

개요
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications 의 얕은 리뷰 포스팅. YOLOv1, YOLOv2, YOLOv3, YOLOv4 와 Scaled-YOLOv4 그 다음 리뷰. YOLOv5는 논문이 없다.
해당 논문의 도입을 보면 기존 YOLO 작업물들을 언급하면서 벤치마크 시 V100 같은 비싼 장비를 사용했음을 꼬집는다. 실제 배포환경에도 중점을 두어야 하는 부분을 언급하며 자신들의 중점을 저가 GPU에서도 추론 시간을 챙기는 것에 뒀음을 밝힌다. 필드에서 일을 해볼 때도 학습 프레임워크가 아닌 배포를 위한 NVIDIA TensorRT를 양자화 배포의 용도로 많이 사용했으며, 추론을 위한 GPU는 비싸고 좋은 장비는 아니었음에 공감한다.
Architecture 변경
- 구조가 단순한 단일 분기 네트워크와 여러 방향으로 얽혀있는 다중 분기 네트워크 중 작은 규모의 네트워크에선 RepVGG 기반의 단일 분기 네트워크를 선택하였다.
- 그러나 모델의 스케일이 커질수록 계산비용이 기하급수적으로 증가하기에 스케일이 큰 모델에선 CSPStackRep 블록 모델을 사용한다.
- 넥 구조는 YOLOv4, YOLOv5에서 채용된 PAN 구조를 활용하고 깊이와 넓이를 조정한다. 일부 블록 단위를 백본에 맞게 변경하여 해당 넥 구조를 Rep-PAN으로 부른다.
- 앵커 포인트 기반 헤드를 채택하며, 분류와 박스위치(회귀) 헤드 브랜치를 분리하고 FCOS, YOLOX 구조의 헤드 대비 합성곱 수를 줄여 latency를 줄인다.
Label Assignment
- 학습 과정에서 예측 된 앵커에 대한 정답 여부를 판단하는 방법론을 의미하며 초기에는 simOTA 방법을 사용하였으나 학습과정에 느려짐을 초래하며 불안정적임도 관측된다.
- YOLOv6에서는 TAL 방식을 기본 라벨 할당 전략으로 가져간다.
- 해당 방식은 PP-YOLOE의 ET-head 사례에서 정확성 향상이 없는 추론 속도를 저하시키는 문제가 관측되었는데, YOLOv6의 Efficient Decoupled Head 설계를 유지함으로 해결한다.
Loss
- 손실함수는 기본적으로 클래스 분류와 박스 위치의 회귀 2개로 나뉜다.
- 분류 관련 손실함수에서 전통적인 크로스 엔트로피 로스를 수정한 Focal Loss, 분류점수와 위치 품질을 함께 표현하는 Quality Focal Loss(QFL), 양성 및 음성 샘플을 비대칭적으로 처리하는 VariFocal Loss(VFL), 일반적인 분류 손실을 가중된 다항식으로 분해하는 Poly Loss 등이 있으나 YOLOv6는 최종적으로 VFL을 채택한다.
- 박스 기반 손실함수는 전통적인 L1 기반 손실에서 점차 발전하여 IoU 계열과 확률 기반 계열 손실함수가 있다.
- IoU 기반에선 GIOU, DIoU, CIou, $\alpha$-IoU, SIoU 등이 있으며, YOLOv6-N, YOLOv6-T 모델에서는 SIoU를, 다른 모델은 GIoU를 채택하였다.
- 확률 기반 손실은 박스 위치의 분포를 이산확률 분포로 단순화 하는데 Distribution Focal Loss(DFL)이 쓰이며 이를 확장한 DFLv2도 있다. 그러나 이는 계산 오버헤드를 가져오는 단점이 있다. 결론적으로 YOLOv6-M/L에서만 DFL을 채택한다.
- 2개의 손실 외에 FCOS에서 처음 제안되고 YOLOX에서도 사용된 Object Loss를 도입한다. 이는 낮은 품질의 바운딩 박스의 점수를 줄여 후처리과정에서 필터링 되도록 하는 Loss이다. YOLOv6에 시도는 했으나 크게 도움이 되지는 않았다고 한다.
Industry-handy imporvements
- 다음은 YOLOv6의 실제 필드에서 적용할만 한 트릭을 소개한다.
- 학습 에폭을 300에서 400으로 증가하였다.
- Loss 함수 추가 부분이 있는데, 분류 손실(VFL), 박스 위치 회귀 손실(DFL)을 확률 분포로 표현할 수 있으므로, 이는 학습 과정에서의 Teacher와 Student 간의 라벨 차이를 줄이도록 KL Divergence를 Loss함수에 추가하여 학습할 수 있다.
- YOLOv5에 추가되었던 회색 border를 추가하면 가장자리에 있는 객체를 잡는데 도움이 되지만 이는 속도 저하가 있으므로 테두리 영역을 조금 변경한뒤 실제 회색 테두리가 아닌 이미지 크기를 해당 사이즈에 맞춘다.
Quantization and DeploymentPermalink
- 실제 필드 배포를 위해 양자화가 쓰이는 것이 당연시 되고있다. 양자화는 크게 훈련 후 수행하는 PTQ와 학습 자체 때 수행하는 QAT로 나뉜다.
- 재매개변수화 트릭이 사용되면서 PTQ는 높은 성능을 제공하지 못한다. 학습과 추론 시의 구조가 달라지면서 추론 시의 구조가 학습 시의 구조와 맞는 양자화를 제대로 제공하지 못하기 때문이다.
- RepOptimizer는 학습 중 최적화 단계 시 재매개변수화를 제안한다. 이는 PTQ가 친화적으로 지원되도록 한다. 이를 재매개변수화 블록에 적용한다.
- 일부 민감한 연산에 대해서는 FP 연산을 유지하여 PTQ 성능을 향상 시킨다. INT8 뿐 아니라 부동소수점 영역을 같이 사용함으로 정확도 감소를 방지하여 성능을 향상한다.
- QAT도 사용할 수 있다. 학습과 추론의 불일치 문제를 해결하기 위해 RepOptimizer 블록 위에 QAT를 구축하도록 하였다.
Experiments
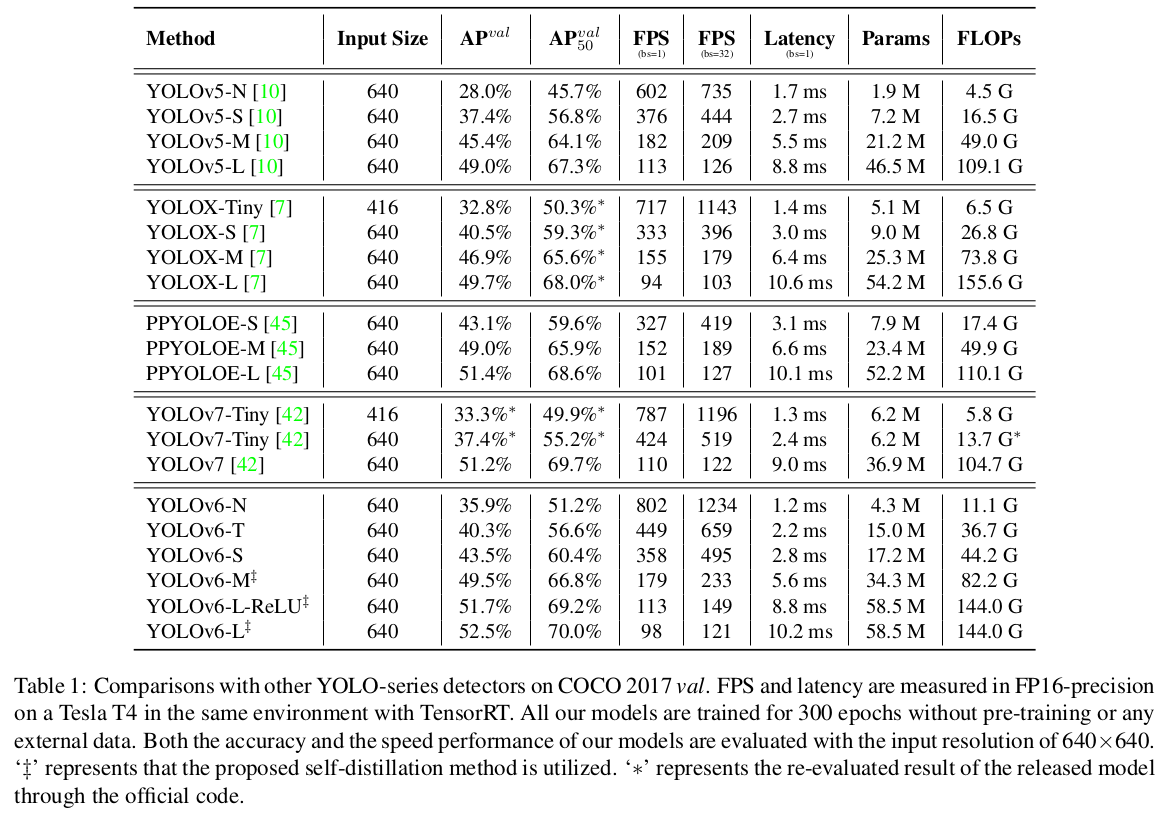
- 모델 별 성능 결과 비교는 아래 번역 내용 중 Table 1을 참고한다.
