x_{center}, y_{center}, w, h$} 또는 좌측 상돤과 우측 하단 좌표, 즉 {$x_{topleft}, y_{topleft}, x_{bottomright}, y_{bottomright}$}에 대해 직접 회귀를 수행합니다. 앵커 기반 방법의 경우, 해당 오프셋을 추정합니다. 예를 들어 {$x_{centeroffset}, y_{centeroffset}, w_{offset}, h_{offset}$} 및 {$x_{topleftoffset}, y_{topleftoffset}, x_{bottomrightoffset}, y_{bottomrightoffset}$}와 같이 추정합니다. 그러나 각 BBox 점의 좌표 값을 직접 추정하는 것은 이러한 점들을 독립 변수로 취급하는 것이며, 실제로 객체 자체의 완전성을 고려하지 않습니다. 이 문제를 더 잘 처리하기 위해 일부 연구자들은 최근 IoU 손실을 제안했는데, 이는 예측된 BBox 영역과 실제 BBox 영역의 커버리지를 고려합니다. IoU 손실 계산 과정은 실제값과 IoU를 수행하여 BBox의 네 좌표 점을 계산한 다음 생성된 결과를 전체 코드에 연결합니다. IoU는 스케일 불변 표현이므로, 전통적인 방법이 $x,y,w,h$ 의 $l_1$ 또는 $l_2$ 손실을 계산할 때 발생하는 문제를 해결할 수 있습니다. 최근 일부 연구자들은 IoU 손실을 계속 개선하고 있습니다. 예를 들어, GIoU 손실은 커버리지 영역 외에도 객체의 형태와 방향을 포함하는 것입니다. 그들은 예측된 BBox와 실제 BBox를 동시에 커버할 수 있는 가장 작은 영역의 BBox를 찾아 이 BBox를 분모로 사용하여 원래 IoU 손실에 사용된 분모를 대체할 것을 제안했습니다. DIoU 손실의 경우, 객체의 중심 거리도 추가로 고려하며, CIoU 손실은 겹치는 영역, 중심점 간의 거리, 그리고 종횡비를 동시에 고려합니다. CIoU는 BBox 회귀 문제에서 더 나은 수렴 속도와 정확성을 달성할 수 있습니다.
2.3. Bag of specials
플러그인 모듈과 사후 처리 방법 중 추론 비용을 약간만 증가시키면서 객체 탐지 정확도를 크게 향상시킬 수 있는 방법들을 “bag of specials”라고 부릅니다. 일반적으로 이러한 플러그인 모듈은 수용 영역을 확장하거나 주의 메커니즘을 도입하거나 특징 통합 기능을 강화하는 등의 모델의 특정 속성을 향상시키기 위한 것입니다. 사후 처리는 모델 예측 결과를 선별하는 방법입니다.
수용 영역을 확장하기 위해 사용할 수 있는 일반적인 모듈은 SPP, ASPP 및 RFB입니다. SPP 모듈은 Spatial Pyramid Matching (SPM)에서 유래되었으며, SPM의 원래 방법은 특징 맵을 여러 $d×d$ 동일한 블록으로 나누는 것이었습니다. 여기서 $d$는 {$1,2,3,…$} 일 수 있으며, 따라서 공간 피라미드를 형성한 후 bag-of-word 특징을 추출합니다. SPP는 SPM을 CNN에 통합하고 bag-of-word 작업 대신 max-pooling 작업을 사용합니다. He 등에서 제안한 SPP 모듈은 1차원 특징 벡터를 출력하므로 Fully Convolutional Network (FCN)에는 적용할 수 없습니다. 따라서 YOLOv3의 설계에서 Redmon과 Farhadi는 SPP 모듈을 커널 크기
$k×k, k={1,5,9,13}$, 스트라이드 1의 max-pooling 출력과 연결되도록 개선했습니다. 이 설계에서 상대적으로 큰 $k×k$ max-pooling은 백본 특징의 수용 영역을 효과적으로 증가시킵니다. 개선된 SPP 모듈을 추가한 후, YOLOv3-608은 MS COCO 객체 탐지 작업에서 $AP_{50}$ 를 2.7% 향상시키며, 0.5%의 추가 계산 비용이 듭니다. ASPP 모듈과 개선된 SPP 모듈 간의 작동 차이점은 주로 원래의 $k×k$ 커널 크기, 스트라이드 1의 max-pooling에서 여러 $3×3$ 커널 크기, $k$ 와 동일한 확장 비율 및 스트라이드 1의 확장된 합성곱 작업으로 전환된 것입니다. RFB 모듈은 $k×k$ 커널의 여러 확장된 합성곱을 사용하며, 확장 비율은 $k$ 와 같고 스트라이드는 1입니다. 이를 통해 ASPP보다 더 포괄적인 공간 커버리지를 얻을 수 있습니다. RFB는 MS COCO에서 SSD의 $AP_{50}$ 를 5.7% 증가시키기 위해 7%의 추가 추론 시간을 소요합니다.
