

개요
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors 의 얕은 리뷰 포스팅. YOLOv10 리뷰 후 YOLOv1, YOLOv2, YOLOv3, YOLOv4, Scaled-YOLOv4 와 YOLOv6 그 다음 버전으로 리뷰한다. YOLOv5 는 아쉽게도 논문이 없다. 소스코드는 공개되어 있어 분석을 못할 것은 아니지만 그러기엔 쉽지 않다.
YOLOv7은 실시간 객체 감지 모델의 실시간 성과 정확도를 전부 제고하기 위해 두가지에 중점을 둔다. 하나는 모델의 재파라미터화(re-parametization)이고 다른 하나는 동적 라벨링 할당이다. 이와 관련되어 coarse-to-fine lead guided label assignment라는 새로운 라벨 할당 방법을 제안한다. 또한 이와 관련되어 생기는 새로운 문제점들과 그 해결방법에 대한 논의를 담는다.
그리고 이러한 제안 방법들을 추론이 아닌 학습에 중점을 맞춰 trainable bag-of-freebies로 지칭한다. 학습 및 훈련 비용은 일부 늘어나지만 추론 비용이 증가하지 않도록 적용한다.
E-ELAN
- 본문의 그림 2에 등장하는 레이어 구조로 다양한 층의 특징을 효율적으로 학습하기 위하여 설계한 네트워크 레이어 구조이다.
- 효율적인 계층 통합을 통해 네트워크의 학습 효율성을 높이는 것을 목표로 한다. 여러 계층의 피쳐 맵을 효과적으로 결합하여 다양한 수준의 정보를 통합한다.
- 기존의 ELAN 구조보다 더 복잡한 문제를 해결하고 학습의 효율성을 높이기 위해 그룹 컨볼루션, 채널 혼합 등의 기법을 도입하여 개선하였다.
- 또한 E-ELAN은 피쳐 맵 결합력을 강화하고 실시간 성능을 극대화 하기 위해 복잡한 계산을 최소화하도록 설계하였다. 백본과 넥 구조에 걸쳐 사용된다.
Model Scaling
- 엣지 GPU, 일반 GPU, 클라우드 수준의 GPU에서 다양하게 돌아가도록 모델 아키텍쳐의 다양한 스케일을 연구하였다.
- 너비(Width), 깊이(Depth), 해상도(Resolution)을 조정시키는 Compound Scaling 기법을 사용하여 성능을 유지하면서 파라미터 수와 연산량을 효율적으로 조정한다.
Coarse-to-fine lead guided label assignment
- 학습 과정에서 라벨의 T/F를 판단하는 과정을 유연하게 적용하기 위한 동적 라벨링 기법이다.
- 느슨한 기준으로 생성된 라벨인 Coarse Label, 엄격한 기준의 Fine Label 2가지의 이중 라벨링을 사용한다.
- Coarse Label은 더 많은 그리드를 Positive sample로 처리하며 보조 헤드(auxiliary head)에서 활용된다.
- Fine Label은 최종 예측을 담당하는 리드 헤드(Lead head)에 활용된다.
- 리드 헤드의 예측 결과를 기반으로 라벨을 생성하고, 이 라벨을 보조 헤드와 리드 헤드 모두의 학습에 활용한다.
- 리드 헤드의 학습 내용을 보조 헤드에 공유하여 잔여 정보를 같이 활용하여 학습할 수 있도록 한다.
- 말 그대로 보조 헤드의 역할은 실제 추론에 사용하는 것은 아니지만 학습 시 리드 헤드와 상호 보완적으로 학습의 효율성을 높이는 것이다.
- 이를 통해 라벨 할당 과정에서 coarse-to-fine 방식으로 접근하면 초기에는 넓은 범위를 보다가, 이후 정밀하게 다듬어지는 성능의 최적화를 달성할 수 있다.
Re-parameterization
- 일반적인 의미에서 재파라미터화는 모델의 성능을 최적화 하기위해 학습과정과 추론 과정에서 모델의 구조를 다르게 사용하는 기법으로 이해하면 편하다.
- 일반적으로 추론단계의 모델 구조가 학습 과정에서의 모델구조보다 더 단순하다. 파라미터 수를 유지하나 연산량을 줄여서 추론 속도를 올리는 기법 등을 활용한다.
- YOLOv7에서는 다양한 합성곱(Conv) 레이어를 하나로 합치고, 복잡한 블록을 단순화 하는 방식으로 재파라미터화 기술을 적용한다.
- 학습단계에서의 복잡한 구조는 다양한 특징들을 반영한 고성능의 학습을 가능하게하고, 추론 시의 단순화된 구조는 메모리 사용을 줄이고, 추론 속도를 향상 시킨다.
결론
YOLOv7 논문이 나온 2022년 해당 시기에는 여러 도멩니에서 트랜스포머 기반의 고성능 아키텍쳐들이 날고 기던 시기다. 그 안에서 실시간 연산 및 성능에 대한 효율성이 뒤쳐지지 않는 좋은 방법론을 제안했다고 생각한다. 물론 SOTA 모델만 보면 DINO, Swin 기반의 모델 등 메트릭이 높은 모델들이 있지만, 이를 실시간 어플리케이션에 활용한다는 것은 또 다른 이야기다. 그런 관점에서 YOLO 시리즈의 발전은 볼수록 경이롭다.
번역
Abstract
YOLOv7은 5 FPS에서 160 FPS 범위에서 속도와 정확도 모두에서 모든 알려진 객체 검출기를 능가하며, GPU V100에서 30 FPS 이상인 모든 알려진 실시간 객체 검출기 중에서 56.8% AP로 가장 높은 정확도를 가집니다. YOLOv7-E6 객체 검출기(56 FPS V100, 55.9% AP)는 transformer 기반 검출기인 SWIN-L Cascade-Mask R-CNN (9.2 FPS A100, 53.9% AP)보다 속도에서 509%, 정확도에서 2% 더 우수하며, convolutional 기반 검출기인 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP)보다 속도에서 551%, 정확도에서 0.7% AP 더 우수합니다. 또한 YOLOv7은 YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B 및 많은 다른 객체 검출기들보다 속도와 정확도에서 더 우수합니다. 게다가, 우리는 다른 데이터셋이나 사전 학습된 가중치를 사용하지 않고 MS COCO 데이터셋만을 사용하여 처음부터 YOLOv7을 훈련시켰습니다. 소스 코드는 https://github.com/WongKinYiu/yolov7에서 공개되었습니다.
1. Introduction
실시간 객체 검출은 컴퓨터 비전에서 매우 중요한 주제로, 종종 컴퓨터 비전 시스템의 필수 구성 요소로 작용합니다. 예를 들어, 다중 객체 추적, 자율 주행, 로봇 공학, 의료 이미지 분석 등이 있습니다. 실시간 객체 검출을 실행하는 컴퓨팅 장치는 보통 모바일 CPU나 GPU, 그리고 주요 제조업체에서 개발한 다양한 신경 처리 장치(NPU)를 포함합니다. 예를 들어, Apple의 neural engine, Intel의 neural compute stick, Nvidia의 Jetson AI 엣지 장치, Google의 엣지 TPU, Qualcomm의 신경 처리 엔진, MediaTek의 AI 처리 장치, 그리고 Kneron의 AI SoCs 등이 모두 NPU에 해당합니다. 위에서 언급한 일부 엣지 장치들은 기본 합성곱, 깊이별 합성곱, 또는 MLP 연산과 같은 다양한 연산 속도를 높이는 데 중점을 둡니다. 이 논문에서 우리가 제안한 실시간 객체 검출기는 엣지부터 클라우드까지 모바일 GPU와 GPU 장치를 모두 지원할 수 있기를 바랍니다.