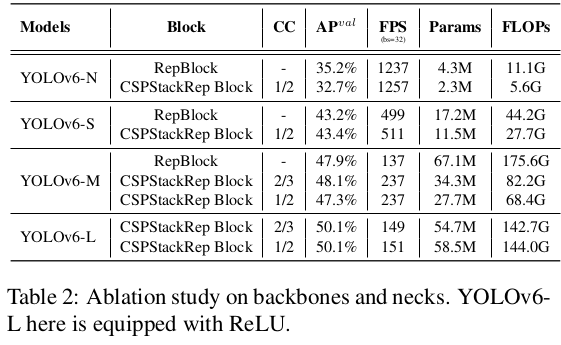
- 소거 연구에서 백본과 넥에 대한 실험을 하였고 핵심은 모델 스케일 마다 단일 경로/다중 경로 구조를 선택하는 등의 최적의 네트워크 구조가 달라져야 한다는 것이다.
- 활성화 함수에 대해서 일반적으로 Conv/SiLU와의 조합이 좋지만 추론 속도가 민감한 필드의 경우엔 RepConv/ReLU 조합을 권장한다.
- 분기 헤드 및 앵커 프리 패러다임을 실험하며, 라벨 할당 전략에서 실험결과 최종적으로 TAL을 라벨 할당 전략으로 채택한다.
- 실제 손실 함수는 클래스, 박스 회귀, 객체 손실의 3가지를 실험하며 최종적으로 객체손실은 YOLOv6에선 한다.
- 300보다 100많은 400 에포크로 학습하여 정확도 향상을 확인하였고 self-distillation 및 weight cosine decay를 적용하여 정확도 향상을 확인하였다.
- 양자화의 관점에선 정확도가 덜 감소하는 것이 성능의 향상이며, PTQ와 QAT 둘다 RepOptimizer 블록을 활용한 실험을 진행한다.
결론
해당 YOLOv6에서는 객체 감지 기술을 활용하는 현장의 요구에 맞게 추론 시간과 처리량의 관점에서 정확도-추론 시간 이라는 복합적인 성능을 효율적으로 잡으려는 필요에서 시작되었다. 이에 대해 합리적인 실험, 방법론을 제시하며 당시 최신 모델들보다 더 높은 성능을 보여주었다.
번역
Abstract
여러 해 동안 YOLO 시리즈는 효율적인 객체 감지를 위한 사실상 산업 표준이었습니다. YOLO 커뮤니티는 다양한 하드웨어 플랫폼과 풍부한 시나리오에서 사용을 풍부하게 하여 크게 번창했습니다. 이 기술 보고서에서 우리는 산업 응용을 위한 확고한 마음가짐으로 한 단계 더 발전시키기 위해 노력합니다. 실제 환경에서의 속도와 정확성에 대한 다양한 요구 사항을 고려하여, 우리는 산업계 또는 학계에서 최신 객체 감지 발전을 광범위하게 조사합니다. 특히, 우리는 최근의 네트워크 설계, 학습 전략, 테스트 기법, 양자화 및 최적화 방법에서 아이디어를 많이 받아들였습니다. 이와 더불어, 다양한 사용 사례에 대응하기 위해 다양한 규모에서 배포 준비가 된 네트워크 모음을 구축하기 위해 우리의 생각과 실천을 통합합니다. YOLO 저자들의 관대한 허가로 우리는 이를 YOLOv6로 명명합니다. 또한, 추가 개선을 위해 사용자 및 기여자들에게 따뜻한 환영을 전합니다. 성능의 예를 들어, 우리의 YOLOv6-N은 NVIDIA Tesla T4 GPU에서 1234 FPS의 처리량으로 COCO 데이터셋에서 35.9%의 AP를 기록합니다. YOLOv6-S는 495 FPS에서 43.5% AP를 기록하며, 동일한 규모의 다른 주류 감지기들(YOLOv5-S, YOLOX-S 및 PPYOLOE-S)을 능가합니다. 우리의 양자화된 YOLOv6-S 버전은 869 FPS에서 43.3% AP의 새로운 최첨단 성능을 제공합니다. 게다가, YOLOv6-M/L은 유사한 추론 속도를 가진 다른 감지기들보다 더 나은 정확도 성능(즉, 49.5%/52.3%)을 달성합니다. 우리는 각 구성 요소의 효과를 검증하기 위해 신중하게 실험을 수행했습니다. 우리의 코드는 https://github.com/meituan/YOLOv6에서 이용할 수 있습니다.
1. Introduction
YOLO 시리즈는 속도와 정확성의 우수한 균형으로 인해 산업 응용 분야에서 가장 인기 있는 감지 프레임워크였습니다. YOLO 시리즈의 선구적인 작업은 YOLOv1-3 [32-34]로, 이후의 실질적인 개선과 함께 단일 단계 감지기의 새로운 길을 열었습니다. YOLOv4 [1]는 감지 프레임워크를 여러 개의 별도 부분(백본, 넥, 헤드)으로 재구성하고, 단일 GPU에서의 훈련에 적합한 프레임워크를 설계하기 위해 bag-of-freebies와 bag-of-specials을 검증했습니다. 현재, YOLOv5 [10], YOLOX [7], PP-YOLOE [44] 및 YOLOv7 [42]는 모두 배포를 위한 효율적인 감지기를 위한 경쟁 후보들입니다. 다양한 크기의 모델들은 일반적으로 스케일링 기법을 통해 얻어집니다.
이 보고서에서 우리는 YOLO 프레임워크를 새로 단장해야 한다는 동기를 부여하는 몇 가지 중요한 요소를 경험적으로 관찰했습니다:
(1) RepVGG [3]에서의 재매개변수화는 감지에 있어 아직 잘 활용되지 않은 우수한 기술입니다. 또한 우리는 RepVGG 블록의 단순 모델 확장이 비실용적임을 인식했으며, 이는 작은 네트워크와 큰 네트워크 간의 네트워크 설계의 우아한 일관성이 불필요하다고 판단했습니다. 단순 단일 경로 아키텍처는 작은 네트워크에 더 나은 선택이지만, 더 큰 모델의 경우 매개변수의 기하급수적 증가와 단일 경로 아키텍처의 계산 비용이 이를 실행 불가능하게 만듭니다.
(2) 재매개변수화 기반 감지기의 양자화 또한 세심한 처리가 필요하며, 그렇지 않으면 훈련 및 추론 중 이질적인 구성으로 인해 성능 저하를 처리하기 어려울 것입니다.
(3) 이전 작업 [7, 10, 42, 44]은 배포에 덜 주목하는 경향이 있으며, 이들의 지연 시간은 주로 V100과 같은 고가의 기계에서 비교됩니다. 실제 서비스 환경에서는 하드웨어 격차가 존재합니다. 일반적으로 Tesla T4와 같은 저가의 GPU는 비용이 적게 들며, 비교적 우수한 추론 성능을 제공합니다.
(4) 라벨 할당 및 손실 함수와 같은 고급 도메인 특화 설계는 아키텍처 변동을 고려하여 서비스 시나리오에 맞게 정밀하게 조정되어야 합니다.
(5) 배포를 위해 우리는 추론 시간을 주요 지표로 고려하여 최적의 아키텍처를 탐색해야 합니다.
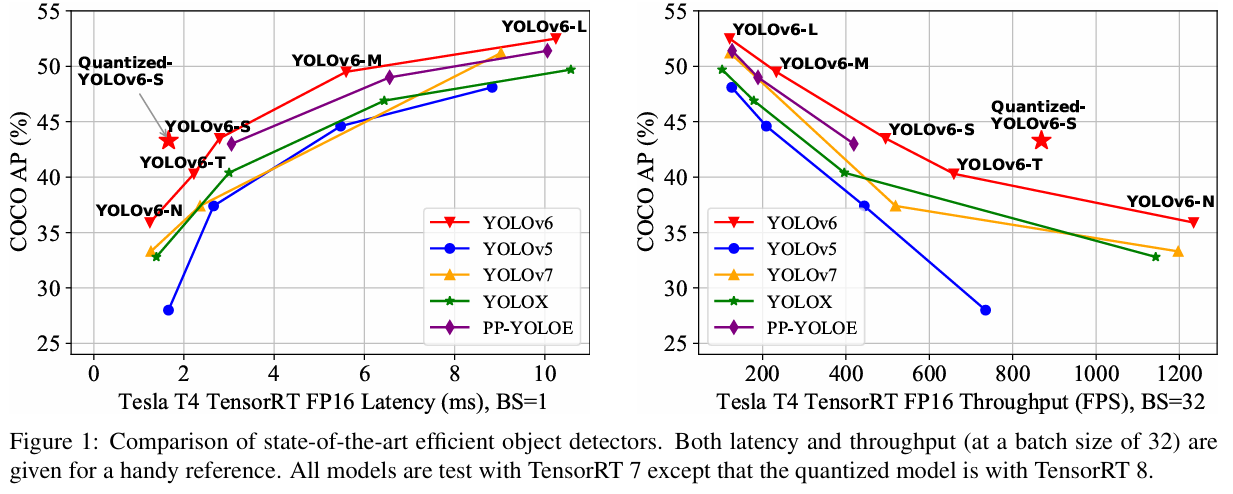
앞서 언급한 관찰을 바탕으로, 우리는 정확성과 속도 면에서 지금까지 최고의 균형을 달성한 YOLOv6의 탄생을 소개합니다. 그림 1에서 유사한 규모의 다른 모델들과 YOLOv6의 비교를 보여줍니다. 성능 저하 없이 추론 속도를 높이기 위해, 우리는 사후 학습 양자화(PTQ)와 양자화 인식 학습(QAT)을 포함한 최첨단 양자화 방법을 검토하였고, 이를 YOLOv6에 적용하여 배포 준비가 완료된 네트워크 목표를 달성했습니다.