객체 탐지에 자주 사용되는 어텐션 모듈은 주로 채널별 어텐션과 포인트별 어텐션으로 나뉘며, 이 두 가지 주의 모델의 대표적인 예는 각각 Squeeze-and-Excitation (SE)와 Spatial Attention Module (SAM)입니다. SE 모듈은 ImageNet 이미지 분류 작업에서 ResNet50의 성능을 1% top-1 정확도로 향상시킬 수 있지만, 계산량을 2%만 증가시킵니다. 그러나 GPU에서는 일반적으로 추론 시간을 약 10% 증가시키므로 모바일 장치에서 사용하는 것이 더 적합합니다. 하지만 SAM의 경우 0.1%의 추가 계산만 필요하며 ImageNet 이미지 분류 작업에서 ResNet50-SE의 top-1 정확도를 0.5% 향상시킬 수 있습니다. 가장 좋은 점은 GPU에서의 추론 속도에 전혀 영향을 미치지 않는다는 것입니다.
특징 통합 측면에서, 초기 방법은 스킵 연결 또는 하이퍼 컬럼을 사용하여 저수준 물리적 특징을 고수준 의미적 특징에 통합하는 것이었습니다. FPN과 같은 다중 스케일 예측 방법이 인기를 끌면서, 다양한 특징 피라미드를 통합하는 여러 경량 모듈이 제안되었습니다. 이러한 종류의 모듈에는 SFAM, ASFF, BiFPN이 포함됩니다. SFAM의 주요 아이디어는 SE 모듈을 사용하여 다중 스케일 연결 특징 맵에서 채널별 레벨 재가중치를 수행하는 것입니다. ASFF의 경우, 소프트맥스를 사용하여 포인트별 레벨 재가중치를 수행한 후 다양한 스케일의 특징 맵을 추가합니다. BiFPN에서는 다중 입력 가중 잔여 연결을 사용하여 스케일별 레벨 재가중치를 수행한 후, 다양한 스케일의 특징 맵을 추가합니다.
딥러닝 연구에서는 좋은 활성화 함수를 찾는 데 집중하는 사람들이 있습니다. 좋은 활성화 함수는 그래디언트를 더 효율적으로 전파할 수 있게 하며, 동시에 추가적인 계산 비용을 많이 초래하지 않습니다. 2010년, Nair와 Hinton은 전통적인 tanh와 sigmoid 활성화 함수에서 자주 발생하는 그래디언트 소실 문제를 실질적으로 해결하기 위해 ReLU를 제안했습니다. 이후 LReLU, PReLU, ReLU6, Scaled Exponential Linear Unit (SELU), Swish, hard-Swish, Mish 등도 그래디언트 소실 문제를 해결하기 위해 제안되었습니다. LReLU와 PReLU의 주요 목적은 출력이 0보다 작을 때 ReLU의 그래디언트가 0이 되는 문제를 해결하는 것입니다. ReLU6와 hard-Swish의 경우, 양자화 네트워크를 위해 특별히 설계되었습니다. 신경망을 자체 정규화하기 위해 SELU 활성화 함수가 제안되었습니다. Swish와 Mish는 모두 연속적으로 미분 가능한 활성화 함수라는 점에 주목해야 합니다.
딥러닝 기반 객체 탐지에서 일반적으로 사용되는 후처리 방법은 NMS로, 동일한 객체를 부정확하게 예측한 BBox를 필터링하고 응답이 높은 후보 BBox만 유지할 수 있습니다. NMS가 개선하려고 하는 방식은 목적 함수를 최적화하는 방법과 일치합니다. NMS가 제안한 원래 방법은 컨텍스트 정보를 고려하지 않기 때문에 Girshick 등은 R-CNN에 분류 신뢰도 점수를 추가하여 참조로 사용하고, 신뢰도 점수 순서에 따라 고득점에서 저득점 순으로 탐욕적 NMS를 수행했습니다. 소프트 NMS의 경우, 객체의 폐색이 IoU 점수와 함께 탐욕적 NMS에서 신뢰도 점수의 저하를 초래할 수 있는 문제를 고려합니다. DIoU NMS 개발자의 사고 방식은 소프트 NMS를 기반으로 중심점 거리 정보를 BBox 선별 과정에 추가하는 것입니다. 주목할 점은, 위에서 언급한 후처리 방법 중 어느 것도 캡처된 이미지 특징을 직접 참조하지 않기 때문에, 후속 앵커 없는 방법 개발에서는 후처리가 더 이상 필요하지 않다는 것입니다.
3. Methodology
기본 목표는 저연산량 이론적 지표(BFLOP)보다는 생산 시스템에서의 신경망의 빠른 작동 속도와 병렬 계산 최적화입니다. 우리는 실시간 신경망의 두 가지 옵션을 제시합니다:
- GPU의 경우, 우리는 컨볼루션 레이어에서 소수의 그룹(1-8)을 사용합니다: CSPResNeXt50 / CSPDarknet53
- VPU의 경우, 우리는 그룹드-컨볼루션을 사용하지만 Squeeze-and-excitement(SE) 블록의 사용은 피합니다 - 구체적으로 다음 모델들이 포함됩니다: EfficientNet-lite / MixNet / GhostNet / MobileNetV3

이미지 분류를 위한 신경망의 매개변수.