최근 몇 년 동안, 실시간 객체 검출기는 여전히 다양한 엣지 장치에 맞춰 개발되고 있습니다. 예를 들어, MCUNet와 NanoDet의 개발은 저전력 단일 칩을 생산하고 엣지 CPU에서 추론 속도를 향상시키는 데 중점을 두었습니다. YOLOX와 YOLOR과 같은 방법들은 다양한 GPU의 추론 속도를 향상시키는 데 중점을 둡니다. 최근에는 실시간 객체 검출기의 개발이 효율적인 아키텍처 설계에 집중되고 있습니다. CPU에서 사용할 수 있는 실시간 객체 검출기는 주로 MobileNet, ShuffleNet, 또는 GhostNet을 기반으로 설계됩니다. 또 다른 주류 실시간 객체 검출기는 GPU용으로 개발되며, 주로 ResNet, DarkNet, 또는 DLA를 사용하고, 이후 CSPNet 전략을 사용하여 아키텍처를 최적화합니다. 이 논문에서 제안하는 방법의 개발 방향은 현재 주류 실시간 객체 검출기와 다릅니다. 아키텍처 최적화 외에도, 우리가 제안한 방법들은 학습 과정의 최적화에 중점을 둘 것입니다. 우리의 중점은 객체 검출의 정확도를 향상시키기 위해 훈련 비용을 강화할 수 있는 일부 최적화된 모듈과 최적화 방법에 있을 것이지만, 추론 비용은 증가시키지 않을 것입니다. 우리는 제안된 모듈과 최적화 방법을 trainable bag-of-freebies라고 부릅니다.
최근 모델 재파라미터화와 동적 레이블 할당이 네트워크 학습과 객체 검출에서 중요한 주제로 떠오르고 있습니다. 주로 위의 새로운 개념들이 제안된 이후, 객체 검출기의 학습에는 많은 새로운 문제가 발생합니다. 이 논문에서는 우리가 발견한 몇 가지 새로운 문제를 제시하고, 이를 해결하기 위한 효과적인 방법들을 고안할 것입니다. 모델 재파라미터화에 대해서는, 다양한 네트워크의 레이어에 적용 가능한 모델 재파라미터화 전략을 그래디언트 전파 경로의 개념과 함께 분석하고, 계획된 재파라미터화 모델을 제안합니다. 또한, 동적 레이블 할당 기술을 사용하여 다중 출력 레이어를 가진 모델의 학습 시 새로운 문제가 발생함을 발견할 때, 즉 “어떻게 서로 다른 분기 출력에 동적 목표를 할당할 것인가?”라는 문제에 대해, 우리는 coarse-to-fine lead guided label assignment라는 새로운 레이블 할당 방법을 제안합니다.
이 논문의 기여는 다음과 같이 요약됩니다: (1) 우리는 여러 가지 trainable bag-of-freebies을 설계하여, 실시간 객체 검출이 추론 비용을 증가시키지 않고도 검출 정확도를 크게 향상시킬 수 있도록 합니다; (2) 객체 검출 방법의 진화를 위해, 우리는 두 가지 새로운 문제, 즉 재파라미터화된 모듈이 원래 모듈을 어떻게 대체하는지, 그리고 동적 레이블 할당 전략이 서로 다른 출력 레이어에 할당을 어떻게 처리하는지를 발견했습니다. 또한, 이러한 문제에서 발생하는 어려움을 해결하기 위한 방법들도 제안합니다; (3) 우리는 파라미터와 계산을 효과적으로 활용할 수 있는 실시간 객체 검출기를 위한 “확장” 및 “복합 스케일링” 방법을 제안합니다; (4) 우리가 제안한 방법은 최첨단 실시간 객체 검출기의 약 40% 파라미터와 50% 계산을 효과적으로 줄일 수 있으며, 더 빠른 추론 속도와 더 높은 검출 정확도를 가집니다.
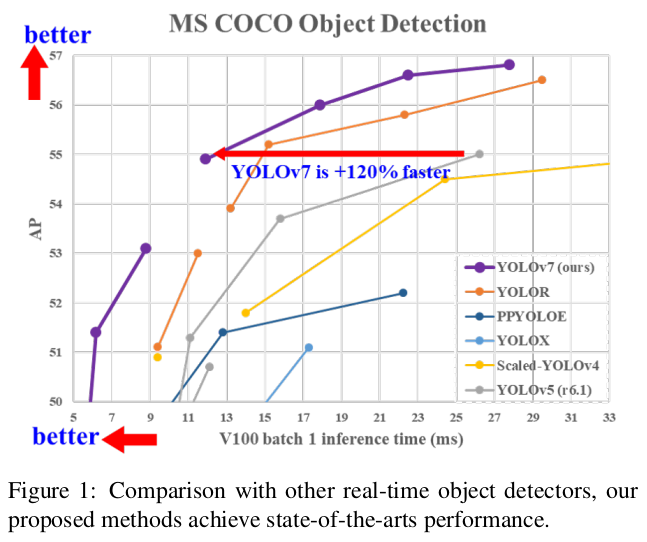
2. Related work
2.1. Real-time object detectors
현재 최첨단 실시간 객체 검출기는 주로 YOLO와 FCOS를 기반으로 하고 있습니다. 최첨단 실시간 객체 검출기가 되기 위해서는 보통 다음과 같은 특성이 필요합니다: (1) 더 빠르고 강력한 네트워크 아키텍처; (2) 더 효과적인 특징 통합 방법; (3) 더 정확한 검출 방법; (4) 더 견고한 손실 함수; (5) 더 효율적인 레이블 할당 방법; (6) 더 효율적인 학습 방법. 이 논문에서는 추가 데이터나 대형 모델을 요구하는 자기 지도 학습이나 지식 증류 방법을 탐구하려는 것이 아닙니다. 대신, 위에서 언급한 (4), (5), (6)와 관련된 최첨단 방법에서 파생된 문제들을 해결하기 위해 새로운 학습 가능한 무료 방법들을 설계할 것입니다.
2.2. Model re-parameterization
모델 재파라미터화 기술은 추론 단계에서 여러 계산 모듈을 하나로 병합합니다. 모델 재파라미터화 기술은 앙상블 기법으로 간주될 수 있으며, 이를 모듈 수준 앙상블과 모델 수준 앙상블의 두 가지 범주로 나눌 수 있습니다. 최종 추론 모델을 얻기 위한 모델 수준 재파라미터화의 두 가지 일반적인 방법이 있습니다. 하나는 서로 다른 학습 데이터를 사용하여 여러 동일한 모델을 학습하고, 여러 학습된 모델의 가중치를 평균화하는 것입니다. 다른 하나는 서로 다른 반복 횟수에서 모델의 가중치를 가중 평균화하는 것입니다. 모듈 수준 재파라미터화는 최근에 더 인기 있는 연구 주제입니다. 이 방법은 학습 중에 모듈을 여러 동일하거나 다른 모듈 분기로 분할하고, 추론 중에 여러 분기된 모듈을 완전히 동일한 모듈로 통합합니다. 그러나 제안된 모든 재파라미터화된 모듈이 다양한 아키텍처에 완벽하게 적용될 수 있는 것은 아닙니다. 이를 염두에 두고, 우리는 새로운 재파라미터화 모듈을 개발하고 다양한 아키텍처에 대한 관련 응용 전략을 설계했습니다.