YOLOv6의 주요 측면을 다음과 같이 요약합니다:
- 우리는 다양한 시나리오에서 산업 응용을 위해 다양한 크기의 네트워크를 새롭게 설계했습니다. 서로 다른 크기의 아키텍처는 최고의 속도와 정확성 균형을 달성하기 위해 다르게 설계되었으며, 작은 모델은 단순한 단일 경로 백본을 특징으로 하고, 큰 모델은 효율적인 다중 브랜치 블록으로 구성됩니다.
- 우리는 YOLOv6에 자체 증류 전략을 적용하여 분류 작업과 회귀 작업 모두에서 수행됩니다. 또한, 우리는 교사 모델과 레이블에서 지식을 동적으로 조정하여 학생 모델이 모든 훈련 단계에서 지식을 보다 효율적으로 학습할 수 있도록 돕습니다.
- 우리는 라벨 할당, 손실 함수 및 데이터 증강 기법에 대한 고급 감지 기술을 광범위하게 검증하고, 성능을 더욱 향상시키기 위해 이를 선택적으로 채택합니다.
- 우리는 RepOptimizer [2]와 채널별 증류 [36]의 도움으로 감지를 위한 양자화 방식을 개혁했으며, 이는 배치 크기 32에서 43.3% COCO AP와 869 FPS의 처리량을 가진 빠르고 정확한 감지기로 이어졌습니다.
2. Method
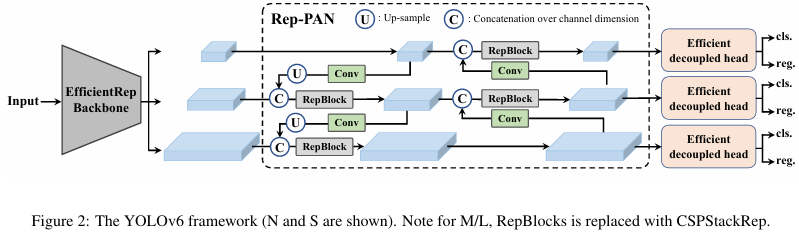
YOLOv6의 개조된 설계는 다음과 같은 구성 요소들로 이루어져 있습니다: 네트워크 설계, 라벨 할당, 손실 함수, 데이터 증강, 산업에서 유용한 개선 사항 및 양자화와 배포.
- Network Design:
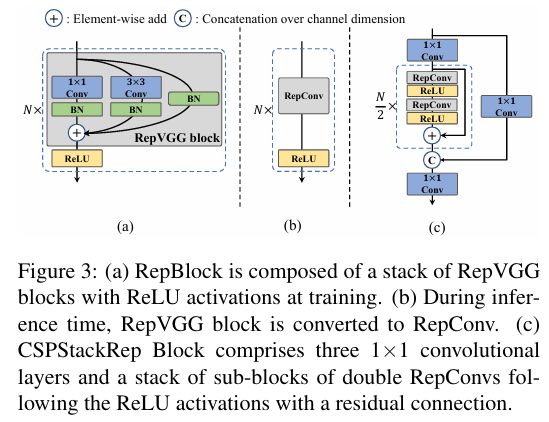
- Backbone: 다른 주요 아키텍처와 비교할 때, 우리는 RepVGG [3] 백본이 작은 네트워크에서 유사한 추론 속도로 더 많은 특징 표현 능력을 제공한다는 것을 발견했습니다. 그러나 파라미터와 계산 비용의 폭발적인 증가로 인해 더 큰 모델로 확장하기는 어렵습니다. 이러한 관점에서 우리는 소형 네트워크의 기본 블록으로 RepBlock [3]을 채택했습니다. 대형 모델의 경우, CSP [43] 블록을 보다 효율적인 CSPStackRep Block으로 개조했습니다.
- Neck: YOLOv6의 목(neck)은 YOLOv4 및 YOLOv5에 이어 PAN 토폴로지 [24]를 채택했습니다. 우리는 RepBlocks 또는 CSPStackRep Blocks를 사용하여 목을 강화하여 RepPAN을 갖추었습니다.
- Head: 디커플드 헤드를 단순화하여 더 효율적으로 만들었으며, 이를 Efficient Decoupled Head라고 합니다.
- Label Assignment: 우리는 라벨 할당 전략의 최신 발전을 평가했으며, 실험을 통해 YOLOv6에서의 라벨 할당 전략을 검토했습니다. 그 결과 TAL [5]이 더 효율적이고 훈련 친화적임을 나타냈습니다.
- Loss Function: 주요 손실 함수는 분류 손실, 박스 회귀 손실, 객체 손실로 구성됩니다. 각 손실에 대해 모든 가능한 기법을 체계적으로 실험한 후, 분류 손실로 VariFocal Loss [50], 회귀 손실로 SIoU [8]와 GIoU [35]를 최종적으로 선택했습니다.
- Industry-handy improvements: 우리는 성능을 향상시키기 위해 자기 증류(self-distillation)와 더 많은 훈련 에포크와 같은 추가적인 일반적인 실습 및 팁을 도입했습니다. 자기 증류의 경우, 분류와 박스 회귀는 각각 교사 모델에 의해 감독됩니다. DFL [20] 덕분에 박스 회귀의 증류가 가능해졌습니다. 또한, 소프트 및 하드 라벨의 정보 비율은 코사인 감소를 통해 동적으로 줄어들어, 훈련 과정의 다른 단계에서 학생이 선택적으로 지식을 획득할 수 있도록 돕습니다. 추가로, 평가 시 여분의 회색 테두리를 추가하지 않고도 성능 저하 문제를 해결하기 위한 해결책을 제공했습니다.
- Quantization and deployment: 재매개변수화 기반 모델을 양자화하는 동안 발생하는 성능 저하를 해결하기 위해, 우리는 YOLOv6를 RepOptimizer [2]로 훈련하여 PTQ에 친화적인 가중치를 얻었습니다. 또한, 채널별 증류 [36]와 함께 QAT를 채택하여 극단적인 성능을 추구했습니다. 우리 양자화된 YOLOv6-S는 32 배치 크기에서 43.3% COCO AP와 869 FPS의 처리량을 제공하며, 새로운 최첨단 성능을 발휘합니다.
2.1. Network Design
단일 단계 객체 감지기는 일반적으로 다음과 같은 부분들로 구성됩니다: 백본, 넥, 그리고 헤드. 백본은 주로 특징 표현 능력을 결정하며, 동시에 계산 비용의 큰 부분을 차지하기 때문에 그 설계는 추론 효율성에 중요한 영향을 미칩니다. 넥은 저수준의 물리적 특징을 고수준의 의미적 특징과 결합하여 모든 수준에서 피라미드 특징 맵을 구축하는 데 사용됩니다. 헤드는 여러 개의 합성곱층으로 구성되며, 넥에 의해 결합된 다층 특징에 따라 최종 감지 결과를 예측합니다. 구조적인 관점에서 이를 앵커 기반과 앵커 비기반, 또는 파라미터 결합 헤드와 파라미터 비결합 헤드로 구분할 수 있습니다.
YOLOv6에서는 하드웨어 친화적인 네트워크 설계 원칙 [3]에 따라, 다양한 크기의 모델을 수용하기 위해 두 가지 확장 가능한 재매개변수화 가능한 백본과 넥을 제안하며, 하이브리드 채널 전략을 사용하는 효율적인 비결합 헤드를 제안합니다. YOLOv6의 전체 아키텍처는 그림 2에 나와 있습니다.
2.1.1 Backbone
앞서 언급한 바와 같이, 백본 네트워크의 설계는 감지 모델의 효과성과 효율성에 큰 영향을 미칩니다. 이전에, 다중 분기 네트워크[13, 14, 38, 39]가 단일 경로 네트워크[15, 37],보다 더 나은 분류 성능을 자주 달성할 수 있지만, 이는 종종 병렬성의 감소와 추론 지연 시간의 증가를 초래함이 입증되었습니다. 반면에, VGG와 같은 단순 단일 경로 네트워크는 높은 병렬성과 적은 메모리 사용량의 이점을 활용하여 더 높은 추론 효율성을 제공합니다. 최근 RepVGG [3]에서는 훈련 시 다중 분기 구조를 추론 시 단순한 아키텍처와 분리하는 구조적 재매개변수화 방법이 제안되어, 더 나은 속도-정확도 균형을 달성하였습니다.