3.1. Selection of architecture
우리의 목표는 입력 네트워크 해상도, 컨볼루션 레이어 수, 매개변수 수 $(\text{filter_size}^2 \times \text{filters} \times \text{channel} / \text{groups})$, 그리고 레이어 출력 수 (필터) 사이에서 최적의 균형을 찾는 것입니다. 예를 들어, 우리의 수많은 연구들은 ILSVRC2012 (ImageNet) 데이터셋에서 객체 분류 측면에서 CSPResNeXt50이 CSPDarknet53보다 상당히 우수하다는 것을 보여줍니다. 그러나 반대로, MS COCO 데이터셋에서는 객체 탐지 측면에서 CSPDarknet53이 CSPResNeXt50보다 더 나은 성능을 보입니다.
다음 목표는 수용 영역을 늘리기 위한 추가 블록을 선택하고, 다양한 탐지기 레벨에 대한 백본 레벨에서 매개변수를 집계하는 가장 좋은 방법을 선택하는 것입니다. 예: FPN, PAN, ASFF, BiFPN.
분류에 최적인 참조 모델이 탐지기에 항상 최적인 것은 아닙니다. 분류기와 달리 탐지기는 다음을 필요로 합니다:
- 더 큰 입력 네트워크 크기(해상도) – 여러 소형 객체를 탐지하기 위해
- 더 많은 레이어 – 입력 네트워크 크기의 증가를 커버하기 위해 더 높은 수용 영역을 위해
- 더 많은 매개변수 – 하나의 이미지에서 다양한 크기의 여러 객체를 탐지할 수 있는 모델의 더 큰 용량을 위해
가설적으로, 더 큰 수용 영역 크기(더 많은 $3×3$ 컨볼루션 레이어)와 더 많은 매개변수를 가진 모델이 백본으로 선택되어야 한다고 가정할 수 있습니다. 표 1은 CSPResNeXt50, CSPDarknet53 및 EfficientNet B3의 정보를 보여줍니다. CSPResNeXt50은 $3×3$ 컨볼루션 레이어 16개, $425×425$ 수용 영역 및 20.6M 매개변수를 포함하는 반면, CSPDarknet53은 $3×3$ 컨볼루션 레이어 29개, $725×725$ 수용 영역 및 27.6M 매개변수를 포함합니다. 이 이론적 정당화와 수많은 실험 결과, CSPDarknet53 신경망이 탐지기의 백본으로 두 모델 중 최적의 모델임을 보여줍니다.
다양한 크기의 수용 영역의 영향은 다음과 같이 요약됩니다:
- 객체 크기까지 - 객체 전체를 볼 수 있습니다.
- 네트워크 크기까지 - 객체 주변의 컨텍스트를 볼 수 있습니다.
- 네트워크 크기를 초과 - 이미지 포인트와 최종 활성화 사이의 연결 수를 증가시킵니다.
우리는 CSPDarknet53 위에 SPP 블록을 추가합니다. 이는 수용 영역을 크게 증가시키고, 가장 중요한 컨텍스트 특징을 분리하며 네트워크 운영 속도의 거의 감소 없이 수행됩니다. 우리는 YOLOv3에서 사용된 FPN 대신에 PANet을 다양한 탐지기 레벨에 대한 다양한 백본 레벨에서 매개변수를 집계하는 방법으로 사용합니다.
마지막으로, 우리는 CSPDarknet53 백본, SPP 추가 모듈, PANet 경로 집계 목(path-aggregation neck), 그리고 YOLOv3(앵커 기반) 헤드를 YOLOv4의 아키텍처로 선택합니다.
미래에는 탐지기를 위한 Bag of Freebies (BoF)의 내용을 크게 확장할 계획입니다. 이는 이론적으로 일부 문제를 해결하고 탐지기 정확도를 높이며, 실험적으로 각 특징의 영향을 순차적으로 확인할 수 있습니다.
우리는 Cross-GPU 배치 정규화(CGBN 또는 SyncBN)나 고가의 특수 장치를 사용하지 않습니다. 이는 누구나 GTX 1080Ti 또는 RTX 2080Ti와 같은 일반적인 그래픽 프로세서에서 우리의 최첨단 결과를 재현할 수 있게 합니다.
3.2. Selection of BoF and BoS
객체 탐지 훈련을 개선하기 위해, CNN은 보통 다음을 사용합니다:
- 활성화 함수: ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, Mish
- 바운딩 박스 회귀 손실: MSE, IoU, GIoU, CIoU, DIoU
- 데이터 증강: CutOut, MixUp, CutMix
- 정규화 방법: DropOut, DropPath, Spatial DropOut, DropBlock
- 평균 및 분산에 의한 네트워크 활성화 정규화: Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), Cross-Iteration Batch Normalization (CBN)
- 스킵 연결: 잔여 연결, 가중 잔여 연결, 다중 입력 가중 잔여 연결, 교차 단계 부분 연결 (CSP)
훈련 활성화 함수의 경우, PReLU와 SELU는 훈련하기 더 어렵고, ReLU6는 양자화 네트워크를 위해 특별히 설계되었기 때문에, 우리는 위의 활성화 함수들을 후보 목록에서 제외했습니다. 정규화 방법에 있어, DropBlock을 발표한 사람들은 그들의 방법을 다른 방법들과 자세히 비교했고, 그들의 정규화 방법이 많이 승리했습니다. 따라서 우리는 주저하지 않고 DropBlock을 정규화 방법으로 선택했습니다. 정규화 방법의 선택에 있어, 우리는 하나의 GPU만 사용하는 훈련 전략에 중점을 두기 때문에 syncBN은 고려하지 않습니다.