2.3. Model scaling
모델 스케일링은 이미 설계된 모델을 크기를 조절하여 다양한 컴퓨팅 장치에 맞게 하는 방법입니다. 모델 스케일링 방법은 보통 입력 이미지의 크기, 레이어의 수, 채널의 수, 특징 피라미드의 단계 수와 같은 다양한 스케일링 요소를 사용하여 네트워크 파라미터 수, 계산량, 추론 속도, 정확도 사이에서 좋은 균형을 이루도록 합니다. 네트워크 아키텍처 검색(NAS)은 일반적으로 사용되는 모델 스케일링 방법 중 하나입니다. NAS는 복잡한 규칙을 정의하지 않고도 검색 공간에서 적절한 스케일링 요소를 자동으로 검색할 수 있습니다. NAS의 단점은 모델 스케일링 요소를 완성하는 데 매우 비싼 계산을 요구한다는 점입니다. 연구자는 스케일링 요소와 파라미터 및 연산량 사이의 관계를 분석하고, 몇 가지 규칙을 직접 추정하여 모델 스케일링에 필요한 스케일링 요소를 얻으려고 합니다. 문헌을 확인한 결과, 거의 모든 모델 스케일링 방법이 개별 스케일링 요소를 독립적으로 분석하고, 복합 스케일링 범주에서도 스케일링 요소를 독립적으로 최적화하는 것으로 나타났습니다. 그 이유는 대부분의 인기 있는 NAS 아키텍처가 상호 연관되지 않은 스케일링 요소를 다루기 때문입니다. 우리는 DenseNet이나 VoVNet과 같은 모든 연결 기반 모델들이 스케일링될 때 일부 레이어의 입력 폭이 변경됨을 관찰했습니다. 제안된 아키텍처는 연결 기반이기 때문에, 우리는 이 모델을 위한 새로운 복합 스케일링 방법을 설계해야 했습니다.
3. Architecture
3.1. Extended efficient layer aggregation networks
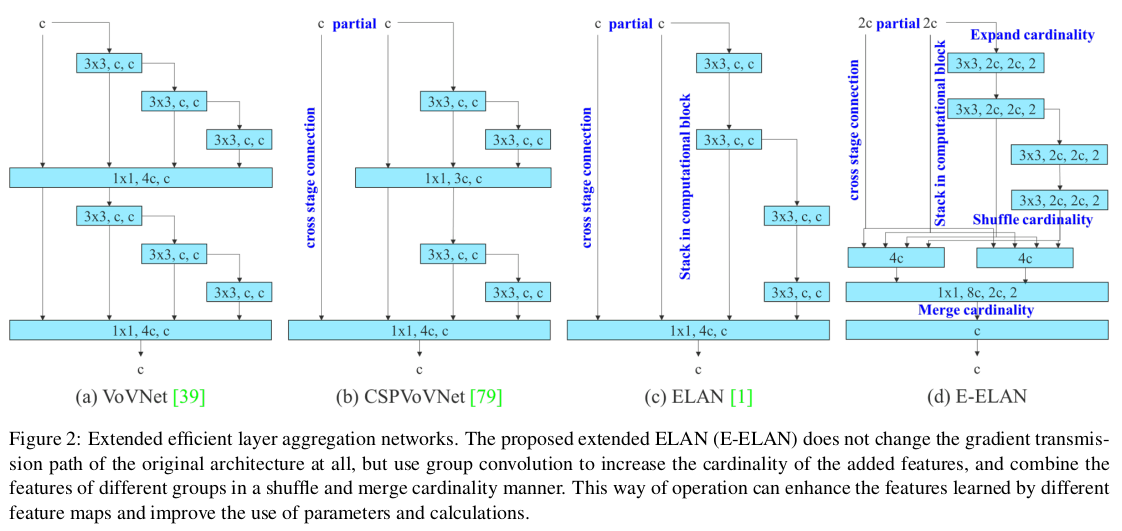
대부분의 효율적인 아키텍처 설계에 관한 문헌에서 주요 고려 사항은 파라미터 수, 계산량, 계산 밀도 이상이 아닙니다. Ma 등은 메모리 접근 비용의 특성에서 시작하여 입력/출력 채널 비율, 아키텍처의 가지 수, 요소별 연산이 네트워크 추론 속도에 미치는 영향을 분석했습니다. Dollár 등은 모델 스케일링을 수행할 때 활성화를 추가로 고려하여, 합성곱 층의 출력 텐서의 요소 수에 더 많은 고려를 두었습니다. 그림 2 (b)에 있는 CSPVoVNet의 설계는 VoVNet의 변형입니다. 앞서 언급한 기본 설계 문제를 고려하는 것 외에도, CSPVoVNet의 아키텍처는 그래디언트 경로를 분석하여 서로 다른 층의 가중치가 더 다양한 특징을 학습할 수 있도록 합니다. 위에서 설명한 그래디언트 분석 접근 방식은 추론을 더 빠르고 정확하게 만듭니다. 그림 2 (c)의 ELAN은 다음과 같은 설계 전략을 고려합니다 – “효율적인 네트워크를 어떻게 설계할 것인가?.” 그들은 결론을 내렸습니다: 가장 짧은 긴 그래디언트 경로를 제어함으로써, 더 깊은 네트워크가 효과적으로 학습하고 수렴할 수 있습니다. 이 논문에서 우리는 ELAN을 기반으로 한 확장 ELAN (E-ELAN)을 제안하며, 그 주요 아키텍처는 그림 2 (d)에 나와 있습니다.
대규모 ELAN에서 그래디언트 경로 길이와 계산 블록의 적층 수에 관계없이 안정된 상태에 도달했습니다. 계산 블록을 무한정으로 쌓으면 이 안정 상태가 파괴되고 파라미터 활용률이 감소할 수 있습니다. 제안된 E-ELAN은 확장, 셔플, 병합 기수를 사용하여 원래의 그래디언트 경로를 파괴하지 않고 네트워크의 학습 능력을 지속적으로 향상시킬 수 있는 능력을 달성합니다. 아키텍처 측면에서 E-ELAN은 계산 블록의 아키텍처만 변경되고, 전환 층의 아키텍처는 완전히 변경되지 않습니다. 우리의 전략은 그룹 합성곱을 사용하여 계산 블록의 채널과 기수를 확장하는 것입니다. 우리는 동일한 그룹 매개 변수와 채널 승수를 계산 층의 모든 계산 블록에 적용할 것입니다. 그런 다음, 각 계산 블록에 의해 계산된 특징 맵은 설정된 그룹 매개 변수에 따라 그룹으로 셔플된 다음 함께 연결됩니다. 이때, 각 특징 맵 그룹의 채널 수는 원래 아키텍처의 채널 수와 동일할 것입니다. 마지막으로, 병합 기수를 수행하기 위해 특징 맵 그룹을 추가합니다. 원래 ELAN 설계 아키텍처를 유지하는 것 외에도, E-ELAN은 다양한 계산 블록 그룹이 더 다양한 특징을 학습할 수 있도록 안내할 수 있습니다.
3.2. Model scaling for concatenation-based models
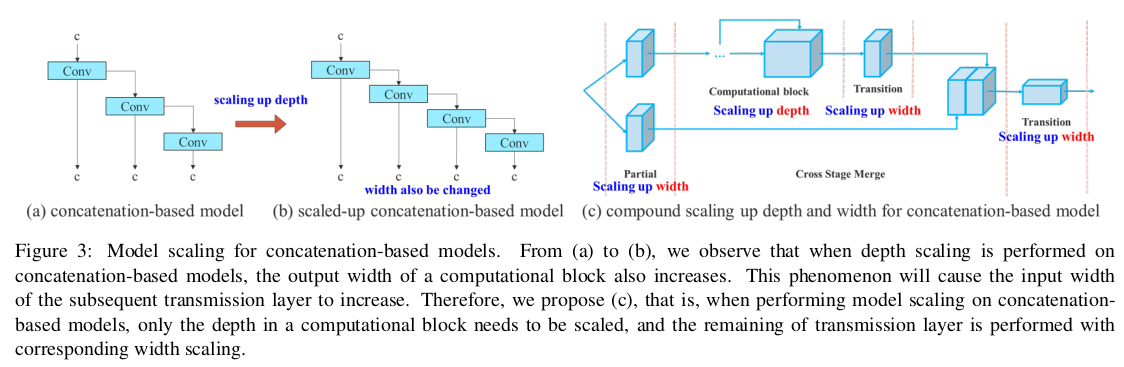
모델 스케일링의 주요 목적은 모델의 일부 속성을 조정하여 다른 추론 속도 요구를 충족시키기 위해 다양한 스케일의 모델을 생성하는 것입니다. 예를 들어 EfficientNet의 스케일링 모델은 너비, 깊이 및 해상도를 고려합니다. scaled-YOLOv4의 스케일링 모델은 단계를 조정하는 것입니다. Dollár 등은 너비와 깊이 스케일링을 수행할 때 바닐라 합성곱과 그룹 합성곱이 파라미터와 계산량에 미치는 영향을 분석하고, 이를 사용하여 해당 모델 스케일링 방법을 설계했습니다.