위의 연구들에 영감을 받아, 우리는 EfficientRep이라고 불리는 효율적인 재매개변수화 가능한 백본을 설계했습니다. 작은 모델의 경우, 백본의 주요 구성 요소는 훈련 단계에서 RepBlock입니다. 이는 그림 3(a)에 나와 있습니다. 그리고 각 RepBlock은 그림 3(b)에 나와 있는 바와 같이, 추론 단계에서 ReLU 활성화를 가진 3 × 3 합성곱 층으로 변환됩니다. 일반적으로 3×3 합성곱은 주류 GPU와 CPU에서 매우 최적화되어 있으며, 더 높은 계산 밀도를 제공합니다. 결과적으로, EfficientRep 백본은 하드웨어의 계산 능력을 충분히 활용하여, 추론 지연 시간을 크게 줄이면서도 동시에 표현 능력을 향상시킵니다.
그러나 우리는 모델 용량이 확장됨에 따라 단일 경로 단순 네트워크의 계산 비용과 매개변수 수가 기하급수적으로 증가하는 것을 확인했습니다. 계산 부담과 정확성 간의 더 나은 균형을 달성하기 위해, 우리는 중대형 네트워크의 백본을 구축하기 위해 CSPStackRep 블록을 수정했습니다. 그림 3(c)에 나와 있듯이, CSPStackRep 블록은 세 개의 1×1 합성곱 층과 두 개의 RepVGG 블록 [3] 또는 RepConv (훈련 또는 추론 시 각각)으로 구성된 하위 블록 스택과 잔차 연결로 구성됩니다. 또한, 과도한 계산 비용 없이 성능을 향상시키기 위해 크로스 스테이지 부분(CSP: Cross Stage Partial) 연결을 채택했습니다. CSPRepResStage [45]와 비교할 때, 이 방식은 더 간결한 외관을 제공하며 정확성과 속도 간의 균형을 고려합니다.
2.1.2 Neck
실제로, 다양한 스케일에서의 특징 통합은 객체 감지에서 중요한 역할을 한다는 것이 입증되었습니다 [9, 21, 24, 40]. 우리는 YOLOv4 [1]와 YOLOv5 [10]에서 수정된 PAN 토폴로지를 감지 네크의 기본으로 채택했습니다. 추가로, YOLOv5에서 사용된 CSP-Block을 작은 모델의 경우 RepBlock으로, 큰 모델의 경우 CSPStackRep Block으로 대체하고, 이에 맞춰 너비와 깊이를 조정했습니다. YOLOv6의 넥은 Rep-PAN으로 명명됩니다.
2.1.3 Head
Efficient decoupled head
YOLOv5의 감지 헤드는 분류와 위치 지정 브랜치 간에 매개변수를 공유하는 결합된 헤드였지만, FCOS [41]와 YOLOX [7]에서는 두 브랜치를 분리하고, 각 브랜치에 두 개의 3×3 합성곱 층을 추가하여 성능을 향상시켰습니다.
YOLOv6에서는 더 효율적인 비결합 헤드를 구축하기 위해 하이브리드 채널 전략을 채택했습니다. 특히, 중간 3×3 합성곱 층의 수를 하나로 줄였습니다. 헤드의 너비는 백본과 넥의 너비 배율에 따라 함께 조정됩니다. 이러한 수정은 계산 비용을 더욱 줄여 추론 지연 시간을 낮추는 데 기여합니다.
Anchor-free
앵커 프리 감지기는 더 나은 일반화 능력과 예측 결과를 디코딩하는 과정에서의 단순성으로 인해 두드러집니다. 사후 처리 시간 비용이 크게 줄어듭니다. 앵커 프리 감지기에는 앵커 포인트 기반 [7, 41]과 키포인트 기반 [16, 46, 53] 두 가지 유형이 있습니다. YOLOv6에서는 앵커 포인트 기반 패러다임을 채택하며, 여기서 박스 회귀 브랜치는 실제로 앵커 포인트에서 경계 상자의 네 변까지의 거리를 예측합니다.
2.2. Label Assignment
라벨 할당은 훈련 단계에서 사전 정의된 앵커에 라벨을 할당하는 역할을 합니다. 이전 연구에서는 단순한 IoU 기반 전략과 내부 그라운드 트루스 방법 [41]부터 더 복잡한 방식 [5, 7, 18, 48, 51]까지 다양한 라벨 할당 전략을 제안했습니다.
SimOTA
OTA [6]는 객체 감지에서 라벨 할당을 최적 전송 문제로 간주합니다. 이 방법은 전역적인 관점에서 각 그라운드 트루스 객체에 대한 긍정/부정 훈련 샘플을 정의합니다. SimOTA [7]는 OTA [6]의 단순화된 버전으로, 추가적인 하이퍼파라미터를 줄이고 성능을 유지합니다. SimOTA는 초기 버전의 YOLOv6에서 라벨 할당 방법으로 사용되었습니다. 그러나 실무에서 우리는 SimOTA를 도입하면 훈련 과정이 느려진다는 것을 발견했습니다. 그리고 불안정한 훈련 상태에 빠지는 것도 드물지 않습니다. 따라서 우리는 SimOTA의 대체 방법을 원합니다.
Task alignment learning
Task Alignment Learning (TAL)은 TOOD [5]에서 처음 제안되었으며, 분류 점수와 예측 박스 품질의 통합 메트릭이 설계되었습니다. IoU는 이 메트릭으로 대체되어 객체 라벨을 할당합니다. 어느 정도는 작업(분류 및 박스 회귀) 불일치 문제를 완화시킵니다.
TOOD의 또 다른 주요 기여는 작업 정렬 헤드(T-head)에 관한 것입니다. T-head는 합성곱 층을 쌓아 상호작용 특징을 구축하며, 그 위에 Task-Aligned Predictor (TAP)가 사용됩니다. PP-YOLOE [45]는 T-head의 레이어 어텐션을 가벼운 ESE 어텐션으로 교체하여 ET-head를 형성함으로써 T-head를 개선했습니다. 그러나 우리는 ET-head가 우리의 모델에서 추론 속도를 저하시키며, 정확성 향상 없이 이뤄진다는 것을 발견했습니다. 따라서 우리는 Efficient Decoupled Head 설계를 유지합니다.
더 나아가, 우리는 TAL이 SimOTA보다 더 많은 성능 향상을 가져오고 훈련을 안정화할 수 있다는 것을 관찰했습니다. 따라서 우리는 YOLOv6에서 TAL을 기본 라벨 할당 전략으로 채택했습니다.
2.3. Loss Functions
객체 감지는 분류와 위치 지정이라는 두 가지 하위 작업을 포함하며, 각각에 해당하는 두 가지 손실 함수: 분류 손실과 박스 회귀 손실이 있습니다. 각 하위 작업에 대해 최근 몇 년 동안 다양한 손실 함수가 제안되었습니다. 이 섹션에서는 이러한 손실 함수들을 소개하고, YOLOv6에 가장 적합한 함수를 선택하는 방법을 설명합니다.
2.3.1 Classification Loss
분류기의 성능을 향상시키는 것은 감지기 최적화의 중요한 부분입니다. Focal Loss [22]는 전통적인 교차 엔트로피 손실을 수정하여 양성 및 음성 예제 간, 또는 어려운 예제와 쉬운 예제 간의 클래스 불균형 문제를 해결했습니다. 훈련과 추론 간의 품질 추정과 분류의 일관성 없는 사용을 해결하기 위해, Quality Focal Loss (QFL) [20]은 분류에서의 감독을 위해 분류 점수와 위치 품질을 함께 표현하는 Focal Loss를 더욱 확장했습니다. VariFocal Loss (VFL) [50]는 Focal Loss [22]에 뿌리를 두고 있지만, 양성 및 음성 샘플을 비대칭적으로 처리합니다. 양성 및 음성 샘플을 서로 다른 중요도로 고려하여, 두 샘플의 학습 신호를 균형 있게 합니다. Poly Loss [17]는 일반적으로 사용되는 분류 손실을 일련의 가중된 다항식 기초로 분해합니다. Poly Loss [17]는 일반적으로 사용되는 분류 손실을 일련의 가중된 다항식 기초로 분해합니다.
우리는 이러한 모든 고급 분류 손실을 YOLOv6에서 평가하여 최종적으로 VFL [50]을 채택했습니다.
2.3.2 Box Regression Loss
박스 회귀 손실은 경계 상자를 정확하게 위치시키기 위한 중요한 학습 신호를 제공합니다. L1 손실은 초기 연구에서 사용된 원래의 박스 회귀 손실입니다. 점진적으로, 잘 설계된 박스 회귀 손실이 등장했으며, 그 중 IoU 계열 손실 [8, 11, 35, 47, 52, 52]과 확률 손실 [20]이 있습니다.