모자이크는 새로운 데이터 증강 방법을 나타냅니다.
3.3. Additional improvements
설계된 탐지기를 단일 GPU에서 훈련하기에 더 적합하게 만들기 위해 다음과 같은 추가 설계와 개선을 했습니다:
- 새로운 데이터 증강 방법인 모자이크(Mosaic)와 자기 대립 훈련(SAT)을 도입했습니다.
- 유전 알고리즘을 적용하여 최적의 하이퍼 파라미터를 선택했습니다.
- 기존 방법을 수정하여 효율적인 훈련과 탐지에 적합하도록 설계했습니다 - modified SAM, modified PAN, 교차 미니 배치 정규화(CmBN).
모자이크(Mosaic)는 4개의 훈련 이미지를 혼합하는 새로운 데이터 증강 방법입니다. 따라서 4개의 다른 컨텍스트가 혼합되며, CutMix는 2개의 입력 이미지만 혼합합니다. 이는 정상적인 컨텍스트 외부의 객체 탐지를 허용합니다. 추가적으로, 배치 정규화는 각 레이어에서 4개의 다른 이미지의 활성화 통계를 계산합니다. 이는 큰 미니 배치 크기의 필요성을 크게 줄입니다.
자기 대립 훈련(SAT)은 2단계의 전방-후방 단계로 작동하는 새로운 데이터 증강 기술입니다. 첫 번째 단계에서는 신경망이 네트워크 가중치 대신 원본 이미지를 변경합니다. 이렇게 해서 신경망은 스스로에 대해 적대적 공격을 수행하며, 원본 이미지를 변경하여 이미지에 원하는 객체가 없다는 속임수를 만듭니다. 두 번째 단계에서는 신경망이 이 수정된 이미지에서 객체를 정상적으로 탐지하도록 훈련됩니다.
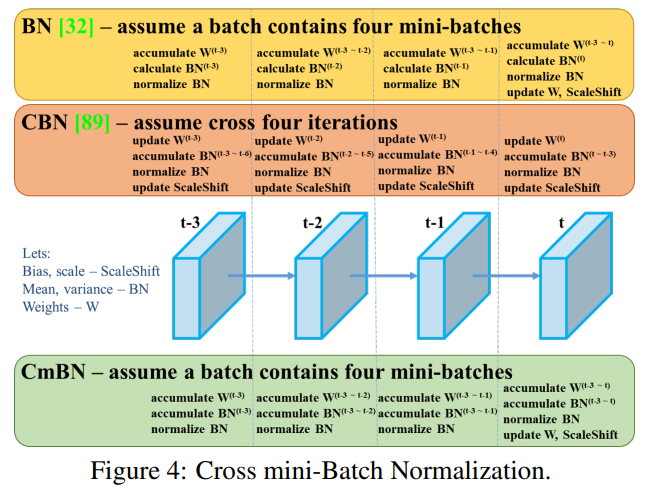
교차 미니 배치 정규화.
CmBN은 그림 4에 나와 있는 CBN 수정 버전으로, 교차 미니 배치 정규화(CmBN)로 정의됩니다. 이는 단일 배치 내의 미니 배치 간의 통계만 수집합니다.
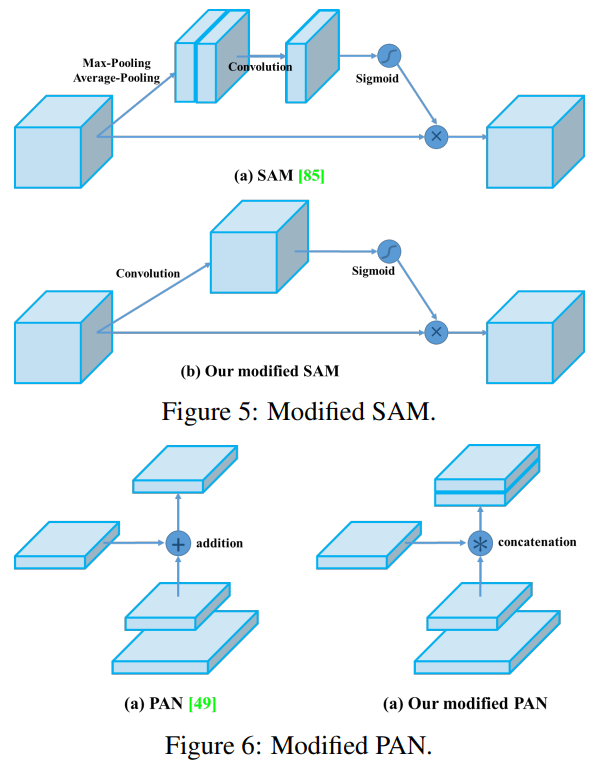
수정된 SAM. 수정된 PAN.
우리는 SAM을 공간별 어텐션에서 점별 어텐션으로 수정하고, 그림 5와 그림 6에 각각 표시된 대로 PAN의 숏컷 연결을 연결로 대체했습니다.
3.4. YOLOv4
이 섹션에서는 YOLOv4의 세부 사항을 설명하겠습니다.