위의 방법들은 주로 PlainNet이나 ResNet과 같은 아키텍처에서 사용됩니다. 이러한 아키텍처들이 스케일 업 또는 스케일 다운을 수행할 때, 각 레이어의 인-디그리와 아웃-디그리가 변하지 않으므로, 각 스케일링 요소가 파라미터와 계산량에 미치는 영향을 독립적으로 분석할 수 있습니다. 그러나 이러한 방법들이 연결 기반 아키텍처에 적용되면, 깊이에 대해 스케일 업 또는 스케일 다운이 수행될 때, 연결 기반 계산 블록 바로 뒤에 있는 전환 층의 인-디그리가 감소하거나 증가함을 알 수 있습니다. 이는 그림 3 (a)와 (b)에 나타나 있습니다.
위의 현상으로부터, 우리는 연결 기반 모델의 경우 서로 다른 스케일링 요소를 별도로 분석할 수 없으며 함께 고려해야 함을 알 수 있습니다. 깊이를 스케일 업하는 예를 들어보면, 이러한 동작은 전환 층의 입력 채널과 출력 채널 간의 비율 변화를 초래하여 모델의 하드웨어 사용량 감소로 이어질 수 있습니다. 따라서 우리는 연결 기반 모델에 대한 해당 복합 모델 스케일링 방법을 제안해야 합니다. 계산 블록의 깊이 요소를 스케일링할 때, 우리는 그 블록의 출력 채널의 변화를 계산해야 합니다. 그런 다음, 전환 층에 동일한 변화를 가하여 너비 요소 스케일링을 수행할 것입니다. 결과는 그림 3 (c)에 나타나 있습니다. 우리가 제안한 복합 스케일링 방법은 초기 설계 시 모델이 가진 특성을 유지하고 최적의 구조를 유지할 수 있습니다.
4. Trainable bag-of-freebies
4.1. Planned re-parameterized convolution
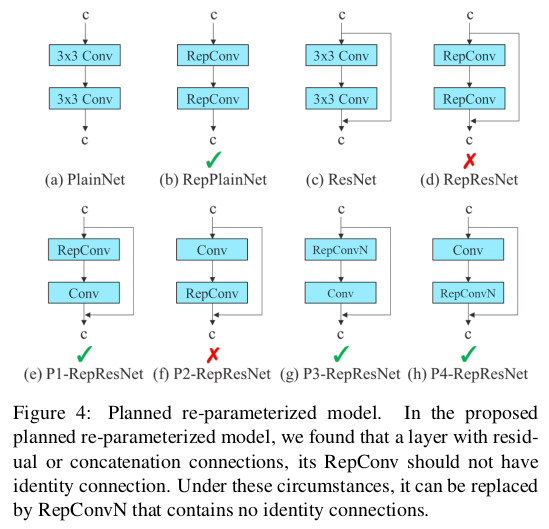
RepConv은 VGG에서 뛰어난 성능을 달성했지만, 이를 ResNet 및 DenseNet 등 다른 아키텍처에 직접 적용하면 정확도가 크게 감소합니다. 우리는 그래디언트 흐름 전파 경로를 사용하여 재파라미터화된 합성곱이 다양한 네트워크와 어떻게 결합되어야 하는지를 분석합니다. 또한 이에 따라 계획된 재파라미터화된 합성곱을 설계했습니다.
RepConv은 실제로 $3×3$ 합성곱, $1×1$ 합성곱, 그리고 아이덴티티 연결을 하나의 합성곱 층에 결합합니다. RepConv과 다른 아키텍처의 조합과 해당 성능을 분석한 결과, RepConv의 아이덴티티 연결이 ResNet의 잔차와 DenseNet의 연결을 파괴하여 다양한 특징 맵에 대한 그래디언트의 다양성을 제공합니다. 위의 이유로, 우리는 아이덴티티 연결이 없는 RepConv (RepConvN)을 사용하여 계획된 재파라미터화된 합성곱의 아키텍처를 설계합니다. 우리의 생각에서는, 잔차나 연결이 있는 합성곱 층이 재파라미터화된 합성곱으로 대체될 때 아이덴티티 연결이 없어야 합니다. 그림 4는 PlainNet과 ResNet에 사용된 우리가 설계한 “계획된 재파라미터화된 합성곱”의 예를 보여줍니다. 잔차 기반 모델과 연결 기반 모델에서의 완전한 계획된 재파라미터화된 합성곱 실험은 절단 연구 세션에서 제시될 것입니다.
4.2. Coarse for auxiliary and fine for lead loss
딥 슈퍼비전은 딥 네트워크 학습에서 자주 사용되는 기법입니다. 주요 개념은 네트워크의 중간 층에 추가 보조 헤드를 추가하고, 얕은 네트워크 가중치를 보조 손실로 안내하는 것입니다. ResNet 및 DenseNet과 같이 보통 잘 수렴하는 아키텍처에서도 딥 슈퍼비전은 여전히 많은 작업에서 모델의 성능을 크게 향상시킬 수 있습니다. 그림 5 (a)와 (b)는 각각 딥 슈퍼비전이 없는 경우와 있는 경우의 객체 검출기 아키텍처를 보여줍니다. 이 논문에서는 최종 출력을 담당하는 헤드를 리드 헤드, 학습을 보조하는 데 사용되는 헤드를 보조 헤드라고 부릅니다.
다음으로 라벨 할당 문제를 논의하고자 합니다. 과거에는 딥 네트워크 학습에서 라벨 할당이 보통 직접적으로 실제 값을 참조하고 주어진 규칙에 따라 강한 라벨을 생성했습니다. 그러나 최근 몇 년 동안 객체 검출을 예로 들면, 연구자들은 종종 네트워크의 예측 출력의 품질과 분포를 사용하고, 그런 다음 실제 값과 함께 고려하여 신뢰할 수 있는 소프트 라벨을 생성하기 위해 일부 계산 및 최적화 방법을 사용합니다. 예를 들어, YOLO는 경계 상자 회귀의 예측과 실제 값의 IoU를 객체성의 소프트 라벨로 사용합니다. 이 논문에서는 네트워크 예측 결과와 실제 값을 함께 고려한 다음 소프트 라벨을 할당하는 메커니즘을 “라벨 할당자”라고 부릅니다.
딥 슈퍼비전은 보조 헤드나 리드 헤드의 상황에 관계없이 목표 목적에 대해 학습되어야 합니다. 소프트 라벨 할당자 관련 기술을 개발하는 동안, 우리는 새로운 파생 문제를 우연히 발견했습니다. 즉, “보조 헤드와 리드 헤드에 소프트 라벨을 어떻게 할당할 것인가?” 우리의 지식에 따르면, 관련 문헌에서는 지금까지 이 문제를 탐구하지 않았습니다. 현재 가장 널리 사용되는 방법의 결과는 그림 5 (c)에 나와 있으며, 이는 보조 헤드와 리드 헤드를 분리한 다음 각자의 예측 결과와 실제 값을 사용하여 라벨 할당을 수행하는 것입니다. 이 논문에서 제안하는 방법은 리드 헤드 예측에 의해 보조 헤드와 리드 헤드를 모두 안내하는 새로운 라벨 할당 방법입니다. 즉, 리드 헤드 예측을 가이드로 사용하여 계층적인 라벨을 생성하고, 이를 각각 보조 헤드와 리드 헤드 학습에 사용합니다. 두 가지 제안된 딥 슈퍼비전 라벨 할당 전략은 각각 그림 5 (d)와 (e)에 나와 있습니다.