IoU-series Loss
IoU 손실 [47]은 예측된 박스의 네 경계를 하나의 단위로 회귀시킵니다. 이는 평가 메트릭과의 일관성으로 인해 효과적임이 입증되었습니다. IoU에는 GIoU [35], DIoU [52], CIoU [52], α-IoU [11], SIoU [8] 등 다양한 변형이 있으며, 관련된 손실 함수를 형성합니다. 이 연구에서 우리는 GIoU, CIoU 및 SIoU를 실험합니다. 그리고 SIoU는 YOLOv6-N 및 YOLOv6-T에 적용되며, 다른 모델은 GIoU를 사용합니다.
Probability Loss
Distribution Focal Loss (DFL) [20]은 박스 위치의 기저 연속 분포를 이산 확률 분포로 단순화합니다. 이는 다른 강력한 사전 정보 없이 데이터의 모호성과 불확실성을 고려하여, 특히 그라운드 트루스 박스의 경계가 흐릿할 때 박스 위치 정확도를 향상시키는 데 유용합니다. DFL에 기반하여, DFLv2 [19]는 분포 통계와 실제 위치 품질 간의 밀접한 상관관계를 활용하기 위해 가벼운 서브 네트워크를 개발하여 감지 성능을 더욱 향상시킵니다. 그러나 DFL은 일반적인 박스 회귀보다 17배 더 많은 회귀 값을 출력하여 상당한 오버헤드를 초래합니다. 추가적인 계산 비용은 작은 모델의 훈련을 크게 방해합니다. DFLv2는 추가적인 서브 네트워크로 인해 계산 부담을 더욱 증가시킵니다. 우리의 실험에서 DFLv2는 DFL과 유사한 성능 향상을 가져왔습니다. 결과적으로, 우리는 YOLOv6-M/L에서만 DFL을 채택했습니다. 실험적 세부 사항은 섹션 3.3.3에서 확인할 수 있습니다.
2.3.3 Object Loss
객체 손실은 낮은 품질의 경계 상자 점수를 줄여서 후처리 과정에서 필터링될 수 있도록 하기 위해 FCOS [41]에서 처음 제안되었습니다. 이는 YOLOX [7]에서도 사용되어 수렴을 가속화하고 네트워크 정확도를 향상시켰습니다. FCOS와 YOLOX와 같은 앵커 프리 프레임워크로서, 우리는 YOLOv6에 객체 손실을 시도했습니다. 불행히도, 이는 많은 긍정적인 효과를 가져오지 못했습니다. 자세한 내용은 섹션 3에서 제공됩니다.
2.4. Industry-handy imporvements
다음의 트릭들은 실제 실무에서 사용하기에 적합합니다. 이들은 공정한 비교를 목적으로 하지는 않지만, 번거로운 노력 없이 꾸준히 성능 향상을 가져옵니다.
2.4.1 More training epochs
경험적 결과에 따르면, 더 많은 훈련 시간이 감지기의 성능을 점진적으로 향상시킵니다. 우리는 더 나은 수렴을 위해 훈련 기간을 300 에포크에서 400 에포크로 연장했습니다.
2.4.2 Self-distillation
추가적인 계산 비용을 크게 증가시키지 않으면서 모델의 정확성을 더욱 향상시키기 위해, 우리는 교사와 학생의 예측 간 KL 발산을 최소화하는 고전적인 지식 증류 기법을 적용합니다. 우리는 교사를 사전 훈련된 학생으로 제한하므로 이를 자기 증류(self-distillation)라고 부릅니다. KL 발산은 일반적으로 데이터 분포 간의 차이를 측정하는 데 사용됩니다. 그러나 객체 감지에는 두 가지 하위 작업이 있으며, 그중 분류 작업만이 KL 발산에 기반한 지식 증류를 직접적으로 활용할 수 있습니다. DFL 손실 [20] 덕분에, 우리는 박스 회귀에도 이를 적용할 수 있습니다. 그런 다음 지식 증류 손실은 다음과 같이 공식화할 수 있습니다:
\[\begin{equation} L_{KD} = KL(p_t^{cls} \Vert p_s^{cls}) + KL(p_t^{reg} \Vert p_s^{reg}) \end{equation}\]여기서 $p_t^{cls}$ 와 $p_s^{cls}$ 는 각각 교사 모델과 학생 모델의 클래스 예측을 나타내며, $p_t^{reg}$ 와 $p_s^{reg}$ 는 박스 회귀 예측을 나타냅니다. 전체 손실 함수는 다음과 같이 공식화됩니다:
\[\begin{equation} L_{total} = L_{det} + \alpha L_{KD} \end{equation}\]여기서 $L_{det}$ 은 예측 및 라벨과 함께 계산된 감지 손실입니다. 하이퍼파라미터 $\alpha$ 는 두 손실 간의 균형을 맞추기 위해 도입되었습니다. 훈련 초기 단계에서는 교사의 소프트 라벨을 더 쉽게 학습할 수 있습니다. 훈련이 계속됨에 따라 학생의 성능은 교사와 일치하게 되며, 이는 하드 라벨이 학생들에게 더 많은 도움을 줄 것입니다. 이에 따라, 우리는 하드 라벨과 교사로부터의 소프트 라벨 정보를 동적으로 조정하기 위해 $\alpha$ 에 코사인 가중치 감소를 적용합니다. 우리는 YOLOv6에서의 자기 증류 효과를 검증하기 위해 상세한 실험을 수행했으며, 이는 섹션 3에서 논의될 것입니다.
2.4.3 Gray border of images
YOLOv5 [10] 및 YOLOv7 [42]의 구현에서 모델 성능을 평가할 때 각 이미지 주변에 반 스크라이드 그레이 보더가 추가된다는 것을 우리는 알게 되었습니다. 유용한 정보는 추가되지 않지만, 이는 이미지 가장자리 근처의 객체를 감지하는 데 도움이 됩니다. 이 트릭은 YOLOv6에도 적용됩니다.
그러나 추가된 회색 픽셀은 명백히 추론 속도를 저하시킵니다. 회색 테두리가 없으면 YOLOv6의 성능이 저하되며, 이는 [10, 42]에서도 마찬가지입니다. 우리는 이 문제가 모자이크 증강 [1, 10]에서의 회색 테두리 패딩과 관련이 있다고 추정합니다. 마지막 에포크 동안 모자이크 증강을 끄는 실험 [7] (일명 페이드 전략)이 검증을 위해 수행되었습니다. 이와 관련하여, 우리는 회색 테두리 영역을 변경하고, 회색 테두리로 이미지를 직접 타겟 이미지 크기로 조정합니다. 이 두 가지 전략을 결합하면, 우리의 모델은 추론 속도의 저하 없이 성능을 유지하거나 심지어 향상시킬 수 있습니다.
2.5. Quantization and Deployment
산업적 배포를 위해, 성능 저하 없이 런타임을 더욱 가속화하기 위해 양자화를 채택하는 것이 일반적인 관행이었습니다. 훈련 후 양자화(PTQ)는 소규모 보정 세트만으로 모델을 직접 양자화합니다. 반면에 양자화 인식 훈련(QAT)은 훈련 세트에 접근하여 성능을 더욱 향상시키며, 이는 일반적으로 증류와 함께 사용됩니다. 그러나 YOLOv6에서 재매개변수화 블록을 많이 사용하기 때문에, 이전의 PTQ 기술은 높은 성능을 제공하지 못했으며, 훈련 및 추론 중에 가짜 양자화기를 일치시키는 데 QAT를 통합하기도 어렵습니다. 여기서 우리는 배포 중에 발생하는 문제점과 해결책을 설명합니다.
2.5.1 Reparameterizing Optimizer
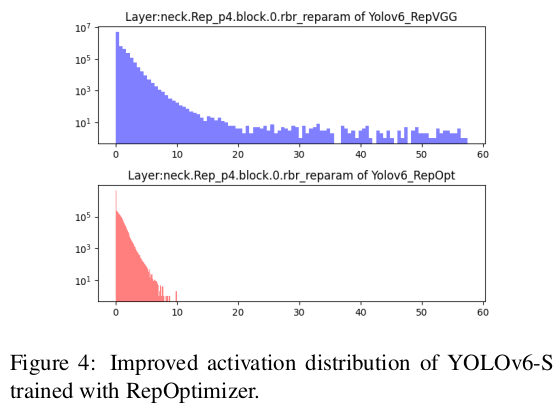
RepOptimizer [2]는 각 최적화 단계에서 그래디언트 재매개변수화를 제안합니다. 이 기술은 또한 재매개변수화 기반 모델의 양자화 문제를 잘 해결합니다. 따라서 우리는 YOLOv6의 재매개변수화 블록을 이 방식으로 재구성하고, PTQ 친화적인 가중치를 얻기 위해 RepOptimizer로 훈련합니다. 특징 맵의 분포는 크게 좁혀지며(예: 그림 4, B.1에서 자세히 설명), 이는 양자화 과정에 크게 도움이 됩니다. 결과는 섹션 3.5.1을 참조하세요.