YOLOv4는 다음으로 구성됩니다:
- 백본: CSPDarknet53
- 목: SPP, PAN
- 헤드: YOLOv3
YOLOv4는 다음을 사용합니다:
- 백본을 위한 Bag of Freebies (BoF): CutMix와 Mosaic 데이터 증강, DropBlock 정규화, 클래스 레이블 스무딩
- 백본을 위한 Bag of Specials (BoS): Mish 활성화, 교차 단계 부분 연결 (CSP), 다중 입력 가중 잔여 연결 (MiWRC)
- 탐지기를 위한 Bag of Freebies (BoF): CIoU-손실, CmBN, DropBlock 정규화, Mosaic 데이터 증강, 자기 대립 훈련, 그리드 감도 제거, 단일 실제값에 대한 다중 앵커 사용, 코사인 에닐링 스케줄러, 최적의 하이퍼 파라미터, 무작위 훈련 형태
- 탐지기를 위한 Bag of Specials (BoS): Mish 활성화, SPP-블록, SAM-블록, PAN 경로 집계 블록, DIoU-NMS
4. Experiments
우리는 ImageNet (ILSVRC 2012 val) 데이터셋에서 분류기의 정확도에 대한 다양한 훈련 개선 기술의 영향을 테스트하고, MS COCO (test-dev 2017) 데이터셋에서 탐지기의 정확도를 테스트합니다.
4.1. Experimental setup
ImageNet 이미지 분류 실험에서 기본 하이퍼 파라미터는 다음과 같습니다: 훈련 단계는 8,000,000; 배치 크기와 미니 배치 크기는 각각 128과 32; 초기 학습률 0.1로 다항식 감쇠 학습률 스케줄링 전략을 채택합니다; 워밍업 단계는 1000입니다; 모멘텀과 가중치 감쇠는 각각 0.9와 0.005로 설정됩니다. 우리의 모든 BoS 실험은 기본 설정과 동일한 하이퍼 파라미터를 사용하며, BoF 실험에서는 추가로 50%의 훈련 단계를 추가합니다. BoF 실험에서는 MixUp, CutMix, Mosaic, Blurring 데이터 증강 및 레이블 스무딩 정규화 방법을 검증합니다. BoS 실험에서는 LReLU, Swish, Mish 활성화 함수의 효과를 비교했습니다. 모든 실험은 1080 Ti 또는 2080 Ti GPU로 훈련됩니다.
MS COCO 객체 탐지 실험에서 기본 하이퍼 파라미터는 다음과 같습니다: 훈련 단계는 500,500; 초기 학습률 0.01로 단계적 감쇠 학습률 스케줄링 전략을 채택하고 400,000 단계와 450,000 단계에서 각각 0.1의 계수로 곱합니다; 모멘텀과 가중치 감쇠는 각각 0.9와 0.0005로 설정됩니다. 모든 아키텍처는 단일 GPU를 사용하여 배치 크기 64에서 다중 스케일 훈련을 실행하며, 미니 배치 크기는 아키텍처와 GPU 메모리 제한에 따라 8 또는 4입니다. 하이퍼 파라미터 검색 실험을 위한 유전 알고리즘을 사용하는 경우를 제외하고, 모든 다른 실험은 기본 설정을 사용합니다. 유전 알고리즘은 GIoU 손실과 함께 YOLOv3-SPP를 사용하여 훈련하고 min-val 5k 세트에 대해 300 에포크를 검색했습니다. 검색된 학습률 0.00261, 모멘텀 0.949, 실제값 할당을 위한 IoU 임계값 0.213, 유전 알고리즘 실험을 위한 손실 정규화기를 채택했습니다. 우리는 격자 감도 제거, 모자이크 데이터 증강, IoU 임계값, 유전 알고리즘, 클래스 레이블 스무딩, 교차 미니 배치 정규화, 자기 대립 훈련, 코사인 에닐링 스케줄러, 동적 미니 배치 크기, DropBlock, 최적화된 앵커, 다양한 IoU 손실 등을 포함한 많은 BoF를 검증했습니다. 또한 Mish, SPP, SAM, RFB, BiFPN, Gaussian YOLO 등을 포함한 다양한 BoS에 대한 실험도 수행했습니다. 모든 실험에서 우리는 훈련을 위해 하나의 GPU만 사용하므로, 여러 GPU를 최적화하는 syncBN과 같은 기술은 사용되지 않습니다.

다양한 데이터 증강 방법.
4.2. Influence of different features on Classifier training
먼저, 분류기 훈련에 대한 다양한 특징의 영향을 연구합니다. 구체적으로, 클래스 레이블 스무딩의 영향, 다양한 데이터 증강 기술의 영향, 양측 블러링, MixUp, CutMix 및 Mosaic의 영향, 그림 7에 표시된 대로, 그리고 Leaky-ReLU(기본값), Swish 및 Mish와 같은 다양한 활성화 함수의 영향을 연구합니다.
우리의 실험에서, 표 2에 설명된 대로, CutMix와 Mosaic 데이터 증강, 클래스 레이블 스무딩, Mish 활성화와 같은 특징을 도입하여 분류기의 정확도가 향상되었습니다. 그 결과, 분류기 훈련을 위한 우리의 BoF-백본(Bag of Freebies)에는 다음이 포함됩니다: CutMix와 Mosaic 데이터 증강 및 클래스 레이블 스무딩. 추가적으로, 우리는 Mish 활성화를 보완 옵션으로 사용합니다. 이는 표 2와 표 3에 표시되어 있습니다.