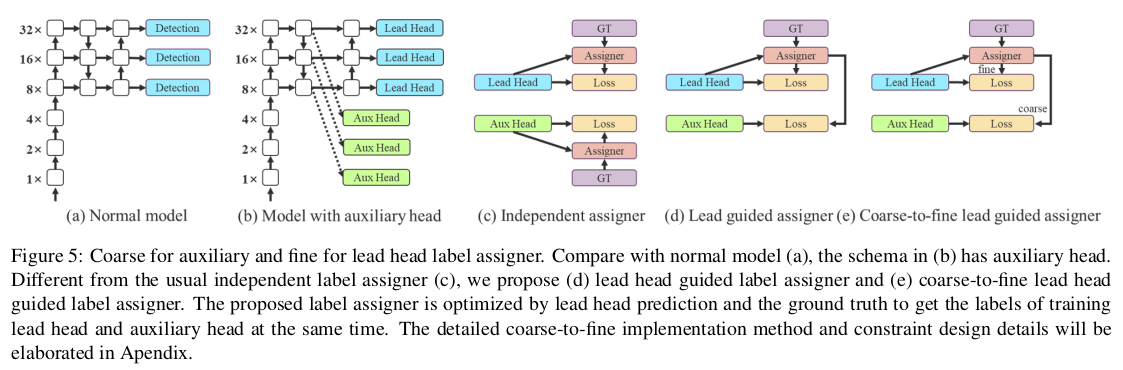
Lead head guided label assigner는 주로 리드 헤드의 예측 결과와 실제 값에 기반하여 계산되며, 최적화 과정을 통해 소프트 라벨을 생성합니다. 이 소프트 라벨 세트는 보조 헤드와 리드 헤드 모두의 목표 학습 모델로 사용됩니다. 이렇게 하는 이유는 리드 헤드가 상대적으로 강한 학습 능력을 가지고 있어, 여기서 생성된 소프트 라벨이 소스 데이터와 대상 간의 분포 및 상관 관계를 더 잘 나타낼 수 있어야 하기 때문입니다. 또한 이러한 학습을 일반화된 잔차 학습의 일종으로 볼 수 있습니다. 얕은 보조 헤드가 리드 헤드가 학습한 정보를 직접 학습하게 함으로써, 리드 헤드는 아직 학습되지 않은 잔차 정보를 학습하는 데 더 집중할 수 있게 됩니다.
Coarse-to-fine lead head guided label assigner도 리드 헤드의 예측 결과와 실제 값을 사용하여 소프트 라벨을 생성했습니다. 그러나 이 과정에서 우리는 두 가지 다른 소프트 라벨 세트, 즉 거친 라벨과 세밀 라벨을 생성합니다. 여기서 세밀 라벨은 리드 헤드 가이드 라벨 할당자에 의해 생성된 소프트 라벨과 동일하며, 거친 라벨은 양성 샘플 할당 과정의 제약을 완화하여 더 많은 그리드를 양성 대상으로 처리할 수 있도록 하여 생성됩니다. 그 이유는 보조 헤드의 학습 능력이 리드 헤드만큼 강하지 않기 때문에 학습해야 할 정보를 잃지 않도록 객체 검출 작업에서 보조 헤드의 재현율 최적화에 중점을 둘 것입니다. 리드 헤드의 출력에 대해서는, 높은 재현율 결과에서 높은 정밀도의 결과를 필터링하여 최종 출력으로 사용할 수 있습니다. 그러나 추가적인 거친 라벨의 가중치가 세밀 라벨의 가중치와 가깝다면, 최종 예측에서 나쁜 사전 확률을 생성할 수 있습니다. 따라서 이러한 추가적인 거친 양성 그리드가 적은 영향을 미치도록 하기 위해 디코더에 제약을 두어, 추가적인 거친 양성 그리드가 소프트 라벨을 완벽하게 생성하지 못하게 합니다. 위에서 언급한 메커니즘은 학습 과정에서 세밀 라벨과 거친 라벨의 중요성을 동적으로 조정할 수 있게 하여, 세밀 라벨의 최적화 가능한 상한이 항상 거친 라벨보다 높도록 만듭니다.
4.3. Other trainable bag-of-freebies
이 섹션에서는 몇 가지 학습 가능한 bag-of-freebies들을 나열하겠습니다. 이 bag-of-freebies들은 우리가 학습에 사용한 몇 가지 트릭이지만, 원래 개념은 우리가 제안한 것이 아닙니다. 이러한 무료 방법들의 학습 세부 사항은 부록에서 자세히 설명될 것입니다. 여기에는 (1) conv-bn-activation 토폴로지에서의 배치 정규화: 이 부분은 주로 배치 정규화 레이어를 합성곱 레이어에 직접 연결합니다. 이는 추론 단계에서 배치 정규화의 평균과 분산을 합성곱 레이어의 바이어스와 가중치에 통합하는 것을 목적으로 합니다. (2) YOLOR에서의 암묵적 지식: 이는 덧셈 및 곱셈 방식으로 합성곱 특징 맵과 결합됩니다. YOLOR의 암묵적 지식은 추론 단계에서 미리 계산하여 벡터로 단순화할 수 있습니다. 이 벡터는 이전 또는 이후의 합성곱 레이어의 바이어스 및 가중치와 결합될 수 있습니다. (3) EMA 모델: EMA는 mean teacher에서 사용되는 기술로, 우리 시스템에서는 최종 추론 모델로 EMA 모델을 사용합니다.
5. Experiments
5.1. Experimental setup
우리는 Microsoft COCO 데이터셋을 사용하여 실험을 수행하고 우리의 객체 검출 방법을 검증합니다. 모든 실험은 사전 학습된 모델을 사용하지 않았습니다. 즉, 모든 모델은 처음부터 학습되었습니다. 개발 과정에서 우리는 train 2017 세트를 사용하여 학습을 수행하였고, val 2017 세트를 사용하여 검증 및 하이퍼파라미터 선택을 수행하였습니다. 마지막으로, 우리는 test 2017 세트에서 객체 검출 성능을 보여주고, 최첨단 객체 검출 알고리즘과 비교합니다. 자세한 학습 파라미터 설정은 부록에 설명되어 있습니다.
우리는 엣지 GPU, 일반 GPU, 클라우드 GPU용 기본 모델을 설계했으며, 각각 YOLOv7-tiny, YOLOv7, YOLOv7-W6라고 부릅니다. 동시에, 우리는 다양한 서비스 요구 사항에 맞춰 모델 스케일링을 위한 기본 모델도 사용하여 다양한 유형의 모델을 얻습니다. YOLOv7의 경우, 우리는 넥에서 스택 스케일링을 수행하고, 제안된 복합 스케일링 방법을 사용하여 전체 모델의 깊이와 너비를 확장하여 YOLOv7-X를 얻습니다. YOLOv7-W6의 경우, 우리는 새롭게 제안된 복합 스케일링 방법을 사용하여 YOLOv7-E6와 YOLOv7-D6를 얻습니다. 또한, 우리는 YOLOv7-E6에 대해 제안된 E-ELAN을 사용하여 YOLOv7-E6E를 완성합니다. YOLOv7-tiny는 엣지 GPU 지향 아키텍처이기 때문에 leaky ReLU를 활성화 함수로 사용할 것입니다. 다른 모델의 경우, 우리는 SiLU를 활성화 함수로 사용합니다. 각 모델의 스케일링 요소에 대해서는 부록에서 자세히 설명할 것입니다.