2.5.2 Sensitivity Analysis
우리는 양자화에 민감한 연산을 부분적으로 부동소수점 계산으로 변환함으로써 PTQ 성능을 더욱 향상시킵니다. 민감도 분포를 얻기 위해 평균 제곱 오차(MSE), 신호 대 잡음비(SNR), 코사인 유사도와 같은 여러 지표가 일반적으로 사용됩니다. 비교를 위해 일반적으로 특정 계층의 활성화 후 출력 특징 맵을 선택하여 양자화 전후에 이러한 지표를 계산할 수 있습니다. 대안으로, 특정 계층에 대해 양자화를 켜고 끄면서 검증 AP를 계산하는 것도 가능합니다 [29]. 우리는 RepOptimizer로 훈련된 YOLOv6-S 모델에서 이러한 지표를 모두 계산하고, 상위 6개의 민감한 계층을 선택하여 부동소수점으로 실행합니다. 민감도 분석의 전체 차트는 B.2에서 확인할 수 있습니다.
2.5.3 Quantization-aware Training with Channel-wise Distillation
PTQ가 충분하지 않은 경우, 우리는 양자화 인식 훈련(QAT)을 도입하여 양자화 성능을 향상시키는 것을 제안합니다. 훈련 및 추론 중 가짜 양자화기들의 불일치 문제를 해결하기 위해, RepOptimizer 위에 QAT를 구축하는 것이 필요합니다. 또한, 채널별 증류 [36] (이후 CW Distill로 불림)이 YOLOv6 프레임워크 내에 적응되어 그림 5에 나와 있습니다. 이는 또한 교사 네트워크가 FP32 정밀도에서 학생 자신인 자기 증류 접근 방식입니다. 실험은 섹션 3.5.1을 참조하십시오.
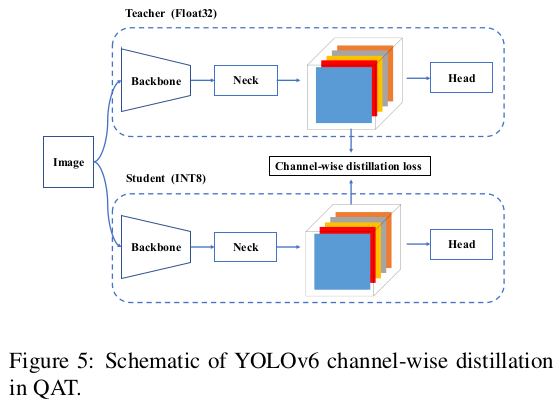
3. Experiments
3.1. Implementation Details
우리는 YOLOv5 [10]와 동일한 옵티마이저와 학습 일정을 사용합니다. 즉, 학습률에서 모멘텀과 코사인 감소를 사용하는 확률적 경사 하강법(SGD)을 사용합니다. 워밍업, 그룹화된 가중치 감소 전략 및 지수 이동 평균(EMA)도 사용됩니다. 우리는 [1, 7, 10]을 따라 두 가지 강력한 데이터 증강 기법(Mosaic [1, 10]과 Mixup [49])을 채택했습니다. 하이퍼파라미터 설정의 전체 목록은 공개된 코드에서 확인할 수 있습니다. 우리는 COCO 2017 [23] 훈련 세트에서 모델을 훈련시키고, COCO 2017 검증 세트에서 정확도를 평가합니다. 모든 모델은 8개의 NVIDIA A100 GPU에서 훈련되었으며, 속도 성능은 별도로 언급되지 않는 한 TensorRT 7.2 버전이 설치된 NVIDIA Tesla T4 GPU에서 측정됩니다. 다른 TensorRT 버전 또는 다른 장치에서 측정된 속도 성능은 부록 A에 설명되어 있습니다.
3.2. Comparisons
이 작업의 목표가 산업 응용을 위한 네트워크 구축이라는 점을 고려하여, 우리는 FLOPs나 파라미터 수보다는 배포 후 모든 모델의 속도 성능, 즉 처리량(FPS, 배치 크기 1 또는 32에서)과 GPU 지연 시간에 주로 초점을 맞춥니다. 우리는 YOLOv5 [10], YOLOX [7], PP-YOLOE [45] 및 YOLOv7 [42]을 포함한 YOLO 시리즈의 최신 감지기들과 YOLOv6를 비교합니다. 모든 공식 모델의 속도 성능은 동일한 Tesla T4 GPU에서 FP16 정밀도로 TensorRT [28]를 사용하여 테스트합니다. YOLOv7-Tiny의 성능은 입력 크기 416 및 640에서 공개된 코드 및 가중치에 따라 재평가됩니다. 결과는 표 1 및 그림 1에 나와 있습니다. YOLOv5-N/YOLOv7-Tiny (입력 크기=416)과 비교하여, 우리의 YOLOv6-N은 각각 7.9%/2.6%의 향상을 보였습니다. 또한, 처리량과 지연 시간 모두에서 최고의 속도 성능을 제공합니다. YOLOX-S/PPYOLOE-S와 비교할 때, YOLOv6-S는 AP를 3.0%/0.4% 향상시키면서 더 높은 속도를 제공합니다. 우리는 YOLOv5-S와 YOLOv7-Tiny(입력 크기=640)와 YOLOv6-T를 비교했을 때, 우리의 방법이 2.9% 더 정확하고 배치 크기 1에서 73/25 FPS 더 빠릅니다. YOLOv6-M은 유사한 속도에서 YOLOv5-M보다 4.2% 높은 AP를 기록하며, 더 높은 속도에서 YOLOX-M/PPYOLOE-M보다 2.7%/0.6% 더 높은 AP를 달성합니다. 또한, 이는 YOLOv5-L보다 더 정확하고 빠릅니다. YOLOv6-L은 동일한 지연 시간 제약에서 YOLOX-L/PPYOLOE-L보다 2.8%/1.1% 더 정확합니다. 우리는 SiLU를 ReLU로 교체한 더 빠른 버전의 YOLOv6-L(YOLOv6-L-ReLU)을 추가로 제공합니다. 이는 8.8ms의 지연 시간으로 51.7% AP를 달성하며, 정확성과 속도 모두에서 YOLOX-L/PPYOLOE-L/YOLOv7을 능가합니다.
3.3. Ablation Study
3.3.1 Network
Backbone and neck
우리는 백본과 넥에서 단일 경로 구조와 다중 분기 구조의 영향, 그리고 CSPStackRep 블록의 채널 계수(CC)를 탐구합니다. 이 부분에서 설명된 모든 모델은 라벨 할당 전략으로 TAL을, 분류 손실로 VFL을, 회귀 손실로는 GIoU와 DFL을 채택합니다. 결과는 표 2에 나와 있습니다. 우리는 모델 크기에 따라 최적의 네트워크 구조가 달라져야 한다는 것을 발견했습니다.
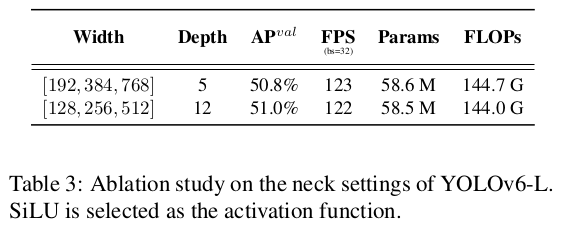
YOLOv6-N의 경우, 단일 경로 구조가 다중 분기 구조보다 정확도와 속도에서 모두 우수합니다. 단일 경로 구조는 다중 분기 구조보다 더 많은 FLOPs와 파라미터를 가지고 있지만, 상대적으로 낮은 메모리 사용량과 더 높은 병렬 처리도로 인해 더 빠르게 실행될 수 있습니다. YOLOv6-S의 경우, 두 가지 블록 스타일이 유사한 성능을 보입니다. 더 큰 모델의 경우, 다중 분기 구조가 정확도와 속도에서 더 나은 성능을 발휘합니다. 그리고 우리는 YOLOv6-M에서는 2/3의 채널 계수를, YOLOv6-L에서는 1/2의 채널 계수를 가진 다중 분기 구조를 최종적으로 선택합니다. 또한, 우리는 YOLOv6-L에서 넥의 너비와 깊이의 영향을 연구했습니다. 표 3의 결과는, 유사한 속도에서 얇은 넥이 넓고 얕은 넥보다 0.2% 더 나은 성능을 보인다는 것을 보여줍니다.