BoF 및 Mish가 CSPResNeXt-50 분류기 정확도에 미치는 영향.

BoF 및 Mish가 CSPDarknet-53 분류기 정확도에 미치는 영향.
4.3. Influence of different features on Detector training
추가 연구는 탐지기 훈련 정확도에 대한 다양한 Bag-of-Freebies (BoF-탐지기)의 영향을 다루며, 이는 표 4에 나와 있습니다. 우리는 FPS에 영향을 미치지 않으면서 탐지기 정확도를 높이는 다양한 특징을 연구하여 BoF 목록을 크게 확장했습니다:
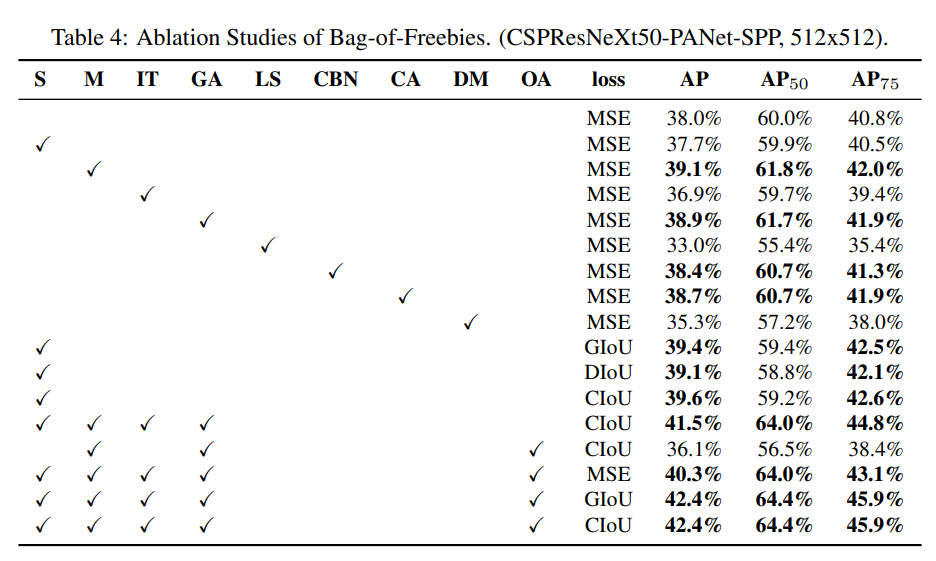
Bag-of-Freebies의 절제 연구. (CSPResNeXt50-PANet-SPP, 512x512)
- S: 격자 감도를 제거하는 방정식 $b_x=\sigma(t_x)+c_x,b_y=\sigma(t_y)+c_y$ 에서 $c_x$ 와 $c_y$ 는 항상 정수이며, 이는 YOLOv3에서 객체 좌표를 평가하는 데 사용됩니다. 따라서 $b_x$ 값이 $c_x$ 또는 $c_x+1$ 값에 접근하도록 하기 위해 매우 높은 $t_x$ 절대 값이 필요합니다. 우리는 시그모이드를 1.0을 초과하는 계수로 곱하여 이 문제를 해결하여 객체가 탐지되지 않는 격자의 영향을 제거합니다.
- M: 모자이크 데이터 증강 - 단일 이미지 대신 훈련 중에 4이미지 모자이크 사용
- IT: IoU 임계값 - 단일 실제값 IoU (truth, anchor) > IoU_threshold에 대해 여러 앵커 사용
- GA: 유전 알고리즘 - 네트워크 훈련의 처음 10% 시간 동안 최적의 하이퍼 파라미터를 선택하기 위해 유전 알고리즘 사용
- LS: 클래스 레이블 스무딩 - 시그모이드 활성화를 위해 클래스 레이블 스무딩 사용
- CBN: CmBN - 단일 미니 배치 내에서 통계를 수집하는 대신 전체 배치 내에서 통계를 수집하기 위해 교차 미니 배치 정규화 사용
- CA: 코사인 에닐링 스케줄러 - 사인파 훈련 동안 학습률 변경
- DM: 동적 미니 배치 크기 - 무작위 훈련 형태를 사용하여 작은 해상도 훈련 동안 미니 배치 크기 자동 증가
- OA: 최적화된 앵커 - 512x512 네트워크 해상도로 훈련하기 위해 최적화된 앵커 사용
- GIoU, CIoU, DIoU, MSE - 바운딩 박스 회귀를 위한 다양한 손실 알고리즘 사용
추가 연구는 탐지기 훈련 정확도에 대한 다양한 Bag-of-Specials (BoS-탐지기)의 영향을 다루며, PAN, RFB, SAM, Gaussian YOLO (G) 및 ASFF를 포함합니다. 이는 표 5에 나와 있습니다. 우리의 실험에서 탐지기는 SPP, PAN 및 SAM을 사용할 때 최고의 성능을 발휘합니다.