5.2. Baselines
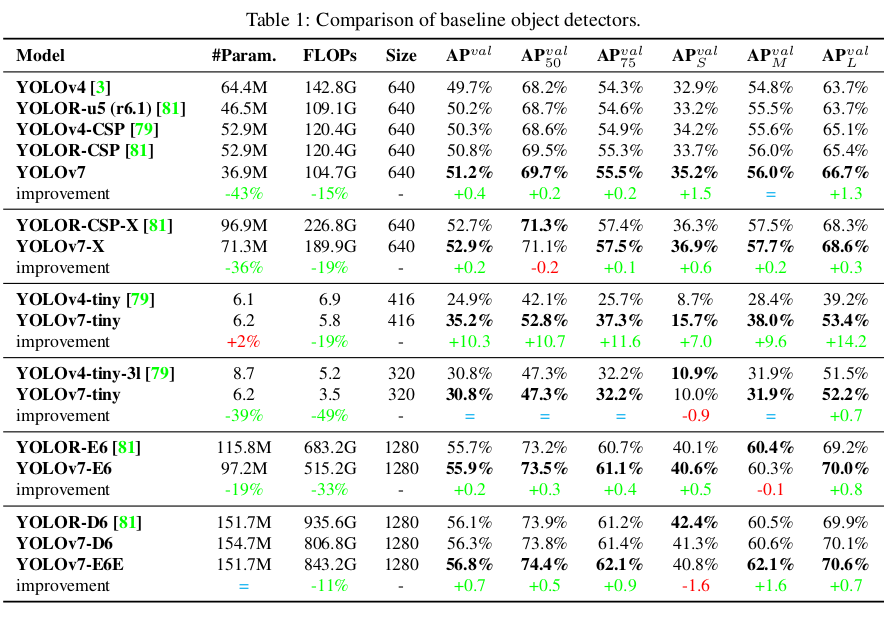
우리는 이전 버전의 YOLO와 최첨단 객체 검출기 YOLOR을 기준선으로 선택했습니다. 표 1은 제안된 YOLOv7 모델과 동일한 설정으로 학습된 기준선 모델의 비교를 보여줍니다.
결과에서 보면, YOLOv4와 비교했을 때 YOLOv7은 75% 적은 파라미터와 36% 적은 계산량을 가지며, 1.5% 더 높은 AP를 제공합니다. 최첨단 YOLOR-CSP와 비교했을 때, YOLOv7은 43% 적은 파라미터와 15% 적은 계산량을 가지며, 0.4% 더 높은 AP를 제공합니다. 작은 모델의 성능에서, YOLOv4-tiny-31과 비교했을 때 YOLOv7-tiny는 파라미터 수를 39% 줄이고 계산량을 49% 줄이지만, 동일한 AP를 유지합니다. 클라우드 GPU 모델에서는 파라미터 수를 19% 줄이고 계산량을 33% 줄이면서도 더 높은 AP를 유지할 수 있습니다.
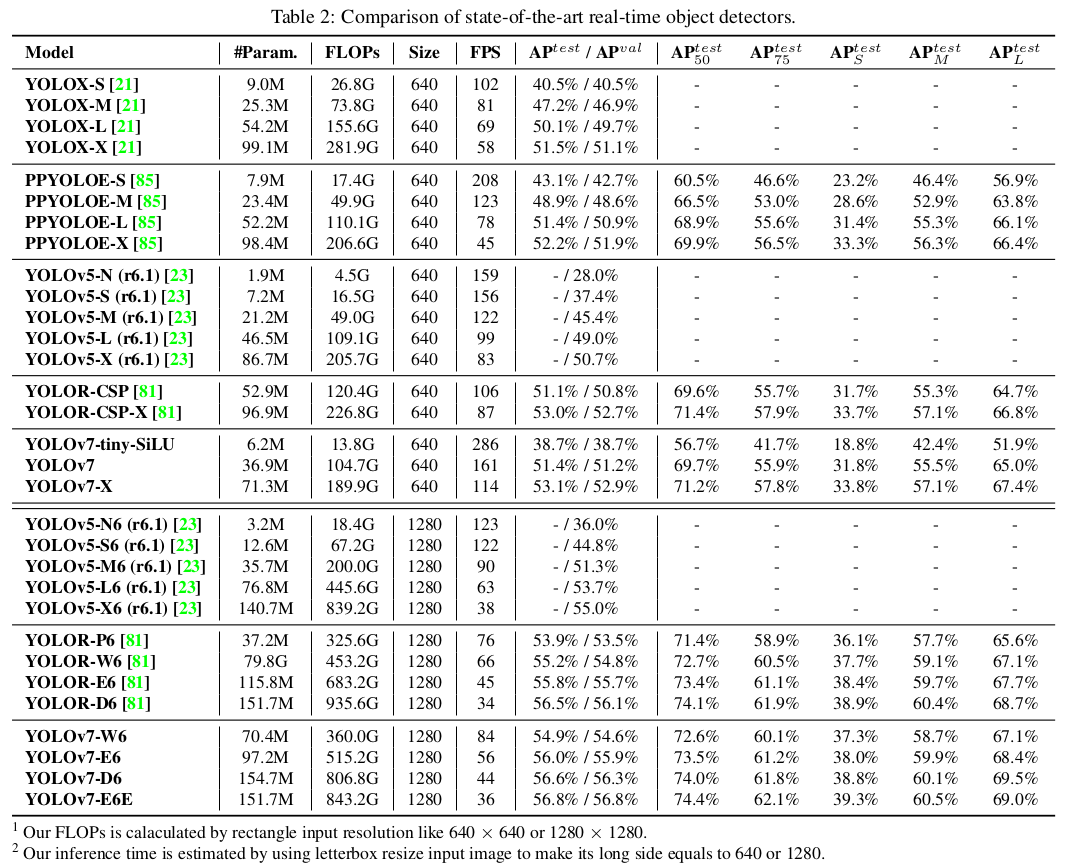
5.3. Comparison with state-of-the-arts
우리는 제안된 방법을 일반 GPU와 모바일 GPU용 최첨단 객체 검출기와 비교하며, 결과는 표 2에 나와 있습니다. 표 2의 결과에서 제안된 방법이 종합적으로 최고의 속도-정확도 균형을 가지고 있음을 알 수 있습니다. YOLOv7-tiny-SiLU와 YOLOv5-N (r6.1)을 비교하면, 우리의 방법은 127 fps 더 빠르고 AP에서 10.7% 더 정확합니다. 또한 YOLOv7은 161 fps의 프레임 속도에서 51.4%의 AP를 가지며, 동일한 AP를 가진 PPYOLOE-L은 프레임 속도가 78 fps에 불과합니다. 파라미터 사용 측면에서, YOLOv7은 PPYOLOE-L보다 41% 적습니다. YOLOv7-X와 99 fps의 추론 속도를 가진 YOLOv5-L (r6.1)을 비교하면, YOLOv7-X는 AP를 3.9% 향상시킬 수 있습니다. 비슷한 규모의 YOLOv5-X (r6.1)와 비교하면, YOLOv7-X의 추론 속도가 31 fps 더 빠릅니다. 또한, 파라미터 수와 계산량 측면에서 YOLOv7-X는 YOLOv5-X (r6.1)보다 파라미터 수를 22% 줄이고 계산량을 8% 줄이면서 AP를 2.2% 향상시킵니다.
입력 해상도 1280을 사용하여 YOLOv7과 YOLOR을 비교하면, YOLOv7-W6의 추론 속도는 YOLOR-P6보다 8 fps 더 빠르고, 검출율도 AP가 1% 증가합니다. YOLOv7-E6와 YOLOv5-X6 (r6.1)을 비교하면, 전자는 후자보다 AP가 0.9% 높고, 파라미터 수는 45% 적으며, 계산량은 63% 적고, 추론 속도는 47% 증가합니다. YOLOv7-D6는 YOLOv-E6와 비슷한 추론 속도를 가지지만, AP는 0.8% 향상됩니다. YOLOv7-E6E는 YOLOv-D6와 비슷한 추론 속도를 가지지만, AP는 0.3% 향상됩니다.