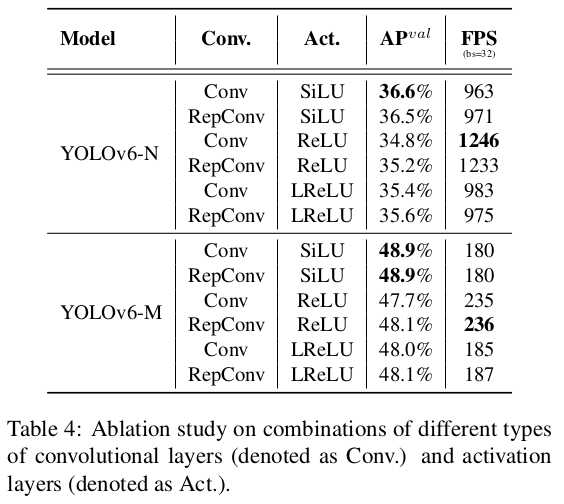
Combinations of convolutional layers and activation functions
YOLO 시리즈는 ReLU [27], LReLU [25], Swish [31], SiLU [4], Mish [26] 등 광범위한 활성화 함수를 채택했습니다. 이 활성화 함수들 중 SiLU가 가장 많이 사용됩니다. 일반적으로 SiLU는 더 나은 정확도를 제공하며, 추가적인 계산 비용을 많이 발생시키지 않습니다. 그러나 산업적 응용, 특히 TensorRT [28] 가속화를 사용하는 모델 배포의 경우, ReLU는 합성곱과의 융합으로 인해 더 큰 속도 이점을 제공합니다. 게다가, 우리는 더 나은 절충을 달성하기 위해, 다양한 크기의 네트워크에서 RepConv/일반 합성곱(Conv)과 ReLU/SiLU/LReLU의 조합의 효과를 추가로 검증했습니다. 표 4에서 보듯이, Conv와 SiLU의 조합이 정확도에서 가장 좋은 성능을 보이며, RepConv와 ReLU의 조합이 더 나은 절충을 달성합니다. 우리는 지연 시간에 민감한 응용에서 RepConv와 ReLU의 조합을 사용할 것을 제안합니다. 우리는 더 높은 추론 속도를 위해 YOLOv6-N/T/S/M에서 RepConv/ReLU 조합을 사용하고, 큰 모델인 YOLOv6-L에서는 훈련을 가속화하고 성능을 향상시키기 위해 Conv/SiLU 조합을 사용하기로 결정했습니다.
Miscellaneous design
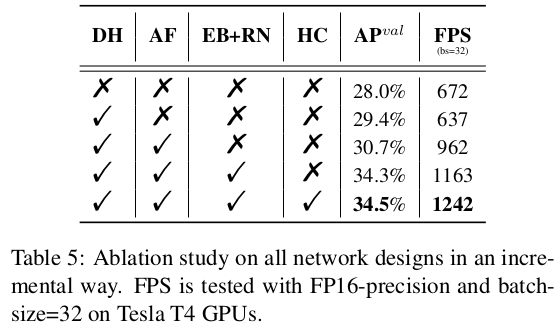
우리는 섹션 2.1에서 언급된 다른 네트워크 부분에 대해 YOLOv6-N을 기반으로 일련의 소거 실험(ablation)을 수행했습니다. 우리는 YOLOv5-N을 기준선으로 선택하고, 다른 구성 요소를 점진적으로 추가했습니다. 결과는 표 5에 나와 있습니다. 먼저, 분리된 헤드(DH)를 사용한 경우, 모델의 정확도가 1.4% 향상되었고, 시간 비용은 5% 증가했습니다. 둘째로, 우리는 앵커 프리(anchor-free) 패러다임이 3배 적은 사전 정의된 앵커를 사용하여 앵커 기반 패러다임보다 51% 더 빠르며, 이는 출력의 차원 감소를 가져온다는 것을 확인했습니다. 또한, 백본(EfficientRep Backbone)과 넥(Rep-PAN neck)의 통합 수정(EB+RN)이 3.6%의 AP 개선과 21% 더 빠른 속도를 제공합니다. 마지막으로, 최적화된 분리형 헤드(HC)는 각각 정확도에서 0.2% AP와 속도에서 6.8% FPS 향상을 가져옵니다.
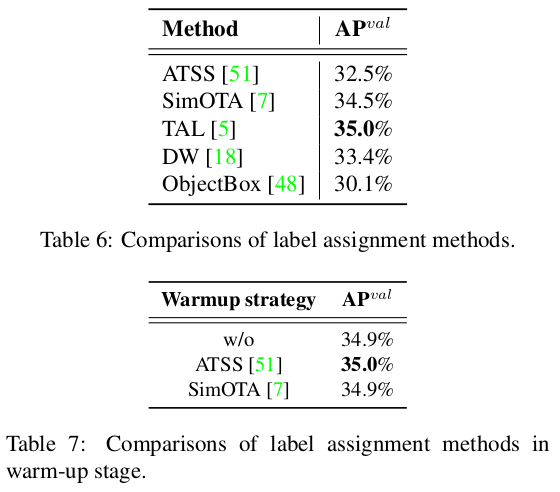
3.3.2 Label Assignment
표 6에서, 우리는 주류 라벨 할당 전략의 효과를 분석합니다. 실험은 YOLOv6-N에서 수행되었습니다. 예상대로, 우리는 SimOTA와 TAL이 가장 우수한 두 가지 전략임을 확인했습니다. ATSS와 비교했을 때, SimOTA는 AP를 2.0% 증가시킬 수 있으며, TAL은 SimOTA보다 0.5% 높은 AP를 제공합니다. TAL의 안정적인 훈련과 더 나은 정확도 성능을 고려하여, 우리는 TAL을 라벨 할당 전략으로 채택합니다.
추가적으로, TOOD [5]의 구현은 초기 훈련 에포크 동안 ATSS [51]을 워밍업 라벨 할당 전략으로 채택합니다. 우리는 워밍업 전략을 유지하면서, 추가로 탐색을 진행했습니다. 세부 사항은 표 7에 나와 있으며, 워밍업 없이 또는 다른 전략(i.e., SimOTA)으로 워밍업된 경우에도 유사한 성능을 달성할 수 있음을 확인할 수 있습니다.
3.3.3 Loss functions
객체 탐지 프레임워크에서 손실 함수는 분류 손실, 박스 회귀 손실 및 선택적 객체 손실로 구성되며, 다음과 같이 공식화할 수 있습니다:
\[\begin{equation} L_{det} = L_{cls}+ \lambda L_{reg} + \mu L_{obj} \end{equation}\]여기서 $L_{cls}$, $L_{reg}$, $L_{obj}$ 는 각각 분류 손실, 회귀 손실 및 객체 손실을 나타내며, $\lambda$ 와 $\mu$ 는 하이퍼파라미터입니다.
이 하위 섹션에서는 YOLOv6에서 각 손실 함수를 평가합니다. 달리 명시되지 않는 한, YOLOv6-N, YOLOv6-S 및 YOLOv6-M의 기준치는 각각 TAL, Focal Loss 및 GIoU Loss로 훈련된 35.0%, 42.9% 및 48.0%입니다.
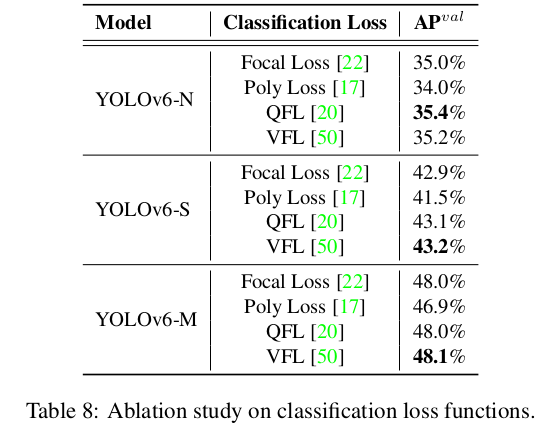
Classification Loss
우리는 YOLOv6-N/S/M에서 Focal Loss [22], Poly loss [17], QFL [20] 및 VFL [50]을 실험합니다. 표 8에서 볼 수 있듯이, VFL은 Focal Loss와 비교하여 YOLOv6-N/S/M에서 각각 0.2%/0.3%/0.1%의 AP 향상을 가져옵니다. 우리는 VFL을 분류 손실 함수로 선택했습니다.
Regression Loss
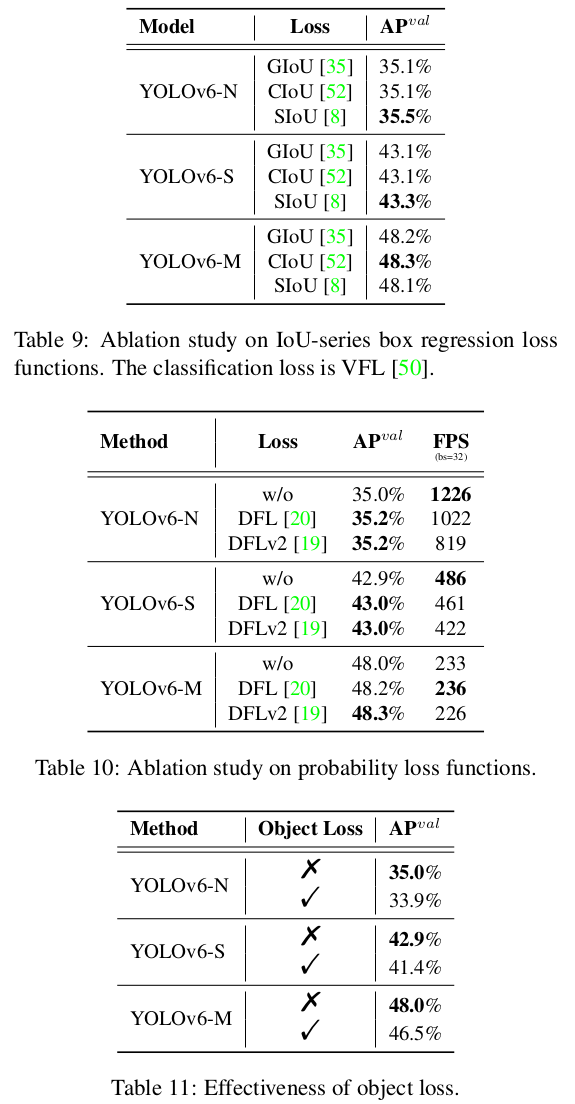
IoU 계열과 확률 손실 함수는 YOLOv6-N/S/M에서 실험됩니다. 최신 IoU 계열 손실이 YOLOv6-N/S/M에 사용됩니다. 표 9의 실험 결과는 SIoU Loss가 YOLOv6-N 및 YOLOv6-T에서 다른 손실들보다 우수하며, CIoU Loss는 YOLOv6-M에서 더 나은 성능을 보임을 보여줍니다. 확률 손실의 경우, 표 10에 나와 있는 것처럼 DFL을 도입하면 YOLOv6-N/S/M에서 각각 0.2%/0.1%/0.2%의 성능 향상을 얻을 수 있습니다. 그러나 소형 모델의 경우 추론 속도가 크게 영향을 받습니다. 따라서 DFL은 YOLOv6-M/L에만 도입됩니다.