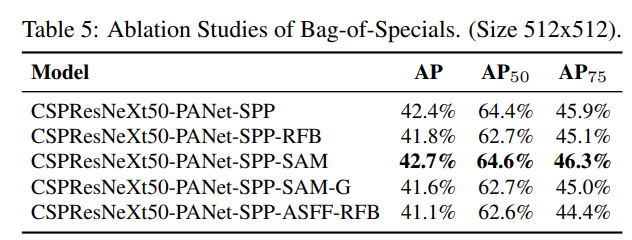
Bag-of-Specials의 절제 연구. (크기 512x512)
4.4. Influence of different backbones and pretrained weightings on Detector training
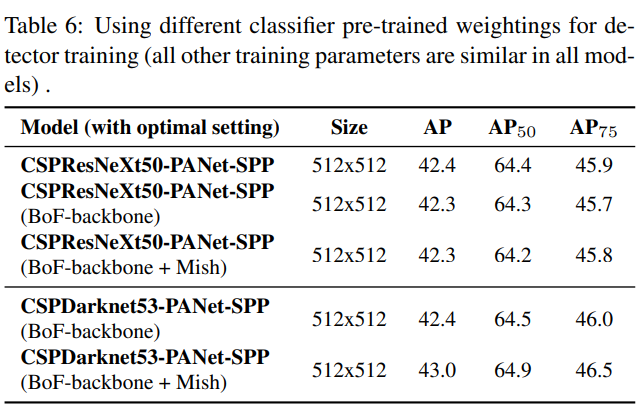
탐지기 훈련을 위한 다양한 분류기 사전 훈련 가중치 사용 (다른 모든 훈련 매개변수는 모든 모델에서 유사함).
우리는 표 6에 표시된 대로 다양한 백본 모델이 탐지기 정확도에 미치는 영향을 추가로 연구합니다. 분류 정확도가 가장 좋은 모델이 항상 탐지기 정확도가 가장 좋은 것은 아니라는 점을 주목합니다.
첫째, 다양한 특징으로 훈련된 CSPResNeXt-50 모델의 분류 정확도는 CSPDarknet53 모델보다 높지만, CSPDarknet53 모델은 객체 탐지 측면에서 더 높은 정확도를 보입니다.
둘째, CSPResNeXt50 분류기 훈련에 BoF와 Mish를 사용하면 분류 정확도가 향상되지만, 이러한 사전 훈련된 가중치를 탐지기 훈련에 추가로 적용하면 탐지기 정확도가 감소합니다. 그러나 CSPDarknet53 분류기 훈련에 BoF와 Mish를 사용하면 이 분류기 사전 훈련 가중치를 사용하는 분류기와 탐지기의 정확도가 모두 향상됩니다. 최종 결과는 CSPDarknet53 백본이 CSPResNeXt50보다 탐지기에 더 적합하다는 것입니다.
우리는 CSPDarknet53 모델이 다양한 개선 덕분에 탐지기 정확도를 높이는 더 큰 능력을 보여준다는 것을 관찰했습니다.
4.5. Influence of different mini-batch size on Detector training
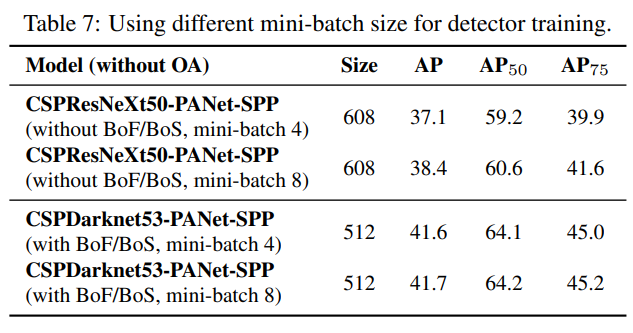
탐지기 훈련을 위한 다양한 미니 배치 크기 사용.
마지막으로, 우리는 다양한 미니 배치 크기로 훈련된 모델로 얻은 결과를 분석했으며, 결과는 표 7에 나와 있습니다. 표 7에 나와 있는 결과에서, BoF와 BoS 훈련 전략을 추가한 후에는 미니 배치 크기가 탐지기의 성능에 거의 영향을 미치지 않는다는 것을 발견했습니다. 이 결과는 BoF와 BoS 도입 후에는 훈련을 위해 고가의 GPU를 사용할 필요가 없음을 보여줍니다. 다시 말해, 누구나 기존의 GPU만으로 훌륭한 탐지기를 훈련할 수 있습니다.