5.4. Ablation study
5.4.1 Proposed compound scaling method
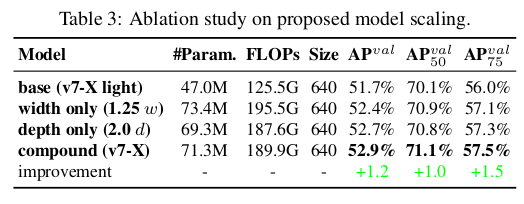
표 3은 다른 모델 스케일링 전략을 사용하여 확장할 때 얻은 결과를 보여줍니다. 그 중에서, 우리가 제안한 복합 스케일링 방법은 계산 블록의 깊이를 1.5배, 전환 블록의 너비를 1.25배로 확장하는 것입니다. 우리의 방법을 너비만 확장한 방법과 비교하면, 우리의 방법은 파라미터 수와 계산량을 줄이면서 AP를 0.5% 향상시킬 수 있습니다. 우리의 방법을 깊이만 확장한 방법과 비교하면, 우리의 방법은 파라미터 수를 2.9% 증가시키고 계산량을 1.2% 증가시켜 AP를 0.2% 향상시킬 수 있습니다. 표 3의 결과에서 볼 수 있듯이, 우리가 제안한 복합 스케일링 전략은 파라미터와 계산을 더 효율적으로 사용할 수 있습니다.
5.4.2 Proposed planned re-parameterized model
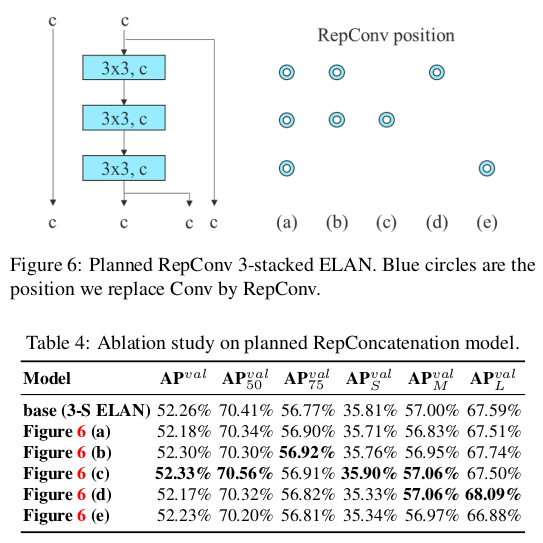
제안된 계획된 재파라미터화 모델의 일반성을 검증하기 위해, 우리는 이를 연결 기반 모델과 잔차 기반 모델에 각각 사용하여 검증합니다. 검증에 선택한 연결 기반 모델과 잔차 기반 모델은 각각 3-스택 ELAN과 CSPDarknet입니다.
연결 기반 모델 실험에서, 우리는 3-스택 ELAN의 다른 위치에 있는 3 × 3 컨볼루션 레이어를 RepConv로 교체하고, 자세한 구성은 그림 6에 나와 있습니다. 표 4에 나와 있는 결과에서 우리는 제안된 계획된 재파라미터화 모델에서 더 높은 AP 값을 모두 확인할 수 있습니다.
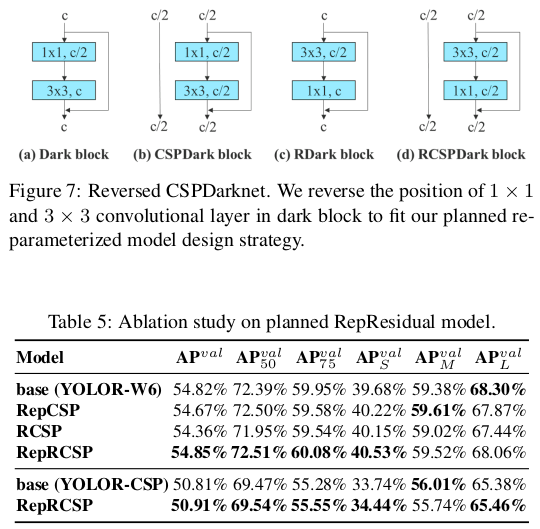
잔차 기반 모델을 다루는 실험에서는, 원래 다크 블록에 우리의 설계 전략에 맞는 3 × 3 컨볼루션 블록이 없기 때문에, 우리는 실험을 위해 반전된 다크 블록을 추가로 설계하였고, 그 아키텍처는 그림 7에 나와 있습니다. 다크 블록과 반전된 다크 블록이 있는 CSPDarknet이 정확히 동일한 수의 파라미터와 연산을 가지기 때문에, 비교가 공정합니다. 표 5에 나와 있는 실험 결과는 제안된 계획된 재파라미터화 모델이 잔차 기반 모델에서도 동일하게 효과적임을 완전히 확인합니다. 우리는 RepCSPResNet [85]의 설계도 우리의 설계 패턴에 맞음을 발견했습니다.
5.4.3 Proposed assistant loss for auxiliary head
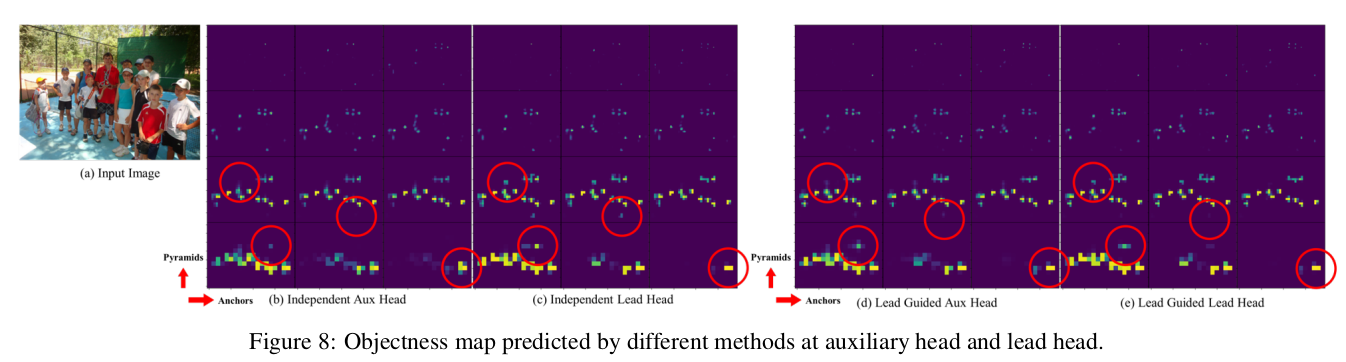
보조 헤드 실험에서의 어시스턴트 손실에서는 리드 헤드와 보조 헤드 방법에 대한 일반적인 독립 레이블 할당과 제안된 두 가지 리드 가이드 레이블 할당 방법을 비교합니다. 표 6에서 모든 비교 결과를 보여줍니다. 표 6에 나와 있는 결과에서 어시스턴트 손실을 증가시키는 모델은 전반적인 성능을 크게 향상시킬 수 있음을 알 수 있습니다. 또한, 제안된 리드 가이드 레이블 할당 전략은 $AP$, $AP_{50}$, $AP_{75}$에서 일반적인 독립 레이블 할당 전략보다 더 나은 성능을 보여줍니다. 제안된 어시스턴트용 거친 레이블과 리드 레이블용 세밀한 레이블 할당 전략은 모든 경우에서 최고의 결과를 냅니다. 그림 8에서는 보조 헤드와 리드 헤드에서 다른 방법으로 예측된 객체성 맵을 보여줍니다. 그림 8에서 보조 헤드가 리드 가이드 소프트 레이블을 학습하면 리드 헤드가 일관된 목표에서 잔여 정보를 추출하는 데 도움이 된다는 것을 알 수 있습니다.
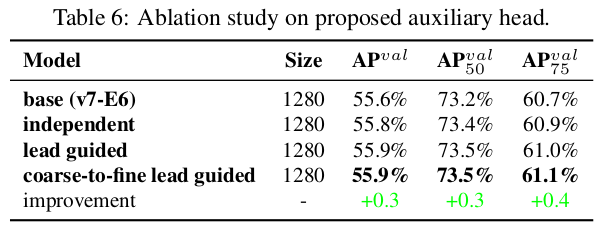
표 7에서는 보조 헤드의 디코더에 대한 제안된 거친-세밀 리드 가이드 레이블 할당 방법의 효과를 추가로 분석합니다. 즉, 상한 제약 조건을 도입한 경우와 도입하지 않은 경우의 결과를 비교했습니다. 표에 나와 있는 숫자로 판단했을 때, 객체의 중심에서의 거리에 의해 객체성의 상한을 제한하는 방법이 더 나은 성능을 얻을 수 있음을 알 수 있습니다.