Object Loss
객체 손실은 표 11에 나와 있듯이 YOLOv6에서도 실험되었습니다. 표 11에서 볼 수 있듯이 객체 손실은 YOLOv6-N/S/M 네트워크에 부정적인 영향을 미치며, YOLOv6-N에서 최대 1.1% AP가 감소합니다. 부정적인 결과는 TAL에서 객체 분기와 다른 두 분기 간의 충돌에서 비롯될 수 있습니다. 특히, 훈련 단계에서 예측된 상자와 실제 상자 간의 IoU, 그리고 분류 점수가 결합되어 라벨 할당의 기준으로 사용됩니다. 그러나 도입된 객체 분기는 정렬할 작업 수를 두 개에서 세 개로 늘려 명백하게 어려움을 증가시킵니다. 실험 결과와 이 분석을 바탕으로, 객체 손실은 YOLOv6에서 폐기됩니다.
3.4 Industry-handy improvements
More training epochs
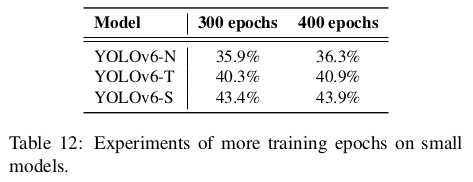
실제로 더 많은 훈련 에포크는 정확도를 더 높이는 간단하고 효과적인 방법입니다. 300 에포크와 400 에포크 동안 훈련된 작은 모델의 결과는 표 12에 나와 있습니다. 우리는 더 긴 에포크로 훈련하면 YOLOv6-N, T, S에서 각각 0.4%, 0.6%, 0.5%의 AP 향상을 크게 높인다는 것을 관찰했습니다. 허용 가능한 비용과 얻어진 이득을 고려할 때, YOLOv6에 대해 400 에포크로 훈련하는 것이 더 나은 수렴 방법이라는 것을 제안합니다.
Self-distillation
우리는 YOLOv6-L에서 제안된 자기 증류 방법을 검증하기 위해 상세한 실험을 수행했습니다. 표 13에서 볼 수 있듯이, 분류 브랜치에만 자기 증류를 적용하면 0.4% AP 향상을 가져올 수 있습니다. 게다가, 우리는 박스 회귀 작업에 자기 증류를 수행하여 0.3% AP 향상을 달성했습니다. 가중치 감소를 도입하면 모델이 0.6% AP 향상을 달성합니다.

Gray border of images
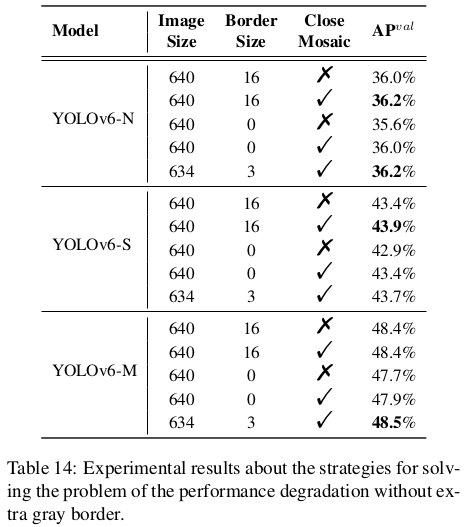
섹션 2.4.3에서 우리는 추가적인 회색 경계선 없이 성능 저하 문제를 해결하기 위한 전략을 소개합니다. 실험 결과는 표 14에 나와 있습니다. 이 실험에서 YOLOv6-N과 YOLOv6-S는 400 에포크 동안, YOLOv6-M은 300 에포크 동안 훈련되었습니다. 회색 경계를 제거할 때, YOLOv6-N/S/M의 정확도가 모자이크 페이딩 없이 각각 0.4%/0.5%/0.7% 감소하는 것을 관찰할 수 있습니다. 그러나 모자이크 페이딩을 적용하면 성능 저하가 각각 0.2%/0.5%/0.5%로 줄어들며, 이로부터 한편으로는 성능 저하 문제가 완화된다는 것을 알 수 있습니다. 한편, 작은 모델(YOLOv6-N/S)의 정확도는 회색 경계를 패딩하든 하지 않든 간에 향상됩니다. 게다가 우리는 입력 이미지를 634x634로 제한하고 가장자리에 3픽셀 너비의 회색 경계를 추가합니다(추가 결과는 부록 C에서 확인할 수 있습니다). 이 전략으로 최종 이미지의 크기는 예상대로 640x640입니다. 표 14의 결과는 최종 이미지 크기가 672에서 640으로 줄어들었을 때 YOLOv6-N/S/M의 최종 성능이 각각 0.2%/0.3%/0.1% 더 정확하다는 것을 나타냅니다.
3.5. Quantization Results
우리는 YOLOv6-S를 예시로 하여 양자화 방법을 검증합니다. 다음 실험은 두 가지 릴리즈 버전에서 진행됩니다. 베이스라인 모델은 300 에포크 동안 훈련되었습니다.
3.5.1 PTQ
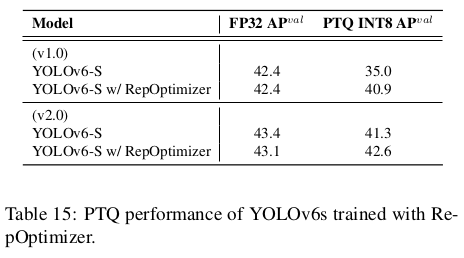
모델이 RepOptimizer로 훈련될 때 평균 성능이 상당히 향상됩니다. 표 15를 참조하세요. RepOptimizer는 일반적으로 더 빠르고 거의 동일한 성능을 보입니다.
3.5.2 QAT
v1.0에서 우리는 섹션 2.5.2에서 얻은 민감하지 않은 레이어에 가짜 양자화를 적용하여 양자화 인식 훈련을 수행하고 이를 부분 QAT라고 부릅니다. 우리는 결과를 표 16에서 전체 QAT와 비교합니다. 부분 QAT는 약간 감소한 처리량과 함께 더 나은 정확도를 제공합니다.

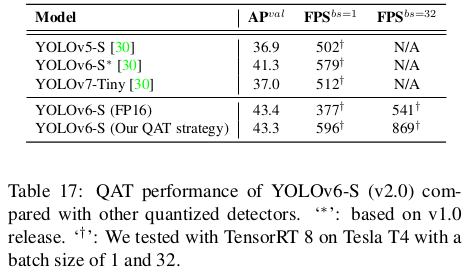
v2.0 릴리즈에서 양자화 민감 레이어를 제거한 덕분에, 우리는 RepOptimizer로 훈련된 YOLOv6-S에 대해 직접 전체 QAT를 사용합니다. 우리는 그래프 최적화를 통해 삽입된 양자화를 제거하여 더 높은 정확도와 더 빠른 속도를 얻습니다. 우리는 PaddleSlim의 증류 기반 양자화 결과를 표 17에서 비교합니다. 우리의 양자화된 YOLOv6-S 버전이 가장 빠르고 가장 정확하다는 점을 주목하세요. 그림 1도 참조하세요.
4. Conclusion
요약하자면, 지속적인 산업적 요구를 염두에 두고 우리는 YOLOv6의 현재 형태를 제시하며, 최신 객체 검출기의 구성 요소에 대한 모든 발전을 신중하게 검토하고, 동시에 우리의 생각과 실천을 주입하였습니다. 그 결과는 다른 사용 가능한 실시간 검출기들보다 정확도와 속도 모두에서 뛰어납니다. 산업 배포의 편의를 위해, 우리는 YOLOv6에 맞춤형 양자화 방법을 제공하여 즉시 사용할 수 있는 빠른 검출기를 제공합니다. 우리는 학문적 및 산업적 커뮤니티의 탁월한 아이디어와 노력에 진심으로 감사드립니다. 미래에는 더 높은 기준과 더욱 까다로운 시나리오를 충족시키기 위해 이 프로젝트를 계속 확장할 것입니다.
Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, Yiduo Li, Bo Zhang, Yufei Liang, Linyuan Zhou, Xiaoming Xu, Xiangxiang Chu, Xiaoming Wei, Xiaolin Wei YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications

댓글남기기