5. Results
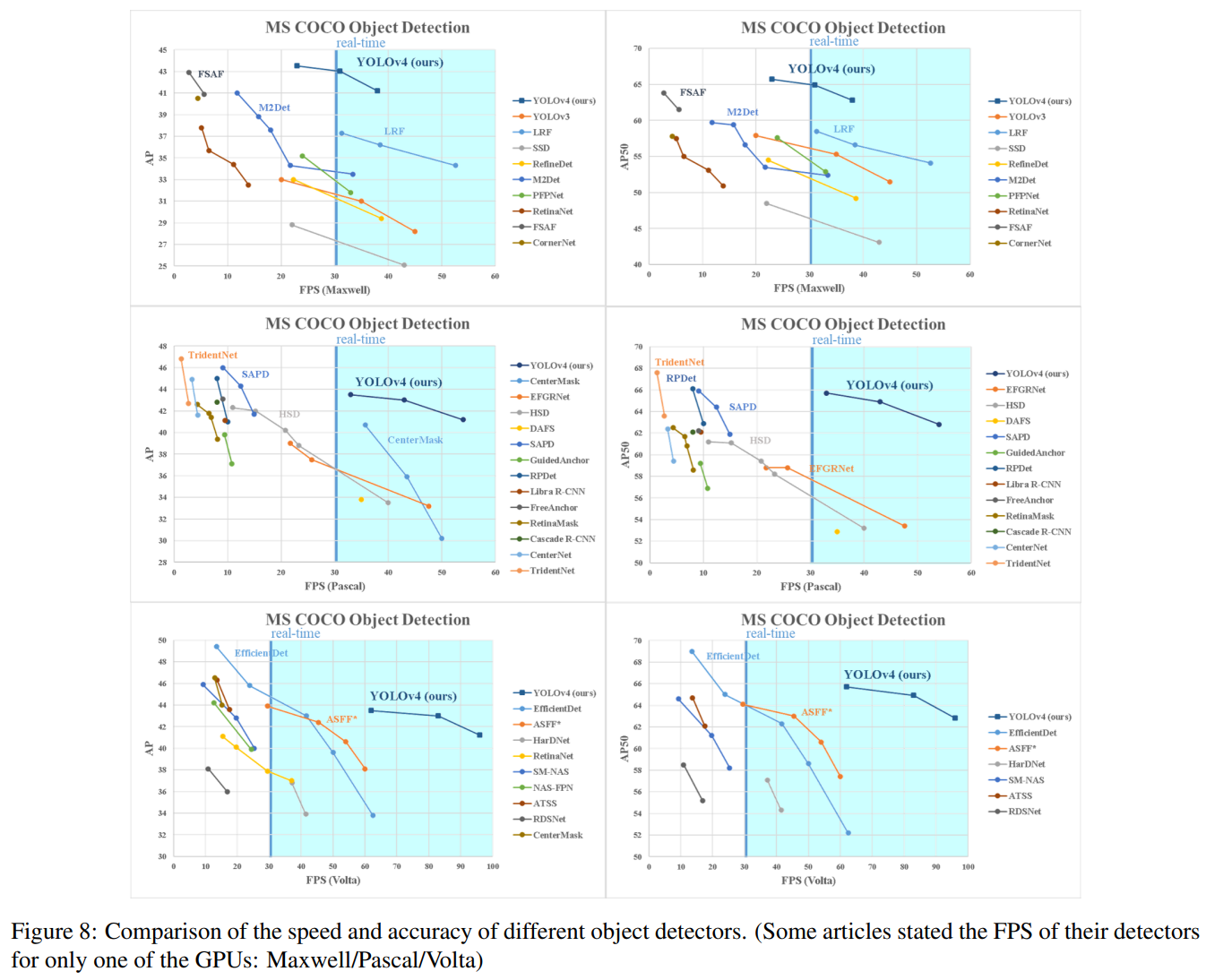
다양한 객체 탐지기의 속도와 정확도 비교. (일부 기사에서는 Maxwell/Pascal/Volta 중 하나의 GPU에 대해서만 탐지기의 FPS를 언급했습니다)
다른 최신 객체 탐지기와 얻은 결과를 비교한 것이 그림 8에 나와 있습니다. 우리의 YOLOv4는 파레토 최적 곡선에 위치하며 속도와 정확도 모두에서 가장 빠르고 가장 정확한 탐지기보다 우수합니다.
다양한 방법이 추론 시간 검증을 위해 다른 아키텍처의 GPU를 사용하기 때문에 우리는 YOLOv4를 Maxwell, Pascal, Volta 아키텍처의 일반적으로 채택된 GPU에서 운영하고 다른 최신 방법과 비교합니다. 표 8은 Maxwell GPU를 사용한 프레임 속도 비교 결과를 나열하며, GTX Titan X (Maxwell) 또는 Tesla M40 GPU일 수 있습니다. 표 9는 Pascal GPU를 사용한 프레임 속도 비교 결과를 나열하며, Titan X (Pascal), Titan Xp, GTX 1080 Ti 또는 Tesla P100 GPU일 수 있습니다. 표 10은 Volta GPU를 사용한 프레임 속도 비교 결과를 나열하며, Titan Volta 또는 Tesla V100 GPU일 수 있습니다.
(그래픽 카드별 성능 비교 표 8,9,10은 원문 참조)
6. Conclusions
우리는 기존의 모든 대체 탐지기보다 빠르고 (FPS) 더 정확한 (MS COCO $AP_{50…95}$ 및 $AP_{50}$) 최첨단 탐지기를 제공합니다. 설명된 탐지기는 8-16 GB-VRAM의 일반 GPU에서 훈련되고 사용할 수 있어 광범위한 사용이 가능합니다. 원래의 단일 단계 앵커 기반 탐지기 개념은 그 실현 가능성을 입증했습니다. 우리는 많은 기능을 검증했으며, 분류기와 탐지기의 정확성을 향상시키기 위해 그 중 일부를 선택하여 사용했습니다. 이러한 기능은 향후 연구 및 개발의 최선의 실천으로 사용될 수 있습니다.
7. Acknowledgements
저자들은 모자이크 데이터 증강의 아이디어, 유전 알고리즘을 사용한 하이퍼 파라미터 선택 및 그리드 감도 문제 해결에 대해 Glenn Jocher에게 감사를 표합니다. https://github.com/ultralytics/yolov3.
Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao YOLOv4: Optimal Speed and Accuracy of Object Detection

댓글남기기