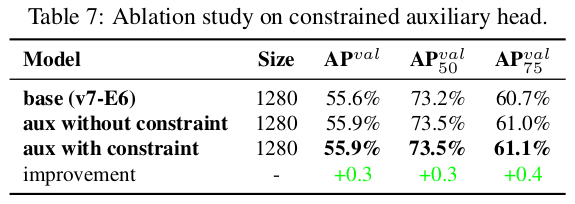
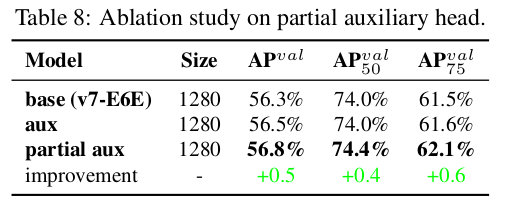
제안된 YOLOv7는 다중 피라미드를 사용하여 객체 검출 결과를 공동 예측하므로, 보조 헤드를 중간 계층의 피라미드에 직접 연결하여 훈련할 수 있습니다. 이러한 유형의 훈련은 다음 단계 피라미드 예측에서 손실될 수 있는 정보를 보완할 수 있습니다. 위의 이유로, 제안된 E-ELAN 아키텍처에서 부분 보조 헤드를 설계했습니다. 우리의 접근 방식은 보조 헤드를 결합 전의 특징 맵 세트 중 하나에 연결하여 보조 손실에 의해 직접 업데이트되지 않도록 하는 것입니다. 이 디자인은 리드 헤드의 각 피라미드가 여전히 다른 크기의 객체에서 정보를 얻을 수 있도록 합니다. 표 8에서는 거친-세밀 리드 가이드 방법과 부분 거친-세밀 리드 가이드 방법을 사용하여 얻은 결과를 보여줍니다. 분명히 부분 거친-세밀 리드 가이드 방법이 더 나은 보조 효과를 가지고 있습니다.
6. Conclusions
이 논문에서는 실시간 객체 검출기의 새로운 아키텍처와 이에 상응하는 모델 스케일링 방법을 제안합니다. 또한 객체 검출 방법의 진화 과정이 새로운 연구 주제를 생성한다는 것을 발견했습니다. 연구 과정에서 우리는 재파라미터화된 모듈의 교체 문제와 동적 레이블 할당 문제를 발견했습니다. 이 문제를 해결하기 위해 객체 검출의 정확도를 높이기 위한 훈련 가능한 프리비즈 방법을 제안합니다. 위에 기반하여 우리는 최첨단 결과를 얻는 YOLOv7 시리즈 객체 검출 시스템을 개발했습니다.
7. Acknowledgements
저자들은 계산 및 저장 자원을 제공해 준 고성능 컴퓨팅 국가 센터(NCHC)에 감사의 뜻을 전합니다.
8. More comparison
YOLOv7는 5 FPS에서 160 FPS 범위에서 모든 알려진 객체 탐지기를 속도와 정확성 면에서 능가하며, GPU V100에서 30 FPS 이상인 모든 알려진 실시간 객체 탐지기 중 가장 높은 정확도 56.8% AP test-dev / 56.8% AP min-val을 가지고 있습니다. YOLOv7-E6 객체 탐지기(56 FPS V100, 55.9% AP)는 변환기 기반 탐지기 SWIN-L Cascade-Mask R-CNN(9.2 FPS A100, 53.9% AP)보다 속도는 509% 빠르고 정확도는 2% 더 높으며, 컨볼루션 기반 탐지기 ConvNeXt-XL Cascade-Mask R-CNN(8.6 FPS A100, 55.2% AP)보다 속도는 551% 빠르고 정확도는 0.7% 더 높습니다. 또한, YOLOv7는 YOLOv4, YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B 및 많은 다른 객체 탐지기들을 속도와 정확성 면에서 능가합니다. 더욱이, 우리는 YOLOv7을 MS COCO 데이터셋에서 다른 데이터셋이나 사전 학습된 가중치를 사용하지 않고 훈련했습니다.
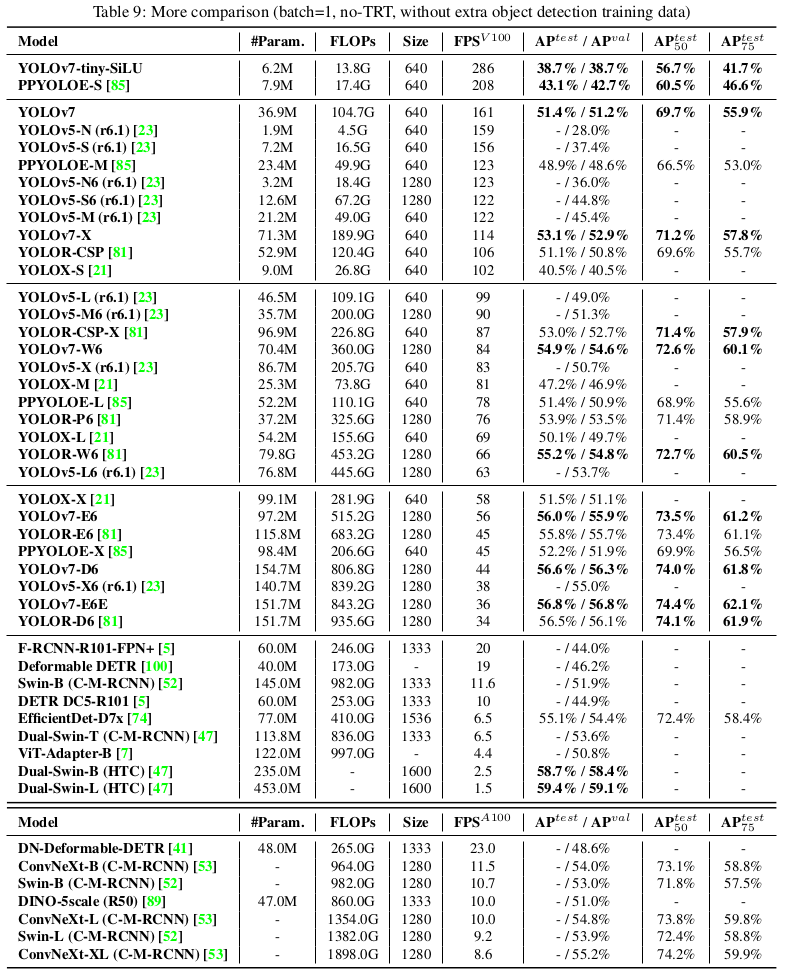
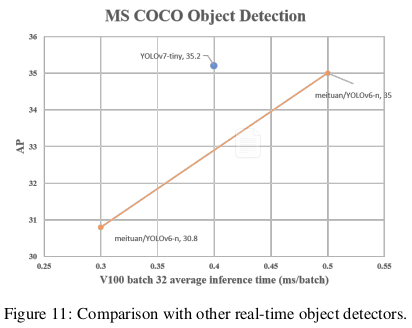
YOLOv7-E6E의 최대 정확도(56.8% AP) 실시간 모델은 COCO 데이터셋에서 메이투안/YOLOv6-s 모델(43.1% AP)보다 +13.7% AP 더 높습니다. 우리의 YOLOv7-tiny (35.2% AP, 0.4ms) 모델은 동일한 조건에서 메이투안/YOLOv6-n 모델(35.0% AP, 0.5ms)보다 +25% 더 빠르고 +0.2% AP 더 높습니다.

Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors

댓글남기기